Splunk组件和架构详解
本文主要讲解的是Splunk组件和架构!
Splunk主要解决的问题:统一管理分布在不同机器上的数据(比如日志数据)。如下图所示:
![]()
![]()
Splunk是一个功能完备的企业级产品,提供了命令行窗口,web图形界面接口和其他接口,查询结果展示,数据查询,权限控制,分布式管理服务,数据索引,网络端口监听,数据警报,文件监听等等。
![]()
Forwarder
Splunk提供了Forwarder组件,它的作用是把不同机器上面的数据,比如log,转发给indexer。forwarder可以运行在不同的操作系统上面。
forwarder支持:
- 元数据标签(资源,资源类型和主机)
- 可以设置缓存
- 可以压缩数据
- 支持SSL安全协议传输数据
- 可以使用任何有效的网络端口。
Splunk提供了三种forwarder,分别是universal forwarder、heavy forwarder和light forwarder。universal forwarder相对于其他两种最重要的优点是:它能够极大地减少对主机硬件资源的占用。但是,它也做出了一定的牺牲,比如不支持查询和建立数据索引。它们具体的官方解释请见:universal forwarder、heavy、light

Indexer
Indexer,顾名思义,它跟索引有关,实际上他不仅仅负责为数据建立索引,还负责响应查找索引数据的用户请求,还有读取数据和负责查找管理工作。虽然indexer可以在查找它本身的数据,但是,在多indexer的集群中,可以通过叫“search head”的组件来整合多个indexer,对外提供统一的查询管理和服务。如下图所示。search head的作用就是根据用户的查询请求查询各个indexers中的数据,融合indexers所返回的结果,统一显示给用户,它只负责查询,不负责建立索引。
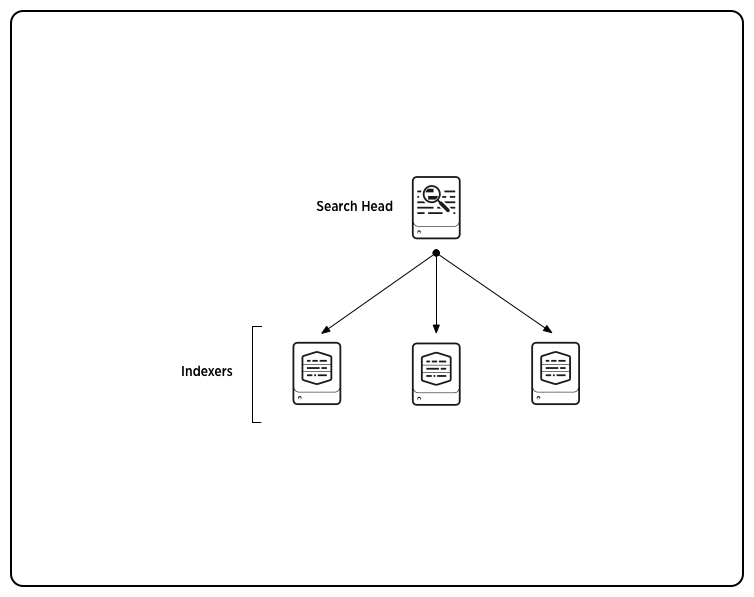
从整体上来看Splunk架构,结合下面两张图片,总体上分为两个部分,分别是数据发送、数据收集并索引。原始数据一开始一般是由不同机器产生,通过不同的组件向indexer发送这些原始数据,这些组件有splunk forwarders、syslog、WMI等等,数据发给indexer之后,indexer就会为数据建立索引,建立索引的目的是加快查询速度。这样之后,用户就可以通过统一的窗口操作数据了,比如查询。
![]()

如果我们系统平台比较大,产生的数据量比较大,那么我们可以不断扩展我们的splunk集群,splunk具备这种扩展能力。用户可以部署任意多个forwarder,用来转发刚刚产生的原始数据。Indexer也可以部署成为一个集群,统一下层提供接收原始数据、建立索引的服务,对上层提供搜索的服务。用户还可以部署多台用于搜索的Search Header。所以,用户可以根据自己平台的实际工作量来部署自己的splunck集群大小。
![]()
data pipeline
数据管道显示了建立索引期间的进程。如下图所示,从上到下,数据从产生的源头到最后建立索引可以提供给用户搜索这整个过程中数据被处理的过程。
数据管道为:数据输入 - 数据分析 - 建立索引 - 用户查询
![]()
reference
ppt
pictures
官方中文文档
universal forwarder
http://docs.splunk.com/Documentation/Forwarder/6.5.2/Forwarder/Abouttheuniversalforwarder
About forwarding and receiving data
http://docs.splunk.com/Documentation/Forwarder/6.5.2/Forwarder/Aboutforwardingandreceiving
Installation manual
http://docs.splunk.com/Documentation/Splunk/6.5.2/Installation/InstallonLinux
其他有关日志收集分析的信息:
ELK技术栈实践 Logstash ElasticSearch和Kibana
三款日志管理工具横向对比:Splunk vs Sumo Logic vs Logstash
kafka
Splunk组件和架构详解相关推荐
- 组件化实践详解(二)
在上一篇文章<组件化实践详解(一)>中我们介绍了组件化实践的目标和实践步骤,本文继续说说关于组件化实践遇到的问题及思考. 1.组件内的架构设计 这条本来我是不想写的,但是很多组件化的文章里 ...
- DL之DeepLabv1:DeepLabv1算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
DL之DeepLabv1:DeepLabv1算法的简介(论文介绍).架构详解.案例应用等配图集合之详细攻略 目录 DeepLabv1算法的简介(论文介绍) 0.实验结果 1.FCN局限性及其改进 De ...
- DL之SSD:SSD算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
DL之SSD:SSD算法的简介(论文介绍).架构详解.案例应用等配图集合之详细攻略 目录 SSD算法的简介(论文介绍) 0.SSD实验结果 1.架构图集合 2.SSD VS Yolo SSD算法的架构 ...
- DL之FasterR-CNN:Faster R-CNN算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
DL之FasterR-CNN:Faster R-CNN算法的简介(论文介绍).架构详解.案例应用等配图集合之详细攻略 目录 Faster R-CNN算法的简介(论文介绍) 1.实验结果 2.三者架构对 ...
- fusionsphere的核心组件_FusionSphere架构详解
FusionSphere 架构详解 关键字: 云计算 XEN Hypervisor FusionSphere 摘要: 本技术案例主要针对 Huawei FusionSphere 云计算软件架构进行深入 ...
- java调用webservice_笃学私教:Java开发网站架构演变过程-从单体应用到微服务架构详解...
原标题:笃学私教:Java开发网站架构演变过程-从单体应用到微服务架构详解 Java开发网站架构演变过程,到目前为止,大致分为5个阶段,分别为单体架构.集群架构.分布式架构.SOA架构和微服务架构.下 ...
- Android开发入门一之Android应用程序架构详解
Android应用程序架构详解如下: src/ java源代码存放目录 gen/自动生成目录 gen 目录中存放所有由Android开发工具自动生成的文件.目录中最重要的就是R.java文件.这个文件 ...
- 大型分布式架构详解:架构模式+敏捷性+可扩展+案例等
大型分布式架构详解:架构模式+敏捷性+可扩展+案例等 本篇是大型分布式网站架构的技术总结篇. 主要对大型分布式架构中涉及的架构模式.高性能.高可用.可伸缩.敏捷性.可扩展等技术点进行简要总结,对大型分 ...
- 揭开面纱:Kubernetes架构详解
[编者的话] 本文介绍了Kubernetes中的主要组件和各个组件的工作模式. 入门导论:Kubernetes组件和组件之间如何协同工作 本文讲的是揭开面纱:Kubernetes架构详解如果你正在实现 ...
最新文章
- SAP RETAIL 商品主数据里的Contents
- C# DateTime 日期加1天 减一天 加一月 减一月 等方法(转)
- Linux内存描述之概述--Linux内存管理(一)
- Mpvue+koa开发微信小程序——腾讯云开发环境的搭建及部署实现真机测试
- 分布式缓存——一致性哈希算法
- .npy文件_Numpy库使用入门(六)文件的存取
- 杀死 Oculus ,Facebook 改名 Meta ,是押注元宇宙还是“金蝉脱壳”?
- leetcode344题:反转字符串
- Flutter mixin用法详解
- IMM将软件测试成熟度分为5个,软件测试成熟度模型
- Android学习之动画(二)
- oracle pdb与cdb区别,浅谈oracle 12C的新特性-CDB和PDB
- android音乐同步到iphone,安卓手机上的音乐还能转移到iPhone,你信不信
- 腾讯云上海服务器稳定吗,腾讯云服务器上海机房速度怎么样 1M带宽是否够用
- ppt画深度学习网络图
- NLP经典论文:Sequence to Sequence、Encoder-Decoder 、GRU 笔记
- 沐风:做一个会自动赚钱的小程序
- 学生社团管理系统c语言代码,毕业设计—校园社团活动助手小程序
- NBUT1225-NEW RDSP MODE I
- 从红队视角看AWD攻击