揭秘Facebook数据库备份策略
首先,简要介绍一些Facebook相关的架构关键:
python
Facebook几乎所有的数据库自动化运维系统都是通过python实现的,所有可文档化的手工操作都有他对应的Python Library库来代替。此外,Facebook内部各个基础服务之间使用thrift作为通讯API的定义。为了很快速的开发基于thrift通讯的python service,Facebook内部使用叫做BaseController的框架,同时github上也有其对应的开源版本sparts。本文将提到的backup-agent也基于它实现。
部署方式
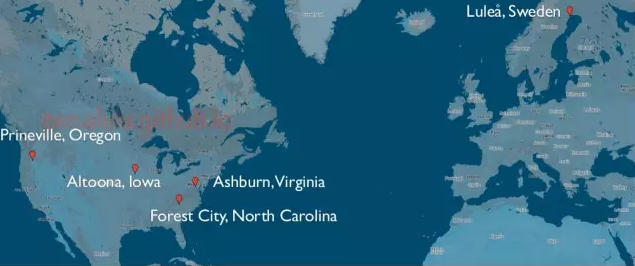
Master/Slave的部署方式,并且所有数据在5个机房中都在其中的2个或两个以上存在副本,本文把整个集群在后文用Recpliaset表示。(5个机房分部见下图)
数据备份的要素
任何数据备份都离不开这几个要素:备份存储形式,备份存储地,备份策略,备份有效性检验,备份来源。后文也会用这样的划分方式,对每一个要素用一个小节来具体介绍。
二备份形式
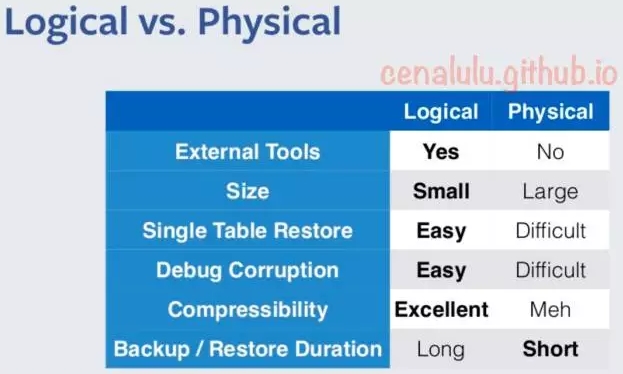
Facebook的MySQL备份形式可能会让你感到有些许惊讶。我们所有的Production MySQL数据都使用mysqldump进行逻辑备份。你一定和我最早听到这个事实的时候一样疑惑:那为什么不选择更为备份速度更快的基于xtrabackup的物理备份呢?原因主要有以下几点:
1、压缩率:这个是最根本的因素。在Facebook由于数据基数巨大。1%的存储空间节省,往往等同于省下了几十万美元的经费。由于物理备份中索引的存在,逻辑备份使用gzip后的压缩率仍然明显优于物理备份。尽管我们已经大规模的使用了Innodb Compress的功能,同样的数据库逻辑备份压缩后的大小,大约是物理备份的二分之一到三分之一左右。
2、内部服务依赖:我们的MySQL数据备份的作用并不仅仅是为了做灾难恢复。他也是数据仓库的非实时分析的基础数据来源。任何一个实验性的调研,都是以逻辑备份作为基础数据来初始化到临时数据仓库中的。而如果使用物理备份,显然要花更多得精力和人力在备份的Parse部分上。
3、其他因素:例如备份数据损坏的Debug,外部工具的开发成本等等方面,逻辑备份都因为其直接可读的文件形式都占据了一定的优势。
当然,这个备份策略并不是绝对最优的,或者说对于所有公司和架构都是普遍适用的。例如,也可以使用xtrabackup的Partial Backups来减小物理备份的体积,以达到和逻辑备份几乎相似的压缩率。而对于数据仓库dump需求,也完全可以通过对物理备份恢复后,再实时导出。在验证了备份有效性的同时也满足的业务需求。当然我们也不是完全不用xtrabackup,在Shard Migration和Instance Migration的时候我们还是会依赖基于物理备份的Rebuild来提升整个迁移速度的。
总而言之:在保证备份可用性的前提下,备份形式会更多的根据公司内部架构和资源来做灵活的调整。
三备份存储地
所有上市公司对于备份的存放地都有来自于审计的要求,当然除此之外我们的设计也还要能经受住每年一次的灾难性演练的考验。目前我们的备份主要有以下两个存放地:
Warm Backup
每个Datacenter中都有一个独立的HDFS集群专门负责存放备份数据,存放最近10天的备份文件(一个逻辑Shard的备份只会存储在一个HDFS中)。
Cold Backup
部分Datacenter中有Isilon设备上,所有超过10天的备份文件按策略转移到冷存储上。
99%的备份恢复需求都能从HDFS上得到满足,这点也比较可以理解。因为大部分用户的需求都是恢复到最近一周内某一天的某个时间点,或者恢复到某个误操作以前的状态。冷备份的存在更多的是用于应对HDFS逻辑故障以及来自于审计压力的历史归档需要。
四备份源的选择
之前也提到,由于多个Datacenter的存在,一个Replicaset中就会有多个Instance可以作为备份源的选择。所以,我们在对于从哪个节点进行备份的策略上也进行了一定的优化。
首先,我们用类似于一致性hash的方法把ShardName映射到一个bucket中,每个HDFS集群都会负责多个bucket的存储。当backup-agent发现当前有一个备份需求时,它会先通过hash决定目标HDFS物理地址,然后通过以下因素决定,应该从哪个MySQL节点,作为备份源进行备份。
网络流量
broekn slave
一致性
五备份策略
备份策略按照数据特点的不同,我们应用不同的备份策略。对于变更热点集中,增量数据多的用户数据,我们采用每隔三天做一次全量备份,期间进行增量备份的策略。对于数据变化量大,或者无法预估change pattern的数据,我们采用每天全量备份的策略。在每一台MySQL Server上,都会有一个Python实现的Backup agent负责每天备份的调度。它的主要职责就是根据配置中心的配置,具体并发起备份。同时决定的备份并发数量,不同实例上备份的优先级,备份失败的重试等等。
六全量备份
如同上文已经提到的,我们的全量备份使用mysqldump + qpress + HDFS client的管道方式,按照Shard为单位进行备份。所谓Shard对应于MySQL中得一个逻辑数据库。Shard和Shard之间可能存在并发。根据服务器硬件配置的不同,我们也有不同的并发策略。例如Flash card上我们可以支持同时运行2-3个mysqldump进行。此外,为了逻辑备份能够更快,并且对Server正常服务影响程度最小的方式运行,我们还使用了Logical Read Ahead的策略,并在mysqldump中添加了相应的option。
七增量备份
增量备份的方法,同样也是我们比较特殊的一个部分。相较于传统的基于Binlog的备份不同,我们的增量备份是基于全量数据的。由于全量备份是以Shard为单位存在的,一个MySQL实例上会有多个Shard,而如果我们以Binlog作为增量备份,就意味着各个Shard的增量备份存在于同一组Binlog中得不同位置。这样也就造成了不同逻辑备份之间的相互依赖,增加了备份的不确定性。假设我们在额外做一个Binlog解析按照Shard来切分的系统的话,那复杂度和不确定很显然会大大增加。此外,由于前面提到的热点数据集中,反复修改多得特点,Binlog中对于同一Object Row或者说同一Primary Key的DML重复度非常高。这样直接备份Binlog会有大量的存储空间浪费。所以,我们开发了一套只备份差异数据的特殊增量备份系统,也先后经历了两个大版本的演变。
版本一:
纯依赖于Hadoop的解决方案,第一版我们把这个问题简化成了HDFS的问题,或者说对MySQL端透明的方案。由于之前的Binlog是MIX级别的,因此没有办法只分析Binlog来合并生成增量备份。每天都往HDFS里写入一份全量备份,然后由Hadoop Job来对两个全备做差异比较并生成差异文件,并把较新的全量备份文件删除。这个方法的弊端也比较明显:HDFS的读写压力大,且浪费资源。每天要写入一份只用来作为比较的全量备份(并删除)。最终上线后发现,受制于HDFS的写入吞吐,已经硬件带宽限制,整个增量备份系统无法在一天内完成所有Shard的备份。
版本二:
我们仍然保持了原有系统的简单程度(对MySQL来说只有jave客户端,没有额外计算),同时又免去了每天都把全量备份写入HDFS冗余操作,取而代之的是通过流的方式实时生成差异文件。全量数据仍然从MySQL端读取,不同的是到了HDFS后,动态的读取最近一次的全量备份在内存中作比较,并做增量文件写入。这个版本也最终成为了我们现在Production上稳定运行一年多的版本。当然,这个方案也是有缺陷的。首先,引入额外的差异比较步骤,已经违背了减少系统复杂度的初衷。同时,每天都从MySQL读取一次全量数据也是对系统资源和网络资源一种不小的损耗。随着RBR的大面积应用,当获取全量Binlog的可靠度越来越高的前提下,我们可以基于Binlog作出一套更好的增量备份系统(详见下文第九点)
八备份验证
没有进行验证的备份是无效的。业界之前也有很多血的教训。例如下厨房的数据恢复,如果备份始终有效,就没有之后更多的故事不是么?所以在Facebook内部,所有的备份(全量/增量)都有一整套恢复验证策略和验证系统来负责备份的有效性。由于篇幅关系,这里我们只简单介绍下概况。
验证系统的主要运行机制是不间断的从热备份存储(HDFS)上根据metadata获取恢复优先级最高的备份,并且恢复到空闲机器上加以验证。越久没有做过验证的备份优先级越高;验证失败次数越多的Schema,优先级越高。如果对于一个逻辑分片(Shard),有连续超过3个备份验证失败,那么我们的alarm dashboard上就会出现相应的警告。验证的主要步骤包括:下载,解压,Load,验证,Binlog Replay等步骤,任何一个步骤的失败都会判定为备份无效。由于我们的PIT(point in time recovery)和验证系统使用的是完全相同的恢复代码,也就意味着,只要通过有效验证的备份就一定能够成功的恢复到任何一个历史上的时间点。
除了HDFS上备份的存储,由于历史数据归档和应对灾难性情况的需要,我们也会对冷备份上的备份做验证。这个验证相对就比较简单,由于之前备份在热存储上已经被验证过,所以我们只通过简单的备份文件checksum比对即可确定冷备份的完整性。
九现有问题和未来展望
由于篇幅关系,这里就不多赘述在整个备份系统演变过程中所遇到的那些趣事了。
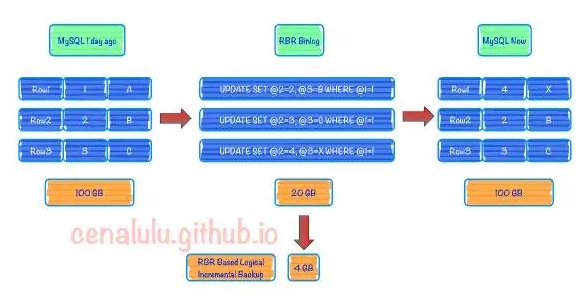
随着RBR在Production的逐步启用,我们可以大胆展望一种新的备份方式。基于RBR的逻辑增量备份。根据互联网用户的行为属性和2/8原则,我们不难假定活跃用户可能只占到20%的总用户数量。相应的数据库上每天用户数据的所有变更中,可能80%的变更都是由20%的重度活跃用户贡献的。我们用下图来举例子:一个100GB的数据库,每天的RBR形式的Binlog就只有20GB;而这20G的增量日志中又有80%的数据是重复用户的变更,所以实际上只有4G的数据是Replay到最终态所需要使用的有效增量数据。也就意味着对于一个100G的数据库,我们每天需要备份的raw数据只有4G,再加上文本压缩,可能最终的物理大小只有500MB。这无疑又会为公司节省几百万美金,当然也是我们接下来的工作重点之一!
Ref:
1. Massively Distributed Backups at Facebook Scale
2. Under the Hood: Automated backups
3. Making full table scan 10x faster in InnoDB
作者介绍:卢钧轶(cenalulu)
DBA+社群MySQL领域原创专家
6年MySQL运维领域相关经验,
目前就职于Facebook MySQL Infra Team,主要负责大规模MySQL数据库运维。在Failover,备份,监控,优化,数据库私有云等相关领域有一定经验和个人理解。
之前先后就职于BesTV和大众点评网。曾在阿里嘉年华和中华数据库大会上有过相关分享。
揭秘Facebook数据库备份策略相关推荐
- 数据库备份策略 分布式_管理优秀的分布式数据团队的4种基本策略
数据库备份策略 分布式 COVID-19 has forced nearly every organization to adapt to a new workforce reality: distr ...
- Windows环境下的Oracle数据库备份策略
最近公司一个新项目上线,服务器有限,无法搭建DG,特制定以下数据库备份策略: 1.每天凌晨1点进行数据库全库导出备份 代码清单: expdp 数据库用户名/密码@IP地址/数据库实例名 schemas ...
- postgresql数据库备份策略
一.生产备份方式:pg_basebackup PostgreSQL脚本监控由于没有安装RMAN插件,我们使用PG_BASEBACKUP进行备份. 任何数据库搭建完成,准备投入使用之后,首先要确定的就是 ...
- mysql数据库备份策略及应用场景
由于mysql存在多种数据库备份方式,而且各有利弊,对于我们初学者来说,选择合适的备份方式确实有些困难.个人觉得,首先要基于公司的需求,考虑能够容忍丢失多少数据.花多少人力时间成本等,这是我们制定备份 ...
- SQL Server 2008备份策略设计下(六)
上一篇博文探讨了各种恢复模式和备份类型,这一节继续来探讨如何设计备份策略.设计一个数据库的最佳备份策略,会面临如何选择使用哪种恢复模式的问题,因为恢复模式控制着备份和还原的行为.一般来讲,简单恢复模式 ...
- 企业级数据库备份方案完全攻略
在当今的发达的信息领域,体现价值的珍贵性的不是计算机软件,也不是计算机硬件,而是计算机内的各种宝贵数据.但是各种因素像人为错误,硬盘损坏,电脑病毒或者各种停电,自然灾害都有可能使得数据的使用变得不牢靠 ...
- MySQL数据库备份恢复(备份恢复)【备份策略三:mydumper备份数据库】
备份策略三:mydumper备份数据库 Mydumper介绍 Mydumper主要特性 语法样式 常用参数(mydumper)[备份] 常用参数(myloader)[恢复] 使用示范(备份) 使用示范 ...
- DG环境数据库RMAN备份策略制定
DG环境数据库RMAN备份策略制定: 主库(Primary) 全库备份 归档备份 删除历史文件夹 备库(Standby) 删除归档 引用说明 主库(Primary) $ crontab -l 0 1 ...
- SQL Server数据库设置自动备份策略
一. 简单介绍 SQL Server自带的维护计划是一个非常有用的维护工具,能够完成大部分的数据库的维护任务. 数据库的备份也是日常工作中非常重要的一个环节.备份的方法非常的多. 今天给大家介绍最简单 ...
- mysql数据库恢复策略_MySQL 备份和恢复策略(一)
在数据库表丢失或损坏的情况下,备份你的数据库是很重要的.如果发生系统崩溃,你肯定想能够将你的表尽可能丢失最少的数据恢复到崩溃发生时的状态.本文主要对MyISAM表做备份恢复. 备份策略一:直接拷贝数据 ...
最新文章
- 存储 dict 的元素前是计算 key 的 hash 值?
- leetcode Longest Palindromic Substring
- MapReduce基础开发之八HDFS文件CRUD操作
- STL 之随机访问迭代器
- Xcode自定义字体不能应用的原因
- 获取父线程 java_java子线程中获取父线程的threadLocal中的值
- 【问题收集·知识储备】Xcode只能选择My Mac,不能选择模拟器如何解决?
- 论文阅读 - Group Normalization
- 6 计算机组成原理第五章 中央处理器 CPU功能和结构 指令执行过程
- ccs是轮_CCS-船型标准.pdf
- 腾讯推出基于区块链存证的“点亮莫高窟”活动
- 案例分享|某医药集团的BI建设案例
- HTTPS客户端的java实现
- MyEclipse的html页面 design视图中 关闭可视化界面
- 【spring bean】bean的配置和创建方式
- VS2015编译VS2013工程文件出错
- MVVM后,下一代开发模式在哪?
- goredis文档中文翻译---Getting started with Golang Redis
- 银河麒麟V10下载安装使用体验(上)
- Source Insight 4.0 选中高亮