大数据求索(8):Spark Streaming简易入门一
大数据求索(8):Spark Streaming简易入门一
一、Spark Streaming简单介绍
Spark Streaming是基于Spark Core上的一个应用程序,可伸缩,高吞吐,容错(这里主要是借助Spark Core的容错方式)处理在线数据流,数据可以有不同的来源,以及同时处理不同来源的数据。Spark Streaming处理的数据可以结合ML和Graph。
Spark Streaming本身是随着流进来的数据按照时间为单位生成Job,然后触发Job,在Cluster执行的一个流式处理引擎,本质上说是加上了时间维度的批处理。
二、Spark Streaming作用
Spark Streaming支持从多种数据源中读取数据,如Kafka,Flume,HDFS,Kinesis,Twitter等,并且可以使用高阶函数如map,reduce,join,window等操作,处理后的数据可以保存到文件系统,数据库,Dashboard等。
![]()
三、Spark Streaming原理
Spark Streaming工作原理如下图所示:
![]()
- 以时间为单位将数据流切分成离散的数据单位
- 将每批数据看做RDD,使用RDD操作符处理
- 最终结果以RDD为单位返回
输入的数据流经过Spark Streaming的receiver,数据切分为DStream(类似RDD,DStream是Spark Streaming中流数据的逻辑抽象),然后DStream被Spark Core的离线计算引擎执行并行处理。
简言之,Spark Streaming就是把数据按时间切分,然后按传统离线处理的方式计算。从计算流程角度看就是多了对数据收集和按时间节分。
四、Spark Streaming核心概念
4.1 Streaming Context
类似于Spark Core,要想使用Spark Streaming,需要创建一个StreamingContext对象作为入口。类似代码如下:
import org.apache.spark._
import org.apache.spark.streaming._val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
观察源码可以发现,其实StreamingContext实现还是创建了一个SparkContext。其中,第二个参数Seconds(1)表示1秒处理一次。目前还是基于秒级的计算,无法做到毫秒级。
Spark Streaming也可以通过传入一个SparkContext对象来创建
import org.apache.spark.streaming._val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))
当创建好上下文对象以后,需要做如下事情:
- 通过创建一个DStreams来定义输入源
- 通过将transformation 和output 操作应用于DStream来定义流式计算
- 开始接收数据并使用streamingContext.start()启动
- 等待使用streamingContext.awaitTermination()停止处理(手动或由于任何错误)
- 可以使用streamingContext.stop()手动停止处理
注意:
- 一旦上下文已经启动,就不能设置或添加新的流式计算。
- 一旦上下文停止后,无法重新启动。(不要和重新运行程序重新创建一个混淆)
- 在JVM中只能同时运行一个StreamingContext
- StreamingContext上的stop也会停止SparkContext。要仅停止StreamingContext,将stopSparkContext的stop的可选参数设置为false。
- 只要在创建下一个StreamingContext之前停止前一个StreamingContext(不停止SparkContext),就可以重复使用SparkContext来创建多个StreamingContexts。
4.2 Discretized Streams (DStreams)
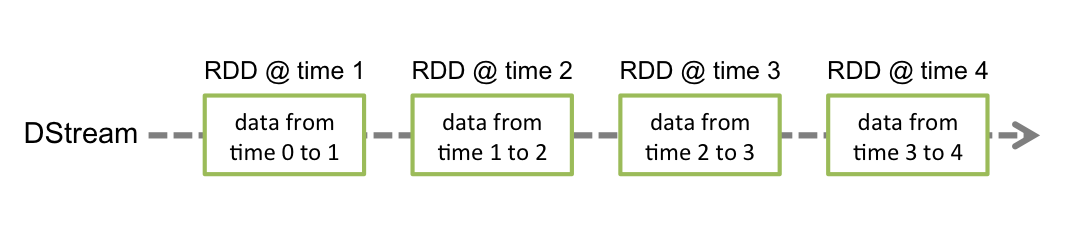
DStream可以说是SPark Streaming 的核心。它代表连续的数据流,可以是从源接收的输入数据流,也可以由转换操作生成的已经处理过的数据流。内部实现上,DStreams其实是一个连续的RDD序列,其中的每个RDD都包含来自特定时间间隔的数据。如下图所示:
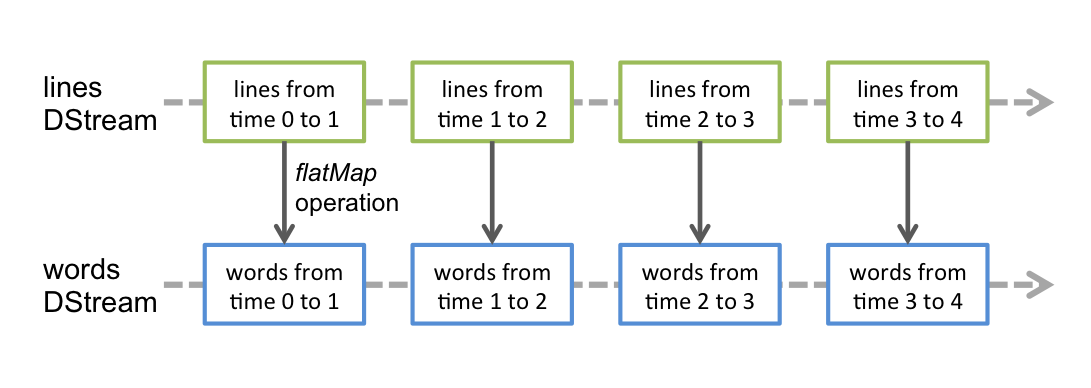
任何应用在DStream上的操作都会转换为底层RDD上的操作。对于词频统计来说,flatMap算子应用于DStream每行中上的每一个RDD以生成单词DStream的RDDs。如下图所示:
4.2 Input DStreams 和 Receivers
Input DStreams代表从Streaming源接收到的数据构成的DStreams。每一个Input DStream(除了file stream)都与一个Receiver对象相关联,这个对象从源接收数据并将其存储在Spark的内存中进行处理。
Spark Streaming提供两种策略用于内置的streaming源
basic sources:
sources直接在StreamingContext的API中得到,如文件系统、socket连接等
advanced sources:
像Kafka、Flume等源,可通过额外的工具类获得,这些需要引入额外的jar包。
注意,如果想在streaming程序中并行接收多个streams数据,可以创建多个input DStreams。这将创建多个Receivers,这些receiver将同时接收多个数据流。但是,Spark的worker/exector是一个长期运行的任务,因此它占用了分配给Spark Streaming应用程序的其中一个核(线程)。所以采用local模式运行,至少分配2个核,不然无法进行下面的计算。
注意点:
- 在本地运行Spark Streaming程序时,请勿使用“local”或“local [1]”作为主URL。这两种模式都意味着只有一个线程用于本地运行任务。如果此时再用receiver接收Input DStream,这单个线程便用来运行Receiver,不会用于接下来的处理数据了。因此,采用“local[n]”,这里的n要大于Receiver的数量。
- 在集群上运行时,分配给Spark Streaming应用程序的核心数必须大于接收器数。否则系统将接收数据,但无法处理数据。
4.3 Basic Sources
上面的举例中,是从套接字中接收文本信息创建一个DStream。除了sockets,StreamingContext API提供了从文件作为输入源创建DStream的方法。
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)
fileStream:用于从与HDFS API兼容的任何文件系统上的文件中读取数据(如HDFS、S3、NFS等),创建一个DStream。
Spark Streaming将会监视传入的dataDirectory目录,并处理在这个目录下创建的所有文件,但不支持嵌套目录
注意:
- 文件必须有相同的格式
- 必须通过原子move或rename的到此目录下的文件
- 一旦移动,这个文件将不能改变。因此,即使这个文件后面被追加了数据,新数据也不会被读取。
下一篇将继续介绍。
大数据求索(8):Spark Streaming简易入门一相关推荐
- 大数据技术之Spark Streaming概述
前言 数据处理延迟的长短 实时数据处理:毫秒级别 离线数据处理:小时 or 天 数据处理的方式 流式(streaming)数据处理 批量(batch)数据处理 spark Streaming也是基于s ...
- sparkstreaming监听hdfs目录_大数据系列之Spark Streaming接入Kafka数据
Spark Streaming官方提供Receiver-based和Direct Approach两种方法接入Kafka数据,本文简单介绍两种方式的pyspark实现. 1.Spark Streami ...
- 大数据Hadoop之——Spark SQL+Spark Streaming
文章目录 一.Spark SQL概述 二.SparkSQL版本 1)SparkSQL的演变之路 2)shark与SparkSQL对比 3)SparkSession 三.RDD.DataFrames和D ...
- 大数据hadoop与spark研究——1 spark环境搭建
第一章 介绍 一. spark组件 Spark是一个用于集群计算的通用计算框架 Spark可将如何Hadoop分布式文件系统(HDFS)上的文件读取为分布式数据集(RDD) Spark是用Scala写 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师.开 ...
- 大数据技术之Spark(一)——Spark概述
大数据技术之Spark(一)--Spark概述 文章目录 前言 一.Spark基础 1.1 Spark是什么 1.2 Spark VS Hadoop 1.3 Spark优势及特点 1.3.1 优秀的数 ...
- 行业大数据 -- 基于hadoop+spark+mongodb+mysql开发医院临床知识库系统(建议收藏)
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大 数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫 ...
- Python+大数据-数据处理与分析-pandas快速入门
Python+大数据-数据处理与分析-pandas快速入门 1.Pandas快速入门 1.1DataFrame和Series介绍 1)DataFrame 用来处理结构化数据(SQL数据表,Excel表 ...
最新文章
- python 日志模块 logging
- python导入本地文件-Python使用import导入本地脚本及导入模块的技巧总结
- python parser count_Python分析哪座城市小吃最好吃
- 公钥和私钥的简单通俗说明
- 如何在 Asp.Net Core 中 管理敏感数据
- d3设置line长度_Graph Embedding之LINE算法解读
- mysql隐藏information_如何让普通用户登录phpmyadmin不显示information_schema
- mysql-5.7.16-winx64+Navicat安装及配置
- 【控制】《最优控制理论与系统》-胡寿松老师-目录
- Centos7/RedHat7安装NVIDIA显卡驱动
- 基于低代码平台实现的政务督办管理系统有哪些特色功能?
- 如何杀掉defunct进程
- Unity5.1 新的网络引擎UNET(十五) Networking 引用--中
- jsf java_JSF学习实战
- NBD Network Block Device
- sed正则表达式替换字符方法
- python银行家算法例题详解_攒人品之作-能考408大题的知识点整理(有两个知识点的补充)...
- 转:鏖战双十一-阿里直播平台面临的技术挑战(webSocket, 敏感词过滤等很不错)...
- CSS------定位和动画
- 开始学习es(饿死)