Java数据结构之链表、树、堆、图手写双向非循环链表
数据结构、手写双向非循环链表
文章目录
- 数据结构、手写双向非循环链表
- 链表
- 1、链表的分类
- 2、链表的特点
- 二、手写双向非循环链表
- 2.1方法总结
- 2.2 环境搭建
- 2.3 add 添加结点
- 2.3.1 *addTail* 实现尾插法
- 2.3.2 *add Head*实现头插法
- 2.4 *get*得到索引节点的值
- *2.5 getNode* 根据索引得到节点
- ***2.6 checkIndex*** 检查索引
- 2.7 size 返回链表长度
- 2.8 *deleteByIndex* 根据索引删除节点*
- 2.9 ***deleteByValue***
- 三、树、堆、图浅显解释
- 3.1 树
- 3.1.1 二叉树
- 3.1.2 查找树
- 3.1.3 平衡二叉树
- 3.1.4 红黑树
- 3.2 图
- **1**. **介绍**
链表
链表为典型的链式结构,非连续空间
1、链表的分类
- 单向链表:
如果前一个结点存储了后一个结点地址,后一个结点没有存储前一个结点地址,这种链表称为单向链表
![]()
2. 双向链表
如果前一个结点存储了后一个结点地址,后一个结点也存储前一个结点地址,这种链表称为双向链表
![]()
- 循环链表
![]()
4. 总结:
链表分类:单向非循环链表、单向循环链表、双向非循环链表、双向循环链表。
2、链表的特点
1. 存储空间不连续。
2. 新增、删除元素效率高于数组。
3. 遍历效率,丧失随机访问的能力。
二、手写双向非循环链表
双向链表中每个结点中存三个部分的值
- 该节点的上一个节点
- 该节点的值
- 该节点的下一个结点
上一个节点与下一个节点存的应该是地址
链表也就是说是由一个个节点通过地址相互连接串起来,像是一根链条环环相扣所以叫做链表
非循环双向链表:
1、首尾不想连
2、每个结点需要存储上个结点与下个结点的地址,头结点的上一个结点地址为null,尾结点下个结点地址为 null
优势:
快速的添加和删除
劣势:
链表不具备随机访问能力。所以每次获取元素都需要从头部或者从尾部一个一个找,可以判断要查询元素的索引值,如果要查询索引值超过最大索引的一半,从后往前找,反之从前往后找
添加新结点的方式:
- 头插法——把新结点当做头结点
- 尾插法——把新结点当做尾结点
2.1方法总结
- 添加结点——public void add(E e)
- 尾插法——public void addLast(E e)
- 头插法——public void addHead(E e)
- 根据索引获得结点中的值——public E get(int index)
- 校验索引——public void checkIndex(int index)
- 获取节点数量——public int size()
- 根据索引修改结点中的值——public boolean set(int index, E e)
- public Node getNode(int index)
- 根据索引删除链表中的节点——public bolean deleteByIndex(int index)
- 根据值删除链表中的节点——public boolean deleteByValue(E e)
- 获取链表中所有的值——public String toString()
2.2 环境搭建
首先我们需要链表类的接口,规定方法和参数
public interface DoubleLinkedList<E> {/*** add new node to tail* @param e node value*/void add(E e);/*** get the value at the index* @param index index* @return value*/E get(int index);/*** return effective value's number* @return number*/int size();/*** revise value at the index* @param index index* @param e revise value* @return whether revise successfully*/boolean set(int index, E e);/*** delete by index* @param index index* @return whether delete successfully*/boolean deleteByIndex(int index);/*** delete by value* @param e value* @return whether delete successfully*/boolean deleteByValue(E e);
}
然后来准备链表的实现类,
- 链表实现类需要有节点,所以需要创建节点的类,由于该类只在创建链表时使用,可以使用内部类的方法创建
- 链表需要记录总共有多少个节点,这时我们需要一个计数器
- 链表实现类需要记录头结点与尾结点,与Node形成关系
- 需要重写 toString 方法,方便直观查看
public class DLListImpl<E> implements DoubleLinkedList<E> {/*** counter*/private int count;/*** head node*/private Node<E> head;/*** tail node*/private Node<E> tail;private class Node<E> {Node<E> pre;E item;Node<E> next;public Node() {}public Node(Node<E> pre, E item, Node<E> next) {this.pre = pre;this.item = item;this.next = next;}}@Overridepublic String toString() {if (head == null) {return "DLListImpl{" +"count=" + 0 +'}';}Node<E> node = this.head;StringBuilder stringBuilder = new StringBuilder();for (int i = 0; i < count; i++) {stringBuilder.append("DLListImpl{" +"id = " + i +", item= " + node.item +'}' + "\n" + " ====================" + "\n");node = node.next;}stringBuilder.append("count = " + count + " head = " + head.item + " tail = " + tail.item + "\n");return stringBuilder.toString();}
}2.3 add 添加结点
用户传来结点的值,
方法中需要创建新结点,
把传来的值存到节点中,
将节点加入到链表中
链表的节点添加可以使用头插法也可以使用尾插法
类中提供头插法与尾插法,默认调用的是尾插法
2.3.1 addTail 实现尾插法
- 接受传递的数据
- 新建节点,节点的父节点这里用 pre 表示,pre 可以指向该类中 head
- 然后做判断,如果 该链表中的head为空,也就是说tail为空,给对象中的链表还没有节点,所以新建的节点也就是第一个节点,那么它即是该类的 head 也是 tail
如果 该链表中的head不为空,该类的 tail 应该等于新建节点
- 最终应该让计数器加一
实现代码
/*** use tail insertion** @param e new node value* 1. build a new node(need old tail node)* 2.tail set to the new node* 3.judge whether the old tail node is null* true -> set the new node to be head node* false -> set the new node to be old tail node next*/public void addLast(E e) {if (e == null) {System.out.println("Null Add!!!");return;}Node<E> oldLast = this.tail;Node<E> newLast = new Node<>(oldLast, e, null);this.tail = newLast;if (oldLast == null) {this.head = newLast;} else {oldLast.next = newLast;}count++;}
2.3.2 add Head实现头插法
首先创建一个新结点 newnode 来存储值,newnode 中的下一个节点 next 为类中的头结点,将类中尾结点设置为newnode
判断类中 head 节点是否为空,如果为空,newnode 赋值给 类中 tail 节点
如果不为空,类中之前的 head 的 pre 节点为 newnode
计数器加一
/*** use head insertion** @param e new node value* 1. build a new node(need old head node)* 2.head node set to the new node* 3.judge whether the head tail node is null* true -> set the new node to be tail node* false -> set the new node to be old head node pre*/public void addHead(E e) {if (e == null) {System.out.println("Add Null!!!");return;}Node<E> oldHead = this.head;Node<E> newNode = new Node<>(null, e, oldHead);this.head = newNode;if (oldHead == null) {this.tail = newNode;} else {oldHead.pre = newNode;}count++;}
2.4 get得到索引节点的值
根据得到的索引进行循环,这里进行判断,
如果传来的索引大于count / 2 那就倒着循环
否则从头开始
这里的索引需要注意:我们默认索引是从0开始的,所以如果是从头开始,那应该是从 0 循环到 index-1(包括)
如果是倒着循环应该是从 count-2 到 index(包括)
在循环中为了得到索引处结点需要使用一个新结点先等于 head 或者 tail 随后一直调用 新节点 = 新节点.next 或者 新节点 = 新节点.pre
这也就是为什么我们需要减一次循环的原因,因为在还没执行0的时候节点已经有了*** head*** 的值
返回索引节点的值
/*** @param index index* @return value of index* 1. check index* 2. if index > count / 2* true -> form before to behind to search* false -> form behind to before to search* 3. return value*/@Overridepublic E get(int index) {checkIndex(index);Node<E> eNode = new Node<>();if (index < (count >> 1)) {eNode = this.head;for (int i = 1; i <= index; i++) {eNode = eNode.next;}} else {eNode = this.tail;for (int i = count - 2 ; i >= index; i--) {eNode = eNode.pre;}}return eNode.item;}
2.5 getNode 根据索引得到节点
该方法实现过程与 get 基本完全一样,不一样就是返回值,
get 方法返回的是索引节点的值,getNode 返回的是索引节点
/*** return Node of index** @param index* @return Node* 1. use the logic of get()* 2. return Node*/private Node<E> getNode(int index) {checkIndex(index);Node<E> eNode = new Node<>();if (index < (count >> 1)) {eNode = this.head;for (int i = 1; i <= index; i++) {eNode = eNode.next;}} else {eNode = this.tail;for (int i = count - 2; i >= index; i--) {eNode = eNode.pre;}}return eNode;}
2.6 checkIndex 检查索引
- 检查索引是否超出范围
- 如果超出则抛出自定义异常类,输出错误信息
public void checkIndex(int index) {if (index < 0 || index > count - 1) {throw new LinkedListOutOfBoundsExecption("Exceeded maximum range of the linked-list index should between 0 ~ " + (count - 1));}}
自定义异常类
public class LinkedListOutOfBoundsExecption extends RuntimeException{/*** Constructs a new runtime exception with {@code null} as its* detail message. The cause is not initialized, and may subsequently be* initialized by a call to {@link #initCause}.*/public LinkedListOutOfBoundsExecption() {}/*** Constructs a new runtime exception with the specified detail message.* The cause is not initialized, and may subsequently be initialized by a* call to {@link #initCause}.** @param message the detail message. The detail message is saved for* later retrieval by the {@link #getMessage()} method.*/public LinkedListOutOfBoundsExecption(String message) {super(message);}
}
2.7 size 返回链表长度
- 返回*** count*** 值
@Overridepublic int size() {return count;}
2.8 deleteByIndex 根据索引删除节点*
- 调用 getNode 方法,根据索引获得待删除节点 node
- 判断 node
- 是否同时为头结点&&尾结点 -> 如果是则要把 head && tail 都要赋值为 null
- 是否只为头结点 -> 要把 node ->next 赋值到 head ,并且 head = node.next, node.next.pre = null
- 是否只为尾结点 ->要把 node -> pre 赋值到 tail,并且 tail = node.pre, node.pre.next = null
- 是否既不是头结点也不是尾结点,node.pre.next = node.next, node.next.pre = node.pre
- 将 node 的值等于 null,返回 是否删除成功
/*** @param index index* @return whether success* 1. check index* 2. get node of the index* 3. if index node is head or tail* index = head&&tail -> head = null, tail = null* index = head -> head = index.next, index.next.head = null* index = tail -> tail = index.pre, index.pre.next = null* index != tali&&head -> index.next.head = index.pre , index.pre.next = index.next*/@Overridepublic boolean deleteByIndex(int index) {try {checkIndex(index);Node<E> node = getNode(index);if (node == this.tail && node == this.head) {this.head = null;this.tail = null;count--;} else if (node == this.head) {this.head = node.next;node.next.pre = null;count--;} else if (node == this.tail) {this.tail = node.pre;node.pre.next = null;count--;} else {node.pre.next = node.next;node.next.pre = node.pre;count--;}node = null;return true;} catch (Exception e) {e.printStackTrace();return false;}}
2.9 deleteByValue
- 判断传来的值是否为空,
- 循环判断,如果节点中的值等于传来的值,就执行 deleteByIndex 方法
- 若所有都遍历过了但还是没有,输出不存在
@Overridepublic boolean deleteByValue(E e) {if (e == null) {System.out.println("Delete Null!!!");return false;}boolean flag = false;Node<E> node = head;for (int i = 0; i < count; i++) {if (node.item.equals(e)) {deleteByIndex(i);flag = true;}}if (flag){return true;}else {System.out.println("Don't Exit!!!\n");return false;}}
三、树、堆、图浅显解释
3.1 树
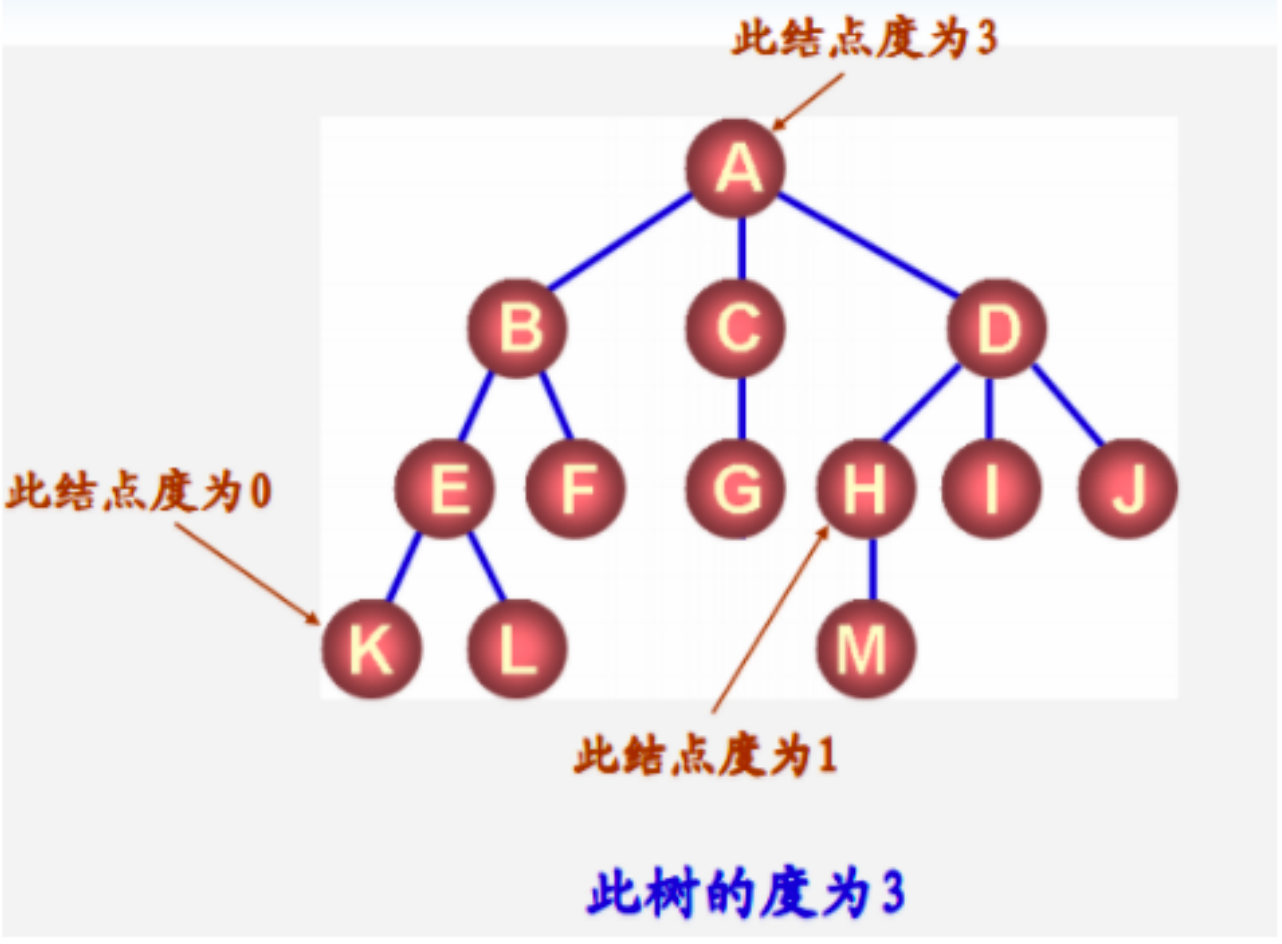
结点拥有的子树的数目称为结点的度(Degree)。
度为0的结点称为叶子(leaf )结点或终端结点。度不为 0 的结点称为 非终端结点或分支结点。除根之外的分支结点也称为内部结点。
树内各结点的度的最大值称为树的度。
3.1.1 二叉树
二叉树或者是一棵空树,或者是一棵由一个根结点和两棵互不相交的分别称为根的左子树和右子树的子树所组成的非空树。
满二叉树:
满二叉树中,每层结点都达到最大数,即每层结点都是满的,因此称为满二叉树。
完全二叉树:
若在一棵满二叉树中,在最下层从最右侧起去掉相邻的若干叶子结点,得到的二叉树即为完全二叉树。
二叉树的存储结构
二叉树存储结构有两种:顺序存储结构和链式存储结构。
3.1.2 查找树
二叉查找/搜索/排序树 BST (binary search/sort tree)
或者是一棵空树;
或者是具有下列性质的二叉树:
(1)若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若它的右子树上所有结点的值均大于它的根结点的值;
(3)它的左、右子树也分别为二叉排序树。
注意:
查找树中每个结点都有一个key,排序时的条件是以key作为排序条件。查找树是不允许出现相同key值的结点的。
缺点:极限情况下,查找树是一个链表。
3.1.3 平衡二叉树
平衡二叉树为是了解决查找树成为链表的情况,它具备查找树的优点。
平衡二叉树(Self-balancing binary search tree) 自平衡二叉查找树 又被称为AVL树, 它是一 棵空树, 或它的左右两个子树的高度差(平衡因子)的绝对值不超过1, 并且左右两个子树都是一棵平衡二叉树, 同时,平衡二叉树必定是二叉搜索树,反之则不一定
平衡因子(平衡度):结点的平衡因子是结点的左子树的高度减去右子树的高度。(或反之定义)
平衡二叉树:每个结点的平衡因子都为 1、-1、0 的二叉排序树。或者说每个结点的左右子树的高度最多差1的二叉排序树。
平衡二叉树的目的是为了减少二叉查找树层次,提高查找速度
平衡二叉树的常用实现方法有AVL、红黑树、替罪羊树、Treap、伸展树等
全完平衡二叉树:左右高度相等。
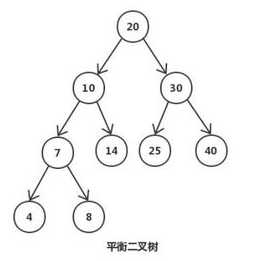
AVL树缺点:插入或删除元素时为了保证平衡可能出现多次旋转。
3.1.4 红黑树
红黑树是为了解决平衡树在插入或删除结点时频繁左旋和右旋问题。它具备平衡树的优点。
R-B Tree,全称是Red-Black Tree,又称为"红黑树",它一种平衡二叉树。红黑树的每个结点上都有存储位表示结点的颜色,可以是红(Red)或黑(Black)。
红黑树的特性:
(1)每个结点或者是黑色,或者是红色。
(2)根结点是黑色。
(3)每个叶子结点(NIL)是黑色。 [注意:这里叶子结点,是指为空(NIL或NULL)的叶子结点!]
(4)如果一个结点是红色的,则它的子结点必须是黑色的。
(5)从一个结点到该结点的子孙结点的所有路径上包含相同数目的黑结点。
注意:
(1) 特性(3)中的叶子结点,是只为空(NIL或null)的结点。
(2) 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树
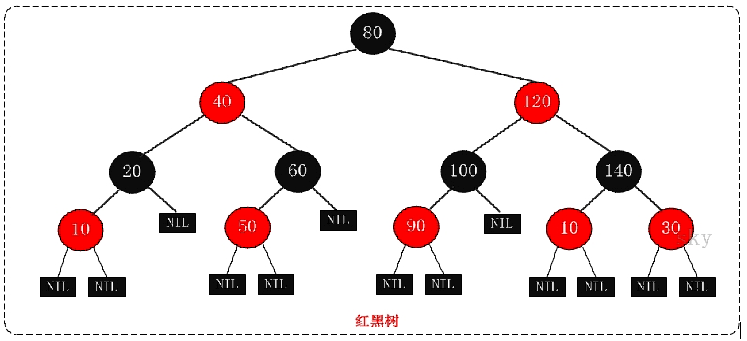
红黑树的应用比较广泛,主要是用它来存储有序的数据,它的时间复杂度是O(logN),效率非常之高。
它虽然是复杂的,但最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目。
例如,Java集合中的TreeSet和TreeMap,C++ STL中的set、map,以及Linux虚拟内存的管理,都是通过红黑树去实现的。
区别
1. 红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
2. 平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新结点之后需要旋转的次数不能预知。
3.2 图
1. 介绍
图的基本概念:多对多关系
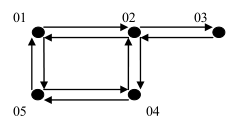
图(graph)是一种网状数据结构,图是由非空顶点集合和一个描述顶点间关系的集合组成。
在无向图和有向图中 V 中的元素都称为顶点,而顶点之间的关系却有不同的称谓,即弧或边,为避免麻烦,在不影响理解的前提下,我们统一的将它们称为边(edge) 。
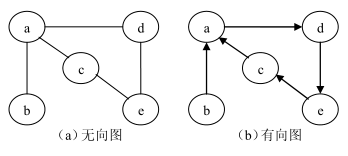
无向图实际上也是有向图,是双向图
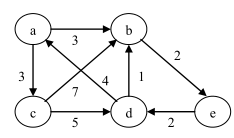
加权图:
在实际应用中,图不但需要表示元素之间是否存在某种关系,而且图的边往往与具有一定实际意义的数有关,即每条边都有与它相关的实数,称为权。
这些权值可以表示从一个顶点到另一个顶点的距离或消耗等信息,在本章中假设边的权均为正数。
这种边上具有权值的图称为带权图(weighted graph)
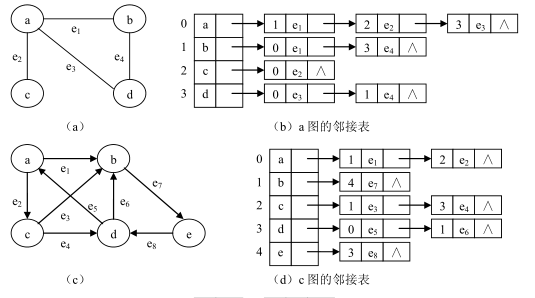
**图的存储结构: **可以采用顺序存储结构和链式存储结构,更多采用链式存储结构
**邻接表:**链表 链式存储结构
Java数据结构之链表、树、堆、图手写双向非循环链表相关推荐
- Java数据结构之链表(单链表)
文章目录 一.链表 概念 结构 二.无头单链表 图解 代码实现 特点 三.带头单链表 为何引入带头单链表 代码实现 注意 提示:以下是本篇文章正文内容,Java系列学习将会持续更新 一.链表 概念 链 ...
- Java数据结构-认识链表
文章目录 一.链表的概念及结构 1.链表的概念 2.链表的分类 二.单向不带头非循环链表 1.创建节点类型 2.头插法 3.尾插法 4.打印单链表 5.查找key是否在单链表中 6.得到单链表的长度 ...
- Java数据结构与算法——树(基本概念,很重要)
声明:码字不易,转载请注明出处,欢迎文章下方讨论交流. 有网友私信我,期待我的下一篇数据结构.非常荣幸文章被认可,也非常感谢你们的监督. 前言:Java数据结构与算法专题会不定时更新,欢迎各位读者监督 ...
- 数据结构练习题之树和图(附答案与解析)
树 (1)把一棵树转换为二叉树后,这棵二叉树的形态是( ). A.唯一的 B.有多种 C.有多种,但根结点都没有左孩子 D.有多种,但根结点 ...
- 【Java数据结构】链表
目录 1. 概况 2. 思路 3. 定义链表节点 4. 实现方法 5. 源代码 MyLinkedList.java test.java 1. 概况 链表在逻辑上是连续的,在物理上不一定连续. 分类: ...
- 堆(手写堆包含STL)
文章目录 前言 一.堆的定义 二.堆的分类及性质(STL的用法) 1.堆的分类 2.STL的用法 3.堆的性质 三.手写堆(重点) 1.手写堆的思想 2.函数模块 3.操作模块 四.完整代码 + 注 ...
- 十年java架构师分享:我是这样手写Spring的
人见人爱的 Spring 已然不仅仅只是一个框架了.如今,Spring 已然成为了一个生态.但深入了解 Spring 的却寥寥无几.这里,我带大家一起来看看,我是如何手写 Spring 的.我将结合对 ...
- c语言用单链表实现lru算法,手写单链表实现和LRU算法模拟
手写单链表,实现增删改查 package top.zcwfeng.java.arithmetic.lru; //单链表 public class LinkedList { Node list; int ...
- Java在线打开word文档实现手写批注
前言: 有些OA系统会有用户在线对word文档添加手写批注的需求,这样的需求看似不好实现,其实是可以实现的. 但是这需要开发者具备将activex控件集成到Java环境的能力.对于大部分Java开发工 ...
最新文章
- 【MATLAB】————matlab raw图转bmp实现
- 分享一篇关于使用阿里云消息队列中遇到的坑
- python 正则表达式 匹配指定字符遇到问题记录
- MyBatis自动生成代码之generatorConfig配置文件及其详细解读
- OpenCV检测子像素中的角点位置
- Android 开发工具类 02_DensityUtils
- python怎么定义全局字典_一种Python全局配置规范以及其魔改
- 截屏没有了_华为手机居然有6种截屏花招,很多人不知道,你会用哪几种?
- html怎么给变量添加样式,通过CSS变量修改样式
- system verilog编程题_拼多多2020校招部分算法编程题合集
- java及java web学习笔记
- SQL null的学问
- matlab中的插值函数
- ARM架构与X86架构
- 微信、qq可以上网,但是浏览器却不能上网怎么办
- 机器学习中的概率分布
- 2022年测试工程师面试题大合集「 功能测试,自动化测试等」300道题
- 计算机视觉(北邮鲁鹏)--边缘提取
- 极路由B70/极路由4增强版改spi,pb-boot启动后切换回nand刷nand breed
- linux终端常用指令