CVPR 2018:阿里提出新零样本学习方法,有效解决偏置问题
大多数现有的零样本学习(Zero-Shot Learning,ZSL)方法都存在强偏问题:训练阶段看不见(目标)类的实例在测试时往往被归类为所看到的(源)类之一。因此,在广义ZSL设置中部署后,它们的性能很差。在本文,我们提出了一个简单而有效的方法,称为准完全监督学习(QFSL),来缓解此问题。我们的方法遵循直推式学习的方式,假定标记的源图像和未标记的目标图像都可用于训练。在语义嵌入空间中,被标记的源图像被映射到由源类别指定的若干个嵌入点,并且未标记的目标图像被强制映射到由目标类别指定的其他点。在AwA2,CUB和SUN数据集上进行的实验表明,我们的方法在遵循广义ZSL设置的情况下比现有技术的方法优越9.3%至24.5%,在遵循传统ZSL设置下有0.2%至16.2%的提升。

归纳式和直推式零样本学习
在大规模的训练数据集的支撑下,计算机视觉中的物体识别算法在近几年取得了突破性的进展。但是人工收集和标注数据是一项十分耗费人力物力的工作。例如,在细粒度分类中,需要专家来区分不同的类别。对于如濒临灭绝的物种,要收集到丰富多样的数据就更加困难了。在给定有限或者没有训练图片的情况下,现在的视觉识别模型很难预测出正确的结果。
零样本学习是一类可以用于解决以上问题的可行方法。零样本学习区分2种不同来源的类,源类(source)和目标类(target),其中源类是有标注的图像数据,目标类是没有标注的图像数据。为了能够识别新的目标类(无标注),零样本学习假定源类和目标类共享同一个语义空间。图像和类名都可以嵌入到这个空间中。语义空间可以是属性(attribute)、词向量(word vector)等。在该假设下,识别来自目标类的图像可以通过在上述语义空间中进行最近邻搜索达成。
根据目标类的无标注数据是否可以在训练时使用,现有的ZSL可以分为2类:归纳式ZSL(inductive ZSL)和直推式ZSL(transductive ZSL)。对于归纳式ZSL,训练阶段只能获取得到源类数据。对于直推式ZSL,训练阶段可以获取到有标注的源类数据和未标注的目标类数据。直推式ZSL希望通过同时利用有标注的源类和无标注的目标类来完成ZSL任务。
在测试阶段,大多数现有的归纳式ZSL和直推式ZSL都假定测试图像都来源于目标类。因此,对测试图片分类的搜索空间被限制在目标类中。我们把这种实验设定叫作传统设定(conventional settings)。然而,在一个更加实际的应用场景中,测试图像不仅来源于目标类,还可能来自源类。这种情况下,来自源类和目标类的数据都应该被考虑到。我们把这种设定叫作广义设定(generalized settings)。
现有的ZSL方法在广义设定下的效果远差于传统设定。这种不良的表现的主要原因可以归纳如下:ZSL通过建立视觉嵌入和语义嵌入之间的联系来实现新的类别的识别。在衔接视觉嵌入和语义嵌入的过程中,大多数现有的ZSL方法存在着强偏 (strong bias)的问题(如图1所示):在训练阶段,视觉图片通常被投影到由源类确定的语义嵌入空间中的几个固定的点。这样就导致了在测试阶段中,在目标数据集中的新类图像倾向于被分到源类当中。
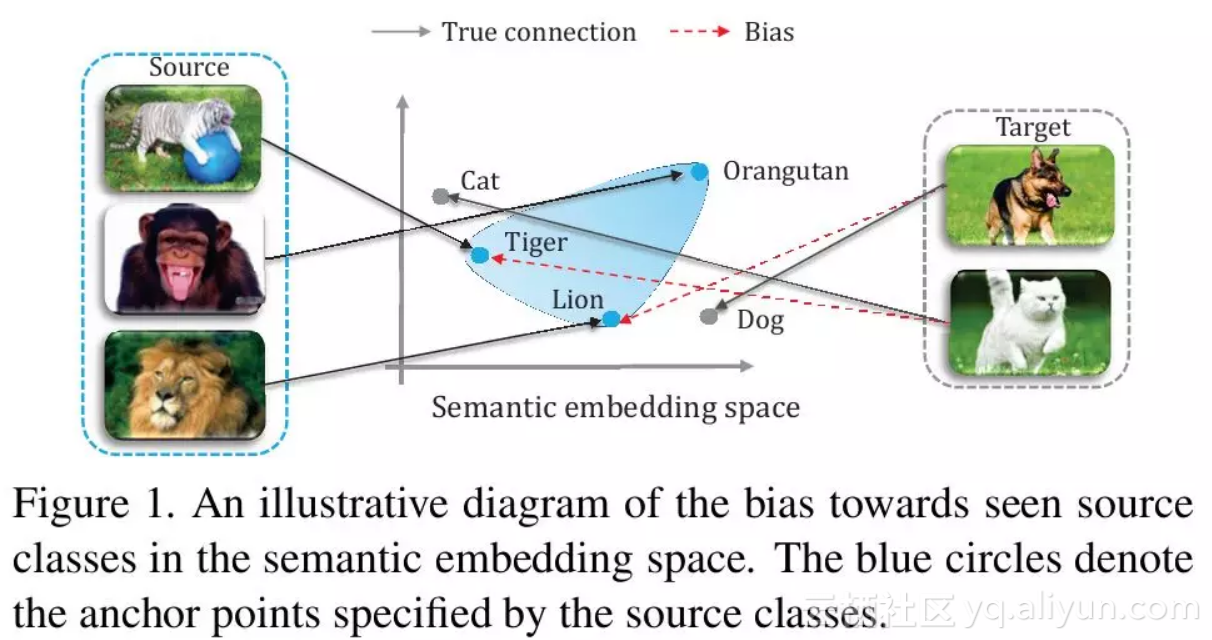
图1
为了解决以上问题,本文提出了一种新的直推式ZSL方法。我们假定有标注的源数据和目标数据都可以在训练阶段得到。一方面,有标注的源数据可以用于学习图像与语义嵌入之间的关系。另外一方面,没有标注的目标数据可以用于减少由于源类引起的偏置问题。更确切地来说,我们的方法允许输入图像映射到其他的嵌入点上,而不是像其他ZSL方法将输入图像映射到固定的由源类确定的几个点上。这样有效地缓解了偏置问题。
我们将这种方法称为准全监督学习(Quasi-Fully Supervised Learning, QFSL)。这种方法和传统的全监督分类工作方式相似,由多层神经网络和一个分类器组成,如图2所示。神经网络模型架构采用现有的主流架构,比如AlexNet、GoogleNet或者其他框架。在训练阶段,我们的模型使用有标注的源类数据和没有标注的目标数据进行端到端的训练。这使得我们的模型有一两个个明显的特性:(1)如果未来可以得到目标类的标注数据,那么标注数据可以直接用于进一步训练和改进现有的网络模型;(2)在测试阶段,我们得到的训练模型可以直接用于识别来自于源类和目标类的图像,而不需要进行任何修改。
本论文的主要贡献总结如下:
 提出了准全监督学习的方法来解决零样本学习中的强偏问题。据我们所知,这是第一个采用直推式学习方法来解决广义设定下零样本学习问题。
提出了准全监督学习的方法来解决零样本学习中的强偏问题。据我们所知,这是第一个采用直推式学习方法来解决广义设定下零样本学习问题。
实验结果表明我们的方法在广义设定下和传统设定下都远超现有的零样本学习方法。
问题的形式化

QFSL模型
不同于以上描述的双线性形式,我们将得分函数F设计成非线性形式。整个模型由深度神经网络实现。模型包括4个模块:视觉嵌入子网络,视觉-语义衔接子网络,得分子网络和分类器。视觉嵌入子网络将原始图像映射到视觉嵌入空间。视觉-语义衔接子网络将视觉嵌入映射到语义嵌入子网络。得分子网络在语义空间中产生每一类的得分。分类器根据得分输出最终的预测结果。所有的模块都是可微分的,包括卷积层,全连接层,ReLU层和softmax层。因此,我们的模型可以进行端到端的训练。
视觉嵌入子网络
现有的大多数模型采用了CNN提取得到的特征作为视觉嵌入。在这些方法中,视觉嵌入函数θ是固定的。这些方法并没有充分利用深度CNN的强大的学习能力。本文采用了预训练的CNN模型来进行视觉嵌入。我们的视觉嵌入模型的主要不同之处在于可以和其他模块一起进行优化。视觉嵌入模块的参数。除非特别说明,我们把第一个全连接层的输出作为视觉嵌入。
视觉-语义衔接子网络
衔接图像和语义嵌入之间的关系对ZSL来说很重要。这种关系可以通过线性函数或者非线性函数来建模。本文采用了非线性函数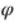 将视觉嵌入映射到语义嵌入。
将视觉嵌入映射到语义嵌入。
由若干个全连接层来实现,其中每一个全连接层后面跟了一个非线性激活函数:ReLU。衔接函数的设计依赖于上述的视觉嵌入子网络的架构。具体来说,我们的设计是按照所选择CNN模型的全连接层来设计的。视觉-语义衔接子网络和视觉嵌入网络一起进行优化。视觉-语义衔接子网络参数记作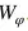 。
。
得分子网络

分类器
经过得分函数后,我们使用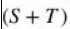 的softmax分类器产生了所有类的概率。输入图像的预测结果为概率最高的那个类。
的softmax分类器产生了所有类的概率。输入图像的预测结果为概率最高的那个类。
模型优化

实验
数据集
我们在三个数据集上评估了我们的方法。这三个数据集分别为AwA2, CUB, SUN。在实验中,我们采用属性作为语义空间,用类平均准确度衡量模型效果。
在传统设置下的效果比较
首先我们在传统设置下对我们方法和现有方法。用来做对比的现有方法分为两类:一类是是归纳式方法,包括DAP,CONSE,SSE,ALE,DEVISE,SJE,ESZSL,SYNC;另一类是直推式方法,包含UDA,TMV,SMS。与此同时,还比较了一个潜在的baseline(标记为QFSL-):只用有标注的源数据来训练我们的模型。实验效果如表1。可以看出,我们的方法大幅度(4.5~16.2%)提升了分类准确度。
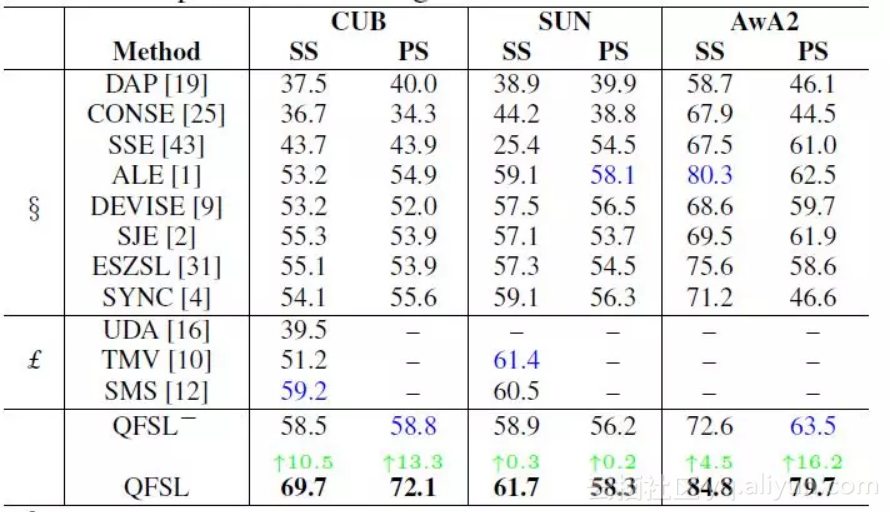
表1. 在传统设置下的实验比较
在广义设置下的效果比较
大多数现有直推式方法在测试阶段都采用了同训练阶段同样的数据来评估性能。然而,如果我们的方法也采用这种方式来评估效果是很不合理的。因为我们的方法已经利用到了无标签的数据来源于目标类这一监督信息。为了解决这一问题,我们将目标数据平分为两份,一份用来训练,另一份用来测试。然后交换这两份数据的角色,再重新训练一个模型。最终的效果为这两个模型的平均。我们比较了我们的方法和若干现有方法,以及一个隐含的baseline:先训练一个二分类器来区分源数据和目标数据,然后再在各自搜索空间中分类。实验结果如表2。
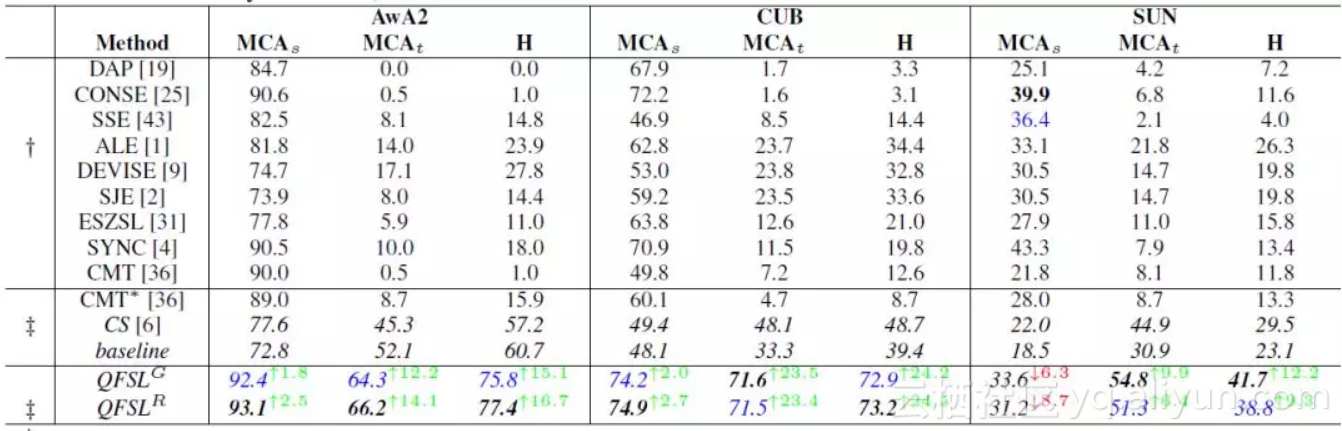
表2
可以看出,我们模型的整体性能(调和平均数H)有着9.3~24.5的明显提高。该项指标的提高主要得益于在目标数据上的效果提升,同时又没有在源数据上大幅度降低准确度。该结果表明,我们的方法能够很大程度上缓解强偏问题。
讨论
现实世界中,目标类的数量可能远远高于源类数量。然而,大多数现有ZSL数据集的源、目标数据划分都违背了这一点。比如,在AwA2中,40个类用来做训练,10个类用来做测试。我们在实验上给出了随着源数据类别的增加,QFSL在效果上如何变化。该实验在SUN数据集上进行,72类作为目标类,随机选取剩下的类作为源类。我们尝试了7个大小不同的源类集,类的数量分别为{100,200,300,450,550,600,645}。用这些不同大小的源类作为训练集,测试我们的方法,效果如图3。由图可以看出,随着类别增加,模型能够学习到更多的知识,其在目标数据集上准确度越来越高。同时,由于源数据和目标数据变得越来越不平衡,强偏问题越来越严重。我们方法能够缓解强偏问题,因而其在效果上的优越性也越来越明显。
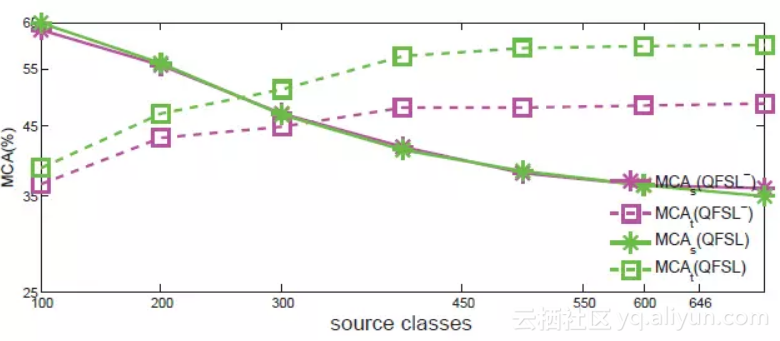
图3. 准全监督在SUN数据集上效果
结论
本文提出了一种用于学习ZSL无偏嵌入的直接但有效的方法。这种方法假设标注的源数据和未标注的目标数据在模型训练的过程中可以使用。一方面,将标注的源数据映射到语义空间中源类对应的点上。另外一方面,将没有标注的目标数据映射到语义空间中目标类对应的点上,从而有效地解决了模型预测结果向源类偏置的问题。在各种基准数据集上的实验表明我们的方法在传统设定和广义设定下,大幅超过了现有的ZSL方法。
原文发布时间为:2018-05-25
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”。
原文链接:CVPR 2018:阿里提出新零样本学习方法,有效解决偏置问题
CVPR 2018:阿里提出新零样本学习方法,有效解决偏置问题相关推荐
- IJCAI 2022 | 用一行代码大幅提升零样本学习方法效果!南京理工牛津提出即插即用分类器模块...
点击下方卡片,关注"CVer"公众号 AI/CV重磅干货,第一时间送达 点击进入-> CV 微信技术交流群 转载自:机器之心 | 作者:陈督兵 来自南京理工大学和牛津大学 ...
- AAAI 2020 | 自动化所:基于对抗视觉特征残差的零样本学习方法
2020-01-16 05:41:55 作者 | 刘博.董秋雷.胡占义编辑 | Camel 本文对中科院自动化所胡占义团队完成,被AAAI-20录用的论文<Zero-Shot Learning ...
- Neural Motifs: Scene Graph Parsing with Global Context (CVPR 2018) 运行复现遇到的一些坑以及解决方法
写在前面 首先,感谢这篇文章 https://blog.csdn.net/weixin_38651565/article/details/87901172 的作者 @jiayan97 和他有很多交流帮 ...
- 达摩院文档级关系抽取新SOTA和零样本关系抽取新任务
©作者 | 邴立东.谭清宇.谢耀赓 单位 | Alibaba DAMO, NUS, SUTD 引言 关系抽取(RE)是 NLP 的核心任务之一,是构建知识库.事件抽取等下游应用的关键技术.多年来受到研 ...
- 近期必读的6篇NeurIPS 2019零样本学习论文
来源 | 专知(ID:Quan_Zhuanzhi) [导读]NeurIPS 是全球最受瞩目的AI.机器学习顶级学术会议之一,每年全球的人工智能爱好者和科学家都会在这里聚集,发布最新研究.NIPS 20 ...
- CVPR 2018 论文解读集锦(9月26日更新)
本文为极市平台原创收集,转载请附原文链接: https://blog.csdn.net/Extremevision/article/details/82757920 CVPR 2018已经顺利闭幕,目 ...
- CVPR 2018 论文解读集锦
之前我们整理过视觉顶级会议CVPR2017的论文解读文章 和ICCV 2017 论文解读集锦,CVPR 2018已经公布了所有收录论文名单,为了能够让大家更深刻了解CVPR的论文,我们进行了一些CVP ...
- 开源开放 | 一个用于知识驱动的零样本学习研究的开源数据集KZSL(CCKS2021)
OpenKG地址:http://openkg.cn/dataset/k-zsl GitHub地址:https://github.com/China-UK-ZSL/Resources_for_KZSL ...
- 近期必读的6篇 NeurIPS 2019 的零样本学习(Zero-Shot Learning)论文
近期必读的6篇 NeurIPS 2019 的零样本学习(Zero-Shot Learning)论文 PS:转发自"专知"公众号 [导读]NeurIPS 是全球最受瞩目的AI.机器学 ...
- 论文研读-机器学习可视化-面向可视解释的零样本分类主动学习
面向可视解释的零样本分类主动学习 1 文章概要 1.1 摘要 1.2 引言 1.2.1 零样本分类 1.1.2 解决方案 1.2.3 文章贡献 1.3 组织结构 2 相关工作 3 用于零样本学习的人机 ...
最新文章
- 假如我是面试官,我会这样虐你
- 【Java】6.7 内部类
- ORACLE 调试输出,字符串执行函数
- 64位ubuntu kylin 16.04下tiny4412开发环境搭建
- Codeforces 835 F Roads in the Kingdom(树形dp)
- 从Android到React Native开发(三、自定义原生控件支持)
- 海康威视+虹软人脸识别
- 戴尔为啥找不到修复计算机,重装系统后戴尔电脑找不到引导设备怎么办
- 【阅读笔记】(语义分割最全总结,综述)《A Review on Deep Learning Techniques Applied to Semantic Segmentation》
- C++银行账户管理程序2
- Xilinx SDSoc 加载opencv库
- 【数理逻辑开篇】朴实的逻辑学与数学危机
- 删除文件名含有特殊字符的文件
- 【NLP入门教程】五、命名实体识别
- DataList绑定照片并分页
- C语言中.c文件与.h文件 的使用-2020-12-27
- R包bs4Dash控件效果对照图
- gvim 6.3 的确不错.
- 微信小程序 python 自动化测试_微信小程序的自动化测试框架
- 十进制转二进制(C++)