python3 scrapy 教程_Scrapy 入门教程
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
Scrapy架构图(绿线是数据流向)
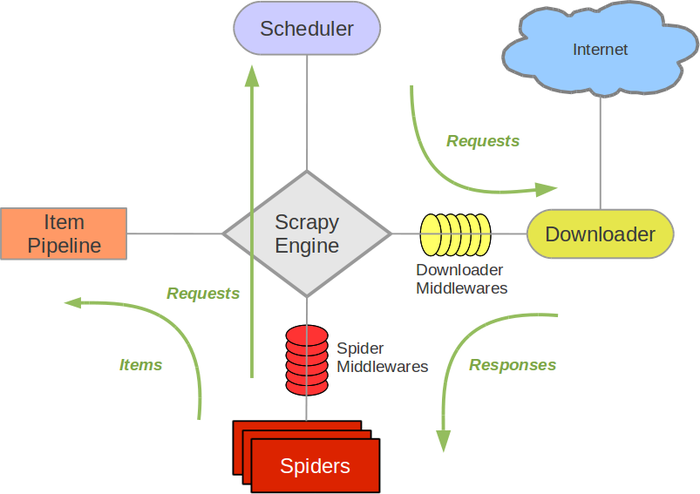
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
1 引擎:Hi!Spider, 你要处理哪一个网站?
2 Spider:老大要我处理xxxx.com。
3 引擎:你把第一个需要处理的URL给我吧。
4 Spider:给你,第一个URL是xxxxxxx.com。
5 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6 调度器:好的,正在处理你等一下。
7 引擎:Hi!调度器,把你处理好的request请求给我。
8 调度器:给你,这是我处理好的request
9 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
10 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12 Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13 引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14 管道调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
安装
Windows 安装方式
升级 pip 版本:
pip install --upgrade pip
通过 pip 安装 Scrapy 框架:
pip install Scrapy
Ubuntu 安装方式
安装非 Python 的依赖:
sudo apt-getinstall python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
通过 pip 安装 Scrapy 框架:
sudo pip install scrapy
Mac OS 安装方式
对于Mac OS系统来说,由于系统本身会引用自带的python2.x的库,因此默认安装的包是不能被删除的,但是你用python2.x来安装Scrapy会报错,用python3.x来安装也是报错,我最终没有找到直接安装Scrapy的方法,所以我用另一种安装方式来说一下安装步骤,解决的方式是就是使用virtualenv来安装。
$ sudo pip install virtualenv
$ virtualenv scrapyenv
$ cd scrapyenv
$ source bin/activate
$ pip install Scrapy
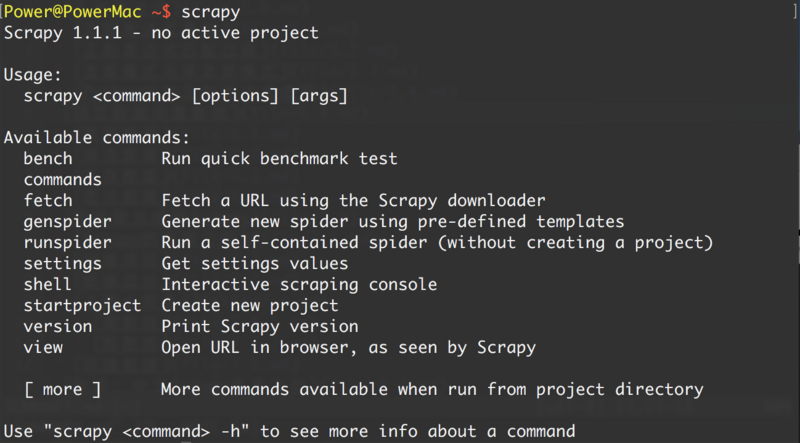
安装后,只要在命令终端输入 scrapy,提示类似以下结果,代表已经安装成功。
入门案例
学习目标
创建一个Scrapy项目
定义提取的结构化数据(Item)
编写爬取网站的 Spider 并提取出结构化数据(Item)
编写 Item Pipelines 来存储提取到的Item(即结构化数据)
一. 新建项目(scrapy startproject)
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider
其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
下面来简单介绍一下各个主要文件的作用:
mySpider/scrapy.cfg
mySpider/__init__.py
items.py
pipelines.py
settings.py
spiders/__init__.py
...
这些文件分别是:
scrapy.cfg: 项目的配置文件。
mySpider/: 项目的Python模块,将会从这里引用代码。
mySpider/items.py: 项目的目标文件。
mySpider/pipelines.py: 项目的管道文件。
mySpider/settings.py: 项目的设置文件。
mySpider/spiders/: 存储爬虫代码目录。
二、明确目标(mySpider/items.py)
我们打算抓取 http://www.itcast.cn/channel/teacher.shtml 网站里的所有讲师的姓名、职称和个人信息。
打开 mySpider 目录下的 items.py。
Item 定义结构化数据字段,用来保存爬取到的数据,有点像 Python 中的 dict,但是提供了一些额外的保护减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个 Item(可以理解成类似于 ORM 的映射关系)。
接下来,创建一个 ItcastItem 类,和构建 item 模型(model)。
importscrapy
classItcastItem(scrapy.Item):name =scrapy.Field()title =scrapy.Field()info =scrapy.Field()
三、制作爬虫 (spiders/itcastSpider.py)
爬虫功能要分两步:
1. 爬数据
在当前目录下输入命令,将在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider itcast "itcast.cn"
打开 mySpider/spider目录里的 itcast.py,默认增加了下列代码:
importscrapy
classItcastSpider(scrapy.Spider):name ="itcast"allowed_domains =["itcast.cn"]start_urls =('http://www.itcast.cn/',)defparse(self,response):pass
其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "" :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
生成需要下一页的URL请求。
将start_urls的值修改为需要爬取的第一个url
start_urls =("http://www.itcast.cn/channel/teacher.shtml",)
修改parse()方法
defparse(self,response):filename ="teacher.html"open(filename,'w').write(response.body)
然后运行一下看看,在mySpider目录下执行:
scrapy crawl itcast
是的,就是 itcast,看上面代码,它是 ItcastSpider 类的 name 属性,也就是使用 scrapy genspider命令的唯一爬虫名。
运行之后,如果打印的日志出现 [scrapy] INFO: Spider closed (finished),代表执行完成。 之后当前文件夹中就出现了一个 teacher.html 文件,里面就是我们刚刚要爬取的网页的全部源代码信息。
注意:Python2.x默认编码环境是ASCII,当和取回的数据编码格式不一致时,可能会造成乱码;我们可以指定保存内容的编码格式,一般情况下,我们可以在代码最上方添加
importsys
reload(sys)sys.setdefaultencoding("utf-8")
这三行代码是 Python2.x 里解决中文编码的万能钥匙,经过这么多年的吐槽后 Python3 学乖了,默认编码是Unicode了...(祝大家早日拥抱Python3)
2. 取数据
爬取整个网页完毕,接下来的就是的取过程了,首先观察页面源码:
xxx
xxxxx
xxxxxxxx
是不是一目了然?直接上 XPath 开始提取数据吧。
xpath 方法,我们只需要输入的 xpath 规则就可以定位到相应 html 标签节点,详细内容可以查看 xpath 教程。
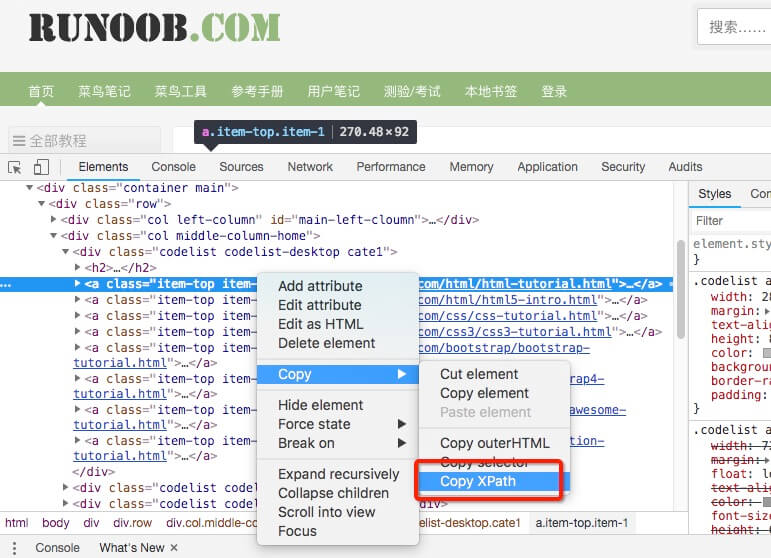
不会 xpath 语法没关系,Chrome 给我们提供了一键获取 xpath 地址的方法(右键->检查->copy->copy xpath),如下图:
这里给出一些 XPath 表达式的例子及对应的含义:
/html/head/title: 选择HTML文档中
标签内的 元素
/html/head/title/text(): 选择上面提到的
元素的文字
//td: 选择所有的
元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素
举例我们读取网站 http://www.itcast.cn/ 的网站标题,修改 itcast.py 文件代码如下::
# -*- coding: utf-8 -*-importscrapy
# 以下三行是在 Python2.x版本中解决乱码问题,Python3.x 版本的可以去掉importsys
reload(sys)sys.setdefaultencoding("utf-8")classOpp2Spider(scrapy.Spider):name ='itcast'allowed_domains =['itcast.com']start_urls =['http://www.itcast.cn/']defparse(self,response):# 获取网站标题context =response.xpath('/html/head/title/text()')# 提取网站标题title =context.extract_first()print(title)pass
执行以下命令:
$ scrapy crawl itcast
......传智播客官网-好口碑IT培训机构,一样的教育,不一样的品质......
我们之前在 mySpider/items.py 里定义了一个 ItcastItem 类。 这里引入进来:
frommySpider.items importItcastItem
然后将我们得到的数据封装到一个 ItcastItem 对象中,可以保存每个老师的属性:
frommySpider.items importItcastItemdefparse(self,response):#open("teacher.html","wb").write(response.body).close()# 存放老师信息的集合items =[]foreach inresponse.xpath("//div[@class='li_txt']"):# 将我们得到的数据封装到一个 `ItcastItem` 对象item =ItcastItem()#extract()方法返回的都是unicode字符串name =each.xpath("h3/text()").extract()title =each.xpath("h4/text()").extract()info =each.xpath("p/text()").extract()#xpath返回的是包含一个元素的列表item['name']=name[0]item['title']=title[0]item['info']=info[0]items.append(item)# 直接返回最后数据returnitems
我们暂时先不处理管道,后面会详细介绍。
保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,命令如下:
scrapy crawl itcast -o teachers.json
json lines格式,默认为Unicode编码
scrapy crawl itcast -o teachers.jsonl
csv 逗号表达式,可用Excel打开
scrapy crawl itcast -o teachers.csv
xml格式
scrapy crawl itcast -o teachers.xml
思考
如果将代码改成下面形式,结果完全一样。
请思考 yield 在这里的作用(Python yield 使用浅析):
# -*- coding: utf-8 -*-importscrapy
frommySpider.items importItcastItem# 以下三行是在 Python2.x版本中解决乱码问题,Python3.x 版本的可以去掉importsys
reload(sys)sys.setdefaultencoding("utf-8")classOpp2Spider(scrapy.Spider):name ='itcast'allowed_domains =['itcast.com']start_urls =("http://www.itcast.cn/channel/teacher.shtml",)defparse(self,response):#open("teacher.html","wb").write(response.body).close()# 存放老师信息的集合items =[]foreach inresponse.xpath("//div[@class='li_txt']"):# 将我们得到的数据封装到一个 `ItcastItem` 对象item =ItcastItem()#extract()方法返回的都是unicode字符串name =each.xpath("h3/text()").extract()title =each.xpath("h4/text()").extract()info =each.xpath("p/text()").extract()#xpath返回的是包含一个元素的列表item['name']=name[0]item['title']=title[0]item['info']=info[0]items.append(item)# 直接返回最后数据returnitems
python3 scrapy 教程_Scrapy 入门教程相关推荐
- TensorFlow 中文资源精选,官方网站,安装教程,入门教程,实战项目,学习路径。
转载至:http://www.nanjixiong.com/thread-122211-1-1.html Awesome-TensorFlow-Chinese TensorFlow 中文资源全集,学习 ...
- extjs form java_[Java教程]ExtJS入门教程02,form也可以很优雅
[Java教程]ExtJS入门教程02,form也可以很优雅 0 2014-03-28 12:00:40 在上一篇<Extjs window 入门>中,我们已经看到了如何将一个form组件 ...
- Python3数据分析——NumPy快速入门教程(官网教程翻译)
目录 一.基础篇 1.创建数组 2.打印数组 3.基本运算 4.通用函数(ufunc) 5.索引,切片和迭代 二.形状操作 1.更改数组的形状 2.组合(stack)不同的数组 3.将一个数组分割(s ...
- python入门语言教程_Python入门教程(1)
人生苦短,我用Python! Python(英语发音:/ˈpaɪθən/), 是一种面向对象.解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于19 ...
- django mysql 教程_Django 入门教程
简介:本课程使用的开发环境为 Python 3.x .Django 1.8.13.课程中将对 Django 的环境搭建.视图.链接路由.模板.模型.数据库操作以及表单进行简单介绍,并结合简单实验示例加 ...
- python tensorflow教程_TensorFlow入门教程TensorFlow 基本使用T
该楼层疑似违规已被系统折叠 隐藏此楼查看此楼 TensorFlow入门教程 TensorFlow 基本使用 TensorFlow官方中文教程 TensorFlow 的特点: 使用图 (graph) 来 ...
- python第一次使用教程-python入门教程第一日
python 官方下载地址:https://www.python.org/downloads/ 根据系统的不同安装包也不同,但是开发的程序兼容各个操作系统,这点是python能吃得开的原因之一. py ...
- linux terminal教程,Linux入门教程 - 如何记录和重放Linux终端会话
原标题:Linux入门教程 - 如何记录和重放Linux终端会话 来自:https://www.linuxmi.com/replay-linux.html 使用命令,我们可以在type文件中记录终端会 ...
- 计算机linux入门教程,Turbolinux入门教程1
原标题:Turbolinux入门教程1 第一课:什么是Linux 简单地说, Linux 是一套免费使用和自由传播的类 Unix 操作系统,它主要用于基于 Intel x86 系列 CPU 的计算机上 ...
最新文章
- 东财计算机应用基础在线作业答案,《计算机应用基础》东财在线20秋第一套作业答案...
- 运维自动化之基于python语言的文字界面的运维管理软件
- python编写命令行框架_python的pytest框架之命令行参数详解(上)
- debugging Auto Layout:Logical Errors
- mysql将表的某一列全部置空NULL。
- 教你如何申请CCNP的电子证书
- OpenCV-图像阴影调整
- php mysql存储中文为空_PHP如何解决MySQL存储数据中文乱码
- unity 编辑器 混合使用固定布局和自动布局(二)
- Android 11 功能和 API 概览
- 《测绘综合能力》——工程测量
- 网友RHCE认证考试经历
- MATLAB显示slic,quickshift超像素分割结果图
- 哈工大软件构造期末复习(根据老师复习提纲整理)
- 【目标检测 论文精读】……YOLO-V2 YOLO9000 ……(YOLO9000: Better, Faster, Stronger)
- 微信小程序 识别身份证,银行卡
- 关于项目连接docker数据库报错不存在表的问题
- np.empty()函数、np.random.uniform()函数、np.random.normal()函数的详细介绍和代码说明
- dns服务器连接未响应,dns服务器未响应解决方法
- 焦作护理学校计算机应用专业,焦作护理学校
热门文章
- 配置类不加@Configuration竟然也可以注册bean
- 点到超平面距离的证明
- C语言: 定义一个函数int isprime(int n),用来判别一个正整数n是否为素数,若为素数函数返回值为1,否则为0。在主函数中输入一个整数x,调用函数isprime(x)来判断这个整数x是
- JVM - 双亲委派
- 一篇文章带你认识芯片分类及代表企业
- 基站信号强度和位置变化详解(可获得其他系统信息)
- 多元函数的极限,连续,偏导数,全微分之间的关系(学习笔记)
- windows10家庭版下找不到gpedit.msc
- NopCommerce 关于Customer的会员类别及会员价处理 的尝试途径
- 快来看啊,2023成都Java培训机构排行榜出来啦!