Beating the state-of-the-art in NLP with HMTL
HMTL: 一个层级的多任务学习模型,利用同一个模型架构同时在不同的训练集上训练多种不同的任务。不同任务的难度不同,低难度的放在网络下层,直观的理解就是少量的参数及网络结构就可以搞定,复杂度高的任务放在网络结构上层,低层任务块的输出可以作为高层任务块的输入。同时作者认为,直连边对结果的性能提升起到很大作用,这应该是来自于 ResNet 家族的灵感,侧面反映 Embedding 层对结果的影响。针对 Embedding 层,作者组合了基于 GloVe 的常规词向量以及 ELMo 训练的词向量以及基于 CNN 训练的基于字符级的向量,在论文中,作者实验证明 ELMo 的贡献较大,且基于字符级的向量涉及到单词的前缀、后缀以及实体名字大写等特征,对于低层任务的影响较大。另外作者提出的基于概率采样以及多任务间的训练切换方案也是一个比较重要的贡献。多任务训练的一个难点在于灾难性的遗忘,简单的说就是当用 A 任务训练完一个 Epoch,当切换到 B 任务上,训练集不同,任务不同,刚学到的 A 的内容很容易被覆写掉。目前而言,多任务训练到底应该怎么训练比较有效,还是一个没有定论的研究领域,且多任务的设计架构以及什么样的任务选择上面还是有一定的技巧。从实验的结果来看,该模型的性能还不错,能被 AAAI 收录还是值得一读!下面是该作者在 Medium 上的一篇介绍博客,这个网站需要翻墙,我给 copy 过来了。可以先读读这边作者的博客,再看论文。
? Beating the state-of-the-art in NLP with HMTL
 Victor Sanh Nov 20, 2018
Victor Sanh Nov 20, 2018
<blink>You read it right, HMTL: a Hierarchical Multi-Task Learning model.</blink>
There is a rising tide ? in NLP in particular but also everywhere in Deep-Learning and Artificial Intelligence which is called Multi-Task Learning!
I’ve been experimenting with Multi-Task Learning for almost a year now and the result is HMTL, a model that beats the state-of-the-art on several NLP tasks and which will be presented in the very selective AAAI conference. We’ve released the paper ? and the training code ⌨️ so be sure to check them out.
Now, what is Multi-Task Learning?
> Multi-Task Learning is a general method in which a single architecture is trained towards learning several different tasks at the same time.
Here is an example: we’ve built a pretty nice online demo that runs HMTL interactively so let’s try for yourself ! ?
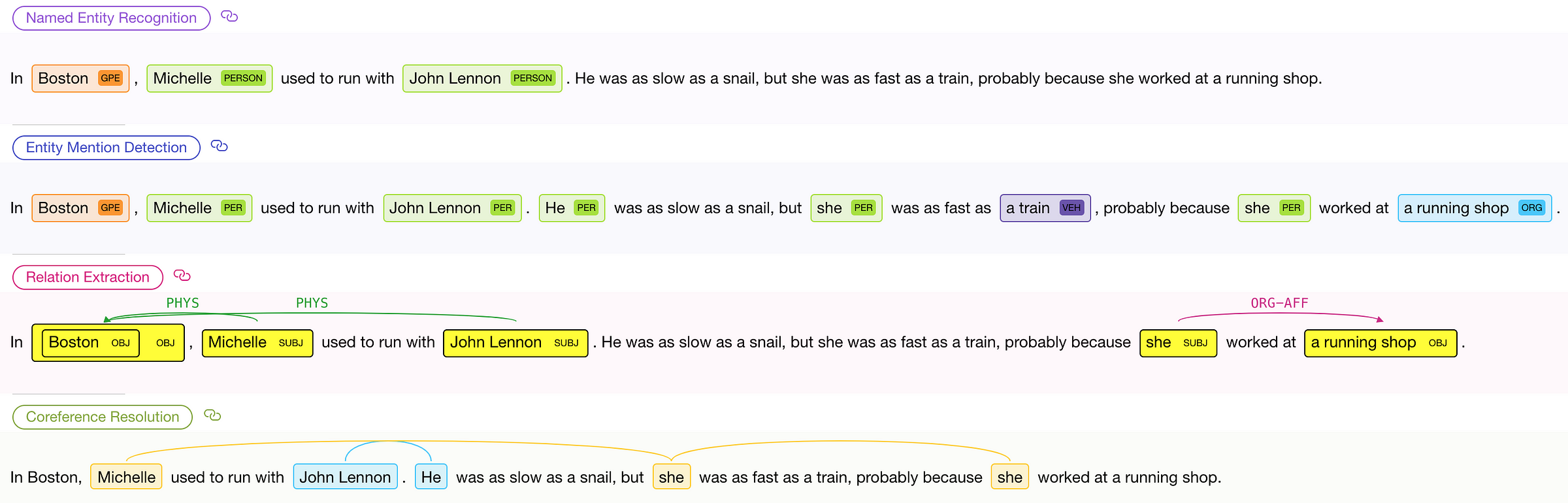
Example of results given by the online demo of HMTL
Traditionally, a specific model was independently trained for each of these NLP tasks (Named-Entity Recognition, Entity Mention Detection, Relation Extraction, Coreference Resolution).
In the case of HMTL, all these results are given by a single model, in a single forward pass!
But Multi-Task Learning is more than just a way to reduce the computation by using a single model instead of several models.
Multi-Task Learning (MTL) can be used to encourage the model to learn embeddings that can be shared between different tasks. One fundamental motivation behind Multi-Task Learning is that related (or loosely related) tasks can benefit from each other by inducing richer representations.
In this post, I will try to give you a sense of how powerful and versatile multi-task learning can be for NLP applications. First, I will share some intuition on why multi-task learning is an exciting trend with pointers to relevant references if you want to go deeper ?, then we will see how we can quickly build a Multi-Task trainer in Python ? ️and I will gather a few lessons we learned ???? while conducting this research project that led to state-of-the-art performances.
A brief introduction to cool ? stuff in Multi-Task Learning and why it matters.
In a classical Machine Learning setup, we train a single model by optimizing a single loss function to perform a single specified task. While focusing the training on a (single) task of interest is still the common approach for a lot of problems in Machine Learning, it does not leverage the information that other related (or loosely related) tasks can bring to further improve the performance.

Ok, this image has little to do with this post, but who doesn’t like dogs ? — Source: Cheezburger.com
As an analogy, Usain Bolt —probably one of the greatest sprinter of all time??, nine-time Olympic gold medalist ? and still title-holder of several world records ?(November 2018)— used to have a very intense and broad training, and spend a significant part of his training not actually running, but training for other exercises. For instance, he lifts weights, box jumps, bounds, etc. These exercises are not directly related to running but develop his muscular strength and explosiveness to be better at the ultimate goal: sprint.
> “Multi-task Learning is an approach to inductive transfer that improves generalization by using the domain information contained in the training signals of related tasks as an inductive bias. It does this by learning tasks in parallel while using a shared representation; what is learned for each task can help other tasks be learned better.” R. Caruana [1]
In Natural Language Processing, MTL was first leveraged in neural-based approaches by R. Collobert and J. Weston [2]. The model they proposed is an MTL instance in which several different tasks (with task-specific layers) rely on the same shared embeddings which are trained by the supervision of the different tasks.
Sharing the same representation among different tasks can sounds like a really low-level signal/way to transfer relevant knowledge from one task to another, but it has proven itself to be really useful in particular for its capacity to improve the generalization ability of a model.
While it is common and straight-forward to fix in advance how the information will be transferred across tasks, we can also let the model decide by itself what parameters and layers it should share, along with the layers that are best suited for a given task as showed in Ruder et al., 2017 [3].
More recently, these ideas of a shared representation have re-emerged under the spotlights notably through the quest for “Universal Sentence Embeddings” which could be used across domains and are not task specific (c.f. Conneau et al. [4]). Several attempts rely on MTL: for instance, Subramanian et al. [5] observe that to be able to generalize over a wide range of diverse tasks, it is necessary to encode multiple linguistic aspects of the sentence. They proposed Gensen*,* an MTL architecture with a shared encoder representation followed by several task-specific layers. The 6 tasks used in this work are weakly related and range from Natural Language Inference, toMachine Translation through Constituency Parsing.
To dive deeper in the current state-of-the-art in sentence embeddings, you can refer to our detailed blog post on Universal Word and Sentence Embeddings?
In short, Multi-Task Learning is getting a lot of traction and is becoming a must known for a broad variety of problems in NLP ?, but obviously also in Computer Vision ?. Benchmarks such as the GLUE benchmark (General Language Understanding Evaluation, Wang et al. [6]) have been introduced recently to evaluate the generalization ability of MTL architectures and more generally Language Understanding models.
For a more comprehensive overview of MTL in NLP, you can refer to this blogpostof S. Ruder. ?
Multi-Task Learning in Python ?
? Now let’s try some code to see how MTL looks in practice.
A very important piece of a multi-task learning scheme is the Trainer: how should we train the network? In which order should we tackle the various tasks? Should we switch task periodically? Should all the tasks be trained for same number of epochs? There is no clear consensus today on all the questions, and many different training procedures have been proposed in the literature ?? so let’s be pragmatic!
First, let’s start with a simple and general piece of code that will be agnostic to the training procedure we pick ?:
- Select a task (whatever your selection algorithm is).
- Select a batch in the dataset for the chosen task (randomly sampling a batch is usually a safe choice).
- Perform a forward pass.
- Propagate the loss (backward pass) through the network.
These 4 steps should suit most of the use cases ?.
During the forward pass, the model computes the loss of the task of interest. During the backward pass, the gradients computed from the loss are propagated through the network to optimize both the task-specific layers and the shared embeddings (and all other relevant trainable parameters).
At Hugging Face, we love ? the AllenNLP library that is being developed by the Allen Institute for AI. It’s a powerful and versatile tool for conducting research in NLP that combine the flexibility of PyTorch with smart modules for data loading and processing that were carefully designed for NLP.
If you haven’t checked it out yet, I highly recommend that you do. The team made an amazing work with the on-boarding tutorials, so you have no excuses ! ?
I will now show a simple piece of code for creating a MTL trainer based on AllenNLP.
Let’s first introduce a class Task which will contain task-specific datasets and all the attributes directly related to the tasks.
from allennlp.data.iterators import DataIteratorclass Task():"""A class to encapsulate the necessary informations (and datasets)about each task.Parameters----------name : ``str``, requiredThe name of the task.validation_metric_name : ``str``, requiredThe name of the validation metric to use to monitor trainingto select the best epoch and to stop the training based on exit condition.validation_metric_decreases : ``bool``, requiredWhether or not the validation metric should decrease for improvement.evaluate_on_test : ``bool`, optional (default = False)Whether or not the task should be evaluated on the test set at the end of the training."""def __init__(self,name: str,validation_metric_name: str,validation_metric_decreases: bool,evaluate_on_test: bool = False) -> None:self._name = nameself._train_data = Noneself._validation_data = Noneself._test_data = Noneself._evaluate_on_test = evaluate_on_testself._val_metric = validation_metric_nameself._val_metric_decreases = validation_metric_decreasesself._data_iterator = Nonedef load_data(self,dataset_path: str,dataset_type: str):"""Load a dataset from a file and store it.Parameters----------dataset_path: ``str``, requiredThe path to the dataset.dataset_type: ``str``, requiredThe type of the dataset (train, validation, test)"""assert dataset_type in ["train", "validation", "test"]dataset = read(dataset_path) # Replace with whatever loading you want.setattr(self, "_%s_data" % dataset_type, dataset)def set_data_iterator(self,data_iterator: DataIterator):self._data_iterator = data_iterator
# task.py hosted with ❤ by GitHub
Now that we have our class Task , we can define our Model.
Creating a model in AllenNLP is pretty easy. Just make your class inherit from the allennlp.models.model.Model class. Lots of useful methods will be automatically supplied such as get_regularization_penalty() which applies penalties (e.g. L1 or L2 regularizations) during the training phase.
Let’s talk about the two main methods that we need: forward() and get_metrics(). These methods respectively compute the forward pass (up to the loss computation) and the training/evaluation metrics for the current task during the training.
Our important element for Multi_task Learning is to add a specific argument task_name which will be used to specify the current task of interest during training. Let’s have a look:
import torchfrom allennlp.models.model import Modelclass MyMTLModel(Model):def __init__(self):"""Whatever you need to initialize your MTL model/architecture."""def forward(self,task_name: str,tensor_batch: torch.Tensor):"""Defines the forward pass of the model. This function is designedto compute a loss function defined by the user.It should return Parameters----------task_name: ``str``, requiredThe name of the task for which to compute the forward pass.tensor_batch: ``torch.Tensor``, requiredAn embedding representation of the input to pass through the model.Returns-------output_dict: ``Dict[str, torch.Tensor]``An output dictionary containing at least the computed loss for the task of interest."""raise NotImplementedErrordef get_metrics(self, task_name: str):"""Compute and update the metrics for the current task of interest.Parameters----------task_name: ``str``, requiredThe name of the current task of interest.Returns-------A dictionary of metrics."""raise NotImplementedError
# model.py hosted with ❤ by GitHub
Now we said that a crucial point in MTL is choosing the training task order. The most straight-forward way to select a task it to sample uniformly ? a task after each parameter update (forward + backward passes). This algorithm was used in a several prior works like Gensen that we mentioned earlier.
But we can be a little bit smarter: we choose a task randomly following a probably distribution in which each probability of choosing a task is proportional to the proportion of training batches for a task compared to the total number of batches. This sampling procedure turns out to be pretty useful as we will see later, and is a pretty elegant way to prevent catastrophic forgetting.
The following snippet of code implements this procedure. Here, task_listdenotes a list of Task on which we want to train our model.
from typing import List
import numpy as npfrom allennlp.data.iterators import DataIterator### Set the Data Iterator for each task ###
# The data iterator is responsible for yield batches over the specified dataset.
for task in task_list:task_name = task._nametask.set_data_iterator(DataIterator()) # Set whatever DataIterator you like.### Create the sampling probability distribution over the tasks ###
sampling_prob = [task._data_iterator.get_num_batches(task._train_data) for task in task_list]
sampling_prob = sampling_prob / np.sum(sampling_prob)def choose_task(sampling_prob):"""Randomly choose one task to train."""return np.argmax(np.random.multinomial(1, sampling_prob))
# choose_task.py hosted with ❤ by GitHub
Let’s try our MTL trainer.
The following snippet of code illustrates how we can assemble the elementary pieces we’ve building so far ?.
The train() method will iterates over the tasks according to the probability distribution over the tasks and will optimize the parameters of the MTL model update after update.
from allennlp.training.optimizers import Optimizerclass MultiTaskTrainer():def __init__(self,model: Model,task_list: List[Task])self._model = modelself._task_list = task_listself._optimizers = {}for task in self._task_list:self._optimizers[task._name] = Optimizer() # Set the Optimizer you like.# Each task can have its own optimizer and own learning rate scheduler.def train(self,n_epochs: int = 50):### Instantiate the training generators ###self._tr_generators = {}for task in self._task_list:data_iterator = task._data_iteratortr_generator = data_iterator(task._train_data,num_epochs = None)self._tr_generators[task._name] = tr_generator### Begin Training ###self._model.train() # Set the model to train mode.for i in range(n_epochs):for _ in range(total_nb_training_batches):task_idx = choose_task()task = self._task_list[task_idx]task_name = task._namenext_batch = next(self._tr_generators[task._name]) # Sample the next batch for the current task of interest.optimizer = self._optimizers[task._name] # Get the task-specific optimizer for the current task of interest. optimizer.zero_grad()output_dict = self._model.forward(task_name = task_name, tensor_batch = batch) #Forward Passloss = output_dict["loss"]loss.backward() # Backward Pass
# view rawmulti_task_trainer.py hosted with ❤ by GitHub
Note that it is always a good idea to include a stopping condition on the training based on the validation metrics (cf _val_metric and _val_metric_decreases in class Task). For instance, we can stop training when the validation metrics stop improving during patience number epochs. This is usually performed after each training epoch. We haven’t done it but, you should be able to easily modify the previous snipped code to take into account these enhancements, or simply have a look at the more complete training code.
There are many other techniques you can use to train a MTL model that I don’t have the cover in depth in this blogpost ⌛️ so I’ll just point out a few references you’ll find worth reading now that you have the basic ideas:
- Successive regularization: one of the main issues that arises when training a MTL model is catastrophic forgetting where the model abruptly forgets part of the knowledge related to a previously learned task as a new task is learned. This phenomenon is especially recurring when multiple tasks are trained sequentially. Hashimoto et al. [6] introduce successive regularization: it prevents the parameter updates from being too far from the parameters at the previous epoch by adding an L2 penalty on the loss. In this particular setting, the MTL trainer does not switch of task after parameter update but go through the whole training dataset for the task of interest.
- Multi-Task as Question Answering: recently, McCann et al. [7]introduced a new paradigm to perform Multi-Task Learning. Each task is reformulated as a question-answering task while a single unified model (MQAN) is jointly trained to answer 10 different tasks considered in this work. MQAN achieves state-of-the-art results in several tasks such as the WikiSQL semantic parsing task. More generally, this work discusses the limits of single-task learning and the relations of Multi-Task Learning with Transfer Learning.
Improving the state-of-the-art ? in semantic tasks: A Hierarchical Multi-Task Learning model (HMTL)
Now that we’ve talked about the training scheme, how can we develop a model that would get the most benefit out of our multi-task learning scheme?
In the recent work that we will present at AAAI in January, we propose to design such a model in a hierarchical way.
More precisely, we build a hierarchy between a set of carefully selected semantic tasks in order to reflect the linguistic hierarchies between the different tasks (see also Hashimoto et al. [6]).
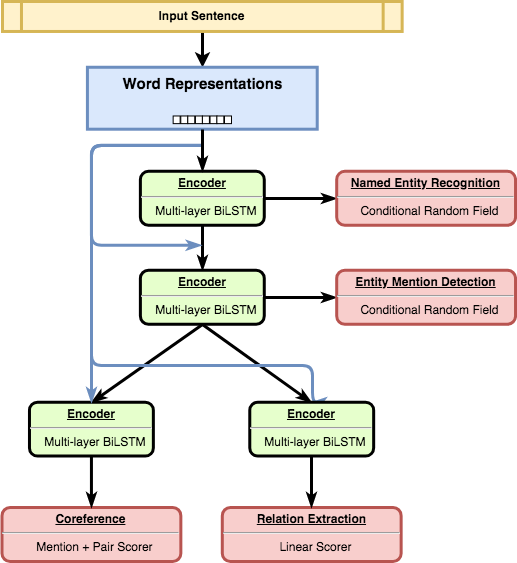
The HMTL (Hierarchical Multi-Task Learning) architecture. The base word representations (embeddings) are shared over the whole architecture through short-connections.
The intuition behind such a hierarchy is that some tasks may be simple and require a limited amount of modification to the input while others may require more knowledge and a more complex processing of the inputs.
The set of semantic tasks we considered is composed of Named Entity Recognition, Entity Mention Detection, Relation Extraction and Coreference Resolution.
The model is organized hierarchically as illustrated on the figure on the left with “simpler” tasks being supervised at lower level of the neural network and “more complex” task supervised at high layer of the neural net.
In our experiments we observed that these tasks can benefit from each other through Multi-Task Learning:
- the combination of these 4 tasks leads to state-of-the-art performance ? on 3 of the tasks (Named Entity Recognition, Relation Extraction and Entity Mention Detection).
- the MTL framework considerably accelerates the speed of training ⏱ compared to single task training frameworks.
We also analyzed the **embeddings that are learned and shared in HMTL.**For the analysis, we used SentEval, a set of 10 probing tasks introduced by Conneau et al. [8]. These probing tasks aim at evaluating how well sentence embeddings are able to capture a wide range of linguistic properties(syntactic, surface and semantic).
Our analysis indicated that the lower level shared embeddings already encode a rich representation and that as we move from the bottom to the top layers of the model, the hidden states of the layers tend to represent more complex semantic information.
This concludes our introduction to Multi-Task Learning. If you want to learn more about our hierarchical model (HMTL), you now have all the tools you need to dive into our paper ? and the training code ⌨️.
We also built a nice online demo ? so you can try HMTL by yourself ! ?
References
[1] ^ R. Caruana, Multitask Learning, 1997
[2] ^ R. Collobert and J. Weston, A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning, 2008
[3] ^ Sebastian Ruder, J. Bingel, I. Augenstein and A. Søgaard, Learning what to share between loosely related tasks, 2017
[4] ^ A. Conneau, D. Kiela, H. Schwenk, L. Barrault and A. Bordes, Supervised Learning of Universal Sentence Representations from Natural Language Inference Data, 2017
[5] ^ S, Subramanian, A. Trischler, Y. Bengio and C. J. Pal, Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning, 2018
[6] ^ K.Hashimoto, C. Xiong, Y. Tsuruoka and R. Socher, A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks, 2017
[7] ^ B. McCann, N. S. Keskar, C. Xiong, R. Socher, The Natural Language Decathlon: Multitask Learning as Question Answering, 2018
[8] ^ A. Conneau, D. Kiela, SentEval: An Evaluation Toolkit for Universal Sentence Representations, 2018
Thanks to Julien Chaumond, Clément Delangue, and Thomas Wolf.
转载于:https://my.oschina.net/dfsj66011/blog/3052339
Beating the state-of-the-art in NLP with HMTL相关推荐
- 跟踪算法基准--Tracking the Trackers: An Analysis of the State of the Art in Multiple Object Tracking
Tracking the Trackers: An Analysis of the State of the Art in Multiple Object Tracking https://arxiv ...
- 最新年龄估计综述(Deep learning approach for facial age classification: a survey of the state of the art)
目录 @[TOC](文章目录) #一.常用数据集 #二.常用的年龄识别方法 #1.多分类(MC) #2.度量回归(metric regression,MR) #3.排序(ranking) #4.深度标 ...
- Facial Emotion Recognition: State of the Art Performance on FER2013
[1] Khaireddin Y , Chen Z . Facial Emotion Recognition: State of the Art Performance on FER2013[J]. ...
- Artificial General Intelligence: Concept, State of the Art, and Future Prospects
Artificial General Intelligence: Concept, State of the Art, and Future Prospects(强人工智能:概念,前沿技术和未来展望) ...
- SLAM综述阅读笔记七:Visual and Visual-Inertial SLAM: State of the Art, Classification,and Experimental 2021
Visual and Visual-Inertial SLAM: State of the Art, Classification,and Experimental Benchmarking 作者:M ...
- 阅读笔记2020_01观点检测综述:《Stance Detection on Social Media: State of the Art and Trends》
观点检测综述:<Stance Detection on Social Media: State of the Art and Trends> 1.观点相关的关键词: Stance dete ...
- 图像处理-State of the Art
https://github.com/BlinkDL/BlinkDL.github.io 目前常见图像任务的 State-of-the-Art 方法,从 Super-resolution 到 Capt ...
- Visual question answering: a state‑of‑the‑art review(一)
论文下载地址:https://link.springer.com/article/10.1007/s10462-020-09832-7 目录 Abstract 1 Introduction 2 Ima ...
- Visual question answering: a state‑of‑the‑art review(二)
上一篇链接:https://blog.csdn.net/sx1996csdn/article/details/111608040 目录 5 Datasets 6 Performance evaluat ...
最新文章
- 进制转换(完成Python14作业的背景补充)
- OkHttp3源码详解(三) 拦截器-RetryAndFollowUpInterceptor
- 妈蛋:kinMaxShow轮播图异常,WebUploader图片上传坑爹,图片被压缩了
- Tungsten Fabric SDN — DCI
- 一个普通大学生的经历
- python nameerror import_Python-ImportError:无法导入名称X
- linux命令行ps1变量_利用Shell中变量PS1定制Linux Shell命令主提示符
- 32位CPU和64位CPU 区别
- matlab watershed函数简单实现_函数指针方法实现简单状态机(附代码)
- unity中链接字符串和变量显示_理解Unity中的优化(六):字符串和文本
- OpenCL 第7课:旋转变换(1)
- 雨林木风与微软数年博弈:蚂蚁和大象共舞
- 网络系统计算机专用术语有哪些,计算机网络专业术语
- 《C语言编程初学者指南》一导读
- Python+Selenium ----unittest单元测试框架
- switchHost以管理员权限打开
- 工程师职业发展的四个阶段
- CTGU实验6_2-创建函数计算图书超期天数
- 服务器虚拟化的工作原理,虚拟化技术及其原理
- Android开发最新所有框架总结排行榜