机器学习中常见的损失函数_机器学习中最常见的损失函数
机器学习中常见的损失函数
现实世界中的DS (DS IN THE REAL WORLD)
In mathematical optimization and decision theory, a loss function or cost function is a function that maps an event or values of one or more variables onto a real number intuitively representing some “cost” associated with the event. — Wikipedia
在数学优化和决策理论中 ,损失函数或成本函数是将一个事件或一个或多个变量的值映射到实数上的函数,该实数直观地表示与该事件相关的某些“成本”。 — 维基百科
As a core element, the Loss function is a method of evaluating your Machine Learning algorithm that how well it models your featured dataset. It is defined as a measurement of how good your model is in terms of predicting the expected outcome.
作为核心要素,损失函数是一种评估您的机器学习算法的方法,该算法可以很好地模拟您的特征数据集。 它的定义是衡量模型在预测预期结果方面的良好程度。
The Cost function and Loss function refer to the same context. The cost function is a function that is calculated as the average of all loss function values. Whereas, the loss function is calculated for each sample output compared to its actual value.
成本函数和损失函数引用相同的上下文。 成本函数是计算为所有损失函数值的平均值的函数。 而损失函数是针对每个样本输出及其实际值进行计算的。
The Loss function is directly related to the predictions of your model that you have built. So if your loss function value is less, your model will be providing good results. Loss function or I should rather say, the Cost function that is used to evaluate the model performance, needs to be minimized in order to improve its performance.
损失函数与您所建立的模型的预测直接相关。 因此,如果损失函数值较小,则模型将提供良好的结果。 损失函数,或者我应该说,用于评估模型性能的Cost函数需要最小化以改善其性能。
Lets now dive into the Loss functions.
现在让我们进入“损失”功能。
Widely speaking, the Loss functions can be grouped into two major categories concerning the types of problems that we come across in the real world — Classification and Regression. In Classification, the task is to predict the respective probabilities of all classes that the problem is dealing with. In Regression, oppositely, the task is to predict the continuous value concerning a given set of independent features to the learning algorithm.
广义上讲,损失函数可以分为两大类,分别是关于我们在现实世界中遇到的问题的类型- 分类和回归 。 在分类中,任务是预测问题正在处理的所有类别的各自概率。 相反,在回归中,任务是预测与学习算法给定的一组独立特征有关的连续值。
Assumptions: n/m — Number of training samples. i — ith training sample in a dataset. y(i) — Actual value for the ith training sample. y_hat(i) — Predicted value for the ith training sample.分类损失 (Classification Losses)
1.二进制互熵损失/对数损失 (1. Binary Cross-Entropy Loss / Log Loss)
This is the most common Loss function used in Classification problems. The cross-entropy loss decreases as the predicted probability converges to the actual label. It measures the performance of a classification model whose predicted output is a probability value between 0 and 1.
这是分类问题中最常用的损失函数。 交叉熵损失随着预测概率收敛到实际标记而减少。 它测量分类模型的性能,该分类模型的预测输出为0到1之间的概率值。
When the number of classes is 2, Binary Classification
当类别数为2时,二进制分类
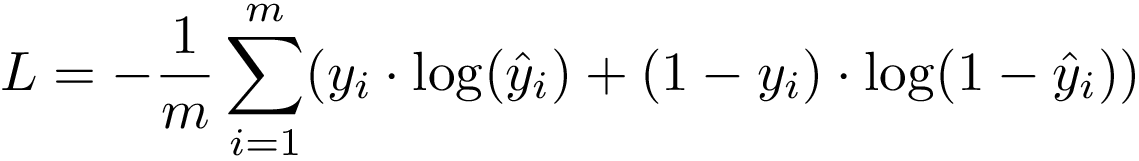
When the number of classes is more than 2, Multi-class Classification
当类别数大于2时,多重类别分类
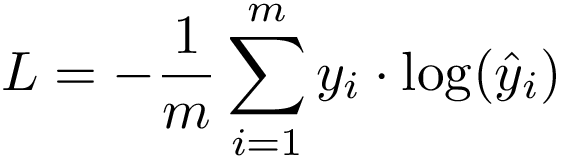
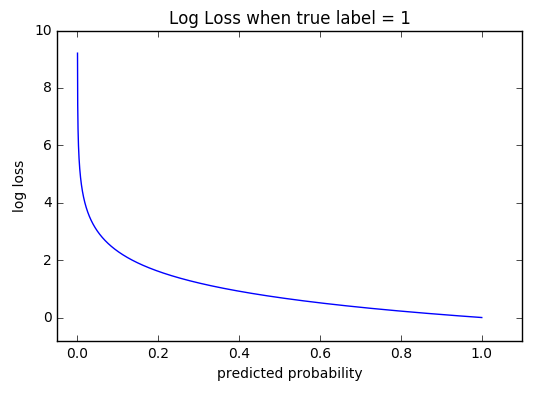
The Cross-Entropy Loss formula is derived from the regular likelihood function, but with logarithms added in.
交叉熵损失公式是从规则似然函数中导出的,但是增加了对数。
2.铰链损失 (2. Hinge Loss)
The second most common loss function used for Classification problems and an alternative to Cross-Entropy loss function is Hinge Loss, primarily developed for Support Vector Machine (SVM) model evaluation.
用于分类问题的第二种最常见的损失函数是“交叉损失”,它是“交叉损失”的另一种选择,主要是为支持向量机(SVM)模型评估而开发的。
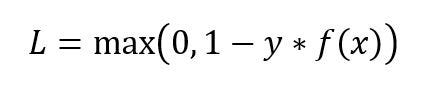

Hinge Loss not only penalizes the wrong predictions but also the right predictions that are not confident. It is primarily used with SVM Classifiers with class labels as -1 and 1. Make sure you change your malignant class labels from 0 to -1.
Hinge Loss不仅会惩罚错误的预测,还会惩罚不确定的正确预测。 它主要与具有类别标签-1和1的SVM分类器一起使用。请确保将恶性类别标签从0更改为-1。
回归损失 (Regression Losses)
1.均方误差/二次损失/ L2损失 (1. Mean Square Error / Quadratic Loss / L2 Loss)
MSE loss function is defined as the average of squared differences between the actual and the predicted value. It is the most commonly used Regression loss function.
MSE损失函数定义为实际值和预测值之间的平方差的平均值。 它是最常用的回归损失函数。
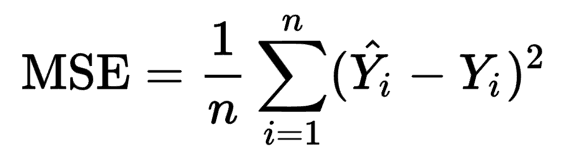
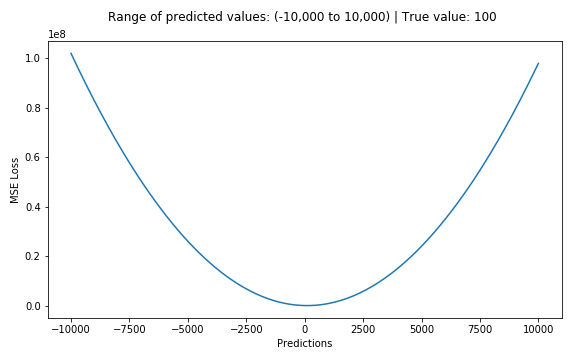
The corresponding cost function is the Mean of these Squared Errors (MSE). The MSE Loss function penalizes the model for making large errors by squaring them and this property makes the MSE cost function less robust to outliers. Therefore, it should not be used if the data is prone to many outliers.
相应的成本函数是这些平方误差的均值 (MSE) 。 MSE损失函数通过对错误进行平方来惩罚模型,以免产生大错误,并且此属性会使MSE成本函数对异常值的鲁棒性降低。 因此, 如果数据容易出现很多异常值 , 则不应使用此方法。
2.平均绝对误差/ L1损失 (2. Mean Absolute Error / L1 Loss)
MSE loss function is defined as the average of absolute differences between the actual and the predicted value. It is the second most commonly used Regression loss function. It measures the average magnitude of errors in a set of predictions, without considering their directions.
MSE损失函数定义为实际值与预测值之间的绝对差的平均值。 它是第二个最常用的回归损失函数。 它测量一组预测中的平均误差幅度,而不考虑其方向。
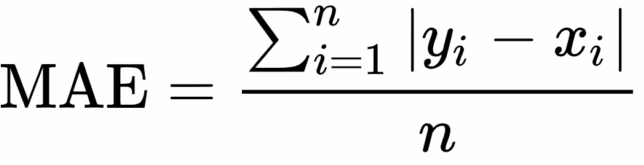
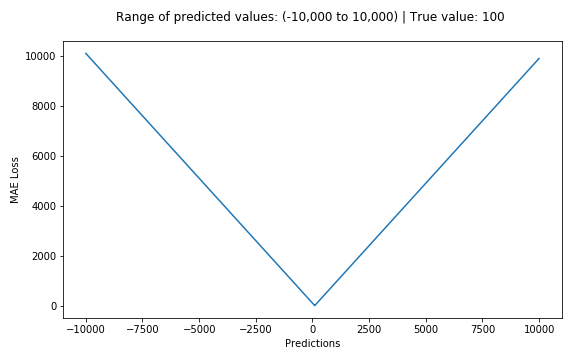
The corresponding cost function is the Mean of these Absolute Errors (MAE). The MAE Loss function is more robust to outliers compared to MSE Loss function. Therefore, it should be used if the data is prone to many outliers.
相应的成本函数是这些绝对误差的平均值 (MAE) 。 与MSE损失函数相比,MAE损失函数对异常值更健壮。 因此, 如果数据容易出现异常值 , 则应使用此方法。
3.胡贝尔损耗/平滑平均绝对误差 (3. Huber Loss / Smooth Mean Absolute Error)
Huber loss function is defined as the combination of MSE and MAE Loss function as it approaches MSE when
机器学习中倒三角符号 By David Weinberger 大卫·温伯格(David Weinberger) AI Outside In is a column by PAIR's writer-i ... 为了利用机器学习进行简单的线性回归,先理解机器学习和线性回归的概念,然后通过案例进行机器学习.本文主要目录如下: 一.机器学习的概念 二.线性回归的概念 三.机器学习线性回归模型 (一)导入数据集 ( ... GC停顿经常超过100ms 现象有同事反馈说,最近开始试用公司的Kubernetes,部署在Docker里的Go进程有问题,接口耗时很长,而且还有超时.逻辑很简单,只是调用了KV存储,KV存储一般响应 ... 甚至连type其本身都是对象,type对象 Python中变量与C/C++/Java中不同,它是指对象的引用,Python是动态类型,程序运行时候,会根据对象的类型 来确认变量到底是什么类型. 单独赋 ... 前言 之前的博客中我介绍了Kalman滤波器,这个算法被广泛用于多目标跟踪任务中的行人运动模型.然而实际场景中存在有很多相机运动,仅仅依赖行人运动模型是不够的.这次我主要介绍下相机运动模型,以对极几何 ... 展开全部 1.超码e68a843231313335323631343130323136353331333365656662: 超码是一个或多个属性的集合,这些属性可以让我们在一个实体集(所谓的实体集就 ... 在几何计算中S是:面积 在代数中S是:路程 在统计方面S是:标准差 在行程问题中S是:距离 在时间问题中S是:秒 三角形全等中S是:边 扩展资料: 化学元素 硫(sulfur)是一种非金属元素,化学符 ... 小波分析中MATLAB阈值获取函数及其应用附程序代码 1.小波分析中MATLAB阈值获取函数 MATLAB中实现阈值获取的函数有ddencmp.thselect.wbmpen和wwdcbm,下面对它们 ... 机器学习朴素贝叶斯算法 朴素贝叶斯算法 (Naive Bayes Algorithm) Naive Bayes is basically used for text learning. Using t ...机器学习中常见的损失函数_机器学习中最常见的损失函数相关推荐
最新文章
热门文章