Python爬虫实战示例-51job和豆瓣电影
2018年7月16日笔记
1.conda常用命令
1.1 列出当前环境的所有库
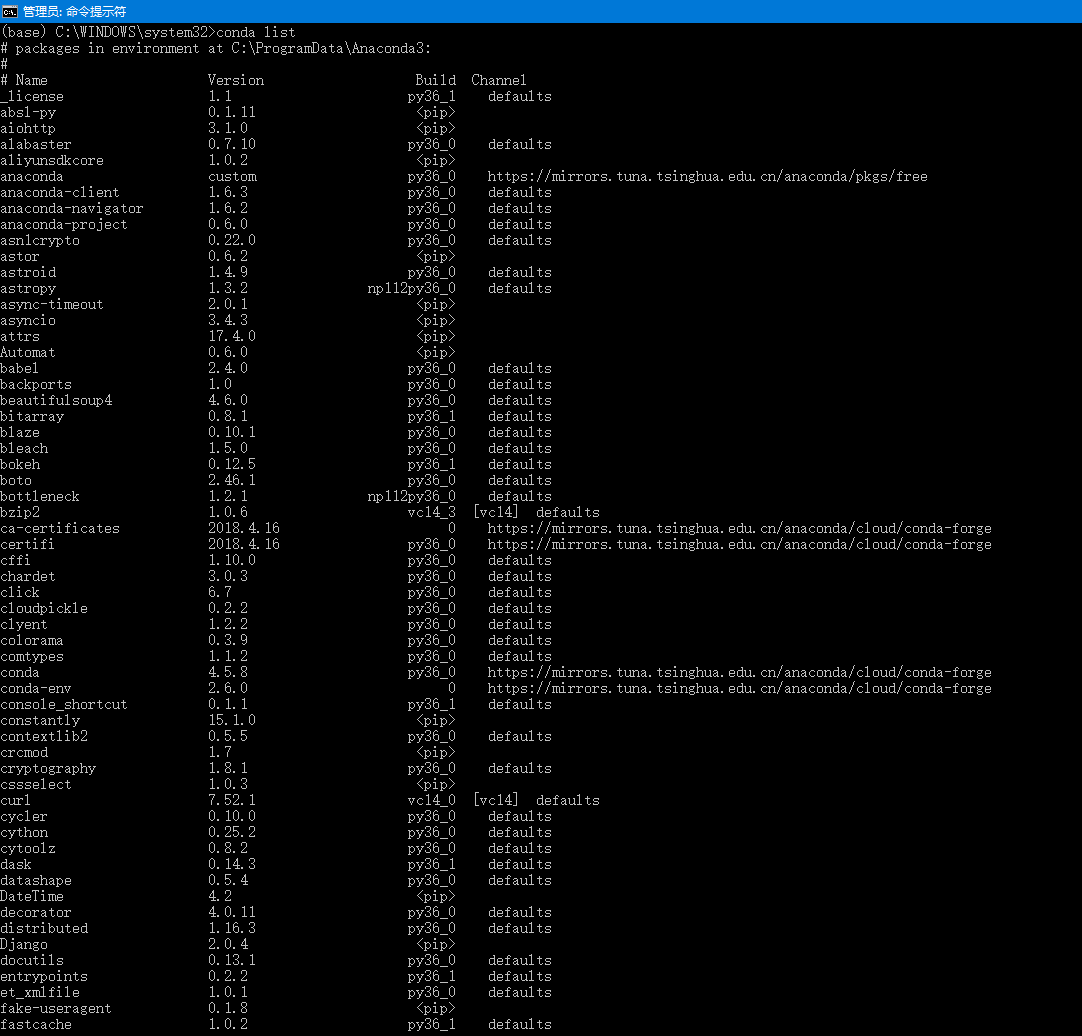
命令:conda list
在cmd中运行命令如下图所示:
1.2 管理环境
创建环境
命令:conda create -n {} python={}第一对大括号替换为环境的命名,第二对大括号替换为python的版本号
例如:conda create -n python27 python=2.7 这个命令就是创建一个python版本为2.7的环境,并命名为python27
列出所有环境
命令:conda info -e
进入环境
activate {},大括号替换为虚拟环境名
环境添加库
conda install {},大括号替换为要安装库的库名
环境删除库
conda remove {},大括号替换为要安装库的库名
删除环境
conda remove -n {} -all,大括号替换为要删除库的库名
2. 爬虫示例
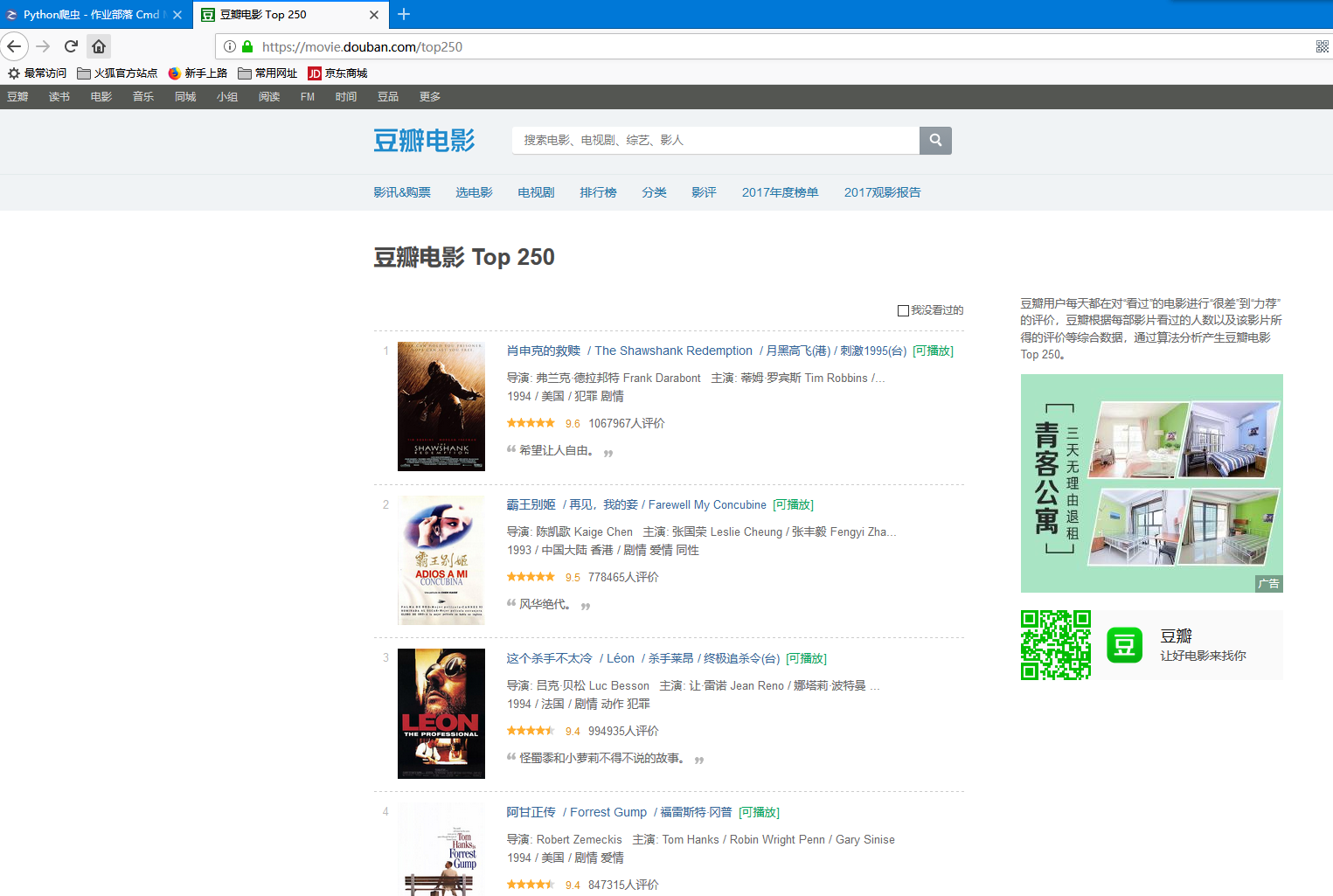
爬取豆瓣钱排名前250条信息,即下图这个网页的信息。
下面的sql语句用来创建数据库的表
drop database if exists douban;
create database douban;
use douban;
DROP TABLE IF EXISTS `top250`;
CREATE TABLE `top250` (`director` varchar(100) DEFAULT NULL,`role` varchar(100) DEFAULT NULL,`year` varchar(100) DEFAULT NULL,`area` varchar(20) DEFAULT NULL,`genre` varchar(100) DEFAULT NULL,`title` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
把豆瓣排名前250的电影信息导入mysql数据库中
下面一段代码能够成功运行的前提有两个:
1.安装库requests:pip install requests
安装库pymysql:pip install pymysql
2.修改下面代码中进入mysql数据库的用户名和密码,即修改下面这一句:
conn = pymysql.connect(host='localhost', user='root', passwd='...your password', db='douban',charset="utf8")
import requests
from bs4 import BeautifulSoup as bs
import pymysqlif __name__ == "__main__":movieInfos = [] # 用于保存所有的电影信息baseUrl = 'https://movie.douban.com/top250?start={}&filter='for startIndex in range(0, 226, 25):url = baseUrl.format(startIndex)# 爬取网页r = requests.get(url)# 获取html内容htmlContent = r.text# 用BeautifulSoup加载html文本内容进行处理soup = bs(htmlContent, "lxml")# 获取到页面中索引的class名为info的标签(应该有25个)movieList = soup.find_all("div", attrs={"class": "info"})# 遍历25条电影信息for movieItem in movieList:movieInfo = {} # 创建空字典,保存电影信息# 获取到名为class名为hd的div标签内容hd_div = movieItem.find("div", attrs={"class": "hd"})# 通过bd_div获取到里面第一个span标签内容hd_infos = hd_div.find("span").get_text().strip().split("\n")# < span class ="title" > 天堂电影院 < / span >movieInfo['title'] = hd_infos[0]# 获取到class名为bd的div标签内容bd_div = movieItem.find("div", attrs={"class": "bd"})# print(bd_div)# 通过bd_div获取到里面第一个p标签内容infos = bd_div.find("p").get_text().strip().split("\n")# print(infos) #包含了两行电影信息的列表# 获取导演和主演infos_1 = infos[0].split("\xa0\xa0\xa0")if len(infos_1) == 2:# 获取导演,只获取排在第一位的导演名字director = infos_1[0][4:].rstrip("...").split("/")[0]movieInfo['director'] = director# 获取主演role = infos_1[1][4:].rstrip("...").rstrip("/").split("/")[0]movieInfo['role'] = roleelse:movieInfo['director'] = NonemovieInfo['role'] = None# 获取上映的时间/地区/电影类型infos_2 = infos[1].lstrip().split("\xa0/\xa0")# 获取上映时间year = infos_2[0]movieInfo['year'] = year# 获取电影地区area = infos_2[1]movieInfo['area'] = area# 获取类型genre = infos_2[2]movieInfo['genre'] = genreprint(movieInfo)movieInfos.append(movieInfo)conn = pymysql.connect(host='localhost', user='root', passwd='...your password', db='douban',charset="utf8")# 获取游标对象cursor = conn.cursor()# 查看结果print('添加了{}条数据'.format(cursor.rowcount))for movietiem in movieInfos:director = movietiem['director']role = movietiem['role']year = movietiem['year']area = movietiem['area']genre = movietiem['genre']title = movietiem['title']sql = 'INSERT INTO top250 values("%s","%s","%s","%s","%s","%s")' % (director, role, year, area, genre, title)# 执行sqlcursor.execute(sql)# 提交conn.commit()print('添加了{}条数据'.format(cursor.rowcount))
插入数据库成功截图如下:

2018年7月17日笔记
3.HTTP理解
3.1 HTTP请求格式
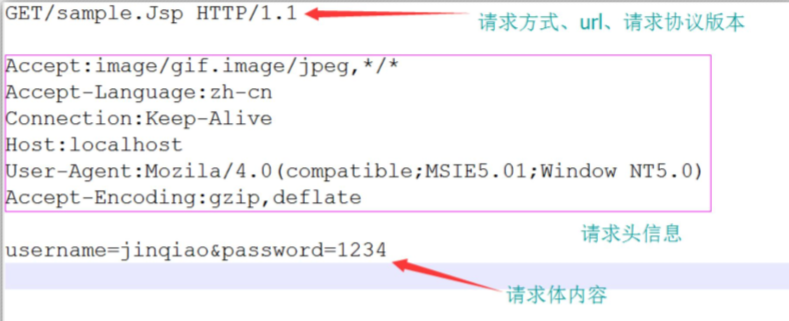
当浏览器向Web服务器发出请求时,它向服务器传递了一个数据块,也就是请求信息,HTTP请求信息由3部分组成:
1.请求方法URL协议/版本;2.请求头;3.请求体内容
3.2 HTTP请求方式
常见的http请求方式有get和post
Get是比较简单的http请求,直接会将发送给web服务器的数据放在请求地址的后面,即在请求地址后使用?key1=value1&ke2=value2形式传递数据,只适合数据量少,且没有安全性的请求
Post是需要发送给web服务器的数据经过编码放到请求体中,可以传递大量数据,并且有一定安全性,常用于表单提交
4.爬取51job网站信息
爬取51job网站信息并将数据持久化为excel文件
import requests
from bs4 import BeautifulSoup as bs
import re
from urllib import parse
import pandas as pddef cssFind(soup,cssSelector,nth=1):if len(soup.select(cssSelector)) >= nth:return soup.select(cssSelector)[nth-1].textelse:return 0def getSoup(url):response = requests.get(url)response.encoding = 'gbk'soup = bs(response.text,'lxml')return soupdef getMaxPageNumber(url):soup = getSoup(url)maxPageNumberBefore = cssFind(soup,"span.td")pattern = "共(\d*)页"maxPageNumber = re.findall(pattern,maxPageNumberBefore)[0]return int(maxPageNumber)def getJobList(url):soup = getSoup(url)webpage_job_list = soup.select("div.dw_table div.el")[1:]job_list = []for item in webpage_job_list:job = {}job['职位名'] = cssFind(item,"a").strip()job['公司名'] = cssFind(item,"span.t2")job['工作地点'] = cssFind(item,"span.t3")job['薪资'] = cssFind(item,"span.t4")job['发布时间'] = cssFind(item,"span.t5")job_list.append(job)return job_listdef getUrl(job,page):url_before = "https://search.51job.com/list/020000,000000,0000,00,9,99,{},2," \"{}.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99&" \"degreefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&" \"ord_field=0&confirmdate=9&dibiaoid=0&specialarea=00"url = url_before.format(parse.quote(job),page)return urlif __name__ == "__main__":job = "人工智能"firstPage_url = getUrl(job,1)maxPageNumber = getMaxPageNumber(firstPage_url)job_list = []for i in range(1,maxPageNumber+1):print("共有%d页,正在获取第%d页" %(maxPageNumber,i))url = getUrl(job,i)job_list.extend(getJobList(url))df = pd.DataFrame(job_list,columns=job_list[0].keys())excel_name = "51job_{}.xlsx".format(job)df.to_excel(excel_name)print("finished!")
5.爬取豆瓣排名前250电影信息
下面一段代码只需要修改连接mysql数据库的密码就可以运行。
sql语句写在代码中,所以代码比较长。
# coding=utf-8
from bs4 import BeautifulSoup as bs
import requests
import re
import pymysqldef cssFind(movie,cssSelector,nth=1):if len(movie.select(cssSelector)) >= nth:return movie.select(cssSelector)[nth-1].text.strip()else:return ''def reFind(pattern,sourceStr,nth=1):if len(re.findall(pattern,sourceStr)) >= nth:return re.findall(pattern,sourceStr)[nth-1]else:return ''def getConn(database ="pydb"):args = dict(host = 'localhost',user = 'root',passwd = '... your password',charset = 'utf8',db = database)return pymysql.connect(**args)if __name__ == "__main__":#连接数据库conn = getConn("douban")cursor = conn.cursor()#解析网页并将每条电影信息插入mysql数据库url_before = "https://movie.douban.com/top250?start={}"flag = Truefor i in range(0,250,25):url = url_before.format(i)response = requests.get(url)response.encoding = 'utf-8'soup = bs(response.text, 'lxml')movie_list = soup.select("ol.grid_view li")for movie in movie_list:item = {}item['title_zh'] = cssFind(movie, "span.title") #提取标题item['title2'] = cssFind(movie, "span.title", 2).lstrip('/').strip() #提取item['title_other'] = cssFind(movie, "span.other").lstrip('/').strip()details = cssFind(movie, "div.bd p")pattern_director = "导演: (.*)主"item['director'] = reFind(pattern_director, details).strip('/...').strip()if item['director'] == "":item['director'] = reFind("导演: (.*)", details).strip('/...').strip()pattern_actor = "主演: (.*)"item['actor'] = reFind(pattern_actor, details).strip('/...').strip()detail2 = details.split('\n')[1]item['year'] = detail2.split('/')[0].strip()item['country'] = detail2.split('/')[1].strip()item['genre'] = detail2.split('/')[2].strip()item['rating_grade'] = cssFind(movie, "span.rating_num")item['rating_number'] = cssFind(movie, "div.star span", 4).rstrip("人评价")item['summary'] = cssFind(movie, "span.inq")if flag:drop_sql = "drop table if exists movie"cursor.execute(drop_sql)conn.commit()table_movie = ','.join(['`%s` varchar(200)'%key for key in item.keys()])create_sql = "create table movie(`id` int primary key auto_increment,%s)" %table_moviecursor.execute(create_sql)conn.commit()flag = Falsetable_field = ','.join(['`%s`'%key for key in item.keys()])table_row = ','.join(['"%s"'%value for value in item.values()])insert_sql = "insert into movie(%s) values(%s)"%(table_field, table_row)print(insert_sql)cursor.execute(insert_sql)conn.commit()conn.close()
Python爬虫实战示例-51job和豆瓣电影相关推荐
- Python爬虫实战(爬取豆瓣电影)
首先介绍一下python的几个库,python之所以在实现爬虫方面有独特的优势,在于其类库非常的丰富,基本涵盖了所有的需求,只要找到对应的库进行import,这就类似于Java中导入类库或者jar包那 ...
- Python爬虫实战 | (3) 爬取豆瓣电影Top250
在本篇博客中,我们将使用requests+正则表达式来爬取豆瓣电影TOP250电影榜单,获取每部电影的序号.片名.导演.编剧.主演.类型.制作国家/地区.语言.上映日期.片长.又名.豆瓣评分和剧情简介 ...
- Python爬虫实战(1) | 爬取豆瓣网排名前250的电影(下)
在Python爬虫实战(1) | 爬取豆瓣网排名前250的电影(上)中,我们最后爬出来的结果不是很完美,这对于"精益求精.追求完美的"程序猿来说怎么能够甘心 所以,今天,用pyth ...
- Python爬虫入门(爬取豆瓣电影信息小结)
Python爬虫入门(爬取豆瓣电影信息小结) 1.爬虫概念 网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或脚本.爬虫的本质是模拟浏览器打开网页,获取网页中我们想要的那部分数据. 2.基本流程 ...
- Python爬虫实战(1) | 爬取豆瓣网排名前250的电影(上)
今天我们来爬取一下豆瓣网上排名前250的电影. 需求:爬取豆瓣网上排名前250的电影,然后将结果保存至一个记事本里. 开发环境: python3.9 pycharm2021专业版 我们先观察网页,看看 ...
- python爬虫实战-bs4爬取2345电影
抓取的原理也比较简单,不过多解释了,代码注释的也比较清楚 参考: Python网络爬虫实战(第二版) # -*- coding: utf-8 -*- """ Create ...
- python爬虫,Scrapy爬取豆瓣电影《芳华》电影短评,分词生成词云图。
项目github地址:https://github.com/kocor01/scrapy_cloud Python版本为3.6 自己写的简单架构<python爬虫,爬取豆瓣电影<芳华> ...
- 爬虫实战:爬取豆瓣电影 Top-250 到 Excel 表格中
最近在家无聊自学了python的一些基础知识.后来看到许多朋友都在写爬虫,自己感觉很有意思,也想试一下 >____< 其实本来我是想将数据爬取到excel之后再增加一些数据库操作,然后用f ...
- Python爬虫实战之爬取豆瓣详情以及影评
爬取豆瓣详情分为三步: 1.爬取豆瓣电影的所有标签,遍历标签,通过分析网址结构获得每一类标签下的电影url 2.通过url 爬取电影详情 3.导入数据库 爬虫代码如下: from urllib imp ...
最新文章
- R语言画图功能到底有多厉害,看看就知道了
- 自学python方法-总算懂得快速学习python的方法
- java免安装版配置,Tomcat(免安装版)的安装与配置 配置成windows服务
- COM 组件设计与应用(一)
- ITK:提取具有多个分量的图像通道
- 每天至少保证4个小时在学习知识
- springboot 监听所有异常_SpringBoot——目前Java开发最流行的框架(一)
- python websocket django vue_Python Django Vue 项目创建过程详解
- luoguP4709 信息传递 置换 + 多项式exp
- Android 使用反射调用StorageManager中 Hide方法getVolumeList、getVolumeState
- 软考·网络工程师认证(第八章)
- 很哇塞的网页特效之字符串切换
- 转载:SpringBoot非官方教程 | 第二十四篇: springboot整合docker
- Samba:centos服务器之间相互共享文件夹,可以用win10连接共享文件夹,并可以使用Docker部署
- oracle 给表空间增加多个数据文件
- mysqldump加速导入参数说明
- spack file hierarchy system
- 用matlab对2003年香港SARS数据建模预估新冠病毒在H市的疫情走势
- 后摩尔时代来临,语音IC封装技术一触即发
- 细思极恐,第三方跟踪器正在获取你的数据,如何防范?
热门文章
- C# 获取url 状态,获取重定向(HttpWebRequest)
- 【滤波跟踪】基于EKF、时差和频差定位实现目标跟踪附matlab代码
- 【C库函数】 strstr函数详解
- 苹果系统使用svg 动画_为什么要使用SVG图像:如何为SVG设置动画并使其快速闪电化
- Spring Security OAuth2:整合jwt
- Java多word文件生成后进行压缩并导出下载后,压缩文件损坏并提示“不可预料的压缩文件末端”和“CRC校验失败”
- [LSTM]时间序列预测存在的问题--滑动窗口是一把双刃剑【持续更新】
- 【JS】网页悬浮广告及联系QQ客服侧边栏
- 武器装备测试系统ETest
- 化工厂人员定位系统助力化工企业安全运行