PostgreSQL,MongoDB,Neo4j,OrientDB和ArangoDB比较
基准:PostgreSQL,MongoDB,Neo4j,OrientDB和ArangoDB
2015年10月13日表现
在这篇博客文章 - 这是一个综合的表现博客系列 - 我想完成我们的NoSQL性能测试的图片,并包括一些来自社区的支持反馈。首先,感谢您的所有意见,贡献和建议,以改进此开源NoSQL性能测试(Github)。这篇博客文章描述了对测试的彻底改革,不需要阅读所有以前的文章来获取图片 - 请看下面的附录,以获取有关硬件和软件的所有详细信息,数据集和测试用于此NoSQL性能比较。
为了响应许多请求,我现在已经添加了PostgreSQL来进行比较,这是一种受欢迎的RDBMS,支持JSON数据类型。关系数据模型是我们测试套件的完美补充,现在涵盖了在表格,文档和/或图表中实现的常见项目用例(读/写和特殊查询)以及一些社交网络相关。多模式方法如何与其通用对手进行对比?
对于本版本的性能测试,我还更新了软件源,将特定数据库的最新可用产品(版本或发行版)替换为自定义预览/快照版本,并将NodeJS版本更新为4.1.1。响应于用户反馈,我还添加了另一个测试 - 在请求邻居的邻居时返回整个配置文件数据,并增加了最短路径(40个而不是19个)和聚合(1000个而不是500个顶点)的测试用例数,因为测试领域中所有数据库的性能提升。
在我挖掘性能数字和测试细节之前:
这是一个供应商启动的测试,当然 - 想要通过设置场景并选择武器来显示他的数据库是有竞争力的:这里 - nodejs作为选择的驱动程序和内存启用设置,使用16核心机器GCE具有60GB的RAM。尽管如此,该设置不仅仅是为了使ArangoDB受益匪浅,而是为了使基础用例和nodej成为可靠的基础,作为每个供应商支持的(并非罕见的)客户端(@see:附录)。
当数据适合内存时,ArangoDB目前工作最佳。如果数据集比内存大得多,性能将会受到影响。我们正在处理这个问题,并将在不久的将来提供一个改进的存储引擎。
我想要尽可能的信任,所以我已经在公共Github存储库中的所有数据,设置和测试脚本中发布了nosql-tests。没有魔法,没有技巧 - 检查代码,做自己的测试!
简要测试说明和结果
以下性能测试将比较不同数据库中相同类型的查询。
对于这些测试,我使用了一个数据集,使我们能够测试基本的数据库操作以及图形相关的查询 - 一个具有用户配置文件和友谊关系的社交网站 - 来自斯坦福大学SNAP的 Pokec 。我不会测量每个可能的数据库操作。相反,我们专注于对几乎每个项目和一些典型的社交网络都是敏感的查询。我们执行个人资料的单次阅读和写入,我们计算一个临时聚合以概述年龄分布,我们要求朋友的朋友,或者我们要求最短的友谊路径。这些查询是针对所有测试的数据库运行的,与他们在内部使用的数据模型无关。结果是,
ArangoDB测试机上的吞吐量测量定义了比较的基线(100%)。较低的百分比指向较高的吞吐量,因此较高百分比表示较低的产量。
我执行了以下测试,所有这些测试都是在运行在node.js 4.1.1中的JavaScript中实现的:
- 单一阅读:单个文档读取配置文件(100,000个不同的文档)
- 单写:单个文档写入的文件(100,000个不同的文档)
- 聚合:单个集合上的自组织聚合(1,632,803个文档)。
在这里,我们计算网络中每个人的年龄分布统计信息,只需计算哪个年龄的频率。 - 邻居:找到(不同)直接邻居加上邻居的邻居,返回ID(1,000个顶点)
- 具有数据的邻居:查找(不同)直接邻居加上邻居的邻居并返回其个人资料(对于100个顶点)
- 最短路径:找到40条最短路径(在高度关联的社交图中)。这回答了两个人在社交网络中彼此接近的问题。
对于我们的测试,我们运行工作负载5次,平均结果。每个测试都从一个单独的预热阶段开始,允许数据库将数据加载到内存中,每个测试迭代从头开始,以防止缓存比较测试。
总体结果

测试表明,多模型数据库可以与单一模型数据库竞争。MongoDB在单个文档读取速度更快,但在聚合或第二个邻居选择时无法竞争。注意:MongoDB没有测试最短路径查询,因为它必须在客户端完全实现。

让我们进一步了解一下,在某些用例中我已经测试了什么,以便您了解发生了什么。也许,单次读/写写并不难理解,所以我专注于聚合和图功能。
年龄分布在社交网络中看起来如何?
测试:聚合
在这个测试中,我们聚集了一个集合(1,632,803个文档)。我们通过简单地计算哪个年龄出现频率,来计算网络中每个人的年龄分布。我们没有在任何数据库上放置此属性的辅助索引,因此它们都必须执行完整的集合扫描并执行计数统计 - 这是一个典型的即席查询。
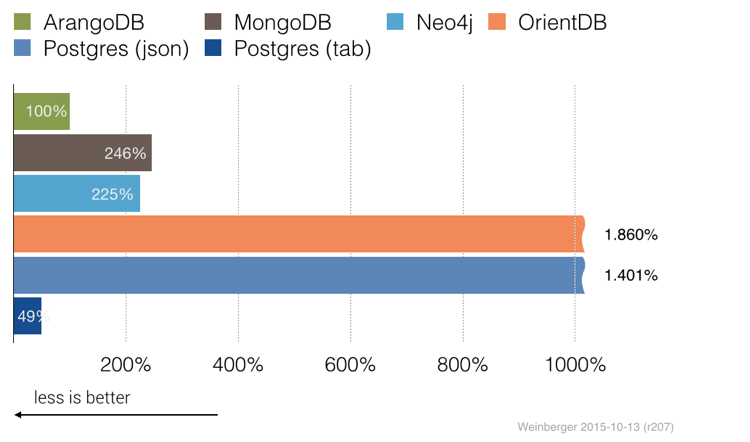
ArangoDB中的聚合是有效的,使用1.25秒。在AVG中为1.6M的文件定义基线为100%。age在PostgreSQL中只有一个显式的表格列,比预期要快得多,在0.61秒内处理聚合。当然这对RDBMS来说是一个很好的用例。由于PostgreSQL还提供了JSON数据类型,您可能需要检查这里的性能...:不,17.5秒。超越了你想要接受的一切。所有其他数据库比ArangoDB要慢得多,从而在OrientDB的情况下,从MongoDB的x2.5到x20。
谁是我的扩展的朋友网络的一部分?
测试:邻居搜索
查找直接邻居加上邻居的邻居1000个顶点。
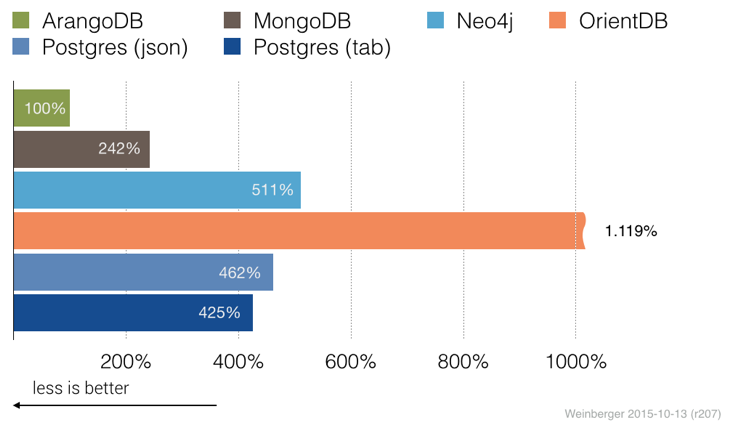
看起来像图数据库的情况,但并不一定。至少Neo4j和OrientDB在这个测试中不能脱颖而出 - 尽管它是一个简单的图形遍历。ArangoDB在AVG中使用的只是464ms,没有图数据库接近。这是因为使用索引查找在已知长度的图形中查找比在每个顶点使用出站链接更快。
[我]和[奥巴马]之间有多少人?
测试:最短路径
找到40个最短路径(在高度连接的社交图中)。这回答了两个人在社交网络中彼此接近的问题。
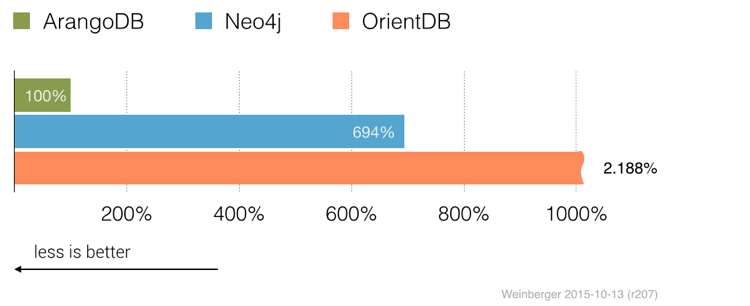
该最短路径是图形数据库的特产,所以我甚至不试图实现的PostgreSQL或MongoDB中类似的东西。ArangoDB需要61ms在AVG处理40个最短路径。
结论
测试结果表明,ArangoDB可以与其领域的领先数据库进行竞争,并与其他多模型数据库OrientDB进行竞争。记忆是我们的痛点,它将在下一个主要版本中得到解决。使用灵活的数据模型,您可以在许多不同的情况下使用多模型数据库,而无需学习新技术。这里给出了一些简短的现实生活中的任务。
请看我们的存储库,做自己的测试,并分享结果。不同的硬件 - 不同的结果:您的里程可能会有所不同,并且您的要求有所不同 - 因此请使用此备件作为样板,并通过自己的测试进行扩展。如果要验证我们的结果,请使用相同的硬件配置。
感谢您对开源基准的贡献和信任。
附录 - 有关数据,机器,软件和测试的详细信息
数据
Pokec是斯洛伐克最受欢迎的在线社交网络。我使用了斯坦福大学SNAP提供的数据的快照。它包含1,632,803人的个人资料。相应的友谊图有30,622,564边。个人资料数据包含性别,年龄,爱好,兴趣,教育等等,但是单个JSON文档是非常多样化的,因为许多人都是空白的。资料数据为斯洛伐克语。Pokec的友谊是针对的。顶点的未压缩JSON数据大约需要600 MB,边缘的未压缩JSON数据大约需要1.832 GB。图形的直径(最长最短路径)为11,但图形高度相关,就像社交网络一样。这使得最短路径问题特别困难。
硬件
所有基准测试都是在n1-standard-16具有16个虚拟内核的Google Compute Engine 虚拟机上完成的(在这些虚拟机上,虚拟内核在2.3 GHz Intel Xeon E5 v3(参见Haswell)上实现为单硬件超线程),共有60个GB的RAM。数据存储在256 GB SSD驱动器上,直接连接到服务器。客户端是n1-standard-8同一网络中的(8个vCPU,30 GB RAM)。
软件
我想使用客户端/服务器模型,因此我需要一种语言来实现测试,我决定必须满足以下条件:
- 比较中的每个数据库必须有合理的驱动程序。
- 它不是我们的竞争者实施的母语之一,因为这可能会给一些不公平的优势。这排除了C ++和Java。
- 该语言必须在市场上相当流行和相关。
- 该语言应该在所有主要平台上都可用。
这实质上离开JavaScript,PHP,Python和Ruby。我决定用JavaScript与node.js的 4.1.1,因为它的流行和已知的要快,特别是与网络的工作负载。
对于每个数据库,我使用JavaScript了相应数据库供应商推荐的最新驱动程序。
我用过
- ArangoDB V2.7.0 RC2 for x86_64(驱动程序:arangojs@3.9.1)
- MongoDB V3.0.6 for x86_64,使用WiredTiger存储引擎(驱动:mongodb@2.0.45)
- 运行在JDK 1.7.0_79上的Neo4j Enterprise Edition V2.3.0 M3(驱动程序:neo4j@2.0.0-RC2)
- OrientDB 2.2 alpha - 社区版(驱动程序:orientjs@2.1.0)
- PostgreSQL 9.4.4(驱动程序:pg-promise@1.11.0)
所有的数据库都安装在同一台机器上,我已尽全力调整配置参数,例如关闭透明的大页面,并为每个进程配置了40,000个打开的文件描述符。此外,我已经调整了社区和供应商提供的配置参数,从Michael Hunger(Neo4j)和Luca Garulli(OrientDB)来改善个人设置。
测试
我已经确保每个实验数据库有机会将所有相关数据加载到RAM中。某些数据库允许对集合进行明确的加载命令,其他数据库不允许。因此,我相应地增加了缓存大小,并将全集合扫描用作预热程序。
我不想对查询缓存进行基准测试,或者同样 - 数据库可能需要一个预热阶段,但是无法根据缓存大小/效率来比较数据库。高速缓存是否有用,在很大程度上取决于个别用例,多次执行某个查询。
对于单个文档测试,我对每个文档使用单独的请求,但使用keep-alive并允许多个并发连接,因为我想测试吞吐量而不是延迟。
每当驱动程序允许配置它时,我选择使用最多25个连接的TCP / IP连接池。请注意,ArangoDB驱动程序不使用HTTP流水线,而MongoDB驱动程序似乎对其二进制协议做了相应的操作,这有助于提高吞吐量。有关每个单独数据库的更多详细信息,请参见下文。
我分别讨论了六项测试:
单个文档读取(100,000个不同的文档)
在这个测试中,我们在node.js客户端中存储了10万个人,并尝试从数据库中获取相应的配置文件,每个都在一个单独的查询中。在node.js中,一切都发生在单个线程中,但是异步。要完全加载数据库连接,我们首先将所有查询提交给驱动程序,然后使用node.js事件循环等待所有回调。我们测量从我们开始发送查询之前的最后一个答案到达的时钟。显然,这将衡量驱动程序/数据库组合的吞吐量,而不是延迟,因此我们给出了所有请求的完整的wallclock时间。
单个文档写入(100,000个不同的文档)
对于此测试,我们进行类似的操作:我们将10万个不同的文档加载到node.js客户端,然后使用单独的查询来测量将所有文件发送到数据库所需的wallclock时间。我们再次首先将所有请求安排到驱动程序,然后使用node.js事件循环等待所有回调。如上所述,这是一个吞吐量测量。
单个文档写入同步(100,000个不同的文档)
与之前相同,但后者等待直到写入同步到磁盘 - 这是Neo4j的默认行为。为了公平起见,我们引入了这个额外的测试来进行比较。
集合在一个集合(1,632,803个文档)
在这个测试中,我们对所有1,632,803个配置文件进行了自组织聚合,并计算出AGE属性的每个值的频率。我们没有在任何数据库上为此属性设置辅助索引,因此它们都必须执行完整的集合扫描并执行计数统计。我们只测量一个请求,因为这是足够的工作来获得准确的测量。扫描的数据量应该超过任何CPU缓存可以容纳的数量,所以我们应该看到真正的RAM访问,但是由于上述的预热过程,通常没有磁盘访问。
找到邻居的邻居和邻居(不同于1000个顶点)
这是与网络使用案例相关的第一个测试。对于每个共有1000个顶点,我们找到所有邻居的所有邻居和所有邻居,实现找到一个人的朋友的朋友和朋友,并返回一组不同的朋友身份。这是考虑长度为1或2的路径的典型图形匹配问题。对于非图形数据库MongoDB,我们可以使用聚合框架来计算结果。在PostgreSQL中,我们可以使用一个具有由索引支持的id from/ id 的关系表to。在使用的Pokec数据集中,我们为我们的1,000个查询顶点获得了邻居的18,972个邻居和852,824个邻居。
使用配置文件数据找到邻居的邻居和邻居(不同于100个顶点)
由于有一个抱怨说,对于真正的用例,我们需要返回多于ID,我添加了一个neighbors with profiles解决这个问题的测试用例,并返回完整的配置文件。在我们的测试用例中,我们从我们查询的前100个顶点中检索出84,972个配置文件。对于nodej,完整的853k配置文件(1,000个顶点)将是非常多的。
找到40条最短路径(在高度关联的社交图中)
这是一个纯粹的图形测试,具有特别适合图形数据库的查询。我们在40个不同的请求中询问数据库,以便在我们的社交图中找到两个给定顶点之间的最短路径。由于图形的高连通性,这样的查询很难,因为顶点的邻域随着半径以指数方式增长。较传统的数据库中最短的路径是非常糟糕的,因为答案涉及图中先验未知数的步骤,通常会导致先验的未知数量的连接。
最初我们选择了20个随机对的顶点,但事实证明,对于其中一个对,图中没有路径。我们排除了第一个测量的那个,因为Neo4j在最短的路径上完全相当,非常缓慢,注意到没有这样的路径。在首次发布的性能测试后,供应商改进了其工具,以便我们可以将最短路径的数量增加到40个,这足以获得准确的测量。然而,请注意,不同对的时间变化很大,因为它取决于最短路径的长度以及有时在边缘穿过的顺序上。
我们完成每个单独数据库的更详细的说明:
ArangoDB:
只要不违反唯一约束,ArangoDB就可以指定主键属性_key的值。它会自动在该属性上创建主散列索引,以及在友谊关系(边集合)中的_from和_to属性上的边缘索引。没有其他指标被使用。
MongoDB的:
由于MongoDB将边缘视为另一个集合中的文档,所以通过在友谊关系的_from和_to属性上创建两个索引来帮助图形查询。由于没有图形操作,我使用汉斯 - 彼得·格拉斯尔(Hans-Peter Grasl)建议的聚合框架来做邻居邻居,甚至没有尝试做最短路径。
请注意:MongoDB 3.0.6的写入性能显着下降。我用MongoDB 3.0.3重新验证了测试,并测量了以前测试中已知的快速结果。(对于100,000个单个写入同步,103秒对324秒)。然而,由于没有迹象表明它是这些版本之一的错误,所以我会留下最新的版本。
Neo4j的:
在Neo4j中,配置文件的属性值作为顶点的属性存储。为了公平比较,我在_key属性上创建了一个索引。Neo4j声称为边缘使用“无索引的邻接”,所以我没有在边上添加另一个索引。
我得到了供应商的配置参数(感谢Michael Hunger),并添加了同步到磁盘测试的写入,因为这是Neo4j支持的默认(仅))行为。在第一次表演测试之后,我还有一个定制的Neo4j 2.3快照从Michael Hunger改进了Neo4j的性能。随着企业版本2.3(M3),这些改进看起来正式发布,以使每个人都能受益。开源是一件很酷的事情。
OrientDB:
OrientDB 2.0.9是第一个测试大多数学科中第四好的数据库。开发人员使用发布的结果来分析一些瓶颈,并在第一篇发布的博客文章(2.1 RC4)后两周内提高了OrientDB的性能。我现在可以从提供的2.2预览快照切换到当前的2.2 alpha,似乎包括快照的所有性能改进。
请注意:有一个OrientDB博客文章作为回应,但它通过激活/实现查询缓存(在OrientDB中)来比较苹果与橘子,以改善结果。
Postgres的:
我已经使用PostgreSQL与存储在表中的用户配置文件,其中包含两个列,即配置文件ID和整个配置文件数据的JSON数据类型。在第二种方法中,我将一个经典的关系数据建模与所有的配置文件属性一起用作表中的列 - 仅供比较。
资源与贡献
此测试中使用的所有代码都可以从我的Github存储库下载,所有数据都在公共的Amazon S3存储区中发布。tar文件由两个文件夹数据(数据库)和导入(源文件)组成。
- https://s3.amazonaws.com/nosql-sample-data/arangodb-2.7rc2.tar.bz2
- https://s3.amazonaws.com/nosql-sample-data/mongodb-3.0.6.tar.bz2
- https://s3.amazonaws.com/nosql-sample-data/neo4j-enterprise-2.3.0-M03.tar.bz2
- https://s3.amazonaws.com/nosql-sample-data/orientdb-2.2alpha.zip
- https://s3.amazonaws.com/nosql-sample-data/postgresql-9.4.4.tar.bz2
PostgreSQL,MongoDB,Neo4j,OrientDB和ArangoDB比较相关推荐
- 常用的图数据库对比(Neo4j、FlockDB、AllegroGrap、GraphDB、InfiniteGraph、TITAN、OrientDb)
1.数据库分类: 传统的关系数据库和NoSQL数据库 传统的关系数据库:mySQL.oracle NoSQL数据库分为Graph,Document,Column Family.Key-Value St ...
- 图数据库对比·201808
图数据库Benchmark. https://github.com/socialsensor/graphdb-benchmarks Benchmark: PostgreSQL, MongoDB, Ne ...
- 力压 MongoDB、Redis,PostgreSQL 蝉联“年度数据库”!
全球知名的数据库流行度排行榜网站 DB-Engines 于今日宣布:PostgreSQL 为 2018 年度数据库管理系统. 根据 PostgreSQL 在 2018 年的数据库排名,它比其他监测到的 ...
- 为什么选择图形数据库,为什么选择Neo4j?
最近在抓取一些社交网站的数据,抓下来的数据用MySql存储.问我为什么用MySql,那自然是入门简单,并且我当时只熟悉MySql.可是,随着数据量越来越大,有一个问题始终困扰着我,那就是社交关系的存储 ...
- python构建知识图谱_NLP第20课:Neo4j 从入门到构建一个简单知识图谱
Neo4j 对于大多数人来说,可能是比较陌生的.其实,Neo4j 是一个图形数据库,就像传统的关系数据库中的 Oracel 和 MySQL一样,用来持久化数据.Neo4j 是最近几年发展起来的新技术, ...
- Neo4j 从入门到构建一个简单知识图谱
Neo4j 对于大多数人来说,可能是比较陌生的.其实,Neo4j 是一个图形数据库,就像传统的关系数据库中的 Oracel 和 MySQL一样,用来持久化数据.Neo4j 是最近几年发展起来的新技术, ...
- hbase redis mongoddb neo4j 非关系型数据库简介
Hbase 列式存储以流的方式在列中存储所有的数据.对于任何记录,索引都可以快速地获取列上的数据:列式存储支持行检索,但这需要从每个列获取匹配的列值,并重新组成行.HBase(Hadoop Datab ...
- DB-Engines 2018:PostgreSQL 蝉联“年度数据库”称号
全球知名的数据库流行度排行榜网站 DB-Engines 于今日宣布:PostgreSQL 为 2018 年度数据库管理系统.理由如下: 根据 PostgreSQL 在 2018 年的数据库排名,它比其 ...
- 12306的西天取经路 - 春节抢票与PostgreSQL数据库设计思考
标签 PostgreSQL , 12306 , 春节 , 一票难求 , 门禁广告 , 数组 , 范围类型 , 抢购 , 排他约束 , 大盘分析 , 广告查询 , 火车票 背景 马上春节了,又到了火车票 ...
最新文章
- 探究rh6上mysql5.6的主从、半同步、GTID多线程、SSL认证主从复制
- python培训班哪些比较好-哪家python培训班比较好?2018年如何选择
- yarn ngc使用练习
- BREW做的第一个程序--Hello world!
- Envoy实现.NET架构的网关(一)静态配置与文件动态配置
- php怎么配置configure,PHP编译参数configure配置详解(持续更新中)
- 2019级C语言大作业 - BrickMansions
- 医院药品管理系统源码 HIS系统源码
- linux 查看pgsql端口,如何查看postgres数据库端口
- google如何恢复误删除书签
- 自适应音频功率放大器
- 《python网络爬虫和信息提取》:全球电影票房排行榜(附更改后的代码)
- Exynos 4412处理器IIC总线控制器(包括协议)
- 计算机毕业设计Java物流信息管理系统录像演示(源码+系统+mysql数据库+Lw文档)
- 第9周 Python计算生态概览
- html和js画圣诞树图片,基于JS2Image实现圣诞树代码
- 《具体数学》部分习题解答4
- android多线程讲解与实例
- 【VPS折腾记】nextcloud——扩展功能之挂载onedrive(三)
- concurrentHashMap代码走读 chm走读