CS231n——机器学习算法——线性分类(上: 线性分类器)
k-Nearest Neighbor分类器存在以下不足:
- 分类器必须记住所有训练数据并将其存储起来,以便于未来测试数据用于比较。这在存储空间上是低效的,数据集的大小很容易就以GB计。
- 对一个测试图像进行分类需要和所有训练图像作比较,算法计算资源耗费高。
引言:我们将要实现一种更强大的方法来解决图像分类问题,该方法可以自然地延伸到神经网络和卷积神经网络上。
这种方法主要有两部分组成:
- 一个是评分函数(score function),它是原始图像数据到类别分值的映射。
- 一个是损失函数(loss function),它是用来量化预测分类标签的得分与真实标签之间一致性的。该方法可转化为一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数值。
从图像到标签分值的参数化映射
该方法的第一部分就是定义一个评分函数,这个函数将图像的像素值映射为各个分类类别的得分,得分高低代表图像属于该类别的可能性高低。
下面是具体例子来展示该方法。
现假设有一个包含很多图像的训练集xi∈RDx_i\in R^Dxi∈RD,每个图像都有一个对应的分类标签yiy_iyi。这里i=1,2...Ni=1,2...Ni=1,2...N并且yi∈1...K。y_i\in 1...K。yi∈1...K。这就是说,我们有N个图像样例,每个图像的维度是D,共有K种不同的分类。
举例来说,在CIFAR-10中,我们有一个N=50000N=50000N=50000的训练集,每个图像有D=32x32x3=3072个像素,而K=10K=10K=10,这是因为图片被分为10个不同的类别(狗,猫,汽车等)。
我们现在定义评分函数为:f:RD→RKf:R^D\to R^Kf:RD→RK,该函数是原始图像像素到分类分值的映射。
线性分类器入门简介:
在本模型中,我们从最简单的概率函数开始,一个线性映射:
f(xi,W,b)=Wxi+b\displaystyle f(x_i,W,b)=Wx_i+bf(xi,W,b)=Wxi+b
在上面的公式中,假设每个图像数据都被拉长为一个长度为DDD的列向量,大小为[D x 1]。其中大小为[K x D]的矩阵WWW和大小为[K x 1]列向量bbb为该函数的参数(parameters)。
还是以CIFAR-10为例,xix_ixi就包含了第iii个图像的所有像素信息,这些信息被拉成为一个[3072 x 1]的列向量,WWW大小为[10x3072],bbb的大小为[10x1]。因此,3072个数字(原始像素数值)输入函数,函数输出10个数字(不同分类得到的分值)。参数WWW被称为权重(weights)。bbb被称为偏差向量(bias vector),这是因为它影响输出数值,但是并不和原始数据xix_ixi产生关联。在实际情况中,人们常常混用权重和参数这两个术语。
需要注意的几点:
- 首先,一个单独的矩阵乘法WxiWx_iWxi就高效地并行评估10个不同的分类器(每个分类器针对一个分类),其中每个类的分类器就是WWW的一个行向量。
- 注意我们认为输入数据(xi,yi)(x_i,y_i)(xi,yi)是给定且不可改变的,但参数WWW和bbb是可控制改变的。我们的目标就是通过设置这些参数,使得计算出来的分类分值情况和训练集中图像数据的真实类别标签相符。
- 该方法的一个优势是训练数据是用来学习到参数WWW和bbb的,一旦训练完成,训练数据就可以丢弃,留下学习到的参数即可。这是因为一个测试图像可以简单地输入函数,并基于计算出的分类分值来进行分类。
- 最后,注意只需要做一个矩阵乘法和一个矩阵加法就能对一个测试数据分类,这比k-NN中将测试图像和所有训练数据做比较的方法快多了。
理解线性分类器
线性分类器计算图像中3个颜色通道中所有像素的值与权重的矩阵乘,从而得到分类分值。
根据我们对权重设置的值,对于图像中的某些位置的某些颜色,函数表现出喜好或者厌恶(根据每个权重的符号而定)。
举个例子,可以想象“船”分类就是被大量的蓝色所包围(对应的就是水)。那么“船”分类器在蓝色通道上的权重就有很多的正权重(它们的出现提高了“船”分类的分值),而在绿色和红色通道上的权重为负的就比较多(它们的出现降低了“船”分类的分值)。
举一个将图像映射到分类分值的例子。

为了便于可视化,假设图像只有4个像素(都是黑白像素,这里不考虑RGB通道),有3个分类(红色代表猫,绿色代表狗,蓝色代表船,注意,这里的红、绿和蓝3种颜色仅代表分类,和RGB通道没有关系)。
首先将图像像素拉伸为一个列向量,与WWW进行矩阵乘,然后得到各个分类的分值。需要注意的是,这个WWW一点也不好:猫分类的分值非常低。从上图来看,算法倒是觉得这个图像是一只狗。
将图像看做高维度的点:
既然图像被伸展成为了一个高维度的列向量,那么我们可以把图像看做这个高维度空间中的一个点(即每张图像是3072维空间中的一个点)。整个数据集就是一个点的集合,每个点都带有1个分类标签。
既然定义每个分类类别的分值是权重和图像的矩阵乘,那么每个分类类别的分数就是这个空间中的一个线性函数的函数值。我们没办法可视化3072维空间中的线性函数,但假设把这些维度挤压到二维,那么就可以看看这些分类器在做什么了:
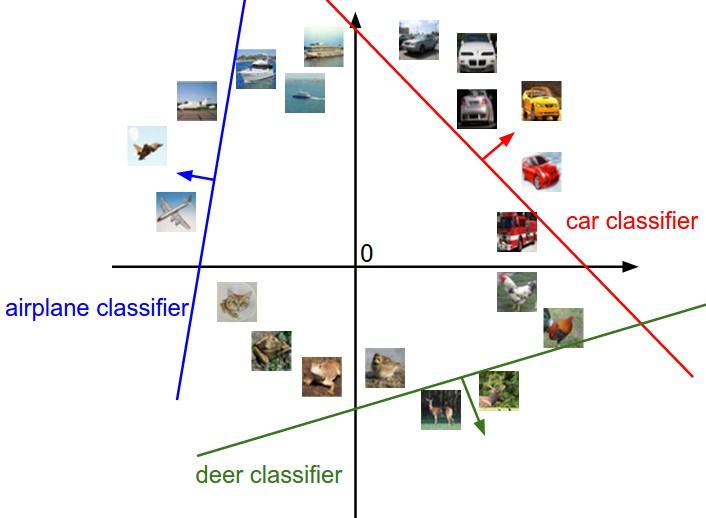
图像空间的示意图
其中每个图像是一个点,有3个分类器。以红色的汽车分类器为例,红线表示空间中汽车分类分数为0的点的集合,红色的箭头表示分值上升的方向。所有红线右边的点的分数值均为正,且线性升高。红线左边的点分值为负,且线性降低。
从上面可以看到,WWW的每一行都是一个分类类别的分类器。对于WWW数字的几何解释是:如果改变其中一行的数字,会看见分类器在空间中对应的直线开始向着不同方向旋转。而偏差b,则允许分类器对应的直线平移。需要注意的是,如果没有偏差,无论权重如何,在xi=0x_i=0xi=0时分类分值始终为0。这样所有分类器的线都不得不穿过原点。
将线性分类器看做模板匹配:
关于权重W的另一个解释是它的每一行对应着一个分类的模板(有时候也叫作原型)。一张图像对应不同分类的得分,是通过使用内积(也叫点积)来比较图像和模板,然后找到和哪个模板最相似。从这个角度来看,线性分类器就是在利用学习到的模板,针对图像做模板匹配。从另一个角度来看,可以认为还是在高效地使用k-NN,不同的是我们没有使用所有的训练集的图像来比较,而是每个类别只用了一张图片(这张图片是我们学习到的,而不是训练集中的某一张),而且我们会使用(负)内积来计算向量间的距离,而不是使用L1或者L2距离。
偏差和权重的合并技巧:它能够将我们常用的参数W和b合二为一。回忆一下,分类评分函数定义为:
f(xi,W,b)=Wxi+b\displaystyle f(x_i,W,b)=Wx_i+bf(xi,W,b)=Wxi+b
分开处理这两个参数(权重参数W和偏差参数b)有点笨拙,一般常用的方法是把两个参数放到同一个矩阵中,同时xix_ixi向量就要增加一个维度,这个维度的数值是常量1,这就是默认的偏差维度。这样新的公式就简化成下面这样:
f(xi,W)=Wxi\displaystyle f(x_i,W)=Wx_if(xi,W)=Wxi
还是以CIFAR-10为例,那么xix_ixi的大小就变成[3073x1],而不是[3072x1]了,多出了包含常量1的1个维度)。WWW大小就是[10x3073]了。WWW中多出来的这一列对应的就是偏差值bbb,具体见下图:
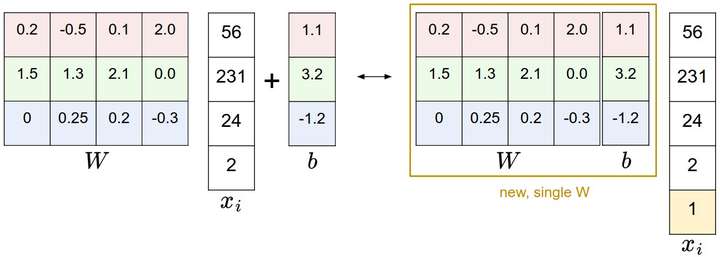
左边是先做矩阵乘法然后做加法,右边是将所有输入向量的维度增加1个含常量1的维度,并且在权重矩阵中增加一个偏差列,最后做一个矩阵乘法即可。左右是等价的。通过右边这样做,我们就只需要学习一个权重矩阵,而不用去学习两个分别装着权重和偏差的矩阵了。
图像数据预处理:在上面的例子中,所有图像都是使用的原始像素值(从0到255)。在机器学习中,对于输入的特征做归一化(normalization)处理是常见的套路。而在图像分类的例子中,图像上的每个像素可以看做一个特征。在实践中,对每个特征减去平均值来中心化数据是非常重要的。 在这些图片的例子中,该步骤意味着根据训练集中所有的图像计算出一个平均图像值,然后每个图像都减去这个平均值,这样图像的像素值就大约分布在[-127, 127]之间了。下一个常见步骤是,让所有数值分布的区间变为[-1, 1]。这就是零均值的中心化。具体以后详解。
CS231n——机器学习算法——线性分类(上: 线性分类器)相关推荐
- 斯坦福CS231n李飞飞计算机视觉之线性分类上
线性分类器简介 线性评分函数 阐明线性分类器 译者注:上篇翻译截止处 损失函数 多类SVM Softmax分类器 SVM和Softmax的比较 基于Web的可交互线性分类器原型 小结 线性分类 上一篇 ...
- AI:人工智能领域算法思维导图集合之有监督学习/无监督学习/强化学习类型的具体算法简介(预测函数/优化目标/求解算法)、分类/回归/聚类/降维算法模型选择思路、11类机器学习算法详细分类之详细攻略
AI:人工智能领域算法思维导图集合之有监督学习/无监督学习/强化学习类型的具体算法简介(预测函数/优化目标/求解算法).分类/回归/聚类/降维算法模型选择思路.11类机器学习算法详细分类(决策树/贝叶 ...
- 【机器学习基础】数学推导+纯Python实现机器学习算法27:LDA线性判别分析
Python机器学习算法实现 Author:louwill Machine Learning Lab 线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的线性分 ...
- 机器学习算法_机器学习算法中分类知识总结!
↑↑↑关注后"星标"Datawhale每日干货 & 每月组队学习,不错过Datawhale干货 译者:张峰,Datawhale成员 本文将介绍机器学习算法中非常重要的知识- ...
- 【机器学习基础】机器学习算法中分类知识总结!
译者:张峰,Datawhale成员 本文将介绍机器学习算法中非常重要的知识-分类(classification),即找一个函数判断输入数据所属的类别,可以是二类别问题(是/不是),也可以是多类别问题( ...
- 正确率能很好的评估分类算法吗_机器学习算法:分类知识超全总结!
关注上方"Python数据科学",选择星标,关键时间,第一时间送达! ☞500g+超全学习资源免费领取 Datawhale,译者:张峰本文将介绍机器学习算法中非常重要的知识-分类 ...
- 机器学习算法(分类算法)—支持向量机(4)
一.回顾 前面三篇博文主要介绍了支持向量机的基本概念,线性可分支持向量机的原理以及线性支持向量机的原理,线性可分支持向量机是线性支持向量机的基础.对于线性支持向量机,选择一个合适的惩罚参数,并 ...
- 从零开始数据科学与机器学习算法-KNN分类算法-07
KNN概念 物以类聚 1.k--超参数(hyper-parameter) 2.k最好为奇数(no even number , better be odd) 3.k大小有学问: k太小:outliers ...
- 【CS231n】斯坦福大学李飞飞视觉识别课程笔记(六):线性分类笔记(上)
[CS231n]斯坦福大学李飞飞视觉识别课程笔记 由官方授权的CS231n课程笔记翻译知乎专栏--智能单元,比较详细地翻译了课程笔记,我这里就是参考和总结. [CS231n]斯坦福大学李飞飞视觉识别课 ...
- CS231n课程笔记翻译3:线性分类笔记
译者注 :本文 智能单元 首发,译自斯坦福CS231n课程笔记 Linear Classification Note ,课程教师 Andrej Karpathy 授权翻译.本篇教程由 杜客 翻译完成, ...
最新文章
- CSS类命名的语义化VS结构化方式
- 07丨切片集群:数据增多了,是该加内存还是加实例
- 一个秒杀系统的设计思考
- setfacl 权限导出_Linux如何使用setfacl命令创建权限文件
- 有上下界网络流问题汇总
- 操作系统之内存管理:1、内存管理基础知识(指令工作原理、地址转化、程序运行过程)
- 董明珠上榜中国杰出商界女性100
- 特斯拉电动皮卡不太香:预订表现不及3年前的Model 3
- 虚拟机中运行windows内核
- springmvc并发调用controller方法时对局部变量的影响
- PRD产品需求文档原型模版
- 电脑硬件检测软件排名列前茅:试试整合了当下最好的硬件检测软件的图吧工具箱吧 | 图吧工具箱在哪里下载
- wordpress邮件地址混淆 你没权限访问整个邮件地址造成的死链接
- 自定义列表数据自动循环向下滚动view(类似于通知通报消息)
- php 上周日期,php获取本周和上周的开始日期和结束日期
- 养乐多深耕三线城市加码长、珠三角;欧康维视在港交所主板挂牌上市 | 美通企业日报...
- Unity Shader学习:SSAO屏幕环境光遮蔽
- Flutter 无法热重载
- baidu进阶训练笔记九20200727
- RoBERTa相比BERT的改进
热门文章
- 富士施乐m115b怎么连接电脑_富士施乐m115b驱动|富士施乐DocuPrint M115b一体机驱动下载 V1.01.00 官方版 - 比克尔下载...
- UOS手动选择富士施乐打印机驱动
- 用户画像——《大数据用户画像的方法及营销实践》演讲
- 用netbean搭建第一个struts的web项目
- android 脱壳 加固,安卓的脱壳之战-爱加密加固
- 如何在虚拟机安装鸿蒙os,VirtualBox安装教程
- 常见工具识别集锦---Windows应急响应工具
- 嵌入式Linux系统的指纹识别,嵌入式指纹识别系统设计
- MKV 高清视频文件分解与封装和音频编码的转换
- python 爬虫 美女_使用Python爬虫爬取网络美女图片