python 爬虫之路教程
原址
摘要: From:https://piaosanlang.gitbooks.io/spiders/content/ 爬虫入门初级篇 IDE 选择: PyCharm(推荐)、SublimeText3、VS2015、wingIDE 装python2还是python3 ? python社区需要很多年才能将现有的模块移植到支持python3. django web.py flask等还不支持p
Fromhttps://piaosanlang.gitbooks.io/spiders/content/
爬虫入门初级篇
IDE 选择 PyCharm(推荐)、SublimeText3、VS2015、wingIDE
装python2还是python3
python社区需要很多年才能将现有的模块移植到支持python3. django web.py flask等还不支持python3。所以推荐安装python2 最新版。
Windows 平台
从 http://python.org/download/ 上安装Python 2.7。您需要修改 PATH 环境变量将Python的可执行程序及额外的脚本添加到系统路径中。将以下路径添加到 PATH 中:
C:\Python2.7\;C:\Python2.7\Scripts\; 。从 http://sourceforge.net/projects/pywin32/ 安装 pywin32。 请确认下载符合您系统的版本(win32或者amd64)
Linux Ubuntu 平台
安装Python sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
学习需求抓取的某个网站或者某个应用的内容提取有用的价值
实现手段模拟用户在浏览器或者应用(app)上的操作实现自动化的程序爬虫应用场景利用爬虫能做什么
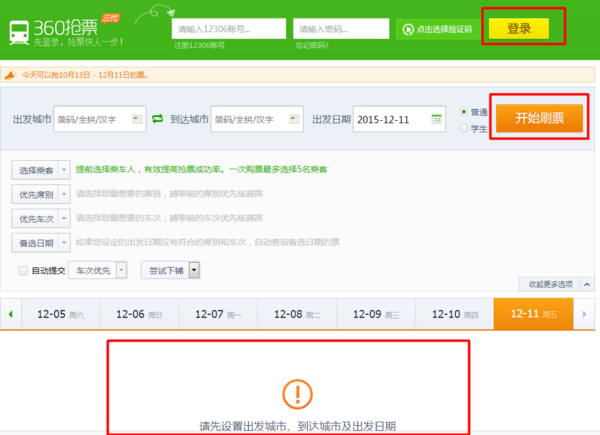
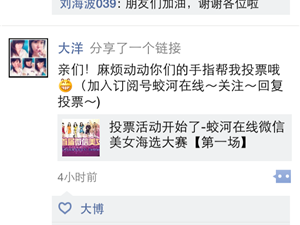
大家最熟悉的应用场景抢票神器360抢票器、投票神器微信朋友圈投票
企业应用场景
- 拉勾网招聘职位数据分析报告
- 2016年中国外卖O2O行业发展报告
2016年中国在线出境游市场研究报告
1、各种热门公司招聘中的职位数及月薪分布

2、对某个App的下载量跟踪

3、 饮食地图
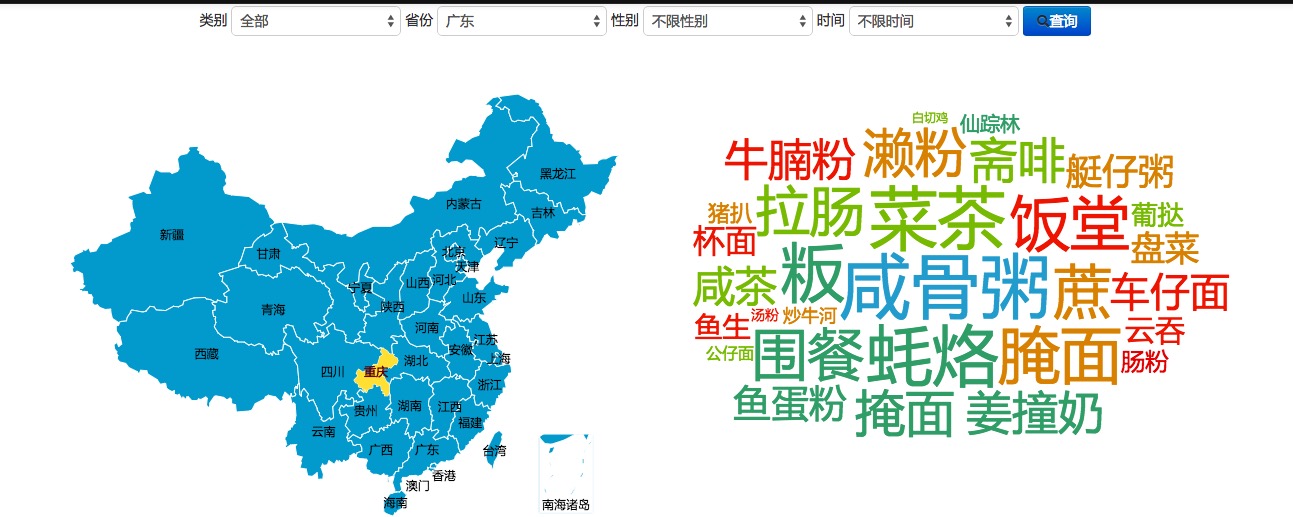
还可以把男的排除掉只看女的

4、 票房预测

爬虫是什么
专业术语 网络爬虫又被称为网页蜘蛛网络机器人网络爬虫是一种按照一定的规则自动的抓取万维网信息的程序或者脚本。
爬虫起源产生背景
随着网络的迅速发展万维网成为大量信息的载体如何有效地提取并利用这些信息成为一个巨大的挑战搜索引擎有YahooGoogle百度等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。网络爬虫是搜索引擎系统中十分重要的组成部分它负责从互联网中搜集网页采集信息这些网页信息用于建立索引从而为搜索 引擎提供支持它决定着整个引擎系统的内容是否丰富信息是否即时因此其性能的优劣直接影响着搜索引擎的效果。
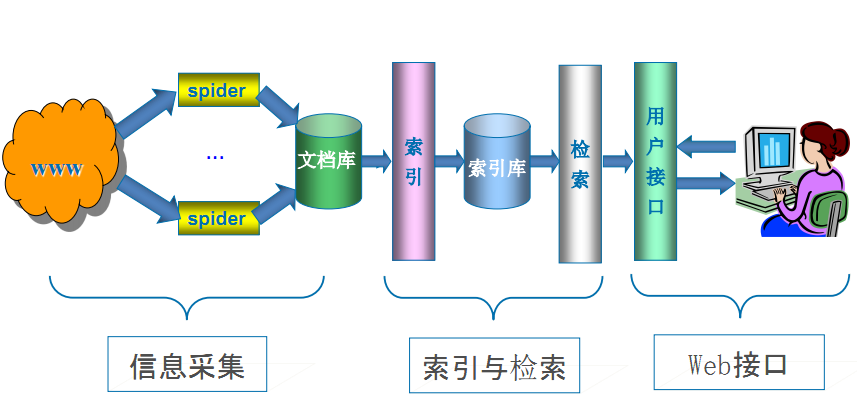
网络爬虫程序的优劣很大程度上反映了一个搜索引擎的好差。
不信你可以随便拿一个网站去查询一下各家搜索对它的网页收录情况爬虫强大程度跟搜索引擎好坏基本成正比。
搜索引擎工作原理
第一步抓取网页爬虫
搜索引擎是通过一种特定规律的软件跟踪网页的链接从一个链接爬到另外一个链接像蜘蛛在蜘蛛网上爬行一样所以被称为“蜘蛛”也被称为“机器人”。搜索引擎蜘蛛的爬行是被输入了一定的规则的它需要遵从一些命令或文件的内容。 Robots协议也称为爬虫协议、机器人协议等的全称是“网络爬虫排除标准”Robots Exclusion Protocol网站通过Robots协议告诉搜索引擎哪些页面可以抓取哪些页面不能抓取
https://www.taobao.com/robots.txt
http://www.qq.com/robots.txt
https://www.taobao.com/robots.txt
第二步数据存储
搜索引擎是通过蜘蛛跟踪链接爬行到网页并将爬行的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。搜索引擎蜘蛛在抓取页面时也做一定的重复内容检测一旦遇到权重很低的网站上有大量抄袭、采集或者复制的内容很可能就不再爬行。
第三步预处理
搜索引擎将蜘蛛抓取回来的页面进行各种步骤的预处理。
⒈提取文字 ⒉中文分词 ⒊去停止词 ⒋消除噪音搜索引擎需要识别并消除这些噪声比如版权声明文字、导航条、广告等…… 5.正向索引 6.倒排索引 7.链接关系计算 8.特殊文件处理。 除了HTML文件外搜索引擎通常还能抓取和索引以文字为基础的多种文件类型如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。但搜索引擎还不能处理图片、视频、Flash 这类非文字内容也不能执行脚本和程序。
第四步排名提供检索服务
但是这些通用性搜索引擎也存在着一定的局限性如
(1)不同领域、不同背景的用户往往具有不同的检索目的和需求通用搜索引擎所返回的结果包含大量用户不关心的网页。
(2)通用搜索引擎的目标是尽可能大的网络覆盖率有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
(3)万维网数据形式的丰富和网络技术的不断发展图片、数据库、音频、视频多媒体等不同数据大量出现通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力不能很好地发现和获取。
(4)通用搜索引擎大多提供基于关键字的检索难以支持根据语义信息提出的查询。
为了解决上述问题定向抓取相关网页资源的聚焦爬虫应运而生。 聚焦爬虫是一个自动下载网页的程序它根据既定的抓取目标有选择的访问万维网上的网页与相关的链接获取所需要的信息。
与通用爬虫(general purpose web crawler)不同聚焦爬虫并不追求大的覆盖而将目标定为抓取与某一特定主题内容相关的网页为面向主题的用户查询准备数据资源。
聚焦爬虫工作原理以及关键技术概述
网络爬虫是一个自动提取网页的程序它为搜索引擎从万维网上下载网页是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始获得初始网页上的URL在抓取网页的过程中不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂需要根据一定的网页分析算法过滤与主题无关的链接保留有用的链接并将其放入等待抓取的URL队列。然后它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL并重复上述过程直到达到系统的某一条件时停止。另外所有被爬虫抓取的网页将会被系统存贮进行一定的分析、过滤并建立索引以便之后的查询和检索对于聚焦爬虫来说这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫聚焦爬虫还需要解决三个主要问题
(1) 对抓取目标的描述或定义
(2) 对网页或数据的分析与过滤
(3) 对URL的搜索策略。
抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。
网络爬虫的发展趋势
随着AJAX/Web2.0的流行如何抓取AJAX等动态页面成了搜索引擎急需解决的问题如果搜索引擎依旧采用“爬”的机制是无法抓取到AJAX页面的有效数据的。 对于AJAX这样的技术所需要的爬虫引擎必须是基于驱动的。而如果想要实现事件驱动首先需要解决以下问题
第一JavaScript的交互分析和解释
第二DOM事件的处理和解释分发
第三动态DOM内容语义的抽取。
爬虫发展的几个阶段博士论文copy
第一个阶段可以说是早期爬虫斯坦福的几位同学完成的抓取当时的互联网基本都是完全开放的人类流量是主流
第二个阶段是分布式爬虫但是爬虫面对新的问题是数据量越来越大传统爬虫已经解决不了把数据都抓全的问题需要更多的爬虫于是调度问题就出现了
第三阶段是暗网爬虫。此时面对新的问题是数据之间的link越来越少比如淘宝点评这类数据彼此link很少那么抓全这些数据就很难还有一些数据是需要提交查询词才能获取比如机票查询那么需要寻找一些手段“发现”更多更完整的不是明面上的数据。
第四阶段智能爬虫这主要是爬虫又开始面对新的问题社交网络数据的抓取。
社交网络对爬虫带来的新的挑战包括
有一条账号护城河
我们通常称UGCUser Generated Content指用户原创内容。为web2.0即数据从单向传达到双向互动人民群众可以与网站产生交互因此产生了账号每个人都通过账号来标识身份提交数据这样一来社交网络就可以通过封账号来提高数据抓取的难度通过账号来发现非人类流量。之前没有账号只能通过cookie和ip。cookie又是易变易挥发的很难长期标识一个用户。
网络走向封闭
新浪微博在2012年以前都是基本不封的随便写一个程序怎么抓都不封但是很快越来越多的站点都开始防止竞争对手防止爬虫来抓取数据逐渐走向封闭越来越多的人难以获得数据。甚至都出现了专业的爬虫公司这在2010年以前是不可想象的。。
反爬手段封杀手法千差万别
写一个通用的框架抓取成百上千万的网站已经成为历史或者说已经是一个技术相对成熟的工作也就是已经有相对成熟的框架来”盗“成百上千的墓但是极个别的墓则需要特殊手段了目前市场上比较难以抓取的数据包括微信公共账号微博facebookins淘宝等等。具体原因各异但基本无法用一个统一框架来完成太特殊了。如果有一个通用的框架能解决我说的这几个网站的抓取这一定是一个非常震撼的产品如果有一定要告诉我那我公开出来然后就改行了。
当面对以上三个挑战的时候就需要智能爬虫。智能爬虫是让爬虫的行为尽可能模仿人类行为让反爬策略失效只有”混在老百姓队伍里面才是安全的“因此这就需要琢磨浏览器了很多人把爬虫写在了浏览器插件里面把爬虫写在了手机里面写在了路由器里面(春节抢票王)。再有一个传统的爬虫都是只有读操作的没有写操作这个很容易被判是爬虫智能的爬虫需要有一些自动化交互的行为这都是一些抵御反爬策略的方法。+
从商业价值上是一个能够抽象千百万网站抓取框架的爬虫工程师值钱还是一个能抓特定难抓网站的爬虫工程师值钱
能花钱来买被市场认可的数据都是那些特别难抓的抓取成本异常高的数据。
目前市场上主流的爬虫工程师都是能够抓成百上千网站的数据但如果想有价值还是得有能力抓特别难抓的数据才能估上好价钱。
爬虫基本原理
爬虫是 模拟用户在浏览器或者某个应用上的操作把操作的过程、实现自动化的程序
当我们在浏览器中输入一个url后回车后台会发生什么比如说你输入http://www.sina.com.cn/
简单来说这段过程发生了以下四个步骤
1.查找域名对应的IP地址。
2.向IP对应的服务器发送请求。
3.服务器响应请求发回网页内容。
4.浏览器解析网页内容。
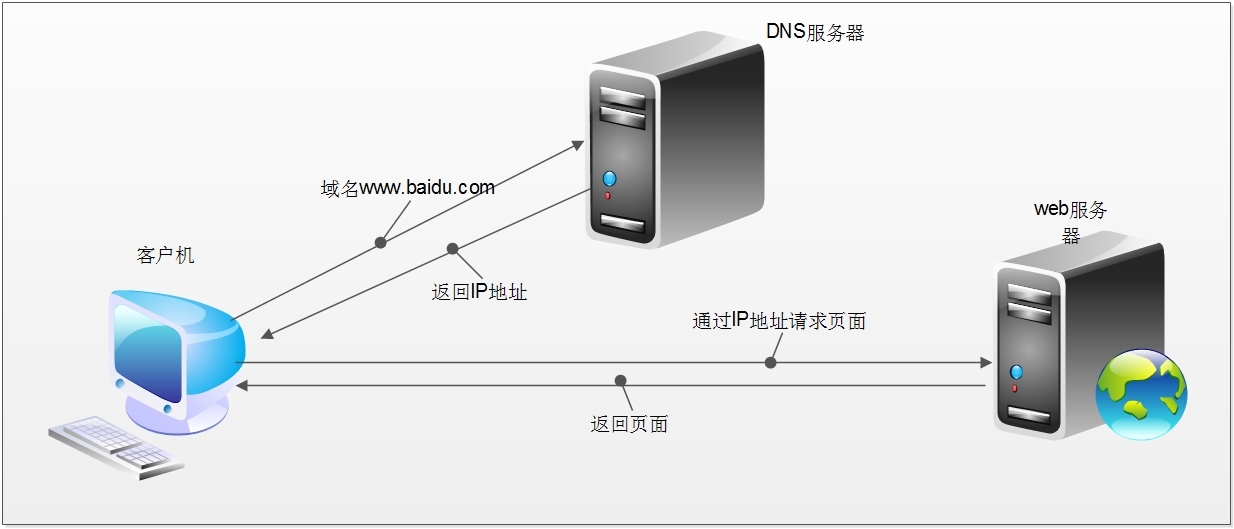
网络爬虫本质本质就是浏览器http请求。
浏览器和网络爬虫是两种不同的网络客户端都以相同的方式来获取网页
网络爬虫要做的简单来说就是实现浏览器的功能。通过指定url直接返回给用户所需要的数据 而不需要一步步人工去操纵浏览器获取。
浏览器是如何发送和接收这个数据呢 HTTP简介。
HTTP协议HyperText Transfer Protocol超文本传输协议目的是为了提供一种发布和接收HTML(HyperText Markup Language)页面的方法。
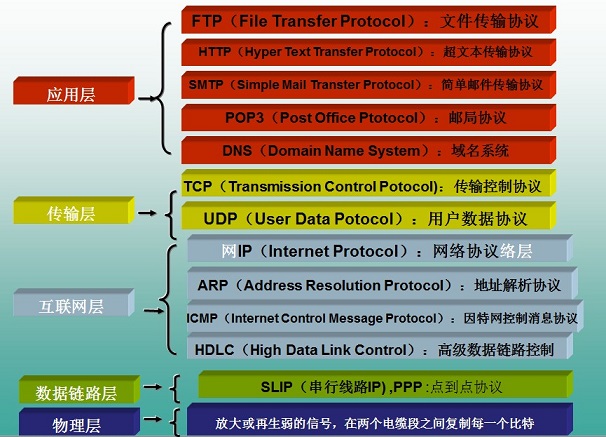
HTTP协议所在的协议层了解
HTTP是基于TCP协议之上的。在TCP/IP协议参考模型的各层对应的协议如下图,其中HTTP是应用层的协议。 默认HTTP的端口号为80HTTPS的端口号为443。
HTTP工作过程
一次HTTP操作称为一个事务其工作整个过程如下
1 ) 、地址解析
如用客户端浏览器请求这个页面http://localhost.com:8080/index.htm从中分解出协议名、主机名、端口、对象路径等部分对于我们的这个地址解析得到的结果如下 协议名http 主机名localhost.com 端口8080 对象路径/index.htm在这一步需要域名系统DNS解析域名localhost.com,得主机的IP地址。
2、封装HTTP请求数据包
把以上部分结合本机自己的信息封装成一个HTTP请求数据包
3封装成TCP包建立TCP连接TCP的三次握手
在HTTP工作开始之前客户机Web浏览器首先要通过网络与服务器建立连接该连接是通过TCP来完成的该协议与IP协议共同构建Internet即著名的TCP/IP协议族因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议根据规则只有低层协议建立之后才能才能进行更层协议的连接因此首先要建立TCP连接一般TCP连接的端口号是80。这里是8080端口
4客户机发送请求命令
建立连接后客户机发送一个请求给服务器请求方式的格式为统一资源标识符URL、协议版本号后边是MIME信息包括请求修饰符、客户机信息和可内容。
5服务器响应
服务器接到请求后给予相应的响应信息其格式为一个状态行包括信息的协议版本号、一个成功或错误的代码后边是MIME信息包括服务器信息、实体信息和可能的内容。
实体消息是服务器向浏览器发送头信息后它会发送一个空白行来表示头信息的发送到此为结束接着它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
6服务器关闭TCP连接
一般情况下一旦Web服务器向浏览器发送了请求数据它就要关闭TCP连接然后如果浏览器或者服务器在其头信息加入了这行代码Connection:keep-alive
TCP连接在发送后将仍然保持打开状态于是浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间还节约了网络带宽。
HTTP协议栈数据流

HTTPS
HTTPS全称Hypertext Transfer Protocol over Secure Socket Layer是以安全为目标的HTTP通道简单讲是HTTP的安全版。即HTTP下加入SSL层HTTPS的安全基础是SSL。其所用的端口号是443。
SSL安全套接层是netscape公司设计的主要用于web的安全传输协议。这种协议在WEB上获得了广泛的应用。通过证书认证来确保客户端和网站服务器之间的通信数据是加密安全的。
有两种基本的加解密算法类型
1对称加密symmetrcic encryption密钥只有一个加密解密为同一个密码且加解密速度快典型的对称加密算法有DES、AESRC53DES等对称加密主要问题是共享秘钥除你的计算机客户端知道另外一台计算机服务器的私钥秘钥否则无法对通信流进行加密解密。解决这个问题的方案非对称秘钥。
2非对称加密使用两个秘钥公共秘钥和私有秘钥。私有秘钥由一方密码保存一般是服务器保存另一方任何人都可以获得公共秘钥。这种密钥成对出现且根据公钥无法推知私钥根据私钥也无法推知公钥加密解密使用不同密钥公钥加密需要私钥解密私钥加密需要公钥解密相对对称加密速度较慢典型的非对称加密算法有RSA、DSA等。
https通信的优点
客户端产生的密钥只有客户端和服务器端能得到
加密的数据只有客户端和服务器端才能得到明文+
客户端到服务端的通信是安全的。
爬虫工作流程
网络爬虫是捜索引擎Baidu、Google、Yahoo抓取系统的重要组成部分。主要目的是将互联网上的网页下载到本地形成一个互联网内容的镜像备份。
网络爬虫的基本工作流程如下
1.首先选取一部分精心挑选的种子URL
2.将这些URL放入待抓取URL队列
3.从待抓取URL队列中取出待抓取在URL解析DNS并且得到主机的ip将URL对应的网页下载下来并存储到已下载网页库中。此外将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL分析其中的其他URL并且将URL放入待抓取URL队列从而进入下一个循环。

import requests #用来爬取网页
from bs4 import BeautifulSoup #用来解析网页
#我们的种子
seds = ["http://www.lagou.com/"]
sum = 0
#我们设定终止条件为爬取到10000个页面时就不玩了
while sum < 10000 :if sum < len(seds):r = requests.get(seds[sum])sum = sum + 1#提取结构化数据做存储操作do_save_action(r)soup = BeautifulSoup(r.content) urls = soup.find_all("href",.....) //解析网页所有的链接for url in urls:seds.append(url)else:break# -*- coding:utf-8 -*-
import os
import requests
from bs4 import BeautifulSoupdef spider():url = "http://bj.grfy.net/"proxies = {"http": "http://172.17.18.80:8080", "https": "https://172.17.18.80:8080"}r = requests.get(url, proxies=proxies)html = r.contentsoup = BeautifulSoup(html, "lxml")divs = soup.find_all("div", class_="content")print len(divs)print soupif __name__ == "__main__":spider()os.system("pause")HTTP代理神器Fidder
Fiddler不但能截获各种浏览器发出的HTTP请求, 也可以截获各种智能手机发出的HTTP/HTTPS请求。 Fiddler能捕获IOS设备发出的请求比如IPhone, IPad, MacBook. 等等苹果的设备。 同理也可以截获AndriodWindows Phone的等设备发出的HTTP/HTTPS。工作原理Fiddler 是以代理web服务器的形式工作的它使用代理地址:127.0.0.1端口:8888。
Fiddler抓取HTTPS设置启动Fiddler打开菜单栏中的 Tools > Fiddler Options打开“Fiddler Options”对话框。
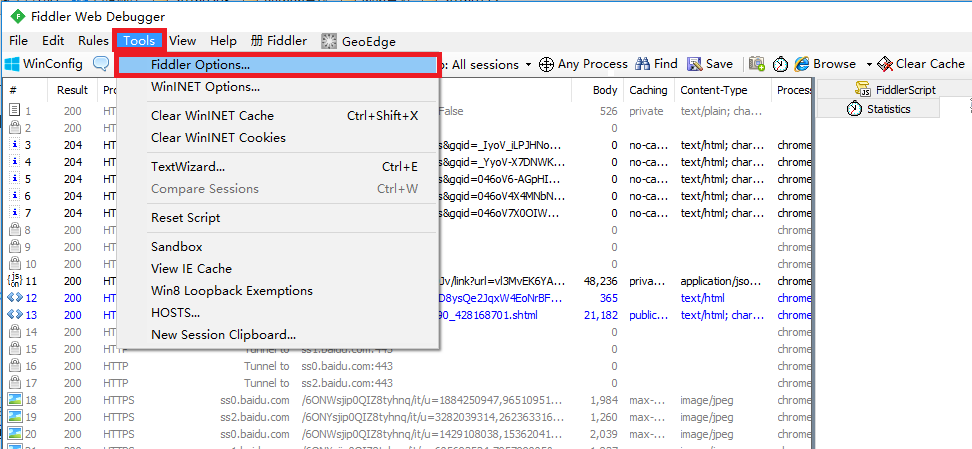
对Fiddler进行设置打开工具栏->Tools->Fiddler Options->HTTPS
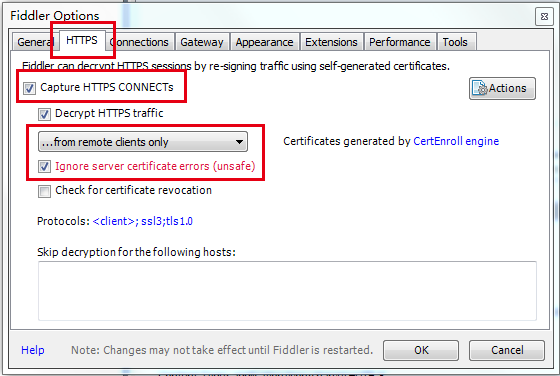
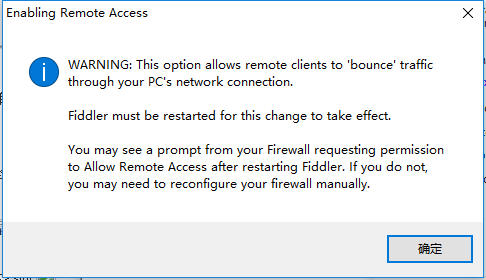
选中Capture HTTPS CONNECTs因为我们要用Fiddler获取手机客户端发出的HTTPS请求所以中间的下拉菜单中选中from remote clients only。选中下方Ignore server certificate errors.

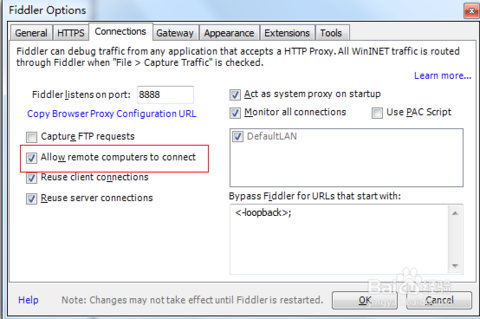
配置Fiddler允许远程连接Fiddler 主菜单 Tools -> Fiddler Options…-> Connections页签选中Allow remote computers to connect。重启Fidler这一步很重要必须做。

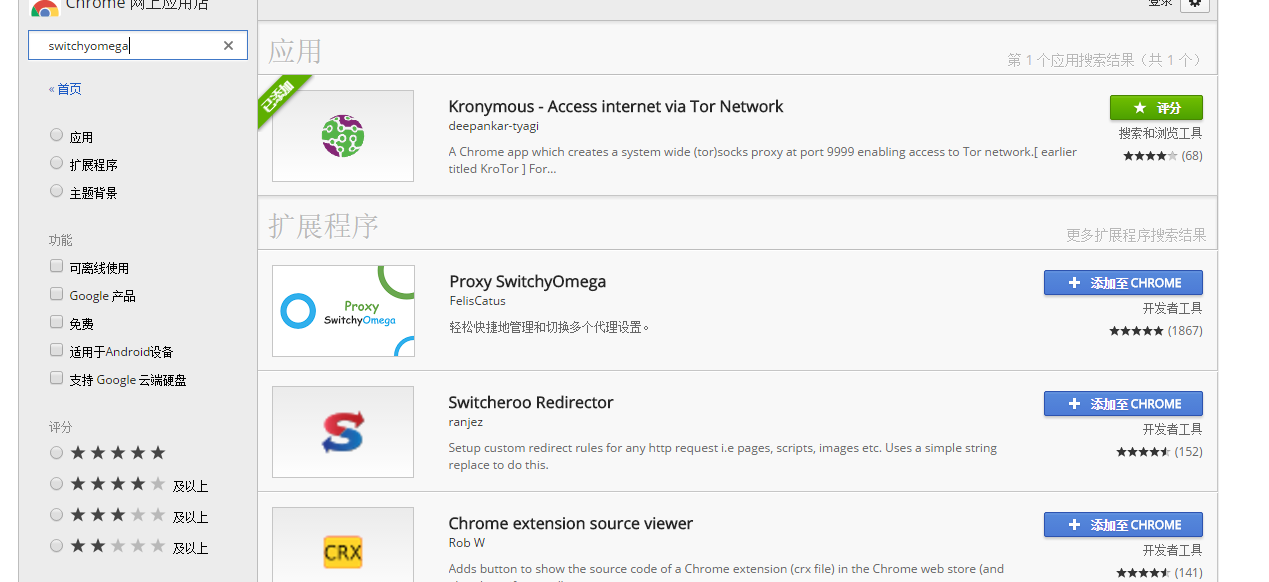
Fiddler 如何捕获Chrome的会话switchyomega安装插件
翻墙工具http://www.ishadowsocks.org/ https://github.com/getlantern/lantern
打开网址https://chrome.google.com/webstore/search/switchyomega?hl=zh-CN
Fiddler 如何捕获Firefox的会话
能支持HTTP代理的任意程序的数据包都能被Fiddler嗅探到Fiddler的运行机制其实就是本机上监听8888端口的HTTP代理。 Fiddler2启动的时候默认IE的代理设为了127.0.0.1:8888而其他浏览器是需要手动设置的所以将Firefox的代理改为127.0.0.1:8888就可以监听数据了。 Firefox 上通过如下步骤设置代理 点击: Tools -> Options, 在Options 对话框上点击Advanced tab - > network tab -> setting.
Fiddler如何捕获HTTPS会话
默认下Fiddler不会捕获HTTPS会话需要你设置下 打开Fiddler Tool->Fiddler Options->HTTPS tab
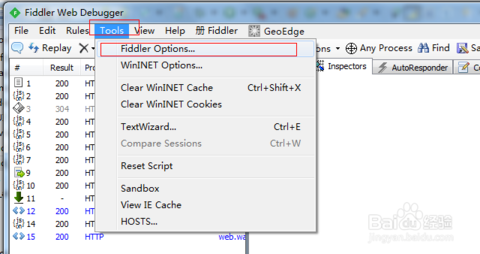
选中checkbox 弹出如下的对话框点击"YES"
点击"Yes" 后就设置好了。
Fiddler的基本界面
特别注意 遇到这个Click请点击Click

Fiddler强大的Script系统
Fiddler包含了一个强大的基于事件脚本的子系统并且能使用.net语言进行扩展。
官方的帮助文档: http://www.fiddler2.com/Fiddler/dev/ScriptSamples.asp
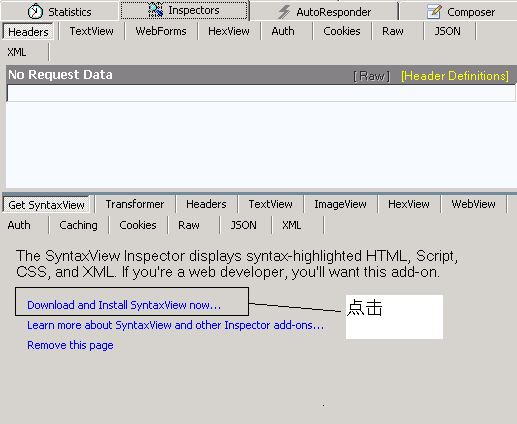
首先先安装SyntaxView插件Inspectors tab->Get SyntaxView tab->Download and Install SyntaxView Now... 如下图
安装成功后Fiddler 就会多了一个Fiddler Script tab如下图
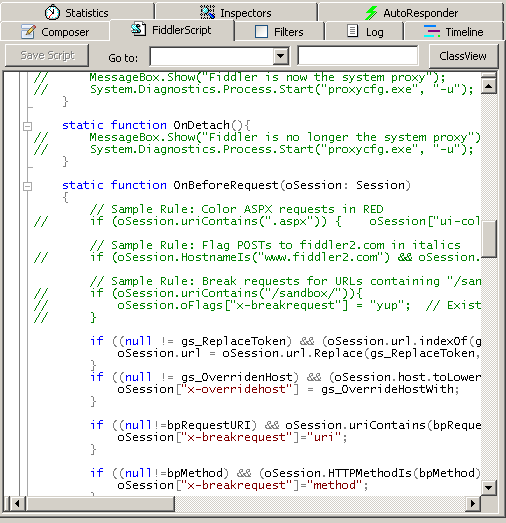
在里面我们就可以编写脚本了 看个实例让所有cnblogs的会话都显示红色。 把这段脚本放在OnBeforeRequest(oSession: Session) 方法下并且点击"Save script"
if (oSession.HostnameIs("www.cnblogs.com")) {oSession["ui-color"] = "red";
}这样所有的cnblogs的会话都会显示红色。
HTTP协议介绍
设计HTTP(HyperText Transfer Protocol)是为了提供一种发布和接收HTML(HyperText Markup Language)页面的方法。
Http两部分组成请求、响应。
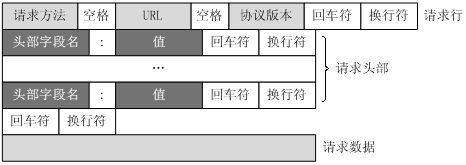
客户端请求消息客户端发送一个HTTP请求到服务器的请求消息包括以下格式请求行request line、请求头部header、空行和请求数据四个部分组成下图给出了请求报文的一般格式。
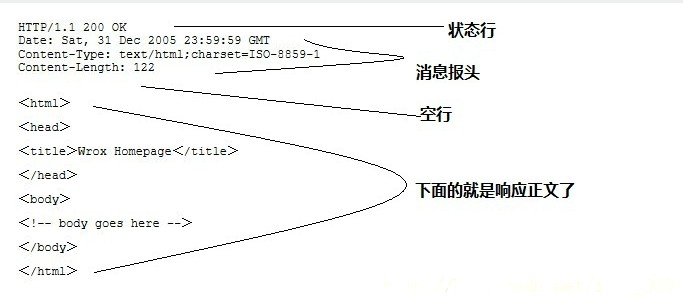
服务器响应消息HTTP响应也由四个部分组成分别是状态行、消息报头、空行和响应正文。
提出一个问题
服务器和客户端的交互仅限于请求/响应过程结束之后便断开 在下一次请求服务器会认为新的客户端;为了维护他们之间的链接让服务器知道这是前一个用户发送的请求必须在一个地方保存客户端的信息Cookie通过在客户端记录信息确定用户身份。 Session通过在服务器端记录信息确定用户身份。
HTTP 请求
请求方法
根据HTTP标准HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法 GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
|
序号 |
方法 |
描述 |
|
1 |
GET |
请求指定的页面信息并返回实体主体。 |
|
2 |
HEAD |
类似于get请求只不过返回的响应中没有具体的内容用于获取报头 |
|
3 |
POST |
向指定资源提交数据进行处理请求例如提交表单或者上传文件。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
|
4 |
PUT |
从客户端向服务器传送的数据取代指定的文档的内容。 |
|
5 |
DELETE |
请求服务器删除指定的页面。 |
|
6 |
CONNECT |
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
|
7 |
OPTIONS |
允许客户端查看服务器的性能。 |
|
8 |
TRACE |
回显服务器收到的请求主要用于测试或诊断。 |
GET和POST方法区别归纳如下几点
1. GET是从服务器上获取数据POST是向服务器传送数据。
2. GET请求参数显示都显示在浏览器网址上,POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送
3. 尽量避免使用Get方式提交表单因为有可能会导致安全问题。 比如说在登陆表单中用Get方式用户输入的用户名和密码将在地址栏中暴露无遗。 但是在分页程序中用Get方式就比用Post好。
URL概述
统一资源定位符URL英语 Uniform / Universal Resource Locator的缩写是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
URL格式基本格式如下 schema://host[:port#]/path/…/[?query-string][#anchor]
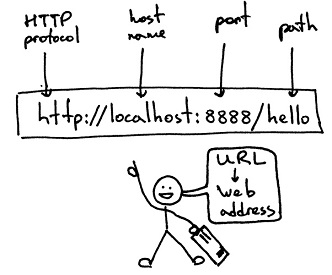
1. schema 协议(例如http, https, ftp)
2. host 服务器的IP地址或者域名
3. port# 服务器的端口如果是走协议默认端口缺省端口80
4. path 访问资源的路径
5. query-string 参数发送给http服务器的数据
6. anchor- 锚跳转到网页的指定锚点位置
例子:
http://www.sina.com.cn/
http://192.168.0.116:8080/index.jsp
http://item.jd.com/11052214.html#product-detail
http://www.website.com/test/test.aspx?name=sv&x=true#stuff
一个URL的请求过程
当你在浏览器输入URL http://www.website.com 的时候浏览器发送一个Request去获取 http://www. website.com的html. 服务器把Response发送回给浏览器. 浏览器分析Response中的 HTML发现其中引用了很多其他文件比如图片CSS文件JS文件。 浏览器会自动再次发送Request去获取图片CSS文件或者JS文件。 当所有的文件都下载成功后 网页就被显示出来了。
常用的请求报头
HostHost初始URL中的主机和端口,用于指定被请求资源的Internet主机和端口号它通常从HTTP URL中提取出来的
Connection表示客户端与服务连接类型
1. client 发起一个包含Connection:keep-alive的请求
2. server收到请求后如果server支持keepalive回复一个包含Connection:keep-alive的响应不关闭连接否则回复一个包含Connection:close的响应关闭连接。
3. 如果client收到包含Connection:keep-alive的响应向同一个连接发送下一个请求直到一方主动关闭连接。 Keep-alive在很多情况下能够重用连接减少资源消耗缩短响应时间HTTP
Accept表示浏览器支持的 MIME 类型
MIME的英文全称是 Multipurpose Internet Mail Extensions多用途互联网邮件扩展
eg
Acceptimage/gif表明客户端希望接受GIF图象格式的资源
Accepttext/html表明客户端希望接受html文本。
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
意思浏览器支持的 MIME 类型分别是 text/html、application/xhtml+xml、application/xml 和 */*优先顺序是它们从左到右的排列顺序。
Text用于标准化地表示的文本信息文本消息可以是多种字符集和或者多种格式的
Application用于传输应用程序数据或者二进制数据设定某种扩展名的文件用一种应用程序来打开的方式类型当该扩展名文件被访问的时候浏览器会自动使用指定应用程序来打开
|
Mime类型 |
扩展名 |
|
text/html |
.htm .html *.shtml |
|
text/plain |
text/html是以html的形式输出比如 |
|
application/xhtml+xml |
.xhtml .xml |
|
text/css |
*.css |
|
application/msexcel |
.xls .xla |
|
application/msword |
.doc .dot |
|
application/octet-stream |
*.exe |
|
application/pdf |
|
|
..... |
..... |
q是权重系数范围 0 =< q <= 1q 值越大请求越倾向于获得其“;”之前的类型表示的内容若没有指定 q 值越大请求越倾向于获得其“则默认为1若被赋值为0则用于提醒服务器哪些是浏览器不接受的内容类型。
Content-TypePOST 提交application/x-www-form-urlencoded 提交的数据按照 key1=val1&key2=val2 的方式进行编码key 和 val 都进行了 URL 转码。
User-Agent 浏览器类型
Referer 请求来自哪个页面用户是从该 Referer URL页面访问当前请求的页面。
Accept-Encoding浏览器支持的压缩编码类型比如gzip,支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间
eg
Accept-Encoding:gzip;q=1.0, identity; q=0.5, *;q=0 // 按顺序支持 gzip , identity
如果有多个Encoding同时匹配, 按照q值顺序排列
如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
Accept-Language浏览器所希望的语言种类当服务器能够提供一种以上的语言版本时要用到。
eg
Accept-Language:zh-cn
如果请求消息中没有设置这个报头域服务器假定客户端对各种语言都可以接受。
Accept-Charset浏览器可接受的字符集,用于指定客户端接受的字符集
eg
Accept-Charset:iso-8859-1,gb2312
ISO8859-1通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符;
gb2312是标准中文字符集;
UTF-8 是 UNICODE 的一种变长字符编码可以解决多种语言文本显示问题从而实现应用国际化和本地化。
如果在请求消息中没有设置这个域缺省是任何字符集都可以接受。
HTTP 响应
掌握常用的响应状态码
服务器上每一个HTTP 应答对象response包含一个数字"状态码"。
有时状态码指出服务器无法完成请求。默认的处理器会为你处理一部分这种应答。
例如:假如response是一个"重定向"需要客户端从别的地址获取文档urllib2将为你处理。
其他不能处理的urlopen会产生一个HTTPError。
典型的错误包含"404"(页面无法找到)"403"(请求禁止)和"401"(带验证请求)。
HTTP状态码表示HTTP协议所返回的响应的状态。
比如客户端向服务器发送请求如果成功地获得请求的资源则返回的状态码为200表示响应成功。
如果请求的资源不存在 则通常返回404错误。
HTTP响应状态码通常分为5种类型分别以15五个数字开头由3位整数组成第一个数字定义了响应的类别
|
分类 |
分类描述 |
|
1** |
信息服务器收到请求需要请求者继续执行操作 |
|
2** |
成功操作被成功接收并处理 |
|
3** |
重定向需要进一步的操作以完成请求 |
|
4** |
客户端错误请求包含语法错误或无法完成请求 |
|
5** |
服务器错误服务器在处理请求的过程中发生了错误 |
最常用的响应状态码
200 (OK): 请求成功找到了该资源并且一切正常。处理方式获得响应的内容进行处理
201 请求完成结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式爬虫中不会遇到
202 请求被接受但处理尚未完成 处理方式阻塞等待
204 服务器端已经实现了请求但是没有返回新的信 息。如果客户是用户代理则无须为此更新自身的文档视图。 处理方式丢弃
300 该状态码不被HTTP/1.0的应用程序直接使用 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式若程序中能够处理则进行进一步处理如果程序中不能处理则丢弃
301 (Moved Permanently): 请求的文档在其他地方新的URL在Location头中给出浏览器应该自动地访问新的URL。处理方式重定向到分配的URL
302 (Found): 类似于301但新的URL应该被视为临时性的替代而不是永久性的。处理方式重定向到临时的URL
304 (NOT MODIFIED): 该资源在上次请求之后没有任何修改。这通常用于浏览器的缓存机制。处理方式丢弃
400 (Bad Request): 请求出现语法错误。非法请求 处理方式丢弃
401 未授权 处理方式丢弃
403 (FORBIDDEN): 客户端未能获得授权。这通常是在401之后输入了不正确的用户名或密码。禁止访问 处理方式丢弃
404 (NOT FOUND): 在指定的位置不存在所申请的资源。没有找到 。 处理方式丢弃
5XX 回应代码以“5”开头的状态码表示服务器端发现自己出现错误不能继续执行请求 处理方式丢弃
500 (Internal Server Error): 服务器遇到了意料不到的情况不能完成客户的请求
503 (Service Unavailable): 服务器由于维护或者负载过重未能应答。
例如Servlet可能在数据库连接池已满的情况下返回503。服务器返回503时可以提供一个Retry-After头
常用的响应报头(了解)
Location表示客户应当到哪里去提取文档,用于重定向接受者到一个新的位置
Server服务器名字包含了服务器用来处理请求的软件信息
eg: Server响应报头域的一个例子
ServerApache-Coyote/1.1
Set-Cookie设置和页面关联的Cookie。
例如前一个 cookie 被存入浏览器并且浏览器试图请求 http://www.ibm.com/foo/index.html 时
Set-Cookiecustomer=huangxp; path=/foo; domain=.ibm.com;
expires= Wednesday, 19-OCT-05 23:12:40 GMT;
Set-Cookie的每个属性解释如下
Customer=huangxp 一个"名称值"对把名称customer设置为值"huangxp"这个属性在Cookie中必须有。
path=/foo 服务器路径。
domain=.ibm.com 指定cookie 的域名。
expires= Wednesday, 19-OCT-05 23:12:40 GMT 指定cookie 失效的时间
使用 Urllib2库
urllib2是python2.7自带的模块(不需要下载),它支持多种网络协议比如 FTP、HTTP、HTTPS等。 urllib2在python3.x中被改为urllib.request
利用urllib2提供了一个接口 urlopen函数
urllib2 官方文档 https://docs.python.org/2/library/urllib2.html
urlopen(url, data, timeout,....)
1第一个参数url即为URL第一个参数URL是必须要传送的
2第二个参数data是访问URL时要传送的数据data默认为空None
3第三个timeout是设置超时时间timeout默认为 60ssocket._GLOBAL_DEFAULT_TIMEOUT
GET请求方式
以传智播客官方网站 http://www.itcast.cn
import urllib2
response = urllib2.urlopen('http://www.itcast.cn/')
data = response.read()
print data
print response.code保存成 demo.py进入该文件的目录执行如下命令查看运行结果 python demo.py
![]()
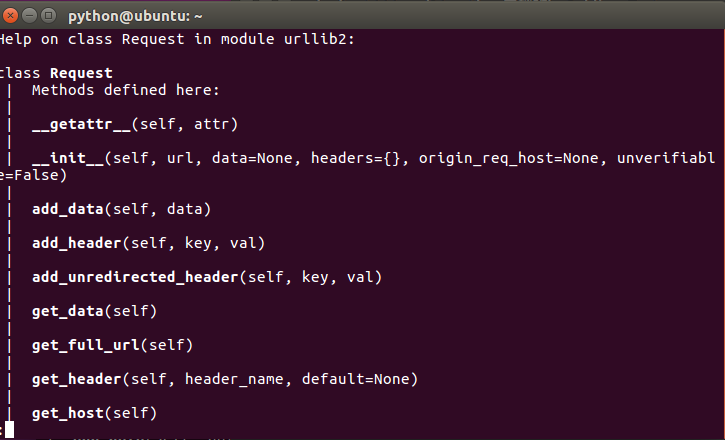
如果我想添加 Header信息怎么办 利用 urllib2.Request类
利用urllib2.Request方法,可以用来构造一个Http请求消息
help(urllib2.Request)
正则headers 转dict
^(.*):\s(.*)$
"\1":"\2",# -*- coding: utf-8 -*-
import urllib2get_headers={'Host': 'www.itcast.cn','Connection': 'keep-alive','Pragma': 'no-cache','Cache-Control': 'no-cache','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',#此处是压缩算法不便于查看要做解压#'Accept-Encoding': 'gzip, deflate, sdch','Accept-Language': 'zh-CN,zh;q=0.8','Cookie': 'pgv_pvi=7044633600; tencentSig=6792114176; IESESSION=alive; pgv_si=s3489918976; CNZZDATA4617777=cnzz_eid%3D768417915-1468987955-%26ntime%3D1470191347; _qdda=3-1.1; _qddab=3-dyl6uh.ireawgo0; _qddamta_800068868=3-0'}
request = urllib2.Request("http://www.itcast.cn/",headers=get_headers)#request.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36')response = urllib2.urlopen(request)
print response.code
data = response.read()
print data提问为什么这两种写法都对
一个headers没写另一个写了都好使 原因是web服务器能够理解请求数据并且没有做验证机制
POST请求方式
抓取拉钩招聘信息http://www.lagou.com/jobs/list_?px=new&city=%E5%85%A8%E5%9B%BD#order
# -*- coding: utf-8 -*-
import urllib2
import urllibproxy_handler = urllib2.ProxyHandler({"http" : 'http://192.168.17.1:8888'})
opener = urllib2.build_opener(proxy_handler)
urllib2.install_opener(opener)Sum = 1
output = open('lagou.json', 'w')
for page in range(1,Sum+1): formdata = 'first=false&pn='+str(page)+'&kd='print '运行到第 (%2d) 页面' %(page)send_headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Accept': 'application/json, text/javascript, */*; q=0.01',' X-Requested-With': 'XMLHttpRequest'}request =urllib2.Request('http://www.lagou.com/jobs/positionAjax.json?px=new&needAddtionalResult=false',headers=send_headers)#request.add_header('X-Requested-With','XMLHttpRequest')#request.headers=send_headersrequest.add_data(formdata)print request.get_data()response = urllib2.urlopen(request)print response.coderesHtml =response.read()#print resHtmloutput.write(resHtml+'\n')
output.close()
print '-'*4 + 'end'+'-'*4![]()
提出一个问题如果要采集的是 拉钩招聘网站 北京>>朝阳区>>望京 以这个网站为例该如何理解这个url
http://www.lagou.com/jobs/list_?px=default&city=%E5%8C%97%E4%BA%AC&district=%E6%9C%9D%E9%98%B3%E5%8C%BA&bizArea=%E6%9C%9B%E4%BA%AC#filterBox
urlencode编码/解码在线工具
# -*- coding: utf-8 -*-
import urllib2
import urllib
query = {'city':'北京','district':'朝阳区','bizArea':'望京'
}
print urllib.urlencode(query)
page =3
values = {'first':'false','pn':str(page),'kd':'后端开发',
}
formdata = urllib.urlencode(values)
print formdata小结
Content-Length 是指报头Header以外的内容长度指 表单数据长度
X-Requested-With: XMLHttpRequest 表示Ajax异步请求
Content-Type: application/x-www-form-urlencoded 表示提交的表单数据 会按照name/value 值对 形式进行编码
例如name1=value1&name2=value2... 。name 和 value 都进行了 URL 编码utf-8、gb2312
在线测试字符串长度
作业
- 常用的请求报头Header、Content-Type、响应报头
- 常用请求方式GET、POST
- gzip、deflate压缩
- 网页编码格式和自动识别
- fidder工具使用
- urllib2、urllib
- HTTP代理
- requests模块
- Beautiful Soup
URL和URI的区别
URL:统一资源定位符uniform resource location;平时上网时在 IE 浏览器中输入的那个地址就是 URL。比如网易 http://www.163.com 就是一个URL 。
URI:统一资源标识符uniform resource identifier。Web 上可用的每种资源 - HTML 文档、图像、视频片段、程序, 由一个通过通用资源标志符 (Universal Resource Identifier, 简称 "URI") 进行定位。
URL是Internet上用来描述信息资源的字符串主要用在各种WWW客户程序和服务器程序上。采用URL可以用一种统一的格式来描述各种信息资源包括文件、服务器的地址和目录等。
URI 是个纯粹的语法结构用于指定标识web资源的字符串的各个不同部分URL 是URI的一个特例它包含定位web资源的足够信息。
URL 是 URI 的一个子集
常见的加密、解密
1) MD5/SHA (单向密散列算法(Hash函数)) MessageDigest是一个数据的数字指纹.即对一个任意长度的数据进行计算,产生一个唯一指纹号. MessageDigest的特性: A) 两个不同的数据,难以生成相同的指纹号 B) 对于指定的指纹号,难以逆向计算出原始数据 代表:MD5/SHA
2) DES、AES、TEA(对称加密算法) 单密钥算法,是信息的发送方采用密钥A进行数据加密,信息的接收方采用同一个密钥A进行数据解密. 单密钥算法是一个对称算法. 缺点:由于采用同一个密钥进行加密解密,在多用户的情况下,密钥保管的安全性是一个问题. 代表:DES
3) RSA(非对称算法) RSA 是一种非对称加解密算法。 RSA is named from the initials of the authors, Ron Rivest, Adi Shamir, and Leonard Adleman,who first published the algorithm.
RSA 与 DSA 都是非对称加密算法。其中RSA的安全性是基于极其困难的大整数的分解两个素数的乘积DSA 的安全性 是基于整数有限域离散对数难题。基本上可以认为相同密钥长度的 RSA 算法与 DSA 算法安全性相当。 公钥用于加密它是向所有人公开的私钥用于解密只有密文的接收者持有。 适用OPENSSL 适用RSA 的命令如下 生成一个密钥(私钥) [root@hunterfu ~]# openssl genrsa -out private.key 1024 注意: 需要注意的是这个文件包含了公钥和密钥两部分也就是说这个文件即可用来加密也可以用来解密,后面的1024是生成 密钥的长度. 通过密钥文件private.key 提取公钥
[root@hunterfu ~]# openssl rsa -in private.key -pubout -out pub.key
使用公钥加密信息
[root@hunterfu ~]# echo -n "123456" | openssl rsautl -encrypt -inkey pub.key -pubin >encode.result
使用私钥解密信息
[root@hunterfu ~]#cat encode.result | openssl rsautl -decrypt -inkey private.key
123456
4) DSA (Digital Signature Algorithm)(数字签名算法)(非对称加密) DSA 一般用于数字签名和认证。 DSA是Schnorr和ElGamal签名算法的变种被美国NIST作为DSS(DigitalSignature Standard)。 DSA是基于整数有限域离散对数难题的其安全性与RSA相比差不多。 在DSA数字签名和认证中发送者使用自己的私钥对文件或消息进行签名接受者收到消息后使用发送者的公钥 来验证签名的真实性。DSA只是一种算法和RSA不同之处在于它不能用作加密和解密也不能进行密钥交换 只用于签名,它比RSA要快很多. 生成一个密钥(私钥)
[root@hunterfu ~]# openssl dsaparam -out dsaparam.pem 1024
[root@hunterfu ~]# openssl gendsa -out privkey.pem dsaparam.pem
生成公钥
[root@hunterfu ~]# openssl dsa -in privkey.pem -out pubkey.pem -pubout
[root@hunterfu ~]# rm -fr dsaparam.pem
# rm -fr == rm -rf == rm -r -f没区别。
使用私钥签名
[root@hunterfu ~]# echo -n "123456" | openssl dgst -dss1 -sign privkey.pem > sign.result
使用公钥验证
[root@hunterfu ~]# echo -n "123456" | openssl dgst -dss1 -verify pubkey.pem -signature sign.result
爬虫入门基础篇
|
数据格式 |
描述 |
设计目标 |
|
XML |
Extensible Markup Language 可扩展标记语言 |
被设计为传输和存储数据其焦点是数据的内容 |
|
HTML |
HyperText Markup Language超文本标记语言 |
显示数据以及如何更好显示数据 |
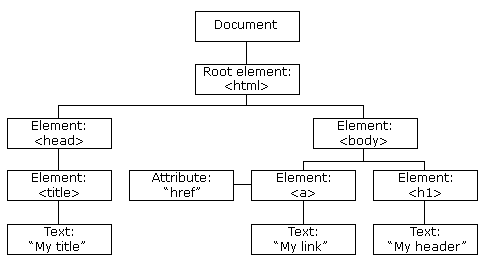
|
HTML DOM |
HTML Document Object Model(文档对象模型) |
通过 JavaScript您可以重构整个HTML文档。您可以添加、移除、改变或重排页面上的项目。要改变页面的某个东西JavaScript就需要对HTML文档中所有元素进行访问的入口。 |
XML 示例
<?xml version="1.0" encoding="utf-8"?>
<bookstore> <book category="cooking"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="children"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="web"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> <book category="web" cover="paperback"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book>
</bookstore>XML DOM 定义访问和操作XML文档的标准方法。 DOM 将 XML 文档作为一个树形结构而树叶被定义为节点。
![]()
HTML DOM 示例
HTML DOM 定义了访问和操作 HTML 文档的标准方法。 DOM 以树结构表达 HTML 文档。
页面解析之数据提取
一般来讲对我们而言需要抓取的是某个网站或者某个应用的内容提取有用的价值内容一般分为两部分非结构化的文本或结构化的文本。
结构化的数据JSON、XML
非结构化的数据HTML文本包含JavaScript代码
HTML文本包含JavaScript代码是最常见的数据格式理应属于结构化的文本组织但因为一般我们需要的关键信息并非直接可以得到需要进行对HTML的解析查找甚至一些字符串操作才能得到所以还是归类于非结构化的数据处理中。
把网页比作一个人那么HTML便是他的骨架JS便是他的肌肉CSS便是它的衣服。
常见解析方式如下XPath、CSS选择器、正则表达式。
一段文本
例如一篇文章或者一句话我们的初衷是提取有效信息所以如果是滞后处理可以直接存储如果是需要实时提取有用信息常见的处理方式如下
分词 根据抓取的网站类型使用不同词库进行基本的分词然后变成词频统计类似于向量的表示词为方向词频为长度。
NLP 自然语言处理进行语义分析用结果表示例如正负面等。
非结构化数据之XPath
XPath 语言XPathXML Path Language是XML路径语言,它是一种用来定位XML文档中某部分位置的语言。
将HTML转换成XML文档之后用XPath查找HTML节点或元素
比如用“/”来作为上下层级间的分隔第一个“/”表示文档的根节点注意不是指文档最外层的tag节点而是指文档本身。
比如对于一个HTML文件来说最外层的节点应该是"/html"。
XPath开发工具开源的XPath表达式编辑工具:XMLQuire(XML格式文件可用)、chrome插件 XPath Helper
![]()
firefox插件 XPath Checker
![]()
XPath语法参考文档http://www.w3school.com.cn/xpath/index.asp
XPath语法
XPath 是一门在 XML 文档中查找信息的语言。
XPath 可用来在 XML 文档中对元素和属性进行遍历。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>选取节点 XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式
|
表达式 |
描述 |
|
/ |
从根节点选取。 |
|
nodename |
选取此节点的所有子节点。 |
|
// |
从当前节点 选择 所有匹配文档中的节点 |
|
. |
选取当前节点。 |
|
.. |
选取当前节点的父节点。 |
|
@ |
选取属性。 |
在下面的表格中我们已列出了一些路径表达式以及表达式的结果
|
路径表达式 |
结果 |
|
/bookstore |
选取根元素 bookstore。注释假如路径起始于正斜杠( / )则此路径始终代表到某元素的绝对路径 |
|
bookstore |
选取 bookstore 元素的所有子节点。默认从根节点选取 |
|
bookstore/book |
选取属于 bookstore 的子元素的所有 book 元素。 |
|
//book |
选取所有 book 子元素而不管它们在文档中的位置。 |
|
//book/./title |
选取所有 book 子元素从当前节点查找title节点 |
|
//price/.. |
选取所有 book 子元素从当前节点查找父节点 |
|
bookstore//book |
选择属于 bookstore 元素的后代的所有 book 元素而不管它们位于 bookstore 之下的什么位置。 |
|
//@lang |
选取名为 lang 的所有属性。 |
谓语条件Predicates
谓语用来查找某个特定的信息或者包含某个指定的值的节点。
所谓"谓语条件"就是对路径表达式的附加条件
谓语是被嵌在方括号中都写在方括号"[]"中表示对节点进行进一步的筛选。
在下面的表格中我们列出了带有谓语的一些路径表达式以及表达式的结果
|
路径表达式 |
结果 |
|
/bookstore/book[1] |
选取属于 bookstore 子元素的第一个 book 元素。 |
|
/bookstore/book[last()] |
选取属于 bookstore 子元素的最后一个 book 元素。 |
|
/bookstore/book[last()-1] |
选取属于 bookstore 子元素的倒数第二个 book 元素。 |
|
/bookstore/book[position()<3] |
选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
|
//title[@lang] |
选取所有拥有名为 lang 的属性的 title 元素。 |
|
//title[@lang=’eng’] |
选取所有 title 元素且这些元素拥有值为 eng 的 lang 属性。 |
|
//book[price] |
选取所有 book 元素且被选中的book元素必须带有price子元素 |
|
/bookstore/book[price>35.00] |
选取 bookstore 元素的所有 book 元素且其中的 price 元素的值须大于 35.00。 |
|
/bookstore/book[price>35.00]/title |
选取 bookstore 元素中的 book 元素的所有 title 元素且其中的 price 元素的值须大于 35.00 |
选取未知节点XPath 通配符可用来选取未知的 XML 元素。
|
通配符 |
描述 |
|
* |
匹配任何元素节点。 |
|
@* |
匹配任何属性节点。 |
在下面的表格中我们列出了一些路径表达式以及这些表达式的结果
|
路径表达式 |
结果 |
|
/bookstore/* |
选取 bookstore 元素的所有子元素。 |
|
//* |
选取文档中的所有元素。 |
|
//title[@*] |
选取所有带有属性的 title 元素。 |
选取若干路径 通过在路径表达式中使用“|”运算符您可以选取若干个路径。
在下面的表格中我们列出了一些路径表达式以及这些表达式的结果
|
路径表达式 |
结果 |
|
//book/title | //book/price |
选取 book 元素的所有 title 和 price 元素。 |
|
//title | //price |
选取文档中的所有 title 和 price 元素。 |
|
/bookstore/book/title | //price |
选取属于 bookstore 元素的 book 元素的所有 title 元素以及文档中所有的 price 元素。 |
XPath 高级用法
模糊查询 contains
目前许多web框架都是动态生成界面的元素id因此在每次操作相同界面时ID都是变化的这样为自动化测试造成了一定的影响。
<div class="eleWrapper" title="请输入用户名">
<input type="text" class="textfield" name="ID9sLJQnkQyLGLhYShhlJ6gPzHLgvhpKpLzp2Tyh4hyb1b4pnvzxFR!-166749344!1357374592067" id="nt1357374592068" />
</div>解决方法 使用xpath的匹配功能//input[contains(@id,'nt')]
测试使用的XML
<Root>
<Person ID="1001" >
<Name lang="zh-cn" >张城斌</Name>
<Email xmlns="www.quicklearn.cn" > cbcye@live.com </Email>
<Blog>http://cbcye.cnblogs.com</Blog>
</Person>
<Person ID="1002" >
<Name lang="en" >Gary Zhang</Name>
<Email xmlns="www.quicklearn.cn" > GaryZhang@cbcye.com</Email>
<Blog>http://www.quicklearn.cn</Blog>
</Person>
</Root>1.查询所有Blog节点值中带有 cn 字符串的Person节点。Xpath表达式/Root//Person[contains(Blog,'cn')]
2.查询所有Blog节点值中带有 cn 字符串并且属性ID值中有01的Person节点。Xpath表达式/Root//Person[contains(Blog,'cn') and contains(@ID,'01')]
学习笔记
1.依靠自己的属性文本定位//td[text()='Data Import']//div[contains(@class,'cux-rightArrowIcon-on')]//a[text()='马上注册']//input[@type='radio' and @value='1'] 多条件//span[@name='bruce'][text()='bruce1'][1] 多条件//span[@id='bruce1' or text()='bruce2'] 找出多个//span[text()='bruce1' and text()='bruce2'] 找出多个
2.依靠父节点定位//div[@class='x-grid-col-name x-grid-cell-inner']/div//div[@id='dynamicGridTestInstanceformclearuxformdiv']/div//div[@id='test']/input
3.依靠子节点定位//div[div[@id='navigation']]//div[div[@name='listType']]//div[p[@name='testname']]
4.混合型//div[div[@name='listType']]//img//td[a//font[contains(text(),'seleleium2从零开始 视屏')]]//input[@type='checkbox']
5.进阶部分//input[@id='123']/following-sibling::input 找下一个兄弟节点//input[@id='123']/preceding-sibling::span 上一个兄弟节点//input[starts-with(@id,'123')] 以什么开头//span[not(contains(text(),'xpath')] 不包含xpath字段的span
6.索引//div/input[2]//div[@id='position']/span[3]//div[@id='position']/span[position()=3]//div[@id='position']/span[position()>3]//div[@id='position']/span[position()<3]//div[@id='position']/span[last()]//div[@id='position']/span[last()-1]
7.substring 截取判断<div data-for="result" id="swfEveryCookieWrap"></div>//*[substring(@id,4,5)='Every']/@id 截取该属性 定位3,取长度5的字符 //*[substring(@id,4)='EveryCookieWrap'] 截取该属性从定位3 到最后的字符 //*[substring-before(@id,'C')='swfEvery']/@id 属性 'C'之前的字符匹配//*[substring-after(@id,'C')='ookieWrap']/@id 属性'C之后的字符匹配
8.通配符*//span[@*='bruce']//*[@name='bruce']
9.轴//div[span[text()='+++current node']]/parent::div 找父节点//div[span[text()='+++current node']]/ancestor::div 找祖先节点
10.孙子节点//div[span[text()='current note']]/descendant::div/span[text()='123']//div[span[text()='current note']]//div/span[text()='123'] 两个表达的意思一样
11.following pre
https://www.baidu.com/s?wd=xpath&pn=10&oq=xpath&ie=utf-8&rsv_idx=1&rsv_pq=df0399f30003691c&rsv_t=7dccXo734hMJVeb6AVGfA3434tA9U%2FXQST0DrOW%2BM8GijQ8m5rVN2R4J3gU//span[@class="fk fk_cur"]/../following::a 往下的所有a//span[@class="fk fk_cur"]/../preceding::a[1] 往上的所有axpath提取多个标签下的text在写爬虫的时候经常会使用xpath进行数据的提取对于如下的代码
<div id="test1">大家好</div>
使用xpath提取是非常方便的。假设网页的源代码在selector中
data = selector.xpath('//div[@id="test1"]/text()').extract()[0]
就可以把“大家好”提取到data变量中去。
然而如果遇到下面这段代码呢
<div id="test2">美女<font color=red>你的微信是多少</font><div>
如果使用
data = selector.xpath('//div[@id="test2"]/text()').extract()[0]
只能提取到“美女”
如果使用
data = selector.xpath('//div[@id="test2"]/font/text()').extract()[0]
又只能提取到“你的微信是多少”
可是我本意是想把“美女你的微信是多少”这一整个句子提取出来。
<div id="test3">我左青龙<span id="tiger">右白虎<ul>上朱雀<li>下玄武。</li></ul>老牛在当中</span>龙头在胸口。<div>
而且内部的标签还不固定如果我有一百段这样类似的html代码又如何使用xpath表达式以最快最方便的方式提取出来
使用xpath的string(.)
以第三段代码为例
data = selector.xpath('//div[@id="test3"]')
info = data.xpath('string(.)').extract()[0]
这样就可以把“我左青龙右白虎上朱雀下玄武。老牛在当中龙头在胸口”整个句子提取出来赋值给info变量。非结构化数据之lxml库
lxml 是一种使用 Python 编写的库,可以迅速、灵活地处理 XML 支持 XPath (XML Path Language)
lxml python 官方文档 http://lxml.de/index.html
学习目的利用上节课学习的XPath语法来快速的定位 特定元素以及节点信息目的是 提取出 HTML、XML 目标数据
如何安装
Ubuntu :
sudo apt-get install libxml2-dev libxslt1-dev python-dev
sudo apt-get install zlib1g-dev
sudo apt-get install libevent-dev
sudo pip install lxml //利用 pip 安装即可
Windows:
http://blog.csdn.net/g1apassz/article/details/46574963
http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
初步使用
首先我们利用lxml来解析 HTML 代码先来一个小例子来感受一下它的基本用法。
使用 lxml 的 etree 库然后利用 etree.HTML 初始化然后我们将其打印出来。
from lxml import etree
text = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul>
</div>
'''
#Parses an HTML document from a string
html = etree.HTML(text)
#Serialize an element to an encoded string representation of its XML tree
result = etree.tostring(html)
print result所以输出结果是这样的
<html><body><div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul>
</div>
</body></html>不仅补全了 li 标签还添加了 bodyhtml 标签。
XPath实例测试
1获取所有的 <li> 标签
print type(html)
result = html.xpath('//li')
print result
print len(result)
print type(result)
print type(result[0])
运行结果
<type 'lxml.etree._ElementTree'>
[<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>]
5
<type 'list'>
<type 'lxml.etree._Element'>
可见每个元素都是 Element 类型;是一个个的标签元素类似现在的实例
<Element li at 0x1014e0e18> Element类型代表的就是
<li class="item-0"><a href="link1.html">first item</a></li>
注意
Element类型是一种灵活的容器对象用于在内存中存储结构化数据。
每个element对象都具有以下属性
1. tagstring对象标签用于标识该元素表示哪种数据即元素类型。
2. attribdictionary对象表示附有的属性。
3. textstring对象表示element的内容。
4. tailstring对象表示element闭合之后的尾迹。
实例
<tag attrib1=1>text</tag>tail
1 2 3 4
result[0].tag
result[0].text
result[0].tail
result[0].attrib
2获取 <li> 标签的所有 class
html.xpath('//li/@class')
运行结果:['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
3获取 <li> 标签下属性 href 为 link1.html 的 <a> 标签
html.xpath('//li/a[@href="link1.html"]')
运行结果:[<Element a at 0x10ffaae18>]
4获取 <li> 标签下的所有 <span> 标签
注意这么写是不对的
html.xpath('//li/span')
因为 / 是用来获取子元素的而 <span> 并不是 <li> 的子元素所以要用双斜杠
html.xpath('//li//span')
运行结果:[<Element span at 0x10d698e18>]
5获取 <li> 标签下的所有 class不包括 <li>
html.xpath('//li/a//@class')
运行结果:['blod']
6获取最后一个 <li> 的<a> 的 href
html.xpath('//li[last()]/a/@href')
运行结果:['link5.html']
7获取 class 为 bold 的标签名
result = html.xpath('//*[@class="bold"]')
print result[0].tag
运行结果:span
实战项目
以腾讯招聘网站为例http://hr.tencent.com/position.php?&start=10
from lxml import etree
import urllib2
import urllib
import jsonrequest = urllib2.Request('http://hr.tencent.com/position.php?&start=10#a')
response =urllib2.urlopen(request)
resHtml = response.read()
output =open('tencent.json','w')html = etree.HTML(resHtml)
result = html.xpath('//tr[@class="odd"] | //tr[@class="even"]')for site in result:item={}name = site.xpath('./td[1]/a')[0].textdetailLink = site.xpath('./td[1]/a')[0].attrib['href']catalog = site.xpath('./td[2]')[0].textrecruitNumber = site.xpath('./td[3]')[0].textworkLocation = site.xpath('./td[4]')[0].textpublishTime = site.xpath('./td[5]')[0].textprint type(name)print name,detailLink,catalog,recruitNumber,workLocation,publishTimeitem['name']=nameitem['detailLink']=detailLinkitem['catalog']=catalogitem['recruitNumber']=recruitNumberitem['publishTime']=publishTimeline = json.dumps(item,ensure_ascii=False) + '\n'print lineoutput.write(line.encode('utf-8'))
output.close()1练习一下lxml、etree、xpath的整个的操作
2试试上节课XPath的语法以及Html自己动手实践
非结构化数据之CSS SelectorCSS 选择器
CSS(即层叠样式表Cascading Stylesheet) Selector来定位locate页面上的元素Elements。Selenium官网的Document里极力推荐使用CSS locator而不是XPath来定位元素原因是CSS locator比XPath locator速度快.
Beautiful Soup
支持从HTML或XML文件中提取数据的Python库。支持Python标准库中的HTML解析器。还支持一些第三方的解析器lxml, 使用的是 Xpath 语法推荐安装。
Beautiful Soup自动将输入文档转换为Unicode编码输出文档转换为utf-8编码。你不需要考虑编码方式除非文档没有指定一个编码方式这时Beautiful Soup就不能自动识别编码方式了。然后你仅仅需要说明一下原始编码方式就可以了
Beautiful Soup4 安装
官方文档链接: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
可以利用 pip来安装pip install beautifulsoup4
安装解析器(上节课已经安装过)
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml:
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib: pip install html5lib
下表列出了主要的解析器
|
解析器 |
使用方法 |
优势 |
劣势 |
|
Python标准库 |
BeautifulSoup(markup, "html.parser") |
Python的内置标准库;执行速度适中;文档容错能力强 |
Python 2.7.3 or 3.2.2前 的版本中文档容错能力差 |
|
lxml HTML 解析器 |
BeautifulSoup(markup, "lxml") |
速度快;文档容错能力强 ; |
需要安装C语言库 |
|
lxml XML 解析器 |
BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") |
速度快;唯一支持XML的解析器 |
需要安装C语言库 |
|
html5lib |
BeautifulSoup(markup, "html5lib") |
最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档 |
速度慢;不依赖外部扩展 |
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>
"""使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,'lxml')下面我们来打印一下 soup 对象的内容
print soup![]()
格式化输出soup 对象
print(soup.prettify())![]()
CSS选择器
在写 CSS 时标签名不加任何修饰。类名前加点。id名前加“#”。
利用类似的方法来筛选元素用到的方法是 soup.select()返回类型是 list
通过标签名查找
print soup.select('title')
#[<title>The Dormouse's story</title>]print soup.select('a')
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]print soup.select('b')
#[<b>The Dormouse's story</b>]通过类名查找
print soup.select('.sister')
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]通过 id 名查找
print soup.select('#link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>]直接子标签查找
print soup.select("head > title")
#[<title>The Dormouse's story</title>]组合查找
组合查找即标签名与类名、id名进行的组合原理是一样的例如查找 p 标签中id 等于 link1的内容
属性 和 标签 不属于 同一节点 二者需要用 空格分开
print soup.select('p #link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>]属性查找
查找时还可以加入属性元素属性需要用中括号括起来
注意属性和标签属于同一节点所以中间不能加空格否则会无法匹配到
print soup.select('a[class="sister"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]print soup.select('a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>]同样属性仍然可以与上述查找方式组合。不在同一节点的使用空格隔开在同一节点的则不用加空格
print soup.select('p a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"></a>]以上的 select 方法返回的结果都是列表形式可以遍历形式输出
用 get_text() 方法来获取它的内容。
print soup.select('title')[0].get_text()
for title in soup.select('title'):print title.get_text()Tag
Tag 是什么通俗点讲就是 HTML 中的一个个标签例如
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>print type(soup.select('a')[0])输出
bs4.element.Tag对于 Tag它有两个重要的属性是 name 和 attrs下面我们分别来感受一下
1. name
print soup.name
print soup.select('a')[0].name
输出
[document]
'a'
soup 对象本身比较特殊它的 name 即为 [document]对于其他内部标签输出的值便为标签本身的名称。
2. attrs
print soup.select('a')[0].attrs
输出
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
在这里我们把 soup.select('a')[0] 标签的所有属性打印输出了出来得到的类型是一个字典。
如果我们想要单独获取某个属性可以这样例如我们获取它的 class 叫什么
print soup.select('a')[0].attrs['class']
输出
['sister']实战案例
我们还是以 腾讯招聘网站http://hr.tencent.com/position.php?&start=10#a
from bs4 import BeautifulSoup
import urllib2
import urllib
import jsonrequest = urllib2.Request('http://hr.tencent.com/position.php?&start=10#a')
response =urllib2.urlopen(request)
resHtml = response.read()
output =open('tencent.json','w')html = BeautifulSoup(resHtml,'lxml')
result = html.select('tr[class="even"]')
result2 = html.select('tr[class="odd"]')
result+=result2
print len(result)for site in result:item={}name = site.select('td a')[0].get_text()detailLink = site.select('td a')[0].attrs['href']catalog = site.select('td')[1].get_text()recruitNumber = site.select('td')[2].get_text()workLocation = site.select('td')[3].get_text()publishTime = site.select('td')[4].get_text()item['name']=nameitem['detailLink']=detailLinkitem['catalog']=catalogitem['recruitNumber']=recruitNumberitem['publishTime']=publishTimeline = json.dumps(item,ensure_ascii=False)print lineoutput.write(line.encode('utf-8'))output.close()正则表达式
掌握了XPath、CSS选择器为什么还要学习正则
正则表达式用标准正则解析一般会把HTML当做普通文本用指定格式匹配当相关文本适合小片段文本或者某一串字符(比如电话号码、邮箱账户)或者HTML包含javascript的代码无法用CSS选择器或者XPath
在线正则表达式测试网站 官方文档
正则表达式常见概念
边界匹配
^ -- 与字符串开始的地方匹配不匹配任何字符
$ -- 与字符串结束的地方匹配不匹配任何字符
str = "cat abdcatdetf ios"^cat : 验证该行以c开头紧接着是a然后是tios$ : 验证该行以t结尾倒数第二个字符为a倒数第三个字符为c^cat$: 以c开头接着是a->t然后是行结束只有cat三个字母的数据行^$ : 开头之后马上结束空白行不包括任何字符^ : 行的开头可以匹配任何行因为每个行都有行开头\b -- 匹配一个单词边界也就是单词和空格之间的位置不匹配任何字符
"er\b"可以匹配"never"中的"er"但不能匹配"verb"中的"er"。\B -- \b取非即匹配一个非单词边界
"er\B"能匹配"verb"中的"er"但不能匹配"never"中的"er"。数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的在少数语言里也可能是默认非贪婪总是尝试匹配尽可能多的字符非贪婪的则相反总是尝试匹配尽可能少的字符。例如
正则表达式"ab*"如果用于查找"abbbc"将找到"abbb"。而如果使用非贪婪的数量词"ab*?"将找到"a"。反斜杠问题
与大多数编程语言相同正则表达式里使用"\"作为转义字符这就可能造成反斜杠困扰。
假如你需要匹配文本中的字符"\"那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\"前两个和后两个分别用于在编程语言里转义成反斜杠转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题这个例子中的正则表达式可以使用r"\\"表示。
同样匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串你再也不用担心是不是漏写了反斜杠写出来的表达式也更直观。
import re
a=re.search(r"\\","ab123bb\c")
print a.group()
\
a=re.search(r"\d","ab123bb\c")
print a.group()
1Python Re模块
Python 自带了re模块它提供了对正则表达式的支持。
match函数re.match 尝试从字符串的起始位置匹配一个模式如果不是起始位置匹配成功的话match()就返回none。
下面是此函数的语法re.match(pattern, string, flags=0)
|
参数 |
描述 |
|
pattern |
这是正则表达式来进行匹配。 |
|
string |
这是字符串这将被搜索匹配的模式在字符串的开头。 |
|
flags |
标志位用于控制正则表达式的匹配方式如是否区分大小写多行匹配等等。 |
匹配成功re.match方法返回一个匹配的对象否则返回None。 我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
|
匹配对象的方法 |
描述 |
|
group(num=0) |
此方法返回整个匹配或指定分组num |
|
groups() |
此方法返回所有元组匹配的子组空如果没有 |
#!/usr/bin/python
import reline = "Cats are smarter than dogs"matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)if matchObj:print "matchObj.group() : ", matchObj.group()print "matchObj.group(1) : ", matchObj.group(1)print "matchObj.group(2) : ", matchObj.group(2)
else:print "No match!!"当执行上面的代码它产生以下结果
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter正则表达式修饰符 - 选项标志
正则表达式字面可以包含一个可选的修饰符来控制匹配的各个方面。修饰符被指定为一个可选的标志。可以使用异或提供多个修饰符|如先前所示并且可以由这些中的一个来表示
|
修饰符 |
描述 |
|
re.I(re.IGNORECASE) |
使匹配对大小写不敏感 |
|
re.M(MULTILINE) |
多行匹配影响 ^ 和 $ |
|
re.S(DOTALL) |
使 . 匹配包括换行在内的所有字符 |
|
re.X(VERBOSE) |
正则表达式可以是多行忽略空白字符并可以加入注释 |
findall()函数
re.findall(pattern, string, flags=0)
返回字符串中所有模式的非重叠的匹配作为字符串列表。该字符串扫描左到右并匹配返回的顺序发现
默认pattren = "\w+"target = "hello world\nWORLD HELLO"re.findall(pattren,target)['hello', 'world', 'WORLD', 'HELLO']re.I: re.findall("world", target,re.I)['world', 'WORLD']re.S: re.findall("world.WORLD", target,re.S)["world\nworld"]re.findall("hello.*WORLD", target,re.S)['hello world\nWORLD']re.M:re.findall("^WORLD",target,re.M)["WORLD"]re.X:reStr = '''\d{3} #区号-\d{8}''' #号码re.findall(reStr,"010-12345678",re.X) ["010-12345678"]search函数
re.search 扫描整个字符串并返回第一个成功的匹配。
下面是此函数语法re.search(pattern, string, flags=0)
|
参数 |
描述 |
|
pattern |
这是正则表达式来进行匹配。 |
|
string |
这是字符串这将被搜索到的字符串中的任何位置匹配的模式。 |
|
flags |
标志位用于控制正则表达式的匹配方式如是否区分大小写多行匹配等等。 |
匹配成功re.search方法返回一个匹配的对象否则返回None。我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
#!/usr/bin/python
import reline = "Cats are smarter than dogs";searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)if searchObj:print "searchObj.group() : ", searchObj.group()print "searchObj.group(1) : ", searchObj.group(1)print "searchObj.group(2) : ", searchObj.group(2)
else:print "Nothing found!!"当执行上面的代码它产生以下结果
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarterre.match与re.search的区别
re.match只匹配字符串的开始如果字符串开始不符合正则表达式则匹配失败函数返回None而re.search匹配整个字符串直到找到一个匹配。
#!/usr/bin/python
import reline = "Cats are smarter than dogs";matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:print "match --> matchObj.group() : ", matchObj.group()
else:print "No match!!"searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:print "search --> searchObj.group() : ", searchObj.group()
else:print "Nothing found!!"当执行上面的代码产生以下结果
No match!!
search --> matchObj.group() : dogs搜索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法re.sub(pattern, repl, string, max=0)
返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现字符将被没有改变地返回。 可选参数 count 是模式匹配后替换的最大次数count 必须是非负整数。缺省值是 0 表示替换所有的匹配。 实例
#!/usr/bin/python
import reurl = "http://hr.tencent.com/position.php?&start=10"
page = re.search('start=(\d+)',url).group(1)nexturl = re.sub(r'start=(\d+)', 'start='+str(int(page)+10), url)
print "Next Url : ", nexturl当执行上面的代码产生以下结果
Next Url : http://hr.tencent.com/position.php?&start=20正则表达式语法
![]()
页面解析之结构化数据
结构化的数据是最好处理一般都是类似JSON格式的字符串直接解析JSON数据提取JSON的关键字段即可。
JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式适用于进行数据交互的场景比如网站前台与后台之间的数据交互。
Python 2.7中自带了JSON模块直接import json就可以使用了。
Json模块提供了四个功能dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换
Python操作json的标准api库参考 在线JSON格式化代码
1. json.loads()
实现json字符串 转化 python的类型返回一个python的类型
从json到python的类型转化对照如下
![]()
import jsona="[1,2,3,4]"
b='{"k1":1,"k2":2}'#当字符串为字典时{}外面必须是''单引号{}里面必须是""双引号
print json.loads(a)
[1, 2, 3, 4]print json.loads(b)
{'k2': 2, 'k1': 1}import urllib2
import jsonresponse = urllib2.urlopen(r'http://api.douban.com/v2/book/isbn/9787218087351')hjson = json.loads(response.read())print hjson.keys()
print hjson['rating']
print hjson['images']['large']
print hjson['summary']2. json.dumps()
实现python类型转化为json字符串返回一个str对象
从python原始类型向json类型的转化对照如下
![]()
import json
a = [1,2,3,4]
b ={"k1":1,"k2":2}
c = (1,2,3,4)json.dumps(a)
'[1, 2, 3, 4]'json.dumps(b)
'{"k2": 2, "k1": 1}'json.dumps(c)
'[1, 2, 3, 4]'json.dumps 中的ensure_ascii 参数引起的中文编码问题
如果Python Dict字典含有中文json.dumps 序列化时对中文默认使用的ascii编码
import chardet
import jsonb = {"name":"中国"}json.dumps(b)
'{"name": "\\u4e2d\\u56fd"}'print json.dumps(b)
{"name": "\u4e2d\u56fd"}chardet.detect(json.dumps(b))
{'confidence': 1.0, 'encoding': 'ascii'}'中国' 中的ascii 字符码而不是真正的中文。想输出真正的中文需要指定ensure_ascii=False
json.dumps(b,ensure_ascii=False)
'{"name": "\xe6\x88\x91"}'print json.dumps(b,ensure_ascii=False)
{"name": "我"}chardet.detect(json.dumps(b,ensure_ascii=False))
{'confidence': 0.7525, 'encoding': 'utf-8'}3. json.dump()
把Python类型 以 字符串的形式 写到文件中
import json
a = [1,2,3,4]
json.dump(a,open("digital.json","w"))
b = {"name":"我"}
json.dump(b,open("name.json","w"),ensure_ascii=False)
json.dump(b,open("name2.json","w"),ensure_ascii=True)4. json.load()
读取 文件中json形式的字符串元素 转化成python类型
# -*- coding: utf-8 -*-
import json
number = json.load(open("digital.json"))
print number
b = json.load(open("name.json"))
print b
b.keys()
print b['name']实战项目
获取 lagou 城市表信息
import urllib2
import json
import chardeturl ='http://www.lagou.com/lbs/getAllCitySearchLabels.json?'
request =urllib2.Request(url)
response = urllib2.urlopen(request)
print response.code
resHtml = response.read()
jsonobj = json.loads(resHtml)
print type(jsonobj)
print jsonobjcitylist =[]allcitys = jsonobj['content']['data']['allCitySearchLabels']print allcitys.keys()for key in allcitys:print type(allcitys[key])for item in allcitys[key]:name =item['name'].encode('utf-8')print name,type(name)citylist.append(name)fp = open('city.json','w')content = json.dumps(citylist,ensure_ascii=False)
print contentfp.write(content)
fp.close()输出
![]()
JSONPath
JSON 信息抽取类库从JSON文档中抽取指定信息的工具
JSONPath与Xpath区别
JsonPath 对于 JSON 来说相当于 XPATH 对于XML。
下载地址https://pypi.python.org/pypi/jsonpath/
安装方法下载jsonpath解压之后执行'python setup.py install'
参考文档
|
XPath |
JSONPath |
Result |
|
|
|
the authors of all books in the store |
|
|
|
all authors |
|
|
|
all things in store, which are some books and a red bicycle. |
|
|
|
the price of everything in the store. |
|
|
|
the third book |
|
|
|
the last book in order. |
|
|
|
the first two books |
|
|
|
filter all books with isbn number |
|
|
|
filter all books cheapier than 10 |
|
|
|
all Elements in XML document. All members of JSON structure. |
案例
还是以 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例获取所有城市
import jsonpath
import urllib2
import chardet
url ='http://www.lagou.com/lbs/getAllCitySearchLabels.json'
request =urllib2.Request(url)
response = urllib2.urlopen(request)
print response.code
resHtml = response.read()##detect charset
print chardet.detect(resHtml)jsonobj = json.loads(resHtml)
citylist = jsonpath.jsonpath(jsonobj,'$..name')print citylist
print type(citylist)
fp = open('city.json','w')content = json.dumps(citylist,ensure_ascii=False)
print contentfp.write(content.encode('utf-8'))
fp.close()XML
xmltodict模块让使用XML感觉跟操作JSON一样
Python操作XML的第三方库参考https://github.com/martinblech/xmltodict
模块安装pip install xmltodict
import xmltodictbookdict = xmltodict.parse("""<bookstore><book><title lang="eng">Harry Potter</title><price>29.99</price></book><book><title lang="eng">Learning XML</title><price>39.95</price></book></bookstore>""")print bookdict.keys()
[u'bookstore']
print json.dumps(bookdict,indent=4)输出结果
{"bookstore": {"book": [{"title": {"@lang": "eng", "#text": "Harry Potter"}, "price": "29.99"}, {"title": {"@lang": "eng", "#text": "Learning XML"}, "price": "39.95"}]}
}数据提取总结
HTML、XML
XPathCSS选择器正则表达式JSON
JSONPath转化成Python类型进行操作json类XML
转化成Python类型xmltodictXPathCSS选择器正则表达式其他js、文本、电话号码、邮箱地址
正则表达式- 精通网页抓取原理及技术精通正则表达式从结构化的和非结构化的数据中获取信息
- XPATH、CSS选择器、正则表达式
- 了解各种Web前端技术包括XHTML/XML/CSS/JavaScript/AJAX等
- 对目标网站进行爬取分析找到最优化的爬取策略。
json.loads的时候出错->要注意要解码的Json字符的编码
![]()
1. 如果传入的字符串的编码是基于ASCII的而不是UTF-8的话需要指定字符编码参数cencoding
对于dataDict = json.loads(dataJsonStr); 其中dataJsonStr是json字符串如果其编码本身是非UTF-8的话比如是GB2312的那么上述代码就会导致出错。改为对应的
dataDict = json.loads(dataJsonStr, encoding="GB2312");
2. 如果要解析的字符串本身的编码类型不是基于ASCII的那么调用json.loads之前需要先将对应字符串转换为Unicode类型的 还是以上述的
dataDict = json.loads(dataJsonStr, encoding="GB2312");为例即使你此处的字符串dataJsonStr已经通过encoding指定了合适的编码但是由于其中包含了其他的编码的字符比如我本身dataJsonStr是GB2312的字符但是其中又包含了的一些日文字符此时json.loads还是会出错因为此处的dataJsonStr不是以ASCII为基础的字符编码所以需要先去将dataJsonStr转换为Unicode然后再调用json.loads就可以了。
代码如下
dataJsonStrUni = dataJsonStr.decode("GB2312");
dataDict = json.loads(dataJsonStrUni, encoding="GB2312");
encode和decode区别
decode的作用是将其他编码的字符串转换成unicode编码。如str1.decode('gb2312')表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串。如str2.encode('gb2312')表示将unicode编码的字符串str2转换成gb2312编码。
爬虫实践篇
培养解决问题的思路、编码解码的理解
解决问题的思路
如何判断需求数据在哪
A) 静态数据可通过查看网页源代码
B) 定位具体哪一个url请求抓包在Fidder里面找怎么快速定位我要的数据呢(通过Body大小除了图片之外的Http请求)
判断是什么请求方式Get还是Post
在Composer raw 模拟发送数据
A) 删除Header信息为什么删除代码简介美观、易于理解
B) 如果做翻页最好拿第二三页做测试不要用首页因为有时候第二页是Post请求而第一是静态Get请求拿第二页测试的时候返回的是第一页容易错误还不自知
参考案例Get、Post案例
写python程序
确认返回数据是什么格式的返回json还是html
A) 那如果是json呢格式化数据应该做存储 B) 那如果是html呢提取数据使用XPath、CSS选择器、正则表达式
Get和Post
1. 右键查看源代码和 F12 Elements区别 右键查看源代码实质是一个Get请求 F12 Elements是整个页面 所有的请求url 加载完成的页面
2. GET 和Post区别的方法 为什么拉钩用的Post不是表单提交密码原因是Post用户体验更好局部加载
Urlencode
urlencode()函数原理就是首先把中文字符转换为十六进制然后在每个字符前面加一个标识符%
http://www.lagou.com/jobs/list_Python?px=default&city=%E5%8C%97%E4%BA%AC&district=%E6%9C%9D%E9%98%B3%E5%8C%BA&bizArea=%E6%9C%9B%E4%BA%AC#filterBox
![]()
提出个问题中文字符按什么编码格式进行转化成十六进制呢 utf-8、gb2312、gbk urlencode编码
utf-8与utf-8 urlencode区别
import urllib
country = u'中国'
country.encode('utf-8')
'\xe4\xb8\xad\xe5\x9b\xbd'
urllib.quote(country.encode('utf-8'))
'%E4%B8%AD%E5%9B%BD'gb2312与gb2312 urlencode区别
import urllib
country = u'中国'
country.encode('gb2312')
'\xd6\xd0\xb9\xfa'
urllib.quote(country.encode('gb2312'))
'%D6%D0%B9%FA'案例
模拟出 拉勾网 如下url地址
http://www.lagou.com/jobs/list_Python?px=default&city=%E5%8C%97%E4%BA%AC&district=%E6%9C%9D%E9%98%B3%E5%8C%BA&bizArea=%E6%9C%9B%E4%BA%AC#filterBox
# -*- coding: utf-8 -*-
import urllib
import chardetcity=u'北京'.encode('utf-8')
district=u'朝阳区'.encode('utf-8')
bizArea=u'望京'.encode('utf-8')query={'city':city,'district':district,'bizArea':bizArea
}print chardet.detect(query['city'])
{'confidence': 0.7525, 'encoding': 'utf-8'}print urllib.urlencode(query)
city=%E5%8C%97%E4%BA%AC&bizArea=%E6%9C%9B%E4%BA%AC&district=%E6%9C%9B%E4%BA%ACprint 'http://www.lagou.com/jobs/list_Python?px=default&'+urllib.urlencode(query)+'#filterBox'
http://www.lagou.com/jobs/list_Python?px=default&city=%E5%8C%97%E4%BA%AC&bizArea=%E6%9C%9B%E4%BA%AC&district=%E6%9C%9B%E4%BA%AC#filterBox模拟出 阿里巴巴 如下url地址
https://s.1688.com/selloffer/offer_search.htm?keywords=%CA%D6%BB%FA%BC%B0%C5%E4%BC%FE%CA%D0%B3%A1
![]()
# -*- coding: utf-8 -*-
import urllib
import chardetkeywords=u'手机及配件市场'.encode('gbk')query={'keywords':keywords,
}
print chardet.detect(query['keywords'])
{'confidence': 0.99, 'encoding': 'GB2312'}
print urllib.urlencode(query)
keywords=%CA%D6%BB%FA%BC%B0%C5%E4%BC%FE%CA%D0%B3%A1print 'https://s.1688.com/selloffer/offer_search.htm?'+urllib.urlencode(query)
https://s.1688.com/selloffer/offer_search.htm?keywords=%CA%D6%BB%FA%BC%B0%C5%E4%BC%FE%CA%D0%B3%A1模拟出 环球经贸网 如下url地址
http://search.nowec.com/search?q=%B0%B2%C8%AB%C3%C5
# -*- coding: utf-8 -*-
import urllib
import chardetq=u'安全门'.encode('gb2312')query={'q':q,
}
print chardet.detect(query['q'])
{'confidence': 0.99, 'encoding': 'GB2312'}
print urllib.urlencode(query)
q=%B0%B2%C8%AB%C3%C5print 'http://search.nowec.com/search?'+urllib.urlencode(query)
http://search.nowec.com/search?q=%B0%B2%C8%AB%C3%C5采集 百度贴吧 信息
http://tieba.baidu.com/f?ie=utf-8&kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&fr=search
解决问题思路
1. 确认需求数据在哪。右键查看源代码
2. Fidder模拟发送数据
# -*- coding:utf-8 -*-
import urllib2
import urllib
from lxml import etree
import chardet
import json
import codecsdef GetTimeByArticle(url):request = urllib2.Request(url)response = urllib2.urlopen(request)resHtml = response.read()html = etree.HTML(resHtml)time = html.xpath('//span[@class="tail-info"]')[1].textprint timereturn timedef main():output = codecs.open('tieba0812.json', 'w', encoding='utf-8')for pn in range(0, 250, 50):kw = u'网络爬虫'.encode('utf-8')url = 'http://tieba.baidu.com/f?kw=' + urllib.quote(kw) + '&ie=utf-8&pn=' + str(pn)print urlrequest = urllib2.Request(url)response = urllib2.urlopen(request)resHtml = response.read()print resHtmlhtml_dom = etree.HTML(resHtml)# print etree.tostring(html_dom)html = html_dom# site = html.xpath('//li[@data-field]')[0]for site in html.xpath('//li[@data-field]'):# print etree.tostring(site.xpath('.//a')[0])title = site.xpath('.//a')[0].textArticle_url = site.xpath('.//a')[0].attrib['href']reply_date = GetTimeByArticle('http://tieba.baidu.com' + Article_url)jieshao = site.xpath('.//*[@class="threadlist_abs threadlist_abs_onlyline "]')[0].text.strip()author = site.xpath('.//*[@class="frs-author-name j_user_card "]')[0].text.strip()lastName = site.xpath('.//*[@class="frs-author-name j_user_card "]')[1].text.strip()print title, jieshao, Article_url, author, lastNameitem = {}item['title'] = titleitem['author'] = authoritem['lastName'] = lastNameitem['reply_date'] = reply_dateprint itemline = json.dumps(item, ensure_ascii=False)print lineprint type(line)output.write(line + "\n")output.close()print 'end'if __name__ == '__main__':main()以 惠州市网上挂牌交易系统
为例http://www.hdgtjy.com/index/Index4/ 采集所有的挂牌交易信息
import urllib2
import jsonfp = open('hdgtjy.json','w')
for page in range(1,28):for i in range(5):try:send_headers = {'X-Requested-With': 'XMLHttpRequest', 'Content-Type': 'application/x-www-form-urlencoded'}request =urllib2.Request('http://www.hdgtjy.com/Index/PublicResults',data='page='+ str(page) +'&size=10',headers=send_headers)response = urllib2.urlopen(request)data = response.read()obj = json.loads(data)print obj['data'][0]['ADDRESS']except Exception,e:print efp.write(data)
fp.close()
print 'end'查看运行结果感受一下。
![]()
Requests基本用法与药品监督管理局
Requests
Requests 是唯一的一个非转基因的 Python HTTP 库人类可以安全享用
urllib2urllib2是python自带的模块自定义 'Connection': 'keep-alive'通知服务器交互结束后不断开连接即所谓长连接。 当然这也是urllib2不支持keep-alive的解决办法之一另一个方法是Requests。
安装 Requests
优点Requests 继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池支持使用cookie保持会话支持文件上传支持自动确定响应内容的编码支持国际化的 URL 和 POST 数据自动编码。
缺陷requests不是python自带的库需要另外安装 easy_install or pip install。直接使用不能异步调用速度慢自动确定响应内容的编码。pip install requests
文档http://cn.python-requests.org/zh_CN/latest/index.html http://www.python-requests.org/en/master/#
使用方法
requests.get(url, data={'key1': 'value1'},headers={'User-agent','Mozilla/5.0'})
requests.post(url, data={'key1': 'value1'},headers={'content-type': 'application/json'})以 药品监督管理局 为例http://app1.sfda.gov.cn/
采集分类 国产药品商品名(6994) 下的所有的商品信息
商品列表页http://app1.sfda.gov.cn/datasearch/face3/base.jsp?tableId=32&tableName=TABLE32&title=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&bcId=124356639813072873644420336632
商品详情页http://app1.sfda.gov.cn/datasearch/face3/content.jsp?tableId=32&tableName=TABLE32&tableView=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&Id=211315
# -*- coding: utf-8 -*-
import urllib
from lxml import etree
import re
import json
import chardet
import requestscurstart = 2values = {'tableId': '32','State': '1','bcId': '124356639813072873644420336632','State': '1','tableName': 'TABLE32','State': '1','viewtitleName': 'COLUMN302','State': '1','viewsubTitleName': 'COLUMN299,COLUMN303','State': '1','curstart': str(curstart),'State': '1','tableView': urllib.quote("国产药品商品名"),'State': '1',
}post_headers = {'Content-Type': 'application/x-www-form-urlencoded','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
url = "http://app1.sfda.gov.cn/datasearch/face3/search.jsp"response = requests.post(url, data=values, headers=post_headers)resHtml = response.text
print response.status_code
# print resHtmlUrls = re.findall(r'callbackC,\'(.*?)\',null', resHtml)
for url in Urls:# 坑print url.encode('gb2312')查看运行结果感受一下。
![]()
总结
1. User-Agent伪装Chrome欺骗web服务器
2. urlencode 字典类型Dict、元祖 转化成 url query 字符串
![]()
1. 完成商品详情页采集
2. 完成整个项目的采集
详情页
# -*- coding: utf-8 -*-
from lxml import etree
import re
import json
import requestsurl ='http://app1.sfda.gov.cn/datasearch/face3/content.jsp?tableId=32&tableName=TABLE32&tableView=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&Id=211315'
get_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36','Connection': 'keep-alive',
}
item = {}
response = requests.get(url,headers=get_headers)
resHtml = response.text
print response.encoding
html = etree.HTML(resHtml)
for site in html.xpath('//tr')[1:]:if len(site.xpath('./td'))!=2:continuename = site.xpath('./td')[0].textif not name:continue# value =site.xpath('./td')[1].textvalue = re.sub('<.*?>', '', etree.tostring(site.xpath('./td')[1],encoding='utf-8'))item[name.encode('utf-8')] = valuejson.dump(item,open('sfda.json','w'),ensure_ascii=False)完整项目
# -*- coding: utf-8 -*-
import urllib
from lxml import etree
import re
import json
import requestsdef ParseDetail(url):# url = 'http://app1.sfda.gov.cn/datasearch/face3/content.jsp?tableId=32&tableName=TABLE32&tableView=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&Id=211315'get_headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36','Connection': 'keep-alive',}item = {}response = requests.get(url, headers=get_headers)resHtml = response.textprint response.encodinghtml = etree.HTML(resHtml)for site in html.xpath('//tr')[1:]:if len(site.xpath('./td')) != 2:continuename = site.xpath('./td')[0].textif not name:continue# value =site.xpath('./td')[1].textvalue = re.sub('<.*?>', '', etree.tostring(site.xpath('./td')[1], encoding='utf-8'))value = re.sub('', '', value)item[name.encode('utf-8').strip()] = value.strip()# json.dump(item, open('sfda.json', 'a'), ensure_ascii=False)fp = open('sfda.json', 'a')str = json.dumps(item, ensure_ascii=False)fp.write(str + '\n')fp.close()def main():curstart = 2values = {'tableId': '32','State': '1','bcId': '124356639813072873644420336632','State': '1','tableName': 'TABLE32','State': '1','viewtitleName': 'COLUMN302','State': '1','viewsubTitleName': 'COLUMN299,COLUMN303','State': '1','curstart': str(curstart),'State': '1','tableView': urllib.quote("国产药品商品名"),'State': '1',}post_headers = {'Content-Type': 'application/x-www-form-urlencoded','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}url = "http://app1.sfda.gov.cn/datasearch/face3/search.jsp"response = requests.post(url, data=values, headers=post_headers)resHtml = response.textprint response.status_code# print resHtmlUrls = re.findall(r'callbackC,\'(.*?)\',null', resHtml)for url in Urls:# 坑url = re.sub('tableView=.*?&', 'tableView=' + urllib.quote("国产药品商品名") + "&", url)ParseDetail('http://app1.sfda.gov.cn/datasearch/face3/' + url.encode('gb2312'))if __name__ == '__main__':main()拉钩招聘网
以拉钩具体详情页为例进行抓取。http://www.lagou.com/jobs/2101463.html
from lxml import etree
import requests
import reresponse = requests.get('http://www.lagou.com/jobs/2101463.html')
resHtml = response.texthtml = etree.HTML(resHtml)title = html.xpath('//h1[@title]')[0].attrib['title']
#salary= html.xpath('//span[@class="red"]')[0].textsalary = html.xpath('//dd[@class="job_request"]/p/span')[0].text
worklocation = html.xpath('//dd[@class="job_request"]/p/span')[1].text
experience = html.xpath('//dd[@class="job_request"]/p/span')[2].text
education = html.xpath('//dd[@class="job_request"]/p/span')[3].text
worktype = html.xpath('//dd[@class="job_request"]/p/span')[4].text
Temptation = html.xpath('//dd[@class="job_request"]/p[2]')[0].textprint salary,worklocation,experience,education,worktype,Temptationdescription_tag = html.xpath('//dd[@class="job_bt"]')[0]
description = etree.tostring( description_tag,encoding='utf-8')
#print description
deal_descp = re.sub('<.*?>','',description)
print deal_descp.strip()
publisher_name = html.xpath('//*[@class="publisher_name"]//@title')[0]
pos = html.xpath('//*[@class="pos"]')[0].text
chuli_lv = html.xpath('//*[@class="data"]')[0].text
chuli_yongshi = html.xpath('//*[@class="data"]')[1].textprint chuli_lv,chuli_yongshi,pos,publisher_name爬取糗事百科段子
确定URL并抓取页面代码,首先我们确定好页面的URL是 http://www.qiushibaike.com/8hr/page/4, 其中最后一个数字1代表页数我们可以传入不同的值来获得某一页的段子内容。我们初步构建如下的代码来打印页面代码内容试试看先构造最基本的页面抓取方式看看会不会成功。在Composer raw 模拟发送数据
GET http://www.qiushibaike.com/8hr/page/2/ HTTP/1.1
Host: www.qiushibaike.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Accept-Language: zh-CN,zh;q=0.8在删除了User-Agent、Accept-Language报错。应该是headers验证的问题加上一个headers验证试试看
# -*- coding:utf-8 -*-
import urllib
import requests
import re
import chardet
from lxml import etreepage = 2
url = 'http://www.qiushibaike.com/8hr/page/' + str(page) + "/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36','Accept-Language': 'zh-CN,zh;q=0.8'}
try:response = requests.get(url, headers=headers)resHtml = response.texthtml = etree.HTML(resHtml)result = html.xpath('//div[contains(@id,"qiushi_tag")]')for site in result:#print etree.tostring(site,encoding='utf-8')item = {}imgUrl = site.xpath('./div/a/img/@src')[0].encode('utf-8')username = site.xpath('./div/a/@title')[0].encode('utf-8')#username = site.xpath('.//h2')[0].textcontent = site.xpath('.//div[@class="content"]')[0].text.strip().encode('utf-8')vote = site.xpath('.//i')[0].text#print site.xpath('.//*[@class="number"]')[0].textcomments = site.xpath('.//i')[1].textprint imgUrl, username, content, vote, commentsexcept Exception, e:print e![]()
![]()
![]()
![]()
多线程爬虫实战糗事百科
python下多线程的思考
Queue是python中的标准库可以直接import Queue引用; 队列是线程间最常用的交换数据的形式。对于共享资源加锁是个重要的环节。因为python原生的list,dict等都是not thread safe的。而Queue是线程安全的因此在满足使用条件下建议使用队列。
Python Queue模块有三种队列及构造函数:
1、Python Queue模块的FIFO队列先进先出。 class Queue.Queue(maxsize)
2、LIFO类似于堆即先进后出。 class Queue.LifoQueue(maxsize)
3、还有一种是优先级队列级别越低越先出来。 class Queue.PriorityQueue(maxsize)Queue队列对象
初始化 class Queue.Queue(maxsize) FIFO 先进先出
包中的常用方法:
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空返回True,反之False
Queue.full() 如果队列满了返回True,反之False
Queue.full 与 maxsize 大小对应
Queue.get([block[, timeout]])获取队列timeout等待时间调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block默认为True。
如果队列为空且block为Trueget()就使调用线程暂停直至有项目可用。
如果队列为空且block为False队列将引发Empty异常。
创建一个“队列”对象
import Queue myqueue = Queue.Queue(maxsize = 10)
将一个值放入队列中
myqueue.put(10)
将一个值从队列中取出
myqueue.get()
![]()
# -*- coding:utf-8 -*-
import requests
from lxml import etree
from Queue import Queue
import threading
import time
import jsonclass thread_crawl(threading.Thread):'''抓取线程类'''def __init__(self, threadID, q):threading.Thread.__init__(self)self.threadID = threadIDself.q = qdef run(self):print "Starting " + self.threadIDself.qiushi_spider()print "Exiting ", self.threadIDdef qiushi_spider(self):# page = 1while True:if self.q.empty():breakelse:page = self.q.get()print 'qiushi_spider=', self.threadID, ',page=', str(page)url = 'http://www.qiushibaike.com/hot/page/' + str(page) + '/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36','Accept-Language': 'zh-CN,zh;q=0.8'}# 多次尝试失败结束、防止死循环timeout = 4while timeout > 0:timeout -= 1try:content = requests.get(url, headers=headers)data_queue.put(content.text)breakexcept Exception, e:print 'qiushi_spider', eif timeout < 0:print 'timeout', urlclass Thread_Parser(threading.Thread):'''页面解析类'''def __init__(self, threadID, queue, lock, f):threading.Thread.__init__(self)self.threadID = threadIDself.queue = queueself.lock = lockself.f = fdef run(self):print 'starting ', self.threadIDglobal total, exitFlag_Parserwhile not exitFlag_Parser:try:'''调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block默认为True。如果队列为空且block为Trueget()就使调用线程暂停直至有项目可用。如果队列为空且block为False队列将引发Empty异常。'''item = self.queue.get(False)if not item:passself.parse_data(item)self.queue.task_done()print 'Thread_Parser=', self.threadID, ',total=', totalexcept:passprint 'Exiting ', self.threadIDdef parse_data(self, item):'''解析网页函数:param item: 网页内容:return:'''global totaltry:html = etree.HTML(item)result = html.xpath('//div[contains(@id,"qiushi_tag")]')for site in result:try:imgUrl = site.xpath('.//img/@src')[0]title = site.xpath('.//h2')[0].textcontent = site.xpath('.//div[@class="content"]')[0].text.strip()vote = Nonecomments = Nonetry:vote = site.xpath('.//i')[0].textcomments = site.xpath('.//i')[1].textexcept:passresult = {'imgUrl': imgUrl,'title': title,'content': content,'vote': vote,'comments': comments,}with self.lock:# print 'write %s' % json.dumps(result)self.f.write(json.dumps(result, ensure_ascii=False).encode('utf-8') + "\n")except Exception, e:print 'site in result', eexcept Exception, e:print 'parse_data', ewith self.lock:total += 1data_queue = Queue()
exitFlag_Parser = False
lock = threading.Lock()
total = 0def main():output = open('qiushibaike.json', 'a')#初始化网页页码page从1-10个页面pageQueue = Queue(50)for page in range(1, 11):pageQueue.put(page)#初始化采集线程crawlthreads = []crawlList = ["crawl-1", "crawl-2", "crawl-3"]for threadID in crawlList:thread = thread_crawl(threadID, pageQueue)thread.start()crawlthreads.append(thread)#初始化解析线程parserListparserthreads = []parserList = ["parser-1", "parser-2", "parser-3"]#分别启动parserListfor threadID in parserList:thread = Thread_Parser(threadID, data_queue, lock, output)thread.start()parserthreads.append(thread)# 等待队列清空while not pageQueue.empty():pass# 等待所有线程完成for t in crawlthreads:t.join()while not data_queue.empty():pass# 通知线程是时候退出global exitFlag_ParserexitFlag_Parser = Truefor t in parserthreads:t.join()print "Exiting Main Thread"with lock:output.close()if __name__ == '__main__':main()入坑-乱码
关于爬虫乱码有很多各式各样的问题这里不仅是中文乱码编码转换、还包括一些如日文、韩文 、俄文、藏文之类的乱码处理因为解决方式是一致的故在此统一说明。
网络爬虫出现乱码的原因源网页编码和爬取下来后的编码格式不一致。如源网页为gbk编码的字节流而我们抓取下后程序直接使用utf-8进行编码并输出到存储文件中这必然会引起乱码 即当源网页编码和抓取下来后程序直接使用处理编码一致时则不会出现乱码; 此时再进行统一的字符编码也就不会出现乱码了
注意区分源网页的编码A、程序直接使用的编码B、统一转换字符的编码C。
乱码的解决方法
确定源网页的编码A,编码A往往在网页中的三个位置
1. http header的Content-Type
获取服务器 header 的站点可以通过它来告知浏览器一些页面内容的相关信息。 Content-Type 这一条目的写法就是 "text/html; charset=utf-8"。
![]()
2. meta charset
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />3. 网页头中Document定义
<script type="text/javascript">
if(document.charset){alert(document.charset+"!!!!");document.charset = 'GBK';alert(document.charset);
}
else if(document.characterSet){alert(document.characterSet+"????");document.characterSet = 'GBK';alert(document.characterSet);
}在获取源网页编码时依次判断下这三部分数据即可从前往后优先级亦是如此。
4. 以上三者中均没有编码信息 一般采用chardet等第三方网页编码智能识别工具来做
安装 pip install chardet
官方网站 http://chardet.readthedocs.io/en/latest/usage.html
Python chardet 字符编码判断
使用 chardet 可以很方便的实现字符串/文件的编码检测 虽然HTML页面有charset标签但是有些时候是不对的。那么chardet就能帮我们大忙了。
chardet实例
import urllib
rawdata = urllib.urlopen('http://www.jb51.net/').read()
import chardet
chardet.detect(rawdata)
{'confidence': 0.99, 'encoding': 'GB2312'}chardet可以直接用detect函数来检测所给字符的编码。函数返回值为字典有2个元素一个是检测的可信度另外一个就是检测到的编码。
在开发自用爬虫过程中如何处理汉字编码?
下面所说的都是针对python2.7,如果不加处理采集到的都是乱码解决的方法是将html处理成统一的utf-8编码 遇到windows-1252编码属于chardet编码识别训练未完成
import chardet
a='abc'
type(a)
str
chardet.detect(a)
{'confidence': 1.0, 'encoding': 'ascii'}a ="我"
chardet.detect(a)
{'confidence': 0.73, 'encoding': 'windows-1252'}
a.decode('windows-1252')
u'\xe6\u02c6\u2018'
chardet.detect(a.decode('windows-1252').encode('utf-8'))
type(a.decode('windows-1252'))
unicode
type(a.decode('windows-1252').encode('utf-8'))
str
chardet.detect(a.decode('windows-1252').encode('utf-8'))
{'confidence': 0.87625, 'encoding': 'utf-8'}a ="我是中国人"
type(a)
str
{'confidence': 0.9690625, 'encoding': 'utf-8'}
chardet.detect(a)# -*- coding:utf-8 -*-
import chardet
import urllib2
#抓取网页html
html = urllib2.urlopen('http://www.jb51.net/').read()
print html
mychar=chardet.detect(html)
print mychar
bianma=mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':html=html.decode('utf-8','ignore').encode('utf-8')
else:html =html.decode('gb2312','ignore').encode('utf-8')
print html
print chardet.detect(html)python代码文件的编码
py文件默认是ASCII编码中文在显示时会做一个ASCII到系统默认编码的转换这时就会出错SyntaxError: Non-ASCII character。
需要在代码文件的第一行添加编码指示
# -*- coding:utf-8 -*-
print '中文'像上面那样直接输入的字符串是按照代码文件的编码'utf-8'来处理的
如果用unicode编码,以下方式
s1 = u'中文' #u表示用unicode编码方式储存信息decode是任何字符串具有的方法将字符串转换成unicode格式参数指示源字符串的编码格式。
encode也是任何字符串具有的方法将字符串转换成参数指定的格式。
模拟登陆及验证码
使用表单登陆
这种情况属于post请求即先向服务器发送表单数据服务器再将返回的cookie存入本地。
data = {'data1':'XXXXX', 'data2':'XXXXX'}Requestsdata为dictjson
import requests
response = requests.post(url=url, data=data)
#Urllib2data为string
import urllib, urllib2
data = urllib.urlencode(data)
req = urllib2.Request(url=url, data=data)
response = urllib2.urlopen(req)使用cookie登陆
使用cookie登陆服务器会认为你是一个已登陆的用户所以就会返回给你一个已登陆的内容。因此需要验证码的情况可以使用带验证码登陆的cookie解决。
import requests
requests_session = requests.session()
response = requests_session.post(url=url_login, data=data)若存在验证码此时采用response = requests_session.post(url=url_login, data=data)是不行的做法应该如下
response_captcha = requests_session.get(url=url_login, cookies=cookies)
response1 = requests.get(url_login) # 未登陆
response2 = requests_session.get(url_login) # 已登陆因为之前拿到了Response Cookie
response3 = requests_session.get(url_results) # 已登陆因为之前拿到了Response Cookie我们以成都学院为例http://202.115.80.153/default2.aspx
账户 201310412102
密码 liudong01032817
# -*- coding: utf-8 -*-
import urllib2
import cookielib
import urllib
import re
import sys
reload(sys)
sys.setdefaultencoding("utf-8")def login():'''模拟登录'''# 验证码地址和post地址CaptchaUrl = "http://202.115.80.153/CheckCode.aspx"PostUrl = "http://202.115.80.153/default2.aspx"# 将cookies绑定到一个opener cookie由cookielib自动管理cookie = cookielib.CookieJar()handler = urllib2.HTTPCookieProcessor(cookie)opener = urllib2.build_opener(handler)#安装opener,此后调用urlopen()时都会使用安装过的opener对象urllib2.install_opener(opener)# 用户名和密码username = '201310412102'password = 'liudong01032817'# 根据抓包信息 构造headersheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.8','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded','Accept-Encoding': 'gzip, deflate','Referer': 'http://202.115.80.153/','User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36',}def get_xsrf(url=None):response = urllib2.urlopen(url)xsrf = re.search('name="__VIEWSTATE" value="(.*)" />', response.read()).group(1)if xsrf == None:return ''else:return xsrfVIEWSTATE = get_xsrf(PostUrl)# 用openr访问验证码地址,获取cookiepicture = urllib2.urlopen(CaptchaUrl).read()# 保存验证码到本地local = open('image.jpg', 'wb')local.write(picture)local.close()# 打开保存的验证码图片 输入SecretCode = raw_input('输入验证码 ')# 根据抓包信息 构造表单postData = {'__VIEWSTATE': VIEWSTATE,'txtUserName': username,'TextBox2': password,'txtSecretCode': SecretCode,'RadioButtonList1': u'学生'.encode('gb2312'),'Button1': '','lbLanguage': '','hidPdrs': '','hidsc': '',}# 生成post数据 ?key1=value1&key2=value2的形式data = urllib.urlencode(postData)# 构造request请求request = urllib2.Request(PostUrl, data, headers)try:# 利用之前存有cookie的opener登录页面response = urllib2.urlopen(request)# 由于该网页是gb2312的编码所以需要解码result = response.read().decode('gb2312')print resultexcept urllib2.HTTPError, e:print e.codeif __name__ == '__main__':login()Python 性能优化
因为GIL的存在Python很难充分利用多核CPU的优势。但是可以通过内置的模块multiprocessing实现下面几种并行模式
1、 多进程并行编程对于CPU密集型的程序可以使用multiprocessing的Process,Pool等封装好的类通过多进程的方式实现并行计算。但是因为进程中的通信成本比较大对于进程之间需要大量数据交互的程序效率未必有大的提高。
2、 多线程并行编程对于IO密集型的程序multiprocessing.dummy模块使用multiprocessing的接口封装threading使得多线程编程也变得非常轻松(比如可以使用Pool的map接口简洁高效)。 分布式multiprocessing中的Managers类提供了可以在不同进程之共享数据的方式可以在此基础上开发出分布式的程序。 不同的业务场景可以选择其中的一种或几种的组合实现程序性能的优化。
爬虫框架Scrapy
官方架构图
![]()
Scrapy主要包括了以下组件
五个功能模块
- 引擎(Scrapy): 用来处理整个系统的数据流处理, 数据流的指挥官负责控制数据流控制各个模块之间的通信)
- 调度器(Scheduler): 负责引擎发过来的请求URL,压入队列成一个URL的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给引擎Scrapy
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(item Pipeline): 负责处理爬虫从网页中抽取的实体主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后将被发送到项目管道并经过几个特定的次序处理数据。
三大中间件
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件从Scrapy引擎发送到调度的请求和响应。
Spider参数
Spider可以通过接受参数来修改其功能。
spider参数一般用来定义初始URL或者指定限制爬取网站的部分。 您也可以使用其来配置spider的任何功能。
在运行 crawl 时添加 -a 可以传递Spider参数:
scrapy crawl myspider -a category=electronicsSpider在构造器(constructor)中获取参数:
import scrapyclass MySpider(Spider):name = 'myspider'def __init__(self, category=None, *args, **kwargs):super(MySpider, self).__init__(*args, **kwargs)self.start_urls = ['http://www.example.com/categories/%s' % category]脚本运行Scrapyhttps://doc.scrapy.org/en/master/topics/practices.html#run-scrapy-from-a-script
经过学习之后有两条路可以走
1. 一个是继续深入学习以及关于设计模式的一些知识强化Python相关知识自己动手造轮子继续为自己的爬虫增加分布式多线程等功能扩展
2. 另一条路便是学习一些优秀的框架先把这些框架用熟可以确保能够应付一些基本的爬虫任务也就是所谓的解决温饱问题企业用人要求然后再深入学习它的源码等知识进一步强化。
爬虫框架其中比较好用的是 Scrapy 和 PySpider。
PySpider
优点分布式框架上手更简单操作更加简便因为它增加了 WEB 界面写爬虫迅速集成了phantomjs可以用来抓取js渲染的页面。
缺点自定义程度低
http://docs.pyspider.org/en/latest/Quickstart/
Scrapy
优点自定义程度高比 PySpider更底层一些适合学习研究需要学习的相关知识多拿来研究分布式和多线程等等是最合适不过的。
缺点非分布式框架可以用scrapy-redis分布式框架
官方文档http://doc.scrapy.org/en/latest/intro/tutorial.html
豆瓣Python小组https://www.douban.com/search?q=python+%E7%88%AC%E8%99%AB
企业招聘要求
![]()
Scrapy介绍
Scrapy是用Python开发的一个快速,高层次的web抓取框架Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试
Scrapy使用了Twisted 异步网络库来处理网络通讯。
整体架构大致如下
![]()
Scrapy运行流程大概如下
1调度器(Scheduler)从 待下载链接 中取出一个链接(URL)
2调度器启动 采集模块Spiders模块
3采集模块把URL传给下载器Downloader下载器把资源下载下来
4提取目标数据抽取出目标对象Item,则交给实体管道item pipeline进行进一步的处理比如存入数据库、文本
5若是解析出的是链接URL,则把URL插入到待爬取队列当中
Scrapy配置安装
文档 官网文档(英文)http://doc.scrapy.org/en/latest/intro/install.html
中文文档(相对官网较老版本)http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
Windows 平台
从 http://python.org/download/ 上安装Python 2.7。您需要修改 PATH 环境变量将Python的可执行程序及额外的脚本添加到系统路径中。将以下路径添加到 PATH 中:
C:\Python2.7\;C:\Python2.7\Scripts\; 。从 http://sourceforge.net/projects/pywin32/ 安装 pywin32。请确认下载符合您系统的版本(win32或者amd64)
安装Scrapy: pip install Scrapy
验证安装输入 Scrapy或者scrapy大小写都可以。如果提示如下命令就证明安装成功啦如果失败了请检查上述步骤有何疏漏。
![]()
Linux Ubuntu 平台
安装 Scrapy
If you prefer to build the python dependencies locally instead of relying on system packages you’ll need to install their required non-python dependencies first:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
You can install Scrapy with pip after thatsudo pip install Scrapy
验证安装安装完毕之后输入 scrapy。 注意这里linux下不要输入Scrapylinux依然严格区分大小写的
如果出现如下提示这证明安装成功
![]()
Scrapy入门教程
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 spider 并提取出结构化数据(Item)
- 编写 Item Pipeline 来存储提取到的Item(即结构化数据)
创建项目
在开始爬取之前您必须创建一个新的Scrapy项目。 进入您打算存储代码的目录中运行下列命令: scrapy startproject tutorial
运行过程
![]()
该命令将会创建包含下列内容的 tutorial 目录:
这些文件分别是:
scrapy.cfg: 项目的配置文件用于发布到服务器
tutorial/: 该项目文件夹。之后将在此编写Python代码。
tutorial/items.py: 项目中的item文件;定义结构化数据字段field.
tutorial/pipelines.py: 项目中的pipelines文件;用于存放执行后期数据处理的功能定义如何存储结构化数据)
tutorial/settings.py: 项目的设置文件(如何修改User-Agent设置爬取时间间隔设置代理配置中间件等等)
tutorial/spiders/: 放置spider代码的目录;编写爬取网站规则定义Item
Item 定义结构化数据字段用来保存爬取到的数据其使用方法和python字典类似。可以通过创建一个 scrapy.Item 类 并且定义类型为 scrapy.Field的类属性来定义一个Item。首先根据需要从腾讯招聘获取到的数据对item进行建模。 我们需要从腾讯招聘中获取 职位名称、职位详情页url、职位类别、人数、工作地点以及发布时间。 对此在item中定义相应的字段。编辑 tutorial 目录中的 items.py 文件:
import scrapyclass RecruitItem(scrapy.Item):name = scrapy.Field()detailLink = scrapy.Field()catalog = scrapy.Field()recruitNumber = scrapy.Field()workLocation = scrapy.Field()publishTime = scrapy.Field()编写第一个爬虫(Spider)
Spider是开发者编写用于从单个网站(或者一些网站)爬取数据的类。创建一个Spider必须继承 'scrapy.Spider' 类 需要定义以下三个属性:
name: spider名字必须是唯一的
start_urls: 初始的URL列表
parse(self, response)每个初始URL完成下载后被调用
这个函数要完成的功能
1.负责解析返回的网页数据(response.body)提取结构化数据(生成item)
2.生成需要下一页的请求URL。
以下为我们的第一个Spider代码保存在 tutorial/spiders 目录下的 tencent_spider.py 文件中:
import scrapyclass RecruitSpider(scrapy.spiders.Spider):name = "tencent"allowed_domains = ["hr.tencent.com"]start_urls = ["http://hr.tencent.com/position.php?&start=0#a"]def parse(self, response):f = open('tengxun.txt', 'wb')f.write(response.body)f.close()爬取
进入项目的根目录执行下列命令启动spider:
scrapy crawl tencentcrawl tencent 启动用于爬取 tencent 的spider您将得到类似的输出:
![]()
现在查看当前目录会注意到有文件被创建了: tengxun.txt,正如我们的 parse 方法里做的一样。
注意在刚启动的时候会有一段error信息不用理会以后会说明可现在自行查找结果
2016-08-11 13:07:35 [boto] ERROR: Caught exception reading instance data
Traceback (most recent call last):File "/usr/lib/python2.7/dist-packages/boto/utils.py", line 210, in retry_urlr = opener.open(req, timeout=timeout)File "/usr/lib/python2.7/urllib2.py", line 429, in openresponse = self._open(req, data)File "/usr/lib/python2.7/urllib2.py", line 447, in _open'_open', req)File "/usr/lib/python2.7/urllib2.py", line 407, in _call_chainresult = func(*args)File "/usr/lib/python2.7/urllib2.py", line 1228, in http_openreturn self.do_open(httplib.HTTPConnection, req)File "/usr/lib/python2.7/urllib2.py", line 1198, in do_openraise URLError(err)
URLError: <urlopen error timed out>刚才发生了什么
Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Request 对象并将 parse 方法作为回调函数(callback)赋值给了Request。
Request 对象经过调度执行生成 scrapy.http.Response 对象并送回给parse() 方法。
提取Item
Selectors选择器简介
Scrapy Selectors 内置XPath 和 CSS Selector 表达式机制
XPath表达式的例子及对应的含义:
/html/head/title: 选择<HTML>文档中 <head> 标签内的 <title> 元素
/html/head/title/text(): 选择上面提到的 <title> 元素的文字
//td: 选择所有的 <td> 元素
//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素Selector有四个基本的方法:
xpath(): 传入xpath表达式返回该表达式所对应的所有节点的selector list列表 。
css(): 传入CSS表达式返回该表达式所对应的所有节点的selector list列表.
extract(): 序列化该节点为unicode字符串并返回list。
re(): 根据传入的正则表达式对数据进行提取返回unicode字符串list列表。尝试Selector选择器
为了介绍Selector的使用方法接下来我们将要使用内置的 scrapy shell 。Scrapy Shell需要您预装好IPython(一个扩展的Python终端)。
您需要进入项目的根目录执行下列命令来启动shell:
scrapy shell "http://hr.tencent.com/position.php?&start=0#a"注解: 当您在终端运行Scrapy时请一定记得给url地址加上引号否则包含参数的url(例如 & 字符)会导致Scrapy运行失败。
shell的输出类似:
![]()
当shell载入后将得到一个包含response数据的本地 response 变量。输入 response.body将输出response的包体 输出 response.headers 可以看到response的包头。
当输入 response.selector 时 将获取到一个response 初始化的类 Selector 的对象。此时可以通过使用 response.selector.xpath() 或 response.selector.css() 来对 response 进行查询。或者scrapy也对 response.selector.xpath() 及 response.selector.css() 提供了一些快捷方式, 例如 response.xpath() 或 response.css()
让我们来试试:
response.xpath('//title')
[<Selector xpath='//title' data=u'<title>\u804c\u4f4d\u641c\u7d22 | \u793e\u4f1a\u62db\u8058 | Tencent \u817e\u8baf\u62db\u8058</title'>]response.xpath('//title').extract()
[u'<title>\u804c\u4f4d\u641c\u7d22 | \u793e\u4f1a\u62db\u8058 | Tencent \u817e\u8baf\u62db\u8058</title>']print response.xpath('//title').extract()[0]
<title>职位搜索 | 社会招聘 | Tencent 腾讯招聘</title>response.xpath('//title/text()')
<Selector xpath='//title/text()' data=u'\u804c\u4f4d\u641c\u7d22 | \u793e\u4f1a\u62db\u8058 | Tencent \u817e\u8baf\u62db\u8058'>response.xpath('//title/text()')[0].extract()
u'\u804c\u4f4d\u641c\u7d22 | \u793e\u4f1a\u62db\u8058 | Tencent \u817e\u8baf\u62db\u8058'print response.xpath('//title/text()')[0].extract()
职位搜索 | 社会招聘 | Tencent 腾讯招聘response.xpath('//title/text()').re('(\w+):')
[u'\u804c\u4f4d\u641c\u7d22',u'\u793e\u4f1a\u62db\u8058',u'Tencent',u'\u817e\u8baf\u62db\u8058']提取数据
现在我们来尝试从这些页面中提取些有用的数据。
我们可以通过XPath选择该页面中网站列表里所有 lass=even 元素:site = response.xpath('//*[@class="even"]')
职位名称:
print site[0].xpath('./td[1]/a/text()').extract()[0]
TEG15-运营开发工程师深圳
职位名称详情页:
print site[0].xpath('./td[1]/a/@href').extract()[0]
position_detail.php?id=20744&keywords=&tid=0&lid=0
职位类别:
print site[0].xpath('./td[2]/text()').extract()[0]
技术类
对于 .xpath() 调用返回selector组成的list 因此可以拼接更多的 .xpath() 来进一步获取某个节点。
for sel in response.xpath('//*[@class="even"]'):name = sel.xpath('./td[1]/a/text()').extract()[0]detailLink = sel.xpath('./td[1]/a/@href').extract()[0]catalog = sel.xpath('./td[2]/text()').extract()[0]recruitNumber = sel.xpath('./td[3]/text()').extract()[0]workLocation = sel.xpath('./td[4]/text()').extract()[0]publishTime = sel.xpath('./td[5]/text()').extract()[0]print name, detailLink, catalog,recruitNumber,workLocation,publishTime在我们的tencent_spider.py文件修改成如下代码:
import scrapyclass RecruitSpider(scrapy.spiders.Spider):name = "tencent"allowed_domains = ["hr.tencent.com"]start_urls = ["http://hr.tencent.com/position.php?&start=0#a"]def parse(self, response):for sel in response.xpath('//*[@class="even"]'):name = sel.xpath('./td[1]/a/text()').extract()[0]detailLink = sel.xpath('./td[1]/a/@href').extract()[0]catalog = sel.xpath('./td[2]/text()').extract()[0]recruitNumber = sel.xpath('./td[3]/text()').extract()[0]workLocation = sel.xpath('./td[4]/text()').extract()[0]publishTime = sel.xpath('./td[5]/text()').extract()[0]print name, detailLink, catalog,recruitNumber,workLocation,publishTime![]()
现在尝试再次爬取hr.tencent.com您将看到爬取到的网站信息被成功输出:
scrapy crawl tencent运行过程
![]()
使用item
Item 对象是自定义的python字典。可以使用标准的字典语法来获取到其每个字段的值。输入 `scrapy shell'
import scrapyclass RecruitItem(scrapy.Item):name = scrapy.Field()detailLink = scrapy.Field()catalog = scrapy.Field()recruitNumber = scrapy.Field()workLocation = scrapy.Field()publishTime = scrapy.Field()item = RecruitItem()
item['name'] = 'sanlang'
item['name']
'sanlang'一般来说Spider将会将爬取到的数据以Item对象返回。所以为了将爬取的数据返回最终tencent_spider.py代码将是:
import scrapy
from tutorial.items import RecruitItem
class RecruitSpider(scrapy.spiders.Spider):name = "tencent"allowed_domains = ["hr.tencent.com"]start_urls = ["http://hr.tencent.com/position.php?&start=0#a"]def parse(self, response):for sel in response.xpath('//*[@class="even"]'):name = sel.xpath('./td[1]/a/text()').extract()[0]detailLink = sel.xpath('./td[1]/a/@href').extract()[0]catalog = sel.xpath('./td[2]/text()').extract()[0]recruitNumber = sel.xpath('./td[3]/text()').extract()[0]workLocation = sel.xpath('./td[4]/text()').extract()[0]publishTime = sel.xpath('./td[5]/text()').extract()[0]print name, detailLink, catalog,recruitNumber,workLocation,publishTimeitem = RecruitItem()item['name']=name.encode('utf-8')item['detailLink']=detailLink.encode('utf-8')item['catalog']=catalog.encode('utf-8')item['recruitNumber']=recruitNumber.encode('utf-8')item['workLocation']=workLocation.encode('utf-8')item['publishTime']=publishTime.encode('utf-8')yield item现在对hr.tencent.com进行爬取将会产生 RecruitItem 对象:
![]()
保存爬取到的数据
最简单存储爬取的数据的方式是使用 Feed exports:
scrapy crawl tencent -o items.json该命令将采用 JSON 格式对爬取的数据进行序列化生成 items.json 文件。
如果需要对爬取到的item做更多更为复杂的操作您可以编写 Item Pipeline 。 类似于我们在创建项目时对Item做的用于您编写自己的 tutorial/pipelines.py 也被创建。 不过如果您仅仅想要保存item您不需要实现任何的pipeline。
Item Pipelines
当Item在Spider中被收集之后它将会被传递到Item Pipeline。每个Item Pipeline组件接收到Item,定义一些操作行为比如决定此Item是丢弃而存储。
item pipeline的一些典型应用验证爬取的数据(检查item包含某些字段比如说name字段)。查重(并丢弃)。将爬取结果保存到文件或者数据库中。
编写item pipeline
编写item pipeline很简单item pipiline组件是一个独立的Python类必须实现process_item方法:
process_item(self, item, spider)
当Item在Spider中被收集之后都需要调用该方法
参数:
item - 爬取的结构化数据
spider – 爬取该item的spider
open_spider(self, spider)当spider被开启时这个方法被调用。
参数:
spider – 被开启的spider
close_spider(spider)当spider被关闭时这个方法被调用
参数:
spider – 被关闭的spider将item写入JSON文件
以下pipeline将所有爬取到的item存储到一个独立地items.json 文件每行包含一个序列化为'JSON'格式的'item':
import jsonclass JsonWriterPipeline(object):def __init__(self):self.file = open('items.json', 'wb')def process_item(self, item, spider):line = json.dumps(dict(item),ensure_ascii=False) + "\n"self.file.write(line)return item启用一个Item Pipeline组件
为了启用Item Pipeline组件必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置就像下面这个例子:
ITEM_PIPELINES = {#'tutorial.pipelines.PricePipeline': 300,'tutorial.pipelines.JsonWriterPipeline': 800,
}分配给每个类的整型值确定了他们运行的顺序item按数字从低到高的顺序通过pipeline通常将这些数字定义在0-1000范围内。
在这里优化
以下pipeline将所有爬取到的item存储到一个独立地items.json 文件每行包含一个序列化为'JSON'格式的'item':
import json
import codecsclass JsonWriterPipeline(object):def __init__(self):self.file = codecs.open('items.json', 'w', encoding='utf-8')def process_item(self, item, spider):line = json.dumps(dict(item), ensure_ascii=False) + "\n"self.file.write(line)return itemdef spider_closed(self, spider):self.file.close()针对spider里面的utf-8编码格式去掉.encode('utf-8')
item = RecruitItem()
item['name']=name.encode('utf-8')
item['detailLink']=detailLink.encode('utf-8')
item['catalog']=catalog.encode('utf-8')
item['recruitNumber']=recruitNumber.encode('utf-8')
item['workLocation']=workLocation.encode('utf-8')
item['publishTime']=publishTime.encode('utf-8')将item写入MongoDB
from_crawler(cls, crawler)
如果使用这类方法被调用创建爬虫管道实例。必须返回管道的一个新实例。crawler提供存取所有Scrapy核心组件配置和信号管理器 对于pipelines这是一种访问配置和信号管理器 的方式。
参数: crawler (Crawler object) – crawler that uses this pipeline
例子中我们将使用pymongo将Item写到MongoDB。MongoDB的地址和数据库名称在Scrapy setttings.py配置文件中这个例子主要是说明如何使用from_crawler()方法
import pymongoclass MongoPipeline(object):collection_name = 'scrapy_items'def __init__(self, mongo_uri, mongo_db):self.mongo_uri = mongo_uriself.mongo_db = mongo_db@classmethoddef from_crawler(cls, crawler):return cls(mongo_uri=crawler.settings.get('MONGO_URI'),mongo_db=crawler.settings.get('MONGO_DATABASE', 'items'))def open_spider(self, spider):self.client = pymongo.MongoClient(self.mongo_uri)self.db = self.client[self.mongo_db]def close_spider(self, spider):self.client.close()def process_item(self, item, spider):self.db[self.collection_name].insert(dict(item))return itemSpiders
Spider
Spider类 定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说Spider就是定义爬取的动作及分析某个网页(或者是有些网页)的地方。
class scrapy.spider.Spider
Spider是最简单的spider。每个spider必须继承自该类。Spider并没有提供什么特殊的功能。其仅仅请求给定的 start_urls/start_requests并根据返回的结果调用spider的parse方法。
name定义spider名字的字符串。例如如果spider爬取 mywebsite.com 该spider通常会被命名为 mywebsite
allowed_domains可选。包含了spider允许爬取的域名(domain)列表(list)
start_urls初始URL列表。当没有制定特定的URL时spider将从该列表中开始进行爬取。
start_requests()当spider启动爬取并且未指定start_urls时该方法被调用。如果您想要修改最初爬取某个网站。
例如如果您需要在启动时以POST登录某个网站你可以这么写:
class MySpider(scrapy.Spider):name = 'myspider'def start_requests(self):return [scrapy.FormRequest("http://www.example.com/login",formdata={'user': 'john', 'pass': 'secret'},callback=self.logged_in)]def logged_in(self, response):# here you would extract links to follow and return Requests for# each of them, with another callbackpassparse(response)当请求url返回网页没有指定回调函数时默认下载回调方法。参数response (Response) – 返回网页信息的response
log(message[, level, component])使用 scrapy.log.msg() 方法记录(log)message。 更多数据请参见 Logging
Spider样例
让我们来看一个例子:
import scrapyclass MySpider(scrapy.Spider):name = 'example.com'allowed_domains = ['example.com']start_urls = ['http://www.example.com/1.html','http://www.example.com/2.html','http://www.example.com/3.html',]def parse(self, response):self.log('A response from %s just arrived!' % response.url)另一个在单个回调函数中返回多个Request以及Item的例子:
import scrapy
from myproject.items import MyItemclass MySpider(scrapy.Spider):name = 'example.com'allowed_domains = ['example.com']start_urls = ['http://www.example.com/1.html','http://www.example.com/2.html','http://www.example.com/3.html',]def parse(self, response):sel = scrapy.Selector(response)for h3 in response.xpath('//h3').extract():yield MyItem(title=h3)for url in response.xpath('//a/@href').extract():yield scrapy.Request(url, callback=self.parse)案例腾讯招聘网翻页功能
import scrapy
from tutorial.items import RecruitItem
import re
class RecruitSpider(scrapy.Spider):name = "tencent"allowed_domains = ["hr.tencent.com"]start_urls = ["http://hr.tencent.com/position.php?&start=0#a"]def parse(self, response):for sel in response.xpath('//*[@class="even"]'):name = sel.xpath('./td[1]/a/text()').extract()[0]detailLink = sel.xpath('./td[1]/a/@href').extract()[0]catalog =Noneif sel.xpath('./td[2]/text()'):catalog = sel.xpath('./td[2]/text()').extract()[0]recruitNumber = sel.xpath('./td[3]/text()').extract()[0]workLocation = sel.xpath('./td[4]/text()').extract()[0]publishTime = sel.xpath('./td[5]/text()').extract()[0]#print name, detailLink, catalog,recruitNumber,workLocation,publishTimeitem = RecruitItem()item['name']=name.encode('utf-8')item['detailLink']=detailLink.encode('utf-8')if catalog:item['catalog']=catalog.encode('utf-8')item['recruitNumber']=recruitNumber.encode('utf-8')item['workLocation']=workLocation.encode('utf-8')item['publishTime']=publishTime.encode('utf-8')yield itemnextFlag = response.xpath('//*[@id="next"]/@href')[0].extract()if 'start' in nextFlag:curpage = re.search('(\d+)',response.url).group(1)page =int(curpage)+10url = re.sub('\d+',str(page),response.url)print urlyield scrapy.Request(url, callback=self.parse)执行:scrapy crawl tencent -L INFO
CrawlSpider
scrapy.spiders.CrawlSpider
爬取一般网站常用的spider。其定义了一些规则(rule)来提供跟进link的方便的机制。除了从Spider继承过来的(您必须提供的)属性外name、allow_domains其提供了一个新的属性:
rules包含一个(或多个) 规则对象的集合(list)。 每个Rule对爬取网站的动作定义了特定操作。 如果多个rule匹配了相同的链接则根据规则在本集合中被定义的顺序第一个会被使用。
parse_start_url(response)当start_url的请求返回时该方法被调用
爬取规则(Crawling rules)
class scrapy.contrib.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
link_extractor其定义了如何从爬取到的页面中提取链接。
callback指定spider中哪个函数将会被调用。 从link_extractor中每获取到链接时将会调用该函数。该回调函数接受一个response作为其第一个参数
注意
当编写爬虫规则时请避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑如果您覆盖了 parse方法crawl spider将会运行失败。
cb_kwargs包含传递给回调函数的参数(keyword argument)的字典。
follow是一个布尔(boolean)值指定了根据该规则从response提取的链接是否需要跟进。 如果callback为Nonefollow默认设置为True 否则默认为False。
process_links指定该spider中哪个的函数将会被调用从link_extractor中获取到链接列表时将会调用该函数。该方法常用于过滤参数
process_request指定该spider中哪个的函数将会被调用该规则提取到每个request时都会调用该函数 (用来过滤request)
CrawlSpider案例
还是以腾讯招聘为例给出配合rule使用CrawlSpider的例子:
首先运行
scrapy shell "http://hr.tencent.com/position.php?&start=0#a"导入匹配规则
from scrapy.linkextractors import LinkExtractor
page_lx = LinkExtractor(allow=('position.php?&start=\d+'))查询匹配结果
page_lx.extract_links(response)没有查到
page_lx = LinkExtractor(allow=(r'position\.php\?&start=\d+'))
page_lx.extract_links(response)[Link(url='http://hr.tencent.com/position.php?start=10', text='2', fragment='', nofollow=False),
Link(url='http://hr.tencent.com/position.php?start=20', text='3', fragment='', nofollow=False),
Link(url='http://hr.tencent.com/position.php?start=30', text='4', fragment='', nofollow=False),
Link(url='http://hr.tencent.com/position.php?start=40', text='5', fragment='', nofollow=False),
Link(url='http://hr.tencent.com/position.php?start=50', text='6', fragment='', nofollow=False),
Link(url='http://hr.tencent.com/position.php?start=60', text='7', fragment='', nofollow=False),
Link(url='http://hr.tencent.com/position.php?start=70', text='...', fragment='', nofollow=False),
Link(url='http://hr.tencent.com/position.php?start=1300', text='131', fragment='', nofollow=False)]
len(page_lx.extract_links(response))那么scrapy shell测试完成之后修改以下代码
#提取匹配 'http://hr.tencent.com/position.php?&start=\d+'的链接
page_lx = LinkExtractor(allow=('start=\d+'))rules = [
#提取匹配,并使用spider的parse方法进行分析;并跟进链接(没有callback意味着follow默认为True)
Rule(page_lx, callback='parse',follow=True)
]这么写对吗 callback 千万不能写parse一定运行有错误
保存以下代码为tencent_crawl.py
# -*- coding:utf-8 -*-
import scrapy
from tutorial.items import RecruitItem
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractorclass RecruitSpider(CrawlSpider):name = "tencent_crawl"allowed_domains = ["hr.tencent.com"]start_urls = ["http://hr.tencent.com/position.php?&start=0#a"]#提取匹配 'http://hr.tencent.com/position.php?&start=\d+'的链接page_lx = LinkExtractor(allow=('start=\d+'))rules = [#提取匹配,并使用spider的parse方法进行分析;并跟进链接(没有callback意味着follow默认为True)Rule(page_lx, callback='parseContent',follow=True)]def parseContent(self, response):print response.urlfor sel in response.xpath('//*[@class="even"]'):name = sel.xpath('./td[1]/a/text()').extract()[0]detailLink = sel.xpath('./td[1]/a/@href').extract()[0]catalog =Noneif sel.xpath('./td[2]/text()'):catalog = sel.xpath('./td[2]/text()').extract()[0]recruitNumber = sel.xpath('./td[3]/text()').extract()[0]workLocation = sel.xpath('./td[4]/text()').extract()[0]publishTime = sel.xpath('./td[5]/text()').extract()[0]#print name, detailLink, catalog,recruitNumber,workLocation,publishTimeitem = RecruitItem()item['name']=name.encode('utf-8')item['detailLink']=detailLink.encode('utf-8')if catalog:item['catalog']=catalog.encode('utf-8')item['recruitNumber']=recruitNumber.encode('utf-8')item['workLocation']=workLocation.encode('utf-8')item['publishTime']=publishTime.encode('utf-8')yield item可以修改配置文件settings.py添加 LOG_LEVEL='INFO'
![]()
运行scrapy crawl tencent_crawl![]()
process_links参数:动态网页爬取动态url的处理
在爬取 https://bitsharestalk.org 的时候发现网站会为每一个url增加一个sessionid属性可能是为了标记用户访问历史而且这个seesionid随着每次访问都会动态变化这就为爬虫的去重处理即标记已经爬取过的网站和提取规则增加了难度。
比如 https://bitsharestalk.org/index.php?board=5.0 会变成https://bitsharestalk.org/index.phpPHPSESSID=9771d42640ab3c89eb77e8bd9e220b53&board=5.0下面介绍集中处理方法
仅适用你的爬虫使用的是 scrapy.contrib.spiders.CrawlSpider, 在这个内置爬虫中你提取url要通过Rule类来进行提取其自带了对提取后的url进行加工的函数。
rules = (Rule(LinkExtractor(allow = ( "https://bitsharestalk\.org/index\.php\?PHPSESSID\S*board=\d+\.\d+$", "https://bitsharestalk\.org/index\.php\?board=\d+\.\d+$" )), process_links = 'link_filtering' ), #默认函数process_linksRule(LinkExtractor(allow = ( " https://bitsharestalk\.org/index\.php\?PHPSESSID\S*topic=\d+\.\d+$" , "https://bitsharestalk\.org/index\.php\?topic=\d+\.\d+$", ),),callback = "extractPost" ,follow = True, process_links = 'link_filtering' ),Rule(LinkExtractor(allow = ( "https://bitsharestalk\.org/index\.php\?PHPSESSID\S*action=profile;u=\d+$" , "https://bitsharestalk\.org/index\.php\?action=profile;u=\d+$" , ),),callback = "extractUser", process_links = 'link_filtering' ))def link_filtering(self, links):ret = []for link in links:url = link.url# print "This is the yuanlai ", link.url urlfirst, urllast = url.split( " ? " )if urllast:link.url = urlfirst + " ? " + urllast.split( " & " , 1)[1]# print link.urlreturn linkslink_filtering()函数对url进行了处理过滤掉了sessid关于Rule类的process_links函数和links类官方文档中并没有给出介绍给出一个参考 https://groups.google.com/forum/#!topic/scrapy-users/RHGtm_2GO1M也许需要梯子你懂得
如果你是自己实现的爬虫那么url的处理更是可定制的只需要自己处理一下就可以了。
process_request参数:修改请求参数
class WeiboSpider(CrawlSpider):name = 'weibo'allowed_domains = ['weibo.com']start_urls = ['http://www.weibo.com/u/1876296184'] # 不加www,则匹配不到cookie, get_login_cookie()方法正则代完善rules = (Rule(LinkExtractor(allow=r'^http:\/\/(www\.)?weibo.com/[a-z]/.*'), # 微博个人页面的规则,或/u/或/n/后面跟一串数字process_request='process_request',callback='parse_item', follow=True), )cookies = Nonedef process_request(self, request):link=request.urlpage = re.search('page=\d*', link).group()type = re.search('type=\d+', link).group()newrequest = request.replace(cookies =self.cookies, url='.../questionType?' + page + "&" + type)return newrequestLogging
Scrapy提供了log功能。您可以通过 logging 模块使用。
Log levels
Scrapy提供5层logging级别:
- CRITICAL - 严重错误(critical)
- ERROR - 一般错误(regular errors)
- WARNING - 警告信息(warning messages)
- INFO - 一般信息(informational messages)
- DEBUG - 调试信息(debugging messages)
默认情况下python的logging模块将日志打印到了标准输出中且只显示了大于等于WARNING级别的日志这说明默认的日志级别设置为WARNING日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG默认的日志格式为DEBUG级别
如何设置log级别
您可以通过终端选项(command line option) --loglevel/-L 或 LOG_LEVEL 来设置log级别。
scrapy crawl tencent_crawl -L INFO
也可以修改配置文件settings.py添加 LOG_LEVEL='INFO'![]()
在Spider中添加log
Scrapy为每个Spider实例记录器提供了一个logger可以这样访问
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://scrapinghub.com']def parse(self, response):self.logger.info('Parse function called on %s', response.url)logger是用Spider的名称创建的但是你可以用你想要的任何自定义logging
例如:
import logging
import scrapylogger = logging.getLogger('zhangsan')class MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://scrapinghub.com']def parse(self, response):logger.info('Parse function called on %s', response.url)Logging设置
以下设置可以被用来配置logging:
LOG_ENABLED 默认: True启用logging
LOG_ENCODING 默认: 'utf-8'logging使用的编码
LOG_FILE 默认: Nonelogging输出的文件名
LOG_LEVEL 默认: 'DEBUG'log的最低级别
LOG_STDOUT 默认: False。如果为 True进程所有的标准输出(及错误)将会被重定向到log中。例如执行 print 'hello' 其将会在Scrapy log中显示。案例(一)
tencent_crawl.py添加日志信息如下
'''添加日志信息'''print 'print',response.urlself.logger.info('info on %s', response.url)self.logger.warning('WARNING on %s', response.url)self.logger.debug('info on %s', response.url)self.logger.error('info on %s', response.url)完整版如下
# -*- coding:utf-8 -*-
import scrapy
from tutorial.items import RecruitItem
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractorclass RecruitSpider(CrawlSpider):name = "tencent_crawl"allowed_domains = ["hr.tencent.com"]start_urls = ["http://hr.tencent.com/position.php?&start=0#a"]#提取匹配 'http://hr.tencent.com/position.php?&start=\d+'的链接page_lx = LinkExtractor(allow=('start=\d+'))rules = [#提取匹配,并使用spider的parse方法进行分析;并跟进链接(没有callback意味着follow默认为True)Rule(page_lx, callback='parseContent',follow=True)]def parseContent(self, response):#print("print settings: %s" % self.settings['LOG_FILE'])'''添加日志信息'''print 'print',response.urlself.logger.info('info on %s', response.url)self.logger.warning('WARNING on %s', response.url)self.logger.debug('info on %s', response.url)self.logger.error('info on %s', response.url)for sel in response.xpath('//*[@class="even"]'):name = sel.xpath('./td[1]/a/text()').extract()[0]detailLink = sel.xpath('./td[1]/a/@href').extract()[0]catalog =Noneif sel.xpath('./td[2]/text()'):catalog = sel.xpath('./td[2]/text()').extract()[0]recruitNumber = sel.xpath('./td[3]/text()').extract()[0]workLocation = sel.xpath('./td[4]/text()').extract()[0]publishTime = sel.xpath('./td[5]/text()').extract()[0]#print name, detailLink, catalog,recruitNumber,workLocation,publishTimeitem = RecruitItem()item['name']=nameitem['detailLink']=detailLinkif catalog:item['catalog']=catalogitem['recruitNumber']=recruitNumberitem['workLocation']=workLocationitem['publishTime']=publishTimeyield item在settings文件中修改添加信息
LOG_FILE='ten.log'
LOG_LEVEL='INFO'接下来执行scrapy crawl tencent_crawl
或者command line命令行执行
scrapy crawl tencent_crawl --logfile 'ten.log' -L INFO输出如下
print http://hr.tencent.com/position.php?start=10
print http://hr.tencent.com/position.php?start=1340
print http://hr.tencent.com/position.php?start=0
print http://hr.tencent.com/position.php?start=1320
print http://hr.tencent.com/position.php?start=1310
print http://hr.tencent.com/position.php?start=1300
print http://hr.tencent.com/position.php?start=1290
print http://hr.tencent.com/position.php?start=1260ten.log文件中记录可以看到级别大于INFO日志输出
2016-08-15 23:10:57 [tencent_crawl] INFO: info on http://hr.tencent.com/position.php?start=70
2016-08-15 23:10:57 [tencent_crawl] WARNING: WARNING on http://hr.tencent.com/position.php?start=70
2016-08-15 23:10:57 [tencent_crawl] ERROR: info on http://hr.tencent.com/position.php?start=70
2016-08-15 23:10:57 [tencent_crawl] INFO: info on http://hr.tencent.com/position.php?start=1320
2016-08-15 23:10:57 [tencent_crawl] WARNING: WARNING on http://hr.tencent.com/position.php?start=1320
2016-08-15 23:10:57 [tencent_crawl] ERROR: info on http://hr.tencent.com/position.php?start=1320案例(二)
tencent_spider.py添加日志信息如下
logger = logging.getLogger('zhangsan') '''添加日志信息'''print 'print',response.urlself.logger.info('info on %s', response.url)self.logger.warning('WARNING on %s', response.url)self.logger.debug('info on %s', response.url)self.logger.error('info on %s', response.url)完整版如下
import scrapy
from tutorial.items import RecruitItem
import re
import logginglogger = logging.getLogger('zhangsan')class RecruitSpider(scrapy.spiders.Spider):name = "tencent"allowed_domains = ["hr.tencent.com"]start_urls = ["http://hr.tencent.com/position.php?&start=0#a"]def parse(self, response):#logger.info('spider tencent Parse function called on %s', response.url)'''添加日志信息'''print 'print',response.urllogger.info('info on %s', response.url)logger.warning('WARNING on %s', response.url)logger.debug('info on %s', response.url)logger.error('info on %s', response.url)for sel in response.xpath('//*[@class="even"]'):name = sel.xpath('./td[1]/a/text()').extract()[0]detailLink = sel.xpath('./td[1]/a/@href').extract()[0]catalog =Noneif sel.xpath('./td[2]/text()'):catalog = sel.xpath('./td[2]/text()').extract()[0]recruitNumber = sel.xpath('./td[3]/text()').extract()[0]workLocation = sel.xpath('./td[4]/text()').extract()[0]publishTime = sel.xpath('./td[5]/text()').extract()[0]#print name, detailLink, catalog,recruitNumber,workLocation,publishTimeitem = RecruitItem()item['name']=nameitem['detailLink']=detailLinkif catalog:item['catalog']=catalogitem['recruitNumber']=recruitNumberitem['workLocation']=workLocationitem['publishTime']=publishTimeyield itemnextFlag = response.xpath('//*[@id="next"]/@href')[0].extract()if 'start' in nextFlag:curpage = re.search('(\d+)',response.url).group(1)page =int(curpage)+10url = re.sub('\d+',str(page),response.url)print urlyield scrapy.Request(url, callback=self.parse)在settings文件中修改添加信息
LOG_FILE='tencent.log'
LOG_LEVEL='WARNING'接下来执行scrapy crawl tencent
或者command line命令行执行
scrapy crawl tencent --logfile 'tencent.log' -L WARNING输出信息
print http://hr.tencent.com/position.php?&start=0
http://hr.tencent.com/position.php?&start=10
print http://hr.tencent.com/position.php?&start=10
http://hr.tencent.com/position.php?&start=20
print http://hr.tencent.com/position.php?&start=20
http://hr.tencent.com/position.php?&start=30tencent.log文件中记录可以看到级别大于INFO日志输出
2016-08-15 23:22:59 [zhangsan] WARNING: WARNING on http://hr.tencent.com/position.php?&start=0
2016-08-15 23:22:59 [zhangsan] ERROR: info on http://hr.tencent.com/position.php?&start=0
2016-08-15 23:22:59 [zhangsan] WARNING: WARNING on http://hr.tencent.com/position.php?&start=10
2016-08-15 23:22:59 [zhangsan] ERROR: info on http://hr.tencent.com/position.php?&start=10小试 LOG_STDOUT
settings.py
LOG_FILE='tencent.log'
LOG_STDOUT=True
LOG_LEVEL='INFO'执行scrapy crawl tencent
输出空
tencent.log文件中记录可以看到级别大于INFO日志输出
2016-08-15 23:28:32 [stdout] INFO: http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [stdout] INFO: print
2016-08-15 23:28:32 [stdout] INFO: http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [zhangsan] INFO: info on http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [zhangsan] WARNING: WARNING on http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [zhangsan] ERROR: info on http://hr.tencent.com/position.php?&start=110
2016-08-15 23:28:32 [stdout] INFO: http://hr.tencent.com/position.php?&start=120
2016-08-15 23:28:33 [stdout] INFO: print
2016-08-15 23:28:33 [stdout] INFO: http://hr.tencent.com/position.php?&start=120
2016-08-15 23:28:33 [zhangsan] INFO: info on http://hr.tencent.com/position.php?&start=120
2016-08-15 23:28:33 [zhangsan] WARNING: WARNING on http://hr.tencent.com/position.php?&start=120
2016-08-15 23:28:33 [zhangsan] ERROR: info on http://hr.tencent.com/position.php?&start=120scrapy之Logging使用
#coding:utf-8
######################
##Logging的使用
######################
import logging
'''
1. logging.CRITICAL - for critical errors (highest severity) 致命错误
2. logging.ERROR - for regular errors 一般错误
3. logging.WARNING - for warning messages 警告错误
4. logging.INFO - for informational messages 消息警告错误
5. logging.DEBUG - for debugging messages (lowest severity) 低级别
'''
logging.warning("This is a warning")logging.log(logging.WARNING,"This is a warning")#获取实例对象
logger=logging.getLogger()
logger.warning("这是警告消息")
#指定消息发出者
logger = logging.getLogger('SimilarFace')
logger.warning("This is a warning")#在爬虫中使用log
import scrapy
class MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://scrapinghub.com']def parse(self, response):#方法1 自带的loggerself.logger.info('Parse function called on %s', response.url)#方法2 自己定义个loggerlogger.info('Parse function called on %s', response.url)'''
Logging 设置
• LOG_FILE
• LOG_ENABLED
• LOG_ENCODING
• LOG_LEVEL
• LOG_FORMAT
• LOG_DATEFORMAT • LOG_STDOUT命令行中使用
--logfile FILE
Overrides LOG_FILE--loglevel/-L LEVEL
Overrides LOG_LEVEL--nolog
Sets LOG_ENABLED to False
'''import logging
from scrapy.utils.log import configure_loggingconfigure_logging(install_root_handler=False)
#定义了logging的些属性
logging.basicConfig(filename='log.txt',format='%(levelname)s: %(levelname)s: %(message)s',level=logging.INFO
)
#运行时追加模式
logging.info('进入Log文件')
logger = logging.getLogger('SimilarFace')
logger.warning("也要进入Log文件")Settings
Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core)插件(extension)pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL
内置设置列表请参考内置设置参考手册
获取设置值(Populating the settings)
设置可以通过多种方式设置每个方式具有不同的优先级。 下面以优先级降序的方式给出方式列表:
命令行选项(Command line Options)(最高优先级) 每个spider的设置 项目设置模块(Project settings module)
命令行选项(Command line options) 命令行传入的参数具有最高的优先级。 您可以使用command line 选项 -s (或 --set) 来覆盖一个(或更多)选项。
scrapy crawl myspider -s LOG_FILE=scrapy.log每个spider的设置 scrapy.spiders.Spider.custom_settings
class MySpider(scrapy.Spider):name = 'myspider'custom_settings = {'SOME_SETTING': 'some value',}项目设置模块(Project settings module) 项目设置模块是您Scrapy项目的标准配置文件
myproject.settings如何访问配置(settings)
In a spider, the settings are available through self.settings:
class MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://example.com']def parse(self, response):print("Existing settings: %s" % self.settings.attributes.keys())Settings can be accessed through the scrapy.crawler.Crawler.settings attribute of the Crawler that is passed to from_crawler method in extensions, middlewares and item pipelines:
class MyExtension(object):def __init__(self, log_is_enabled=False):if log_is_enabled:print("log is enabled!")@classmethoddef from_crawler(cls, crawler):settings = crawler.settingsreturn cls(settings.getbool('LOG_ENABLED'))案例
添加一行代码 print("Existing settings: %s" % self.settings['LOG_FILE'])
# -*- coding:utf-8 -*-
import scrapy
from tutorial.items import RecruitItem
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
import loggingclass RecruitSpider(CrawlSpider):name = "tencent_crawl"allowed_domains = ["hr.tencent.com"]start_urls = ["http://hr.tencent.com/position.php?&start=0#a"]#提取匹配 'http://hr.tencent.com/position.php?&start=\d+'的链接page_lx = LinkExtractor(allow=('start=\d+'))rules = [#提取匹配,并使用spider的parse方法进行分析;并跟进链接(没有callback意味着follow默认为True)Rule(page_lx, callback='parseContent',follow=True)]def parseContent(self, response):print response.urlprint("Existing settings: %s" % self.settings['LOG_FILE'])self.logger.info('Parse function called on %s', response.url)for sel in response.xpath('//*[@class="even"]'):name = sel.xpath('./td[1]/a/text()').extract()[0]detailLink = sel.xpath('./td[1]/a/@href').extract()[0]catalog =Noneif sel.xpath('./td[2]/text()'):catalog = sel.xpath('./td[2]/text()').extract()[0]recruitNumber = sel.xpath('./td[3]/text()').extract()[0]workLocation = sel.xpath('./td[4]/text()').extract()[0]publishTime = sel.xpath('./td[5]/text()').extract()[0]#print name, detailLink, catalog,recruitNumber,workLocation,publishTimeitem = RecruitItem()item['name']=name.encode('utf-8')item['detailLink']=detailLink.encode('utf-8')if catalog:item['catalog']=catalog.encode('utf-8')item['recruitNumber']=recruitNumber.encode('utf-8')item['workLocation']=workLocation.encode('utf-8')item['publishTime']=publishTime.encode('utf-8')yield item内置设置参考手册
BOT_NAME默认: 'scrapybot'。当您使用 startproject 命令创建项目时其也被自动赋值。
CONCURRENT_ITEMS默认: 100。Item Processor(即 Item Pipeline) 同时处理(每个response的)item的最大值。
CONCURRENT_REQUESTS默认: 16。Scrapy downloader 并发请求(concurrent requests)的最大值。
DEFAULT_REQUEST_HEADERS 默认:
{'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}
Scrapy HTTP Request使用的默认header。
DEPTH_LIMIT默认: 0。爬取网站最大允许的深度(depth)值。如果为0则没有限制。
DOWNLOAD_DELAY默认: 0。下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度 减轻服务器压力。同时也支持小数:
DOWNLOAD_DELAY = 0.25 # 250 ms of delay
该设置影响(默认启用的) RANDOMIZE_DOWNLOAD_DELAY 设置。 默认情况下Scrapy在两个请求间不等待一个固定的值 而是使用0.5到1.5之间的一个随机值 * DOWNLOAD_DELAY 的结果作为等待间隔。
DOWNLOAD_TIMEOUT默认: 180。下载器超时时间(单位: 秒)。
ITEM_PIPELINES默认: {}。保存项目中启用的pipeline及其顺序的字典。该字典默认为空值(value)任意。 不过值(value)习惯设置在0-1000范围内。
样例:
ITEM_PIPELINES = {
'mybot.pipelines.validate.ValidateMyItem': 300,
'mybot.pipelines.validate.StoreMyItem': 800,
}
LOG_ENABLED默认: True。是否启用logging。
LOG_ENCODING默认: 'utf-8'。logging使用的编码。
LOG_LEVEL默认: 'DEBUG'。log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG 。
USER_AGENT默认: "Scrapy/VERSION (+http://scrapy.org)"。爬取的默认User-Agent除非被覆盖。阳光热线问政平台
http://wz.sun0769.com/index.php/question/questionType?type=4
items.py添加以下代码
from scrapy.item import Item, Fieldclass SunItem(Item):number = Field()url = Field()title = Field()content = Field()在spiders目录下新建一个自定义SunSpider.py
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from tutorial.items import SunItem
import scrapy
import urllib
import time
import reclass SunSpider(CrawlSpider):name = 'sun0769'num = 0allow_domain = ['http://wz.sun0769.com/']start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4']rules = {Rule(LinkExtractor(allow='page'), process_links='process_request', follow=True),Rule(LinkExtractor(allow='/html/question/\d+/\d+\.shtml$'), callback='parse_content')}def process_request(self, links):ret=[]for link in links:try:page = re.search('page=\d*', link.url).group()type = re.search('type=\d+', link.url).group()link.url ='http://wz.sun0769.com/index.php/question/questionType?' + page + "&" + typeexcept Exception, e:passret.append(link)return retdef parse_content(self, response):item = SunItem()url = response.urltitle = response.xpath('//*[@class="greyframe"]/div/div/strong/text()')[0].extract().strip()number = response.xpath('//*[@class="greyframe"]/div/div/strong/text()')[0].extract().strip().split(':')[-1]content = response.xpath('//div[@class="c1 text14_2"]/text()').extract()[0].strip()item['url'] = urlitem['title'] = titleitem['number'] = numberitem['content'] = contentyield item在pipelines.py添加如下代码
import json
import codecsclass JsonWriterPipeline(object):def __init__(self):self.file = codecs.open('items.json', 'w', encoding='utf-8')def process_item(self, item, spider):line = json.dumps(dict(item), ensure_ascii=False) + "\n"self.file.write(line)return itemdef spider_closed(self, spider):self.file.close()settings.py:添加如下代码启用组件
ITEM_PIPELINES = {'tutorial.pipelines.JsonWriterPipeline': 300,
}window 下调试
在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline
cmdline.execute('scrapy crawl sun0769'.split())scrapy案例和scrapyd部署
简历设计
腾讯招聘
http://hr.tencent.com/position.php
items.py添加以下代码
from scrapy.item import Item, Fieldclass TencentItem(Item):title = Field()catalog = Field()workLocation = Field()recruitNumber = Field()duty = Field()Job_requirement= Field()url = Field()publishTime = Field()在spiders目录下新建一个自定义tencent_info.py
# -*- coding:utf-8 -*-
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import re
from tutorial.items import TencentItemclass TencentSpider(CrawlSpider):name = "tengxun_info"allowed_domains = ["tencent.com"]start_urls = ["http://hr.tencent.com/position.php"]rules = [Rule(LinkExtractor(allow=("start=\d+"))),Rule(LinkExtractor(allow=("position_detail\.php")), follow=True, callback='parse_item')]def parse_item(self,response):item =TencentItem()title = response.xpath('//*[@id="sharetitle"]/text()')[0].extract()workLocation = response.xpath('//*[@class="lightblue l2"]/../text()')[0].extract()catalog = response.xpath('//*[@class="lightblue"]/../text()')[0].extract()recruitNumber = response.xpath('//*[@class="lightblue"]/../text()').re('(\d+)')[0]duty_pre = response.xpath('//*[@class="squareli"]')[0].extract()duty = re.sub('<.*?>','',duty_pre)Job_requirement_pre = response.xpath('//*[@class="squareli"]')[1].extract()Job_requirement = re.sub('<.*?>','',Job_requirement_pre)item['title']=titleitem['url']=response.urlitem['workLocation']=workLocationitem['catalog']=catalogitem['recruitNumber']=recruitNumberitem['duty']=dutyitem['Job_requirement']=Job_requirementyield item在pipelines.py添加如下代码
import json
import codecsclass JsonWriterPipeline(object):def __init__(self):self.file = codecs.open('items.json', 'w', encoding='utf-8')def process_item(self, item, spider):line = json.dumps(dict(item), ensure_ascii=False) + "\n"self.file.write(line)return itemdef spider_closed(self, spider):self.file.close()settings.py:添加如下代码启用组件
ITEM_PIPELINES = {'tutorial.pipelines.JsonWriterPipeline': 300,
}在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline
cmdline.execute('scrapy crawl tengxun_info'.split())国家食品药品监督管理总局
http://app1.sfda.gov.cn/datasearch/face3/dir.html
items.py添加以下代码
from scrapy import Field
import scrapyclass Sfda1Item(scrapy.Item):# define the fields for your item here like:data = scrapy.Field()在spiders目录下新建一个自定义spider
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import FormRequest
from tutorial.items import Sfda1Item
import urllib
import reclass sfdaSpider(scrapy.Spider):name = 'sfda'allowed_domains = ['sfda.gov.cn']def start_requests(self):url = 'http://app1.sfda.gov.cn/datasearch/face3/search.jsp'data = {'tableId': '32','State': '1','bcId': '124356639813072873644420336632','State': '1','tableName': 'TABLE32','State': '1','viewtitleName': 'COLUMN302','State': '1','viewsubTitleName': 'COLUMN299,COLUMN303','State': '1','curstart': '1','State': '1','tableView': urllib.quote("国产药品商品名"),'State': '1',}yield FormRequest(url=url, formdata=data, meta={'data': data}, callback=self.parseContent)def parseContent(self, response):for site in response.xpath('//a').re(r'callbackC,\'(.*?)\',null'):id = re.search('.+Id=(.*?)$', site).group(1)#print idurl = 'http://app1.sfda.gov.cn/datasearch/face3/content.jsp?tableId=32&tableName=TABLE32&tableView=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&Id=' + idyield scrapy.Request(url,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'},callback=self.ParseDetail)data = response.meta['data']data['curstart'] = str(int(data['curstart']) + 1)yield FormRequest(url=response.request.url, formdata=data, meta={'data': data}, callback=self.parseContent)def ParseDetail(self, response):item = dict()for site in response.xpath('//table[1]/.//tr')[1:-1]:try:if not site.xpath('./td/text()').extract()[0]:continuename = site.xpath('./td/text()').extract()[0]value = re.sub('<.*?>', '', site.xpath('./td')[1].extract()).strip()print name, valueitem[name] = valueexcept Exception, e:print 'error', esfa = Sfda1Item()sfa['data'] = itemyield sfa在pipelines.py添加如下代码
import json
import codecsclass JsonWriterPipeline(object):def __init__(self):self.file = codecs.open('items.json', 'w', encoding='utf-8')def process_item(self, item, spider):line = json.dumps(dict(item), ensure_ascii=False) + "\n"self.file.write(line)return itemdef spider_closed(self, spider):self.file.close()settings.py:添加如下代码启用组件
ITEM_PIPELINES = {'tutorial.pipelines.JsonWriterPipeline': 300,
}在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline
cmdline.execute('scrapy crawl sfda -L INFO'.split())使用scrapyd 管理爬虫
scrapyd 是由scrapy 官方提供的爬虫管理工具使用它我们可以非常方便地上传、控制爬虫并且查看运行日志。
参考官方文档 : http://scrapyd.readthedocs.org/en/latest/api.html
使用scrapyd 和我们直接运行
scrapy crawl myspider有什么区别呢
scrapyd 同样是通过上面的命令运行爬虫的不同的是它提供一个JSON web service 监听的请求
我们可以从任何一台可以连接到服务器的电脑发送请求安排爬虫运行或者停止正在运行的爬虫。
甚至我们可以使用它提供的API上传新爬虫而不必登录到服务器上进行操作。
安装scrapyd
pip install scrapyd
参考文档https://github.com/scrapy/scrapyd-client
运行scrapyd 服务
直接运行命令scrapyd即可
scrapyd默认情况下scrapyd 监听 0.0.0.0:6800 端口运行scrapyd 后在浏览器http://localhost:6800/ 即可查看到当前可以运行的项目
- web接口
http://localhost:6800/
部署scrapy 项目
直接使用scrapyd-client提供的scrapyd-deploy工具.
pip install scrapyd-client直接在项目根目录
修改工程目录下的 scrapy.cfg 文件
[deploy:scrapyd2] #默认情况下并没有scrapyd2它只是一个名字可以在配置文件中写多个名字不同的deploy
url = http://scrapyd.mydomain.com/api/scrapyd/ #要部署项目的服务器的地址
username = john #访问服务器所需的用户名和密码如果不需要密码可以不写
password = secret其中的username 和 password 用于在部署时验证服务器的HTTP basic authentication须要注意的是这里的用户密码并不表示访问该项目须要验证而是登录服务器用的。
Ubuntu/Windows:
[deploy:tutorial_deploy]
url = http://192.168.17.129:6800/
project = tutorial
username = enlong
password = test部署项目到服务器
直接在项目根目录
Windows:
python c:\Python27\Scripts\scrapyd-deploy![]()
Ubuntu:
scrapyd-deploy tutorial_deploy -p tutorial![]()
部署操作会打包你的当前项目如果当前项目下有setup.py文件就会使用它没有的会就会自动创建一个。
(如果后期项目需要打包的话可以根据自己的需要修改里面的信息也可以暂时不管它).
从返回的结果里面可以看到部署的状态项目名称版本号和爬虫个数以及当前的主机名称.
查看项目spider
通过scrapyd-deploy -l 查看当前目录下的可以使用的部署方式target
Windows/Ubuntu
scrapy list
scrapyd-deploy -l![]()
或再次打开http://localhost:6800/, 也可以看到Available projects: default, tutorial
列出服务器上所有的项目检查tutorial_deploy是否已经部署上去了:
scrapyd-deploy -L tutorial_deploy
default
tutorialAPI
scrapyd的web界面比较简单主要用于监控所有的调度工作全部依靠接口实现.
参考官方文档http://scrapyd.readthedocs.org/en/stable/api.html
开启爬虫 schedule
curl http://localhost:6800/schedule.json -d project=tutorial -d spider=tencentWindows/Ubuntu 注意执行时 cd 到项目根目录执行curl http://localhost:6800/schedule.json -d project=tutorial -d spider=tencent
{"status": "ok", "jobid": "94bd8ce041fd11e6af1a000c2969bafd", "node_name": "ubuntu"}![]()
停止 cancel
curl http://localhost:6800/cancel.json -d project=tutorial -d job=94bd8ce041fd11e6af1a000c2969bafd列出爬虫
curl http://localhost:6800/listspiders.json?project=tutorial删除项目
curl http://localhost:6800/delproject.json -d project=tutorial更新
对于scrapyd默认项目(即是启动scrapyd命令后看到的default项目)
只有在scrapy项目里启动scrapyd命令时才有默认项目默认项目就是当前的scrapy项目
如果在非scrapy项目下执行scrapyd, 是看不到default的
![]()
![]()
注意执行时 cd 到项目根目录执行
第一种情况
cfg:[deploy]
url = http://192.168.17.129:6800/
project = tutorial
username = enlong
password = test
运行结果
python@ubuntu:~/project/tutorial$ scrapyd-deploy
Packing version 1471069533
Deploying to project "tutorial" in http://192.168.17.129:6800/addversion.json
Server response (200):
{"status": "ok", "project": "tutorial", "version": "1471069533", "spiders": 1, "node_name": "ubuntu"}第二种情况
cfg:[deploy:tutorial_deploy]
url = http://192.168.17.129:6800/
project = tutorial
username = enlong
password = test
运行结果
python@ubuntu:~/project/tutorial$ scrapyd-deploy tutorial_deploy
Packing version 1471069591
Deploying to project "tutorial" in http://192.168.17.129:6800/addversion.json
Server response (200):
{"status": "ok", "project": "tutorial", "version": "1471069591", "spiders": 1, "node_name": "ubuntu"}为scrapyd创建服务
Systemd 是 Linux 系统工具用来启动守护进程已成为大多数发行版的标准配置。首先检查你的系统中是否安装有systemd并确定当前安装的版本
Systemd 入门教程命令篇
Systemd 入门教程实战篇
systemd --version
sudo vi /lib/systemd/system/scrapyd.serviceThen add the following line into that file:
[Unit]
Description=scrapyd
After=network.target
Documentation=http://scrapyd.readthedocs.org/en/latest/api.html[Service]
User=root
ExecStart=/usr/local/bin/scrapyd --logfile /var/scrapyd/scrapyd.log[Install]
WantedBy=multi-user.target[Unit]区块通常是配置文件的第一个区块用来定义 Unit 的元数据以及配置与其他 Unit 的关系
After如果该字段指定的 Unit After 也要启动那么必须在当前 service 之前启动
Documentation服务文档地址
Description简短描述[Service]区块用来 Service 的配置只有 Service 类型的 Unit 才有这个区块
ExecStart启动当前服务的命令[Install]通常是配置文件的最后一个区块用来定义如何启动以及是否开机启动
WantedBy它的值是一个或多个 Target当前 Unit 激活时enable符号链接会放入/etc/systemd/system目录下面以 Target 名 + .wants后缀构成的子目录中At this point, we can now start our new service by running the command below:
sudo systemctl start scrapyd
sudo service scrapyd startTo check the status of the service, issue the following command:
sudo systemctl status scrapyd开机启动
To make the services start at boot time, use the command below:
sudo systemctl enable scrapyd
Created symlink from /etc/systemd/system/multi-user.target.wants/scrapyd.service to /lib/systemd/system/scrapyd.service.取消开机启动
sudo systemctl disable scrapydscrapyd 服务器添加认证信息
我们也可以在scrapyd前面加一层反向代理来实现用户认证。以nginx为例, 配置nginx
安装nginx
sudo apt-get install nginx配置nginx
vi /etc/nginx/nginx.conf 修改如下
# Scrapyd local proxy for basic authentication.
# Don't forget iptables rule.
# iptables -A INPUT -p tcp --destination-port 6800 -s ! 127.0.0.1 -j DROPhttp {server {listen 6801;location / {proxy_pass http://127.0.0.1:6800/;auth_basic "Restricted";auth_basic_user_file /etc/nginx/conf.d/.htpasswd;}}
}/etc/nginx/htpasswd/user.htpasswd里设置的用户名 enlong和密码都是test 修改配置文件添加用户信息
Nginx使用htpasswd创建用户认证
python@ubuntu:/etc/nginx/conf.d$ sudo htpasswd -c .htpasswd enlong
New password:
Re-type new password:
Adding password for user enlong
python@ubuntu:/etc/nginx/conf.d$ cat .htpasswd
enlong:$apr1$2slPhvee$6cqtraHxoxclqf1DpqIPM.python@ubuntu:/etc/nginx/conf.d$ sudo htpasswd -bc .htpasswd admin adminapache htpasswd命令用法实例
1、如何利用htpasswd命令添加用户
htpasswd -bc .passwd www.leapsoul.cn php
在bin目录下生成一个.passwd文件用户名www.leapsoul.cn密码php默认采用MD5加密方式
2、如何在原有密码文件中增加下一个用户
htpasswd -b .passwd leapsoul phpdev
去掉c选项即可在第一个用户之后添加第二个用户依此类推
重启nginx
sudo service nginx restart
测试Nginx
F:\_____gitProject_______\curl-7.33.0-win64-ssl-sspi\tieba_baidu>curl http://localhost:6800/schedule.json -d project=tutorial -d spider=tencent -u enlong:test
{"status": "ok", "jobid": "5ee61b08428611e6af1a000c2969bafd", "node_name": "ubuntu"}配置scrapy.cfg文件
[deploy]
url = http://192.168.17.129:6801/
project = tutorial
username = admin
password = admin
注意上面的url已经修改为了nginx监听的端口。
提醒: 记得修改服务器上scrapyd的配置bind_address字段为127.0.0.1以免可以从外面绕过nginx, 直接访问6800端口。 关于配置可以参看本文后面的配置文件设置.
修改配置文件
sudo vi /etc/scrapyd/scrapyd.conf
[scrapyd]
bind_address = 127.0.0.1
scrapyd启动的时候会自动搜索配置文件配置文件的加载顺序为
/etc/scrapyd/scrapyd.conf /etc/scrapyd/conf.d/* scrapyd.conf ~/.scrapyd.conf
最后加载的会覆盖前面的设置
默认配置文件如下, 可以根据需要修改
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir = items
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
关于配置的各个参数具体含义可以参考官方文档http://scrapyd.readthedocs.io/en/stable/config.html
采集感兴趣的网站1京东 2豆瓣 3论坛 。。。。
进阶篇移动篇
模拟手机应用进行抓包
前提条件是安装Fiddler的机器跟智能手机 在同一个网络里 否则智能手机不能把HTTP发送到Fiddler的机器上来。
配置Fiddler, 允许"远程连接"。用Fiddler对Android应用进行抓包
启动Fiddler打开菜单栏中的 Tools > Fiddler Options打开“Fiddler Options”对话框。
![]()
在Fiddler Options”对话框切换到“Connections”选项卡然后勾选“Allow romote computers to connect”后面的复选框然后点击“OK”按钮。
![]()
在本机命令行输入ipconfig找到本机的ip地址。
![]()
下面来设置Android设备上的代理服务器
打开android设备的“设置”->“WLAN”找到你要连接的网络在上面长按然后选择“修改网络”弹出网络设置对话框在接下来弹出的对话框中勾选“显示高级选项”。在接下来显示的页面中点击“代理”选择“手动”。
在“代理”后面的输入框选择“手动”在“代理服务器主机名”后面的输入框输入电脑的ip地址在“代理服务器端口”后面的输入框输入8888然后点击“保存”按钮。
代理服务器主机名设为PC的IP代理服务器端口设为Fiddler上配置的端口8888点"保存"。
![]()
然后启动android设备中的浏览器访问百度的首页在fiddler中可以看到完成的请求和响应数据。
![]()
用Fiddler对IOS应用进行抓包
打开IPhone, 找到你的网络连接 打开HTTP代理 输入Fiddler所在机器的IP地址(比如:192.168.1.104) 以及Fiddler的端口号8888
![]()
只能捕获HTTP,而不能捕获HTTPS的解决办法
为了让Fiddler能捕获HTTPS请求。如果你只需要截获HTTP请求 可以忽略这一步
- 首先要知道Fiddler所在的机器的IP地址 假如我安装了Fiddler的机器的IP地址是:192.168.1.104
- 打开IPhone 的Safari, 访问 http://192.168.0.52:8888 点"FiddlerRoot certificate" 然后安装证书
![]()
![]()
过证书校验
上面的设置还不能抓像招商银行、支付宝等APP的https包因为这些APP对https证书进行了校验还需要将Fiddler代理服务器的证书导到Android设备上才能抓这些APP的包
导入的过程:
打开浏览器在地址栏中输入代理服务器的IP和端口会看到一个Fiddler提供的页面
![]()
点击页面中的“FiddlerRootcertificate”链接接着系统会弹出对话框
![]()
输入一个证书名称然后直接点“确定”就好了。
注意用完了 记得把IPhone上的Fiddler代理关闭 以免IPhone上不了网。
夜神android模拟器设置代理的方法
app开发测试为了调试方便通常会在电脑上装一些android模拟器开多台进行测试。调试中通常要干的一件事就是抓取那么想要抓包我们必须要设置代理。
夜神android模拟机设置代理的方法
- 点击设置然后进入到wifi连接选项。 如图1
![]()
进入列表后鼠标点击wifi位置长按左键会出现一个修改网络的弹窗如下图
![]()
点击上图中的“修改网络”会出现下图中的弹窗勾选“显示高级选项”
![]()
接着一切都明了了代理服务器主机名填写你电脑的ip就行了window系统的话用ipconfig查看接着再填写端口
![]()
斗鱼App妹子图下载
创建项目'douyu'
scrapy startproject douyu树形图展示项目
cd douyu/
tree![]()
Sublime打开项目
subl .![]()
生成采集模块spider
genspider 在当前项目中创建spider。
语法: scrapy genspider [-t template] <name> <domain>$ scrapy genspider -l
Available templates:basiccrawlcsvfeedxmlfeed$ scrapy genspider -d basic
import scrapyclass $classname(scrapy.Spider):name = "$name"allowed_domains = ["$domain"]start_urls = ('http://www.$domain/',)def parse(self, response):pass$ scrapy genspider -t basic example example.com
Created spider 'example' using template 'basic' in module:mybot.spiders.example创建
scrapy genspider douyu_spider douyucdn.cn
![]()
编辑项目
item.py
import scrapyclass DouyuItem(scrapy.Item):# define the fields for your item here like:data = scrapy.Field()image_path = scrapy.Field()passsetting.py
设置 USER_AGENT
USER_AGENT = 'DYZB/2.271 (iPhone; iOS 9.3.2; Scale/3.00)'douyu_spider.py
# -*- coding: utf-8 -*-
import scrapy'''添加内容'''
from douyu.items import DouyuItem
import jsonclass DouyuSpiderSpider(scrapy.Spider):name = 'douyu_spider'allowed_domains = ["douyucdn.cn"]'''添加内容'''offset = 0start_urls = ('http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset='+str(offset),)def parse(self, response):'''添加内容'''data=json.loads(response.body)['data']if not data:returnfor it in data:item = DouyuItem()item['image_url']=it['vertical_src']item['data']=ityield itemself.offset+=20yield scrapy.Request('http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=%s'%str(self.offset),callback=self.parse)pipeline.py
文件系统存储: 文件以它们URL的 SHA1 hash 作为文件名
sha1sum sha1sum对文件进行唯一较验的hash算法
用法: sha1sum [OPTION] [FILE]... 参数 -b, --binary 二进制模式读取 -c, --check 根据sha1 num检查文件 -t, --text 文本模式读取默认
举例
f51be4189cce876f3b1bbc1afb38cbd2af62d46b scrapy.cfg{ 'image_path': 'full/9fdfb243d22ad5e85b51e295fa60e97e6f2159b2.jpg', 'image_url': u'http://staticlive.douyucdn.cn/upload/appCovers/845876/20160816/c4eea823766e2e5e018eee6563e4c420_big.jpg' }测试
sudo vi test.txt
拷贝内容
http://staticlive.douyucdn.cn/upload/appCovers/845876/20160816/c4eea823766e2e5e018eee6563e4c420_big.jpg
sha1sum test.txt
9fdfb243d22ad5e85b51e295fa60e97e6f2159b2 test.txt
参考文档:
http://doc.scrapy.org/en/latest/topics/media-pipeline.html
注意 项目环境 Scrapy 1.0.3 class scrapy.pipelines.images.ImagesPipeline 项目环境 Scrapy 1.0 class scrapy.pipeline.images.ImagesPipeline
下面是你可以在定制的图片管道里重写的方法
class scrapy.pipelines.images.ImagesPipeline
get_media_requests(item, info)
管道会得到文件的URL并从项目中下载。需要重写 get_media_requests() 方法并对各个图片URL返回一个Request
def get_media_requests(self, item, info):for image_url in item['image_urls']:yield scrapy.Request(image_url)当它们完成下载后结果将以2-元素的元组列表形式传送到item_completed() 方法 results 参数: 每个元组包含 (success, file_info_or_error):
success是一个布尔值当图片成功下载时为True因为某个原因下载失败为Falsefile_info_or_error是一个包含下列关键字的字典如果成功为 True或者出问题时为Twisted Failure- url - 文件下载的url。这是从 get_media_requests() 方法返回请求的url。
- path - 图片存储的路径
- checksum - 图片内容的
MD5 hash
下面是
item_completed(results, items, info)中 results 参数的一个典型值:
[(True,
{'checksum': '2b00042f7481c7b056c4b410d28f33cf','path': 'full/0a79c461a4062ac383dc4fade7bc09f1384a3910.jpg','url': 'http://staticlive.douyucdn.cn/upload/appCovers/420134/20160807/f18f869128d038407742a7c533070daf_big.jpg'}),
(False,
Failure(...))]默认 get_media_requests() 方法返回 None 这意味着项目中没有文件可下载。
item_completed(results, items, info)
当图片请求完成时要么完成下载要么因为某种原因下载失败,该方法将被调用
item_completed() 方法需要返回一个输出其将被送到随后的项目管道阶段因此你需要返回或者丢弃项目
举例
其中我们将下载的图片路径传入到results中存储到file_paths 项目组中如果其中没有图片我们将丢弃项目:
from scrapy.exceptions import DropItemdef item_completed(self, results, item, info):image_paths = [x['path'] for ok, x in results if ok]'''image_paths=s[]for ok, x in results:if ok:image_paths.append(x['path'])return image_paths'''if not image_paths :raise DropItem("Item contains no images")item['image_paths'] = image_pathsreturn item默认情况下item_completed()方法返回项目
定制图片管道:
下面是项目图片管道
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItemclass ImagesPipeline(ImagesPipeline):def get_media_requests(self, item, info):image_url = item['image_url']yield scrapy.Request(image_url)def item_completed(self, results, item, info):image_paths = [x['path'] for ok, x in results if ok]if not image_paths:raise DropItem("Item contains no images")item['image_path'] = image_paths[0]return item启用pipelines
设置图片下载位置
是定义在 IMAGES_STORE 设置里的文件夹
IMAGES_STORE = '/home/python/project/douyu/photos'启用PIPELINES设置item后处理模块
ITEM_PIPELINES = {
'douyu.pipelines.ImagesPipeline': 300,
}运行爬虫
scrapy runspider douyu/spiders/douyu_spider.py
或者是 scrapy crawl douyu_spider项目还缺什么
item存储
pipeline.py编写
import json
import codecsclass JsonWriterPipeline(object):def __init__(self):self.file = codecs.open('items.json', 'w', encoding='utf-8')def process_item(self, item, spider):line = json.dumps(dict(item), ensure_ascii=False) + "\n"self.file.write(line)return itemdef spider_closed(self, spider):self.file.close()启用JsonWriterPipeline编写
ITEM_PIPELINES = {'douyu.pipelines.ImagesPipeline': 300,'douyu.pipelines.JsonWriterPipeline': 800,
}再次运行
scrapy crawl douyu_spider美团App热门商圈团购采集(1)
环境针对美团版本5.4
![]()
在tutorial项目下
新建一个spider
scrapy genspider -t basic Meituan_City meituan.com编辑items.py
class MeituanCity(Item):
data = Field()编辑 Meituan_City.py
# -*- coding: utf-8 -*-
import scrapy
import json
from tutorial.items import MeituanCityclass MeituanCitySpider(scrapy.Spider):name = "Meituan_City"allowed_domains = ["meituan.com"]start_urls = ('http://api.mobile.meituan.com/group/v1/city/list?show=all',)def parse(self, response):data = json.loads(response.body)for item in data['data']:cityId = item['id']# http://api.mobile.meituan.com/group/v2/area/list?cityId=42&spatialFields=centerurl = 'http://api.meituan.com/group/v2/area/list?cityId=%s&spatialFields=center' % cityIdprint urlyield scrapy.Request(url,callback=self.Parse_Geo,meta={'item': item})breakdef Parse_Geo(self, response):print response.urldata = json.loads(response.body)metaitem = response.meta['item']# 商区信息subareasinfo = dict()if 'data' in data:if 'subareasinfo' in data['data']:for item in data['data']['subareasinfo']:subareasinfo[item['id']] = itemif 'data' in data:if 'areasinfo' in data['data']:for line in data['data']['areasinfo']:# 行政区districtName = line['name']districtId = line['id']for tmp in line['subareas']:# 商圈信息area = subareasinfo[tmp]center = area['center']center = center.replace('POINT(', '').replace(')', '').split()if len(center) > 1:lat = center[1]lng = center[0]longitude = Nonelatitude = Nonetry:longitude = str(int(float(lng) * 1000000))latitude = str(int(float(lat) * 1000000))except:passItem = MeituanCity()Item['data'] =dict()geoItem=Item['data'] # 城市信息geoItem['cityid'] = metaitem['id']geoItem['cityname'] = metaitem['name']# 行政区geoItem['districtId'] = districtIdgeoItem['districtName'] = districtName# 商圈geoItem['SubAreaId'] = area['id']geoItem['secondArea'] = area['name']# 经纬度geoItem['longitude'] = longitudegeoItem['latitude'] = latitudeyield Item此时运行
scrapy runspider tutorial/spiders/Meituan_City.py美团App热门商圈团购采集(2)
把上节内容生成的城市信息 items.json改成city_items.json 作为第二部分爬虫的启动数据
添加items.py
class MeituanItem(Item):data = Field()创建模板
scrapy genspider -t basic Meituan_meishi meituan.com添加以下代码到Meituan_meishi.py
# -*- coding: utf-8 -*-
import scrapy
import codecs
import json
from tutorial.items import MeituanItem
import reclass MeituanMeishiSpider(scrapy.Spider):'''美食团购页面信息采集'''name = "Meituan_meishi"allowed_domains = ["meituan.com"]'''start_urls = ('http://www.meituan.com/',)'''offset = 0def start_requests(self):file = codecs.open('city_items.json', 'r', encoding='utf-8')for line in file:item = json.loads(line)cityid = item['data']['cityid']latitude = item['data']['latitude']longitude= item['data']['longitude']lat = round(float(latitude), 6)lng= round(float(longitude), 6)url = 'http://api.mobile.meituan.com/group/v4/deal/select/city/42/cate/1?sort=defaults&mypos='+ str(lat) +'%2C'+ str(lng) +'&offset=0&limit=15'yield scrapy.Request(url,callback=self.parse)breakfile.close()def parse(self, response):'''数据存储以及翻页操作'''item = MeituanItem()data = json.loads(response.body)item['data']=dict()item['data'] = datayield itemoffset = re.search('offset=(\d+)',response.request.url).group(1)url = re.sub('offset=\d+','offset='+str(int(offset)+15),response.request.url)yield scrapy.Request(url,callback=self.parse)运行scrapy runspider tutorial/spiders/Meituan_meishi.py
采集方案策略设计
首先大的地方我们想抓取某个数据源我们要知道大概有哪些路径可以获取到数据源基本上无外乎三种
PC端网站
针对移动设备响应式设计的网站也就是很多人说的H5, 虽然不一定是H5
移动App
原则是能抓移动App的最好抓移动App如果有针对移动设备优化的网站就抓针对移动设备优化的网站最后考虑PC网站。因为移动App基本都是API很简单而移动设备访问优化的网站一般来讲都是结构简单清晰的HTML而PC网站自然是最复杂的了
针对PC端网站和移动网站的做法一样分析思路可以一起讲移动App单独分析。
网站类型的分析
首先是网站类的使用的工具就是Chrome建议用Chrome的隐身模式分析时不用频繁清除cookie直接关闭窗口就可以了。
具体操作步骤如下
输入网址后先不要回车确认右键选择审查元素然后点击网络记得要勾上preserve log选项因为如果出现上面提到过的重定向跳转之前的请求全部都会被清掉影响分析尤其是重定向时还加上了Cookie
接下来观察网络请求列表资源文件例如css图片基本都可以忽略第一个请求肯定就是该链接的内容本身所以查看源码确认页面上需要抓取的内容是不是在HTML标签里面很简单的方法找到自己要找的内容看到父节点然后再看源代码里面该父节点里面有没有内容如果没有那么一定是异步请求如果是非异步请求直接抓该链接就可以了。 分析异步请求按照网络列表略过资源文件然后点击各个请求观察是否在返回时包含想要的内容有几个方法
内容比较有特点例如人的属性信息物品的价格或者微博列表等内容直接观察可以判断是不是该异步请求
知道异步加载的内容节点或者父节点的class或者id的名称找到js代码阅读代码得到异步请求 确认异步请求之后就是要分析异步请求了简单的直接请求异步请求能得到数据但是有时候异步请求会有限制所以现在分析限制从何而来。
针对分析对请求的限制思路是逆序方法。
先找到最后一个得到内容的请求然后观察headers先看post数据或者url的某个参数是不是都是已知数据或者有意义数据如果发现不确定的先带上只是更改某个关键字段例如pagecount看结果是不是会正常如果不正常比如多了个token或者某个字段明显被加密例如用户名密码那么接下来就要看JS的代码看到底是哪个函数进行了加密一般会是原生JS代码加密那么看到代码直接加密就行如果是类似RSA加密那么就要看公钥是从何而来如果是请求得到的那么就要往上分析请求另外如果是发现请求headers里面有陌生字段或者有Cookie也要往上看请求Cookie在哪一步设置的
接下来找到刚刚那个请求未知来源的信息例如Cookie或者某个加密需要的公钥等等看看上面某个请求是不是已经包含依次类推。
App的分析
App类使用的工具是Fidder手机和电脑在一个局域网内先用Fidder配置好端口然后手机设置代理ip为电脑的ip端口为设置的端口然后如果手机上请求网络内容时Fidder会显示相应地请求那么就ok了分析的大体逻辑基本一致限制会相对少很多但是也有几种情况需要注意
- 加密App有时候也有一些加密的字段这个时候,一般来讲都会进行反编译进行分析找到对应的代码片段逆推出加密方法
- gzip压缩或者base64编码base64编码的辨别度较高有时候数据被gzip压缩了不过Charles都是有自动解密的
- https证书有的https请求会验证证书, Fidder提供了证书可以在官网找到手机访问然后信任添加就可以。
爬虫搜索策略
在爬虫系统中待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题因为这涉及到先抓取那个页面后抓取哪个页面。而决定这些URL排列顺序的方法叫做抓取策略。
1、 深度优先搜索策略顺藤摸瓜(Depth-First Search)
即图的深度优先遍历算法。网络爬虫会从起始页开始一个链接一个链接跟踪下去处理完这条线路之后再转入下一个起始页继续跟踪链接。
2、 广度宽度优先搜索策略Breadth First Search
宽度优先遍历策略的基本思路是将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页然后再选择其中的一个链接网页继续抓取在此网页中链接的所有网页。
有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。
广度优先搜索和深度优先搜索
深度优先搜索算法涉及的是堆栈
广度优先搜索涉及的是队列。
堆栈(stacks)具有后进先出(last in first outLIFO)的特征
队列(queue)是一种具有先进先出(first in first outLIFO)特征的线性数据结构
![]()
Scrapy是以广度优先还是深度优先进行爬取的呢
默认情况下Scrapy使用 LIFO 队列来存储等待的请求。简单的说就是 深度优先顺序 。深度优先对大多数情况下是更方便的。如果您想以 广度优先顺序 进行爬取你可以设置以下的设定:
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'二叉树的深度优先遍历与广度优先遍历 [ C++ 实现 ]
深度优先搜索算法Depth First Search是搜索算法的一种。是沿着树的深度遍历树的节点尽可能深的搜索树的分支。
当节点v的所有边都己被探寻过搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。
如果还存在未被发现的节点则选择其中一个作为源节点并重复以上过程整个进程反复进行直到所有节点都被访问为止。
如右图所示的二叉树
A 是第一个访问的然后顺序是 B、D然后是 E。接着再是 C、F、G。
那么怎么样才能来保证这个访问的顺序呢
分析一下在遍历了根结点后就开始遍历左子树最后才是右子树。
因此可以借助堆栈的数据结构由于堆栈是后进先出的顺序由此可以先将右子树压栈然后再对左子树压栈
这样一来左子树结点就存在了栈顶上因此某结点的左子树能在它的右子树遍历之前被遍历。
深度优先遍历代码片段
//深度优先遍历
void depthFirstSearch(Tree root){stack<Node *> nodeStack; //使用C++的STL标准模板库nodeStack.push(root);Node *node;while(!nodeStack.empty()){node = nodeStack.top();printf(format, node->data); //遍历根结点nodeStack.pop();if(node->rchild){nodeStack.push(node->rchild); //先将右子树压栈}if(node->lchild){nodeStack.push(node->lchild); //再将左子树压栈}}
}广度优先搜索算法Breadth First Search又叫宽度优先搜索或横向优先搜索。
是从根节点开始沿着树的宽度遍历树的节点。如果所有节点均被访问则算法中止。
如右图所示的二叉树A 是第一个访问的然后顺序是 B、C然后再是 D、E、F、G。
那么怎样才能来保证这个访问的顺序呢
借助队列数据结构由于队列是先进先出的顺序因此可以先将左子树入队然后再将右子树入队。
这样一来左子树结点就存在队头可以先被访问到。
广度优先遍历代码片段
//广度优先遍历
void breadthFirstSearch(Tree root){queue<Node *> nodeQueue; //使用C++的STL标准模板库nodeQueue.push(root);Node *node;while(!nodeQueue.empty()){node = nodeQueue.front();nodeQueue.pop();printf(format, node->data);if(node->lchild){nodeQueue.push(node->lchild); //先将左子树入队}if(node->rchild){nodeQueue.push(node->rchild); //再将右子树入队}}
}完整代码:
/*** <!--* File : binarytree.h* Author : fancy* Email : fancydeepin@yeah.net* Date : 2013-02-03* --!>*/
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <Stack>
#include <Queue>
using namespace std;
#define Element char
#define format "%c"typedef struct Node {Element data;struct Node *lchild;struct Node *rchild;
} *Tree;int index = 0; //全局索引变量//二叉树构造器,按先序遍历顺序构造二叉树
//无左子树或右子树用'#'表示
void treeNodeConstructor(Tree &root, Element data[]){Element e = data[index++];if(e == '#'){root = NULL;}else{root = (Node *)malloc(sizeof(Node));root->data = e;treeNodeConstructor(root->lchild, data); //递归构建左子树treeNodeConstructor(root->rchild, data); //递归构建右子树}
}//深度优先遍历
void depthFirstSearch(Tree root){stack<Node *> nodeStack; //使用C++的STL标准模板库nodeStack.push(root);Node *node;while(!nodeStack.empty()){node = nodeStack.top();printf(format, node->data); //遍历根结点nodeStack.pop();if(node->rchild){nodeStack.push(node->rchild); //先将右子树压栈}if(node->lchild){nodeStack.push(node->lchild); //再将左子树压栈}}
}//广度优先遍历
void breadthFirstSearch(Tree root){queue<Node *> nodeQueue; //使用C++的STL标准模板库nodeQueue.push(root);Node *node;while(!nodeQueue.empty()){node = nodeQueue.front();nodeQueue.pop();printf(format, node->data);if(node->lchild){nodeQueue.push(node->lchild); //先将左子树入队}if(node->rchild){nodeQueue.push(node->rchild); //再将右子树入队}}
}/*** <!--* File : BinaryTreeSearch.h* Author : fancy* Email : fancydeepin@yeah.net* Date : 2013-02-03* --!>*/
#include "binarytree.h"int main() {//上图所示的二叉树先序遍历序列,其中用'#'表示结点无左子树或无右子树Element data[15] = {'A', 'B', 'D', '#', '#', 'E', '#', '#', 'C', 'F','#', '#', 'G', '#', '#'};Tree tree;treeNodeConstructor(tree, data);printf("深度优先遍历二叉树结果: ");depthFirstSearch(tree);printf("\n\n广度优先遍历二叉树结果: ");breadthFirstSearch(tree);return 0;}分布式爬虫 scrapy - redis
scrapy分布式爬虫
文档http://doc.scrapy.org/en/master/topics/practices.html#distributed-crawls
Scrapy并没有提供内置的机制支持分布式(多服务器)爬取。不过还是有办法进行分布式爬取 取决于您要怎么分布了。
如果您有很多spider那分布负载最简单的办法就是启动多个Scrapyd并分配到不同机器上。
如果想要在多个机器上运行一个单独的spider那您可以将要爬取的url进行分块并发送给spider。 例如:
首先准备要爬取的url列表并分配到不同的文件url里:
http://somedomain.com/urls-to-crawl/spider1/part1.list
http://somedomain.com/urls-to-crawl/spider1/part2.list
http://somedomain.com/urls-to-crawl/spider1/part3.list接着在3个不同的Scrapd服务器中启动spider。spider会接收一个(spider)参数 part 该参数表示要爬取的分块:
curl http://scrapy1.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=1
curl http://scrapy2.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=2
curl http://scrapy3.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=3![]()
scrapy-redis分布式爬虫
scrapy-redis巧妙的利用redis队列 实现 request queue和 items queue利用redis的 set实现request的去重将scrapy从单台机器扩展多台机器实现较大规模的爬虫集群
Scrapy-Redis 架构分析
scrapy任务调度是基于文件系统这样只能在单机执行crawl。
scrapy-redis将待抓取request请求信息和数据items信息的存取放到redis queue里使多台服务器可以同时执行crawl和items process大大提升了数据爬取和处理的效率。
scrapy-redis是基于redis的scrapy组件主要功能如下
• 分布式爬虫
多个爬虫实例分享一个redis request队列非常适合大范围多域名的爬虫集群
• 分布式后处理
爬虫抓取到的items push到一个redis items队列,这就意味着可以开启多个items processes来处理抓取到的数据比如存储到Mongodb、Mysql
• 基于scrapy即插即用组件
Scheduler + Duplication Filter, Item Pipeline, Base Spiders.
scrapy原生架构
分析scrapy-redis的架构之前先回顾一下scrapy的架构
![]()
• 调度器(Scheduler)调度器维护request 队列每次执行取出一个request。
• SpidersSpider是Scrapy用户编写用于分析response提取item以及跟进额外的URL的类。每个spider负责处理一个特定(或一些)网站。
• Item PipelineItem Pipeline负责处理被spider提取出来的item。典型的处理有清理、验证数据及持久化(例如存取到数据库中)。
scrapy-redis 架构
![]()
如上图所示scrapy-redis在scrapy的架构上增加了redis基于redis的特性拓展了如下组件
• 调度器(Scheduler)
scrapy-redis调度器通过redis的set不重复的特性巧妙的实现了Duplication Filter去重DupeFilter set存放爬取过的request。
Spider新生成的request将request的指纹到redis的DupeFilter set检查是否重复并将不重复的request push写入redis的request队列。
调度器每次从redis的request队列里根据优先级pop出一个request, 将此request发给spider处理。• Item Pipeline
将Spider爬取到的Item给scrapy-redis的Item Pipeline将爬取到的Item存入redis的items队列。可以很方便的从items队列中提取item从而实现items processes 集群总结
scrapy-redis巧妙的利用redis 实现 request queue和 items queue利用redis的set实现request的去重将scrapy从单台机器扩展多台机器实现较大规模的爬虫集群
scrapy-redis安装与使用
文档: https://scrapy-redis.readthedocs.org.
安装scrapy-redis
之前已经装过scrapy了这里直接装scrapy-redis
pip install scrapy-redis使用scrapy-redis的example来修改
先从github上拿到scrapy-redis的example然后将里面的example-project目录移到指定的地址
git clone https://github.com/rolando/scrapy-redis.git
cp -r scrapy-redis/example-project ./scrapy-youyuan或者将整个项目下载回来scrapy-redis-master.zip解压后
cp -r scrapy-redis-master/example-project/ ./redis-youyuan
cd redis-youyuan/tree查看项目目录
![]()
修改settings.py
下面列举了修改后的配置文件中与scrapy-redis有关的部分middleware、proxy等内容在此就省略了。
https://scrapy-redis.readthedocs.io/en/stable/readme.html
注意settings里面的中文注释会报错换成英文
# 指定使用scrapy-redis的Scheduler
SCHEDULER = "scrapy_redis.scheduler.Scheduler"# 在redis中保持scrapy-redis用到的各个队列从而允许暂停和暂停后恢复
SCHEDULER_PERSIST = True# 指定排序爬取地址时使用的队列默认是按照优先级排序
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# 可选的先进先出排序
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderQueue'
# 可选的后进先出排序
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderStack'# 只在使用SpiderQueue或者SpiderStack是有效的参数,指定爬虫关闭的最大空闲时间
SCHEDULER_IDLE_BEFORE_CLOSE = 10# 指定RedisPipeline用以在redis中保存item
ITEM_PIPELINES = {'example.pipelines.ExamplePipeline': 300,'scrapy_redis.pipelines.RedisPipeline': 400
}# 指定redis的连接参数
# REDIS_PASS是我自己加上的redis连接密码需要简单修改scrapy-redis的源代码以支持使用密码连接redis
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
#REDIS_URL = 'redis://user:pass@hostname:9001'
#REDIS_PARAMS['password'] = 'itcast.cn'
LOG_LEVEL = 'DEBUG'DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'#The class used to detect and filter duplicate requests.#The default (RFPDupeFilter) filters based on request fingerprint using the scrapy.utils.request.request_fingerprint function. In order to change the way duplicates are checked you could subclass RFPDupeFilter and override its request_fingerprint method. This method should accept scrapy Request object and return its fingerprint (a string).#By default, RFPDupeFilter only logs the first duplicate request. Setting DUPEFILTER_DEBUG to True will make it log all duplicate requests.
DUPEFILTER_DEBUG =True# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.8','Connection': 'keep-alive','Accept-Encoding': 'gzip, deflate, sdch',
}查看pipeline.py
from datetime import datetimeclass ExamplePipeline(object):def process_item(self, item, spider):item["crawled"] = datetime.utcnow()item["spider"] = spider.namereturn item项目案例
以抓取有缘网 北京 18-25岁 女朋友为例
修改items.py
增加我们最后要保存的Profile项
class Profile(Item):# 提取头像地址header_url = Field()# 提取相册图片地址pic_urls = Field()username = Field()# 提取内心独白monologue = Field()age = Field()# youyuansource = Field()source_url = Field()crawled = Field()spider = Field()修改爬虫文件
在spiders目录下增加youyuan.py文件编写我们的爬虫之后就可以运行爬虫了。 这里的提供一个简单的版本
# -*- coding: utf-8 -*-
from scrapy.linkextractors import LinkExtractor
from example.items import Profile
import re
from scrapy.dupefilters import RFPDupeFilter
from scrapy.spiders import CrawlSpider,Ruleclass YouyuanSpider(CrawlSpider):name = 'youyuan'allowed_domains = ['youyuan.com']# 有缘网的列表页start_urls = ['http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/']pattern = re.compile(r'[0-9]')# 提取列表页和Profile资料页的链接形成新的request保存到redis中等待调度profile_page_lx = LinkExtractor(allow=('http://www.youyuan.com/\d+-profile/'),)page_lx = LinkExtractor(allow =(r'http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/'))rules = (Rule(page_lx, callback='parse_list_page', follow=True),Rule(profile_page_lx, callback='parse_profile_page', follow=False),)# 处理列表页其实完全不用的就是留个函数debug方便def parse_list_page(self, response):print "Processed list %s" % (response.url,)#print response.bodyself.profile_page_lx.extract_links(response)pass# 处理Profile资料页得到我们要的Profiledef parse_profile_page(self, response):print "Processing profile %s" % response.urlprofile = Profile()profile['header_url'] = self.get_header_url(response)profile['username'] = self.get_username(response)profile['monologue'] = self.get_monologue(response)profile['pic_urls'] = self.get_pic_urls(response)profile['age'] = self.get_age(response)profile['source'] = 'youyuan'profile['source_url'] = response.url#print "Processed profile %s" % response.urlyield profile# 提取头像地址def get_header_url(self, response):header = response.xpath('//dl[@class="personal_cen"]/dt/img/@src').extract()if len(header) > 0:header_url = header[0]else:header_url = ""return header_url.strip()# 提取用户名def get_username(self, response):usernames = response.xpath('//dl[@class="personal_cen"]/dd/div/strong/text()').extract()if len(usernames) > 0:username = usernames[0]else:username = ""return username.strip()# 提取内心独白def get_monologue(self, response):monologues = response.xpath('//ul[@class="requre"]/li/p/text()').extract()if len(monologues) > 0:monologue = monologues[0]else:monologue = ""return monologue.strip()# 提取相册图片地址def get_pic_urls(self, response):pic_urls = []data_url_full = response.xpath('//li[@class="smallPhoto"]/@data_url_full').extract()if len(data_url_full) <= 1:pic_urls.append("");else:for pic_url in data_url_full:pic_urls.append(pic_url)if len(pic_urls) <= 1: return "" return '|'.join(pic_urls)# 提取年龄 def get_age(self, response): age_urls = response.xpath('//dl[@class="personal_cen"]/dd/p[@class="local"]/text()').extract() if len(age_urls) > 0:age = age_urls[0]else:age = ""age_words = re.split(' ', age)if len(age_words) <= 2:return "0"#20岁age = age_words[2][:-1]if self.pattern.match(age):return agereturn "0"运行项目
这个项目演示了在多个spiders实例之间如何共享(share)一个爬虫spider的请求队列
第一次运行的爬虫然后停止它
cd redis-youyuanscrapy crawl youyuan... [youyuan] ...^C重新运行停止的爬虫
scrapy crawl youyuan2016-08-22 22:32:04 [youyuan] DEBUG: Resuming crawl (13 requests scheduled)启动一个或更多的scrapy爬虫
scrapy crawl youyuan... [dmoz] DEBUG: Resuming crawl (8712 requests scheduled)
过程分析
假定有两个爬虫那么是如何实现分布式具体的步骤如下
1) 首先运行爬虫A
爬虫A中start_urls push 待下载request队列、调度器从待下载request队列取出一个request交给spider下载,spider根据定义的rules得到链接然后把链接push到redis request队列中。
备注待下载request队列是redis 队列实现的也就是将生成request(url)push到queue中调度器请求时pop出来。
2) 停止爬虫A, 重新运行爬虫A、B
爬虫 A 和 B 同时到 待下载request队列中取request任务等待下载request完成之后爬虫A和B 各自下载自定义的链接比如start_urls一般来讲此时大部分请求连接都被去重任务基本完成。
备注在scrapy-redis中 待下载request队列 默认使用的是SpiderPriorityQueue方式这是由sorted set实现的一种非FIFO,LIFO方式。
注意每次执行重新爬取时应该将redis中存储的数据清空否则会影响爬虫运行。
处理爬回来的items
在完成前三步骤操作之后开始第四步
4.启动一个或多个后处理存储:
有缘网的profile爬回来了这些profile都被保存在redis的youyuan:items队列中。因为配置文件里面没有定制自己的ITEM_PIPELINES而是使用了RedisPipeline
于是现在需要另外处理。
在scrapy-youyuan目录下可以看到一个process_items.py文件这个文件就是scrapy-redis的example提供的从redis读取item进行处理的模版。
修改 process_items.py文件 第50行
name-->username
url-->source_url
Argparse Tutorial文档https://docs.python.org/2/howto/argparse.html
try:name = item.get('username')url = item.get('source_url')logger.debug("[%s] Processing item: %s <%s>", source, name, url)
except KeyError:logger.exception("[%s] Failed to process item:\n%r",source, pprint.pformat(item))continuepython process_items.py youyuan:items --host=127.0.0.1 --port=6379 --verbose运行效果
![]()
存储
假设我们要把youyuan:items中保存的Profile读出来写进Mongodb、mysql那么我们可以修改模板process_items.py文件然后保持后台运行就可以不停地入库爬回来的Profile了。
导出MongoDB
- 数据库youyuan、表名Infos
import pymongoconn = pymongo.Connection('192.168.17.129', 27017)
db = conn.youyuandb["Infos"].save(item)执行命令python process_items.py youyuan:items -v
设置调试信息
![]()
效果如图
![]()
导出MYSQL
- sql语句建立数据库youyuan、表名Infos
-- ----------------------------
-- Table structure for Infos
-- ----------------------------
DROP TABLE IF EXISTS `Infos`;
CREATE TABLE `Infos` (`header_url` varchar(255) DEFAULT NULL,`pic_urls` text,`username` varchar(255) DEFAULT NULL,`monologue` varchar(255) DEFAULT NULL,`age` varchar(255) DEFAULT NULL,`source` varchar(255) DEFAULT NULL,`source_url` varchar(255) DEFAULT NULL,`crawled` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,`spider` varchar(255) DEFAULT NULL,`id` int(11) NOT NULL AUTO_INCREMENT,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=742 DEFAULT CHARSET=utf8;修改process_items.py
import MySQLdbconn = MySQLdb.connect(host='192.168.17.129', user='root', passwd='root', db = 'youyuan', port=3306,charset="utf8")cur = conn.cursor()
sqlstr = '''insert into Infos(header_url,pic_urls,username,monologue,age,source,source_url,crawled,spider)
values('%s','%s','%s','%s','%s','%s','%s','%s','%s')'''%(
item['header_url'],
item['pic_urls'],
item['username'],
item['monologue'],
item['age'],
item['source'],
item['source_url'],
item['crawled'],
item['spider']);print(sqlstr)
cur.execute(sqlstr)
conn.commit()cur.close()![]()
Ubuntu 16.04 安装mysql并设置远程访问
安装mysql
- 安装需要使用root账号,安装mysql过程中,需要设置mysql的root账号的密码不要忽略了。
sudo apt-get install mysql-server apt install mysql-client apt install libmysqlclient-dev - 以上3个软件包安装完成后使用如下命令查询是否安装成功
sudo netstat -tap | grep mysql查询结果如下图所示表示安装成功。
root@xyz:~# netstat -tap | grep mysql tcp6 0 0 [::]:mysql [::]:* LISTEN 7510/mysqld root@xyz:~#
设置mysql远程访问
编辑mysql配置文件把其中bind-address = 127.0.0.1注释了
vi /etc/mysql/mysql.conf.d/mysqld.cnf使用root进入mysql命令行执行如下2个命令示例中mysql的root账号密码root
python@ubuntu:/etc/mysql/conf.d$ mysql -u root -pEnter password: grant all on *.* to root@'%' identified by 'root';flush privileges;重启mysql
service mysql restart重启成功后在其他计算机上便可以登录。
从redis启动Spider
scrapy_redis.spiders下有两个类RedisSpider和RedisCrawlSpider,能够使spider从Redis读取start_urls
spider从redis中读取要爬的start_urls,然后执行爬取若爬取过程中返回更多的request url那么它会继续进行直至所有的request完成之后再从redis start_urls中读取下一个url循环这个过程
RedisSpider
以example下mycrawler_redis.py举例
运行
scrapy runspider example/spiders/myspider_redis.pypush urls to redis:
redis-cli lpush myspider:start_urls http://baidu.com
RedisCrawlSpider
以example下mycrawler_redis.py举例
run the spider:
scrapy runspider example/spiders/mycrawler_redis.pypush urls to redis:
redis-cli lpush mycrawler:start_urls http://baidu.com
防禁封策略-分布式实战
以丁香园用药助手项目为例。架构示意图如下
![]()
首先通过药理分类采集一遍按照drug_id排序发现
我们要完成 http://drugs.dxy.cn/drug/[50000-150000].htm
正常采集
![]()
异常数据情况包括如下
- 药品不存在
![]()
- 当采集频率过快弹出验证码
![]()
- 当天采集累计操作次数过多弹出禁止
![]()
这个时候就需要用到代理
项目流程
1. 创建项目
scrapy startproject drugs_dxy创建spider
cd drugs_dxy/
scrapy genspider -t basic Drugs dxy.cn2. items.py下添加类DrugsItem
class DrugsItem(scrapy.Item):# define the fields for your item here like:#药品不存在标记exists = scrapy.Field()#药品iddrugtId = scrapy.Field()#数据data = scrapy.Field()#标记验证码状态msg = scrapy.Field()pass3. 编辑spider下DrugsSpider类
# -*- coding: utf-8 -*-
import scrapy
from drugs_dxy.items import DrugsItem
import reclass DrugsSpider(scrapy.Spider):name = "Drugs"allowed_domains = ["dxy.cn"]size = 60def start_requests(self):for i in xrange(50000,50000+self.size,1):url ='http://drugs.dxy.cn/drug/%d.htm' % (i)yield scrapy.Request(url=url,callback=self.parse)def parse(self, response):drug_Item = DrugsItem()drug_Item["drugtId"] = int(re.search('(\d+)',response.url).group(1))if drug_Item["drugtId"]>=150000:returnurl ='http://drugs.dxy.cn/drug/%d.htm' % (drug_Item["drugtId"]+self.size)yield scrapy.Request(url=url,callback=self.parse)if '药品不存在' in response.body:drug_Item['exists'] = Falseyield drug_Item returnif '请填写验证码继续正常访问' in response.body:drug_Item["msg"] = u'请填写验证码继续正常访问'returndrug_Item["data"] = {}details = response.xpath("//dt")for detail in details:detail_name = detail.xpath('./span/text()').extract()[0].split(':')[0]if detail_name ==u'药品名称':drug_Item['data'][u'药品名称'] = {}try:detail_str = detail.xpath("./following-sibling::*[1]")detail_value = detail_str.xpath('string(.)').extract()[0].replace('\r','').replace('\t','').strip()for item in detail_value.split('\n'):item = item.replace('\r','').replace('\n','').replace('\t','').strip()name = item.split(u'')[0]value = item.split(u'')[1]#print name,valuedrug_Item['data'][u'药品名称'][name] = valueexcept:passelse:detail_str = detail.xpath("./following-sibling::*[1]")detail_value = detail_str.xpath('string(.)').extract()[0].replace('\r','').replace('\t','').strip()#print detail_str,detail_valuedrug_Item['data'][detail_name] = detail_valueyield drug_Item4. Scrapy代理设置
4.1 在settings.py文件里
1启用scrapy_redis组件
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300
}# Specify the host and port to use when connecting to Redis (optional).
REDIS_HOST = '101.200.170.171'
REDIS_PORT = 6379# Custom redis client parameters (i.e.: socket timeout, etc.)
REDIS_PARAMS = {}
#REDIS_URL = 'redis://user:pass@hostname:9001'
REDIS_PARAMS['password'] = 'itcast.cn'2) 启用DownLoader中间件httpproxy
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {'drugs_dxy.middlewares.ProxyMiddleware': 400,'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
}3) 设置禁止跳转code=301、302超时时间90s
DOWNLOAD_TIMEOUT = 90
REDIRECT_ENABLED = False4.2 在drugs_dxy目录下创建middlewares.py并编辑(settings.py同级目录)
# -*- coding: utf-8 -*-
import random
import base64
import Queue
import redisclass ProxyMiddleware(object):def __init__(self, settings):self.queue = 'Proxy:queue'# 初始化代理列表self.r = redis.Redis(host=settings.get('REDIS_HOST'),port=settings.get('REDIS_PORT'),db=1,password=settings.get('REDIS_PARAMS')['password'])@classmethoddef from_crawler(cls, crawler):return cls(crawler.settings)def process_request(self, request, spider):proxy={}source, data = self.r.blpop(self.queue)proxy['ip_port']=dataproxy['user_pass']=Noneif proxy['user_pass'] is not None:#request.meta['proxy'] = "http://YOUR_PROXY_IP:PORT"request.meta['proxy'] = "http://%s" % proxy['ip_port']#proxy_user_pass = "USERNAME:PASSWORD"encoded_user_pass = base64.encodestring(proxy['user_pass'])request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_passprint "********ProxyMiddleware have pass*****" + proxy['ip_port']else:#ProxyMiddleware no passprint request.url, proxy['ip_port']request.meta['proxy'] = "http://%s" % proxy['ip_port']def process_response(self, request, response, spider):"""检查response.status, 根据status是否在允许的状态码中决定是否切换到下一个proxy, 或者禁用proxy"""print("-------%s %s %s------" % (request.meta["proxy"], response.status, request.url))# status不是正常的200而且不在spider声明的正常爬取过程中可能出现的# status列表中, 则认为代理无效, 切换代理if response.status == 200:print 'rpush',request.meta["proxy"]self.r.rpush(self.queue, request.meta["proxy"].replace('http://','')) return responsedef process_exception(self, request, exception, spider):"""处理由于使用代理导致的连接异常"""proxy={}source, data = self.r.blpop(self.queue)proxy['ip_port']=dataproxy['user_pass']=Nonerequest.meta['proxy'] = "http://%s" % proxy['ip_port']new_request = request.copy()new_request.dont_filter = Truereturn new_request5. 运行
![]()
出错记录
Scrapy URLError
错误信息如下
2015-12-03 16:05:08 [scrapy] INFO: Scrapy 1.0.3 started (bot: LabelCrawler)
2015-12-03 16:05:08 [scrapy] INFO: Optional features available: ssl, http11, boto
2015-12-03 16:05:08 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'LabelCrawler.spiders', 'SPIDER_MODULES': ['LabelCrawler.spiders'], 'BOT_NAME': 'LabelCrawler'}
2015-12-03 16:05:08 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-12-03 16:05:09 [boto] DEBUG: Retrieving credentials from metadata server.
2015-12-03 16:05:09 [boto] ERROR: Caught exception reading instance data
Traceback (most recent call last):File "D:\Anaconda\lib\site-packages\boto\utils.py", line 210, in retry_urlr = opener.open(req, timeout=timeout)File "D:\Anaconda\lib\urllib2.py", line 431, in openresponse = self._open(req, data)File "D:\Anaconda\lib\urllib2.py", line 449, in _open'_open', req)File "D:\Anaconda\lib\urllib2.py", line 409, in _call_chainresult = func(*args)File "D:\Anaconda\lib\urllib2.py", line 1227, in http_openreturn self.do_open(httplib.HTTPConnection, req)File "D:\Anaconda\lib\urllib2.py", line 1197, in do_openraise URLError(err)
URLError: <urlopen error [Errno 10051] >原因如下
That particular error message is being generated by boto (boto 2.38.0 py27_0), which is used to connect to Amazon S3. Scrapy doesn't have this enabled by default.
解决办法
1.在settings.py文件中加上
DOWNLOAD_HANDLERS = {'S3': None,}
- 在settings.py文件中加上
AWS_ACCESS_KEY_ID = "" AWS_SECRET_ACCESS_KEY = ""即使报错也不影响爬虫
(error) MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk.
今天运行Redis时发生错误错误信息如下
(error) MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error.
Redis被配置为保存数据库快照但它目前不能持久化到硬盘。用来修改集合数据的命令不能用。请查看Redis日志的详细错误信息。
原因
强制关闭Redis快照导致不能持久化。
解决方案
运行config set stop-writes-on-bgsave-error no 命令后关闭配置项stop-writes-on-bgsave-error解决该问题。
root@ubuntu:/usr/local/redis/bin# ./redis-cli
127.0.0.1:6379> config set stop-writes-on-bgsave-error no
OK
127.0.0.1:6379> lpush myColour "red"
(integer) 1redis-scrapy
settings.py 千万不能添加
LOG_STDOUT=True
进阶扩展篇
1.世界上最简单的爬虫——用python写成只需要三行。
import requests
url="http://www.cricode.com"
r=requests.get(url)2.一个正常的爬虫程序
上面那个最简单的爬虫是一个不完整的残疾的爬虫。因为爬虫程序通常需要做的事情如下
1给定的种子URLs爬虫程序将所有种子URL页面爬取下来
2爬虫程序解析爬取到的URL页面中的链接将这些链接放入待爬取URL集合中
3重复1、2步直到达到指定条件才结束爬取
因此一个完整的爬虫大概是这样子的
import requests #用来爬取网页
from bs4 import BeautifulSoup #用来解析网页
seds = ["http://www.hao123.com", #我们的种子"http://www.csdn.net","http://www.cricode.com"]
sum = 0 #我们设定终止条件为爬取到100000个页面时就不玩了while sum < 10000 :if sum < len(seds):r = requests.get(seds[sum])sum = sum + 1do_save_action(r)soup = BeautifulSoup(r.content) urls = soup.find_all("href",.....) //解析网页for url in urls:seds.append(url)else:break上面那个完整的爬虫不足20行代码相信你能找出20个茬来。因为它的缺点实在是太多。下面一一列举它的N宗罪
1我们的任务是爬取1万个网页按上面这个程序一个人在默默的爬取假设爬起一个网页3秒钟那么爬一万个网页需要3万秒钟。MGD我们应当考虑开启多个线程(池)去一起爬取或者用分布式架构去并发的爬取网页。
2种子URL和后续解析到的URL都放在一个列表里我们应该设计一个更合理的数据结构来存放这些待爬取的URL才是比如队列或者优先队列。
3对各个网站的url我们一视同仁事实上我们应当区别对待。大站好站优先原则应当予以考虑。
4每次发起请求我们都是根据url发起请求而这个过程中会牵涉到DNS解析将url转换成ip地址。一个网站通常由成千上万的URL因此我们可以考虑将这些网站域名的IP地址进行缓存避免每次都发起DNS请求费时费力。
5解析到网页中的urls后我们没有做任何去重处理全部放入待爬取的列表中。事实上可能有很多链接是重复的我们做了很多重复劳动。
6…..
4.找了这么多茬后很有成就感真正的问题来了学挖掘机到底哪家强
现在我们就来一一讨论上面找茬找出的若干问题的解决方案。
1并行爬起问题
我们可以有多重方法去实现并行。
多线程或者线程池方式一个爬虫程序内部开启多个线程。同一台机器开启多个爬虫程序如此我们就有N多爬取线程在同时工作。能大大减少时间。
此外当我们要爬取的任务特别多时一台机器、一个网点肯定是不够的我们必须考虑分布式爬虫。常见的分布式架构有主从Master——Slave架构、点对点Peer to Peer架构混合架构等。
说道分布式架构那我们需要考虑的问题就有很多我们需要分派任务各个爬虫之间需要通信合作共同完成任务不要重复爬取相同的网页。分派任务我们要做到公平公正就需要考虑如何进行负载均衡。负载均衡我们第一个想到的就是Hash比如根据网站域名进行hash。
负载均衡分派完任务之后千万不要以为万事大吉了万一哪台机器挂了呢原先指派给挂掉的哪台机器的任务指派给谁又或者哪天要增加几台机器任务有该如何进行重新分配呢
一个比较好的解决方案是用一致性Hash算法。
2待爬取网页队列
如何对待待抓取队列跟操作系统如何调度进程是类似的场景。
不同网站重要程度不同因此可以设计一个优先级队列来存放待爬起的网页链接。如此一来每次抓取时我们都优先爬取重要的网页。
当然你也可以效仿操作系统的进程调度策略之多级反馈队列调度算法。
3DNS缓存
为了避免每次都发起DNS查询我们可以将DNS进行缓存。DNS缓存当然是设计一个hash表来存储已有的域名及其IP。
4网页去重
说到网页去重第一个想到的是垃圾邮件过滤。垃圾邮件过滤一个经典的解决方案是Bloom Filter布隆过滤器。布隆过滤器原理简单来说就是建立一个大的位数组然后用多个Hash函数对同一个url进行hash得到多个数字然后将位数组中这些数字对应的位置为1。下次再来一个url时同样是用多个Hash函数进行hash得到多个数字我们只需要判断位数组中这些数字对应的为是全为1如果全为1那么说明这个url已经出现过。如此便完成了url去重的问题。当然这种方法会有误差只要误差在我们的容忍范围之类比如1万个网页我只爬取到了9999个剩下那一个网页who cares
5数据存储的问题
数据存储同样是个很有技术含量的问题。用关系数据库存取还是用NoSQL抑或是自己设计特定的文件格式进行存储都大有文章可做。
6进程间通信
分布式爬虫就必然离不开进程间的通信。我们可以以规定的数据格式进行数据交互完成进程间通信。
7……
实现的过程中你会发现我们要考虑的问题远远不止上面这些。
如何“跟踪”和“过滤”
在很多情况下我们并不是只抓取某个页面而需要“顺藤摸瓜”从几个种子页面通过超级链接索最终定位到我们想要的页面。
Scrapy对这个功能进行了很好的抽象
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import Selector
from scrapy.item import Item
class Coder4Spider(CrawlSpider):name = 'coder4'allowed_domains = ['xxx.com']start_urls = ['http://www.xxx.com']rules = ( Rule(SgmlLinkExtractor(allow=('page/[0-9]+', ))),Rule(SgmlLinkExtractor(allow=('archives/[0-9]+', )), callback='parse_item'),) def parse_item(self, response):self.log('%s' % response.url)在上面我们用了CrawlSpider而不是Spidername、 allowed_domains、start_urls就不解释了。
重点说下Rule
第1条不带callback的表示只是“跳板”即只下载网页并根据allow中匹配的链接去继续遍历下一步的页面实际上Rule还可以指定deny=xxx 表示过滤掉哪些页面。
第2条带callback的是最终会回调parse_item函数的网页。
如何过滤重复的页面
Scrapy支持通过RFPDupeFilter来完成页面的去重防止重复抓取。
RFPDupeFilter实际是根据request_fingerprint实现过滤的实现如下
def request_fingerprint(request, include_headers=None):if include_headers:include_headers = tuple([h.lower() for h in sorted(include_headers)])cache = _fingerprint_cache.setdefault(request, {}) if include_headers not in cache:fp = hashlib.sha1()fp.update(request.method)fp.update(canonicalize_url(request.url))fp.update(request.body or '') if include_headers:for hdr in include_headers:if hdr in request.headers:fp.update(hdr)for v in request.headers.getlist(hdr):fp.update(v)cache[include_headers] = fp.hexdigest()return cache[include_headers]我们可以看到去重指纹是sha1(method + url + body + header)
所以实际能够去掉重复的比例并不大。
如果我们需要自己提取去重的finger需要自己实现Filter并配置上它。
下面这个Filter只根据url去重
from scrapy.dupefilter import RFPDupeFilter
class SeenURLFilter(RFPDupeFilter):"""A dupe filter that considers the URL"""def __init__(self, path=None):self.urls_seen = set()RFPDupeFilter.__init__(self, path)def request_seen(self, request):if request.url in self.urls_seen:return Trueelse:self.urls_seen.add(request.url)不要忘记配置上
DUPEFILTER_CLASS ='scraper.custom_filters.SeenURLFilter'海量数据处理算法Bloom Filter
Bloom-Filter即布隆过滤器1970年由Bloom中提出。是一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合但是并不严格要求100%正确的场合。
Bloom Filter有可能会出现错误判断但不会漏掉判断。
也就是Bloom Filter判断元素不再集合那肯定不在。如果判断元素存在集合中有一定的概率判断错误
因此Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下Bloom Filter比其他常见的算法如hash折半查找极大节省了空间。 它的优点是空间效率和查询时间都远远超过一般的算法缺点是有一定的误识别率和删除困难。
一. 实例
为了说明Bloom Filter存在的重要意义举一个实例
假设要你写一个网络蜘蛛web crawler。由于网络间的链接错综复杂蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”就需要知道蜘蛛已经访问过那些URL。给一个URL怎样知道蜘蛛是否已经访问过呢稍微想想就会有如下几种方案
1. 将访问过的URL保存到数据库。
2. 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。
3. URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库。
4. Bit-Map方法。建立一个BitSet将每个URL经过一个哈希函数映射到某一位。
方法1~3都是将访问过的URL完整保存方法4则只标记URL的一个映射位。
以上方法在数据量较小的情况下都能完美解决问题但是当数据量变得非常庞大时问题就来了。
方法1的缺点数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了
方法2的缺点太消耗内存。随着URL的增多占用的内存会越来越多。就算只有1亿个URL每个URL只算50个字符就需要5GB内存。
方法3由于字符串经过MD5处理后的信息摘要长度只有128BitSHA-1处理后也只有160Bit因此方法3比方法2节省了好几倍的内存。
方法4消耗内存是相对较少的但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的Hash表冲突的各种解决方法么若要降低冲突发生的概率到1%就要将BitSet的长度设置为URL个数的100倍。
实质上上面的算法都忽略了一个重要的隐含条件允许小概率的出错不一定要100%准确也就是说少量url实际上没有没网络蜘蛛访问而将它们错判为已访问的代价是很小的——大不了少抓几个网页呗。
二. Bloom Filter的算法
废话说到这里下面引入本篇的主角——Bloom Filter。其实上面方法4的思想已经很接近Bloom Filter了。方法四的致命缺点是冲突概率高为了降低冲突的概念Bloom Filter使用了多个哈希函数而不是一个。
Bloom Filter算法如下
创建一个m位BitSet先将所有位初始化为0然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为histr且histr的范围是0到m-1 。
(1) 加入字符串过程
下面是每个字符串处理的过程首先是将字符串str“记录”到BitSet中的过程
对于字符串str分别计算h1strh2str…… hkstr。然后将BitSet的第h1str、h2str…… hkstr位设为1。
图1.Bloom Filter加入字符串过程
很简单吧这样就将字符串str映射到BitSet中的k个二进制位了。
(2) 检查字符串是否存在的过程
下面是检查字符串str是否被BitSet记录过的过程
对于字符串str分别计算h1strh2str…… hkstr。然后检查BitSet的第h1str、h2str…… hkstr位是否为1若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1则“认为”字符串str存在。
若一个字符串对应的Bit不全为1则可以肯定该字符串一定没有被Bloom Filter记录过。这是显然的因为字符串被记录过其对应的二进制位肯定全部被设为1了
但是若一个字符串对应的Bit全为1实际上是不能100%的肯定该字符串被Bloom Filter记录过的。因为有可能该字符串的所有位都刚好是被其他字符串所对应这种将该字符串划分错的情况称为false positive 。
三. Bloom Filter参数选择
(1)哈希函数选择
哈希函数的选择对性能的影响应该是很大的一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦一种简单的方法是选择一个哈希函数然后送入k个不同的参数。
(2) m,n,k值我们如何取值
我们定义
可能把不属于这个集合的元素误认为属于这个集合False Positive
不会把属于这个集合的元素误认为不属于这个集合False Negative。
哈希函数的个数k、位数组大小m、加入的字符串数量n的关系。哈希函数个数k取10位数组大小m设为字符串个数n的20倍时false positive发生的概率是0.0000889 即10万次的判断中会存在9次误判对于一天1亿次的查询误判的次数为9000次。
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考参考文献
(http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html)。
| m/n | k | k=17 | k=18 | k=19 | k=20 | k=21 | k=22 | k=23 | k=24 |
| 22 | 15.2 | 2.67e-05 | |||||||
| 23 | 15.9 | 1.61e-05 | |||||||
| 24 | 16.6 | 9.84e-06 | 1e-05 | ||||||
| 25 | 17.3 | 6.08e-06 | 6.11e-06 | 6.27e-06 | |||||
| 26 | 18 | 3.81e-06 | 3.76e-06 | 3.8e-06 | 3.92e-06 | ||||
| 27 | 18.7 | 2.41e-06 | 2.34e-06 | 2.33e-06 | 2.37e-06 | ||||
| 28 | 19.4 | 1.54e-06 | 1.47e-06 | 1.44e-06 | 1.44e-06 | 1.48e-06 | |||
| 29 | 20.1 | 9.96e-07 | 9.35e-07 | 9.01e-07 | 8.89e-07 | 8.96e-07 | 9.21e-07 | ||
| 30 | 20.8 | 6.5e-07 | 6e-07 | 5.69e-07 | 5.54e-07 | 5.5e-07 | 5.58e-07 | ||
| 31 | 21.5 | 4.29e-07 | 3.89e-07 | 3.63e-07 | 3.48e-07 | 3.41e-07 | 3.41e-07 | 3.48e-07 | |
| 32 | 22.2 | 2.85e-07 | 2.55e-07 | 2.34e-07 | 2.21e-07 | 2.13e-07 | 2.1e-07 | 2.12e-07 | 2.17e-07 |
该文献证明了对于给定的m、n当 k = ln(2)* m/n 时出错的概率是最小的。(log2 e ≈ 1.44倍)
同时该文献还给出特定的kmn的出错概率。例如根据参考文献1哈希函数个数k取10位数组大小m设为字符串个数n的20倍时false positive发生的概率是0.0000889 这个概率基本能满足网络爬虫的需求了。
四.Python实现Bloom filter
官方文档
http://axiak.github.io/pybloomfiltermmap/index.html
https://github.com/axiak/pybloomfiltermmap安装
sudo apt-get install libssl-dev
sudo pip install pybloomfiltermmap==0.2.0
sudo pip install pybloomfiltermmap==0.3.12Here’s a quick example:
from pybloomfilter import BloomFilterbf = BloomFilter(10000000, 0.01, 'filter.bloom')with open("/usr/share/dict/words") as f:for word in f:bf.add(word.rstrip())print 'apple' in bf
#outputs True>>> fruit = pybloomfilter.BloomFilter(100000, 0.1, '/tmp/words.bloom')
>>> fruit.extend(('apple', 'pear', 'orange', 'apple'))
>>> len(fruit)
3
>>> 'mike' in fruit
Falsefruitbf = bf.copy_template("fruit.bloom")
fruitbf.update(("apple", "banana", "orange", "pear"))
print fruitbf.to_base64()
"eJzt2k13ojAUBuA9f8WFyofF5TWChlTHaPzqrlqFCtj6gQi/frqZM2N7aq3Gis59d2ye85KTRbhk"
"0lyu1NRmsQrgRda0I+wZCfXIaxuWv+jqDxA8vdaf21HIOSn1u6LRE0VL9Z/qghfbBmxZoHsqM3k8"
"N5XyPAxH2p22TJJoqwU9Q0y0dNDYrOHBIa3BwuznapG+KZZq69JUG0zu1tqI5weJKdpGq7PNJ6tB"
"GKmzcGWWy8o0FeNNYNZAQpSdJwajt7eRhJ2YM2NOkTnSsBOCGGKIIYbY2TA663GgWWyWfUwn3oIc"
"fyLYxeQwiF07RqBg9NgHrG5ba3jba5yl4zS2LtEMMcQQQwwxmRiBhPGOJOywIPafYhUwqnTvZOfY"
"Zu40HH/YxDexZojJwsx6ObDcT7D8vVOtJBxiAhD/AjMmjeF2Wnqd+5RrHdo4azPEzoANabiUhh0b"
"xBBDDDHEENsf8twlrizswEjDhnTbzWazbGKpQ5k07E9Ox2iFvXBZ2D9B7DawyqLFu5lshhhiiGUK"
"a4nUloa9yxkwR7XhgPPXYdhRIa77uDtnyvqaIXalGK02ufv3J36GmsnG4lquPnN9gJo1VNxqgYbt"
"ji/EC8s1PWG5fuVizW4Jox6/3o9XxBBDDLFbwcg9v/AwjrPHtTRsX34O01mxLw37bhCTjJk0+PLK"
"08HYd4MYYojdKmYnBfjsktEpySY2tGGZzWaIIfYDGB271Yaieaat/AaOkNKb">>> bf = BloomFilter.from_base64("/tmp/mike.bf","eJwFwcuWgiAAANC9v+JCx7By0QKt0GHEbKSknflAQ9QmTyRfP/fW5E9XTRSX""qcLlqGNXphAqcfVH\nRoNv0n4JlTpIvAP0e1+RyXX6I637ggA+VPZnTYR1A4""Um5s9geYaZZLiT208JIiG3iwhf3Fwlzb3Y\n5NRL4uNQS6/d9OvTDJbnZMnR""zcrplOX5kmsVIkQziM+vw4hCDQ3OkN9m3WVfPWzGfaTeRftMCLws\nPnzEzs""gjAW60xZTBbj/bOAgYbK50PqjdzvgHZ6FHZw==\n")
>>> "MIKE" in bf
TrueBloomFilter.copy_template(filename[, perm=0755]) → BloomFilter Creates a new BloomFilter object with the same parameters–same hash seeds, same size.. everything. Once this is performed, the two filters are comparable, so you can perform logical operators. Example:
>>> apple = BloomFilter(100, 0.1, '/tmp/apple')
>>> apple.add('apple')
False
>>> pear = apple.copy_template('/tmp/pear')
>>> pear.add('pear')
False
>>> pear |= appleBloomFilter.len(item) → Integer Returns the number of distinct elements that have been added to the BloomFilter object, subject to the error given in error_rate.
>>> bf = BloomFilter(100, 0.1, '/tmp/fruit.bloom')
>>> bf.add("Apple")
>>> bf.add('Apple')
>>> bf.add('orange')
>>> len(bf)
2
>>> bf2 = bf.copy_template('/tmp/new.bloom')
>>> bf2 |= bf
>>> len(bf2)
Traceback (most recent call last):...
pybloomfilter.IndeterminateCountError: Length of BloomFilter object is unavailable after intersection or union called.五Bloom Filter的优缺点。
优点
节约缓存空间空值的映射不再需要空值映射。
减少数据库或缓存的请求次数。
提升业务的处理效率以及业务隔离性。
缺点
存在误判的概率。
传统的Bloom Filter不能作删除操作。
六Bloom-Filter的应用场景
Bloom-Filter一般用于在大数据量的集合中判定某元素是否存在。
(1)适用于一些黑名单,垃圾邮件等的过滤例如邮件服务器中的垃圾邮件过滤器。
像网易QQ这样的公众电子邮件email提供商总是需要过滤来自发送垃圾邮件的人spamer的垃圾邮件。
一个办法就是记录下那些发垃圾邮件的 email地址。由于那些发送者不停地在注册新的地址全世界少说也有几十亿个发垃圾邮件的地址将他们都存起来则需要大量的网络服务器。
如果用哈希表每存储一亿个 email地址就需要 1.6GB的内存用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹然后将这些信息指纹存入哈希表由于哈希表的存储效率一般只有 50%因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB即十六亿字节的内存。因此存贮几十亿个邮件地址可能需要上百 GB的内存。
而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
BloomFilter决不会漏掉任何一个在黑名单中的可疑地址。而至于误判问题常见的补救办法是在建立一个小的白名单存储那些可能别误判的邮件地址。
(2)在搜索引擎领域Bloom-Filter最常用于网络蜘蛛(Spider)的URL过滤网络蜘蛛通常有一个URL列表保存着将要下载和已经下载的网页的URL网络蜘蛛下载了一个网页从网页中提取到新的URL后需要判断该URL是否已经存在于列表中。此时Bloom-Filter算法是最好的选择。
2 .Google的BigTable Google的BigTable也使用了Bloom Filter以减少不存在的行或列在磁盘上的查询大大提高了数据库的查询操作的性能。
3.key-value 加快查询 一般Bloom-Filter可以与一些key-value的数据库一起使用来加快查询。
一般key-value存储系统的values存在硬盘查询就是件费时的事。将Storage的数据都插入Filter在Filter中查询都不存在时那就不需要去Storage查询了。当False Position出现时只是会导致一次多余的Storage查询。
由于Bloom-Filter所用的空间非常小所有BF可以常驻内存。这样子的话对于大部分不存在的元素我们只需要访问内存中的Bloom-Filter就可以判断出来了只有一小部分我们需要访问在硬盘上的key-value数据库。从而大大地提高了效率。
Scrapy_redis 去重优化(7亿数据)
背景
前些天接手了上一位同事的爬虫一个全网爬虫用的是scrapy+Redis分布式任务调度用的scrapy_redis模块。
大家应该知道scrapy是默认开启了去重的用了scrapy_redis后去重队列放在redis里面爬虫已经有7亿多条URL的去重数据了再加上一千多万条requests的种子redis占用了一百六十多G的内存服务器Centos7总共才一百七十五G好么。去重占用了大部分的内存不优化还能跑
一言不合就用Bloomfilter+Redis优化了一下内存占用立马降回到了二十多G保证漏失概率小于万分之一的情况下可以容纳50亿条URL的去重效果还是很不错的在此记录一下最后附上Scrapy+Redis+Bloomfilter去重的Demo可将去重队列和种子队列分开希望对使用scrapy框架的朋友有所帮助。
记录
我们要优化的是去重首先剥丝抽茧查看框架内部是如何去重的。
因为scrapy_redis会用自己scheduler替代scrapy框架的scheduler进行任务调度所以直接去scrapy_redis模块下查看scheduler.py源码即可。
在open()方法中有句
self.df = RFPDupeFilter(...)
可见去重应该是用了RFPDupeFilter这个类再看下面的enqueue_request()方法里面有句if not request.dont_filter and self.df.request_seen(request):returnself.df.request_seen()这就是用来去重的了。按住Ctrl再左键点击request_seen查看它的代码可看到下面的代码de request_seen(self, request)fp = request_fingerprint(request)added = self.server.sadd(self.key, fp)return not added
- 可见scrapy_redis是利用set数据结构来去重的去重的对象是request的fingerprint。至于这个fingerprint到底是什么可以再深入去看request_fingerprint()方法的源码其实就是用hashlib.sha1()对request对象的某些字段信息进行压缩。我们用调试也可以看到其实fp就是request对象加密压缩后的一个字符串40个字符0~f。
是否可用Bloomfilter进行优化
以上步骤可以看出我们只要在这个
request_seen()
方法上面动些手脚即可。由于现有的七亿多去重数据存的都是这个fingerprint所有Bloomfilter去重的对象仍然是request对象的fingerprint。更改后的代码如下
def request_seen(self, request):fp = request_fingerprint(request)if self.bf.isContains(fp): # 如果已经存在return Trueelse:self.bf.insert(fp)return Falseself.bf是类Bloomfilter()的实例化关于这个Bloomfilter()类详见基于Redis的Bloomfilter去重
以上优化的思路和代码就是这样以下将已有的七亿多的去重数据转成Bloomfilter去重。
- 内存将爆动作稍微大点机器就能死掉更别说Bloomfilter在上面申请内存了。当务之急肯定是将那七亿多个fingerprint导出到硬盘上而且不能用本机导并且先要将redis的自动持久化给关掉。
- 因为常用Mongo所以习惯性首先想到Mongodb从redis取出2000条再一次性插入Mongo但速度还是不乐观瓶颈在于MongoDB。猜测是MongoDB对_id的去重导致的也可能是物理硬件的限制
- 后来想用SSDB因为SSDB和Redis很相似用list存肯定速度快很多。然而SSDB唯独不支持Centos7其他版本的系统都可。。
- 最后才想起来用txt这个最傻的方法却是非常有效的方法。速度很快只是为了防止读取时内存不足每100万个fingerprint存在了一个txt四台机器txt总共有七百个左右。
- fingerprint取出来后redis只剩下一千多万的Request种子占用内存9G+。然后用Bloomfilter将txt中的fingerprint写回Redis写完以后Redis占用内存25G开启redis自动持久化后内存占用49G左右。
基于Redis的Bloomfilter去重
“去重”是日常工作中会经常用到的一项技能在爬虫领域更是常用并且规模一般都比较大。去重需要考虑两个点去重的数据量、去重速度。为了保持较快的去重速度一般选择在内存中进行去重。
- 数据量不大时可以直接放在内存里面进行去重例如python可以使用set()进行去重。
- 当去重数据需要持久化时可以使用redis的set数据结构。
- 当数据量再大一点时可以用不同的加密算法先将长字符串压缩成 16/32/40 个字符再使用上面两种方法去重
- 当数据量达到亿甚至十亿、百亿数量级时内存有限必须用“位”来去重才能够满足需求。Bloomfilter就是将去重对象映射到几个内存“位”通过几个位的 0/1值来判断一个对象是否已经存在。
- 然而Bloomfilter运行在一台机器的内存上不方便持久化机器down掉就什么都没啦也不方便分布式爬虫的统一去重。如果可以在Redis上申请内存进行Bloomfilter以上两个问题就都能解决了。
本文即是用Python基于Redis实现Bloomfilter去重。下面先放代码最后附上说明。
# encoding=utf-8import redis
from hashlib import md5class SimpleHash(object):def __init__(self, cap, seed):self.cap = capself.seed = seeddef hash(self, value):ret = 0for i in range(len(value)):ret += self.seed * ret + ord(value[i])return (self.cap - 1) & retclass BloomFilter(object):def __init__(self, host='localhost', port=6379, db=0, blockNum=1, key='bloomfilter'):""":param host: the host of Redis:param port: the port of Redis:param db: witch db in Redis:param blockNum: one blockNum for about 90,000,000; if you have more strings for filtering, increase it.:param key: the key's name in Redis"""self.server = redis.Redis(host=host, port=port, db=db)self.bit_size = 1 << 31 # Redis的String类型最大容量为512M现使用256M= 2^8 *2^20 字节 = 2^28 * 2^3bitself.seeds = [5, 7, 11, 13, 31, 37, 61]self.key = keyself.blockNum = blockNumself.hashfunc = []for seed in self.seeds:self.hashfunc.append(SimpleHash(self.bit_size, seed))def isContains(self, str_input):if not str_input:return Falsem5 = md5()m5.update(str_input)str_input = m5.hexdigest()ret = Truename = self.key + str(int(str_input[0:2], 16) % self.blockNum)for f in self.hashfunc:loc = f.hash(str_input)ret = ret & self.server.getbit(name, loc)return retdef insert(self, str_input):m5 = md5()m5.update(str_input)str_input = m5.hexdigest()name = self.key + str(int(str_input[0:2], 16) % self.blockNum)for f in self.hashfunc:loc = f.hash(str_input)self.server.setbit(name, loc, 1)if __name__ == '__main__':
""" 第一次运行时会显示 not exists!之后再运行会显示 exists! """bf = BloomFilter()if bf.isContains('http://www.baidu.com'): # 判断字符串是否存在print 'exists!'else:print 'not exists!'bf.insert('http://www.baidu.com')- Bloomfilter算法如何使用位去重这个百度上有很多解释。简单点说就是有几个seeds现在申请一段内存空间一个seed可以和字符串哈希映射到这段内存上的一个位几个位都为1即表示该字符串已经存在。插入的时候也是将映射出的几个位都置为1。
需要提醒一下的是Bloomfilter算法会有漏失概率即不存在的字符串有一定概率被误判为已经存在。这个概率的大小与seeds的数量、申请的内存大小、去重对象的数量有关。下面有一张表m表示内存大小多少个位n表示去重对象的数量k表示seed的个数。例如我代码中申请了256M即1<<31m=2^31约21.5亿seed设置了7个。看k=7那一列当漏失率为8.56e-05时m/n值为23。所以n = 21.5/23 = 0.93(亿表示漏失概率为8.56e-05时256M内存可满足0.93亿条字符串的去重。同理当漏失率为0.000112时256M内存可满足0.98亿条字符串的去重。
基于Redis的Bloomfilter去重其实就是利用了Redis的String数据结构但Redis一个String最大只能512M所以如果去重的数据量大需要申请多个去重块代码中blockNum即表示去重块的数量。
代码中使用了MD5加密压缩将字符串压缩到了32个字符也可用hashlib.sha1()压缩成40个字符。
它有两个作用
一是Bloomfilter对一个很长的字符串哈希映射的时候会出错经常误判为已存在压缩后就不再有这个问题
二是压缩后的字符为 0~f 共16中可能我截取了前两个字符再根据blockNum将字符串指定到不同的去重块进行去重。
总结
基于Redis的Bloomfilter去重既用上了Bloomfilter的海量去重能力又用上了Redis的可持久化能力基于Redis也方便分布式机器的去重。在使用的过程中要预算好待去重的数据量则根据上面的表适当地调整seed的数量和blockNum数量seed越少肯定去重速度越快但漏失率越大。
原文链接http://blog.csdn.net/bone_ace/article/details/53107018
scrapy_redis 种子优化
继 scrapy_redis去重优化(7亿数据) 优化完去重之后Redis的内存消耗降了许多然而还不满足。这次对scrapy_redis的种子队列作了一些优化严格来说并不能用上“优化”这词其实就是结合自己的项目作了一些改进对本项目能称作优化对scrapy_redis未必是个优化。
scrapy_redis默认是将Request对象序列化后变成一条字符串存入Redis作为种子需要的时候再取出来进行反序列化还原成一个Request对象。
现在的问题是序列化后的字符串太长短则几百个字符长则上千。我的爬虫平时至少也要维护包含几千万种子的种子队列占用内存在20G~50G之间Centos。想要缩减种子的长度这样不仅Redis的内存消耗会降低各个slaver从Redis拿种子的速度也会有所提高从而整个分布式爬虫系统的抓取速度也会有所提高效果视具体情况而定要看爬虫主要阻塞在哪里。
1、首先看调度器即scrapy_redis模块下的scheduler.py文件可以看到enqueue_request()方法和next_request()方法就是种子入队列和出队列的地方self.queue指的是我们在setting.py里面设定的SCHEDULER_QUEUE_CLASS值常用的是'scrapy_redis.queue.SpiderPriorityQueue'。
2、进入scrapy模块下的queue.py文件SpiderPriorityQueue类的代码如下
class SpiderPriorityQueue(Base):"""Per-spider priority queue abstraction using redis' sorted set"""def __len__(self):"""Return the length of the queue"""return self.server.zcard(self.key)def push(self, request):"""Push a request"""data = self._encode_request(request)pairs = {data: -request.priority}self.server.zadd(self.key, **pairs)def pop(self, timeout=0):"""Pop a requesttimeout not support in this queue class"""pipe = self.server.pipeline()pipe.multi()pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0)results, count = pipe.execute()if results:return self._decode_request(results[0])可以看到上面用到了Redis的zset数据结构它可以给种子加优先级在进Redis之前用_encode_request()方法将Request对象转成字符串_encode_request()和_decode_request是Base类下面的两个方法
def _encode_request(self, request):"""Encode a request object"""return pickle.dumps(request_to_dict(request, self.spider), protocol=-1)def _decode_request(self, encoded_request):"""Decode an request previously encoded"""return request_from_dict(pickle.loads(encoded_request), self.spider)可以看到这里先将Request对象转成一个字典再将字典序列化成一个字符串。Request对象怎么转成一个字典呢看下面的代码一目了然。
def request_to_dict(request, spider=None):"""Convert Request object to a dict.If a spider is given, it will try to find out the name of the spider methodused in the callback and store that as the callback."""cb = request.callbackif callable(cb):cb = _find_method(spider, cb)eb = request.errbackif callable(eb):eb = _find_method(spider, eb)d = {'url': to_unicode(request.url), # urls should be safe (safe_string_url)'callback': cb,'errback': eb,'method': request.method,'headers': dict(request.headers),'body': request.body,'cookies': request.cookies,'meta': request.meta,'_encoding': request._encoding,'priority': request.priority,'dont_filter': request.dont_filter,}return d
![]()
注d为Request对象转过来的字典data为字典序列化后的字符串。
3、了解完scrapy_redis默认的种子处理方式现在针对自己的项目作一些调整。我的是一个全网爬虫每个种子需要记录的信息主要有两个url和callback函数名。此时我们选择不用序列化直接用简单粗暴的方式将callback函数名和url拼接成一条字符串作为一条种子这样种子的长度至少会减少一半。另外我们的种子并不需要设优先级所以也不用zset了改用Redis的list。以下是我新建的SpiderSimpleQueue类加在queue.py中。如果在settings.py里将
SCHEDULER_QUEUE_CLASS值设置成 'scrapy_redis.queue.SpiderSimpleQueue'即可使用我这种野蛮粗暴的种子。
from scrapy.utils.reqser import request_to_dict, request_from_dict, _find_methodclass SpiderSimpleQueue(Base):""" url + callback """def __len__(self):"""Return the length of the queue"""return self.server.llen(self.key)def push(self, request):"""Push a request"""url = request.urlcb = request.callbackif callable(cb):cb = _find_method(self.spider, cb)data = '%s--%s' % (cb, url)self.server.lpush(self.key, data)def pop(self, timeout=0):"""Pop a request"""if timeout > 0:data = self.server.brpop(self.key, timeout=timeout)if isinstance(data, tuple):data = data[1]else:data = self.server.rpop(self.key)if data:cb, url = data.split('--', 1)try:cb = getattr(self.spider, str(cb))return Request(url=url, callback=cb)except AttributeError:raise ValueError("Method %r not found in: %s" % (cb, self.spider))__all__ = ['SpiderQueue', 'SpiderPriorityQueue', 'SpiderSimpleQueue', 'SpiderStack']4、另外需要提醒的是如果scrapy中加了中间件process_request()当yield一个Request对象的时候scrapy_redis会直接将它丢进Redis种子队列未执行process_requset()需要一个Request对象的时候scrapy_redis会从Redis队列中取出种子此时才会处理process_request()方法接着去抓取网页。
所以并不需要担心process_request()里面添加的Cookie在Redis中放太久会失效因为进Redis的时候它压根都还没执行process_request()。事实上Request对象序列化的时候带上的字段很多都是没用的默认字段很多爬虫都可以用 “callback+url” 的方式来优化种子。
5、最后在Scrapy_Redis_BloomfilterGithub传送门这个demo中我已作了修改大家可以试试效果。
结语
经过以上优化Redis的内存消耗从42G降到了27G里面包含7亿多条种子的去重数据 和4000W+条种子。并且六台子爬虫的抓取速度都提升了一些。两次优化内存消耗从160G+降到现在的27G效果也是让人满意
原文链接http://blog.csdn.net/bone_ace/article/details/53306629
DNS解析缓存
这是Python爬虫中DNS解析缓存模块中的核心代码是去年的代码了现在放出来 有兴趣的可以看一下。
一般一个域名的DNS解析时间在10~60毫秒之间这看起来是微不足道但是对于大型一点的爬虫而言这就不容忽视了。例如我们要爬新浪微博同个域名下的请求有1千万这已经不算多的了那么耗时在10~60万秒之间一天才86400秒。也就是说单DNS解析这一项就用了好几天时间此时加上DNS解析缓存效果就明显了。
下面直接放代码说明在后面。
# encoding=utf-8
# ---------------------------------------
# 版本0.1
# 日期2016-04-26
# 作者九茶<bone_ace@163.com>
# 开发环境Win64 + Python 2.7
# ---------------------------------------import socket
# from gevent import socket_dnscache = {}def _setDNSCache():""" DNS缓存 """def _getaddrinfo(*args, **kwargs):if args in _dnscache:# print str(args) + " in cache"return _dnscache[args]else:# print str(args) + " not in cache"_dnscache[args] = socket._getaddrinfo(*args, **kwargs)return _dnscache[args]if not hasattr(socket, '_getaddrinfo'):socket._getaddrinfo = socket.getaddrinfosocket.getaddrinfo = _getaddrinfo说明
其实也没什么难度就是将socket里面的缓存保存下来避免重复获取。
可以将上面的代码放在一个dns_cache.py文件里爬虫框架里调用一下这个_setDNSCache()方法就行了。
需要说明一下的是如果你使用了gevent协程并且用上了monkey.patch_all()要注意此时爬虫已经改用gevent里面的socket了DNS解析缓存模块也应该要用gevent的socket才行。
爬虫扩展
Python-Goose - Article Extractor : 文章提取
Goose Extractor是什么
Goose Extractor是一个Python的开源文章提取库。可以用它提取文章的文本内容、图片、视频、元信息和标签。Goose本来是由Gravity.com编写的Java库最近转向了scala。
Goose Extractor网站是这么介绍的
'Goose Extractor完全用Python重写了。目标是给定任意资讯文章或者任意文章类的网页不仅提取出文章的主体同时提取出所有元信息以及图片等信息。'
官方网站https://github.com/grangier/python-goose
Setup
mkvirtualenv --no-site-packages goose
git clone https://github.com/grangier/python-goose.git
cd python-goose
pip install -r requirements.txt
python setup.py installConfiguration
There are two ways to pass configuration to goose. The first one is to pass goose a Configuration() object. The second one is to pass a configuration dict.
For instance, if you want to change the userAgent used by Goose just pass:
g = Goose({'browser_user_agent': 'Mozilla'})
Switching parsers : Goose can now be used with lxml html parser or lxml soup parser. By default the html parser is used. If you want to use the soup parser pass it in the configuration dict :g = Goose({'browser_user_agent': 'Mozilla', 'parser_class':'soup'})Goose is now language aware
For example, scraping a Spanish content page with correct meta language tags:
from goose import Goose
url = 'https://www.yahoo.com/news/keegan-michael-key-brings-back-201647910.html?nhp=1'
g = Goose()
article = g.extract(url=url)
article.title
u"Keegan-Michael Key Brings Back Obama's Hilarious Anger Translator for RNC"
article.cleaned_text
u"Keegan-Michael Key does an impersonation of his role as President Obama's 'anger translator' from the 2015 White House Correspondents Dinner during Popcorn With Peter Travers."
article.infos
{'authors': [],'cleaned_text': u"Keegan-Michael Key does an impersonation of his role as President Obama's 'anger translator' from the 2015 White House Correspondents Dinner during Popcorn With Peter Travers.",'domain': 'www.yahoo.com','image': {'height': 0, 'type': 'image', 'url': '1280', 'width': 0},'links': [],'meta': {'canonical': 'https://www.yahoo.com/news/keegan-michael-key-brings-back-201647910.html','description': "Keegan-Michael Key does an impersonation of his role as President Obama's 'anger translator' from the 2015 White House Correspondents Dinner during Popcorn With Peter Travers.",'favicon': 'https://s.yimg.com/os/mit/media/p/common/images/favicon_new-7483e38.svg','keywords': '','lang': 'en'},'movies': [],'opengraph': {'description': "Keegan-Michael Key does an impersonation of his role as President Obama's 'anger translator' from the 2015 White House Correspondents Dinner during Popcorn With Peter Travers.",'image': 'https://s.yimg.com/uu/api/res/1.2/lSnhGN5TgE81cDklUN91jg--/aD03MjA7dz0xMjgwO3NtPTE7YXBwaWQ9eXRhY2h5b24-/http://media.zenfs.com/en-US/video/video.abcnewsplus.com/d5fbdafba5110e27aaf0fb4084967e0c','title': "Keegan-Michael Key Brings Back Obama's Hilarious Anger Translator for RNC",'type': 'article','url': 'https://www.yahoo.com/news/keegan-michael-key-brings-back-201647910.html'},'publish_date': None,'tags': [],'title': u"Keegan-Michael Key Brings Back Obama's Hilarious Anger Translator for RNC",'tweets': []}Goose in Chinese
Some users want to use Goose for Chinese content. Chinese word segmentation is way more difficult to deal with than occidental languages. Chinese needs a dedicated StopWord analyser that need to be passed to the config object.
from goose import Goose
from goose.text import StopWordsChinese
url = 'http://world.huanqiu.com/exclusive/2016-07/9209839.html'
g = Goose({'stopwords_class': StopWordsChinese})
article = g.extract(url=url)
print article.cleaned_text[:150]
【环球时报综合报道】针对美国共和党全国代表大会审议通过的新党纲在台湾、涉藏、经贸、南海等问题上出现干涉中国内政、指责中国政策的内容中国外交部发言人陆慷20日回应说推动中美关系稳定发展符合两国根本利益有利于亚太地区乃至世界的和平与发展是双方应该坚持的正确方向。美国无论哪个党派都应该客观、理性
print article.meta_description
美国共和党新党纲“21次提及中国”。
print article.meta_keywords
中国,美共和党,党纲,内政Known issues
There are some issues with unicode URLs.
Cookie handling : Some websites need cookie handling. At the moment the only work around is to use the raw_html extraction. For instance:
import urllib2
import goose
url = "http://oversea.huanqiu.com/article/2016-07/9198141.html"
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(url)
raw_html = response.read()
g = goose.Goose()
a = g.extract(raw_html=raw_html)
a.infos
{'authors': [],'cleaned_text': u'','domain': None,'image': None,'links': [],'meta': {'canonical': None,'description': u'\u4f60\u771f\u4e22\u4eba\uff01\u4e2d\u56fd\u7528\u5927\u5c4f\u5e55\u66dd\u5149\u201c\u8001\u8d56\u201d','favicon': 'http://himg2.huanqiu.com/statics/images/favicon1.ico','keywords': u'\u73af\u7403\u7f51','lang': None},'movies': [],'opengraph': {},'publish_date': None,'tags': [],'title': u'\u6cf0\u5a92\uff1a\u4f60\u771f\u4e22\u4eba\uff01\u4e0a\u6d77\u7528\u5927\u5c4f\u5e55\u66dd\u5149\u201c\u8001\u8d56\u201d_\u6d77\u5916\u770b\u4e2d\u56fd_\u73af\u7403\u7f51','tweets': []}a.meta_keywords u'\u8521\u82f1\u6587,\u4e5d\u4e8c\u5171\u8bc6'
浏览器命令行 CURL
CURL是利用URL语法在命令行方式下工作的开源文件传输工具。它支持http,https,ftp,ftps,telnet等多种协议常被用来抓取网页和监控Web服务器状态。Curl是Linux下一个很强大的http命令行工具其功能十分强大。
CURL使用
curl命令可以用来构造http请求。 通用语法curl [option] [URL...]
基本用法
curl http://www.baidu.com抓取 www.ip138.com 查询网 如发现乱码可以使用iconv转码
curl http://ip138.com|iconv -f gb2312回车之后html显示在屏幕上了 ~
1.1 get方式提交数据
curl -G -d "name=value&name2=value2" http://www.baidu.com1.2 post方式提交数据
curl -d "name=value&name2=value2" http://www.baidu.com #post数据 curl -d a=b&c=d&txt@/tmp/txt http://www.baidu.com #post文件以表单的方式上传文件
curl -F file=@/tmp/me.txt http://www.aiezu.com相当于设置form表单的method="POST"和enctype='multipart/form-data'两个属性。
保存访问的网页
curl http://www.baidu.com > page.html或者用curl的内置option就好存下http的结果用这个option: -o
curl -o page.html http://www.baidu.comcurl -O http://sh.meituan.com/shop/42030772% Total % Received % Xferd Average Speed Time Time Time CurrentDload Upload Total Spent Left Speed 100 159k 0 159k 0 0 328k 0 --:--:-- --:--:-- --:--:-- 328k下载过程中标准输出还会显示下载的统计信息,比如进度、下载字节数、下载速度等
这样自动保存文件42030772看到屏幕上出现一个下载页面进度指示。显示100%则表示保存成功
设置Header
curl -H 'Host: 157.166.226.25'-H 'Accept-Language: es'-H 'Cookie: ID=1234' http://cnn.com显示文档信息
-I显示文档信息
curl -I http://www.sina.com.cn/ -H Accept-Encoding:gzip,defalte指定proxy服务器以及其端口
-x 可以指定http访问所使用的proxy服务器及其端口
curl -x 123.45.67.89:1080 -o page.html http://www.linuxidc.com使用cookie
有些网站是使用cookie来记录session信息。对于chrome这样的浏览器可以轻易处理cookie信息但在curl中只要增加相关参数也是可以很容易的处理cookie
-c 保存http的response里面的cookie信息。
curl -c cookiec.txt http://www.baidu.com执行后cookie信息就被存到了cookiec.txt里面了
-D 保存http的response里面的header信息
curl -D cookied.txt http://www.baidu.com执行后cookie信息就被存到了cookied.txt里面了 注意-c(小写)产生的cookie和-D里面的cookie是不一样的。
-b使用cookie
很多网站都是通过监视你的cookie信息来判断你是否按规矩访问他们的网站的因此我们需要使用保存的cookie信息。
curl -b cookiec.txt http://www.baidu.com模仿浏览器信息
有些网站需要使用特定的浏览器去访问他们有些还需要使用某些特定的版本。
-A :指定浏览器去访问网站
curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.baidu.com这样服务器端就会认为是使用IE8.0去访问的
伪造referer盗链
很多服务器会检查http访问的referer从而来控制访问。比如你是先访问首页然后再访问首页中的邮箱页面这里访问邮箱的referer地址就是访问首页成功后的页面地址如果服务器发现对邮箱页面访问的referer地址不是首页的地址就断定那是个盗连了
-e设定referer
curl -e "www.baidu.com" http://news.baidu.com/这样就会让服务器其以为你是从www.baidu.com点击某个链接过来的
下载文件
9.1 -o/-O文件下载
-o 把输出写到该文件中
curl -o dodo1.jpg http://www.shaimn.com/uploads/allimg/160613/1-160613121111.jpg-O把输出写到该文件中保留远程文件的文件名
curl -O http://www.shaimn.com/uploads/allimg/160613/1-160613121111.jpg这样就会以服务器上的名称保存文件到本地
9.2 循环下载
有时候下载图片可以能是前面的部分名称是一样的就最后的尾椎名不一样
curl -O http://www.shaimn.com/uploads/allimg/160613/1-16061312111[1-5].jpg这样就会把 1-16061312111.jpg、 1-16061312112.jpg、 1-16061312113.jpg、 1-16061312114.jpg、 1-16061312115.jpg 全部保存下来
9.3 下载重命名
curl http://www.shaimn.com/uploads/allimg/160613/1-16061312111[1-5].jpg -o dodo#1.jpgdodo1.jpgdodo2.jpgdodo3.jpgdodo4.jpgdodo5.jpg
9.4 分块下载
有时候下载的东西会比较大这个时候我们可以分段下载。使用内置option-r
curl -r 0-100 -o dodo1_part1.JPG http://www.shaimn.com/uploads/allimg/160613/1-160613121111.jpg curl -r 100-200 -o dodo1_part2.JPG http://www.shaimn.com/uploads/allimg/160613/1-160613121111.jpg curl -r 200- -o dodo1_part3.JPG http://www.shaimn.com/uploads/allimg/160613/1-160613121111.jpg cat dodo1_part* > dodo1.JPG这样就可以查看dodo1.JPG的内容了
9.5 通过ftp下载文件
curl可以通过ftp下载文件curl提供两种从ftp中下载的语法
curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG9.6 显示下载进度条
curl -# -O http://www.linux.com/dodo1.JPG9.7不会显示下载进度信息
curl -s -O http://www.linux.com/dodo1.JPG断点续传
在windows中我们可以使用迅雷这样的软件进行断点续传。
curl可以通过内置option:-C同样可以达到相同的效果 如果在下载dodo1.JPG的过程中突然掉线了可以使用以下的方式续传
curl -C -O http://www.linux.com/dodo1.JPG通过使用-C选项可对大文件使用断点续传功能如# 当文件在下载完成之前结束该进程 curl -O http://www.gnu.org/software/gettext/manual/gettext.html ############## 20.1%# 通过添加-C选项继续对该文件进行下载已经下载过的文件不会被重新下载 curl -C - -O http://www.gnu.org/software/gettext/manual/gettext.html ############### 21.1%上传文件
curl不仅仅可以下载文件还可以上传文件。通过内置option:-T来实现
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/这样就向ftp服务器上传了文件dodo1.JPG
显示抓取错误
# curl -f http://www.linux.com/error对CURL使用网络限速
通过--limit-rate选项对CURL的最大网络使用进行限制
下载速度最大不会超过1000B/second curl --limit-rate 1000B -O http://www.gnu.org/software/gettext/manual/gettext.html
linux curl命令
-a/--append 上传文件时附加到目标文件
-A/--user-agent <string> 设置用户代理发送给服务器
- anyauth 可以使用“任何”身份验证方法
-b/--cookie <name=string/file> cookie字符串或文件读取位置
- basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII /文本传输
-c/--cookie-jar <file> 操作结束后把cookie写入到这个文件中
-C/--continue-at <offset> 断点续转
-d/--data <data> HTTP POST方式传送数据
--data-ascii <data> 以ascii的方式post数据
--data-binary <data> 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
-D/--dump-header <file> 把header信息写入到该文件中
--egd-file <file> 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-e/--referer 来源网址
-E/--cert <cert[:passwd]> 客户端证书文件和密码 (SSL)
--cert-type <type> 证书文件类型 (DER/PEM/ENG) (SSL)
--key <key> 私钥文件名 (SSL)
--key-type <type> 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass <pass> 私钥密码 (SSL)
--engine <eng> 加密引擎使用 (SSL). "--engine list" for list
--cacert <file> CA证书 (SSL)
--capath <directory> CA目录 (made using c_rehash) to verify peer against (SSL)
--ciphers <list> SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout <seconds> 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
-f/--fail 连接失败时不显示http错误
--ftp-create-dirs 如果远程目录不存在创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form <name=content> 模拟http表单提交数据
-form-string <name=string> 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header <line>自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
从文件中读取-j/--junk-session-cookies忽略会话Cookie
- 界面<interface>指定网络接口/地址使用
- krb4 <级别>启用与指定的安全级别krb4
-j/--junk-session-cookies 读取文件进忽略session cookie
--interface <interface> 使用指定网络接口/地址
--krb4 <level> 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate <rate> 设置传输速度
--local-port<NUM> 强制使用本地端口号
-m/--max-time <seconds> 设置最大传输时间
--max-redirs <num> 设置最大读取的目录数
--max-filesize <bytes> 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-o/--output 把输出写到该文件中
-O/--remote-name 把输出写到该文件中保留远程文件的文件名
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port <address> 使用端口地址而不是使用PASV
-Q/--quote <cmd>文件传输前发送命令到服务器
-r/--range <range>检索来自HTTP/1.1或FTP服务器字节范围
--range-file 读取SSL的随机文件
-R/--remote-time 在本地生成文件时保留远程文件时间
--retry <num> 传输出现问题时重试的次数
--retry-delay <seconds> 传输出现问题时设置重试间隔时间
--retry-max-time <seconds> 传输出现问题时设置最大重试时间
-s/--silent静音模式。不输出任何东西
-S/--show-error 显示错误
--socks4 <host[:port]> 用socks4代理给定主机和端口
--socks5 <host[:port]> 用socks5代理给定主机和端口
--stderr <file>
-t/--telnet-option <OPT=val> Telnet选项设置
--trace <file> 对指定文件进行debug
--trace-ascii <file> Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时添加时间戳
-T/--upload-file <file> 上传文件
--url <URL> Spet URL to work with
-u/--user <user[:password]>设置服务器的用户和密码
-U/--proxy-user <user[:password]>设置代理用户名和密码
-v/--verbose
-V/--version 显示版本信息
-w/--write-out [format]什么输出完成后
-x/--proxy <host[:port]>在给定的端口上使用HTTP代理
-X/--request <command>指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1SSL
-2/--sslv2 使用SSLv2的SSL
-3/--sslv3 使用的SSLv3SSL
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url进行第三方传送
--3p-user 使用用户名和密码进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
-#/--progress-bar 用进度条显示当前的传送状态一些常见的限制方式
上述都是讲的都是一些的基础的知识现在我就列一些比较常见的限制方式如何突破这些限制抓取数据。
Basic Auth 一般会有用户授权的限制会在headers的Autheration字段里要求加入
Referer 通常是在访问链接时必须要带上Referer字段服务器会进行验证例如抓取京东的评论
User-Agent 会要求真是的设备如果不加会用编程语言包里自有User-Agent可以被辨别出来
Cookie 一般在用户登录或者某些操作后服务端会在返回包中包含Cookie信息要求浏览器设置Cookie没有Cookie会很容易被辨别出来是伪造请求
也有本地通过JS根据服务端返回的某个信息进行处理生成的加密信息设置在Cookie里面
Gzip 请求headers里面带了gzip返回有时候会是gzip压缩需要解压
JavaScript加密操作 一般都是在请求的数据包内容里面会包含一些被javascript进行加密限制的信息例如新浪微博会进行SHA1和RSA加密之前是两次SHA1加密然后发送的密码和用户名都会被加密
其他字段 因为http的headers可以自定义地段所以第三方可能会加入了一些自定义的字段名称或者字段值这也是需要注意的。
真实的请求过程中其实不止上面某一种限制可能是几种限制组合在一次比如如果是类似RSA加密的话可能先请求服务器得到Cookie然后再带着Cookie去请求服务器拿到公钥然后再用js进行加密再发送数据到服务器。所以弄清楚这其中的原理并且耐心分析很重要。
防封禁策略
Scrapy:
http://doc.scrapy.org/en/master/topics/practices.html#avoiding-getting-banned
如何让你的scrapy爬虫不再被ban
根据scrapy官方文档http://doc.scrapy.org/en/master/topics/practices.html#avoiding-getting-banned里面的描述要防止scrapy被ban主要有以下几个策略。
- 动态设置user agent
- 禁用cookies
- 设置延迟下载
- 使用Google cache
- 使用IP地址池Tor project、VPN和代理IP
- 使用Crawlera
由于Google cache受国内网络的影响你懂得 所以主要从动态随机设置user agent、禁用cookies、设置延迟下载和使用代理IP这几个方式。
本文以cnblogs为例
- 创建middlewares.py
scrapy代理IP、user agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控制下面我们创建middlewares.py文件。
编辑 `middlewares.py`
[root@bogon cnblogs]# vi cnblogs/middlewares.py如下内容
import random
import base64
from settings import PROXIESclass RandomUserAgent(object):"""Randomly rotate user agents based on a list of predefined ones"""def __init__(self, agents):self.agents = agents@classmethoddef from_crawler(cls, crawler):return cls(crawler.settings.getlist('USER_AGENTS'))def process_request(self, request, spider):#print "**************************" + random.choice(self.agents)request.headers.setdefault('User-Agent', random.choice(self.agents))class ProxyMiddleware(object):def process_request(self, request, spider):proxy = random.choice(PROXIES)if proxy['user_pass'] is not None:#request.meta['proxy'] = "http://YOUR_PROXY_IP:PORT"request.meta['proxy'] = "http://%s" % proxy['ip_port']#proxy_user_pass = "USERNAME:PASSWORD"encoded_user_pass = base64.encodestring(proxy['user_pass'])request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_passprint "**************ProxyMiddleware have pass************" + proxy['ip_port']else:print "**************ProxyMiddleware no pass************" + proxy['ip_port']request.meta['proxy'] = "http://%s" % proxy['ip_port']类RandomUserAgent主要用来动态获取user agentuser agent列表USER_AGENTS在settings.py中进行配置。
类ProxyMiddleware用来切换代理proxy列表PROXIES也是在settings.py中进行配置。
如果你用的是socks5代理那么对不起目前scrapy还不能直接支持可以通过Privoxy等软件将其本地转化为http代理
- 修改settings.py配置USER_AGENTS和PROXIES
a)添加USER_AGENTSUSER_AGENTS = ["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)","Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5","Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20","Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]b)添加代理IP设置PROXIESPROXIES = [{'ip_port': '111.11.228.75:80', 'user_pass': ''},{'ip_port': '120.198.243.22:80', 'user_pass': ''},{'ip_port': '111.8.60.9:8123', 'user_pass': ''},{'ip_port': '101.71.27.120:80', 'user_pass': ''},{'ip_port': '122.96.59.104:80', 'user_pass': ''},{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]代理IP可以网上搜索一下上面的代理IP获取自http://www.xici.net.co/
c)禁用cookies
COOKIES_ENABLED=False
d)设置下载延迟
DOWNLOAD_DELAY=3
e)最后设置DOWNLOADER_MIDDLEWARES DOWNLOADER_MIDDLEWARES = {'cnblogs.middlewares.RandomUserAgent': 1,'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,'cnblogs.middlewares.ProxyMiddleware': 100,
}保存settings.py
3、测试
[root@bogon cnblogs]# scrapy crawl CnblogsSpider
本文的user agent和proxy列表都是采用settings.py的方式进行设置的实际生产中user agent和proxy有可能会经常更新每次更改配置文件显得很笨拙也不便于管理。因而可以根据需要保存在mysql数据库
SSL会话劫持
SSL中间人监测关键技术-SSL会话劫持
数据流重定向技术是SSL中间人监测的基础该技术的使用使得被监测主机与SSL服务器的通信流量都会经过监测主机。对于一般的中间人监测来说再加上数据转发机制就已经足够。但对于SSL中间人监测来说仅仅通过数据流重定向得到的都是经过加密后的数据无法直接用来进行HTTP协议解析。故此必需使用SSL会话劫持技术才能得到被监测主机与SSL服务器之间通信数据的明文。
自SSL问世以来在其应用范围越来越广泛同时多种针对SSL协议本身的缺陷或者其不规范引用的SSL会话劫持方法也随之出现下面将详细分析两种典型的SSL会话劫持的实现原理和实现条件。
一、利用伪造的X.509证书
1.1 会话劫持原理
当SSL客户端与SSL服务端建立连接时在正常的连接握手阶段客户端必定会要求服务端出示其X.509公钥证书并根据以下3个要素验证服务器证书的有效性
a 该公钥证书的subject name(主题名)和所访问的服务器站点的名称是否一致 b 该公钥证书的是否过期 c 该公钥证书及其签发者证书链中的证书的数字签名是否有效层层验证一直验证到根CA证书为止。
当SSL客户端访问一个基于HTTPS的加密Web站点时只要上述三个要素有一个验证没有通过SSL协议就会发出告警大多数浏览器会弹出一个提示框提示服务器证书存在的问题但不会直接断开SSL连接而是让用户决定是否继续。图1-1展示了IE浏览器弹出的安全警报提示框。
图1-1 IE浏览器验证服务器证书失败后弹出的提示框
大多数浏览器在验证到服务器证书存在问题后的处理方式是存在巨大隐患的因为用户往往由于缺乏安全意识或者图方便而选择接受不安全的证书这就使得伪造一个和合法证书极为相似的“伪证书”骗取SSL 客户端用户信任的手段成为可能。图1-2展示了这种SSL会话劫持的主要流程图中C为SSL客户端M为监测主机S为SSL服务端
图1-2 基于伪造证书进行劫持的流程
文字描述如下
主机M通过数据流重定向技术使得主机C与主机S之间的通信流量都流向主机M主机C本欲与主机S建立SSL连接但发送的连接建立请求被重定向到了主机M 主机C首先与主机M建立TCP连接然后向主机M发起SSL连接请求 主机M收到来自主机C的连接请求后首先与主机S建立TCP连接然后向主机S发起SSL连接请求 主机S响应主机M的请求由此主机M与主机S之间成功建立SSL连接主机M同时获得主机S的X.509公钥证书Certificate_S 主机M根据Certificate_S中的关键信息主要是subject name、有效期限等伪造一个极相似的自签名证书Certificate_S’,并以此证书响应第②步中来自主机C的SSL连接请求 主机C的浏览器验证Certificate_S’的有效性发现subject name与请求的站点名称一致证书还在有效期内但是并非由信任的机构颁发。于是弹出提示框让用户选择是否继续。由于Certificate_S’与Certificate_S从外表上几乎看不出来差别大部分用户会选择继续 这是SSL会话劫持可以成功的关键 由此主机C与主机M成功建立SSL连接。 这样以后主机C发往SSL服务端的数据主机M可以捕获并解密查看主机S返回给SSL客户端的数据主机M也可以捕获并解密查看。至此主机M实现了完整的SSL中间人监测。 经过以上步骤主机M成功实现了主机CSSL客户端与主机SSSL服务端之间的会话劫持并可以对明文形式的会话内容进行监测。
1.2 成功的必要条件 这种类型的SSL会话劫持成功的必要条件如下
a 能够通过ARP欺骗、DNS欺骗或者浏览器数据重定向等欺骗技术使得SSL客户端C和服务端S之间的数据都流向中间人监测主机 b SSL客户端在接收到伪造的X.509证书后用户选择信任该证书并继续SSL连接 c SSL服务端未要求对SSL客户端进行认证。 二、利用HTTP与HTTPS之间跳转的验证漏洞 2.1 会话劫持原理 用户浏览网页时使用SSL协议的方式一般有两种。一种是在浏览器地址栏输入网址时直接指定协议类型为HTTPS另一种是通过HTTP响应的302状态将网页重定向到HTTPS 链接。2009年2月在美国拉斯维加斯举行的BlackHat黑客大会上安全研究人员Moxie Marlinspike演示了通过自己研发的SSLstrip工具劫持SSL会话来截获注册数据的方法为SSL会话劫持提供了新思路。
SSLstrip使用了社会工程学的原理许多人为了图方便省事在输入网址时一般不考虑传输协议习惯上只是简单输入主机名浏览器默认在这种情况下会使用HTTP协议。例如用户为了使用Gmail邮箱直接输入accounts.google.com浏览器会给谷歌服务器发送一个HTTP 请求谷歌服务器认为电子邮件属于应加密的重要事务使用HTTP不恰当应改为使用HTTPS于是它返回一个状态码为302的HTTP 响应给出一个重定向网址https://accounts.google.com/ServiceLogin?passive=1209600&continue=https%3A%2F%2Faccounts.google.com%2FManageAccount&followup=https%3A%2F%2Faccounts.google.com%2FManageAccount浏览器再使用这个重定向网址发出HTTPS 请求。 一个原本应该从头到尾使用HTTPS加密会话的过程中混入了使用明文传输的HTTP会话一旦HTTP会话被劫持HTTPS会话就可能受到威胁 。SSLstrip 正是利用这一点通过劫持HTTP 会话劫持了SSL会话如图2-1所示。
图2-1 SSLstrip原理示意图
下面具体阐述基于SSLstrip的SSL会话劫持流程阐述中依然以主机C为SSL客户端主机M为监测主机主机S为SSL服务端
主机M通过ARP重定向技术使得主机C所有与外网的通信流都会从主机M处经过。 主机C向主机S的一个HTTPS页面发出一个HTTP请求主机M监听这个请求并转发给主机S。 主机S返回一个状态码为302的HTTP 响应报文报文消息头中Location头域以及消息实体中都给出了重定向网址形式分别为“Location: https://***.com/…”与“”。 主机M解析来自主机S的响应报文将其中所有的https替换成http指定主机M另一个未使用的端口为通信端口假设为8181端口并且记录修改过的url。需要做的替换包括消息头中的“Location: https://***.com/…”替换成“Location: http://***.com:8181/…”消息实体中链接“< a href=”https://***.com/…”>”替换成“”。 主机C解析经过篡改后的HTTP响应报文经过重定向与主机M的8181端口通过HTTP方式建立了连接二者之间通信数据明文传输。 主机M冒充客户端与主机S建立HTTPS会话二者之间的通信数据通过密文传输但主机M可以自由地解密这些数据。 经过以上步骤主机M成功实现了主机CSSL客户端与主机SSSL服务端之间的会话劫持并可以对明文形式的会话内容进行监测。 2.2 成功的必要条件 这种类型的SSL会话劫持成功的必要条件如下
a 能够通过ARP欺骗、DNS欺骗或者浏览器数据重定向等欺骗技术使得SSL客户端和服务端S之间的数据都流向中间人监测主机 b 客户端访问的Web页面存在http页面至https页面的跳转 c SSL服务端未要求对SSL客户端进行认证。
三、两种典型SSL会话劫持技术的对比小结
传统的基于伪造X.509证书的SSL会话劫持方式其最大的问题就在于客户端浏览器会弹出警告提示对话框这个提示是如此醒目以至于只要用户有一定的安全意识和网络知识劫持成功的概率就会大大降低。随着网络知识的慢慢普及这种技术的生存空间会越来越小。
基于HTTP与HTTPS之间跳转验证漏洞的SSL会话劫持方式是近几年新出的一种技术。在此种方式下客户端浏览器不会有任何不安全的警告或提示只是原先的HTTPS连接已经被HTTP连接所替换迷惑性大大增强。一般为了进一步加强欺骗效果监测主机还可以一个银色的“安全锁”图案显示在非安全的网址前面。但其缺陷也很明显一旦用户在浏览器地址栏的输入中指定使用HTTPS协议就会发现网页根本无法打开。因此只要用户养成良好的上网习惯这种方式的会话劫持就会失败。
pycurl
sudo apt-get install libcurl4-openssl-dev
pip install pycurl关于Python网络编程使用urllib与服务器通信时客户端的数据是添加到Head里面通过URL发送到服务器端urllib包实现客户端上传文件时会出现死掉的状态实际上是超时设置问题。
Pycurl包是一个libcurl的Python接口它是由C语言编写的。与urllib相比pycurl的速度要快很多。
Libcurl 是一个支持FTPFTPSHTTPHTTPSGOPHERTELNETDICTFILE 和 LDAP的客户端URL传输库。libcurl也支持HTTPS认证HTTP、POST、HTTP PUT、FTP上传代理Cookies基本身份验证FTP文件断点继传HTTP代理通道等等。
pycurl模块的方法
c = pycurl.Curl() #创建一个curl对象
c.setopt(pycurl.CONNECTTIMEOUT, 5) #连接的等待时间设置为0则不等待
c.setopt(pycurl.TIMEOUT, 5) #请求超时时间
c.setopt(pycurl.NOPROGRESS, 0) #是否屏蔽下载进度条非0则屏蔽
c.setopt(pycurl.MAXREDIRS, 5) #指定HTTP重定向的最大数
c.setopt(pycurl.FORBID_REUSE, 1) #完成交互后强制断开连接不重用
c.setopt(pycurl.FRESH_CONNECT,1) #强制获取新的连接即替代缓存中的连接
c.setopt(pycurl.DNS_CACHE_TIMEOUT,60) #设置保存DNS信息的时间默认为120秒
c.setopt(pycurl.URL,"http://www.baidu.com") #指定请求的URL
c.setopt(pycurl.USERAGENT,"Mozilla/5.2 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50324)") #配置请求HTTP头的User-Agent
c.setopt(pycurl.HEADERFUNCTION, getheader) #将返回的HTTP HEADER定向到回调函数getheader
c.setopt(pycurl.WRITEFUNCTION, getbody) #将返回的内容定向到回调函数getbody
c.setopt(pycurl.WRITEHEADER, fileobj) #将返回的HTTP HEADER定向到fileobj文件对象
c.setopt(pycurl.WRITEDATA, fileobj) #将返回的HTML内容定向到fileobj文件对象
c.getinfo(pycurl.HTTP_CODE) #返回的HTTP状态码
c.getinfo(pycurl.TOTAL_TIME) #传输结束所消耗的总时间
c.getinfo(pycurl.NAMELOOKUP_TIME) #DNS解析所消耗的时间
c.getinfo(pycurl.CONNECT_TIME) #建立连接所消耗的时间
c.getinfo(pycurl.PRETRANSFER_TIME) #从建立连接到准备传输所消耗的时间
c.getinfo(pycurl.STARTTRANSFER_TIME) #从建立连接到传输开始消耗的时间
c.getinfo(pycurl.REDIRECT_TIME) #重定向所消耗的时间
c.getinfo(pycurl.SIZE_UPLOAD) #上传数据包大小
c.getinfo(pycurl.SIZE_DOWNLOAD) #下载数据包大小
c.getinfo(pycurl.SPEED_DOWNLOAD) #平均下载速度
c.getinfo(pycurl.SPEED_UPLOAD) #平均上传速度
c.getinfo(pycurl.HEADER_SIZE) #HTTP头部大小 #!/usr/bin/env python2
#encoding=utf8import pycurl
import StringIO# 安装pycurl到http://pycurl.sourceforge.net/这里去找.
# 在windows安装的话http://pycurl.sourceforge.net/download/ , 看你使用的版本决定下载那个我在 windows使用的是python2.4, 所以下载 pycurl-ssl-7.15.5.1.win32-py2.4.exe 。def test(debug_type, debug_msg):print "debug(%d): %s" % (debug_type, debug_msg)def postFile(url,post_file):pass
#print pycurl.version_info()#这个函数创建一个同 libcurl中的CURL处理器相对应的Curl对象.Curl对象自动的设置CURLOPT_VERBOSE为0, CURLOPT_NOPROGRESS为1,提供一个默认的CURLOPT_USERAGENT和设置CURLOPT_ERRORBUFFER指向一个私有的错误缓冲区.
c = pycurl.Curl() #创建一个同libcurl中的CURL处理器相对应的Curl对象b = StringIO.StringIO()#c.setopt(c.POST, 1)c.setopt(pycurl.URL, url) #设置要访问的网址 url = "http://www.cnn.com"#写的回调
c.setopt(pycurl.WRITEFUNCTION, b.write)
c.setopt(pycurl.FOLLOWLOCATION, 1) #参数有1、2#最大重定向次数,可以预防重定向陷阱
c.setopt(pycurl.MAXREDIRS, 5)
#连接超时设置
c.setopt(pycurl.CONNECTTIMEOUT, 60) #链接超时
# c.setopt(pycurl.TIMEOUT, 300) #下载超时# c.setopt(pycurl.HEADER, True)
# c.setopt(c.HTTPHEADER, ["Content-Type: application/x-www-form-urlencoded","X-Requested-With:XMLHttpRequest","Cookie:"+set_cookie[0]])
#模拟浏览器
c.setopt(pycurl.USERAGENT, "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)")
# c.setopt(pycurl.AUTOREFERER,1)
# c.setopt(c.REFERER, url)# cookie设置
# Option -b/--cookie <name=string/file> Cookie string or file to read cookies from
# Note: must be a string, not a file object.
# c.setopt(pycurl.COOKIEFILE, "cookie_file_name")# Option -c/--cookie-jar Write cookies to this file after operation
# Note: must be a string, not a file object.
# c.setopt(pycurl.COOKIEJAR, "cookie_file_name")# Option -d/--data HTTP POST data
post_data_dic = {"name":"value"}
c.setopt(c.POSTFIELDS, urllib.urlencode(post_data_dic))#设置代理
# c.setopt(pycurl.PROXY, ‘http://11.11.11.11:8080′)
# c.setopt(pycurl.PROXYUSERPWD, ‘aaa:aaa’)
#不明确作用
# c.setopt(pycurl.HTTPPROXYTUNNEL,1) #隧道代理
# c.setopt(pycurl.NOSIGNAL, 1)#设置post请求 上传文件的字段名 上传的文件
#post_file = "/home/ubuntu/avatar.jpg"
c.setopt(c.HTTPPOST, [("textname", (c.FORM_FILE, post_file))])# 调试回调.调试信息类型是一个调试信 息的整数标示类型.在这个回调被调用时VERBOSE选项必须可用
# c.setopt(c.VERBOSE, 1) #verbose 详细
# c.setopt(c.DEBUGFUNCTION, test)# f = open("body", "wb")
# c.setopt(c.WRITEDATA, f)
# h = open("header", "wb")
# c.setopt(c.WRITEHEADER, h)
# print "Header is in file 'header', body is in file 'body'"
# f.close()
# h.close()# c.setopt(c.NOPROGRESS, 0)
# c.setopt(c.PROGRESSFUNCTION, progress)# c.setopt(c.OPT_FILETIME, 1)#访问,阻塞到访问结束
c.perform() #执行上述访问网址的操作print "HTTP-code:", c.getinfo(c.HTTP_CODE) #打印出 200(HTTP状态码)
print "Total-time:", c.getinfo(c.TOTAL_TIME)
print "Download speed: %.2f bytes/second" % c.getinfo(c.SPEED_DOWNLOAD)
print "Document size: %d bytes" % c.getinfo(c.SIZE_DOWNLOAD)
print "Effective URL:", c.getinfo(c.EFFECTIVE_URL)
print "Content-type:", c.getinfo(c.CONTENT_TYPE)
print "Namelookup-time:", c.getinfo(c.NAMELOOKUP_TIME)
print "Redirect-time:", c.getinfo(c.REDIRECT_TIME)
print "Redirect-count:", c.getinfo(c.REDIRECT_COUNT)# epoch = c.getinfo(c.INFO_FILETIME)
#print "Filetime: %d (%s)" % (epoch, time.ctime(epoch))html = b.getvalue()
print(html)b.close()
c.close()其他
scrapy
了解scrapy已经做过的功能优化等。。。防止重复造轮子如去重编码检测dns缓存http长连接,gzip等等。
JS相关。
这个是被问的最多的。看具体情况解决。可模拟相关js执行、绕过或直接调浏览器去访问。自己用一个JS引擎+模拟一个浏览器环境难度太大了参见V8的DEMO。
调浏览器有很多方法。难以细说关键字如下seleniumphantomjscasperjsghostwebkitscrapyjssplash。一些细节如关掉CSS渲染图片加载等。只有scrapyjs是完全异步的相对是速度最快的scrapyjs将webkit的事件循环和twisted的事件循环合在一起了。其他的方案要么阻塞要么用多进程。简单的js需求对效率要求不高随意选最优方案是scrapyjs+定制webkit去掉不需要的功能。调浏览器开页面是比较耗资源的主要是cpu
内容解析。
对于页面解析最强大的当然是XPATH、css选择器、正则表达式这个对于不同网站不同的使用者都不一样就不用过多的说明附两个比较好的网址
正则表达式入门http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
正则表达式在线测试http://tool.oschina.net/regex/
其次就是解析库了常用的有两个lxml和BeautifulSoup对于这两个的使用介绍两个比较好的网站
lxmlhttp://my.oschina.net/jhao104/blog/639448
BeautifulSouphttp://cuiqingcai.com/1319.html
对于这两个库都是HTML/XML的处理库Beautifulsoup纯python实现效率低但是功能实用比如能用通过结果搜索获得某个HTML节点的源码lxmlC语言编码高效支持Xpath
机器学习不一定好用效果问题人工问题-需要训练。还有写些正则去模糊匹配。
新闻类似的正文提取有readability,boilerplate。
分布式。
首先考虑按任务目标切分然后让不同目标的爬虫在不同机器上跑
完全的对等分布式多爬虫爬一个目标把任务队列替换掉爬虫改改即可。github里面有几个现有的实现参考。
分布式需求可能是伪命题。想清楚为何要分布式。硬件够不够像什么拿一个不支持持久化的url队列的爬虫说量大需要分布式的我只能默念你为何这么吊。
部署调度
部署推荐scrapyd。这也是官方推荐的方法。
大量爬虫的调度这个目前13-10没有现成的合适方法期望是实现爬虫的某些配置放数据库提供web后台 然后按配置周期、定时运行爬虫终止暂停爬虫等等。可以实现但要自己写不少东西。
ip限制问题
买的起大量ip的可买买大量同网段爬可能导致整网段被封。
找大量免费的开放http代理筛选可用的免费开放代理不可靠写个调度机制自动根据成功次数延迟等选择合适代理这个功能难以在scrapy内实现参考scrapinghub的crawlera我完成了一个本地版。
在开发爬虫过程中经常会遇到IP被封掉的情况这时就需要用到代理IP
在urllib2包中有ProxyHandler类通过此类可以设置代理访问网页如下代码片段
import urllib2proxy = urllib2.ProxyHandler({'http': '127.0.0.1:8087'})opener = urllib2.build_opener(proxy)urllib2.install_opener(opener)response = urllib2.urlopen('http://www.baidu.com')print response.read()url去重
如果有千万级的URL需要去重需要仔细看下scrapy的去重机制和bloom filter布隆过滤器。bloomfilter有个公式可以算需要多少内存。另bloomfilter + scrapy在github有现有实现可以参考。
存储。
mongodbmongodb不满足某些功能时考虑hbase,参考http://blog.scrapinghub.com/2013/05/13/mongo-bad-for-scraped-data/
硬件
硬件扛不住别玩爬虫。。。曾在I3 4G 1T上跑爬虫。卡在磁盘io量大磁盘io差内存低出现内存占用飙升。很难调试调试爬虫看实际跑耗时较长初步以为是爬虫有问题内存占用高导致数据库卡。调试结果确认为配置低量太大导致数据库慢数据库慢之后爬虫任务队列占满内存并开始写磁盘又循环导致数据库慢。
爬虫监控
scrapyd自带简单的监控不够的话用scrapy的webservice自己写
如何防止死循环
在Scrapy的默认配置中是根据url进行去重的。这个对付一般网站是够的。但是有一些网站的SEO做的很变态为了让爬虫多抓会根据request动态的生成一些链接导致爬虫 在网站上抓取大量的随机页面甚至是死循环。。
为了解决这个问题有2个方案
(1) 在setting.py中设定爬虫的嵌套次数上限(全局设定实际是通过DepthMiddleware实现的)
DEPTH_LIMIT = 20(2) 在parse中通过读取response来自行判断(spider级别设定)
def parse(self, response):if response.meta['depth'] > 100:print 'Loop?'如何设置代理
为了实现代理需要配置2个Middleware
setting.py中定义
SPIDER_MIDDLEWARES = {'project_name.middlewares.MyProxyMiddleware': 100,'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110
}其中100、110是执行的优先级即我们自己定义的MyProxyMiddleware先执行系统的HttpProxyMiddleware后执行。
我们自己的MyProxyMiddleware主要负责向meta中写入代理信息
# Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication
import base64# Start your middleware class
class ProxyMiddleware(object):# overwrite process requestdef process_request(self, request, spider):# Set the location of the proxyrequest.meta['proxy'] = "http://YOUR_PROXY_IP:PORT"# Use the following lines if your proxy requires authenticationproxy_user_pass = "USERNAME:PASSWORD"# setup basic authentication for the proxyencoded_user_pass = base64.encodestring(proxy_user_pass)request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass如果你用的是socks5代理那么对不起目前scrapy还不能直接支持可以通过Privoxy等软件将其本地转化为http代理。
<div id="test3">我左青龙<span id="tiger">右白虎<ul>上朱雀<li>下玄武。</li></ul>老牛在当中</span>龙头在胸口。<div>
使用xpath的string(.)
data = selector.xpath('//div[@id="test3"]')
info = data.xpath('string(.)').extract()[0]这样就可以把'''我左青龙右白虎上朱雀下玄武。老牛在当中龙头在胸口'''整个句子提取出来赋值给info变量。
使用正则表达式匹配嵌套Html标签
概述
正则表达式是做文本解析工作必不可少的技能。如Web服务器日志分析网页前端开发等。很多高级文本编辑器都支持正则表达式的一个子集熟练掌握正则表达式经常能够使你的一些工作事半功倍。例如统计代码行数只需一个正则就搞定。嵌套Html标签的匹配是正则表达式应用中一个比较难的话题因为它涉及到的正则语法比较多也比较难。因此也就更有研究的价值。
思路
任何复杂的正则表达式都是由简单的子表达式组成的要想写出复杂的正则来一方面需要有化繁为简的功底另外一方面我们需要从正则引擎的角度去思考问题。关于正则引擎的原理推荐《Mastering Regular Expression》中文名叫《精通正则表达式》。挺不错的一本书。
OK先确定我们要解决的问题——从一段Html文本中找出特定id的标签的innerHTML。
这里面最大的难点就是Html标签是支持嵌套的怎么能够找到指定标签相对应的闭合标签呢
我们可以这样想先匹配最前面的起始标签假设是div吧<div然后一旦遇到嵌套div就“压入堆栈”然后一遇到div结束标签了就“弹出堆栈”。如果遇到结束标签的时候堆栈里面已经没有东西了那么匹配结束此结束标签为正确的闭合标签。
我之所以能够这样去思考是因为我了解过正则的特性我知道正则中的平衡组能够实现我刚才说的“堆栈”操作。所以如果我们要编写复杂正则表达式需要对正则的一些高级特性至少有所了解这样我们思考问题才有个方向。
实现
这里假设我们要匹配的文本是一段合法的Html文本。下面这段Html代码是从我的博客上拷贝下来的作为我们的测试文本。我们要匹配的就是footer这个div的innerHTML同时把标签名也捕获下来。
<div style="background-color:gray;" id="footer"><a id="gotop" href="#" οnclick="MGJS.goTop();return false;">Top</a><a id="powered" href="http://wordpress.org/">WordPress</a><div id="copyright">Copyright © 2009 简单生活 —— Kevin Yang的博客 </div><div id="themeinfo">Theme by <a href="http://www.neoease.com/">mg12</a>.Valid <a href="http://validator.w3.org/check?uri=referer">XHTML 1.1</a>and <a href="http://jigsaw.w3.org/css-validator/">CSS 3</a>.</div> </div> 这里我们需要借助Expresso工具来构建和测试编写的正则表达式。
匹配起始标签
起始标签特征很好提取以尖括号打头然后跟着一连串英文字母然后一大串属性中非尖括号字符匹配id不区分大小写=footer。需要注意的是footer可以被双引号或者单引号包裹也可以什么都不加。正则如下
<(?<HtmlTag>[\w]+)[^>]*\s[iI][dD]=(?<Quote>["']?)footer(?(Quote)\k<Quote>)["']?[^>]*>上面的正则表达式需要做几点说明
1. <尖括号在正则中算是一个特殊字符在显式捕获分组中用它将分组名括起来。但是因为开头的尖括号在此上下文下并不会出现解析歧义因此加不加转义符效果是一样的。
2. (?<GroupName>RegEx)格式定义一个命名分组我们在上面定义了一个HtmlTag的标签分组用来存放匹配到的Html标签名。Quote分组是用来给后面的匹配使用的。
3. (?(GroupName)Then|Else)是条件语句表示当捕获到GroupName分组时执行Then匹配否则执行Else匹配。上面的正则中我们先尝试匹配footer字符串左边的引号并将其存入LeftQuote分组中然后在footer右侧进行条件解析如果之前匹配到LeftQuote分组那么右侧也应该批评LeftQuote分组。这样一来我们就能精确匹配id的各种情况了。
匹配闭合标签
((?<Nested><\k<HtmlTag>[^>]*>)|</\k<HtmlTag>>(?<-Nested>)|.*?)*</\k<HtmlTag>>在成功匹配到起始标签之后后面的Html文本可以分为三种情况
A. 匹配到嵌套div起始标签<div这个时候需要将其捕获到Nested分组。
B. 匹配到嵌套div起始标签的闭合标签这个时候需要将之前的Nested分组释放
C. 其他任意文本。注意需要使用.*?方式关闭贪婪匹配否则最后的闭合标签可能会过度匹配
使用(RegEx1|RegEx2|RegEx3)*这种方式可以将几个条件以或的形式组合起来然后再取若干次匹配结果最终再匹配闭合标签。其中(?<-Nested>)是表示释放之前捕获的Nested分组。确切的语法是(?<N-M>)即使用N分组替换掉M分组如果N分组没有指定或不存在则释放M分组。
update前面过于侧重分析了最后没有给出一个完整的正则真是抱歉。
<(?<HtmlTag>[\w]+)[^>]*\s[iI][dD]=(?<Quote>["']?)footer(?(Quote)\k<Quote>)
["']?[^>]*>((?<Nested><\k<HtmlTag>[^>]*>)|</\k<HtmlTag>>(?<-Nested>)|.*?)*</\k<HtmlTag>>上面这个正则能够匹配任意id=footer的html标签。
需要注意此正则表达式需要设置SingleLine=true这样点号才可以把换行符也匹配进去。
对于domoxz 的问题如果要匹配p标签那么只需将上述的正则中的HtmlTag替换成p即可
python 爬虫之路教程相关推荐
- python爬虫教程下载-Python爬虫文件下载图文教程
而今天我们要说的内容是:如果在网页中存在文件资源,如:图片,电影,文档等.怎样通过Python爬虫把这些资源下载下来. 1.怎样在网上找资源: 就是百度图片为例,当你如下图在百度图片里搜索一个主题时, ...
- Python爬虫学习系列教程
大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己实际写的一些小爬虫,在这里跟大家一同分享,希望对Python爬虫 ...
- Python爬虫学习系列教程-----------爬虫系列 你值的收藏
静觅 » Python爬虫学习系列教程:http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把 ...
- Python 爬虫学习 系列教程
Python爬虫 --- 中高级爬虫学习路线 :https://www.cnblogs.com/Eeyhan/p/14148832.html 看不清图时,可以把图片保存到本地在打开查看... Pyth ...
- python怎么下载教程-Python爬虫文件下载图文教程
而今天我们要说的内容是:如果在网页中存在文件资源,如:图片,电影,文档等.怎样通过Python爬虫把这些资源下载下来. 1.怎样在网上找资源: 就是百度图片为例,当你如下图在百度图片里搜索一个主题时, ...
- Python 爬虫入门的教程(2小时快速入门、简单易懂、快速上手)
http://c.biancheng.net/view/2011.html 这是一篇详细介绍 Python 爬虫入门的教程,从实战出发,适合初学者.读者只需在阅读过程紧跟文章思路,理清相应的实现代码, ...
- 手把手带你飞Python爬虫+数据清洗新手教程(一)
本文共有2394字,读完大约需要10分钟. 目录 简介 思考 撸起袖子开始干 1 获取网页源代码 2 在网页源代码里找出所需信息的位置 3 数据清洗 4 完整代码 5 优化后的代码 简介 本文使用An ...
- selenium+python爬虫全流程教程
python+selenium爬虫全流程详解 selenium+python爬虫简介 selenium测试脚本 python+selenium 模拟浏览器----以chrome为例 浏览器驱动安装 浏 ...
- 最好的python爬虫 小白入门教程
Python爬虫入门教程:超级简单的Python爬虫教程 这是一篇详细介绍 Python 爬虫入门的教程,从实战出发,适合初学者.读者只需在阅读过程紧跟文章思路,理清相应的实现代码,30 分钟即可学会 ...
- Python爬虫100例教程导航帖(已完结)
目录 写在2022年3月22日 Python 爬虫 基础部分内容 pyspider scrapy 手机抓取部分 爬虫进阶部分 验证码识别技术 反爬虫技术 分布式爬虫技术 爬虫高级扩展部分 帮粉丝 ...
最新文章
- Codeforces Round #343 (Div. 2) D. Babaei and Birthday Cake 线段树维护dp
- 汇编中的数组分配和指针
- C#窗体内控件大小随窗体等比例变化
- 边缘计算如何实现海量IoT数据就地处理
- Day7—socket进阶
- rdd转换成java数据结构_Spark RDD转换成其他数据结构
- nginx启动成功,web页面报错
- 网易常用镜像及使用方式
- vba正则表达式入门
- 初级Java程序员如何快速提升自己的能力?
- “熵减”之下,欧瑞博填补全屋智能国产操作系统空白
- 一位老人告诉我的人生哲理
- mvcnn代码详解_使用colab运行tensorflow版本的faster-rcnn
- [Pytorch系列-35]:卷积神经网络 - 搭建LeNet-5网络与CFAR10分类数据集
- Microsoft SQL Server 数据库使用(一)
- 后部发声-----学会英语的发音方法
- 用例规约初版(希望大家进来修改一下)
- 震惊世界的25张照片
- 使用burpsuite对移动app抓包分析
- uniapp微信H5公众号授权与支付