sql server死锁_如何使用扩展事件和SQL Server代理自动执行SQL Server死锁收集过程
sql server死锁
介绍 (Introduction)
This article is the last one of a series in which we discussed how to collect data about deadlocks so that we can not only monitor them but also build reports based on our collection results.
本文是该系列文章的最后一篇,其中我们讨论了如何收集有关死锁的数据,这样我们不仅可以监视死锁,还可以根据收集的结果生成报告。
If you came directly to this article, you will find below a list of previous articles with a little word about each of them. We recommend you to read them all before going any further.
如果您直接阅读本文,您将在下面的以前的文章列表中找到有关它们的简短信息。 我们建议您先阅读所有内容,然后再进行操作。
- What are SQL Server deadlocks and how to monitor them 什么是SQL Server死锁以及如何监视死锁
In this article, we’ve described what a deadlock is and what are the differences between deadlocks and blocking. We’ve also seen that there are multiple ways to monitor them (SQL Server Error Log, SQL Server Profiler and, starting SQL Server 2008,
在本文中,我们描述了什么是死锁以及死锁和阻塞之间的区别。 我们还看到有多种监视它们的方法(SQL Server错误日志,SQL Server Profiler以及启动SQL Server 2008的system_health or homemade Extended Events). system_health或自制的扩展事件)。 - How to report on SQL Server deadlock occurrences 如何报告SQL Server死锁事件
In the next article, we talked about data collection procedures that can be used to store information about deadlocks into a table from either Error Log and Extended Events. This information takes the form of an XML description of the deadlock events.
在下一篇文章中,我们讨论了可用于将有关死锁的信息从错误日志和扩展事件存储到表中的数据收集过程。 此信息采用死锁事件的XML描述的形式。We’ve also seen that we could generate a nice timeline of their occurrences over time for a given time period.
我们还看到,我们可以为给定时间段内的事件随时间生成一个不错的时间表。
- How to use SQL Server Extended Events to parse a Deadlock XML and generate statistical reports 如何使用SQL Server扩展事件来解析死锁XML并生成统计报告
In the previous article, we defined and implemented (as dynamically as possible) a process for deadlock handling based on Extended Events consisting into three steps that were:
在上一篇文章中,我们基于扩展事件定义并实现了(尽可能动态地)死锁处理过程,该过程包括三个步骤: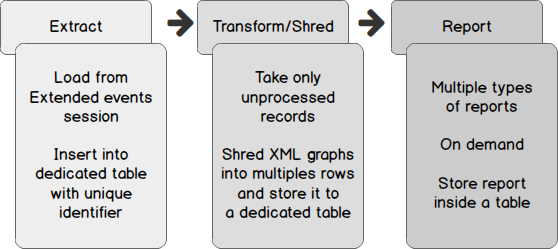
The „Extract” step is implemented in a stored procedure called Monitoring.CollectDeadlockInformation while the “Transform/Shred” step is implemented in the Reporting.ShredDeadlockHistoryTbl stored procedure. You can download the code of this procedure (and for related objects) from the following link, or at the end of third article of this series.
“提取”步骤在名为Monitoring.CollectDeadlockInformation的存储过程中实现,而“转换/撕碎”步骤在Reporting.ShredDeadlockHistoryTbl存储过程中实现。 您可以从以下链接或本系列第三篇文章的结尾下载此过程的代码(以及相关对象的代码)。
Now, it’s time to automate the first two steps of the above process. This means that we need to make choices on different aspects:
现在,是时候自动化上述过程的前两个步骤了。 这意味着我们需要在不同方面做出选择:
- system_health or homemade? And in what configuration? system_health还是自制的? 并以什么配置?
- Which tables should be used as input or output of which part of the process? 哪些表应该用作过程的哪个部分的输入或输出?
- How will we automate things? Will we use a SQL Agent Job or a Windows Scheduled Task? 我们将如何使事情自动化? 我们将使用SQL Agent Job还是Windows Scheduled Task?
These questions will find answers in following sections.
这些问题将在以下各节中找到答案。
选择我们初始数据收集的来源 (Choosing source of our initial data collection)
Here, we have two choices. We can either use a built-in Extended Events called system_health or create a specific one. If we choose system_health Extended Events though, there are some additional tasks that may be necessary to get something equivalent to a homemade Extended Event.
在这里,我们有两个选择。 我们可以使用称为system_health的内置扩展事件,也可以创建特定事件。 但是,如果我们选择system_health扩展事件,则可能需要执行一些其他任务才能获得等同于自制扩展事件的内容。
In order to properly choose our source, let’s first review what has to be done for each option.
为了正确选择我们的来源,让我们首先回顾每个选项必须做的事情。
创建专门用于死锁监视的扩展事件 (Creating an Extended Event dedicated to deadlock monitoring)
You will find attached to this article a file called:
您会在本文附件中找到一个文件:
Runnable.SetupMonitoringExtendedEvent.sql
Runnable.SetupMonitoringExtendedEvent.sql
This file contains the code to create such a specialized Extended Event Session. It’s a modified version of the one provided in first article and is almost executable directly: all we have to do is to edit following lines to match our configuration and requirements:
该文件包含用于创建此类专门的扩展事件会话的代码。 它是第一篇文章中提供的版本的修改版本,几乎可以直接执行:我们要做的就是编辑以下几行内容以符合我们的配置和要求:
-- ======================== ( User Configuration ) SET @EventsOutputPath = 'D:\ScriptsLOGS\Monitoring\ExtendedEvents';
SET @EventSessionName = 'Collect-Deadlocks';
SET @EventMaxFileSizeMb = 512;
SET @EventFileMaxNumber = 3;
-- ======================== (DO NOT EDIT FROM HERE) As we can see, we can specify the output directory and the event session name. Filenames corresponding to that event session will bear the name of that session with a .xel extension.
如我们所见,我们可以指定输出目录和事件会话名称。 对应于该事件会话的文件名将带有扩展名.xel的该会话的名称。
We can also provide a maximum file size for these files and the number of files for roll-over logging.
我们还可以提供这些文件的最大文件大小以及用于翻转日志记录的文件数。
This script is version-aware and generates different statement based on the version you are currently running. The reason for this is that File Target definition is slightly different between SQL Server 2008 (R2) and SQL Server 2012+. For further details about these differences, refer to first article of this series.
该脚本具有版本意识,并根据您当前正在运行的版本生成不同的语句。 原因是SQL Server 2008(R2)和SQL Server 2012+之间的文件目标定义略有不同。 有关这些差异的更多详细信息,请参阅本系列的第一篇文章 。
You can run this script multiple times if you want. It will check for the existence of an Extended Event Session called by the value of @EventSessionName and will only launch creation statement if no session exists. This means that it won’t alter an existing Extended Events Session.
您可以根据需要多次运行此脚本。 它将检查是否存在由@EventSessionName的值调用的扩展事件会话,并且仅在不存在会话的情况下启动创建语句。 这意味着它将不会更改现有的扩展事件会话。
If we want to check for the existence of our Extended Events Session, we can use following T-SQL statement:
如果我们要检查是否存在扩展事件会话,可以使用以下T-SQL语句:
SELECT es.Name as SessionName, CASE WHEN ISNULL(es.name,'No') = 'No' THEN 'NO'ELSE 'YES'END AS EventSessionExists, CASE WHEN ISNULL(xe.name,'No') = 'No' THEN 'NO'ELSE 'YES'END AS EventSessionRunning
FROM sys.server_event_sessions es
LEFT OUTER JOIN sys.dm_xe_sessions xe
ON es.name = xe.name
-- WHERE es.Name = 'Collect-Deadlocks'
;Here is a sample output:
这是一个示例输出:
As soon as we see a state like second line in previous example, we are able to get deadlock graphs from Collect-Deadlocks Event Session using a modified version of the script presented in section entitled Option 3: Extended Events and system_health session of first article. This version can be downloaded as a stored procedure call Monitoring.CollectDeadlockInformation in the archive containing All scripts used along this series. The link to this archive can be found at the end of this article.
一旦在上一示例中看到类似第二行的状态,就能够使用第一篇文章标题3:选项3:扩展事件和system_health会话中介绍的脚本的修改版本从Collect-Deadlocks事件会话中获取死锁图。 该版本可以作为存储过程调用Monitoring.CollectDeadlockInformation下载到包含此系列中使用的所有脚本的存档中。 可以在本文末尾找到此档案的链接。
Note that, as stated above, we can say that it collects live data because it reads corresponding session log files and displays the results but.
请注意,如上所述,我们可以说它收集实时数据,因为它读取相应的会话日志文件并显示结果。
Here is the kind of the output you would get when executing the modified version of this query:
这是执行此查询的修改版本时将获得的输出类型:
In the configurable values presented above, there is a variable called @EventsOutputPath. This variable tends to tell that the Extended Events Session we created writes its data to disk and it’s absolutely the case! Expressed in technical terms, we used a File Target Type for our Extended Events. If we consider system_health and we generate the script to recreate it, we will see that there is another Target Type called Ring Buffer. Let’s see the differences between both target types and make the appropriate choice.
在上面显示的可配置值中,有一个名为@EventsOutputPath的变量。 这个变量倾向于告诉我们我们创建的扩展事件会话将其数据写入磁盘,绝对是这样! 用技术术语表示,我们为扩展事件使用了文件目标类型。 如果考虑使用system_health并生成重新创建脚本的脚本,我们将看到还有另一个名为Ring Buffer的 Target Type。 让我们看看两种目标类型之间的差异,并做出适当的选择。
目标类型注意事项:环形缓冲区与文件 (Target types considerations: Ring Buffer vs File)
According to Microsoft’s documentation page about Ring Buffer Target, this target type holds event data in memory while the event session is active. This means that when the Event Session is stopped, SQL Server frees allocated memory buffers and therefore we can’t access previously collected data anymore.
根据Microsoft关于“ 环形缓冲区目标”的文档页面,当事件会话处于活动状态时,此目标类型将事件数据保存在内存中 。 这意味着当事件会话停止时,SQL Server释放已分配的内存缓冲区,因此我们无法再访问以前收集的数据。
This also means that a restart of SQL Server instance would lead to a loss of collected data too.
这也意味着重新启动SQL Server实例也将导致丢失收集的数据。
In contrast, stopping an Event Session or restarting SQL Server won’t affect a File target.
相反,停止事件会话或重新启动SQL Server不会影响File目标。
We can conclude that we should choose File Target over Ring Buffer whenever data persistence is considered important.
我们可以得出结论,只要数据持久性很重要,就应该选择“文件目标”而不是“环形缓冲区”。
自定义system_health扩展事件 (Customizing system_health Extended Event)
Before SQL Server 2012
在SQL Server 2012之前
In SQL Server 2008 and 2008R2, system_health only has ring_buffer target, so no persisting data could be retrieved.
在SQL Server 2008和2008R2中, system_health仅具有ring_buffer目标,因此无法检索任何持久数据。
The following query will give you a list of target types per event session.
以下查询将为您提供每个事件会话的目标类型列表。
select sess.name as SessionName, tgt.target_name
from sys.dm_xe_sessions sess
inner join sys.dm_xe_session_targets tgt
on sess.address = tgt.event_session_addressIf we run it against a SQL Server 2008 R2 instance, we will get following results:
如果针对SQL Server 2008 R2实例运行它,我们将得到以下结果:
Since we’ve seen how to create a complete Extended Event Session with a file target, it’s not a difficult task to edit the system_health session in SQL Server 2008 (R2) so that it also writes to an asynchronous file target.
由于我们已经看到了如何使用文件目标创建完整的扩展事件会话,因此在SQL Server 2008(R2)中编辑system_health会话并不困难,因此它也可以写入异步文件目标。
Starting SQL Server 2012
启动SQL Server 2012
Starting this version, both targets ring_buffer and file targets are defined.
从该版本开始,同时定义了目标ring_buffer和文件目标。
We can run the previous query against a SQL Server 2012 instance and we will get:
我们可以对SQL Server 2012实例运行上一个查询,我们将获得:
So, data from system_health event now can persist after a server restart. Let’s first check its configuration with the following query.
因此,来自system_health事件的数据现在可以在服务器重新启动后保留。 首先,使用以下查询检查其配置。
SELECT es.name as EventSessionName, esf.name as SessionParamName, esf.value as SessionParamValue
FROM sys.server_event_session_fields AS esf
JOIN sys.server_event_sessions AS es
ON esf.event_session_id=es.event_session_id
WHEREes.startup_state=1
AND es.name = 'system_health'
AND esf.name IN ('filename','max_file_size','max_rollover_files')
;We will notice that this target will roll over four files of 5 Mb each. This means that we only keep 20 Mb of data.
我们将注意到,该目标将滚动4个文件,每个文件5 Mb。 这意味着我们仅保留20 Mb的数据。
If we estimate this is not enough, we could edit the configuration for this target. This is done by dropping the event target and creating a new file target to the system_health extended event.
如果我们估计这还不够,我们可以编辑该目标的配置。 这是通过删除事件目标并为system_health扩展事件创建新的文件目标来完成的。
-- Preferable to stop server activity
-- and prevent end user connections.
ALTER EVENT SESSION [system_health] ON SERVER STATE = STOP ;
GO-- Remove the file target
ALTER EVENT SESSION [system_health] ON SERVER
DROP TARGET package0.event_file ;-- Define new file target with new settings
ALTER EVENT SESSION [system_health] ON SERVER
ADD TARGET package0.event_file (SET FILENAME = N'system_health.xel',max_file_size = (100), --size of each file in MBmax_rollover_files = (10)
)
GO-- Restart Session
ALTER EVENT SESSION [system_health] ON SERVER STATE = START
GONote
注意
Don’t forget to check that there is enough space on event file target partition or disk.
不要忘记检查事件文件目标分区或磁盘上是否有足够的空间。
一次为变量组件设置值 (Setting values to variable components once for all)
We are about to create an automatic data collection and split of data related to deadlock. The stored procedures presented above have variable input and output and so are parameterizable.
我们将创建一个自动数据收集和拆分与死锁相关的数据。 上面介绍的存储过程具有可变的输入和输出,因此可以进行参数设置。
We will now define, once for all, values to these parameters as follows:
现在,我们将首先为这些参数定义值,如下所示:
- Based on considerations from the previous section, we will choose the Collect-Deadlocks Extended Events option that we can create using attached script called Runnable.SetupMonitoringExtendedEvent.sql vs the system_health Extended Event. Another reason to that choice it that I think it’s preferable not to “hack” the system.
基于上一节的考虑,我们将选择“收集-死锁扩展事件”选项,可以使用名为Runnable.SetupMonitoringExtendedEvent.sql与system_health扩展事件的附加脚本来创建该选项。 选择该文件的另一个原因是,我认为最好不要“破解”系统。As a reminder, the Collect-Deadlocks Extended Event is defined to use a file target type.
提醒一下,Collect-Deadlocks扩展事件定义为使用文件目标类型。
- We will call it Monitoring.DeadlocksHistory. This will be the name of the source for next step.
我们将其称为Monitoring.DeadlocksHistory。 这将是下一步的来源名称。 - This table will be called Reporting.ShreddedDeadlocksHistory.
该表将称为Reporting.ShreddedDeadlocksHistory。
For simplicity of management, these two tables will be stored in the same database as the stored procedures.
为了简化管理,这两个表将与存储过程存储在同一数据库中。
In terms of Transact SQL, this means the script that will setup the automation process will contain following lines, assuming we are already connected to the appropriate database:
就Transact SQL而言,这意味着将要设置自动化过程的脚本将包含以下几行,假设我们已经连接到适当的数据库:
DECLARE @TargetDatabaseName VARCHAR(256);
DECLARE @HistorySchemaName VARCHAR(256);
DECLARE @HistoryTableName VARCHAR(256);
DECLARE @ShreddingSchemaName VARCHAR(256);
DECLARE @ShreddingTableName VARCHAR(256);SELECT @TargetDatabaseName = DB_NAME(),@HistorySchemaName = 'Monitoring',@HistoryTableName = 'DeadlocksHistory',@ShreddingSchemaName = 'Reporting',@ShreddingTableName = 'ShreddedDeadlocksHistory'
;For an automation mechanism, we have multiple choices, but, for simplicity, we will choose to create a SQL Server Agent Job and schedule its execution regularly so that collection of deadlocks information won’t be too long.
对于自动化机制,我们有多种选择,但为简单起见,我们将选择创建SQL Server代理作业并定期安排其执行时间,以使死锁信息的收集不会太长。
使用SQL Server代理创建自动化机制 (Creating the automation mechanism, using SQL Server Agent)
Now, we will review the steps we should follow in order to create a SQL Server Agent Job that will call both Monitoring.CollectDeadlockInformation and Reporting.ShredDeadlockHistoryTbl procedures.
现在,我们将回顾创建一个SQL Server代理作业的步骤,该作业将调用Monitoring.CollectDeadlockInformation和Reporting.ShredDeadlockHistoryTbl过程。
Each procedure call will be defined as a step of this SQL Server Agent Job with a transition condition: the first step (corresponding to “Collect” step) must succeed for the second step to run (corresponding to the “Transform/shred” step).
每个过程调用都将被定义为此SQL Server代理作业的一个带有过渡条件的步骤:第一步(对应于“收集”步骤)必须成功才能使第二步运行(对应于“转换/切碎”步骤) 。
We will schedule this collection every hour as:
我们将每小时按以下时间安排此收集:
- The main purpose is more reporting than monitoring because there is no DBA action required when it happens 主要目的是提供比监视更多的报告,因为在发生时不需要DBA动作
- Following the same logic, we don’t need live data 按照相同的逻辑,我们不需要实时数据
- In our configuration, data will be collected to disk, so there is no emergency for getting back data. 在我们的配置中,数据将被收集到磁盘上,因此无需紧急获取数据。
Here are the steps in SQL Server Management Studio (SSMS) to create such a job.
这是SQL Server Management Studio(SSMS)中创建此类作业的步骤。
- Open SQL Server Management Studio (SSMS) and connect to the target database server for which you want to monitor and analyze deadlocks 打开SQL Server Management Studio(SSMS)并连接到要监视和分析死锁的目标数据库服务器
- In Object Explorer, go down to “SQL Server Agent” node and right-click on it. 在对象资源管理器中,转到“ SQL Server代理”节点,然后右键单击它。

-
- Then, select “Steps” page. 然后,选择“步骤”页面。
-
For convenience, here is the code pasted in “Command” text field:
为了方便起见,下面是粘贴在“命令”文本字段中的代码:
DECLARE @EventSessionName VARCHAR(1024); SET @EventSessionName = 'Collect-Deadlocks';EXEC [Monitoring].[CollectDeadlockInformation] @OutputType = 'NONE',@UseApplicationParamsTable = 1,@EventSessionName = @EventSessionName,@ApplicationName = 'Day2Day Database Management',@OutputDatabaseName = 'DBA',@OutputSchemaName = 'Monitoring',@OutputTableName = 'DeadlocksHistory',@Debug = 0 ; -
-
Still for convenience, here is the code used in the “Command” text field:
仍为方便起见,以下是“命令”文本字段中使用的代码:
EXEC [Reporting].[ShredDeadlockHistoryTbl] @SourceSchemaName = ''Monitoring'',@SourceTableName = ''DeadlocksHistory'',@TargetSchemaName = ''Reporting'',@TargetTableName = ''ShreddedDeadlocksHistory'',@Debug = 0 ;Once done, also check the “include step output in history” checkbox in “Advanced” page then click OK.
完成后,还要选中“高级”页面中的“在历史中包括步骤输出”复选框,然后单击“确定”。
- Go to “Schedules” page 转到“时间表”页面
-
Just ignore it and click on “Yes”.
只需忽略它,然后单击“是”即可。
-
-
- Once you think everything is ok, press the “OK” button. 一旦您认为一切正常,请按“确定”按钮。
And now, the job will appear in Jobs list:
现在,该作业将出现在“作业”列表中:
If you want to check everything is OK, you could run the job by right-clicking on it then clicking on “Start Job at Step…” in contextual menu
如果要检查一切正常,可以右键单击该作业,然后在上下文菜单中单击“在步骤开始作业...”,以运行该作业。
If we don’t have centralized management and execution for SQL Server Agent jobs, we have to set this job for each and every SQL Server instance. To do so, we could follow these steps but it would be nicer to automate this process.
如果我们没有针对SQL Server代理作业的集中管理和执行,则必须为每个SQL Server实例设置此作业。 为此,我们可以按照以下步骤进行操作,但是自动化此过程会更好。
There are two alternatives:
有两种选择:
- You can script the job to a file and run it against each SQL Server instance. But this means you should ask for a “Drop and create” script. Otherwise, you could get an error when the job already exists. 您可以将作业编写脚本到文件中,并针对每个SQL Server实例运行它。 但这意味着您应该请求“拖放并创建”脚本。 否则,当作业已经存在时,您可能会收到错误消息。
- You could create your own script that would work at every execution and would let intact an existing SQL Agent job called “[Monitoring] Historize Deadlock Data”. Such a script is attached to this article and bear the name of “Runnable.SetupMonitoringAgentob.sql”. 您可以创建自己的脚本,该脚本可以在每次执行时使用,并且可以保留一个名为“ [[Monitoring] Historize Deadlock Data]”的现有SQL Agent作业。 此类脚本附于本文后,名称为“ Runnable.SetupMonitoringAgentob.sql”。
Note
注意
Once this collection process is in place, you should take time to define a data management process that will delete rows that are too old and so not needed anymore.
收集过程到位后,您应该花一些时间定义一个数据管理过程,该过程将删除太旧且不再需要的行。
结论 (Conclusion)
This closes our series of articles about deadlocks.
这将结束我们有关死锁的系列文章。
We’ve made a great journey from the first article, where we learned what a deadlock in contrast to blocking is, until this one, where we used everything we defined in previous articles to create an automated collection of information about deadlock.
从第一篇文章开始,我们经历了一段伟大的历程,在那篇文章中我们了解了与阻塞相反的僵局,直到本文利用之前文章中定义的所有内容创建了有关僵局的自动化信息。
If everything went successfully and collection runs regularly, we are now able to report issues to developers or support teams with valuable information they can use in order to fix recurrent deadlock signatures.
如果一切顺利,并且收集工作正常进行,我们现在可以向开发人员或支持团队报告问题,他们可以使用有价值的信息来修复经常性的死锁签名。
Previous articles in this series:
本系列以前的文章:
- What are SQL Server deadlocks and how to monitor them什么是SQL Server死锁以及如何监视死锁
- How to report on SQL Server deadlock occurrences如何报告SQL Server死锁事件
- How to use SQL Server Extended Events to parse Deadlock XML and generate statistical reports 如何使用SQL Server扩展事件来解析死锁XML并生成统计报告
资料下载 (Downloads)
- Runnable.SetupMonitoringAgentJob.sqlRunnable.SetupMonitoringAgentJob.sql
- Runnable.SetupMonitoringExtendedEvent.sqlRunnable.SetupMonitoringExtendedEvent.sql
- All scripts used along this series本系列中使用的所有脚本
翻译自: https://www.sqlshack.com/automate-sql-server-deadlock-collection-process-using-extended-events-sql-server-agent/
sql server死锁
sql server死锁_如何使用扩展事件和SQL Server代理自动执行SQL Server死锁收集过程相关推荐
- sql活动监视器 死锁_使用system_health扩展事件监视SQL Server死锁
sql活动监视器 死锁 Performance monitoring is a must to do the task for a DBA. You should ensure that the da ...
- SQL Server扩展事件(Extended Events)-- 将现有 SQL 跟踪脚本转换为扩展事件会话
SQL Server扩展事件(Extended Events)-- 将现有 SQL 跟踪脚本转换为扩展事件会话 如果您具有想要转换为扩展事件会话的现有 SQL 跟踪脚本,则可以使用本主题中的过程创建等 ...
- python 目标直方图_深入了解扩展事件–直方图目标
python 目标直方图 An Extended events target is the destination for all of the information that is capture ...
- SqlPackage.exe –使用bacpac和PowerShell或Batch技术自动执行SQL Server数据库还原
Data is the key to your organization's future, but if it's outdated, irrelevant, or hidden then it's ...
- SQL server 定时自动执行SQL存储过程
当一个存储过程是为了生成报表,并且是周期性的,则不需要人工干预,由SQL作业定时自动执行些SQL存储过程即可. 本示例,假设已需要定时执行的存储过程为:Pr_test 工具/原料 SQL Server ...
- 利用批处理自动执行sql脚本、备份、还原数据库
自动执行sql脚本: 假设sql脚本文件为a.txt,数据库用户名为sa 密码123 将sql脚本文件和批处理放在同一目录下,以下为批处理文件的内容: osql -U sa -P 123 -d Rif ...
- postgre sql 括字段_【技术干货】30个最适合初学者的SQL查询
毫无疑问,SQL或结构化查询语言是最流行的编程语言之一,尤其是因为它具有访问和修改数据库中数据的功能.SQL与数据库接口的基本用法是其流行的最重要原因. 关于SQL的最基本方面之一就是查询.基本上,S ...
- docker 运行mysql镜像_docker 生成mysql镜像启动时自动执行sql
在docker 创建 mysql 容器时,往往需要在创建容器的过程中创建database 实例,代码如下: docker run -d -p 3308:3306 -e MYSQL_ROOT_PASSW ...
- sql server死锁_如何报告SQL Server死锁事件
sql server死锁 介绍 (Introduction) In the previous article entitled "What are SQL Server deadlocks ...
最新文章
- 用于数字成像的双三次插值技术
- 用switch写收水费的c语言程序,超级新手,用switch写了个计算器程序,求指导
- 分布式任务队列 Celery — 应用基础
- HDU5900 QSC and Master(区间DP + 最小费用最大流)
- C#网络编程(异步传输字符串) - Part.3[转自JimmyZhang博客]
- 8 操作系统第二章 进程管理 信号量 PV操作 用信号量机制实现 进程互斥、同 步、前驱关系
- 嵌入式linux 网络唤醒,C语言实现wake on lan(网络唤醒...-Windows系统下用命令行编译C/C++...-字符串常量引起的思考_169IT.COM...
- 决策树Decision Tree+ID3+C4.5算法实战
- java如何使用while_java中的while(true)语句的用法是什么
- 万能硬盘数据恢复软件注册码真的可以用吗?
- DevKitPro(GBA),MakeFile文件大概分析(编译)
- 文件下载直接在浏览器显示内容
- win2008虚拟化服务器配置,玩转Windows Server 2008自带的虚拟化功能
- 【预测模型】预测某地区未来 10-20 年按年龄划分的人口结构(PDE模型)
- 假程序员启示录:房价
- 在线正则表达式大全测试
- 如何确定当前的iPhone /设备型号?
- MATLAB进行不定积分和定积分的求解
- Golang big.int类型转int
- python练习题 21-30
热门文章
- python list去重并删除某些元素_使用Python实现list(列表)中的重复元素删除,例如: X= [1,1,2,a,a,[1,2,3]] 去重后:X= 「1,2,a,[1,2...
- java取linux本地xml,java-使用apache poi读取.xlsx文件会在Linux机器...
- 删除ubuntu旧内核
- 2019-06-04 Sublime Text 中文输入法的问题
- 网易云复盘:云计算前端这一年(AngularJS粉慎入)
- github上传文件
- Java实现Oracle导出数据到Excel
- c++ 中 define
- 软件测试基础方法总结
- 042_前端规范 2021-06-03