《R与Hadoop大数据分析实战》一1.6 HDFS和MapReduce架构
本节书摘来自华章出版社《R与Hadoop大数据分析实战》一书中的第1章,第1.6节,作者 (印)Vignesh Prajapati,更多章节内容可以访问云栖社区“华章计算机”公众号查看
1.6 HDFS和MapReduce架构
由于HDFS和MapReduce是Hadoop框架的两个主要特征,我们将专注于它们。先从HDFS开始。
1.6.1 HDFS架构
HDFS是主从架构。主HDFS命名为名称节点(NameNode),而从HDFS命名为数据节点(DataNode)。名称节点是一个管理文件系统命名空间和调整客户端文件访问(开启、关闭、重命名及其他操作)的服务器。它将输入数据分块并且公布存储在各个数据节点上的数据。数据节点是一个从装置,它存储分区数据集的副本并且收到请求时提供数据。它还进行块的创建和删除。
HDFS的内部机理可将文件划分为一个或多个块,这些块储存在一系列数据节点中。在一般情况下,需备份3个复件,HDFS将第一个复件保存在本地节点中,第二个保存在本地另一个节点的磁道中,第3个复件保存在其他节点的磁道中。HDFS支持大文件,它的块容量为64MB,根据需求,可以进行扩充。
HDFS组件
HDFS使用主从架构进行管理,包括以下组件:
名称节点(NameNode):这是HDFS的主干。它维护目录、文件以及管理在数据节点上的块。
数据节点(DataNode):这些是被部署在每台机器上并且提供实际存储的从动装置。它们负责为客户提供读写数据的服务。
代理主节点(Secondary NameNode):它负责周期性检查中断点,如果主节点突然中断,可由储存在代理主节点中的中断点镜像来代替。
1.6.2 MapReduce架构
MapReduce也采用主从架构,典型的MapReduce 包含作业提交、作业的初始化、任务分配、任务执行、进度和状态更新,以及作业完成相关的活动,这主要是由JobTracker节点管理和TaskTracker节点执行。客户端应用程序提交作业给JobTracker,然后在整个集群中划分输入,JobTracker再计算要处理的Map和Reduce执行单元的数量,并命令TaskTracker开始执行该作业。TaskTracker必须复制资源到本地计算机,并启动JVM对数据进行Map和Reduce操作。与此同时,TaskTracker必须周期性地发送更新信息给JobTracker,这称为心跳(heartbeat),用于帮助更新作业ID、作业状态和资源使用情况。
MapReduce组件
MapReduce是由包含以下几部分的主从架构管理的:
JobTracker:它是MapReduce系统的主机节点,管理着集群中的作业及资源。JobTracker规划好每个Map,使TaskTracker中实际正在被处理的数据同Map尽量接近,正运行该数据节点的TaskTracker作业优先执行。
TaskTracker:这些都是部署在每台机器上的客户机节点。它们负责由JobTracker分配的Map和Reduce作业。
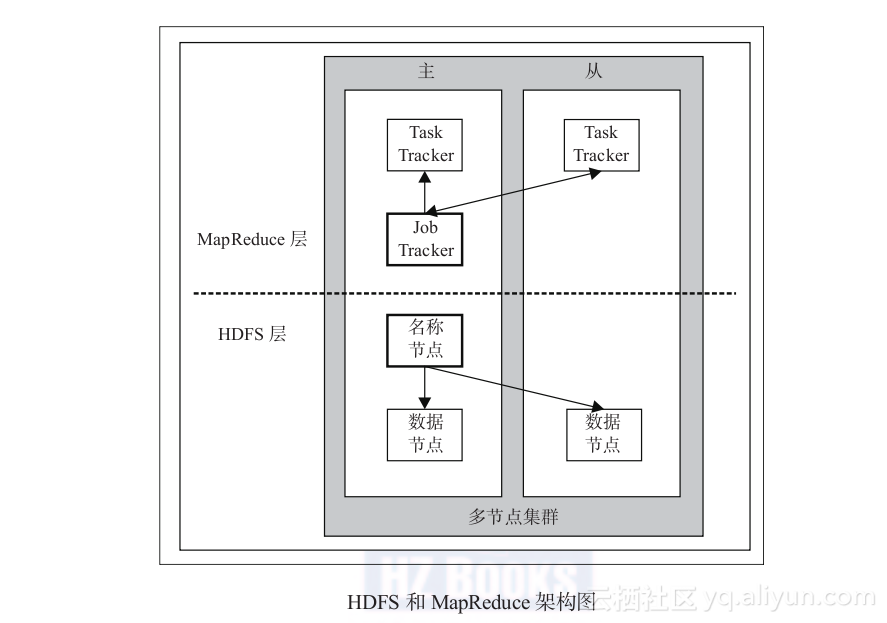
1.6.3 通过图示了解HDFS和MapReduce架构
在下图中,NameNode和DataNode在HDFS上,JobTracker和TaskTracker在MapReduce范式中,HDFS和MapReduce主服务器和从服务器部件也包括其中。
本图包含了HDFS和MapReduce的主从组件,其中名称节点和数据节点来自HDFS,JobTracker和TaskTracker来自MapReduce。
两个示例都是由主从组件构成的,在控制MapReduce和HDFS的操作中各有分工。在该图中包括两个部分:前一个是MapReduce层,后一个是HDFS层。
Hadoop是一个Apache的顶级项目,也是一个非常复杂的Java框架。为避免技术上的复杂性,Hadoop社区中已开发了许多Java框架,丰富了其额外的功能,本书中将它们视为Hadoop的子项目。在这里,我们将分别讨论Hadoop的组件,它们是HDFS或MapReduce的抽象层。
《R与Hadoop大数据分析实战》一1.6 HDFS和MapReduce架构相关推荐
- 《R与Hadoop大数据分析实战》一2.6 小结
本节书摘来自华章出版社<R与Hadoop大数据分析实战>一书中的第2章,第2.6节,作者 (印)Vignesh Prajapati,更多章节内容可以访问云栖社区"华章计算机&qu ...
- 【Hadoop大数据分析与挖掘实战】(一)----------P19~22
这是一本书的名字,叫做[Hadoop大数据分析与挖掘实战],我从2017.1开始学习 软件版本为Centos6.4 64bit,VMware,Hadoop2.6.0,JDK1.7. 但是这本书的出版时 ...
- 《Spark大数据分析实战》——1.4节弹性分布式数据集
本节书摘来自华章社区<Spark大数据分析实战>一书中的第1章,第1.4节弹性分布式数据集,作者高彦杰 倪亚宇,更多章节内容可以访问云栖社区"华章社区"公众号查看 1. ...
- 每周一书《Spark与Hadoop大数据分析》分享!
Spark与Hadoop大数据分析比较系统地讲解了利用Hadoop和Spark及其生态系统里的一系列工具进行大数据分析的方法,既涵盖ApacheSpark和Hadoop的基础知识,又深入探讨所有Spa ...
- 《Spark与Hadoop大数据分析》一一1.1 大数据分析以及 Hadoop 和 Spark 在其中承担的角色...
本节书摘来自华章计算机<Spark与Hadoop大数据分析>一书中的第1章,第1.1节,作者:文卡特·安卡姆(Venkat Ankam) 更多章节内容可以访问云栖社区"华章计算机 ...
- 大数据分析实战-信用卡欺诈检测(五)-逻辑回归模型
大数据分析实战-信用卡欺诈检测(一) 大数据分析实战-信用卡欺诈检测(二)-下采样方案和交叉验证 大数据分析实战-信用卡欺诈检测(三)- 模型评估 大数据分析实战-信用卡欺诈检测(四)-正则化惩罚 逻 ...
- 大数据分析实战-信用卡欺诈检测(四)-正则化惩罚
大数据分析实战-信用卡欺诈检测(一) 大数据分析实战-信用卡欺诈检测(二)-下采样方案和交叉验证 大数据分析实战-信用卡欺诈检测(三)- 模型评估 文章目录 正则化惩罚 正则化惩罚 正则化惩罚,这个名 ...
- 大数据分析实战-信用卡欺诈检测(三)- 模型评估
大数据分析实战-信用卡欺诈检测(二)-下采样方案和交叉验证 大数据分析实战-信用卡欺诈检测(一) 文章目录 模型评估方法 模型评估方法 接下来,没错,还没到实际建模任务,还需要考虑模型的评估方法,为什 ...
- 大数据分析实战-信用卡欺诈检测(二)-下采样方案和交叉验证
第一部分已经写到这里了,看完第一部分再看这一部分:大数据分析实战-信用卡欺诈检测 文章目录 下采样方案 交叉验证 下采样方案 下采样方案的实现过程比较简单,只需要对正常样本进行采样,得到与异常样本一样 ...
最新文章
- 实战Gradle——第一部分 Gradle介绍
- 昌吉学院计算机工程系毕业后安排工作嘛,0昌吉学院.doc
- linux 运行cmd文件,cmd文件如何在虚拟linux下运行
- ES6之路第十三篇:Iterator和for...of循环
- Windows系统带你一步一步无脑使用babel
- arduinowifi.send怎么获取响应_Vue3.0 响应式原理 (一)
- 从零开始学 Web 之 ES6(三)ES6基础语法一
- 三种model 在lfw 上的精度
- 【Node学习】—运行node服务demo
- 计算机网络—PPP协议和HDLC协议
- python股票自动交易系统_怎样用 Python 写一个股票自动交易的程序
- IPsec的NAT穿越详解
- 转贴:操盘手心理训练手册
- bbsmax mysql_MySQL中自己不太常用的命令
- Matlab取整函数
- 局域网SDN技术硬核内幕 二 从局域网到互联网
- android 签名工具 autoSign jarsigner
- 史上最实用网站集锦----不容错过
- 东风谷早苗机器人玩法_神秘谷介绍机器人
- 设计模式之多用组合,少用继承