PaddlePaddle文本卷积实现情感分类和微博女友情绪监控AI
本期文章我们将使用文本卷积和StackLSTM层来实现一个情感分类网络,这样你就可以拥有一个属于自己的情感监控AI啦,甚至通过微博的接口来监控你女朋友的情绪。而要实现这一切,你不需要别的什么东西,你只需要一个微博认证开发者账号,以及你女朋友的微博ID,当然还有我们牛逼的PaddlePaddle深度学习开发神器。噢,对了,我差点忘记了,首先你要有个女朋友。。。什么?你没有?去淘宝买个二手充气的吧。。。
开个玩笑,其实没有女朋友也没有关系啦,你可以用这个AI来监控任何你想监控的任何一个人。长久以来,人们都希望自己有一个人工智能,我是说,真正的人工智能,可以自动判别人类情感,并且将判别结果告知主人,这样我们就可以从繁琐的刷微博、看朋友圈等浪费时间的却又有时候不得不做的事情中解放出来。设想有一个人工智能可以监控你喜欢的人的微博,甚至监控你的朋友圈,当TA发一些比较消极的消息时,能被我们的智能AI探测到,然后AI会通过邮箱或者短信等手段通知你,你收到之后便可能第一时间给予TA一个深情的安慰…继而发展出一段旷世恋情…听起来非常不错吧?而这个东西就是我们本文要实现的东西。
0. 准备工作
啊,在开始之前,我们来捋一捋我们的思路,这将是一个不大却略显复杂的项目。
- 我们将需要一个微博账号,这个微博账号要能申请到微博接口,并且访问它;
- 我们需要一个超强的情感分类数据集,毕竟我们是在搞AI,脱离数据都是扯淡;
- 我们需要用到PaddlePaddle,这在之前我们提到过,它在构建情感分类上有着得天独厚的优势,如果你还没有入门,那么请看看我之前写的入门博客,将PaddlePaddle当做一个轻量级框架来用确实是个不错的主意。
哇,咋一看需要的东西真多,别急让我们一步一步来,我们将会把一些准备工作简单的介绍,但是主要的工作还是在,构建一个情感分类AI。首先当然我们既然要做一个微博情感监控,那么我们肯定要让AI能够access到微博的数据。所以说你要有个微博账号啦,没有的话申请一个。如果你想进一步看到我每天更新的博客文章,也可以来关注关注我啊,强行收粉,传送门.
1. 微博开发者认证及应用创建
好吧,有句话怎么说来着,不会后台开发的深度学习工程师不是好设计师….既然我们踏上了一条通往人工智能的不归路那就得下定决心踩着坑了。说起微博开发者认证,你可能需要准备,你的身份证照片等信息。从这里进入开始开发者认证开发者认证连接. 在本文中就不详细说明如何去认证了。一旦认证完了微博开发者,接下来就来创建一个移动应用。当然我们这里创建的移动应用并不是真正的移动应用,而是一个获取API接口的机会。从微博开放平台进入微连接,接入移动应用,这个时候会需要创建一个全新的应用。应用名称就随便填一个吧,应用平台选择其他,因为我们只要做一个Python后台程序,所以也不需要用到什么Android或者iOS SDK,当然啦,你要创建一个应用需要这么一些前提:
- 你要有一个应用,其实为此你不必要搭建一个网站,可以直接用我的应用网址:www.luoli-luoli.com;
- 你需要给你的应用取一个名字,这个就随便取啦,只要和已有的不重复即可,然后你可能还需要为你的应用设置一个logo,这个就看个人PS水平了。
这是我申请时候用的app:
如果你好奇为什么叫萝莉萝莉这个名字,是因为我的APP名字叫做萝莉萝莉…
好啦,相信你已经开始操作,操作完之后,你可能需要把这篇文章放入readlist,一天之后再来继续看吧…因为微博应用审核需要一天。
2. 开始构建情感分类深度学习模型
我们是一个数据工作者,数据工作者的事情时候需要去自己寻找数据。我们已经有了一个大胆的 设想,做一个人工智能来监控女朋友的反常情感。那么我们肯定需要一些标注的数据集来训练我们的模型,以此来实现一个可以判别情感的AI。在开始搜寻数据之前,让我们来大胆的设想一下,加入我们把情感值分为两类,Positive 和 Negative,可能情况会变得简单一些,这个时候,情感分类的任务就变成了一个二分类问题,我们有时候只需要知道女朋友是开心还是伤心,或者说是中性,而对于其他的情感,我们目前可能不是非常关心。因此,我们将目标锁定在中文情感分类数据集,我们暂且不去考虑分级过多的情感数据集,先从最简单的开始。
让我们来分析一下,要构建一个情感分类模型,初步来想有两种方法:
- 第一种构建一个正面词汇词库,和一个反面词汇词库,这样每次来一个新的句子的时候我们可以判断是正面词汇多呢,还是反面词汇多,从而来决定一个句子是反面还是正面,尽管这种方法简单易行,但是在遇到比如这样的句子时: 你他妈今天还真的把我当纸老虎了是不? 那么这句话中,他妈实际上是一个消极词汇,但是却不能归到消极词汇中,因为它也可能是一个中性词汇;
- 第二种当然是使用深度学习的方法啦,深度学习构建出来的复杂模型,不仅仅可以根据标签来判定哪些词汇是正面的,哪些词汇是负面的,同时也能够学习到不同词语在不同语境下所表现出来的消极以及正面性。
在本篇文章中,我们将使用一个stacked LSTM模型和一个文本卷积模型来实现情感的分类,为了简化操作,我们将使用一个英文的电影评价数据集,用这个来做一个简易的英文情感分类器,我们将使用PaddlePaddle训练一个模型来对句子进行精准的分类。当然啦,如果大家希望把这个转移到中文上,我在这里也提供一些中文方面的语料给大家,中国计算机中文信息技术会议的一个微博情感分类标注数据集,该数据集包含了20个话题,其中每个话题有正负两种情感的评论总共约2000余条,下载地址 (百度网盘)在此。这个数据集中,每个话题的评论在一个xml文件中,xml中包含句子和词性标注。
而Imdb数据集非常小巧,我们将在PaddlePaddle的代码中直接实现下载,无需手动下载。
3. PaddlePaddle构建情感分类器 - 文本处理
如果之前对PaddlePaddle没有什么了解,那么可以参照我之前写的文章,与其他框架的对比,传送门,简而言之,我们之所以使用PaddlePaddle来构建这么一个应用是基于它的这么一些优点:
- 快速实现和部署,为什么我说快速,PaddlePaddle有着其他国外框架无法比拟的优势,那就是健全的中文文档,包括像我写的这么一些非官方的文档,对于新手搭建网络来说非常的轻而易举;
- 轻量级,我认为PaddlePaddle相对于其他的框架来说,轻量是它的一个非常好的优点,它没有TensorFlow那么笨重,除此之外我甚至认为MXNet在轻量级上没有它好。原因很简单,从安装到构建网络到训练我可以在一个脚本文件中完成整个Pipeline。
好啦,闲话不多说,让我们先用PaddlePaddle来玩一些Playground的东西。在PaddlePaddle里面其实是内置了一些数据的,当然啦,这些数据会自动通过网络下载,但是我们可以直接导入它,从而可以知道PaddlePaddle喂入数据的格式到底是什么,闲话不多说,直接上代码:
|
from __future__ import print_function
import sys
import paddle.v2 as paddle
from __future__ import print_function
import sys
import paddle.v2 as paddle
import sys
import os
import json
import nltk
if __name__ == '__main__':
# init
paddle.init(use_gpu=False)
print('load dictionary...')
word_dict = paddle.dataset.imdb.word_dict()
print(word_dict)
|
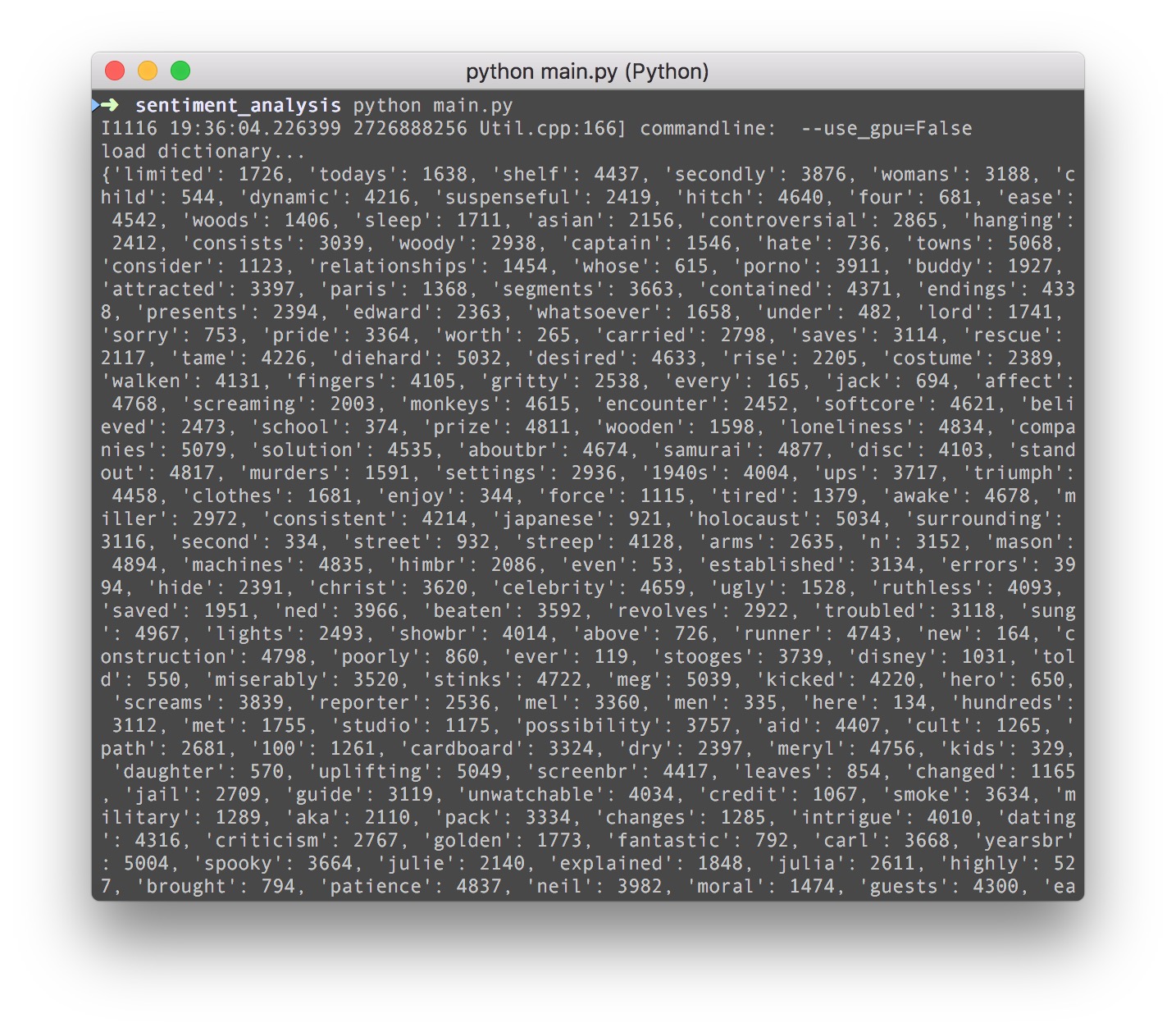
简单吧,一切就是如此的简洁,大家可以看到打印出来的word dict其实就是一个词袋,后面的数字表示的是这个词的id,为什么要这么处理?这就是涉及到文本处理领域基本的东西了-word bag,词袋法。我们知道一个神经网络模型,不管它多复杂,它的输入其实都是数字向量,那么文本怎么变成数字向量输入到网络里面去呢?我们知道图片输入到网络好理解,因为图片本身就是一个个的像素点啊。那文本要输入网络其实也非常简单,只需要把文字映射成为一个int ID就可以了。至于怎么映射,直接对所有词汇取一个词袋,给它一个ID即可。
毫无疑问,如果大家要构建中文的情感分类器,那原理也是一样的,只不过是对中文语料的进行一个词袋和ID映射的处理。
4. PaddlePaddle构建情感分类器 - 网络构建
其实情感分类也是一个分类任务,和图片分类是一样,而且情感分类是一个非常简单的二分类问题。大家如果有想法的话可以发散为三分类四分类问题,那么对应的就是不同的情感等级。我们做一个简易教程,当然无法做到非常深入,但是万变不离其宗,非常期待大家继续跟我一起关注PaddlePaddle的后续发展动态,我会在PaddlePaddle更新API之后不断地维护这些代码以及创造更多的教程来教大家怎么把这个框架用起来。闲话不多说,我们首先思考一下两个问题:
- 图片分类网络是怎么构建的?
- 图片分类的网络可以用来分类文本吗?
首先我们知道图片分类用CNN分,那么CNN其实它的要求是一个二维的矩阵,文本也和图片是一样的,但是文本通过ID转换之后得到的实际上是一个一维的向量,因为只有一句话。所以在这里有一个东西不得不传授给大家,那就是embedding,这个embedding你可以理解为嵌入,为什么要嵌入,什么是嵌入?这个其实不难理解,意思就是你事先有一个矩阵,这个矩阵的每一个元素是一个随机分布里面取的值,然后你在一个句子中的每一个ID,都映射到这个矩阵当中来,从而得到一个二维的矩阵,达到次嵌入的目的,一般情况下,词嵌入是一个比较复杂的东西,如果把这个东西加入到网络一起训练的话,你甚至可以做你的word2vec模型了,好在PaddlePaddle已经帮我们处理好了这些问题,我们可以直接调用PaddlePaddle里面的embed层来把一维的句子,转成CNN需要的二维。
在转换之前,我们需要看一下Imdb的数据是怎么读取的:
|
def reader_creator(pos_pattern, neg_pattern, word_idx, buffer_size):
# this unk is a token
UNK = word_idx['<unk>']
# start a quen to using multi-process
qs = [Queue.Queue(maxsize=buffer_size), Queue.Queue(maxsize=buffer_size)]
def load(pattern, queue):
for doc in tokenize(pattern):
queue.put(doc)
queue.put(None)
def reader():
# Creates two threads that loads positive and negative samples
# into qs.
t0 = threading.Thread(
target=load, args=(
pos_pattern,
qs[0], ))
t0.daemon = True
t0.start()
t1 = threading.Thread(
target=load, args=(
neg_pattern,
qs[1], ))
t1.daemon = True
t1.start()
# Read alternatively from qs[0] and qs[1].
i = 0
doc = qs[i].get()
while doc != None:
yield [word_idx.get(w, UNK) for w in doc], i % 2
i += 1
doc = qs[i % 2].get()
# If any queue is empty, reads from the other queue.
i += 1
doc = qs[i % 2].get()
while doc != None:
yield [word_idx.get(w, UNK) for w in doc], i % 2
doc = qs[i % 2].get()
return reader()
|
这个方法其实已经内置在Paddle中,我们不需要写它,但是为了让大家能够理解,我把它单独拿出来讲解一下,这个函数执行的操作其实非常简单,那就是根据上面所得到的word dict,把文本的每一个句子转换成一维的数字向量。由于Imdb里面是一句正情绪,一句负情绪,所以或有一个 %2的操作。
好了,接下来重点来了,我们要用PaddlePaddle构建我们的模型了,我之前提到了这个embed层,我们直接embed之后,接一个CNN来构建一个简单的文本卷积分类网络:
|
def convolution_net(input_dim, class_dim=2, emb_dim=128, hid_dim=128):
# we are starting with a embed layer
data = paddle.layer.data("word",
paddle.data_type.integer_value_sequence(input_dim))
emb = paddle.layer.embedding(input=data, size=emb_dim)
# this convolution is a sequence convolution
conv_3 = paddle.networks.sequence_conv_pool(
input=emb, context_len=3, hidden_size=hid_dim)
conv_4 = paddle.networks.sequence_conv_pool(
input=emb, context_len=4, hidden_size=hid_dim)
output = paddle.layer.fc(
input=[conv_3, conv_4], size=class_dim, act=paddle.activation.Softmax())
lbl = paddle.layer.data("label", paddle.data_type.integer_value(2))
cost = paddle.layer.classification_cost(input=output, label=lbl)
return cost, output
|
可以说,这个网络简直到令人想哭,但是它并不是“简单”,这里面有一个词嵌入操作,紧接着是两个卷积层,注意这里的卷基层并非是图片卷积,而是文本序列卷积,这个应该是PaddlePaddle中特有的一个特殊层,百度在文本序列和语音序列处理上还是有一套,等一下大家会看到,这么一个简单的模型可以在仅仅6个epoch就达到99.99%的精确度。embed的size是128,隐藏层神经元个数是128。大家其实完全不用关系这些网络是怎么连接的,我们把训练的代码写贴上来:
|
from __future__ import print_function
import sys
import paddle.v2 as paddle
import sys
import os
import json
import nltk
def convolution_net(input_dim, class_dim=2, emb_dim=128, hid_dim=128):
data = paddle.layer.data("word",
paddle.data_type.integer_value_sequence(input_dim))
emb = paddle.layer.embedding(input=data, size=emb_dim)
conv_3 = paddle.networks.sequence_conv_pool(
input=emb, context_len=3, hidden_size=hid_dim)
conv_4 = paddle.networks.sequence_conv_pool(
input=emb, context_len=4, hidden_size=hid_dim)
output = paddle.layer.fc(
input=[conv_3, conv_4], size=class_dim, act=paddle.activation.Softmax())
lbl = paddle.layer.data("label", paddle.data_type.integer_value(2))
cost = paddle.layer.classification_cost(input=output, label=lbl)
return cost, output
if __name__ == '__main__':
# init
paddle.init(use_gpu=False)
# those lines are get the code
print('load dictionary...')
word_dict = paddle.dataset.imdb.word_dict()
print(word_dict)
dict_dim = len(word_dict)
class_dim = 2
train_reader = paddle.batch(
paddle.reader.shuffle(
lambda: paddle.dataset.imdb.train(word_dict), buf_size=1000),
batch_size=100)
test_reader = paddle.batch(
lambda: paddle.dataset.imdb.test(word_dict),
batch_size=100)
feeding = {'word': 0, 'label': 1}
# get the output of the model
[cost, output] = convolution_net(dict_dim, class_dim=class_dim)
parameters = paddle.parameters.create(cost)
adam_optimizer = paddle.optimizer.Adam(
learning_rate=2e-3,
regularization=paddle.optimizer.L2Regularization(rate=8e-4),
model_average=paddle.optimizer.ModelAverage(average_window=0.5))
trainer = paddle.trainer.SGD(
cost=cost, parameters=parameters, update_equation=adam_optimizer)
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 100 == 0:
print("\nPass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics))
else:
sys.stdout.write('.')
sys.stdout.flush()
if isinstance(event, paddle.event.EndPass):
with open('./params_pass_%d.tar' % event.pass_id, 'w') as f:
trainer.save_parameter_to_tar(f)
result = trainer.test(reader=test_reader, feeding=feeding)
print("\nTest with Pass %d, %s" % (event.pass_id, result.metrics))
inference_topology = paddle.topology.Topology(layers=output)
with open("./inference_topology.pkl", 'wb') as f:
inference_topology.serialize_for_inference(f)
trainer.train(
reader=train_reader,
event_handler=event_handler,
feeding=feeding,
num_passes=20)
|
我们直接来跑起来看一下:
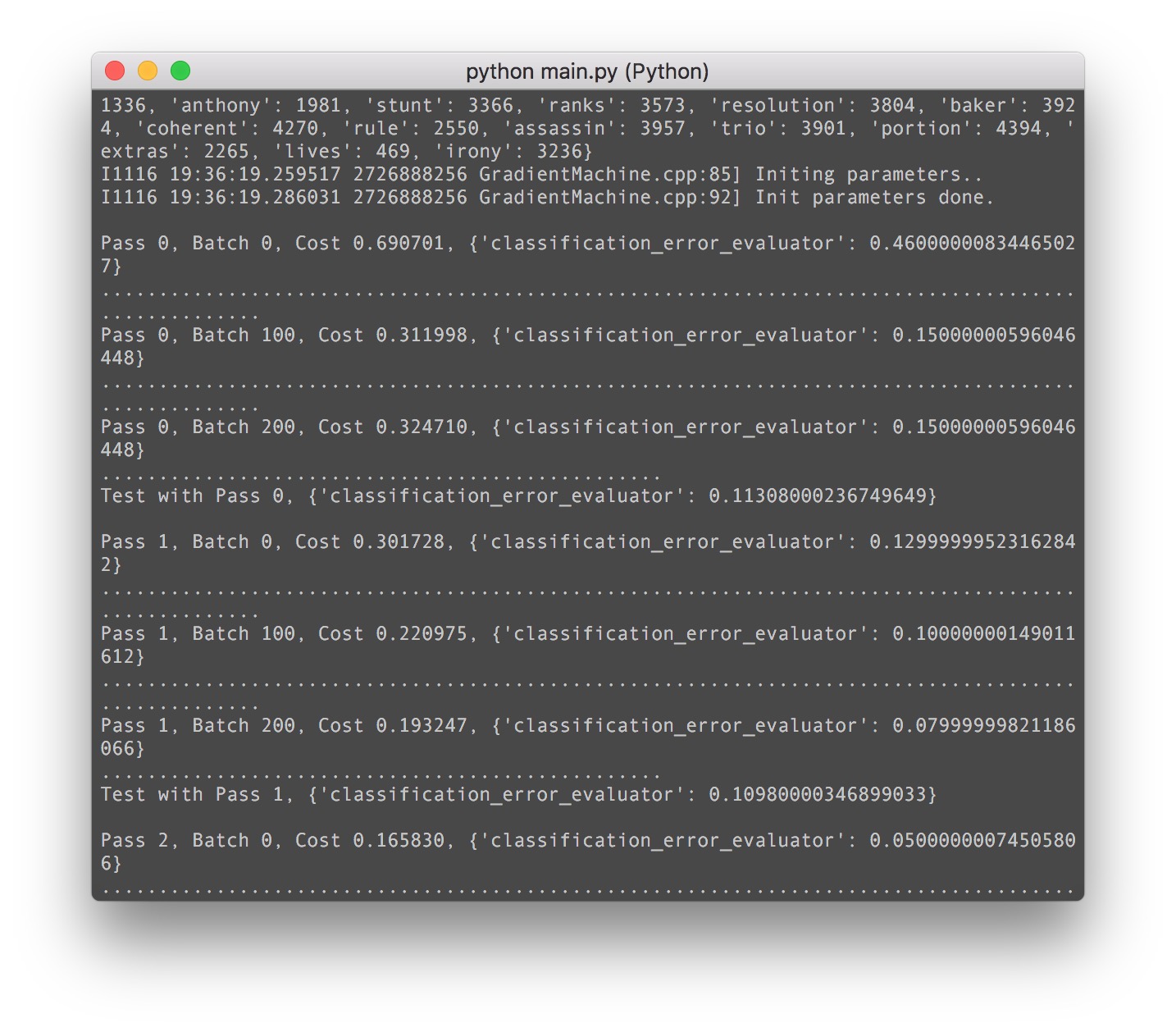
简直amazing,2个epoch之后就达到了90%的准确度!!! 非常非常的impressive!!
5. PaddlePaddle构建情感分类模型 - 模型部署
好了,到了最最重要的时刻来了,我们辛辛苦苦训练了两天两夜的模型,是时候看看它的威力了。此时此刻,你的项目文件夹的目录最少要跟我一样:
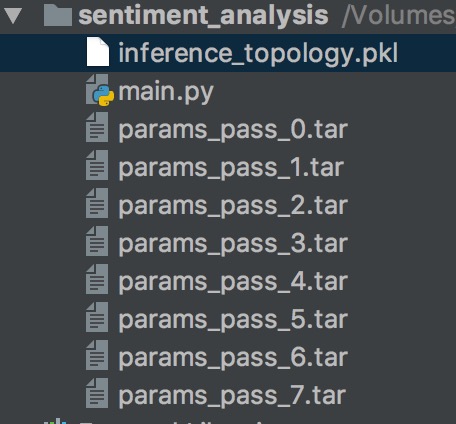
我现在只有一个main.py,这里面就是我们训练的脚本。我们有一个inference_topology.pkl,这个是我们的网络模型保存的二进制文件。大家注意了,这是我见过的最清晰的网络保存和权重保存方式!!没有之一!!PaddlePaddle的网络模型保存在了pkl,权重是一个tar的压缩文件!!!。这个比TensorFlow或者MXNet要人性化很多!!MXNet jb的根本不知道保存到哪里去了, TensorFlow还得手动写一个脚本来frozen一个模型,PaddlePaddle一步到位,非常牛逼!!
为了让大家体验一下预测的快感,我直接把代码贴出来了:
|
# -*- coding: utf-8 -*-
# file: predict.py
# author: JinTian
# time: 16/11/2017 8:17 PM
# Copyright 2017 JinTian. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ------------------------------------------------------------------------
import numpy as np
import sys
import paddle.v2 as paddle
from __future__ import print_function
import sys
import os
import json
import nltk
def convolution_net(input_dim,
class_dim=2,
emb_dim=128,
hid_dim=128,
is_predict=False):
data = paddle.layer.data("word",
paddle.data_type.integer_value_sequence(input_dim))
emb = paddle.layer.embedding(input=data, size=emb_dim)
conv_3 = paddle.networks.sequence_conv_pool(
input=emb, context_len=3, hidden_size=hid_dim)
conv_4 = paddle.networks.sequence_conv_pool(
input=emb, context_len=4, hidden_size=hid_dim)
output = paddle.layer.fc(input=[conv_3, conv_4],
size=class_dim,
act=paddle.activation.Softmax())
if not is_predict:
lbl = paddle.layer.data("label", paddle.data_type.integer_value(2))
cost = paddle.layer.classification_cost(input=output, label=lbl)
return cost
else:
return output
if __name__ == '__main__':
# Movie Reviews, from imdb test
paddle.init(use_gpu=False)
word_dict = paddle.dataset.imdb.word_dict()
dict_dim = len(word_dict)
class_dim = 2
reviews = [
'Read the book, forget the movie!',
'This is a great movie.'
]
print(reviews)
reviews = [c.split() for c in reviews]
UNK = word_dict['<unk>']
input = []
for c in reviews:
input.append([[word_dict.get(words, UNK) for words in c]])
# 0 stands for positive sample, 1 stands for negative sample
label = {0: 'pos', 1: 'neg'}
# Use the network used by trainer
out = convolution_net(dict_dim, class_dim=class_dim, is_predict=True)
parameters = paddle.parameters.create(out)
print(parameters)
# out = stacked_lstm_net(dict_dim, class_dim=class_dim, stacked_num=3, is_predict=True)
probs = paddle.infer(output_layer=out, parameters=parameters, input=input)
print('probs:', probs)
labs = np.argsort(-probs)
print(labs)
for idx, lab in enumerate(labs):
print(idx, "predicting probability is", probs[idx], "label is", label[lab[0]])
|
让我们来看一下预测的结果:
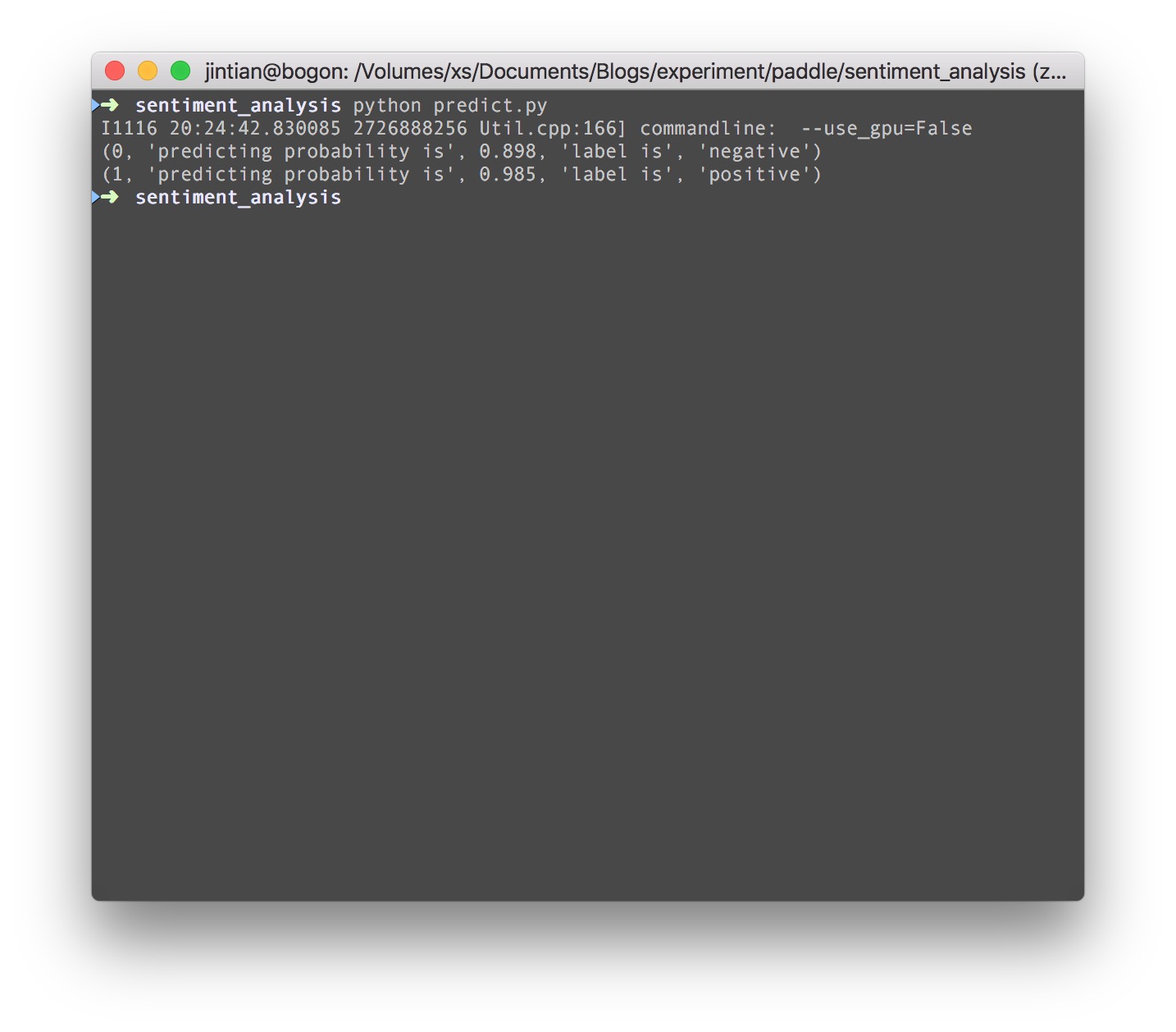
6. 后记
我们已经可以用PaddlePaddle构建自己的深度学习应用了!!!这次是情感分类!!这是一个非常不错的开端,我们已经有了自己的预测脚本,接下来只需要把我们的预测脚本和你的微博应用程序结合起来,当检测到女友的情绪不稳定时,就通过邮件通知你。当然这部分工作一直到现在我都没有通过微博的审核。。。。(无力吐槽微博ing)。不管怎么用,我们不得不再次赞一下百度PaddlePaddle的开发团队,用PaddlePaddel构建模型没有太多的abstraction,构建出来的模型非常简单便捷,如果要在深度学习和人工智能领域定义一个敏捷开发的代表,那么PaddlePaddle非它莫属啦~~。
7. 扩展
实现情感分类其实只是PaddlePaddle应用的冰山一角,我们可以通过这个基础的应用来实现无数的创意深度学习应用,就像Android操作系统一样,虽然底层的API都是一样但是却可以在这个基础之上建造微信,支付宝,直播APP这样的功能多样的应用程序。本文虽然给大家展示的是一个微博情感监控,大家也可以把这个东西应用在自己的APP当中,比如,根据用户发的评论来回复的情感极性来回复相应的话语,比如用在自己的聊天机器人中,使得它更加具有情感性,都是不错的应用。如果大家有什么好的想法和创意,也可以在原始博客下面评论与我互动,我会把更好的idea更新在我后面的博客中,期待你的创意!
本期列车到此结束,如果大家对本文由任何疑问,欢迎通过微信找到我,也欢迎大家订阅本文的首发地址也是永久更新维护地址: https://jinfagang.github.io
PaddlePaddle文本卷积实现情感分类和微博女友情绪监控AI相关推荐
- 机器学习:朴素贝叶斯算法+中文情感分类+python
朴素贝叶斯中文情感分类 1.写在前面 朴素贝叶斯算法理论在很多博客上已经解释的很详细了,本文就不再叙述,本文注重于算法的应用以及编程实现,在读取前人的博客以及他们的项目应用,本人结合书本<机器学 ...
- 疫情微博文本情感分类 (简化版SMP2020赛题)
编者按 代码仅供参考,欢迎交流:请勿用于任何形式的课程作业.如有任何错误,敬请批评指正~ Pytorch系列文章: Pytorch实验一:从零实现Logistic回归和Softmax回归 Pytorc ...
- 基于Python文本内容/情感的对微博文本自动二元分类
资源下载地址:https://download.csdn.net/download/sheziqiong/85836603 资源下载地址:https://download.csdn.net/downl ...
- bert中文文本情感分类 微博评论挖掘之Bert实战应用案例-文本情感分类
Bert模型全称Bidirectional Encoder Representations from Transformers,主要分为两个部分:1训练语言模型(language model)的预训练 ...
- MXNet中使用卷积神经网络textCNN对文本进行情感分类
在图像识别领域,卷积神经网络是非常常见和有用的,我们试图将它应用到文本的情感分类上,如何处理呢?其实思路也是一样的,图片是二维的,文本是一维的,同样的,我们使用一维的卷积核去处理一维的文本(当作一维的 ...
- python微博文本分析_微博评论挖掘之Bert实战应用案例-文本情感分类
Bert模型全称Bidirectional Encoder Representations from Transformers,主要分为两个部分:1训练语言模型(language model)的预训练 ...
- PaddlePaddle︱开发文档中学习情感分类(CNN、LSTM、双向LSTM)、语义角色标注
PaddlePaddle出教程啦,教程一部分写的很详细,值得学习. 一期涉及新手入门.识别数字.图像分类.词向量.情感分析.语义角色标注.机器翻译.个性化推荐. 二期会有更多的图像内容. 随便,帮国产 ...
- 中文文本情感分类(基于LSTM和textCNN)
中文新闻数据集 负面文本: 正面文本: 数据文本都是用爬虫从网络上爬取的,由人工进行分类,在使用这些数据之前,需要先对文本进行预处理,预处理包括去除标点符号,停用词过滤和分词等,由于篇幅有限,这里就不 ...
- 学习微博情感分类的特定情感词嵌入(A14, ACL2014)*
Learning sentiment-specific word embedding for twitter sentiment classification 学习微博情感分类的特定情感词嵌入(A14 ...
最新文章
- c# 连接mysql数据库_C#连接Mysql数据库
- List(Map(String, Object))转为Fastjson JSONArray
- Stanford_NLP_TOOLS:CRFClassifier
- 爬虫-使用xpath拿36KR的数据-xpath的学习与演练
- 7. 吴恩达机器学习课程-作业7-Kmeans and PCA
- c/c++ 多线程 ubuntu18.04 boost编译与运行的坑
- 6.爬虫 requests库讲解 总结
- dijkstra + 优先队列(C++)
- 刘强东不是一个人,互联网寒冬真的来了
- vue3 组件naiveui报错: Extraneous non-props attributes (class) were passed to component but could not be
- 累计亏31亿的尚德机构:研发费用递减,多次被罚,市值缩水近九成
- nginx做小程序外链跳转_微信小程序跳转到其他网页(外部链接)的实现方法
- Typora丢失文件数据找回
- 类似微信聊天 日期算法(转换)
- 在 unity中可以使用的直接设置音量大小的方法
- python制作海报_用python制作“除夕夜倒计时”海报,新的一年你准备好了么?
- 图划分软件Metis的使用
- 无法为数据库中的对象分配空间,因为'PRIMARY'文件组已满问题处理方式
- CPI成折叠式OLED面板保护层关键材料
- 力技艺法道,工匠师圣仙