odps之sql性能优化
前一段时间做了一些作业成本优化的工作,这里做下总结。
首先说明本篇中谈及的优化主要的目标是在不大幅度增加作业运行时长的条件下对作业运行成本的优化。
1. odps的优化引擎并没有那么智能
odps自带的优化引擎会对sql作业做一定的优化处理,如列裁剪、分区裁剪和谓词下推。但是还会存在一些不会优化处理的地方。甚至有些会和我们想象的存在一定的差异。具体碰到的情况有如下几种
1.1 多路输出(MULTI INSERT)中的想象差异
为了避免多次读取同一份数据,我们会使用multi insert的语句。如果在from语句中有一些较复杂的处理,如select语句有耗时的udf处理或者where语句有耗时的udf处理时会存在一些问题。
如如下sql:
FROM (SELECT tolower(bi_udf:bi_get_url_domain(host,1)) root_domain,tolower(secods:url_path(flow_str_concat('http://a.cn',uri))) pathfrom odl_beaver_log
where ds='20170818' and hh='07'and tolower(parse_url(uri,'EXT'))!='do'
)
insert overwrite table a(ds='20170818')
select root_domain...
insert overwrite table b
select ....
insert overwrite table c
select ....我们查看一下该sql实际的执行计划(具体查看计划请使用MaxCompute Studio工具)
注意:这里的sql与下面的执行计划的图不是一致的,这里只是举例说明
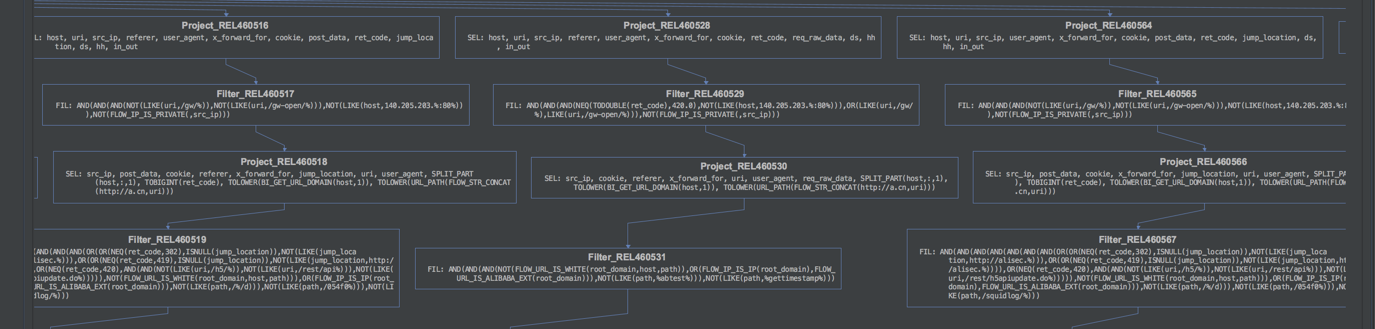
通过执行计划的图我们可以看出其处理流程并没按我们设想的先把from中的结果计算出来,然后再多路输出。而是先按多路输出进行列裁剪,然后再分别进行SEL(select语句)和FIL(where语句)的处理。那这里就会造成重复的计算处理,如果多路输出的表越多,造成的重复计算越多。
解决方法:如果from语句中有较复杂的sql处理逻辑,建议先将from语句的结果存为一张临时表,然后再进行后面的多路输出的处理
1.2 where和select语句中对同一字段的重复的udf处理并不会合并
在where语句中,有时我们会对同一字段的值进行多次的判断,且需要通过一个udf将该字段进行转换了后来进行多次的判断处理。同样select语句中也会存在这样的情况,一个udf处理的结果在多个表达式中用到。实际这里优化器不会对这样重复的表达式进行合并处理。这样就造成了重复的计算处理。如如下sql:
select * from odl_beaver_log
where ds='20170818' and hh='07'and not to_lower(uri) like '%abtest%'and not to_lower(uri) like '%gettimestamp%' and not to_lower(uri) like '%tb_eagleeyex_t%'解决方法:通过做一个子查询,先将该表达式在select语句中处理,然后再过滤。
select * from(
select ..., to_lower(uri) urifrom odl_beaver_log
where ds='20170818' and hh='07'
) awhere not uri like '%abtest%'and not uri like '%gettimestamp%' and not uri like '%tb_eagleeyex_t%'1.3 隐藏的隐式转换处理
在sql语句中如果条件2边的类型不一致时会自动进行隐式转换处理。例如如下sql:
selectsum(case when ret_code=200 then 1 else 0 end) as status_200_cnt,sum(case when ret_code in (301,302,419,420) then 1 else 0 end) as status_302_cnt,sum(case when ret_code>=300 and ret_code<=399 and ret_code not in (301,302) then 1 else 0 end) as status_3xx_cnt,sum(case when ret_code=401 then 1 else 0 end) as status_401_cnt,sum(case when ret_code=403 then 1 else 0 end) as status_403_cnt,sum(case when ret_code=404 then 1 else 0 end) as status_404_cnt
from a这里表中的ret_code的字段类型为string,那在执行上述sql时就会多次对ret_code进行string->bigint的处理。这里同样是存在多次的重复计算。
解决方法:这里先做一个子查询将ret_code转换为bigint类型,参考sql如下:
select sum(case when ret_code=200 then 1 else 0 end) as status_200_cnt,sum(case when ret_code in (301,302,419,420) then 1 else 0 end) as status_302_cnt,sum(case when ret_code>=300 and ret_code<=399 and ret_code not in (301,302) then 1 else 0 end) as status_3xx_cnt,sum(case when ret_code=401 then 1 else 0 end) as status_401_cnt,sum(case when ret_code=403 then 1 else 0 end) as status_403_cnt,sum(case when ret_code=404 then 1 else 0 end) as status_404_cnt
from(
select ...,cast(ret_code as bigint) ret_code from a
) a1.4 筛选条件的重排
在where语句中如果有多个filter处理条件,这里是支持短路求值的,在这样的场景下,where语句有多个filter处理条件,其中有一个条件计算成本低且能过滤较多的记录数,而另一个条件计算成本高,那我们希望在sql执行时能先执行前面那个过滤条件,而在目前odps的处理逻辑中是按照顺序从左到右执行的(注意:这里要考虑到sql优化引擎的谓词下推的处理,具体的执行顺序请参考执行计划的内容)
解决方法:评估where条件中各个筛选逻辑的计算成本和过滤的记录数的情况,调整sql,优先让计算成本低且过滤记录数较多的条件先执行。
能根据sql执行的实际情况重排筛选条件的这个需求已经给odps那边提了,他们有安排开发处理:http://sqi.alibaba-inc.com/arsenal//requirementDetail.htm?id=43362&departmentId=26718&bu=dataworks,但具体时间点完成还不清楚,如果能确定哪个比较优化,我们先在sql中手工处理了。
2. udf的优化
在odps的sql作业中,我们会用到较多的udf函数,其中有很多是自定义开发的udf函数,那这些函数如果性能有问题,会导致sql作业性能低,计算成本消耗较多。在实际的优化分析中,有碰到如下几类情形。
2.1 自定义开发的udf的功能与系统自带udf功能重复
在sql中的使用的自定义udf实际上系统自带的udf是支持的,一般来说自定义开发的udf的性能是没有系统自带的udf性能高的,所以一般情况下,建议使用系统自带的udf。
2.2 选择合适的udf
在开发中选择适合的udf对计算性能的优化也很明显,下面举几个例子来说明。
1)从字符串中解析出多个key值
业务中较常见从字符串中解析出多个值的情况,如keyvalue格式拼接的字符串,json字符串,url字符串等。
一般我们从json中解析key,系统有提供函数GET_JSON_OBJECT,那如果我们要解析多个key,那写法可能就是如下的:
selectGET_JSON_OBJECT(json_str, '$.key1'),GET_JSON_OBJECT(json_str, '$.key2'),GET_JSON_OBJECT(json_str, '$.key3'),GET_JSON_OBJECT(json_str, '$.key4')from a这样会对json_str做多次的解析,影响了性能。如果能一次将多个key解析出来,那就只需要解析一次了。自定义的udf:secods:json_tuple可以解决如上的问题。需注意,secods:json_tuple是一个udtf,如果select语句中还有其他字段时,写法上有一点不一样,参考sql如下:
selectcol1,col2,key1,key2,key3,key4from a
lateral view secods:json_tuple(json_str,"key1","key2","key3","key4") json_view as key1,key2,key3,key4同样keyvalue格式拼接的字符串要解析出多个key值的时候,同样也可以使用str_to_map来替代多次使用KEYVALUE,注意这里str_to_map是一个udf,返回的是一个Map类型。
在url字符串的场景,会有要解析出不同的part的情况,如HOST, PATH, QUERY, REF, PROTOCOL,这样就需要多次使用parse_url来解析处理,如果有一个udf可以一次解析出多个part,这样性能也会优化很多。不过目前还没有这个udf。
另外针对json和keyvalue格式,是否我们在底层就存储为map类型的字段这样会更好。
2)也有系统自带的udf性能没有自定义的高的情况
经测试parse_url就没有secods:url_path secods:url_host的性能高
2.3 优化自定义的udf
如果没有系统自带的udf可以替换,且不是多次解析的情况下,也可以从自定义udf的代码层面来优化。
如python的udf中对正则表达式先进行编译后再使用。这里我们可以使用一些profiling的工具来对自定义udf的性能进行分析,扁鹊中有带了java的profiling功能https://www.atatech.org/articles/38367,python的支持不是很好,那python代码使用profiling来分析,就是要自己准备一下环境。
那如何来快速定位存在性能问题的udf呢,首先我们可以通过查看作业执行的日志来看,在每个Task的日志中会打印如下的日志信息
Filter cursor process data time in milliseconds:1788.45
Filter cursor process data time in milliseconds:6.61
Filter cursor process data time in milliseconds:7.281
Filter cursor process data time in milliseconds:89.214
Filter cursor process data time in milliseconds:7.271
Select cursor process data time in milliseconds:2.782
Select cursor process data time in milliseconds:2.247
Select cursor process data time in milliseconds:2898.92
com.taobao.bi.odps.udf.endecode.UDFMd5 finally processed 107528 records. produced 107528 records. elapsed time in milliseconds: 404通过这些日志就可以看到哪个操作执行比较耗时。对应的关系猜测是按执行计划中的顺序号排列,待与odps相关同学确认后再更新。同时通过查看对应的执行计划就可以看到这一步中有哪些udf的操作。另外目前日志中会对java的udf把执行所消耗的时间会打印出来。如果是python的udf那就需要自己准备一些测试的sql来进行测试定位了。
3. odps系统参数优化
在一些场景下,我们也可以通过手工调整odps系统参数的值来达到成本优化的效果
3.1 hbo失效
当我们的作业发生修改后,那当时hbo就会失效,对于一些耗资源较多的作业,那成本的增长就非常的明显,那我们在作业修改上线时可以手工配置odps.sql.mapper.cpu和odps.sql.reducer.cpu的值来减少成本的巨大波动。这2个值默认为100,如果有修改上线后成本增长较多,那说明这2个参数在hbo生效时会减少,一般为50。另大家可以通过查看以前该作业hbo有生效的日志来查看这2个参数的具体值。
3.2 map任务执行时间太短
对于简单的sql加工作业,map任务执行的时间非常短(几秒~十几秒),但是可能会有很多的map任务,这种场景下我们可以调大odps.sql.mapper.split.size(单位M,默认值256),减少map任务的个数,增大每个map任务的执行时长。
odps之sql性能优化相关推荐
- 高效sql性能优化极简教程
一,sql性能优化基础方法论 对于功能,我们可能知道必须改进什么:但对于性能问题,有时我们可能无从下手.其实,任何计算机应用系统最终队可以归结为: cpu消耗 内存使用 对磁盘,网络或其他I/O设备的 ...
- 做 SQL 性能优化真是让人干瞪眼
很多大数据计算都是用 SQL 实现的,跑得慢时就要去优化 SQL,但常常碰到让人干瞪眼的情况. 比如,存储过程中有三条大概形如这样的语句执行得很慢: select a,b,sum(x) from T ...
- SQL性能优化案例分析
这段时间做一个SQL性能优化的案例分析, 整理了一下过往的案例,发现一个比较有意思的,拿出来给大家分享. 这个项目是我在项目开展2期的时候才加入的, 之前一期是个金融内部信息门户, 里面有个功能是收集 ...
- 如何进行正确的SQL性能优化
在SQL查询中,为了提高查询的效率,我们常常采取一些措施对查询语句进行SQL性能优化.本文我们总结了一些优化措施,接下来我们就一一介绍. 1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE ...
- Oracle SQL性能优化的40条军规
Oracle SQL性能优化的40条军规 1. SQL语句执行步骤 语法分析> 语义分析> 视图转换 >表达式转换> 选择优化器 >选择连接方式 >选择连接顺序 & ...
- SQL性能优化前期准备-清除缓存、开启IO统计
如果需要进行SQl Server下的SQL性能优化,需要准备以下内容: 一.SQL查询分析器设置: 1.开启实际执行计划跟踪. 2.每次执行需优化SQL前,带上清除缓存的设置SQL. 平常在进行SQL ...
- 想让DBA瞬间崩溃,那就让他去做SQL性能优化
本文分享自华为云社区<做 SQL 性能优化真是让人干瞪眼>,作者: 石臻臻的杂货铺 . 很多大数据计算都是用 SQL 实现的,跑得慢时就要去优化 SQL,但常常碰到让人干瞪眼的情况. 比如 ...
- SQL性能优化常见措施(Lock wait timeout exceeded)
SQL性能优化常见措施 目 录 1.mysql中explain命令使用 2.mysql中mysqldumpslow的使用 3.mysql中修改my.ini配置文件记录日志 4.mysql中如何加索引 ...
- SQL性能优化以及性能测试
SQL性能优化以及性能测试 博主介绍 笛卡尔连接 分页limit的sql优化的几种方法
最新文章
- 将HLSL射线追踪到Vulkan
- 【Codeforces 738D】Sea Battle(贪心)
- 武器化道路越走越远的无人机
- linux基础(一)
- JetBrains——账户登录错误(JetBrains Account Error:JetBrains Account connection error: www.jetbrains.com)解决方案
- Oracle其它数据库对象:视图、序列、同义词
- IDEA 启动时,报“淇℃伅”的字符
- 哪一类人用苹果手机最多?
- select * from什么意思_SQL入门教程第15课:什么是内连接
- WordPress多语言插件
- 组装一台计算机必需的配件有,哪位可以告诉我自己想组装一台电脑需要那些配件...
- 新视野大学英语(第三版)读写教程4答案
- 电子邮件邮箱怎么设置签名?手机邮箱签名设置攻略
- Python_抽奖游戏
- Python之(scikit-learn)机器学习
- Android studio安卓虚拟机无法启动
- EXCEL排名一样大的不重复
- 以太坊区块链快速入门
- linux操作系统 第09章 操作系统接口
- 网页游戏封包辅助技术