[爬虫+数据分析] 分析北京Python开发的现状
如下图我们可以得知
url:https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false
请求方式:post
result:为发布的招聘信息
totalCount:为招聘信息的条数
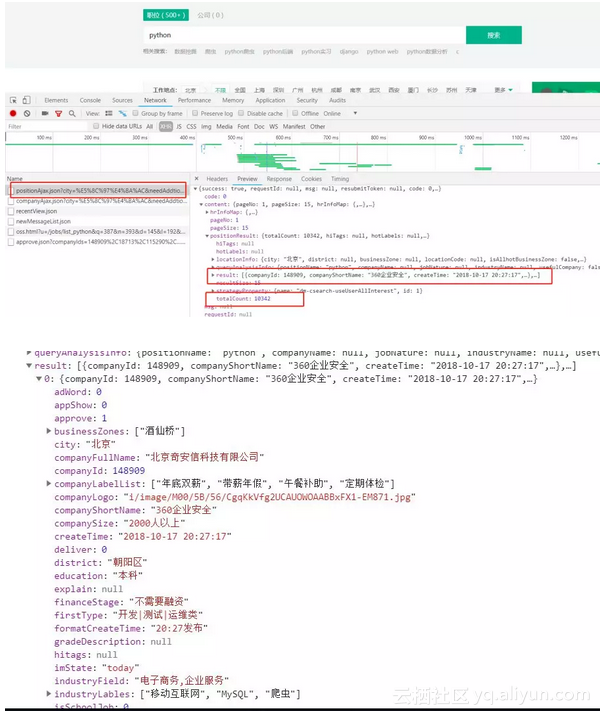
通过实践发现除了必须携带headers之外,拉勾网对ip访问频率也是有限制的。一开始会提示 '访问过于频繁',继续访问则会将ip拉入黑名单。不过一段时间之后会自动从黑名单中移除。
针对这个策略,我们可以对请求频率进行限制,这个弊端就是影响爬虫效率。
其次我们还可以通过代理ip来进行爬虫。网上可以找到免费的代理ip,但大都不太稳定。付费的价格又不太实惠。
具体就看大家如何选择了
1思路
通过分析请求我们发现每页返回15条数据,totalCount又告诉了我们该职位信息的总条数。
向上取整就可以获取到总页数。然后将所得数据保存到csv文件中。这样我们就获得了数据分析的数据源!
post请求的Form Data传了三个参数
first : 是否首页(并没有什么用)
pn:页码
kd:搜索关键字
2no bb, show code
# 获取请求结果# kind 搜索关键字# page 页码 默认是1def get_json(kind, page=1,):# post请求参数
param = {'first': 'true','pn': page,'kd': kind
}
header = {'Host': 'www.lagou.com','Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}# 设置代理
proxies = [
{'http': '140.143.96.216:80', 'https': '140.143.96.216:80'},
{'http': '119.27.177.169:80', 'https': '119.27.177.169:80'},
{'http': '221.7.255.168:8080', 'https': '221.7.255.168:8080'}
]# 请求的url
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'# 使用代理访问# response = requests.post(url, headers=header, data=param, proxies=random.choices(proxies))
response = requests.post(url, headers=header, data=param, proxies=proxies)
response.encoding = 'utf-8'if response.status_code == 200:
response = response.json()# 请求响应中的positionResult 包括查询总数 以及该页的招聘信息(公司名、地址、薪资、福利待遇等...)return response['content']['positionResult']return None接下来我们只需要每次翻页之后调用 get_json 获得请求的结果 再遍历取出需要的招聘信息即可
if __name__ == '__main__':# 默认先查询第一页的数据
kind = 'python'# 请求一次 获取总条数
position_result = get_json(kind=kind)# 总条数
total = position_result['totalCount']
print('{}开发职位,招聘信息总共{}条.....'.format(kind, total))# 每页15条 向上取整 算出总页数
page_total = math.ceil(total/15)
# 所有查询结果
search_job_result = []#for i in range(1, total + 1)# 为了节约效率 只爬去前100页的数据for i in range(1, 100):
position_result = get_json(kind=kind, page= i)# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)# 当前页的招聘信息
page_python_job = []for j in position_result['result']:
python_job = []# 公司全名
python_job.append(j['companyFullName'])# 公司简称
python_job.append(j['companyShortName'])# 公司规模
python_job.append(j['companySize'])# 融资
python_job.append(j['financeStage'])# 所属区域
python_job.append(j['district'])# 职称
python_job.append(j['positionName'])# 要求工作年限
python_job.append(j['workYear'])# 招聘学历
python_job.append(j['education'])# 薪资范围
python_job.append(j['salary'])# 福利待遇
python_job.append(j['positionAdvantage'])
page_python_job.append(python_job)
# 放入所有的列表中
search_job_result += page_python_job
print('第{}页数据爬取完毕, 目前职位总数:{}'.format(i, len(search_job_result)))# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)ok! 数据我们已经获取到了,最后一步我们需要将数据保存下来
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=search_job_result,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '工资', '职位福利'])
df.to_csv('lagou.csv', index=False, encoding='utf-8_sig')运行main方法直接上结果:
数据分析
通过分析cvs文件,为了方便我们统计,我们需要对数据进行清洗
比如剔除实习岗位的招聘、工作年限无要求或者应届生的当做 0年处理、薪资范围需要计算出一个大概的值、学历无要求的当成大专
# 读取数据
df = pd.read_csv('lagou.csv', encoding='utf-8')# 数据清洗,剔除实习岗位
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True) # print(df.describe())# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = '\d+'
df['work_year'] = df['工作经验'].str.findall(pattern)# 数据处理后的工作年限
avg_work_year = []# 工作年限for i in df['work_year']:# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0 if len(i) == 0:
avg_work_year.append(0) # 如果匹配值为一个数值,那么返回该数值 elif len(i) == 1:
avg_work_year.append(int(''.join(i))) # 如果匹配值为一个区间,那么取平均值 else:
num_list = [int(j) for j in i]
avg_year = sum(num_list)/2
avg_work_year.append(avg_year)
df['工作经验'] = avg_work_year
# 将字符串转化为列表,再取区间的前25%,比较贴近现实
df['salary'] = df['工资'].str.findall(pattern)# 月薪
avg_salary = [] for k in df['salary']:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df['月工资'] = avg_salary
# 将学历不限的职位要求认定为最低学历:大专\
df['学历要求'] = df['学历要求'].replace('不限','大专')数据通过简单的清洗之后,下面开始我们的统计
1绘制薪资直方图
# 绘制频率直方图并保存
plt.hist(df['月工资'])
plt.xlabel('工资 (千元)')
plt.ylabel('频数')
plt.title("工资直方图")
plt.savefig('薪资.jpg')
plt.show() 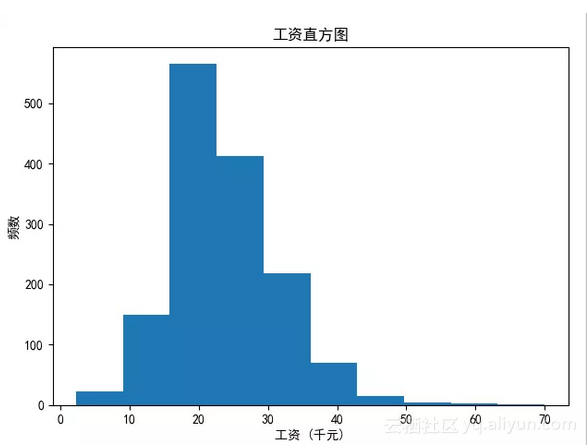
结论:北京市Python开发的薪资大部分处于15~25k之间
2公司分布饼状图
# 绘制饼图并保存
count = df['区域'].value_counts()
plt.pie(count, labels = count.keys(),labeldistance=1.4,autopct='%2.1f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('pie_chart.jpg')
plt.show() 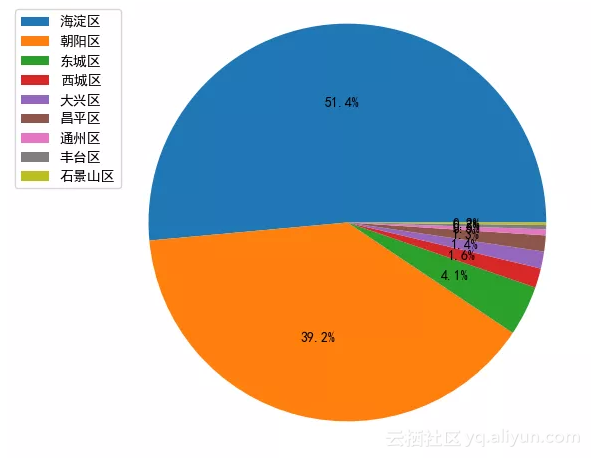
结论:Python开发的公司最多的是海淀区、其次是朝阳区。准备去北京工作的小伙伴大概知道去哪租房了吧
3学历要求直方图
# {'本科': 1304, '大专': 94, '硕士': 57, '博士': 1}
dict = {}for i in df['学历要求']:if i not in dict.keys():
dict[i] = 0else:
dict[i] += 1
index = list(dict.keys())
print(index)
num = []for i in index:
num.append(dict[i])
print(num)
plt.bar(left=index, height=num, width=0.5)
plt.show()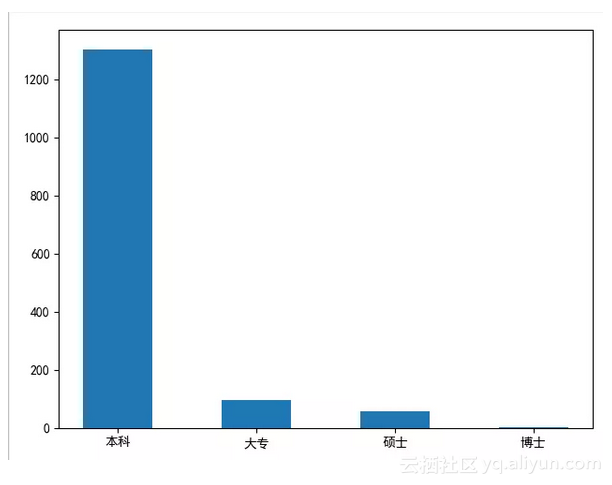
结论:在Python招聘中,大部分公司要求是本科学历以上。但是学历只是个敲门砖,如果努力提升自己的技术,这些都不是事儿
4福利待遇词云图
# 绘制词云,将职位福利中的字符串汇总
text = '' for line in df['职位福利']:
text += line # 使用jieba模块将字符串分割为单词列表
cut_text = ' '.join(jieba.cut(text))#color_mask = imread('cloud.jpg') #设置背景图
cloud = WordCloud(
background_color = 'white',# 对中文操作必须指明字体
font_path='yahei.ttf',#mask = color_mask,
max_words = 1000,
max_font_size = 100
).generate(cut_text)
# 保存词云图片
cloud.to_file('word_cloud.jpg')
plt.imshow(cloud)
plt.axis('off')
plt.show()
结论:弹性工作是大部分公司的福利,其次五险一金少数公司也会提供六险一金。团队氛围、扁平化管理也是很重要的一方面。
至此,此次分析到此结束。有需要的同学也可以查一下其他岗位或者地区的招聘信息哦~
希望能够帮助大家定位自己的发展和职业规划。
原文发布时间为: 2018-10-18
本文作者: 程序员共成长
本文来自云栖社区合作伙伴“ 程序员共成长”,了解相关信息可以关注“ 程序员共成长”。
[爬虫+数据分析] 分析北京Python开发的现状相关推荐
- python开发工程师面试题-分析经典Python开发工程师面试题
你知道吗?实际上Python早在20世纪90年代初就已经诞生,可是火爆时间却并不长,就小编本人来说,也是前几年才了解到它.据统计,目前Python开发人员的薪资待遇为10K以上,这样的诱惑很难让人拒绝 ...
- python简单爬虫程序分析_[Python专题学习]-python开发简单爬虫
掌握开发轻量级爬虫,这里的案例是不需要登录的静态网页抓取.涉及爬虫简介.简单爬虫架构.URL管理器.网页下载器(urllib2).网页解析器(BeautifulSoup) 一.爬虫简介以及爬虫的技术价 ...
- python qq协议_SmartQQ协议分析以及Python开发:登录部分
这两天一个小学弟向我请教QQ机器人是怎么开发的,想想自己也有近两年没研究过WebQQ的协议,突然兴起研究一下,其实吧,现在已经不存在所谓的WebQQ了,取而代之的是SmartQQ,其实说白了就是不需要 ...
- python适合什么样的人群_什么样的人比较适合选择Python开发+人工智能技术?
原标题:什么样的人比较适合选择Python开发+人工智能技术? 互联网行业最近几年来确实成为了竞相追捧的行业,人工智能.大数据的不断发展让Python开发技术成为了继Java开发之后的又一热门编程语言 ...
- python开发实例-python开发案例
广告关闭 2017年12月,云+社区对外发布,从最开始的技术博客到现在拥有多个社区产品.未来,我们一起乘风破浪,创造无限可能. gitee.com52itstylepythonblobmasterda ...
- 【爬虫+数据可视化毕业设计:英雄联盟数据爬取及可视化分析,python爬虫可视化/数据分析/大数据/大数据屏/数据挖掘/数据爬取,程序开发-哔哩哔哩】
[爬虫+数据可视化毕业设计:英雄联盟数据爬取及可视化分析,python爬虫可视化/数据分析/大数据/大数据屏/数据挖掘/数据爬取,程序开发-哔哩哔哩] https://b23.tv/TIoy6hj
- 【【数据可视化毕业设计:差旅数据可视化分析,python爬虫可视化/数据分析/大数据/大数据屏/数据挖掘/数据爬取,程序开发-哔哩哔哩】-哔哩哔哩】 https://b23.tv/iTt30QG
[[数据可视化毕业设计:差旅数据可视化分析,python爬虫可视化/数据分析/大数据/大数据屏/数据挖掘/数据爬取,程序开发-哔哩哔哩]-哔哩哔哩] https://b23.tv/iTt30QG ht ...
- 开课吧python爬虫数据分析统计服_使用爬虫分析Python岗位招聘情况
职位要求 提取了所有的职位要求,进行分词统计,清理没意义的词,统一英文字符,如 Python 和 python 不区分大小. 提取前 50 个中文词汇以及出现次数,这个词频排序挺有趣的,要来好好研究一 ...
- Python爬虫+数据分析+数据可视化(分析《雪中悍刀行》弹幕)
Python爬虫+数据分析+数据可视化(分析<雪中悍刀行>弹幕) 哔哔一下 爬虫部分 代码部分 效果展示 数据可视化 代码展示 效果展示 视频讲解 福利环节 哔哔一下 雪中悍刀行兄弟们都看 ...
最新文章
- Python模块-创建和执行程序(或者脚本)
- 使用复合索引代替单键索引,来避免单键有null值的情况
- 10.Shell操作符
- SAP License:BW/BCS(BO)难在那里--SAP中的公司和会计凭证
- 《南溪的目标检测学习笔记》——权重初始化
- NUC1214 回文素数
- 多线程中的静态代理模式
- sql 保留整数_Spark 3.0发布啦,改进SQL,弃Python 2,更好的兼容ANSI SQL,性能大幅提升...
- vb.net mysql 实例教程_VB.NET数据库编程基础教程(转载
- Kaggle 时间序列教程
- PS CS6 打不开RAW格式文件
- 针对目前windows系统的所有勒索病毒补丁和安全工具
- 什么是虚拟计算机集群
- 学习笔记 | Python编程从入门到实践 | 第二章变量和简单数据类型
- 时光飞逝,思考,实践,伴我一生的经验
- 4月11号软件资讯更新合集......
- squid代理及加速(理论加案例篇)
- 老牌好用免费的数据恢复软件easyrecovery操作简单一键恢复
- java模拟多人接力赛跑_Java多线程--模拟接力赛跑
- 对植物大战僵尸的数据修改