优先体验重播matlab_如何为深度Q网络实施优先体验重播
优先体验重播matlab
In this article, we will use the OpenAI environment called Lunar Lander to train an agent to play as well as a human! To do that, we will implement a version of the Deep Q-Network algorithm called Prioritized Experience Replay.
在本文中,我们将使用称为Lunar Lander的OpenAI环境来训练代理商像人类一样玩! 为此,我们将实现称为优先体验重播的Deep Q-Network算法版本。
To have a sense of what we want to accomplish, let’s watch an untrained agent play the game. While the goal is landing between the two yellow flags, we can see that the agent still has a lot to learn!
为了了解我们想要达成的目标,让我们看一个未经训练的经纪人玩游戏。 虽然目标是降落在两个黄旗之间,但我们可以看到该代理仍然有很多东西要学习!
To begin with, let’s refresh a bit our memory and place things into context. What is Deep Q-Network (DQN) and why do we use it? Globally, what kind of problems do we want to solve?
首先,让我们刷新一下内存,然后将其放入上下文中。 什么是深度Q网络(DQN),为什么要使用它? 在全球范围内,我们要解决什么样的问题?
The deep Q-network belongs to the family of the reinforcement learning algorithms, which means we place ourselves in the case where an environment is able to interact with an agent. The agent is able to take an action which will bring it from one state into another one. The environment will then provide a reward for attaining this new state, which can be positive or negative (penalty). The problem that we want to solve is being able to choose the best action for every state so that we maximize our total cumulative reward.
深度Q网络属于强化学习算法家族,这意味着我们将自己置于环境能够与代理交互的情况下。 代理能够采取将其从一种状态带入另一种状态的动作。 然后,环境将为达到此新状态提供奖励,可以是正面的或负面的(惩罚)。 我们要解决的问题是能够为每个州选择最佳行动,从而使我们的总累积奖励最大化。
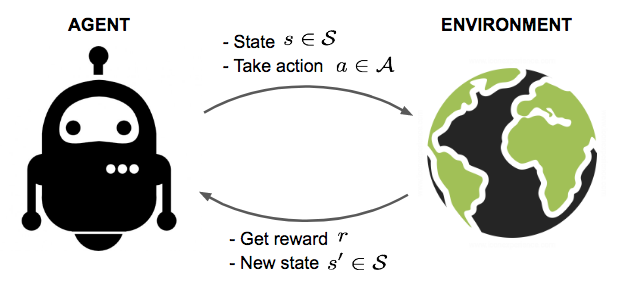
For Reinforcement Learning algorithms to work, given a state, the action that will provide the best cumulative reward should not depend on the pasts visited states. This framework is called a Markov Decision Process. By visiting states multiple times and by updating our expected cumulative reward with the one we actually obtain, we are able to find out the best action to take for every state of the environment. This is the basis of the Q-Network algorithm.
为了使强化学习算法在给定状态的情况下起作用,将提供最佳累积奖励的动作不应取决于过去的访问状态。 该框架称为马尔可夫决策过程。 通过多次访问州,并通过用实际获得的奖励来更新我们的预期累积奖励,我们能够找到针对每种环境状态采取的最佳措施。 这是Q网络算法的基础。
Now, this is very fine when we have a finite number of states, for example when an agent moves through a grid where the state is defined by the case its located at. The problem that we wish to solve now is the case of non-finite state variables (or actions). For example, a robot arm for which the environment state is a list of joint positions and velocities. The states being non-finite, it is very unlikely that we are going to visit a state multiple times, thus making it impossible to update the estimation of the best action to take. We need something that can, given two known states close enough to our current state, predict what would be the best action to take in our current state. You guessed it, the solution is some form of interpolation. When linear interpolation simply consists in “drawing a line between two states”, we need to be able to predict with a higher degree of complexity. That’s where neural network comes onto the stage. Neural networks give us the possibility to predict the best action to take given known states (and their optimal actions) with a non-linear model. And here it is, the Deep Q-Network. DQN posed several implementation problems, related to the training part of the neural network. The “trick” is called experience replay, which basically means that we episodically stop visiting the environment to first collect some data about the past visited states, and then train our neural network on the collected experiences. In other words, it’s alternating between phases of exploration and phases of training, decoupling the two allowing the neural network the converge towards an optimal solution.
现在,当我们有有限数量的状态时(例如,当一个代理移动通过网格时,状态是由其所在的情况定义的),这很好。 我们现在要解决的问题是非有限状态变量(或动作)的情况。 例如,机械臂的环境状态是关节位置和速度的列表。 由于状态是非限定性的,因此我们不太可能多次访问某个状态,因此无法更新对要采取的最佳措施的估计。 在两个已知状态与当前状态足够接近的情况下,我们需要能够预测在当前状态下采取最佳措施的方法。 您猜对了,解决方法是某种形式的插值。 当线性插值仅包含“在两个状态之间绘制一条线”时,我们需要能够以更高的复杂度进行预测。 那就是神经网络进入舞台的地方。 神经网络使我们有可能通过非线性模型预测采取给定已知状态的最佳动作(及其最佳动作)。 这就是深度Q网络。 DQN提出了一些与神经网络的训练部分有关的实现问题。 这种“技巧”称为体验重播,这基本上意味着我们通常停止访问环境,首先收集有关过去访问状态的一些数据,然后对收集到的体验进行神经网络训练。 换句话说,它在探索阶段和训练阶段之间交替,将两者解耦,使神经网络朝着最佳解决方案收敛。
Now that we have a good understanding of what brought us to a Q-Network, let the fun begins. In this article, we want to implement a variant of the DQN named Prioritized Experience Replay (see publication link). The concept is quite simple: when we sample experiences to feed the Neural Network, we assume that some experiences are more valuable than others. In a uniform sampling DQN, all the experiences have the same probability to be sampled. As a result, every experience will be used about the same number of times at the end of the training. If we sample with weights, we can make it so that some experiences which are more beneficial get sampled more times on average. Now how do we distribute the weights for each experience? The publication advises us to compute a sampling probability which is proportional to the loss obtained after the forward pass of the neural network. This is equivalent to say that we want to keep the experiences which led to an important difference between the expected reward and the reward that we actually got, or in other terms, we want to keep the experiences that made the neural network learn a lot.
现在我们对将我们带入Q网络的原因有了很好的了解,让我们开始乐趣。 在本文中,我们要实现DQN的一个变体,名为Prioritized Experience Replay(请参阅发布链接)。 这个概念非常简单:当我们采样经验以供入神经网络时,我们假设某些经验比其他经验更有价值。 在统一采样DQN中,所有体验都具有相同的采样概率。 结果,在培训结束时,每种体验将被使用相同的次数。 如果我们使用权重进行采样,那么我们可以做到这一点,从而使一些更有益的体验平均可以采样更多次。 现在,我们如何分配每种体验的权重? 该出版物建议我们计算采样概率,该概率与神经网络正向通过后获得的损失成比例。 这相当于说我们要保留导致预期奖励与实际获得的奖励之间存在重要差异的体验,或者换句话说,我们要保留使神经网络学到很多东西的体验。
Alright, now that we got the concept, it’s time to implement on a real case scenario. We will try to solve the OpenAI gym environment called “Lunar-lander”. In this environment, the agent is a spaceship undergoing gravity which can take 4 different actions: do nothing or fire left, right, or bottom engine. We get rewarded if the spaceship lands at the correct location, and penalized if the lander crashes. We also get a small penalty each time we use the bottom throttle, to avoid converging towards a situation where the AI would keep the lander in the air.
好了,既然我们有了概念,就该在实际案例中实施了。 我们将尝试解决称为“ Lunar-lander”的OpenAI体育馆环境。 在这种环境下,特工是承受重力的太空飞船,可以采取4种不同的动作:不做任何动作或向左,向右或向底部引擎射击。 如果飞船降落在正确的位置,我们将获得奖励;如果着陆器坠毁,我们将受到惩罚。 每次使用底部油门时,我们也会受到一点罚款,以避免收敛到AI会使着陆器处于空中的情况。
Now we can question our approach to this problem. Why do we want to use Deep Q-Network here? The states of this environment are described by 8 variables: x, y coordinates and velocities, rotation and angular velocity of the lander, and two boolean variables to state whether the legs of the lander are in contact with the ground. As we can see, most of the variables are continuous, so a discrete approach of the Q-Network would be inadequate, and we need to be able to interpolate the total reward we expect to get at one state to choose the best action, here with a neural network.
现在我们可以质疑我们对这个问题的处理方法。 为什么我们要在这里使用Deep Q-Network? 该环境的状态由8个变量描述:x,y坐标和速度,着陆器的旋转和角速度,以及两个布尔变量,用于说明着陆器的腿是否与地面接触。 如我们所见,大多数变量是连续的,因此Q网络的离散方法是不够的,我们需要能够插值我们期望在一种状态下获得的总奖励,以选择最佳操作。用神经网络。
Now comes another question, how do prioritizing some experiences may help us to obtain better or faster results in this scenario? When we begin training our algorithm, it is very probable that the lander will just crash most of the times. However, it might be that the lander will be able to touch the ground without crashing, or land correctly on rare occasions. In that case, the difference between the expected result (negative reward) and the actual output (positive reward) would be significant, leading to a much higher probability for this experience to be sampled. In a sense, we wish to use this experience multiple times to train the neural network as an example of what is working and what direction we should take to improve the weights of the network.
现在又出现了另一个问题,在这种情况下,如何优先考虑一些经验可以帮助我们获得更好或更快速的结果? 当我们开始训练算法时,着陆器很可能在大多数情况下都会崩溃。 但是,着陆器可能能够在不坠落的情况下接触地面,或者在极少数情况下能够正确着陆。 在那种情况下,预期结果(负奖励)与实际输出(正奖励)之间的差异将是巨大的,从而导致这种体验被采样的可能性更高。 从某种意义上说,我们希望多次使用这种经验来训练神经网络,以作为提高网络权重的有效方法和方向的示例。
Great, we are now sure that our approach is valid. Let’s dig into the details of the implementation. We will focus on the class `ReplayBuffer` as it contains most of the implementation related to the Prioritized Experience Replay, but the rest of the code is available on GitHub. The goal that we will set is to improve the rapidity of the algorithm (to be able to solve the environment with fewer episodes), without sacrificing running time due to additional computation complexity. To do that, we will be careful about the types of containers we will use to store our data, as well as how we access and sort out data. The publication cites two ways to store the priorities, one with a regular container and one with sum trees, a custom data type that can grant write and access over a priority with complexity o(1). We will try to focus here on the implementation with a regular container, as it seems more challenging to optimize so as to reduce complexity, providing with a good coding exercise!
太好了,我们现在确定我们的方法是有效的。 让我们深入研究实现的细节。 我们将专注于类ReplayBuffer,因为它包含与优先体验重播有关的大多数实现,但是其余代码可在GitHub上获得。 我们将设定的目标是提高算法的速度(以更少的情节解决环境),而不会因为额外的计算复杂性而牺牲运行时间。 为此,我们将谨慎使用用于存储数据的容器类型,以及如何访问和整理数据。 该出版物引用了两种存储优先级的方法,一种是使用常规容器,另一种是使用总和树,这是一种自定义数据类型,可以授予对具有复杂度o(1)的优先级进行写入和访问。 我们将尝试着重于使用常规容器的实现,因为优化似乎似乎更具挑战性,以降低复杂性,并提供良好的编码练习!
We assume here that the implementation of the Deep Q-Network is already done, that is we already have an agent class, which role is to manage the training by saving the experiences in the replay buffer at each step and to train the neural network episodically. The neural network is also already defined, here we chose a neural network with two hidden layers of respective size 256 and 128 neurons with ReLu activation, and a final linear activation layer.
我们在这里假设Deep Q-Network的实现已经完成,也就是说,我们已经有一个agent类,其作用是通过在每一步中将经验保存在重播缓冲区中来管理训练,并对神经网络进行训练。 。 还已经定义了神经网络,这里我们选择了一个神经网络,该网络具有两个分别具有ReLu激活大小的256和128个神经元的隐藏层,以及一个最终的线性激活层。
In the uniform sampling DQN, we randomly sample through the experiences with a linear distribution, which means we only need one container to store the experiences without any need for additional computation. For Prioritized Experience Replay, we do need to associate every experience with additional information, its priority, probability and weight.
在统一采样DQN中,我们通过线性分布对经验进行随机采样,这意味着我们只需要一个容器即可存储经验,而无需进行其他计算。 对于优先体验重播,我们确实需要将每个体验与其他信息,优先级,概率和权重相关联。
The priority is updated according to the loss obtained after the forward pass of the neural network. The probability is computed out of the experiences priorities, while the weight (correcting the bias introduced by not uniformly sampling during the neural network backward pass) is computed out of the probabilities. The paper introduces two more hyper-parameters alpha and beta, which control how much we want to prioritize: at the end of the training, we want to sample uniformly to avoid overfitting due to some experiences being constantly prioritized. The equations can be found below:
根据在神经网络正向传递之后获得的损失来更新优先级。 概率是从经验优先级中计算出来的,而权重(校正由于在神经网络反向传递过程中不均匀采样而引入的偏差)是从概率中计算出来的。 本文介绍了另外两个超参数alpha和beta,它们控制我们要确定优先级的数量:在培训结束时,由于某些经验始终处于优先地位,我们希望统一采样以避免过度拟合。 这些方程式可以在下面找到:
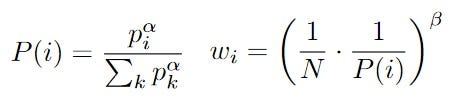
According to the authors, the weights can be neglected in the case of Prioritized Experience Replay only, but are mandatory when associated with dual Q-network, another DQN implementation. The weights will still be implemented here for a potential usage in combination with a dual Q-network.
作者认为,仅在“优先体验重播”的情况下权重可以忽略,但是在与另一个DQN实现的双Q网络关联时,权重是必需的。 权重仍将在此处实现,以便与双Q网络结合使用。
So compared to the uniform DQN we now have 3 values to associate with the experiences. Worse than that, we need to be able to update these variables. In terms of implementation, it means that after randomly sampling our experiences, we still need to remember from where we took these experiences. Concretely, that is remembering the index of the experience in the container when we sample it (Ah, if only we had pointers). So we now get 4 variables to associate. The container that we choose is a dictionary. Actually two dictionaries, one for the experiences themselves and one for the associated data, this is fine since we need to remember the index anyway. Because we need to find the data back after processing them in the neural network, a dictionary is a good fit since the complexity of its accessor is of magnitude o(1) as we don’t need to browse the whole container. For both dictionaries, the values are in form of named tuples, which makes the code clearer. We also add a small for loop to initialize the dictionaries indexes.
因此,与统一DQN相比,我们现在有3个值可与体验相关联。 更糟糕的是,我们需要能够更新这些变量。 在实施方面,这意味着在随机抽样我们的经验之后,我们仍然需要记住这些经验的来源。 具体来说,就是在我们对容器进行体验采样时记住它的索引(啊,如果只有指针的话)。 因此,我们现在获得了四个要关联的变量。 我们选择的容器是一个字典。 实际上有两本字典,一本用于体验本身,一本用于相关数据,这很好,因为我们仍然需要记住索引。 因为我们需要在神经网络中对数据进行处理后再找回数据,所以字典非常适合,因为它的访问器的复杂度为o(1),因为我们不需要浏览整个容器。 对于这两个字典,值均采用命名元组的形式,这使代码更清晰。 我们还添加了一个小的for循环来初始化字典索引。
Next, let’s dissect the probably most computationally expensive step, the random sampling. It is expensive because, in order to sample with weights, we probably need to sort our container containing the probabilities. To sample, we use the random.choices function, let’s see how this is implemented.
接下来,让我们剖析可能是计算上最昂贵的步骤,即随机采样。 这很昂贵,因为为了进行加权采样,我们可能需要对包含概率的容器进行排序。 作为示例,我们使用random.choices函数,让我们看看它是如何实现的。
If we browse the Python documentation for the function bisect we can see this: “This module provides support for maintaining a list in sorted order without having to sort the list after each insertion”. Bingo! No need to look further into the code, the function does need to sort the container at least once every time we call random.choices, which is equivalent to a complexity of magnitude o(n). Our dictionary being of size 10e5, that’s far from being negligible. We can’t really afford to sort the container every sample, as we sample every four steps. A solution to go around this problem is to sample multiple batches at once for multiple neural network trainings in prevision. We saw that random.choices is implemented with the bissect function which makes sure that the container is only sorted once, so sampling more batches does not add any complexity.
如果浏览Python文档中的bisect函数,我们将看到:“此模块提供了对列表进行维护的支持,而无需在每次插入后对列表进行排序”。 答对了! 无需进一步研究代码,该函数确实需要在每次我们调用random.choices时至少对容器进行一次排序,这等效于量级为o(n)的复杂性。 我们的字典的大小为10e5,远远不能忽略。 由于我们每四个步骤进行一次采样,因此我们真的无法负担对每个样本进行排序的能力。 解决此问题的一种解决方案是一次对多个批次进行抽样以进行预先的多个神经网络训练。 我们看到用bissect函数实现了random.choices,该函数确保容器仅被排序一次,因此对更多批次进行采样不会增加任何复杂性。
This approach has two drawbacks:
这种方法有两个缺点:
- When we sample for some batch other than the first, the priorities that we use are not the most updated ones. This is actually okay as the priorities are still updated for the next batches sampling so this difference won’t be seen after many sampling iterations.当我们为第一个批次以外的批次采样时,我们使用的优先级不是最新的。 这实际上是可以的,因为在下一批采样时仍会更新优先级,因此在进行多次采样迭代后就不会看到这种差异。
- Python’s random.choices will sample the same value multiple times. If we only sample a fraction of the collected states it does not really make a difference, but if we start to sample too many batches in one time, some states will get overly sampled. The tests done with the implementation showed that a sampling size of 2000 (compared to a container of size 10e5) showed the best results.Python的random.choices将多次采样相同的值。 如果我们仅对收集到的状态的一小部分进行采样,则并不会真正起到作用,但是如果我们一次开始采样太多批次,则某些状态将被过度采样。 通过该实现进行的测试表明,抽样大小为2000(与大小为10e5的容器相比)显示出最佳结果。
Let’s see how this has been implemented in the ReplayBuffer class:
让我们看看如何在ReplayBuffer类中实现它:
Here the variables update_mem_every and update_nn_every represent respectively how often we want to compute a new set of experience batches and how often we want to train the network. The current_batch variable represents which batch is currently used to feed the neural network and is here reset to 0.
在这里,变量update_mem_every和update_nn_every分别表示我们要多久计算一组新的体验批次以及我们要多久训练一次网络。 current_batch变量表示当前用于供给神经网络的批次,并在此处重置为0。
We are now able to sample experiences with probability weights efficiently. Let’s take a look at the PER algorithm to understand how to include our sampling in the bigger picture.
现在,我们可以有效地使用概率权重对经验进行抽样。 让我们看一下PER算法,以了解如何在更大的范围内包括我们的采样。

We can notice two things that could be tricky for computation complexity optimization: being able to remember the maximum priority and the maximum weight for each step. This might seem easy to do, basically just comparing the newly updated values with the max at each step. But that’s forgetting that the container is of fixed size, meaning that each step we will also delete an experience to be able to add one more. Now what if we delete the maximum, how do we find the second highest value? Should we always keep track of the order of the values in the container? Of course not! This would mean o(n) complexity at each step. In practice, we can simply find the maximum each time the maximum value gets deleted. So we keep track of the max, then compare every deleted entry with it. Usually, experiences to be deleted already have been used couple of times, so their priority should be low, so as the chances that it is actually the maximum value. So we are fine with sorting the container once in a while. See code below at line 9:
我们可以注意到对于计算复杂性优化可能棘手的两件事:能够记住每个步骤的最大优先级和最大权重。 这似乎很容易做到,基本上只是将每个步骤的新更新值与最大值进行比较。 但这忘记了容器的大小是固定的,这意味着我们还将删除每个步骤以增加一个体验。 现在,如果我们删除最大值,该如何找到第二高的值呢? 我们是否应该始终跟踪容器中值的顺序? 当然不是! 这将意味着每个步骤的复杂度为o(n)。 实际上,每次删除最大值时,我们都可以简单地找到最大值。 因此,我们跟踪最大值,然后将每个删除的条目与其进行比较。 通常,要删除的体验已经使用过两次,因此它们的优先级应该低一些,以使它实际上是最大值。 因此,我们可以偶尔对容器进行排序。 参见下面第9行的代码:
To point out, we also have a variable named priorities_sum_alpha. As can be seen in the definition of the sampling probability, the sum of all the recorded experiences priorities to the power alpha needs to be computed each time. And for sure we don’t want to compute this value from scratch each time so we keep track of it and update it upon addition/deletion of an experience.
要指出的是,我们还有一个名为priority_sum_alpha的变量。 从采样概率的定义中可以看出,每次都需要计算功率α的所有记录经验优先级的总和。 并且可以肯定的是,我们不想每次都从头开始计算该值,因此我们会跟踪并在添加/删除体验时对其进行更新。
Our code is pretty much optimized, overall we should have a complexity of o(n/T), T being the number of batches we sample at once. Of course, the complexity depends on that parameter and we can play with it to find out which value would lead to the best efficiency.
我们的代码已经过优化,总体而言,我们应该具有o(n / T)的复杂度,T是我们一次采样的批次数。 当然,复杂度取决于该参数,我们可以使用它来找出哪个值将导致最佳效率。
Time to test out our implementation! We run two tests, one with the prioritized experience replay implementation, another one with the uniform sampling DQN. We plot the obtained graph shown as below:
该测试我们的实现了! 我们运行了两个测试,一个测试具有优先级的经验重播实现,另一个测试具有统一的采样DQN。 我们绘制获得的图,如下所示:
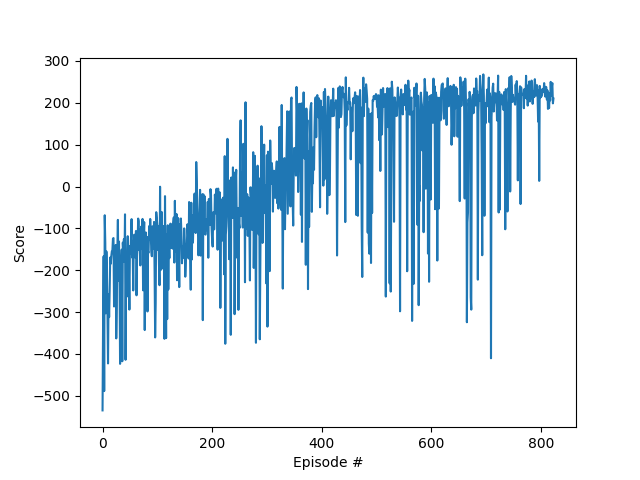
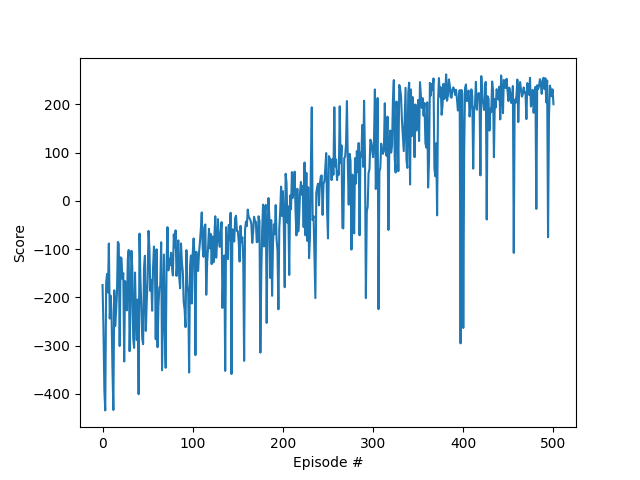
No, this is not a mistake, the uniform sampling is outperforming the prioritized sampling! Both of the algorithms were run with the same hyper-parameters so the results can be compared. And we find out that by using prioritized sampling we are able to solve the environment in about 800 episodes while we can do it in about 500 in the case of uniform sampling. Though we went through the theory and saw that prioritizing experiences would be beneficial! Few reasons that could explain what went wrong here:
不,这不是一个错误,统一采样的性能优于优先采样! 两种算法都使用相同的超参数运行,因此可以比较结果。 而且我们发现,通过使用优先采样,我们可以在大约800个情节中解决环境问题,而在统一采样的情况下,我们可以在大约500个情节中解决问题。 尽管我们研究了该理论,但发现优先考虑经验将是有益的! 几个原因可以解释这里出了什么问题:
- We can see from the publication that the prioritizing experiences have a different outcome on the result across multiple environments. Especially, there is already a gap in performance between the two presented approaches, the rank based and proportional one. It is not certain that lunar lander will benefit of prioritizing experiences.从出版物中我们可以看到,在多个环境中,优先级排序经验对结果产生不同的结果。 特别是,两种基于等级的方法和成比例的方法之间在性能上已经存在差距。 不确定月球着陆器是否会优先考虑经验。
- In the publication, all the experiments are led with prioritizing experiences on top of a double Q-network algorithm. The authors do not detail the impact that this implementation has over the results for PER. It is possible that implementing two dueling Q-networks would enable the prioritized experience replay to unleash its full potential.在该出版物中,所有实验都是在双Q网络算法的基础上优先考虑经验来进行的。 作者没有详细介绍此实施对PER结果的影响。 实施两个决斗的Q网络可能使优先级的体验重播释放其全部潜力。
- We can’t fail to notice that Lunar Lander is a fairly simple environment to solve, with about 400 experiences needed. Other games from the Atari collection might need several orders of magnitude more experiences to be considered solved. After all, in our case, the experiences which matter most, let’s say collect a high reward for touching the ground without crashing, are not that rare. Prioritizing too much on them would overfit the neural network for this particular event. In other terms, you would learn to touch the ground properly but would have no idea how to go get close to the ground!我们一定会注意到,Lunar Lander是一个非常简单的解决方案,需要大约400种经验。 Atari系列的其他游戏可能需要几个数量级以上的经验才能考虑解决。 毕竟,就我们而言,最重要的经历并不是少见的,因为他们在不坠落的情况下接触地面可以获得很高的回报。 对它们进行过多的优先处理将使神经网络不适合该特定事件。 换句话说,您将学会正确地接触地面,但不知道如何接近地面!
As a matter of fact, we tried tweaking the algorithm so as to prioritize the positive experiences only. The reasoning behind that is, when learning how to play, the algorithm would crash much more than it would land correctly, and since we can crash on a much wider area than we can land, we would tend to remember much more crashing experiences than anything else. For that purpose, we tried to following adaptation: we look at the signed difference between the neural networks actual output and the expected value. If it’s positive, we actually got a better reward than what we expected! Then we apply a ReLu function to assign the difference to be 0 if negative, else do nothing. In the replay buffer, so as to not just delete purely the experiences with a negative difference, we assign them with average priority.
实际上,我们尝试调整算法,以便仅优先考虑积极体验。 其背后的原因是,当学习如何玩时,该算法将比其正确着陆时崩溃得多,并且由于我们可能在比着陆范围更广的范围内崩溃,因此我们往往会记住比任何东西都多的崩溃经验其他。 为此,我们尝试进行以下调整:我们查看神经网络实际输出与期望值之间的有符号差异。 如果是积极的,我们实际上会得到比预期更好的回报! 然后,我们应用ReLu函数将差值分配为0(如果为负),否则不执行任何操作。 在重播缓冲区中,为了不仅仅是删除具有负差异的体验,我们将它们分配为平均优先级。
In theory, that would result in simply prioritizing a bit more the experiences with high positive reward difference (landing). In practice, that’s a different story… The algorithm does not even converge anymore! Truth be told, prioritizing experiences is a dangerous game to play, it is easy to create bias as well as prioritizing the same experiences over and over leading to overfitting the network for a subset of experiences and failing to learn the game properly. The publication does advise to anneal the value of alpha (controlling how much you rely on priority) to 0 so that we tend towards uniform sampling, which we use, but in our case, it only results in forcing the algorithm to converge after enough iterations.
从理论上讲,这将导致仅优先考虑具有较高正奖励差异(着陆)的体验。 实际上,这是另一回事了……该算法甚至不再收敛! 说实话,优先体验是一个危险的游戏,容易产生偏见,并且一遍又一遍地优先考虑相同的体验,导致过分适合网络,以获得一部分体验,并且无法正确学习游戏。 该出版物确实建议将alpha值(控制对优先级的依赖程度)退火为0,以便我们倾向于使用统一采样,但在我们的情况下,这只会导致算法在经过足够的迭代后收敛。
Even though the algorithm does not lead to better learning performances, we can still verify that our other goal, reducing computation complexity, is met. To that end, we will use the uniform sampling algorithm which we know solves the environment, and a modified version of the prioritized experience implementation where the parameter alpha is assigned to 0. This way, we do sample uniformly while keeping the complexity of prioritizing experiences: we still need to sample with weights, update priorities for each training batch and so on. Since the two experiments are similar, we can safely directly compare the training duration
即使该算法不能带来更好的学习效果,我们仍然可以验证是否达到了降低计算复杂性的另一个目标。 为此,我们将使用已知的解决环境的统一采样算法,以及将参数alpha分配为0的优先体验实现的修改版本。通过这种方式,我们在保持优先体验复杂性的同时进行均匀采样:我们仍然需要进行权重采样,为每个培训批次更新优先级,等等。 由于两个实验相似,因此我们可以安全地直接比较训练时间
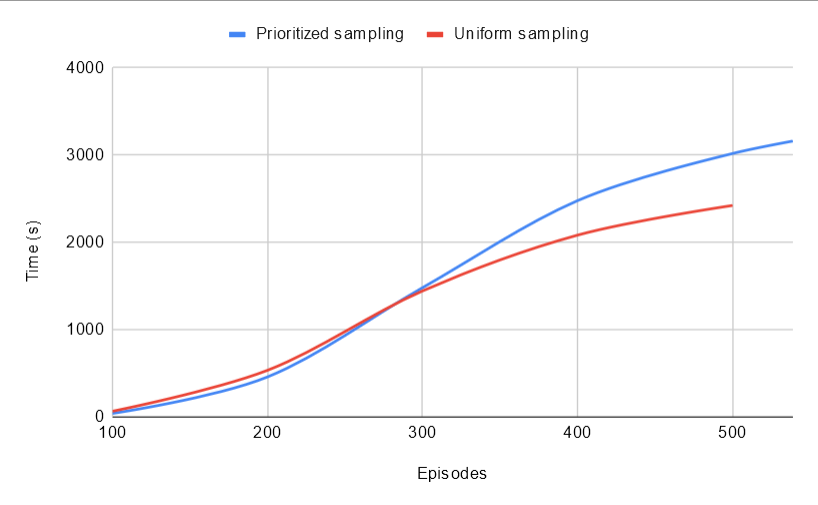
As we can see, our implementation does increase the overall computation time to solve the environment from 2426s to 3161s, which corresponds to approximately a 34% increase. This is an acceptable price to pay given the complexity of what we intend to do (access and modify elements of a container at each iteration, order a container to sample from it frequently). Looking at the graph, it seems that until 300 episodes, both algorithms require about the same time to process but diverge later. This is understandable given the fact that the container of 10e5 elements becomes full at about this stage. Remember that tiny detail about having to update all the container if we remove the highest priority value, which is okay since it almost never happens? Well here, all the priorities are the same so it does happen every time once the container is full. So to look at a real comparison we can limit ourselves to the first 300 experiences which see little difference between the two implementations! To note, the publication mention that their implementation with sum trees lead to an additional computation time of about 3%. It seems that our implementation can provide similar results which is rather satisfying.
正如我们所看到的,我们的实现确实将解决环境所需的总体计算时间从2426s增加到了3161s,这大约相当于增加了34%。 考虑到我们要执行的操作的复杂性,这是可以接受的价格(每次迭代访问和修改容器的元素,并经常从中订购容器)。 查看图表,似乎直到300集,这两种算法都需要大约相同的时间来处理,但以后会有所不同。 考虑到10e5元素的容器大约在此阶段已满的事实,这是可以理解的。 还记得关于如果我们删除最高优先级值就必须更新所有容器的微小细节,这没关系,因为它几乎永远不会发生? 在这里,所有优先级都相同,因此每次容器装满后都会发生。 因此,要进行真实的比较,我们可以将自己限制在前300种体验中,这两种实现之间的差异很小! 要注意的是,该出版物提到它们用总和树的实现导致大约3%的额外计算时间。 看来我们的实现可以提供令人满意的类似结果。
Of course, these results depend on the hyper-parameters chosen for the prioritized experience replay implementation, namely how many batches do you want to sample at once and how frequently do you want to update the parameters alpha and beta (which need to update every single probability in the buffer). The higher these two values get, the faster the algorithm would compute, but that would probably have a non-negligible impact on the training. Since our algorithm does not provide benefits on this part, it is hard to define optimal parameters, but it should be possible to benchmark a set of parameters and decide what is the best overall compromise.
当然,这些结果取决于为优先体验重放实施选择的超参数,即您要一次采样多少批次,以及您要多久更新一次参数alpha和beta(需要更新每一个参数)缓冲区中的概率)。 这两个值越高,算法将计算得越快,但这可能对训练产生不可忽略的影响。 由于我们的算法在这方面没有提供好处,因此很难定义最佳参数,但是应该可以对一组参数进行基准测试并确定最佳的整体折衷方案。
What can we conclude in this experiment? First that we were able to implement the prioritized experience replay for deep Q-network with almost no additional computation complexity. Second, that this implementation seems not improving the agent’s learning efficiency for this environment. So what could we do next?
在这个实验中我们可以得出什么结论? 首先,我们能够实现深度Q网络的优先体验重播,而几乎没有额外的计算复杂性。 其次,这种实现似乎并没有提高代理在这种环境下的学习效率。 那么下一步我们该怎么办?
- Implement the dueling Q-network together with the prioritized experience replay.实施对决Q网络以及优先级的经验重播。
- Try this agent on other environments to see if the prioritized experience replay can lead to improve results given this implementation.在其他环境中尝试使用此代理程序,以查看优先级的体验重播是否可以改善此实施方案的结果。
- Implement the rank based prioritize experience replay (the one using sum trees) as it is claimed to provide better results.实施基于等级的优先体验重放(使用求和树的一种),因为它可以提供更好的结果。
Last but not least, let’s observe a trained agent play the game! We deserve that after all of that gruesome computation. Of course, we use the trained agent from the prioritized memory replay implementation, it took more time but it’s still trained well enough!
最后但并非最不重要的一点,让我们观察训练有素的经纪人玩游戏! 经过所有令人毛骨悚然的计算之后,我们值得这样做。 当然,我们使用优先级内存重放实现中训练有素的代理,虽然花费了更多时间,但仍然训练得足够好!
To improve…
改善...
Full code: https://github.com/Guillaume-Cr/lunar_lander_per
完整代码: https : //github.com/Guillaume-Cr/lunar_lander_per
Publication: https://arxiv.org/abs/1511.05952
出版物: https : //arxiv.org/abs/1511.05952
翻译自: https://towardsdatascience.com/how-to-implement-prioritized-experience-replay-for-a-deep-q-network-a710beecd77b
优先体验重播matlab
http://www.taodudu.cc/news/show-1874138.html
相关文章:
- 人工智能ai以算法为基础_为公司采用人工智能做准备
- ieee浮点数与常规浮点数_浮点数如何工作
- 模型压缩_模型压缩:
- pytorch ocr_使用PyTorch解决CAPTCHA(不使用OCR)
- pd4ml_您应该在本周(7月4日)阅读有趣的AI / ML文章
- aws搭建深度学习gpu_选择合适的GPU进行AWS深度学习
- 证明神经网络的通用逼近定理_在您理解通用逼近定理之前,您不会理解神经网络。...
- ai智能时代教育内容的改变_人工智能正在改变我们的评论方式
- 通用大数据架构-_通用做法-第4部分
- 香草 jboss 工具_使用Tensorflow创建香草神经网络
- 机器学习 深度学习 ai_人工智能,机器学习和深度学习。 真正的区别是什么?...
- 锁 公平 非公平_推荐引擎也需要公平!
- 创建dqn的深度神经网络_深度Q网络(DQN)-II
- kafka topic:1_Topic️主题建模:超越令牌输出
- dask 于数据分析_利用Dask ML框架进行欺诈检测-端到端数据分析
- x射线计算机断层成像_医疗保健中的深度学习-X射线成像(第4部分-类不平衡问题)...
- r-cnn 行人检测_了解用于对象检测的快速R-CNN和快速R-CNN。
- 语义分割空间上下文关系_多尺度空间注意的语义分割
- 自我监督学习和无监督学习_弱和自我监督的学习-第2部分
- 深度之眼 alexnet_AlexNet带给了深度学习的世界
- ai生成图片是什么技术_什么是生成型AI?
- ai人工智能可以干什么_我们可以使人工智能更具道德性吗?
- pong_计算机视觉与终极Pong AI
- linkedin爬虫_这些框架帮助LinkedIn大规模构建了机器学习
- 词嵌入生成词向量_使用词嵌入创建诗生成器
- 端到端车道线检测_如何使用Yolov5创建端到端对象检测器?
- 深度学习 检测异常_深度学习用于异常检测:全面调查
- 自我监督学习和无监督学习_弱和自我监督的学习-第3部分
- 聊天工具机器人开发_聊天机器人-精致的交流工具? 还是您的客户服务团队不可或缺的成员?...
- 自我监督学习和无监督学习_弱和自我监督的学习-第4部分
优先体验重播matlab_如何为深度Q网络实施优先体验重播相关推荐
- 【EasyRL学习笔记】第八章 针对连续动作的深度Q网络
文章目录 一.连续动作 二.方案1:对动作进行采样 三.方案2:梯度上升 四.方案3:设计网络架构 五.方案4:不使用深度Q网络 六.习题 一.连续动作 深度 Q\mathrm{Q}Q 网络其实存在一 ...
- 【强化学习】双深度Q网络(DDQN)求解倒立摆问题 + Pytorch代码实战
文章目录 一.倒立摆问题介绍 二.双深度Q网络简介 三.详细资料 四.Python代码实战 4.1 运行前配置 4.2 主要代码 4.3 运行结果展示 4.4 关于可视化的设置 一.倒立摆问题介绍 A ...
- 【EasyRL学习笔记】第七章 深度Q网络进阶技巧(Double-DQN、Dueling-DQN、Noisy-DQN、Distributional-DQN、Rainbow-DQN)
文章目录 一.双深度Q网络(DDQN) 二.竞争深度Q网络(Dueling DQN) 三.优先级经验回放 四.在蒙特卡洛方法和时序差分方法中取得平衡 五.噪声深度Q网络(Noisy DQN) 六.分布 ...
- 通过深度Q网络DQN构建游戏智能体
目录 什么是深度Q网络(DQN) DQN的基本结构 DQN的关键技术 用Python和Gym实现DQN 算法优化 1. 网络结构优化 2. 训练策略优化 3. 超参数优化 欢迎来到我的博客,今天我们将 ...
- 第七章 深度强化学习-深度Q网络系列1(Deep Q-Networks,DQN)
获取更多资讯,赶快关注上面的公众号吧! 文章目录 第七章 深度强化学习-深度Q网络 7.1 学习目标 7.2 深度学习和强化学习的区别 7.3 DQN原理 7.4 DQN算法 7.4.1 预处理 7. ...
- 强化学习_07_DataWhale深度Q网络进阶技巧
习题 7-1 为什么传统的深度Q 网络的效果并不好?可以参考其公式Q(st, at) = rt + maxa Q(st+1, a) 来描述. 因为实际上在做的时候,我们要让左边的式子跟目标越接近越好. ...
- 【EasyRL学习笔记】第六章 DQN 深度Q网络(基本概念)
文章目录 一.深度Q网络的引入 1.1 传统表格型方法的缺点 1.2 引入深度Q网络 二.状态价值函数 2.1 基于蒙特卡洛的方法 2.2 基于时序差分的方法 2.3 两方法对比 2.4 举例说明 三 ...
- RL(十三)深度Q网络(DQN)
目录 1.神经网络和强化学习的差异对比 2.DQN(Depp Q-Network)算法 2.1神经网络来近似价值函数 2.2经验回放 2.3使用两个网络 3.总结 在前面的学习中,我们主要是学习强化学 ...
- 【强化学习】Deep Q Network深度Q网络(DQN)
1 DQN简介 1.1 强化学习与神经网络 该强化学习方法是这么一种融合了神经网络和Q-Learning的方法,名字叫做Deep Q Network. Q-Learning使用表格来存储每一个状态st ...
- 三人决斗_使用深度q决斗学习为厄运建立进攻性AI代理
三人决斗 介绍 (Introduction) Over the last few articles, we've discussed and implemented Deep Q-learning ( ...
最新文章
- ORA-08002: sequence MySeq.currval is not yet defined in this session
- python下载文件暂停恢复_python下载文件记录黑名单的实现代码
- 马斯克的火箭又炸了,这次可能怪美国宇航管理局:因督导员迟到,星舰原型SN11被迫在浓雾中发射...
- 动态调用WebService
- axios create拦截_Vue学习-axios
- VS Code 新扩展,面向 Web 开发人员调试 DOM
- ggplot2图集汇总(一)
- OpenCV图像 OSG模型 vs2015 摄像头 图像 插入模型
- matlab函数句柄介绍
- Onvif协议学习:12、修改分辨率
- 广告公司管理软件介绍
- 人机大战!人工智能轻松打败美国空军
- c语言判断闰年并输出该月天数,C语言宏定义实现闰年判断并输出指定月的天数...
- python:实现balanced parentheses平衡括号表达式算法(附完整源码)
- SQL Prompt数据库教程:标量用户定义函数误用作常量
- PCB板的线宽、铜厚度,与通过的电流对应的关系,一文看懂!
- 鸿蒙系统升级到第几批了,鸿蒙系统第四批升级名单有哪些 鸿蒙系统第四批升级机型介绍...
- 自动与Internet时间服务器同步
- 基于zynq的SGMII调试
- springmvc临时不使用视图解析器的自动添加前后缀
热门文章
- HDU1013 Digital Roots
- 通过脚本执行sql语句
- 需要掌握的flex知识点
- AdaBoost(1)
- 表格中文字如何设置上下居中
- 第12章 决策树 学习笔记下 决策树的学习曲线 模型复杂度曲线
- 第11章 支撑向量机 SVM 学习笔记 下 SVM思路解决回归问题
- opencv 图像对比度、亮度值调整 和滑动条
- Atitit db query op shourt code lib list 数据库查询最佳实践 JdbcTemplate spring v2 u77 .docx Atitit db query o
- Atitit postgre sql json使用法 目录 1.1.1. 插入数据 1 2. json数据的常见操作 1 1.1.1.插入数据 插入数据可以直接以json格式插入: insert