基于深度学习的图像超分论文推荐
时隔一年,重新回顾超分领域,真是读论文的速度赶不上发论文的速度,一年不见,已经出现了不少优秀的paper。先来一波,
CVPR2019中关于超分辨率算法的16篇论文压压惊。
好了,上干货,开始我们的重点,首先介绍下概念:
超分辨率(Super Resolution,SR)
超分辨率是一项底层图像处理任务,将低分辨率的图像映射至高分辨率,以期达到增强图像细节的作用。图像模糊不清的原因有很多,比如各式噪声、有损压缩、降采样,甚至还有可能是你熬夜过多所致……
超分辨率是计算机视觉的一个经典应用。SR是指通过软件或硬件的方法,从观测到的低分辨率图像重建出相应的高分辨率图像(说白了就是提高分辨率),在监控设备、卫星图像遥感、数字高清、显微成像、视频编码通信、视频复原和医学影像等领域都有重要的应用价值。
超分分为以下两种:
Image SR 只参考当前低分辨率图像,不依赖其他相关图像的超分辨率技术,称之为单幅图像的超分辨率(single image super resolution,SISR)。
Video SR 参考多幅图像或多个视频帧的超分辨率技术,称之为多帧视频/多图的超分辨率(multi-frame super resolution)。对于video SR,其核心思想就是用时间带宽换取空间分辨率。简单来讲,就是在无法得到一张超高分辨率的图像时,可以多取相邻几帧,然后将这一系列低分辨率的图像组成一张高分辨的图像。
一般来讲Video SR相比于Image SR具有更多的可参考信息,并具有更好的高分辨率视频图像的重建质量,但是其更高的计算复杂度也限制了其应用。本博文主要介绍SISR。SISR是一个逆问题,对于一个低分辨率图像,可能存在许多不同的高分辨率图像与之对应,因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。在传统的方法中,这个先验信息可以通过若干成对出现的低-高分辨率图像的实例中学到。而基于深度学习的SR通过神经网络直接学习分辨率图像到高分辨率图像的端到端的映射函数。
我们通常理解的超分辨率都是指SISR,我们只需要输入一张低分辨率图像而获得高分辨率图像的输出。 而VSR会利用视频的时间关联性来获得对某一帧的SR。本文的算法就是针对前者。
最早将深度学习用到SISR的居然是Kaiming大神等人在ECCV2014年提到的SRCNN,那时并没有像NTIRE这样相关的比赛,只有少量开源数据集可以玩玩。至此,对kaiming大神的敬仰又多了一分。
ECCV2018有一篇关于小物体目标检测的论文让人印象深刻,迅速引起了大家的关注,这篇文章叫SOD-MTGAN,文中巧妙利用了SR对小物体进行放大,然后得到更高的小物体检测准确率。这也是木盏开始研究SR的原因,因为SR被证明是有利于目标检测和跟踪的。
SOD-MTGAN论文地址:SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network

不同的超分辨率算法
上图从左到右依次是原图、Bicubic、SMPSR、SRCNN、IRCNN、RDN三倍放大结果。使用的神经网络越复杂,得到的输出效果越好。
评价指标
如果来描述SR效果呢?业界有个约定俗成的指标,叫做PSNR,即峰值信噪比。这个指标可以比较你SR结果图和ground truth(即原高清大图)之间的差距;此外,还有一个指标叫做SSIM,即结构相似性。这个指标与PSNR一样,也可以评价你SR的恢复效果。关于PSNR和SSIM两个指标,我都写了相关博文进行详细描述,想了解可以点击《PSNR》和《SSIM》
让我们先看看LOL的插值效果究竟如何:

LOL视频的超分辨率结果(4倍)
上图依次是原图、SRCNN、VDSR、EDSR
可以看出,虽然输出图像远好于低分辨率的输入,但距离真正的高清原图还有一定差距。
残差网络的提出有效解决了深度网络导致的梯度消失问题,来自首尔大学的Kim等人发表于CVPR2016的VDSR(超分辨率)便是一个代表性工作,他们将CNN扩展到20层,并且以训练残差ΔI=IHR-I^HR差代替直接训练IHR。
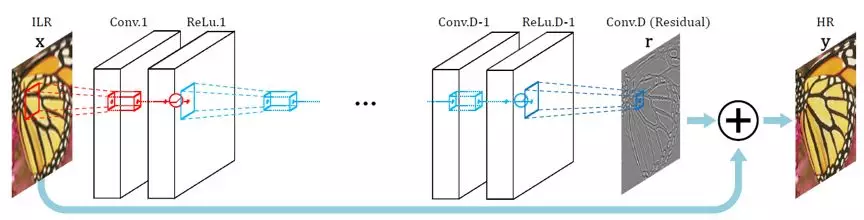
VDSR堆叠了更多的卷积层,并且用残差结构避免梯度消失的问题
虽然VDSR做到了最好的基准成绩,但对细节的处理让人仍不满意。当“更大更好”这个逻辑仍然成立时,研究者把目光放向更加复杂的结构,主要思路可以概括为两点——特征层的划分和组合,极大地扩展了卷积层数。
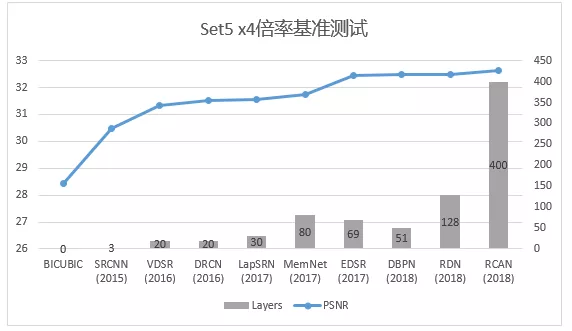
不断加深的层数和不断提升的成绩
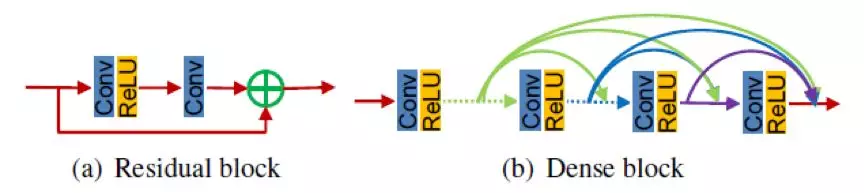
常用的组合结构:(a)残差块;(b)密集块

随着研究进一步发展,人们开始将目光转向视频序列的超分辨率。相对于单帧图像,视频是由时间上连续的图像构成,具有高度的时间关联性。同一场景下连续的两帧It和It+1,可以看作It经过“运动”变成了It+1。
如果忽略时间维度,仅对单帧独立超分辨率,虽然可以得到看似“不错”的结果,但如果将输出帧再连起来播放,就会发现视频中容易出现“波浪”效果。这是由于忽略了时间相关性,生成像素在时间上不一定连续,使得时间上匹配的像素发生了偏移,连贯播放起来就产生了波浪效果。

低清GIF

SISR GIF

VSR GIF
在视频任务中,主流做法是采用光流法引入时间关联。所谓光流,是指两帧图像对应像素的运动矢量。有了光流信息,就能用“运动”的概念联系起帧间信息。为了使卷积网络能够正确处理运动关联,一般将d-1个参考帧根据光流信息重新采样到目标帧:
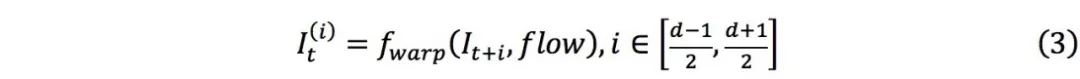
加强长度为d的帧的集合在空间上的重合度,有利于网络学习到像素的多重关联信息。
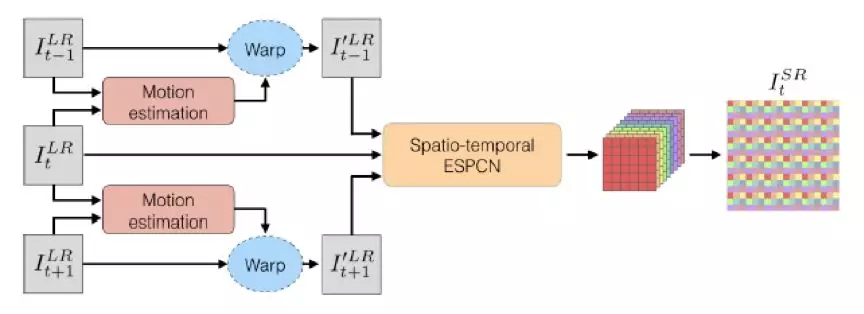
针对视频处理的超分辨率网络结构

实时网络
在效率上,不少研究者认为在浅层网络直接学习HR到HR的映射效率不高,因为浅层CNN可能很难掌握HR空间中的细节,更多的是LR空间便能学到的粗信息。因此一开始并不像SRCNN和VDSR那样先将ILR通过插值映射到HR空间,而是在最后几层通过转置卷积的方法将特征层上采样到HR空间。Twitter发表于CVPR2016上的工作ESPCN通过采用类似于固定参数的转置卷积层(称为Efficient Sub-pixel,或Depth to Space层),快速对特征层上采样,大受好评,其与相关变种后来被广泛应用于超分辨率网络。
不过,当前要想取得优良的输出质量仍然离不开大量的卷积层叠加,而超分辨率的运算维度又非常大,实时化运算仍然需要寻找新的突破口。
对抗生成
超分辨率是一个典型的非适定性(ill-posed)问题,LR到HR的映射具有高度不确定性,每一个LR输入都有大量的合理的HR与之对应,但是神经网络往往无法从这些合理HR集合中挑选出单一样本,而只能输出整个集合的统计期望(优化L2目标函数近似得到平均值),因此导致输出图像锐度消失。采用生成对抗网络(GAN)训练框架,有助于解决纹理缺失的问题。GAN是一个非常庞杂的问题,在超分辨率领域,主要依靠增加的对抗损失函数来指导生成网络训练,在经过仔细调参后,使生成网络输出接近训练集HR空间分布的图像,填充缺失的细节纹理。
论文整理
下面是前辈们吐血整理的paper list及awesome repos,来源于此,最后我将一些需要重点关注的文章及冠军论文都加粗显示,请留意。
Awesome paper list:
Single-Image-Super-Resolution
Super-Resolution.Benckmark
Video-Super-Resolution
VideoSuperResolution
Awesome repos:
| repo | Framework |
|---|---|
| EDSR-PyTorch | PyTorch |
| Image-Super-Resolution | Keras |
| image-super-resolution | Keras |
| Super-Resolution-Zoo | MxNet |
| super-resolution | Keras |
| neural-enhance | Theano |
| srez | Tensorflow |
| waifu2x | Torch |
| BasicSR | PyTorch |
| super-resolution | PyTorch |
| VideoSuperResolution | Tensorflow |
| video-super-resolution | Pytorch |
benchmark:https://github.com/huangzehao/Super-Resolution.Benckmark
DL based approach
Note this table is referenced from here
| Model | Published | Code | Keywords |
|---|---|---|---|
| SRCNN | ECCV14 | Keras | Kaiming |
| RAISR | arXiv | - | Google, Pixel 3 |
| ESPCN | CVPR16 | Keras | Real time/SISR/VideoSR |
| VDSR | CVPR16 | Matlab | Deep, Residual |
| DRCN | CVPR16 | Matlab | Recurrent |
| DRRN | CVPR17 | Caffe, PyTorch | Recurrent |
| LapSRN | CVPR17 | Matlab | Huber loss |
| IRCNN | CVPR17 | Matlab | |
| EDSR | CVPR17 | PyTorch | NTIRE17 Champion |
| BTSRN | CVPR17 | - | NTIRE17 |
| SelNet | CVPR17 | - | NTIRE17 |
| TLSR | CVPR17 | - | NTIRE17 |
| SRGAN | CVPR17 | Tensorflow | 1st proposed GAN |
| VESPCN | CVPR17 | - | VideoSR |
| MemNet | ICCV17 | Caffe | |
| SRDenseNet | ICCV17 | -, PyTorch | Dense |
| SPMC | ICCV17 | Tensorflow | VideoSR |
| EnhanceNet | ICCV17 | TensorFlow | Perceptual Loss |
| PRSR | ICCV17 | TensorFlow | an extension of PixelCNN |
| AffGAN | ICLR17 | - | |
| MS-LapSRN | TPAMI18 | Matlab | Fast LapSRN |
| DCSCN | arXiv | Tensorflow | |
| IDN | CVPR18 | Caffe | Fast |
| DSRN | CVPR18 | TensorFlow | Dual state,Recurrent |
| RDN | CVPR18 | Torch | Deep, BI-BD-DN |
| SRMD | CVPR18 | Matlab | Denoise/Deblur/SR |
| xUnit | CVPR18 | PyTorch | Spatial Activation Function |
| DBPN | CVPR18 | PyTorch | NTIRE18 Champion |
| WDSR | CVPR18 | PyTorch,TensorFlow | NTIRE18 Champion |
| ProSRN | CVPR18 | PyTorch | NTIRE18 |
| ZSSR | CVPR18 | Tensorflow | Zero-shot |
| FRVSR | CVPR18 | VideoSR | |
| DUF | CVPR18 | Tensorflow | VideoSR |
| TDAN | arXiv | - | VideoSR,Deformable Align |
| SFTGAN | CVPR18 | PyTorch | |
| CARN | ECCV18 | PyTorch | Lightweight |
| RCAN | ECCV18 | PyTorch | Deep, BI-BD-DN |
| MSRN | ECCV18 | PyTorch | |
| SRFeat | ECCV18 | Tensorflow | GAN |
| TSRN | ECCV18 | Pytorch | |
| ESRGAN | ECCV18 | PyTorch | PRIM18 region 3 Champion |
| EPSR | ECCV18 | PyTorch | PRIM18 region 1 Champion |
| PESR | ECCV18 | PyTorch | ECCV18 workshop |
| FEQE | ECCV18 | Tensorflow | Fast |
| NLRN | NIPS18 | Tensorflow | Non-local, Recurrent |
| SRCliqueNet | NIPS18 | - | Wavelet |
| CBDNet | arXiv | Matlab | Blind-denoise |
| TecoGAN | arXiv | Tensorflow | VideoSR GAN |
| RBPN | CVPR19 | PyTorch | VideoSR |
| SRFBN | CVPR19 | PyTorch | Feedback |
| MoreMNAS | arXiv | - | Lightweight,NAS |
| FALSR | arXiv | TensorFlow | Lightweight,NAS |
| Meta-SR | arXiv | Arbitrary Magnification | |
| AWSRN | arXiv | PyTorch | Lightweight |
| OISR | CVPR19 | PyTorch | ODE-inspired Network |
| DPSR | CVPR19 | PyTorch | |
| DNI | CVPR19 | PyTorch | |
| MAANet | arXiv | Multi-view Aware Attention | |
| RNAN | ICLR19 | PyTorch | Residual Non-local Attention |
| FSTRN | CVPR19 | - | VideoSR, fast spatio-temporal residual block |
| MsDNN | arXiv | TensorFlow | NTIRE19 real SR 21th place |
| SAN | CVPR19 | Pytorch | Second-order Attention,cvpr19 oral |
| EDVR | CVPR19 | Pytorch | Video, NTIRE19 video restoration and enhancement champions |
| Ensemble for VSR | CVPR19 | - | VideoSR, NTIRE19 video SR 2nd place |
| TENet | arXiv | Pytorch | a Joint Solution for Demosaicking, Denoising and Super-Resolution |
| MCAN | arXiv | Pytorch | Matrix-in-matrix CAN, Lightweight |
| IKC&SFTMD | CVPR19 | - | Blind Super-Resolution |
文章速览
WDSR(2018 best),来自UIUC的华人学生JiaHui Yu的论文。在SR界有一个比赛,叫做NTIRE,从2016年以来也才举办三届,不过自2017年开始,NTIRE就逐渐被全球学者所关注。NTIRE的冠军基本是保送CVPR的,NTIRE成长为SR界的COCO也是指日可待的。
NTIRE2018链接:http://www.vision.ee.ethz.ch/ntire18/
而WDSR就恰好是NTIRE2018的冠军,所以,目前看来WDSR就是SR界的state-of-the-art。WDSR文章目前只是挂在arxiv上,未来也许会发表在CVPR2019或ICCV2019上,所以,我们可以在论文正式发表之前了解到这篇优质算法。
在这里正式对WDSR算法进行剖析。这里的W表示的是wide,即具有更宽泛的特征图。怎么理解更宽泛的特征图呢?作者对激活函数之前的特征图channel数增多,称为特征图更宽泛。这个描述怪怪的,不过就是这么个意思。
很多同学会认为SR算法一般会跟生成式算法GAN产生联系,然而事实并不是这样。确实有利用GAN来做SR的,不过目前顶尖的SR算法都是基于CNN的,WDSR也不例外。WDSR是基于CNN的SR算法。
为什么基于CNN能做到SR?这个疑问先留在这里,待会儿好好解答。
基于CNN的SR算法自2014年何恺明大神的SRCNN以来,逐渐发展成如今的SR,具有四大法宝:
1. 上采样方法。我们从低分辨率图像转换到高分辨率图像,是不是要涉及上采样呢?100x100到400x400肯定要涉及上采样方法的。如果研究过自编码器等算法的同学会知道反卷积是图像深度学习种常用的上采样方法,在yolo v3中用到的上采样方法也是反卷积。事实上,反卷积这种上采样方法在目前一线的SR算法中是遭到鄙视的(虽然SOD-MTGAN中还在用)。不用反卷积用什么呢,有一种叫做pixel shuffle的新型卷积方法在CVPR2016年被提出来,也叫做sub-pixel convolution。这种新型卷积就是为SR量身定做的,如果想要详细了解这种卷积是如何操作的,请戳《pixel shuffle》,这也解释了为什么目前基于CNN的SR能比基于GAN效果更好了;
2. 超级深度&循环神经网络。神经网络深度的重要性相比无须多言了,在不少前辈们的研究成果表现,神经网络的深度是影响SR算法性能的关键因素之一。同时,利用循环神经网络的方法,可以增加权重的复用性。WDSR并没有用到RNN,可以跳过这个;
3. 跳跃连接。就如果Resnet做的那样,将前层输出与深层输出相加连接。一来呢,可以有效解决反向传播的梯度弥散,二来呢,可以有效利用浅层特征信息。目前的一线SR算法都会含有resblocks,WDSR也不例外。
4. 标准化层。BN层已经是说烂了的trick之一了,各种算法似乎都离不开BN。但batch normalization也不是唯一的normalization方法。如我其他博文中提到的LN,IN还有kaiming大神提出的GN。而WDSR算法采用了weight normalization的方法。对标准化层不熟悉的同学可以看我以前的文章《Batch Normalization》。
基于上面四个trick,作者提出了WDSR-A模型结构,我们可以看看长什么样子:
![]()
左边的EDSR呢,是NTIRE2017的冠军,自然要被2018的冠军吊打的。我们直接看右边,网络结构是超级简单的, residual body就是一系列的resblock组到一起,可以看作是一个自带激活函数的非线性卷积模块。上图的模块只包含三种:res模块,conv模块和pixel shuffle模块。只有pixel shuffle模块要特别注意。
WDSR在EDSR上的结构提升,一方面是去除了很多冗余的卷积层,这样计算更快。另一方面是改造了resblock。我们一分为二来看,去除冗余的卷积层(如上图阴影部分)作者认为这些层的效果是可以吸收到resbody里面的,通过去除实验之后,发现效果并没有下降,所以去除冗余卷积层可以降低计算开销。
改造resblock的方法如下:
![]()
左图呢就是ESDR的原始resblock,中间是WDSR-A,右边的是WDSR-B。作者在文中提出了两个版本的WDSR,这两个版本的区别就是resblock不同而已。 对于EDSR中的resblock,我们成为原始resblock,relu是在两个卷积运算中间,而且卷积核的filter数较少;而WDSR-A是在不增加计算开销的前提下,增加relu前卷积核的filter数以增加feature map的宽度。怎么理解这个操作呢?我们有神器neutron,用neutron分别打开ESDR和WDSR的结构图我们可以看到:
![]()
上图左边就是ESDR,右边就是WDSR-A。我们可以从relu前卷积核的filter数看到, 后者(192)是前者(64)的3倍。不过前者在relu后的filter数是后者的2倍。作者主要提的trick就是增加激活函数前的特征图的channel数。这样效果会更好。同样,我们可以对WDSR-B一目了然:
![]()
WDSR-B进一步解放了计算开销,将relu后的大卷积核拆分成两个小卷积核,这样可以在同样计算开销的前提下获得更宽泛的激活函数前的特征图(即channel数可以更多)。
所以,对于同样计算开销的前提下,表现性能是:WDSR-B > WDSR-A > ESDR。
Weight Normalization vs Batch Normalization
WN应该算是WDSR的最后一个重要的trick了。WN来自openAI在NIPS2016发表的一篇文章,就是将权重进行标准化。
![]()
对于WN我只是粗略了解,做一个简单的||v||表示v的欧几里得范数,w, v都是K维向量,而g=||w||,是一个标量。w是v的次态。 g/||v||这个标量就是为了线性改变向量v,从而使得||w||更靠近g。这样来使得权重w的值在一个规范的范围内。注意,WN和BN的操作有很大的不同。
根据作者的实验表明,WN可以用更高的学习率(10倍以上),而且可以获得更好的训练和测试准确率。
![]()
附:
超级分辨率资源的精选列表
参考文献:
1.https://blog.csdn.net/leviopku/article/details/85048846
2.http://www.sohu.com/a/257091617_100206743
3.https://blog.csdn.net/gwplovekimi/article/details/83041627#SRCNN%EF%BC%88Super-Resolution%20Convolutional%20Neural%20Network%EF%BC%89
4.
基于深度学习的图像超分论文推荐相关推荐
- 深度学习图像融合_基于深度学习的图像超分辨率最新进展与趋势【附PDF】
因PDF资源在微信公众号关注公众号:人工智能前沿讲习回复"超分辨"获取文章PDF 1.主题简介 图像超分辨率是计算机视觉和图像处理领域一个非常重要的研究问题,在医疗图像分析.生物特 ...
- 深度学习磁共振图像超分与重建论文阅读
深度学习磁共振图像超分与重建算法研究 Super-resolution reconstruction of MR image with a novel residual learning networ ...
- 学习笔记之——基于深度学习的图像超分辨率重建
最近开展图像超分辨率( Image Super Resolution)方面的研究,做了一些列的调研,并结合本人的理解总结成本博文~(本博文仅用于本人的学习笔记,不做商业用途) 本博文涉及的paper已 ...
- 基于深度学习的图像超分辨率重建
最近开展图像超分辨率( Image Super Resolution)方面的研究,做了一些列的调研,并结合本人的理解总结成本博文~(本博文仅用于本人的学习笔记,不做商业用途) 本博文涉及的paper已 ...
- 基于深度学习的图像超分辨率——综述
2021-Deep Learning for Image Super-resolution:A Survey 基本信息 作者: Zhihao Wang, Jian Chen, Steven C.H. ...
- 基于深度学习的图像超分辨率方法 总结
基于深度学习的SR方法 懒得总结,就从一篇综述中选取了一部分基于深度学习的图像超分辨率方法. 原文:基于深度学习的图像超分辨率复原研究进展 作者:孙旭 李晓光 李嘉锋 卓力 北京工业大学信号与信息处理 ...
- 基于深度学习的图像超分辨率重建技术的研究
1 超分辨率重建技术的研究背景与意义 图像分辨率是一组用于评估图像中蕴含细节信息丰富程度的性能参数,包括时间分辨率.空间分辨率及色阶分辨率等,体现了成像系统实际所能反映物体细节信息的能力.相较于低分辨 ...
- 《深度学习》图像超分初识
一:简介 图像超分(super-Resolution)是将低分辨率的图像或者视频序列恢复出高分辨率图像. 可以用在视频数字高清播放,视频监控,视频编码,图像还原和医学影像等领域,按照类别可分为单个图像 ...
- 经典论文复现 | 基于深度学习的图像超分辨率重建
过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含"伪代码".这是今年 AAAI ...
- SRCNN-基于深度学习的图像超分入门
图像超分 图像超分辨率问题定义: 输入一张低分辨率图像时(low resolution,LR),通过算法,输出一张高分辨率图像(high resolution,HR) 传统的图像插值算法可以在某种程度 ...
最新文章
- 据说电脑上可以刷朋友圈啦!又多了个上班摸鱼的途径?
- oracle ora 47306,Oracle SQL提示含义与示例 --- 分布式查询和并行提示
- 2016全球可再生能源投资额为2416亿美元
- OS X上搭建distcc使用XCode进行分布式编译
- 微软全球执行副总裁沈向洋:人工智能的机遇和挑战
- Struts2类型转换--浪曦视频第三讲
- 人工智能民主化无关紧要,数据孤岛以及如何建立一家AI公司
- CCF推荐期刊/会议历年发表论文数据库:CCF Rec-Paper DB
- 捷联惯导系统模型及仿真(三)
- html+移动端图片点击放大,移动端点击图片放大特效PhotoSwipe.js插件实现
- execute()方法
- 【三环集团logo】用Python 小海龟实现~
- 精彩回顾 | Dev.Together 2022 开发者生态峰会圆满落幕
- python 麻将算胡,快速算法 没有递归,不超过100行
- 手机怎么把图片制作成短视频,原来还有这种傻瓜式的操作,长知识了
- 书到用时方恨少? 整理了一份初中、高中数学教材pdf 百度云
- 风暴魔域怎么在电脑上玩 风暴魔域电脑版玩法教程
- sql数据删除后恢复
- 运动耳机有什么好处,五款好用的运动蓝牙耳机分享
- 使用cpolar发布群晖NAS上的网页(2)