利用好手头的资源解决海量语料资源收集以及利用哈工大的LTP云平台解决依存句法和语义依存分析
一、利用好手头的资源解决海量语料资源
基于语料做机器学习需要海量数据支撑,如何能不存一点数据获取海量数据呢?我们可以以互联网为强大的数据后盾,搜索引擎为我们提供了高效的数据获取来源,结构化的搜索结果展示为我们实现了天然的特征基础,唯一需要我们做的就是在海量结果中选出我们需要的数据,本节我们来探索如何利用互联网拿到我们所需的语料资源
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
关键词提取
互联网资源无穷无尽,如何获取到我们所需的那部分语料库呢?这需要我们给出特定的关键词,而基于问句的关键词提取上一节已经做了介绍,利用pynlpir库可以非常方便地实现关键词提取,比如:
# coding:utf-8import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )import pynlpirpynlpir.open()
s = '怎么才能把电脑里的垃圾文件删除'key_words = pynlpir.get_key_words(s, weighted=True)
for key_word in key_words:print key_word[0], '\t', key_word[1]pynlpir.close()提取出的关键词如下:
电脑 2.0
垃圾 2.0
文件 2.0
删除 1.0我们基于这四个关键词来获取互联网的资源就可以得到我们所需要的语料信息
充分利用搜索引擎
有了关键词,想获取预料信息,还需要知道几大搜索引擎的调用接口,首先我们来探索一下百度,百度的接口是这样的:
https://www.baidu.com/s?wd=机器学习 数据挖掘 信息检索
把wd参数换成我们的关键词就可以拿到相应的结果,我们用程序来尝试一下:
首先创建scrapy工程,执行:
scrapy startproject baidu_search自动生成了baidu_search目录和下面的文件(不知道怎么使用scrapy,请见我的文章教你成为全栈工程师(Full Stack Developer) 三十-十分钟掌握最强大的python爬虫)
创建baidu_search/baidu_search/spiders/baidu_search.py文件,内容如下:
# coding:utf-8import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )import scrapyclass BaiduSearchSpider(scrapy.Spider):name = "baidu_search"allowed_domains = ["baidu.com"]start_urls = ["https://www.baidu.com/s?wd=机器学习"]def parse(self, response):print response.body
这样我们的抓取器就做好了,进入baidu_search/baidu_search/目录,执行:
scrapy crawl baidu_search我们发现返回的数据是空,下面我们修改配置来解决这个问题,修改settings.py文件,把ROBOTSTXT_OBEY改为
ROBOTSTXT_OBEY = False并把USER_AGENT设置为:
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'为了避免抓取hang住,我们添加如下超时设置:
DOWNLOAD_TIMEOUT = 5再次执行
scrapy crawl baidu_search这次终于可以看到大片大片的html了,我们临时把他写到文件中,修改parse()函数如下:
def parse(self, response):filename = "result.html"with open(filename, 'wb') as f:f.write(response.body)重新执行后生成了result.html,我们用浏览器打开本地文件如下:

说明我们抓取到了正确的结果
语料提取
上面得到的仅是搜索结果,它只是一种索引,真正的内容需要进入到每一个链接才能拿到,下面我们尝试提取出每一个链接并继续抓取里面的内容,那么如何提取链接呢,我们来分析一下result.html这个抓取百度搜索结果文件

我们可以看到,每一条链接都是嵌在class=c-container这个div里面的一个h3下的a标签的href属性
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
所以我们的提取规则就是:
hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract()修改parse()函数并添加如下代码:
hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract()for href in hrefs:print href执行打印出:
……
2016-06-30 09:22:51 [scrapy] DEBUG: Crawled (200) <GET https://www.baidu.com/s?wd=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0> (referer: None)
http://www.baidu.com/link?url=ducktBaLUAdceZyTkXSyx3nDbgLHoYlDVgAGlxPwcNNrOMQrbatubNKGRElo0VWua26AC7JRD2pLxFcaUBjcOq
http://www.baidu.com/link?url=PGU6qW3zUb9g5uMT3W1O4VxPmoH-Fg-jolx8rBmBAeyOuXUl0wHzzNPkX3IDS5ZFSSSHyaBTjHd5f2r8CXBFjSctF9SGKaVock5xaJNuBCy
http://www.baidu.com/link?url=JMirHAkIRJWI_9Va7HNc8zXWXU7JeTYhPGe66cOV4Zi5LH-GB7IQvVng4Gn35IiVhsUYP3IFyn6MKRl4_-byca
http://www.baidu.com/link?url=Et9xy9Qej4XRmLB9UdFUlWD_AugxoDxQt-BZHCFyZEDPYzEx52vL_jsr_AvkNLHC-TfLThm0dKs21IGR1QA6h_
http://www.baidu.com/link?url=Ajb1DXzWj9A6KAYicHl4wS4RV6iDuy44kP_j-G0rbOHYQy5IR5JOigxbJERsqyH3
http://www.baidu.com/link?url=uRDMnVDsmS7sD4frNv8EHd2jKSvOB5PtqxeT8Q7MFzRyHPIVTYyiWEGNReHAbRymMnWOxqF_CSQOXL87v3o4qa
http://www.baidu.com/link?url=18j6NZUp8fknmM1nUYIfsmep5H0JD39k8bL7CkACFtKdD4whoTuZy0ZMsCxZzZOj
http://www.baidu.com/link?url=TapnMj78otilz-AR1NddZCSfG2vqcPYGNCYRu9_z70rmAKWqIVAvjV06iJvcvuECGDbwAefdsAmGRHba6TDpFMV1Pk-_JRs_bt9iE4T3bVi
http://www.baidu.com/link?url=b1j-GMumC7s5eDXTHIMPpsdL7HtxrP4Rb_kw0GNo3z2ZSlkhLVd_4aFEzflPGArPHv7VBtZ1xbyHo3JtG0PEZq
http://www.baidu.com/link?url=dG3GISijkExWf6Sy6Zn1xk_k--eGPUl1BrTCLRBxUOaS4jlrpX-PzV618-5hrCeos2_Rzaqrh0SecqYPloZfbyaj6wHSfbJHG9kFTvY6Spi
2016-06-30 09:22:51 [scrapy] INFO: Closing spider (finished)
……下面我们把这些url添加到抓取队列中继续抓取,修改baidu_search.py文件,如下:
def parse(self, response):hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract()for href in hrefs:yield scrapy.Request(href, callback=self.parse_url)def parse_url(self, response):print len(response.body)抓取效果如下:
……
2016-06-30 09:26:52 [scrapy] DEBUG: Crawled (200) <GET https://www.baidu.com/s?wd=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0> (referer: None)
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://book.douban.com/subject/1102235/> from <GET http://www.baidu.com/link?url=S1kmtqU1ZBDaSKlVXdeKfNtyv7fErWDMC_TuOEXdedXEe2DzoMqRbMdbejbC4vts4MHm5NQUIRbk0Y0QdohY5_>
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://www.kuqin.com/shuoit/20140512/339858.html> from <GET http://www.baidu.com/link?url=_6fKf9IjO_EJ4hw91Y6RnfXnqS5u8VmwvDsJh3tduapsgXKQb-nMjsxMRPLW1bt5JlnzJPgOobHQwyHTgkWolK>
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://wenku.baidu.com/link?url=7pAXoiFZz4alDMOjp-41OJaONe3B86GMEiFu96bqQy8qakk37vouey5Q-SxL7oN-r9mnNukKgVjN8iOloEKQoeEmgKLzukIFkX_rpr3dhy3> from <GET http://www.baidu.com/link?url=7pAXoiFZz4alDMOjp-41OJaONe3B86GMEiFu96bqQy8qakk37vouey5Q-SxL7oN-r9mnNukKgVjN8iOloEKQoeEmgKLzukIFkX_rpr3dhy3>
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://blog.csdn.net/zouxy09/article/details/16955347> from <GET http://www.baidu.com/link?url=5dh-19wDKE_agNpwz_9YTm01wHLJ9IxBfrZPVWo6RfFECGmIW7bt0vk6POhWDN04O4QHem_v8-iYLTzoeXmQZK>
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://open.163.com/special/opencourse/machinelearning.html> from <GET http://www.baidu.com/link?url=ti__XlRN8Oij0rFvqxfTtJz-dLhng6NANkAVwwISlHQ4nKOhRXNSJQhzekflnnFuuW5033lDRcqywOlqrzoANUhB0yQf3Nq-pXMWmBQO7x7>
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://www.guokr.com/group/262/> from <GET http://www.baidu.com/link?url=cuifybqWoLRMULYGe70JCzyrZMEKL9GgfAa6V7p_7ONb7Q6KzXPad5zMfIYsKqN6>
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://mooc.guokr.com/course/16/Machine-Learning/> from <GET http://www.baidu.com/link?url=93Yp_GA3ZLnSwjN5YREAML4sP5BthETto8Psn7ty5VJHoMB95gWhKTT6iDBFHeAfHjDhqwCf-NBrgeoP7YD1zq>
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://tieba.baidu.com/f?kw=%BB%FA%C6%F7%D1%A7%CF%B0&fr=ala0&tpl=5> from <GET http://www.baidu.com/link?url=EjCvUWhJWV1_FEgNyetjTAu6HqImgl-A2229Lp8Kl3BfpcqlrSLOUabc-bzgn6KD1Wbg_s547FunrFp79phQTqXuIx6tkn9NGBhSqxhYUhm>
2016-06-30 09:26:52 [scrapy] DEBUG: Redirecting (302) to <GET http://www.geekpark.net/topics/213883/> from <GET http://www.baidu.com/link?url=kvdmirs22OQAj10KSbGstZJtf8L74bTgd4p1AxYk6c2B9lP_8_nSrLNDlfb9DHW7>
……看起来能够正常抓取啦,下面我们把抓取下来的网页提取出正文并尽量去掉标签,如下:
def parse_url(self, response):print remove_tags(response.selector.xpath('//body').extract()[0])下面,我们希望把百度搜索结果中的摘要也能够保存下来作为我们语料的一部分,如下:
def parse(self, response):hrefs = response.selector.xpath('//div[contains(@class, "c-container")]/h3/a/@href').extract()containers = response.selector.xpath('//div[contains(@class, "c-container")]')for container in containers:href = container.xpath('h3/a/@href').extract()[0]title = remove_tags(container.xpath('h3/a').extract()[0])c_abstract = container.xpath('div/div/div[contains(@class, "c-abstract")]').extract()abstract = ""if len(c_abstract) > 0:abstract = remove_tags(c_abstract[0])request = scrapy.Request(href, callback=self.parse_url)request.meta['title'] = titlerequest.meta['abstract'] = abstractyield requestdef parse_url(self, response):print "url:", response.urlprint "title:", response.meta['title']print "abstract:", response.meta['abstract']content = remove_tags(response.selector.xpath('//body').extract()[0])print "content_len:", len(content)解释一下,首先我们在提取url的时候顺便把标题和摘要都提取出来,然后通过scrapy.Request的meta传递到处理函数parse_url中,这样在抓取完成之后也能接到这两个值,然后提取出content,这样我们想要的数据就完整了:url、title、abstract、content
百度搜索数据几乎是整个互联网的镜像,所以你想要得到的答案,我们的语料库就是整个互联网,而我们完全借助于百度搜索引擎,不必提前存储任何资料,互联网真是伟大!
之后这些数据想保存在什么地方就看后面我们要怎么处理了,欲知后事如何,且听下面分解
二、利用哈工大的LTP云平台解决依存句法和语义依存分析
句法分析是自然语言处理中非常重要的环节,没有句法分析是无法让计算机理解语言的含义的,依存句法分析由法国语言学家在1959年提出,影响深远,并且深受计算机行业青睐,依存句法分析也是做聊天机器人需要解决的最关键问题之一,语义依存更是对句子更深层次的分析,当然,有可用的工具我们就不重复造轮子,本节介绍如何利用国内领先的中文语言技术平台实现句法分析
什么是依存句法分析呢?
叫的晦涩的术语,往往其实灰常简单,句法就是句子的法律规则,也就是句子里成分都是按照什么法律规则组织在一起的。而依存句法就是这些成分之间有一种依赖关系。什么是依赖:没有你的话,我存在就是个错误。“北京是中国的首都”,如果没有“首都”,那么“中国的”存在就是个错误,因为“北京是中国的”表达的完全是另外一个意思了。
什么是语义依存分析呢?
“语义”就是说句子的含义,“张三昨天告诉李四一个秘密”,那么语义包括:谁告诉李四秘密的?张三。张三告诉谁一个秘密?李四。张三什么时候告诉的?昨天。张三告诉李四什么?秘密。
语义依存和依存句法的区别
依存句法强调介词、助词等的划分作用,语义依存注重实词之间的逻辑关系
另外,依存句法随着字面词语变化而不同,语义依存不同字面词语可以表达同一个意思,句法结构不同的句子语义关系可能相同。
依存句法分析和语义依存分析对我们的聊天机器人有什么意义呢?
依存句法分析和语义分析相结合使用,对对方说的话进行依存和语义分析后,一方面可以让计算机理解句子的含义,从而匹配到最合适的回答,另外如果有已经存在的依存、语义分析结果,还可以通过置信度匹配来实现聊天回答。
依存句法分析到底是怎么分析的呢?
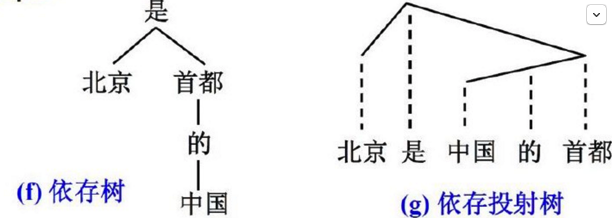
依存句法分析的基本任务是确定句式的句法结构(短语结构)或句子中词汇之间的依存关系。依存句法分析最重要的两棵树:
依存树:子节点依存于父节点
依存投射树:实线表示依存联结关系,位置低的成分依存于位置高的成分,虚线为投射线
依存关系的五条公理
1. 一个句子中只有一个成分是独立的
2. 其他成分直接依存于某一成分
3. 任何一个成分都不能依存于两个或两个以上的成分
4. 如果A成分直接依存于B成分,而C成分在句子中位于A和B之间,那么C或者直接依存于B,或者直接依存于A和B之间的某一成分
5. 中心成分左右两面的其他成分相互不发生关系
什么地方存在依存关系呢?比如合成词(如:国内)、短语(如:英雄联盟)很多地方都是
LTP依存关系标记
|
主谓关系 |
SBV |
subject-verb |
我送她一束花 (我 <-- 送) |
|
动宾关系 |
VOB |
直接宾语,verb-object |
我送她一束花 (送 --> 花) |
|
间宾关系 |
IOB |
间接宾语,indirect-object |
我送她一束花 (送 --> 她) |
|
前置宾语 |
FOB |
前置宾语,fronting-object |
他什么书都读 (书 <-- 读) |
|
兼语 |
DBL |
double |
他请我吃饭 (请 --> 我) |
|
定中关系 |
ATT |
attribute |
红苹果 (红 <-- 苹果) |
|
状中结构 |
ADV |
adverbial |
非常美丽 (非常 <-- 美丽) |
|
动补结构 |
CMP |
complement |
做完了作业 (做 --> 完) |
|
并列关系 |
COO |
coordinate |
大山和大海 (大山 --> 大海) |
|
介宾关系 |
POB |
preposition-object |
在贸易区内 (在 --> 内) |
|
左附加关系 |
LAD |
left adjunct |
大山和大海 (和 <-- 大海) |
|
右附加关系 |
RAD |
right adjunct |
孩子们 (孩子 --> 们) |
|
独立结构 |
IS |
independent structure |
两个单句在结构上彼此独立 |
|
核心关系 |
HED |
head |
指整个句子的核心 |
请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址
那么依存关系是怎么计算出来的呢?
是通过机器学习和人工标注来完成的,机器学习依赖人工标注,那么都哪些需要我们做人工标注呢?分词词性、依存树库、语义角色都需要做人工标注,有了这写人工标注之后,就可以做机器学习来分析新的句子的依存句法了
LTP云平台怎么用?
首先注册用户,得到每月免费20G的流量,在http://www.ltp-cloud.com/注册一个账号,注册好后登陆并进入你的dashboard:http://www.ltp-cloud.com/dashboard/,可以看到自己唯一的api_key,我的保密,就不贴出来了,在dashboard里还可以查询自己流量使用情况
具体使用方法如下(参考http://www.ltp-cloud.com/document):
curl -i "http://api.ltp-cloud.com/analysis/?api_key=YourApiKey&text=我是中国人。&pattern=dp&format=plain"把这里的YourApiKey换成你自己的api_key,得到结果如下:
我_0 是_1 SBV
是_1 -1 HED
中国_2 人_3 ATT
人_3 是_1 VOB
。_4 是_1 WP通过这个接口修改pattern参数可以做很多工作,比如:
分词(pattern=ws):
GET http://api.ltp-cloud.com/analysis/?api_key=YourApiKey&text=我是中国人。&pattern=ws&format=plain
我 是 中国 人 。词性标注(pattern=pos):
GET http://api.ltp-cloud.com/analysis/?api_key=YourApiKey&text=我是中国人。&pattern=pos&format=plain
我_r 是_v 中国_ns 人_n 。_wp命名实体识别(pattern=ner):
GET http://api.ltp-cloud.com/analysis/?api_key=YourApiKey&text=我是中国人。&pattern=ner&format=plain
我 是 [中国]Ns 人 。语义依存分析(pattern=sdp):
GET http://api.ltp-cloud.com/analysis/?api_key=YourApiKey&text=我是中国人。&pattern=sdp&format=plain
我_0 是_1 Exp
是_1 -1 Root
中国_2 人_3 Nmod
人_3 是_1 Clas
。_4 是_1 mPunc语义角色标注(pattern=srl):
GET http://api.ltp-cloud.com/analysis/?api_key=YourApiKey&text=我是中国人。&pattern=srl&format=plain
[我]A0 [是]v [中国 人]A1 。免费终究会有限制,无论是流量还是速度还是一次性分析文本大小,LTP平台有有一定限制,这也是可以理解的,毕竟为大家开放了科研必备的资源和技术,成本也是需要控制的。
利用好手头的资源解决海量语料资源收集以及利用哈工大的LTP云平台解决依存句法和语义依存分析相关推荐
- 温湿度监测云平台—解决异地仓储与集团总部远程温湿度监控难题
物联网.云计算.大数据,可能是最近几年比较火的技术名词,万物互联.云端互通在各行各业得到快速发展. 在过去,温湿度监控系统主要是部署在企业本地计算机,根据监测对象的环境不用,选择通过网线.GPRS.4 ...
- 使用 Velero 跨云平台迁移集群资源到 TKE
作者:李全江(jokey),腾讯云工程师,热衷于云原生领域.目前主要负责腾讯云 TKE 的售中.售后的技术支持,根据客户需求输出合理技术方案与最佳实践. 概述 Velero 是一个非常强大的开源工具, ...
- 计算机及服务器硬件统计表,云平台与传统平台资源交付场景研究
李云鹏 乔林 陈硕 摘 要:云计算技术是一种新兴的计算模型.云计算主要以廉价X86架构PC服务器为硬件平台,大量使用虚拟化技术.分布式计算技术.分布式存储技术对外提供计算存储服务,满足用户需求.较为主 ...
- 阿里云发布黑科技:面对海量的文本翻译任务,阿里翻译团队是如何解决的
对国际化企业来说语言问题是亟待突破的重要关口.面对海量的文本翻译任务,昂贵低效的人工翻译显然不能满足需求,利用计算机自动进行文本翻译的机器翻译才是解决这个问题的关键.阿里翻译团队在机器翻译领域做了大量 ...
- 黑科技揭秘:面对海量的文本翻译任务,阿里翻译团队是如何解决的
对国际化企业来说语言问题是亟待突破的重要关口.面对海量的文本翻译任务,昂贵低效的人工翻译显然不能满足需求,利用计算机自动进行文本翻译的机器翻译才是解决这个问题的关键.阿里翻译团队在机器翻译领域做了大量 ...
- 黑科技揭秘:面对海量的文本翻译任务,阿里翻译团队是如何解决的 1
摘要: 对国际化企业来说语言问题是亟待突破的重要关口.面对海量的文本翻译任务,昂贵低效的人工翻译显然不能满足需求,利用计算机自动进行文本翻译的机器翻译才是解决这个问题的关键.阿里翻译团队在机器翻译领域 ...
- 开发者必看!探秘阿里云Hi购季开发者分会场:海量学习资源0元起!
2019阿里云云上Hi购季活动已经于2月25日正式开启,从已开放的活动页面来看,活动分为三个阶段: 2月25日-3月04日的活动报名阶段.3月04日-3月16日的新购满返+5折抢购阶段.3月16日- ...
- python正则匹配找到所有的浮点数_如何利用Python抓取静态网站及其内部资源
遇到的需求 前段时间需要快速做个静态展示页面,要求是响应式和较美观.由于时间较短,自己动手写的话也有点麻烦,所以就打算上网找现成的. 中途找到了几个页面发现不错,然后就开始思考怎么把页面给下载下来. ...
- Day 09 - Amazon Linux 2 上解决跨来源资源共用 (CORS) 与开机自动启动 uwsgi
Day 09 - Amazon Linux 2 上解决跨来源资源共用 (CORS) 与开机自动启动 uwsgi 在应用的后端,我们已经解决了以下几个问题: 资料库存取: MariaDB. RESTfu ...
最新文章
- Linux IO多路复用之Select简史
- Docker 不香吗,为啥还要 K8s?
- View Transform(视图变换)详解
- PageRequestManagerServerError
- UML建模工具EA和Rose比较
- servlet请求和响应的过程
- The connection to adb is down, and a severe error has occured.问题解决方法小结
- vista 中php4, php5 共存
- CAP 3.0 版本正式发布
- adf开发_了解ADF生命周期中的ADF绑定
- Tomacat服务器的安装和配置
- TVM:在树莓派上部署预训练的模型
- Spark基础学习笔记02:Spark运行时架构
- 详解ISA2006的三种客户端模式
- Tensorflow:模型调参
- 1.业务层 、服务层、数据层、表现层
- UOS U盘复制性能,3M
- PDMS开发使用的pml界面设计器
- 离散数学真值表c语言实验报告,NJUPT【离散数学】实验报告
- C C++编程子资料库(小程序)
热门文章
- Mac - 苹果电脑mac系统释放硬盘空间方法汇总
- iOS Emoji表情编码/解码
- jQuery全屏滚动插件fullPage.js
- 感觉又学到了不少,在这里写下来,但也有一个问题,不知道是为甚吗?
- virtualbox 启动时报Kernel driver not installed (rc=-1908) 的错误
- python可视化报表制作教程_如何使用Python快速制作可视化报表
- ArrayList的使用
- oracle 数据库字段html显示正常text显示不全,layui表格字段表格显示不全(自适应)...
- rocketmq删除topic_RocketMq 快速入门教程
- 互联网晚报 | 4月17日 星期天 | 滴滴2021年第四季度收入同比下降;以岭药业表示世卫从未推荐连花清瘟;上海有序复工复产...