GAN原始论文翻译及相关推导
参考博客:https://blog.csdn.net/stalbo/article/details/79283399
0、摘要
GAN提出了一个通过对抗过程估计生成模型的新框架,在新框架中同时训练两个模型:一个用来捕获数据分布的生成模型G,和一个用来估计样本来自训练数据而不是G的概率的判别模型D,G的训练过程是最大化D产生错误的概率。这个框架相当于一个极小极大化的双方博弈。在任意函数G 和D 的空间中存在唯一的解,其中G恢复训练数据分布,并且D处处都等于1/2 。 在G和D 由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间不需要任何马尔科夫链或展开的近似推理网络。 实验通过对生成的样品进行定性和定量评估来展示这个框架的潜力。
符号说明:
![]() →真实数据(groundtruth)
→真实数据(groundtruth)
![]() →真实数据的分布
→真实数据的分布
![]() →噪音
→噪音
![]() →原始噪音的分布
→原始噪音的分布
![]() →经过生成器后的数据分布
→经过生成器后的数据分布
![]() →生成映射函数,
→生成映射函数,![]() 代表生成器,结构为一个多层感知机,参数为
代表生成器,结构为一个多层感知机,参数为 ![]() ,
,为生成映射函数,将噪音
![]() 映射到新的数据空间。
映射到新的数据空间。
![]() →判别映射函数,
→判别映射函数,![]() 代表判别器,也是一个多层感知机,参数为
代表判别器,也是一个多层感知机,参数为 ![]() ,
,输出为一个标量,表示
![]() 来自真实数据
来自真实数据![]() 而不是生成数据的概率。
而不是生成数据的概率。
1、介绍
深度学习的任务是寻找丰富的层次模型,能够在人工智能领域里用来表达各种数据的概率分布,例如自然图像,包含语音的音频波形和自然语言语料库中的符号等。到目前为止,在深度学习领域,目前为止最成功的模型之一就是判别式模型,通常它们将高维丰富的特征表示输入映射到类别标签上。这些显著的成功主要是基于反向传播和丢弃(dropout)算法来实现的,特别是具有特别良好梯度的分段线性单元。由于在最大似然估计和相关策略中出现的许多难以解决的概率计算的困难,以及很难利用在生成上下文中时使用分段线性单元的好处,深度生成模型的影响很小。我们提出一个新的生成模型估计程序,来分步处理这些难题。
在提到的对抗网络框架中,生成模型对抗着一个对手:一个学习去判别一个样本是来自模型分布还是数据分布的判别模型。生成模型可以被认为是一个伪造团队,试图产生假货并在不被发现的情况下使用它,而判别模型类似于警察,试图检测假币。在这个游戏中的竞争驱使两个团队改进他们的方法,直到真假难分为止。
这个框架可以针对多种模型和优化算法提供特定的训练算法。在这篇文章中,我们探讨了生成模型通过将随机噪声传输到多层感知机来生成样本的特例,同时判别模型也是通过多层感知机实现的。我们称这个特例为对抗网络。在这种情况下,我们可以仅使用非常成熟的反向传播和丢弃算法训练两个模型,生成模型在生成样本时只使用前向传播算法。并且不需要近似推理和马尔可夫链作为前题。
2、相关工作
含隐变量的有向图模型可以由含隐变量的无向图模型替代,例如受限制波兹曼机(RBM),深度波兹曼机(DBM)和它们很多的变种。这些模型之间的相互影响可以被表达为非标准化的势函数的乘积,再通过随机变量的所有状态的全局整合来标准化。这个数量(配分函数)和它的梯度的估算是很棘手的,尽管他们能够依靠马尔可夫链和蒙特卡罗(MCMC)算法来估计,同时依靠MCMC算法的混合也会引发一个严重的问题。
深度信念网络(DBN)是一个包含一个无向层和若干有向层的混合模型。当使用一个快速逐层训练法则时,DBNS 会引发无向模型和有向模型相关的计算难题。
不是利用似然函数的估计或约数的选择准则已经被提出来了,例如分数匹配和噪音压缩评估(NCE)。他们都需要知道先验概率密度知识用来分析指定一个规范化的常量。请注意,许多有趣的带有一些隐层变量的生成模型(如DBN和DBM),它们甚至不需要一些难以处理的非标准化的概率密度先验知识。一些模型如自动编码降噪机和压缩编码的学习准则与分数匹配在RBM上的应用非常相似。在NCE中,使用一个判别训练准则来拟合一个生成模型。然而,生成模型常常被用来判别从一个固定噪音分布中抽样生成的数据,而不是拟合一个独立的判别模型。由于NCE使用一个固定的噪音分布,仅仅是从观测变量的一个小子集中学习到一个大致正确的分布后,模型的学习便急剧减慢。
最后,一些技术并没有用来明确定义概率分布,而是用来训练一个生成器来从期望的分布中拟合出样本。这个方法优势在于这些机器学习算法能够设计使用反向传播算法训练。这个领域最近比较突出的工作包含生成随机网络(GSN),它扩展了广义的除噪自动编码器:两者都可以看作是定义了一个参数化的马尔可夫链,即一个通过执行生成马尔科夫链的一个步骤来学习机器参数的算法。同GSNs相比,对抗网络不需要使用马尔可夫链来采样。由于对抗网络在生成阶段不需要循环反馈信息,它们能够更好的利用分段线性单元,这可以提高反向传播的效率。大部分利用反向传播算法来训练生成器的例子包括贝叶斯变分自动编码和随机反向传播。
3、对抗网络
当模型是多层感知器时,对抗模型框架是最直接应用的。为了学习生成器关于数据 ![]() 上的分布
上的分布![]() ,我们定义输入噪声的先验变量
,我们定义输入噪声的先验变量 ,然后使用
来代表数据空间的映射。这里G是一个由含有参数
![]() 的多层感知机表示的可微函数。我们再定义了一个多层感知机
的多层感知机表示的可微函数。我们再定义了一个多层感知机 用来输出一个单独的标量。
代x来自于真实数据分布而不是
![]() 的概率,我们训练D来最大化分配正确标签给不管是来自于训练样例还是G生成的样例的概率。我们同时训练G来最小化
的概率,我们训练D来最大化分配正确标签给不管是来自于训练样例还是G生成的样例的概率。我们同时训练G来最小化 ![]() 。换句话说,D和G的训练是关于值函数
。换句话说,D和G的训练是关于值函数 ![]() 的极小化极大的二人博弈问题:
的极小化极大的二人博弈问题:
![]()
在下一节中,我们提出了对抗网络的理论分析,基本上表明基于训练准则可以恢复数据生成分布,因为G和D被给予足够的容量,即在非参数极限。如图1展示了该方法的一个非正式却更加直观的解释。实际上,我们必须使用迭代数值方法来实现这个过程。在训练的内部循环中优化D到完成的计算是禁止的,并且有限的数据集将导致过拟合。相反,我们在优化D的k个步骤和优化G的一个步骤之间交替。只要G变化足够慢,可以保证D保持在其最优解附近。该过程如算法1所示。
实际上,方程(1)可能无法为G提供足够的梯度来学习。训练初期,当G的生成效果很差时,D会以高置信度来拒绝生成样本,因为它们与训练数据明显不同。因此,![]() 饱和。因此我们选择最大化
饱和。因此我们选择最大化![]() 而不是最小化
而不是最小化![]() 来训练G,该目标函数使G和D的动力学稳定点相同,并且在训练初期,该目标函数可以提供更强大的梯度。
来训练G,该目标函数使G和D的动力学稳定点相同,并且在训练初期,该目标函数可以提供更强大的梯度。
![]()
图1.训练对抗的生成网络时,同时更新判别分布(D,蓝色虚线)使D能区分数据生成分布![]() (黑色虚线)中的样本和生成分布
(黑色虚线)中的样本和生成分布![]() (G,绿色实线) 中的样本。下面的水平线为均匀采样z的区域,上面的水平线为x的部分区域。朝上的箭头显示映射
(G,绿色实线) 中的样本。下面的水平线为均匀采样z的区域,上面的水平线为x的部分区域。朝上的箭头显示映射 ![]() 如何将非均匀分
如何将非均匀分![]() 作用在转换后的样本上。G在
作用在转换后的样本上。G在![]() 高密度区域收缩,且在
高密度区域收缩,且在![]() 的低密度区域扩散。(a)考虑一个接近收敛的对抗的模型对:
的低密度区域扩散。(a)考虑一个接近收敛的对抗的模型对:![]() 与
与![]() 相似,且D是个部分准确的分类器。(b)算法的内循环中,训练D来判别数据中的样本,收敛到:
相似,且D是个部分准确的分类器。(b)算法的内循环中,训练D来判别数据中的样本,收敛到:![]() 。(c)在G的1次更新后,D的梯度引导
。(c)在G的1次更新后,D的梯度引导流向更可能分类为数据的区域。(d)训练若干步后,如果G和D性能足够,它们接近某个稳定点并都无法继续提高性能,因为此时
。判别器将无法区分训练数据分布和生成数据分布,即
。
算法1.生成对抗网络的mini-batch随机梯度下降训练。判别器的训练步数k,是一个超参数。在我们的试验中使用k=1 ,使消耗最小。
![]()
4、理论结果
当时,获得样本G(z), 产生器G隐式的定义概率分布
为G(z) 获得的样本的分布。因此,如果模型容量和训练时间足够大时,我们希望算法1收敛为
的良好估计量。本节的结果是在非参数设置下完成的,例如,我们通过研究概率密度函数空间中的收敛来表示具有无限容量的模型。
我们将在4.1节中显示,这个极小化极大问题的全局最优解为 。我们将在4.2节中展示使用算法1来优化等式1,从而获得期望的结果。
4.1 全局最优: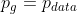
首先任意给生成器G,考虑最优判别器D。
命题1.固定G,最优判别器D为:![]() ……(2)
……(2)
证明:给定任意生成器G,判别器D的训练标准为最大化目标函数V(G,D),而得出最优判别器 D。其中,最大化 V(D,G) 评估了 和
之间的差异或距离。因为在原论文中价值函数可写为在 x上的积分,即将数学期望展开为积分形式:
![]()
关于上面积分式的证明
在 GAN 原论文中,有一个思想和其它很多方法都不同,即生成器 G 不需要满足可逆条件。Scott Rome 认为这一点非常重要,因为实践中 G 就是不可逆的。而很多证明笔记都忽略了这一点,他们在证明时错误地使用了积分换元公式,而积分换元却又恰好基于 G 的可逆条件。Scott 认为证明只能基于以下等式的成立性:
该等式来源于测度论中的 Radon-Nikodym 定理。
有一些证明过程使用了积分换元公式,但进行积分换元就必须计算 G(−1)G(−1),而 G 的逆却并没有假定为存在。并且在神经网络的实践中,它也并不存在。可能这个方法在机器学习和统计学文献中太常见了,因此我们忽略了它。
对于任意的 ,函数
在[0,1]中的
处达到最大值。无需在
外定义判别器,证毕。
在数据给定,G 给定的前提下, 与
都可以看作是常数,我们可以分别用 a,b 来表示他们,这样我们就可以得到如下的式子:
![]()
注意到,判别器D的训练目标可以看作为条件概率P(Y=y|x) 的最大似然估计,当y=1时,x来自于 ;当y=0时,x来自
。公式1中的极小化极大问题可以变形为:
![]()
定理:.当且仅当时,C(G)达到全局最小。此时,C(G)的值为−log4。
证明: 时,
(公式2)。再根据公式4可得,
。为了看仅当
时C(G)是否是最优的,观测:
![]()
然后从 减去上式,可得:
![]()
其中KL为Kullback–Leibler散度。我们在表达式中识别出了模型判别和数据生成过程之间的Jensen–Shannon散度:
![]()
由于两个分布之间的Jensen–Shannon散度总是非负的,并且当两个分布相等时,值为0。因此为C(G)的全局极小值,并且唯一解为
,即生成模型能够完美的复制数据的生成过程。
4.2 算法1的收敛性
命题2:如果G和D有足够的性能,对于算法1中的每一步,给定G时,判别器能够达到它的最优,并且通过更新 来提高这个判别准则:
![]()
则收敛于
.
证明:如上述准则,考虑 为关于
的函数。注意到
为
的凸函数。该凸函数上确界的一次导数包括达到最大值处的该函数的导数。换句话说,如果
且对于每一个
,
是关于x的凸函数,那么如果
,则
。这等价于给定对应的G和最优的D,计算
的梯度更新。如定理1所证明,
是关于
的凸函数且有唯一的全局最优解,因此,当
的更新足够小时,
收敛到
,证毕。
实际上,对抗的网络通过函数 表示
分布的有限簇,并且我们优化
而不是
本身。使用一个多层感知机来定义G在参数空间引入了多个临界点。然而,尽管缺乏理论证明,但在实际中多层感知机的优良性能表明了这是一个合理的模型。
5、GAN的优势和缺陷
5.1 优势
优点:
- 根据实际的结果,它们看上去可以比其它模型产生了更好的样本(图像更锐利、清晰)。
- 生成对抗式网络框架能训练任何一种生成器网络(理论上-实践中,用 REINFORCE 来训练带有离散输出的生成网络非常困难)。大部分其他的框架需要该生成器网络有一些特定的函数形式,比如输出层是高斯的。重要的是所有其他的框架需要生成器网络遍布非零质量(non-zero mass)。生成对抗式网络能学习可以仅在与数据接近的细流形(thin manifold)上生成点。
- 不需要设计遵循任何种类的因式分解的模型,任何生成器网络和任何鉴别器都会有用。
- 无需利用马尔科夫链反复采样,无需在学习过程中进行推断(Inference),回避了近似计算棘手的概率的难题。
与其他生成式模型相比较,生成式对抗网络有以下四个优势:
- 与PixelRNN相比,生成一个样本的运行时间更小。GAN 每次能产生一个样本,而 PixelRNN 需要一次产生一个像素来生成样本。
- 与VAE 相比,它没有变化的下限。如果鉴别器网络能完美适合,那么这个生成器网络会完美地恢复训练分布。换句话说,各种对抗式生成网络会渐进一致(asymptotically consistent),而 VAE 有一定偏置。
- 与深度玻尔兹曼机相比,既没有一个变化的下限,也没有棘手的分区函数。它的样本可以一次性生成,而不是通过反复应用马尔可夫链运算器(Markov chain operator)。
- 与 GSN 相比,它的样本可以一次生成,而不是通过反复应用马尔可夫链运算器。
- 与NICE 和 Real NVE 相比,在 latent code 的大小上没有限制。
5.2 缺陷或存在的问题
①解决不收敛(non-convergence)的问题。
目前面临的基本问题是:所有的理论都认为 GAN 应该在纳什均衡(Nash equilibrium)上有卓越的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。当博弈双方都由神经网络表示时,在没有实际达到均衡的情况下,让它们永远保持对自己策略的调整是可能的。
②难以训练:崩溃问题(collapse problem)
GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。当然Goodfellow在【Improved Techniques for Training GANs】文章中也有一些相应的改进方法例如:特征映射等。
③无需预先建模,模型过于自由不可控。
与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了(超高维)。在GAN[Goodfellow Ian, Pouget-Abadie J] 中,每次学习参数的更新过程,被设为D更新k回,G才更新1回,也是出于类似的考虑。
GAN原始论文翻译及相关推导相关推荐
- BEGAN(Boundary Equilibrium GAN)论文翻译
BEGAN(Boundary Equilibrium GAN)论文翻译 BEGAN:边界平衡生成式对抗网络 摘要 我们提出了一种新的促进平衡的方法,以及配套的损失函数,这个损失的设计由Wasserst ...
- FaceID-GAN:Learning a Symmetry Three-Player GAN for Identity-Preserving Face Synthesis论文翻译和解读
写在之前:这篇work的精妙程度是我平生仅见,或者是我还没看过太多论文.网络模型的设计加上合适的损失函数,一篇CVPR就出来了. 摘要 人脸合成使用GANs已经获得了很卓越的效果.现存在的方法将GAN ...
- GAN对抗生成网络原始论文理解笔记
文章目录 论文:Generative Adversarial Nets 符号意义 生成器(Generator) 判别器(Discriminator) 生成器和判别器的关系 GAN的训练流程简述 论文中 ...
- Transformers in Vision: A Survey论文翻译
Transformers in Vision: A Survey 论文翻译 原文 翻译链接 摘要 摘要--Transformer模型在自然语言任务上的惊人结果引起了视觉界的兴趣,而致力于研究它们在计算 ...
- 手把手带你掌握计算机视觉原始论文细节阅读
人工智能研究在本质上是学术性的,在你能够获得人工智能的某些细节之前,需要掌握大量的跨各类学科的知识. 那么,阅读原始论文在学习的过程中有多重要? 原始论文细节阅读是互联网大厂人工智能岗位面试必考题,也 ...
- 生成对抗网络(GAN)论文原文详解
最近在学习生成对抗网络的相关知识,首先接触到的当然是Ian Goodfellow的原始论文,文章中作者很简要的阐明了GAN的基本算法,同时也给出该算法可行的理论证明. 该模型通俗点说,就是可以利用已知 ...
- 论文翻译:搜索人脸活体检测的中心差异卷积网络及实现代码
搜索人脸活体检测的中心差异卷积网络 摘要 1. 绪论 2. 相关工作 人脸活体检测 卷积运算符 神经架构搜索 3. 方法论 3.1 中心差分卷积 基本卷积 基本卷积结合中心差分操作 中心差分卷积的实现 ...
- 联邦学习笔记-《Federated Machine Learning: Concept and Applications》论文翻译个人笔记
联邦学习笔记-<Federated Machine Learning: Concept and Applications>论文翻译个人笔记 摘要 今天的人工智能仍然面临着两大挑战.一是在大 ...
- Scaled-YOLOv4: Scaling Cross Stage Partial Network 论文翻译
Scaled-YOLOv4: Scaling Cross Stage Partial Network论文翻译 摘要 1.介绍 2.相关工作 2.1 实时检测器 2.2 模型缩放 3.模型缩放的原则 3 ...
最新文章
- python程序设计报告-20192404 实验一 《Python程序设计》实验报告
- vue教程2-03 vue计算属性的使用 computed
- C语言经典例27-利用递归逆序输出字符串
- QT的QStandardItemEditorCreator类的使用
- mysql 当前用户连接数_实战:判断mysql中当前用户的连接数-分组淘选
- app inventor离线版_小鸡漫画app手机版下载_小鸡漫画好看的漫画手机版下载
- 用lnmp.org中的lnmp下安装ftp(pureftp)
- Haar特征与积分图
- 基于SpringBoot在线电影订票系统
- 如何在Mac电脑上更改地区或国家?
- PIC单片机c语言休眠,PIC16F72 休眠程序
- 解决Gradle‘s dependency cache may be corrupt (this sometimes occurs after a network connection timeout
- python标准库不需要导入即可使用其中的所有对象和方法_2021智慧树网课答案创业基础考试期末答案...
- linux下刻录光盘读取不了_Linux下刻录光盘
- ASPX一句话及一句话客户端
- element-ui 点击Switch开关弹出对话框确认后再改变switch开关状态
- 接口获取行政区划代码_全国省市县行政区划分
- Windows装机方案
- 一个完美的JS加密和解密程序
- fpga实操训练(vga测试)