理解HTTP之keep-alive(转)
理解HTTP之keep-alive
在前面一篇文章中讲了TCP的keepalive,这篇文章再讲讲HTTP层面keep-alive。两种keepalive在拼写上面就是不一样的,只是发音一样,于是乎大家就都迷茫了。HTTP层面的keep-alive是我们接触比较多的,也是大家平时口头上的"keepalive"。下面我们就来谈谈HTTP的keep-alive
短连接&长连接&并行连接
再说keep-alive之前,先说说HTTP的短连接&长连接。
短连接
所谓短连接,就是每次请求一个资源就建立连接,请求完成后连接立马关闭。每次请求都经过“创建tcp连接->请求资源->响应资源->释放连接”这样的过程
长连接
所谓长连接(persistent connection),就是只建立一次连接,多次资源请求都复用该连接,完成后关闭。要请求一个页面上的十张图,只需要建立一次tcp连接,然后依次请求十张图,等待资源响应,释放连接。
并行连接
所谓并行连接(multiple connections),其实就是并发的短连接。
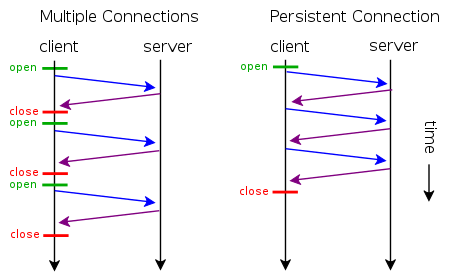
keep-alive
具体client和server要从短连接到长连接最简单演变需要做如下改进:
- client发出的HTTP请求头需要增加Connection:keep-alive字段
- Web-Server端要能识别Connection:keep-alive字段,并且在http的response里指定Connection:keep-alive字段,告诉client,我能提供keep-alive服务,并且"应允"client我暂时不会关闭socket连接
在HTTP/1.0里,为了实现client到web-server能支持长连接,必须在HTTP请求头里显示指定
Connection:keep-alive
在HTTP/1.1里,就默认是开启了keep-alive,要关闭keep-alive需要在HTTP请求头里显示指定
Connection:close
现在大多数浏览器都默认是使用HTTP/1.1,所以keep-alive都是默认打开的。一旦client和server达成协议,那么长连接就建立好了。
接下来client就给server发送http请求,继续上面的例子:请求十张图片。如果每次"请求->响应"都是独立的,那还好,10张图片的内容都是独立的。但是如果pipeline模式,上一个请求还没响应,下一个请求就发出,这样并发地发出10个请求,对于10个response client要怎么区分呢?而HTTP协议又是没有办法区分的,所以这种情况下必须要求server端地响应是顺序的,通过Conten-Length区分每次请求,这还只是针对静态资源,那对于动态资源无法预知页面大小的情况呢?我还没有深入研究,可以查看https://www.byvoid.com/blog/http-keep-alive-header
另外注意: 指定keep-alive是一种client和server端尽可能需要满足的约定,client和server可以在任意时刻都关闭keep-alive,彼此都不应该受影响。
Nginx keepa-alive配置
具体到Nginx的HTTP层的keepalive配置有
- keepalive_timeout
Syntax: keepalive_timeout timeout [header_timeout];Default: keepalive_timeout 75s;Context: http, server, location
The first parameter sets a timeout during which a keep-alive client connection will stay open on the server side. The zero value disables keep-alive client connections. The optional second parameter sets a value in the “Keep-Alive: timeout=time” response header field. Two parameters may differ.
- keepalive_requests
Syntax: keepalive_requests number;Default: keepalive_requests 100;Context: http, server, location
Sets the maximum number of requests that can be served through one keep-alive connection. After the maximum number of requests are made, the connection is closed.
可以看看Nginx的关于 keepalive_timeout 是实现
./src/http/ngx_http_request.cstatic void
ngx_http_finalize_connection(ngx_http_request_t *r){
...if (!ngx_terminate&& !ngx_exiting&& r->keepalive&& clcf->keepalive_timeout > 0){ngx_http_set_keepalive(r);return;}
...
}static void
ngx_http_set_keepalive(ngx_http_request_t *r){//如果发现是pipeline请求,判断条件是缓存区里有N和N+1个请求同时存在if (b->pos < b->last) {/* the pipelined request */}// 本次请求已经结束,开始释放request对象资源r->keepalive = 0;ngx_http_free_request(r, 0);c->data = hc;// 如果尝试读取keep-alive的socket返回值不对,可能是客户端close了。那么就关闭socketif (ngx_handle_read_event(rev, 0) != NGX_OK) {ngx_http_close_connection(c);return;}//开始正式处理pipeline...rev->handler = ngx_http_keepalive_handler;...// 设置了一个定时器,触发时间是keepalive_timeout的设置ngx_add_timer(rev, clcf->keepalive_timeout);...}static void
ngx_http_keepalive_handler(ngx_event_t *rev){// 发现超时则关闭socketif (rev->timedout || c->close) {ngx_http_close_connection(c);return;}// 读取keep-alive设置从socketn = c->recv(c, b->last, size);if (n == NGX_AGAIN) {if (ngx_handle_read_event(rev, 0) != NGX_OK) {ngx_http_close_connection(c);return;}...}//此处尚有疑惑?ngx_reusable_connection(c, 0);c->data = ngx_http_create_request(c);// 删除定时器ngx_del_timer(rev);// 重新开始处理请求rev->handler = ngx_http_process_request_line;ngx_http_process_request_line(rev);
}参考资料
- http://nginx.org/en/docs/http/ngx_http_core_module.html
转载于:https://www.cnblogs.com/roy-blog/p/8340954.html
理解HTTP之keep-alive(转)相关推荐
- linux tcp keepalive,Linux下TCP的Keepalive相关参数学习
一 基本原理 TCP的Keepalive可以简单理解成为keep tcp alive,用来检测TCP sockets的连接是否正常或是已经断开. Keeplived的原理很简单,当建立一个TCP连接时 ...
- 深入理解Ribbon之源码解析
什么是Ribbon Ribbon是Netflix公司开源的一个负载均衡的项目,它属于上述的第二种,是一个客户端负载均衡器,运行在客户端上.它是一个经过了云端测试的IPC库,可以很好地控制HTTP和TC ...
- Activity采用栈式管理的理解
本文来自:安卓航班网 Android针对Activity的管理使用的是栈,就是说某一个时刻只有一个Activity处在栈顶,当这个Activity被销毁后,下面的Activity才有可能浮到栈顶,或者 ...
- 《深入理解Java虚拟机》-----第3章 垃圾收集器与内存分配策略
Java与C++之间有一堵由内存动态分配和垃圾收集技术所围成的"高墙",墙外面的人想进去,墙里面的人却想出来. 3.1 概述 说起垃圾收集(Garbage Collection,G ...
- 深入理解JVM之二:垃圾收集器概述
前言 我们知道Java的内存区域分为程序计数器.虚拟机栈.本地方法栈.Java堆和方法区,而且其中的程序计数器.虚拟机栈和本地方法栈都是线程独立的,也就是说这三块内存区域的生命周期与线程是同生共死的. ...
- 《深入理解java虚拟机》学习笔记四/垃圾收集器GC学习/一
Grabage Collection GC GC要完毕的三件事情: 哪些内存须要回收? 什么时候回收? 怎样回收? 内存运行时区域的各个部分中: 程序计数器.虚拟机栈.本地方法栈这3个区域随 ...
- 课时 16 深入理解 etcd:基于原理解析(曾凡松)
本文将主要分享以下三方面的内容: 第一部分,会为大家介绍 etcd 项目发展的整个历程,从诞生至今 etcd 经历的那些重要的时刻: 第二部分,会为大家介绍 etcd 的技术架构以及其内部的实现机制, ...
- 使用java理解程序逻辑 第十二章_Java弱引用的理解与使用
Java弱引用的理解与使用 WeakReference 前言 看到篇帖子, 国外一个技术面试官在面试senior java developer的时候, 问到一个weak reference相关的问题. ...
- Eureka深入理解
客户端负载均衡Ribbon,声明式的Http Client Feign,那我们回到Eureka上面去,我们对Eureka进行一些补充,对他进行一些更深入的理解,我们来看Eureka的文档Service ...
- TCP的FIN_WAIT1状态理解|深入理解TCP
原文链接: https://blog.csdn.net/dog250/article/details/81697403 近期遇到一个问题,简单点说,主机A上显示一条ESTABLISHED状态的TCP连 ...
最新文章
- 您知道为何要采用固定的迭代周期吗
- 动态添加跨行表格_手把手教你制作Excel动态统计表格,主管看了都会竖起大拇指!-Office教程...
- 算法面试:栈实现队列的方案
- MySQL 备份和恢复
- Option键用的好,鼠标用的少(这6个你绝对不知道的...)
- Python3 从零单排7_模块ossys
- 沈向洋、王海峰候选中国工程院院士!计算机领域7位入围增选
- TensorFlow tf.data.Dataset
- 接口测试——接口测试流程
- Linux find xargs rm .orig
- 用Java实现修改头像
- Redis之连接redis服务命令
- 计算机并口被禁用,电脑并口被禁用怎么办
- stm32Cubemx USB虚拟串口
- 单表(sqlserver不支持)、整库,支持本地和远程备份
- 微信视频号视频保存,微信视频号视频下载的方法
- 好玩的Canvas射箭小游戏
- 运用计算机巧记英语词汇,词根词缀法巧记考研英语词汇:词根graph-(写)
- 系统学习NLP(三十一)--基于CNN句子分类
- goland + dlv
热门文章
- 信创办公--基于WPS的Word最佳实践系列(图文环绕方式)
- Smtplib之发邮件模块
- java怎么生成apk文件,【连载】聊聊 APK(四) —— 脱离 AS 手工创造 APK 文件
- 怎么进入python 的venv文件夹_mac下Python关于venv 的使用
- html中怎么把文字环绕圆形,Photoshop如何制作环绕圆形路径文字(章环绕的圆形文字)及使用技巧记录...
- 机器学习 --- 刘建平整理
- CSDN博客打不开的解决办法
- 献上一串Python代码,拿去冲顶百万大奖吧!王思聪周鸿祎这回真要哭晕了
- WPS表格奇偶数页打印怎么设置?如何只打印奇数页?
- DruidDataSource理解数据库Mysql超时设置