独家揭秘阿里云SQL Server AlwaysOn集群版重大突破
缘起
早在2015年的时候,随着阿里云业务突飞猛进的发展,SQLServer业务也积累了大批忠实客户,其中一些体量较大的客户在类似大促的业务高峰时RDS的单机规格(规格是按照 内存CPUIOPS 一定比例分配,根据底层资源不同都会有各自上限)已经不能满足用户的业务需求,在我们看来也需要做Scale Out了,但SQLServer并没有完备的中间件产品,所以无论是逻辑Sharding还是只读分离,都需要用户配合做应用改造,而从用户角度看Sharding改动量很大不是一时间能完成的,那么更多寄希望我们提供读写分离的方案来满足业务需求。
那么读写分离我们第一个想到的即是AlwaysOn技术,但由于当时AlwaysOn对域控和Windows群集都是强依赖,而这两者又对我们所依赖的基础设施有很大挑战,需要做很多的突破产品限制的非标准化操作才有可能实现并且还有安全风险,所以最后我们只能放弃AlwaysOn技术方案,重新设计方案帮助用户度过难关。
最后,面对这类客户需求我们的方案如何产品化是值得我们思考的。
产品快速发展
除了读写分离,产品上还有很多更重要的问题急需我们去解决,所以从2015年到2017年我们经历了一个飞速发展阶段,围绕产品稳定性、多样性以及用户体验做了非常多的事情,举几个点:
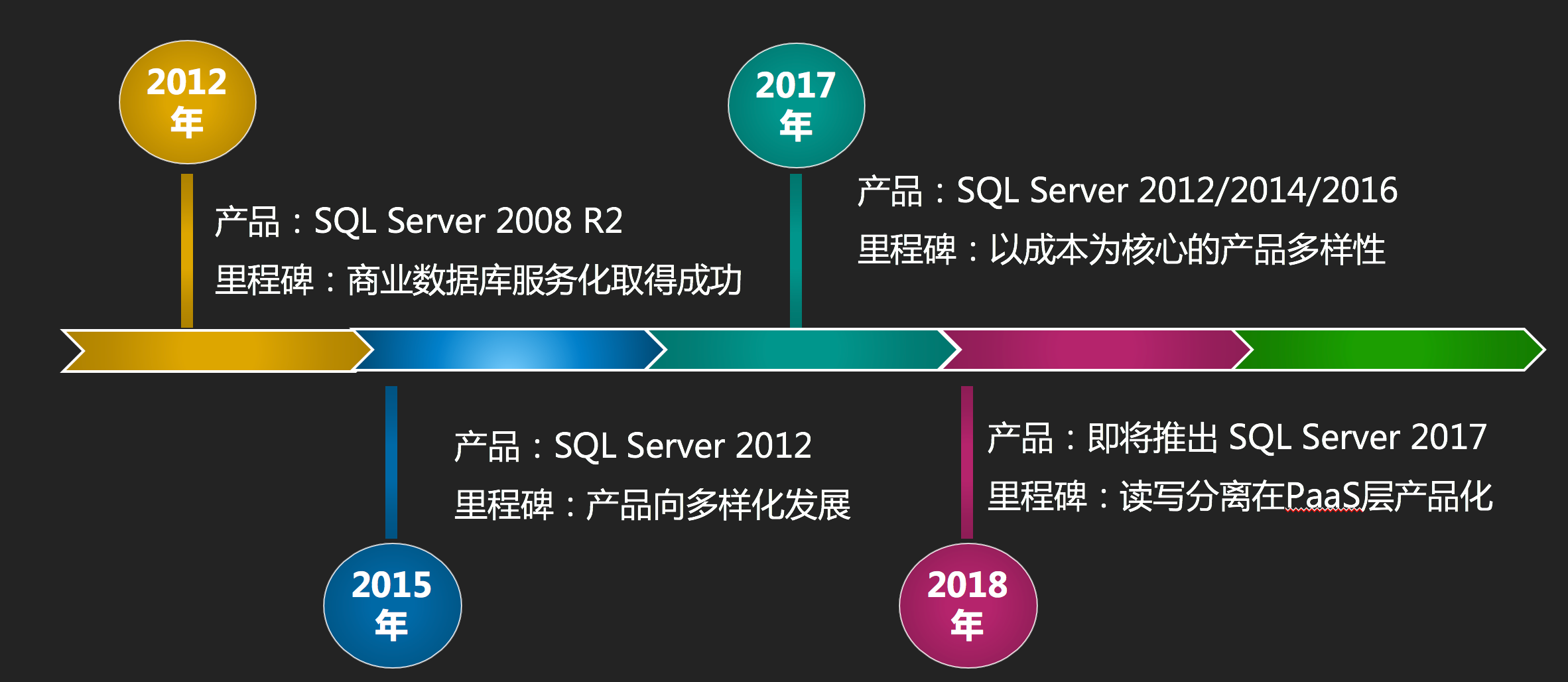
- 为了提高稳定性和用户体验我们最先替换了底层架构,这也为后续产品多样化发展打下基础
- 为了满足不同用户需求,推出了SQLServer 2008R2/2012/2014/2016 Web/Standard/Enterprise 不同Version、Edition的组合版本
- 为解决上云难问题推出了上云评估工具,以及针对不同版本、不同场景的上云方案全量备份数据上云SQL Server 2008 R2版、全量备份数据上云SQL Server 2012及以上版本、增量备份数据上云SQL Server 2012及以上版本、SQL Server实例级别数据库上云
- 为了提升用户体验支持更多特性,我们在SQL层提供了很多封装的存储过程,这里有些看似简单的功能在面对外部的安全、内部的SQL镜像等因素的共同作用下,实现的挑战还是很大的
- 为了让专家服务更智能、更能贴近每个用户,我们研发了SQLServer CloudDBA集合了云上大量性能、空间问题的解决方案
在这当中依旧不断有读写分离的用户需求,每次遇到我们都先引导到了IaaS层用ECS自建实现,因为PaaS化的时机并不成熟,具体原因跟SQLServer当前的技术栈和云产品的结合有着密切的关系,这里也可以把我们背后的一些思考分享出来。
读写分离
首先明确我们讨论的读写分离是什么,MySQL的读写分离大部分是利用中间层做路由解析,基本上可以实现对应用端透明只有少部分场景需要用户做适配。
SQLServer并没有成熟的中间件产品,本质上讲是TDS(Tabular Data Stream)不完全开放的原因,如果要做也是有办法的,只是投入的成本远大于收益;基于此,SQLServer无论利用当前何种技术实现读写分离,对应用来讲都需要做一些适配,即使是使用AlwaysOn技术在链接驱动的参数配置上也会不同,所以我们后面讨论的读写分离都是基于这个前提。
技术选型
我们对比了SQLServer所有相关的技术栈
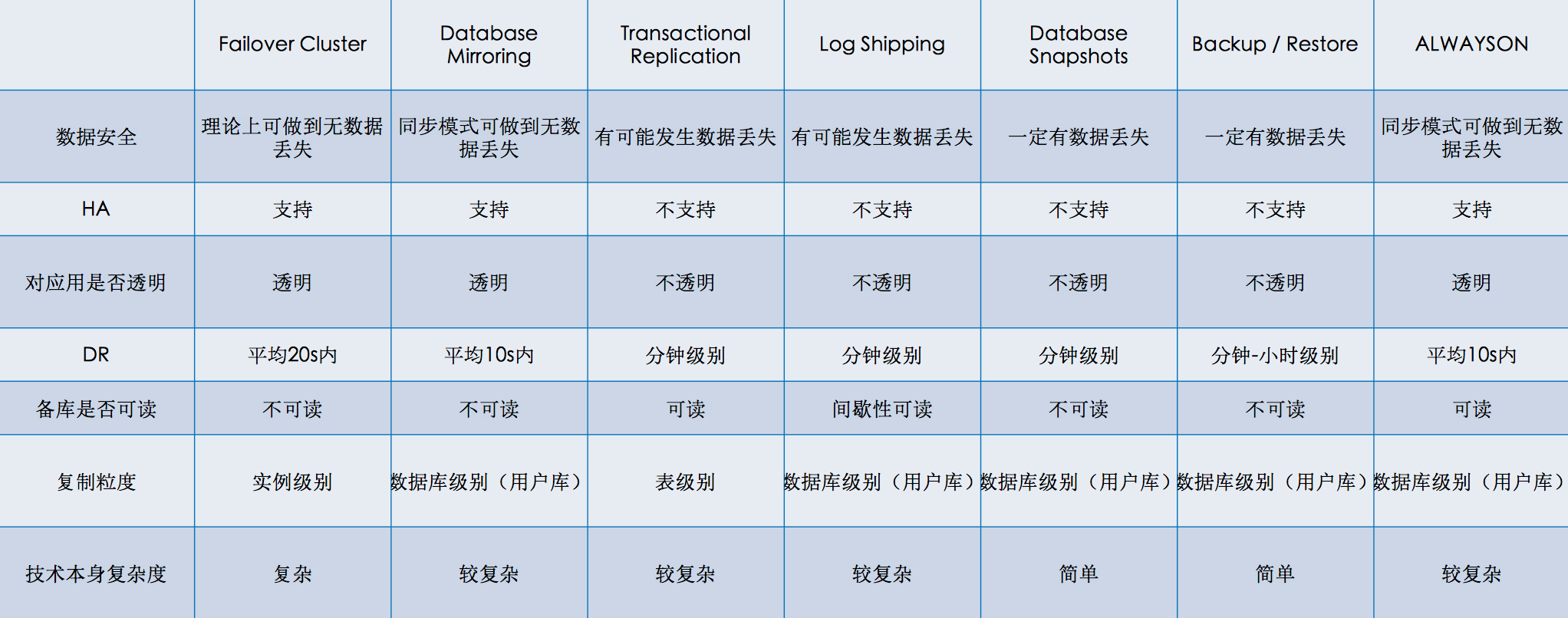
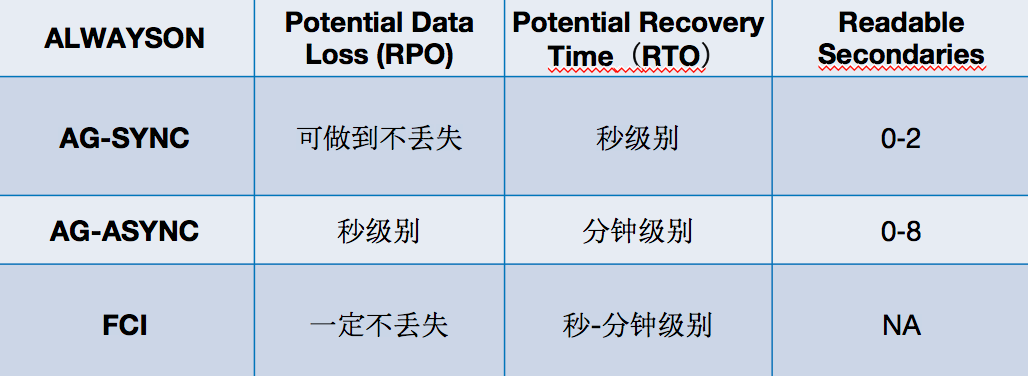
其中数据安全、HA(High Availability 高可用)、DR(Disaster Recovery 灾难恢复)以及备库是否可读是我们最关注的;这里的HA是指原生技术本身是否支持自动HA,当结合了部分云产品后我们也有能力把不支持变为支持,数据安全和灾难恢复的时间基本是原生技术决定的,备库是否可读是对单一技术的说明但做一些技术组合是可以把不可读变为可读的(比如Database Mirroring+Database Snapshots),最终综合来看Transactional Replication和AlwaysOn是我们觉得有机会做读写分离产品化的技术。
接着我们单独来看这两种技术对比
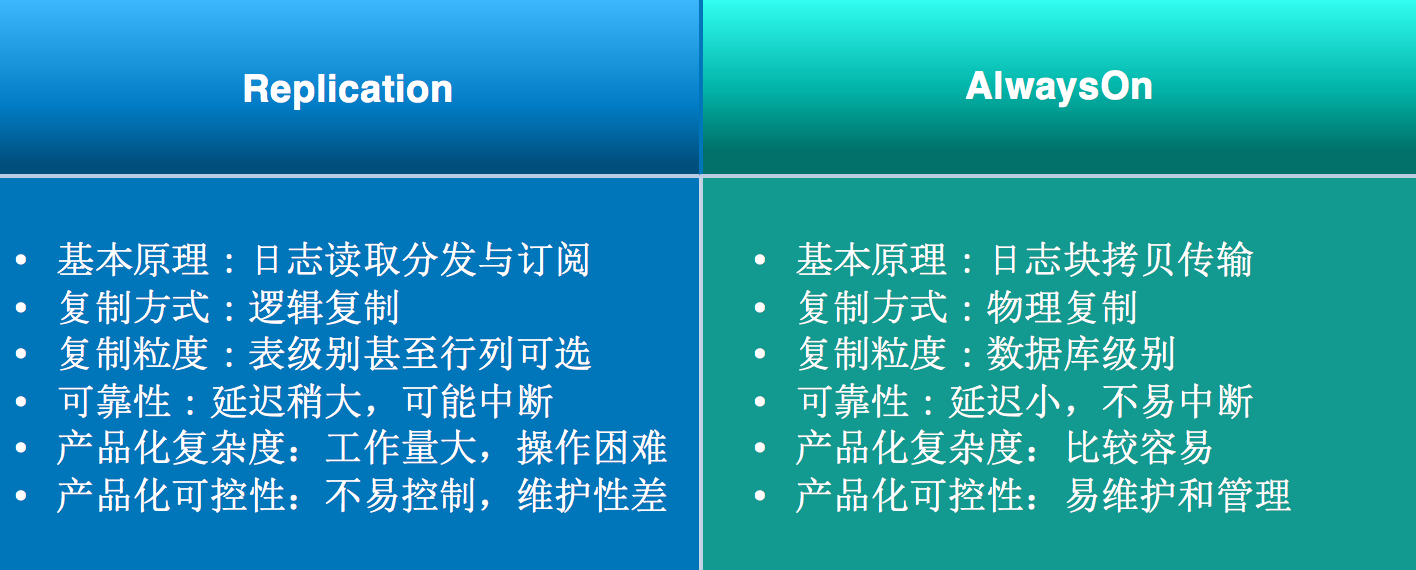
原理上讲Replication是逻辑复制,对比AlwaysOn的物理复制在性能、延迟、可靠性上都会有一定的差距;并且在产品复杂度读、可控性上和易用性上,由于Replication过于灵活细到表、列级别很难控制,无论用户使用还是我们做产品化整个复杂度非常高;所以最终我们选用AlwaysOn。
AlwaysOn技术
AlwaysOn是原生支持High Availability和Disaster Recovery的技术,本身又分为Failover Cluster Instances(后续简称FCI)和Availability Groups(后续简称AG),下面的图是FCI和AG的基础架构
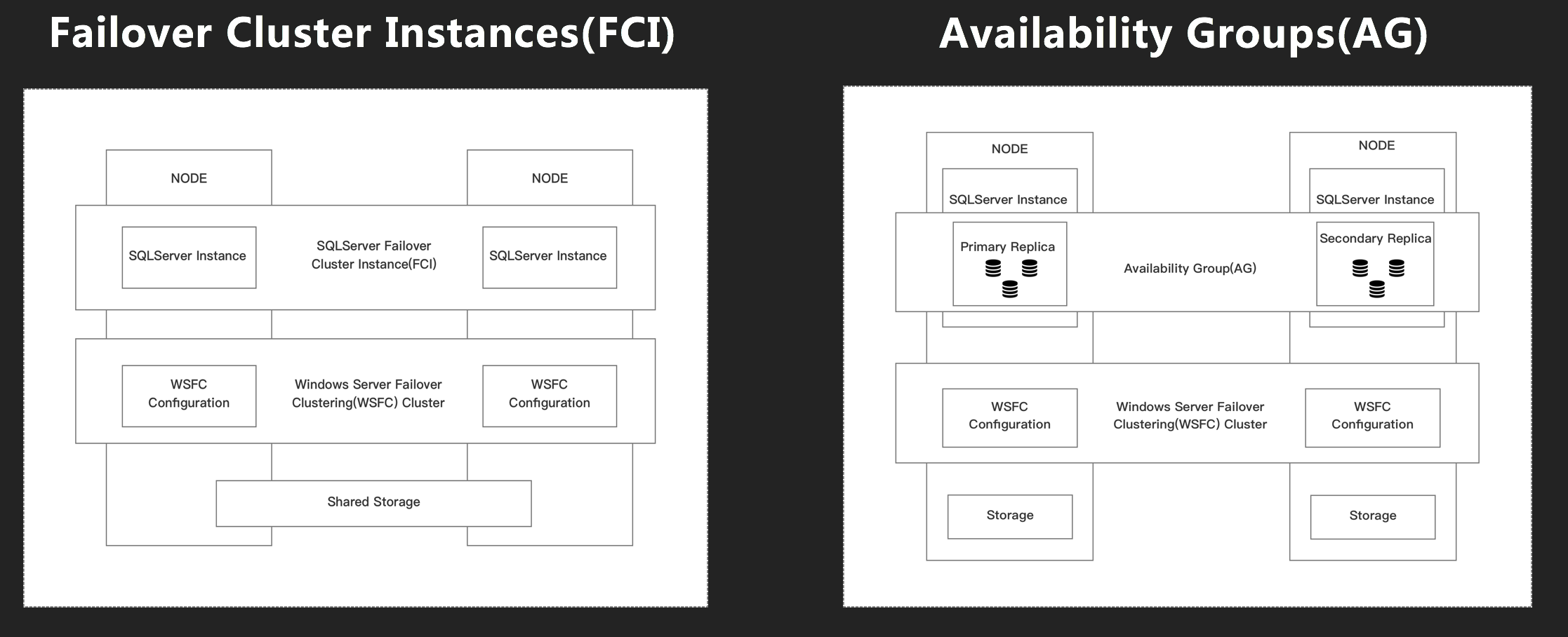
其中FCI和常规版本的AG都依赖Windows Server Failover Clustering(后续简称WSFC),不同点是FCI是Share Storage而AG是Share Nothing,FCI是实例级别同步而AG是DB级别,那么很容易想到Share Nothing会有同步和异步的区别(和镜像技术类似),其中两者的区别点需要我们知道AlwaysOn的基本同步过程

首先在Primary节点的日志(Commit/Log Block Write)会从Log Cache刷到磁盘,同时Primary节点的Log Capture也会把日志发送到其它所有Replica节点,对应节点的Log Receive线程把收到的日志同样从Log Cache刷到磁盘,最后会由Redo Thread应用这些日志刷到数据文件里。
这其中还有一步,就是在Secondary端刷日志的时候,如果Primary节点等待这次返回的Acknowlege Commit,那么就是同步模式,反之如果Primary端不等Secondary的返回那么就是异步模式,两者的区别由此展开。
这是基本的同步过程,但无论是AlwaysOn还是Database Mirroring都存在一种情况,即同步模式下如果Secondary端异常,Primary端没有收到他的心跳也没有收到这次的Acknowlege Commit,那么也并不会算作写入失败,因为它一旦认定Secondary异常就不会等这次ACK,而是退化为类似异步的模式,但会把Secondary端的异常状态记录在基表里,通过相关视图(sys.dm_hadr_database_replica_states、sys.database_mirroring)暴露出来,就是我们常见的NOT SYNCHRONIZING/Disconnect状态,这时候自动化运维系统或者DBA就需要做判断处理,等到Secondary修复重新联机后会向Primary报告End of Log (EOL) LSN,Primary端再向它发送EOL LSN 之后hardened的所有日志,一旦Secondary端开始接收到这些日志并逐步刷到日志文件中,那么整个AG或者Mirroring相关的视图又会标记其状态为Synchronizing,表明正在追赶直到Last Hardened (LH) LSN达到主备一致状态,这时重新回到同步模式。
以前的情况一直是这样,直到SQLServer 2017 CU 1引入了REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT这个参数,参数名字很长但也基本包含了他的作用,应对刚才的场景是可以让Primary端一直等到Secondary节点重新联机并同步后在提供服务。
了解了AG同步、异步以及FCI,在总结下我们关心的点
在实际方案中这些也可以结合起来,最终再和阿里云产品整合做一个整体方案,之前也讲到阿里云从15年就开始做类似方案来解决用户问题,一直到最终PaaS化也过度了三个版本。
云上演进
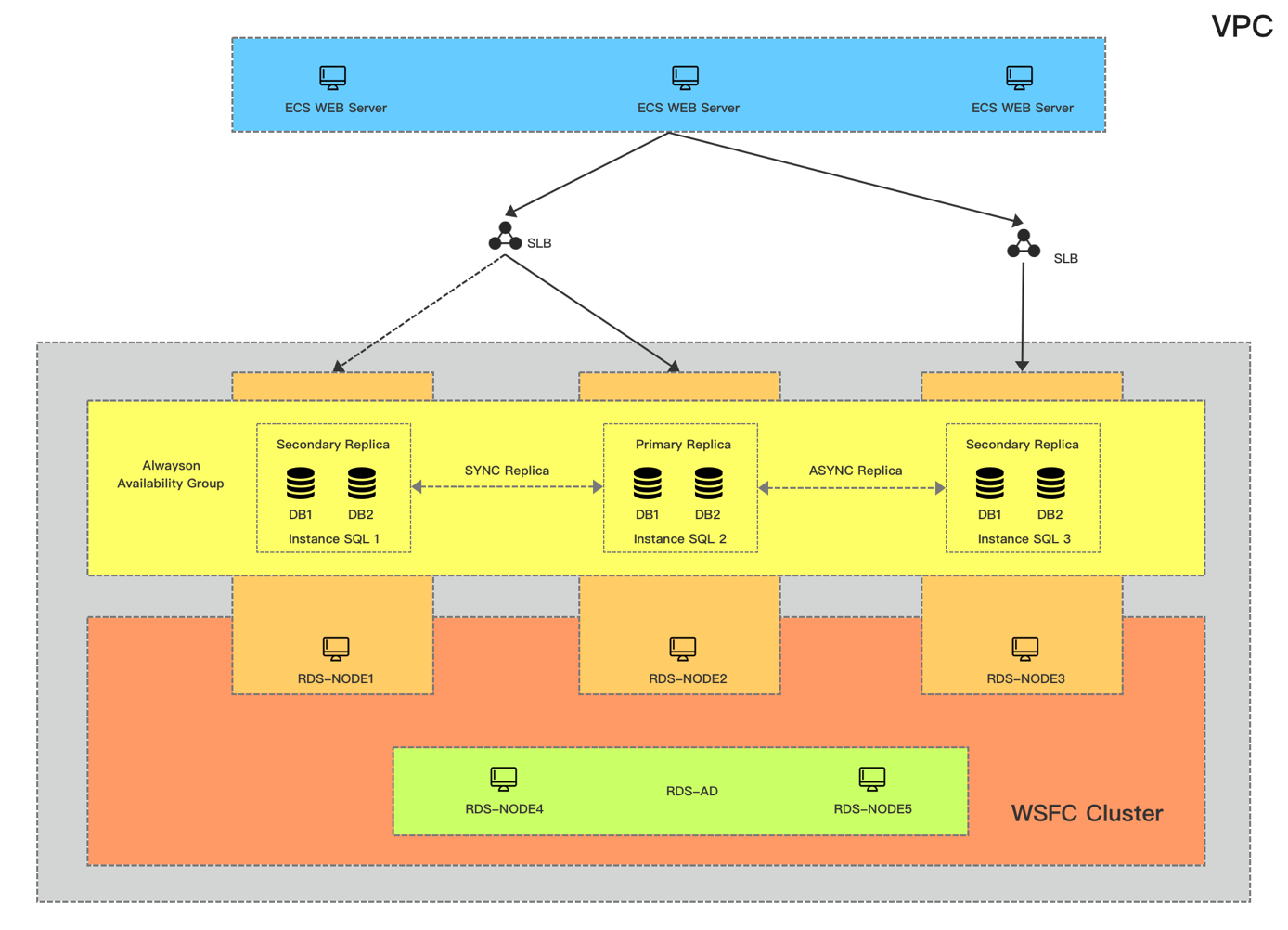
第一版本我们使用了ECS、SSD云盘、OSS、VPC、SLB作为基础;在SQL技术上,我们使用SQL+WSFC+AD的方式,目前看这种方式支持的版本也非常多,从12到17都可以;验证方式既可以用域控也可以用证书。
但他有2个缺点:第一是成本高,除了Primary和两个Secondary节点还要有两个AD节点,毕竟我们每个环节都要保证高可用;
第二点是稳定性不够,网络抖动的情况非常容易让WSFC判断异常,SQL端DB同时出现不可用;
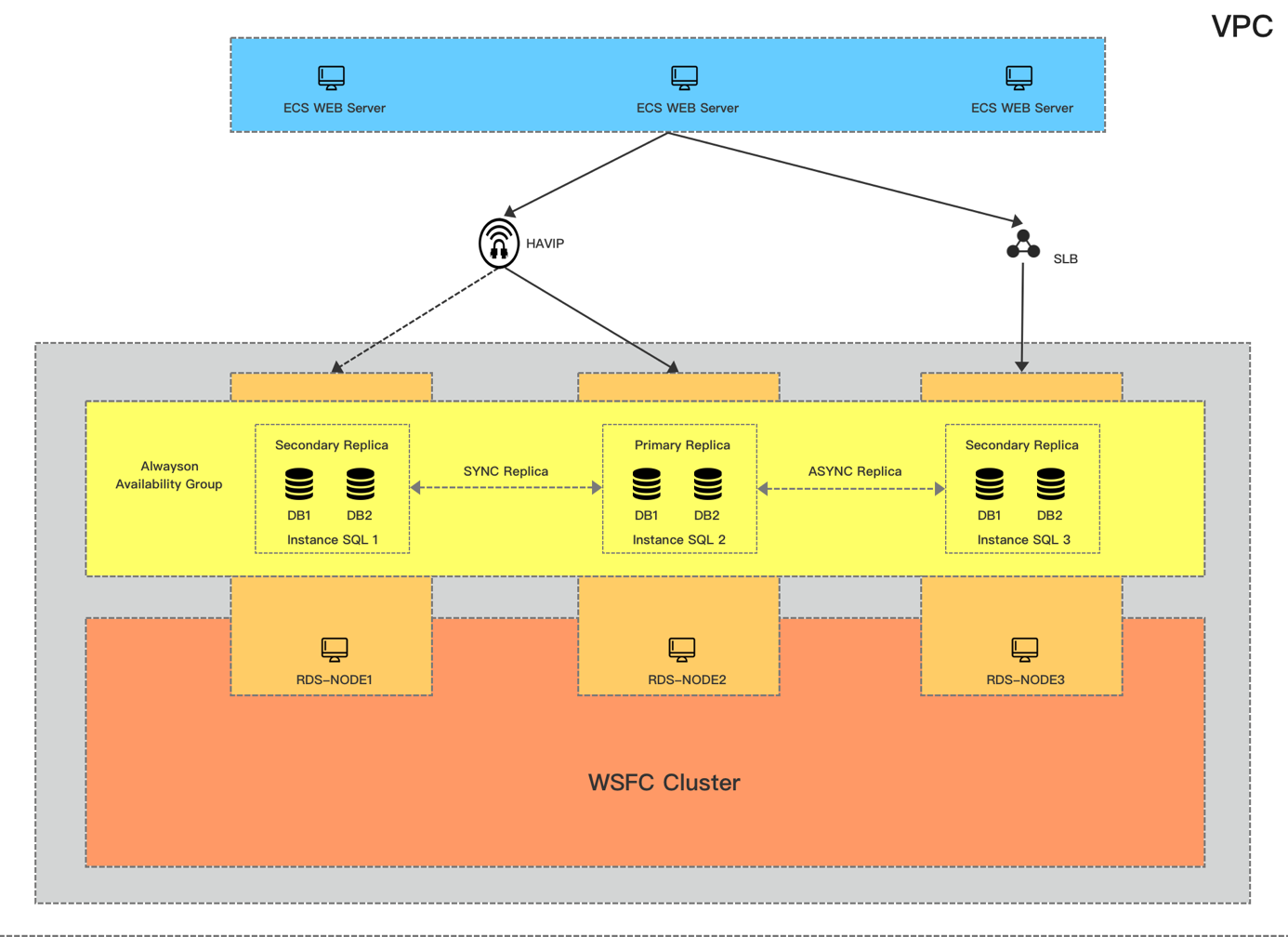
这是第二版的架构,跟第一版相比我们用到了HAVIP来解决监听器问题,去掉了AD只能用证书做验证,但也因此最小资源开销降低到3;这个方案也是之前在阿里云上用的比较多的,但同第一个方案一样,在网络稳定性上会有很多挑战,因为我们未来面对的场景不只是同城跨可用区还会有更多跨Region以及打通海外的场景,所以这个方案也只能Cover一部分用户的需求,但对我们不是一个最终方案。
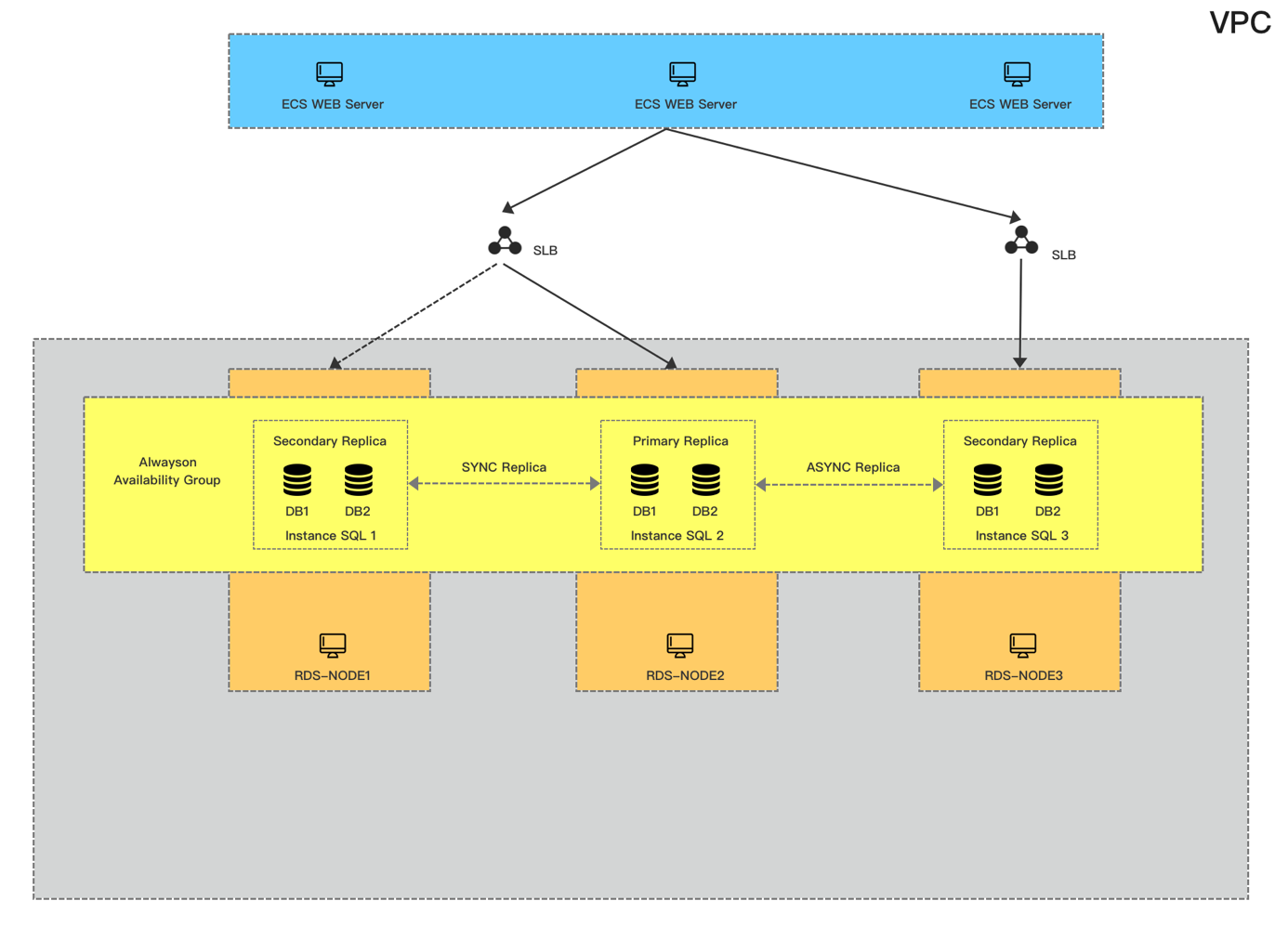
最终我们找到了方案三,去除了WSFC和AD,只关注基础云产品和SQL本身;最终要的是跟方案二相比,对网络的抖动敏感度会更低也更可控,最多是在Primary端出现Send Queue的堆积,这个我们完全可以通过SQLServer相关的Performance Counter监控并做一些修复调整。
但没有方案是完美的,可控性强的代价是这种无群集无域控架构原生是不具备HADR能力的,这点熟悉WSFC的同学可以知道之前架构的HA都是依赖WSFC,他包括健康检查、资源管理、分布式元数据通知维护以及故障转移,所以这时候就必须我们自己去解决这个问题;为此我们也做了很多努力,最终实现了支持AlwaysOn无域控无群集的HA系统,不依赖Cluster完全自主可控的HA。
产品化
最终的产品架构如下,首先会保证有2个同步节点做主备,并且尽量分配在不同的可用区,其它只读节点默认是异步,最多可以有7个只读节点;用户的访问链路可以有三种:
- 第一种是读写链路,会指向两个同步节点,由我们的HA来保证高可用
- 第二种是统一只读链路,根据用户需求设定,把指定的Replica节点绑定到一起按照一定的权重比例分配链接
- 第三种是单一只读链路,即每个只读节点会提供一个单独的链接,让用户也可以自己灵活配置,比如用户的APP Server就是在可用区A那么就可以直接访问可用区A的只读地址,避免再通过统一只读被路由到其它区域
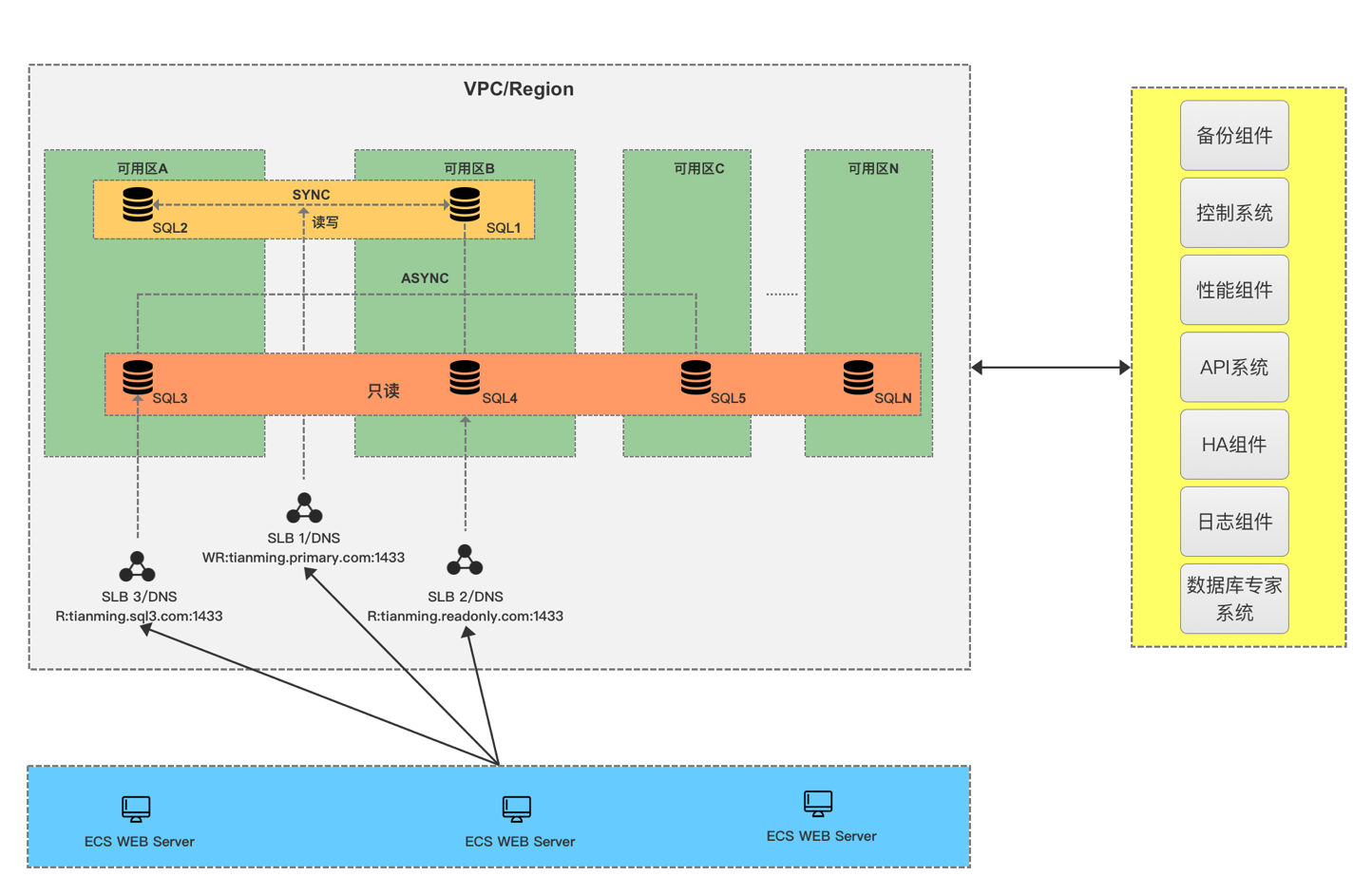
至此SQLServer AlwaysOn已经在阿里云PaaS化,当然目前只是支持最主要功能,后续还有很多可以完善丰富的地方,希望有更多用户了解和使用这个产品并帮他们解决实际问题。
独家揭秘阿里云SQL Server AlwaysOn集群版重大突破相关推荐
- 阿里云重磅发布RDS for SQL Server AlwaysOn集群版
2018年双十一刚过,阿里云数据库发布RDS for SQL Server AlwaysOn集群版,这是业界除微软云SQL Database外,首家云计算公司基于SQL Server最新AlwaysO ...
- SQL Server AlwaysOn 集群 关于主Server IP与Listener IP调换的详细测试
1. 背景 SQL Server 搭建AlwaysOn后,我们就希望程序连接时使用虚拟的侦听IP(Listener IP),而不再是主Server 的IP.如果我们有采用中间件,则可以在配置中,直接用 ...
- SQL Server AlwaysOn集群在辅助副本创建只读账号
由于大数据需要抽取SQL Server中的数据,为了减轻主库压力,决定在辅助副本中创建只读账号.然而再辅助副本创建账号时发现有报错.提示无法更新数据库,因为数据库是只读的. 在我原来的理解中,创建账号 ...
- 【沉淀】懵懂入行,但一做就沉心钻研十年——记访谈阿里云SQL Server专家杨钊...
<沉淀>是云栖社区展示专家风采的人物栏目.它呈现每个专家独一无二的人生经历.认识和感悟的同时,也能帮助你沉淀技术,收获对技术和人生的判断.我们的想法是:"若你想精进为一个很厉害的 ...
- 懵懂入行,但一做就沉心钻研十年——记访谈阿里云SQL Server专家杨钊
杨钊,花名石沫,阿里云SQL Server数据库专家.在数据库设计.开发与规范,数据高可用与容灾,数据库的优化,数据库的自动化和智能化方向积累大量的经验,处理过超大群集和超高并发场景的业务. 作为一个 ...
- 阿里云ESC搭建hadoop集群
阿里云ESC搭建hadoop集群 前置 购买至少三台服务器,为了节约成本借了两个账号买了三台同一区域的服务器,安装的是 centos7:因此设计到不同账号相同地域之间通讯问题,阿里给了解决方案,详情参 ...
- 通过阿里云ecs部署k8s集群
通过阿里云ecs部署k8s集群 1. 搭建环境 2. 安装步骤 禁用Selinux Restart Docker 此处仅有两台服务器,一台master节点,一台node节点,后期可按照步骤继续增加no ...
- 阿里云超算异构Spot集群,助力深势科技30%成本驱动MDaaS海量算力
本文主要介绍药物研发算法科技公司深势科技是如何实现低成本在阿里云上构建分子模拟MDaaS (Molecular Dynamics as a Service)超算集群. 客户简介 公司名称:深势科技 公 ...
- Docker——阿里云搭建Docker Swarm集群
阿里云搭建Docker Swarm集群 Docker Swarm概念 环境部署 Swarm集群搭建 安装Docker 配置阿里云镜像加速 搭建集群 Raft一致性算法 Swarm集群弹性创建服务(扩缩 ...
最新文章
- Access应用日志一
- C语言的第一例,简单易操作
- 进入环境_如何进入Windows恢复环境(WinRE)
- java日志——基本日志+高级日志
- 【Prince2科普】P2七大主题之变更
- 64位系统目录在那里_旷视王珏:前Adobe首席科学家,手握64项专利,曾助力奥斯卡...
- IBM推出Watson广告服务:认知计算将重塑营销市场?
- linux并发控制方法,linux系统并发控制
- python批量读取Excel文件
- 2022年美赛C题M奖思路复盘(附代码、附论文)
- 黑苹果 驱动有线网卡 Intel i225-V 驱动教程
- android NFC getId()后进制转换
- fedora20 安装nvidia独立显卡驱动
- ti最新版akamai的js分析与逆向------002小试牛刀
- opencv形态学-开操作和闭操作
- 通过echarts绘制双十一销量实时统计图表
- API接口安全思考和最佳实践
- 微信公众号点击列表进入详情页
- SSH框架整合3——原生态SessionFactory
- 深度学习 3d人脸 重建_深度学习实时3D人脸跟踪
热门文章
- rabbitmq windows 连接 linux,在Centos7中,从主机 Windows 上无法远程访问 Linux 上rabbitmq的解决方法...
- 服务器php 启动命令_php启动内置服务器
- java的linux内核构建,构建一个Docker 的Java编译环境
- java.util.timer 定时任务_java.util系列源码解读之Timer定时器
- php操作mysql数据库的扩展有哪些_PHP使用PDO扩展操作mysql数据库
- 如何创建_重庆市百科如何创建
- unity3d发布linux版本_密码管理器 1Password 发布第一个 Linux 测试版本
- php 过滤所有html,php过滤所有html标签_PHP教程
- python ctypes实现api测试_Windows下通过Python 3.x的ctypes调用C接口
- mysql 压测结果_用mysqlslap压测mysql