海量小文件存储(转)
Web2.0网站,数据内容以几何级数增长,尤其是那些小文件,几K~几百K不等,数量巨多,传统的文件系统处理起来很是吃力,很多网站在scaling的过程中都遇到了这样的问题:磁盘IO过高;备份困难;单点问题,容量和读写无法水平扩展,还存在故障的可能。
YouTube也碰到这样的问题,每一个视频有4个缩微图,这样的话缩微图数量是视频数量的四倍,想象一下YouTube有多少视频,看一下他们遇到的问题:
大量的磁盘寻址,在操作系统层面出现inodes cache和page cache的问题单个目录文件数限制,尤其是Ext3文件系统,采用目录分级的做法,最新的Linux Kernel 2.6优化了Ext3文件系统,单目录能存储的文件数提高了100倍,但是把所有的文件存一个目录不是一个好的方法高RPS(requests per second每秒请求数),因为一个页面可能要显示60个缩微图高负载下Apache性能差Apache前面加一层Squid,能抗一会,但负载上来之后,性能下降厉害,由300RPS降到20RPS尝试lighttpd,但是lighttpd是单线程,多线程的话也有问题,线程之间缓存不能共享加一台服务器的话需要24小时,因为文件数太多了存在“冷却”的问题,重启服务器后需要6~10个小时才能缓存好
YouTube的解决方案是Google的BigTable,一般人没戏。(原文参见:http://www.hfadeel.com/Blog/?p=127)
Facebook也遇到了同样的问题,他们的方案参见:http://www.dbanotes.net/arch/facebook_photos_arch.html,他们经历了三个阶段:
NFS共享,挂一个盘阵,APP服务器通过NFS读写加一个中间层Cachr:eventHttp + memcached(lighttpd + mod_memcache实现同样的功能),后端还是通过NFS连盘阵Haystacks,详细的去读这里(E文)。
对于一般的网站来说,实用的方案有哪些呢?
一、NFS共享
是的,这个有很多问题,但实施成本低,很多公司都在用(我们也在用),在不是那么多文件,不是那么高并发的情况下还是很不错的,设置Hash目录,不要让一个目录下文件数过多,对于一般的网站来说足够用了。
备份确实是一个问题,如果不是海量的话,根据文件更新时间每天增量备份+周期性的全量备份应该可以。
二、文件存数据库
真有人这么做,手机之家用MySQL建了256个表来存储超过1T的文件,前端加一个多级缓存(具体未知,也许就是memcached也许还是文件),数据库做数据备份用,他们用起来觉得还不错。
或者觉得MySQL太重,试试key->value的数据库,比如BDB,Tokyo Cabinet等。
三、分布式文件系统
开源的很多,好看簿用的是MogileFS,与memcached师出同门。傲游用MFS来存储用户的收藏夹文件,详细文章参见:分布式文件系统MFS(moosefs)实现存储共享(一) 、(二),据说数百万轻松处理。
分布式文件系统好处是可以均衡读写压力,数据可靠性大大增加,某个数据节点挂了也没事。
还不行?自己DIY一个去吧,豆瓣就这么做的,TokyoCabinet做为底层存储,封装了一个memcached协议接口(与Tokyo Tyrant何异?),一致性哈希,应用程序根据哈希规则在node中读写数据:
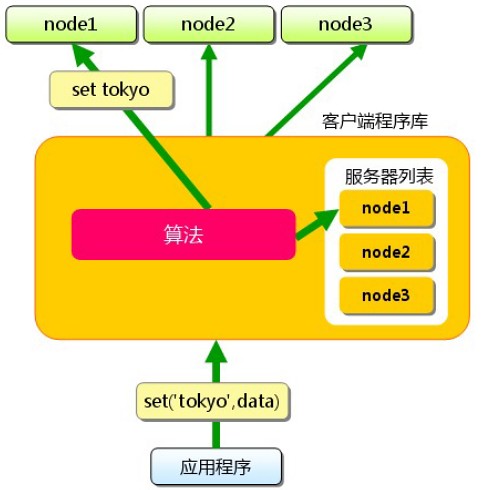
DoubanFS结构图,版权由charlee所有
From:http://blogread.cn/it/article/239?f=sinat
转载于:https://www.cnblogs.com/bizhu/archive/2012/11/29/2794211.html
海量小文件存储(转)相关推荐
- 海量小文件存储与Ceph实践
海量小文件存储(简称LOSF,lots of small files)出现后,就一直是业界的难题,众多博文(如[1])对此问题进行了阐述与分析,许多互联网公司也针对自己的具体场景研发了自己的存储方案( ...
- FastDFS小文件存储原理
小文件存储 需要小文件存储的原因 小文件应用场景 小文件存储带来的问题 FastDFS小文件机制配置 FastDFS合并存储文件命名与文件 启动小文件存储时服务返回给客户端的fileid有变化 Tru ...
- StarGFS海量小文件的高性能存储和保护方案
一.小文件场景和挑战 1.1 小文件的场景 当今各行各业每天都有海量的数据产生.据IDC预测达到2025年,全球将总共产生175ZB文件.接下去5年时间内产生的数据量将会比过去几十年人类产生数据量总和 ...
- 【云原生AI】Fluid + JindoFS 助力微博海量小文件模型训练速度提升 18 倍
简介: 深度学习平台在微博社交业务扮演着重要的角色.计算存储分离架构下,微博深度学习平台在数据访问与调度方面存在性能低效的问题.本文将介绍微博内部设计实现的一套全新的基于 Fluid(内含 Jindo ...
- 海量小文件场景下训练加速优化之路
作者:星辰算力平台 1. 背景 随着大数据.人工智能技术的蓬勃发展,人类对于算力资源的需求也迎来大幅度的增长.在腾讯内部,星辰算力平台以降本增效为目标,整合了公司的GPU训练卡资源,为算法工程师们提供 ...
- # 小文件大问题——海量小文件解决方案初探
小文件大问题--海量小文件解决方案初探 作者 陈闯 背景: 当今互联网,数据呈现爆炸式增长,社交网络.移动通信.网络视频.电子商务等各种应用往往能产生亿级甚至十亿.百亿级的海量小文件.由于在元数据管理 ...
- python 提高文件查询效率_Python 大量小文件存储提高效率的简单示例
这篇文章主要为大家详细介绍了Python 大量小文件存储提高效率的简单示例,具有一定的参考价值,可以用来参考一下. 对python这个高级语言感兴趣的小伙伴,下面一起跟随512笔记的小编两巴掌来看看吧 ...
- clean后class文件全部丢失_大数据专家,详解HadoopMapReduce处理海量小文件:压缩文件
前言 在HDFS上存储文件,大量的小文件是非常消耗NameNode内存的,因为每个文件都会分配一个文件描述符,NameNode需要在启动的时候加载全部文件的描述信息,所以文件越多,对NameNode来 ...
- windows server 驱动精灵_还在用Windows文件共享?我来教你一键摆脱Windows海量小文件使用和备份的噩梦...
每当我问到客户,"你用什么存储产品作为文件共享?" 经常听到的一个答案(自豪滴)是,"文件共享需要存储么?我们用Windows就可以做到." Windows就是 ...
最新文章
- 找不到或无法加载主类 org.jivesoftware.openfire.starter.ServerStarter
- php根据修改时间删除指定目录下文件
- 【论文笔记】Region-based Convolutional Networks for Accurate Object Detection and Segmentation
- python不支持_不支持的操作:不可写的python
- 解决Ubuntu下切换到root用户后没有声音问题
- 怎样教育孩子,能让孩子有更好的学习?
- 一些经常会用到的Javascript检测函数
- 加入百度地图遇到 framework not found BaiduMapAPI***
- android助手专业版,安卓助手-安卓助手app专业版下载-安卓助手付费版-电玩咖
- 2022中山大学计算机考研专硕初试经验分享
- java实现微信退款
- Python fractions模块 —— 分数相关函数
- 生物信息学Bioinformatics学习笔记(三)-高通量测序
- python 制作网站教程_Python爬取网站博客教程并制作成PDF
- 【量化策略】横盘策略20211209
- 不知不觉发财10大秘诀(转)
- 用js计算12个月的社保缴纳总额-企业信息公示
- 进阶题73 纯粹合数
- 01、低噪声放大电路设计——ATF-54143
- 面经/字节跳动,面试流程及问题分享(附答案)
热门文章
- comparator比较器用法_电压跟随器的这些点,确定都懂了吗?如果设计成同相端追随反向端会怎样? #运放...
- 照片浏览器_2020护考报名失败!只因照片太大瞎忙乎三小时...
- win10计算机系统优化设置,有效提升Win10运行速度的基本优化设置方案
- xlrd读取所有sheet名_如何在Python对Excel进行读取
- 计算机用户名SYSTEN,system是什么用户
- 高中电子技术——指针式万用表调零
- NAT-PT (Network Address Translation-Protocol)网络地址转换协议转换
- 网易高并发优化 | 公开课-02
- PAT (Basic Level) Practice1001 害死人不偿命的(3n+1)猜想
- 享元模式在文本编辑器中的应用