不止性能优化,移动端 APM 产品研发技能
2019独角兽企业重金招聘Python工程师标准>>> 
江赛,听云研发总监,负责听云移动端产品的研发工作。在 OSC 第 55 期广州源创会上发表了题为《移动端 APM 产品研发技能》的演讲。现场介绍移动端 APM 产品底层技术细节与实现方法, 演示如何通过在代码中埋点来解决移动 APP 的性能问题 ;分享在实际产品开发中碰到的问题和一些经验,以及一些技术细节。

一、移动 APM 概况
移动端 APM 产品,从字面上来理解,APM(application performance monitor)就是应用性能相关的监测,可随着现在产品的边界越来越模糊,监测的范围不仅包括 performance,还包括用户行为,以及在稳定性、卡顿、崩溃这些方面的数据都有监测,已经远远超过 performance 这一个角度,毕竟产品结构越来越大了。
所以对于这样一个产品,要做数据监控和数据分析,它的基本前提是什么呢?就是必须要采集大龄的数据,包括一些基本的数据。将这些数据放在不同的维度分析。
举个例子,从网络的角度来说,有用户反馈某个产品在某个运营商范围接入的情况下,网络性能很差。这个数据就会直接从报表里面去体现,因为会采集到一些基本的网络数据,也会采集到其他的不同的维护数据,然后这些问题就会展现出来。
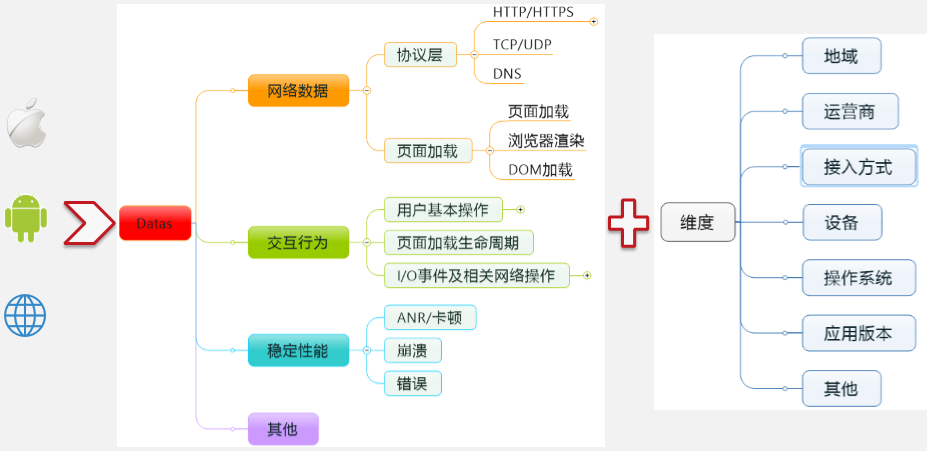
从这张图来看,数据是我们产品的一个移动研究方向,而且我们的产品会支持苹果、Android 还有 Web 这三端。会采集的数据包括:网络数据、交互行为数据、稳定性相关数据和一些其他的数据(例如采集手机的信号。这些数据会有一些不同的应用,比如说运营商,它在部署各种基站的时候,会有一个参考值,就是哪个地方信号不太好,它会在那里部署基站,但是怎样知道信号不好呢?不可能在每一个角落都放一台手机看信号如何。此时我们的产品就可以完成这个任务,移动端可以采集到这些信号,然后根据不同的地域来分析手机信号分布情况),这就是采集数据的大概内容。
然后往下细分会有更多类别。例如网络数据,从应用层的数据来看,主要是采集 HTTP/HTTPS 的数据,但又不仅仅是 HTTP/HTTPS 数据,比如说一条 HTTP 请求,假如从 Web 上或者是浏览器中输入一个网址,我们会把所有的 HTTP 请求内容分析出来,例如出去包的长度、回来包的长度和 response 的时间等等。如果出现错误的时候,还会把 response 的包和头部信息打印出来,会把 HTTP 协议请求全部分析一遍,分析字节大小,响应时间,还有错误这些情况。然后还会往下分析,比如 HTTP 请求访问之前需要做 TCP 链接的所用时间。
这些数据正常情况下是没有办法采集的,需要特定的技术,这个也是今天我要分享的内容 —— 我们是如何抓取这些底层数据的。
还有一个是页面加载的数据,页面的加载包含三种数据(页面加载、浏览器渲染和 DOM 加载)。Android 和 iOS 会通过 JS 注入监控一些数据,和监测一些页面加载的详细数据。
关于交互行为数据,举个例子,产品会监控用户在一个应用里的一些点击行为,像一系列的滑动,对菜单的选中。比如说点击一个按钮以后,如果它的响应时间过长,一般阈值是 3 秒钟,如果点击完按钮 3 秒后才处理完,我们会自动把事件抓取并上报。现在我们还可以做到,当监测到卡顿以后,会自动去把当前的操作截屏(可以做一秒钟 10 帧的截屏)。通过一秒钟 10 帧的数据而生成的动画,也就能看到卡顿的时候所在的页面。这个产品暂时还没发布,但技术上已经实现了。现在关键的问题是普通的截屏会非常影响性能和耗电,现在能做到 1 帧数据在 5 毫秒左右,效率非常高,截屏速度也非常快。
关于稳定性,稳定性就是崩溃和 ANR(卡顿)相关的。有一些开源项目可以支持这种需求,所以类似崩溃、ANR 这些数据的采集难度不大。
收集了不同的源数据以后,就会接触到不同的维度,这些维度包括地域、运营商、接入方式、设备、操作系统、应用版本以及其他一些维度数据。根据这些维度数据和一些自定义的相关信息,会做特定的网络数据监控。通过这个,就可以看到对应的不同源数据在不同的维度组合下的结果,比如可以选择某一个地方、某一个运营商或者某个设备在某种接入方式上,它的 HTTP 请求效率,这就是基本源数据以及基本数据的应用。
很多应用厂商也尝试自己抓取这些庞大的数据,但如果用传统的方式来做,就意味着需要打很多的点,比如说一段代码,需要在 excute 进入的地方打一个点,出去的地方也打一个点,同时还要把参数抓取下来做参数的解析,这就意味着如果手工来做这种工作,工作量会非常大,因为所有监控的地方都要埋点,而且一旦这段代码发生变化,也就要重新去修改埋点的代码,而且重新去埋点,也会导致工作量非常大。
因此做数据采集的时候,我们有一个基本原则:尽量不让程序员做任何事情。添加一行初始化代码就够了。那么如何采集到这些数据?这就是数据采集的基础,自动埋点技术。这些埋点的操作不需要自己做,会通过程序自动完成。下面介绍几种自动埋点的方法。
二、APM 实现 —— 自动埋点技术的介绍
主要通过以下的技术手段实现:
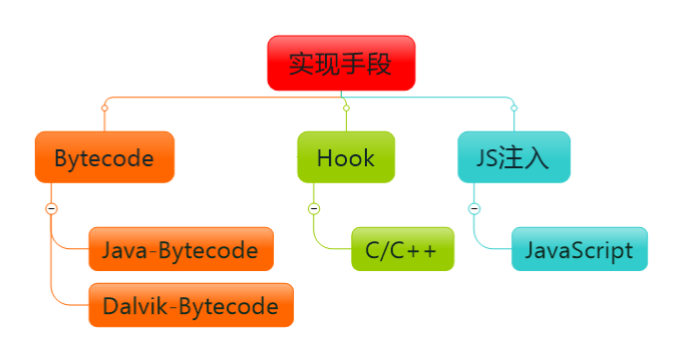
下面对每一个技术细节展开进行讲述:
对于 ByteCode 的处理,支持 Java ByteCode 的注入以及 Dalvik ByteCode 的注入。在内应用层会提供 Hook 方法来 Hook 分析 C/C++ 代码,JavaScript 相关的会通过 JS 注入的方式来采集数据。
看起来比较抽象,下面一一展开来描述:
1. 从 Java 源代码到 Dalvik Bytecode
对于 Android 程序员来说,大部分代码都是用 Java 写的,拓展名是 .java 的文件。但真正打包编译完以后,会生成 apk 文件。如果你把它解压会看到有一个 dex 文件,因为现在的包越来越大了,可能会有多个 dex 文件,那么这些 .java 文件是怎么变成 dex 文件的,这个过程是如何的?
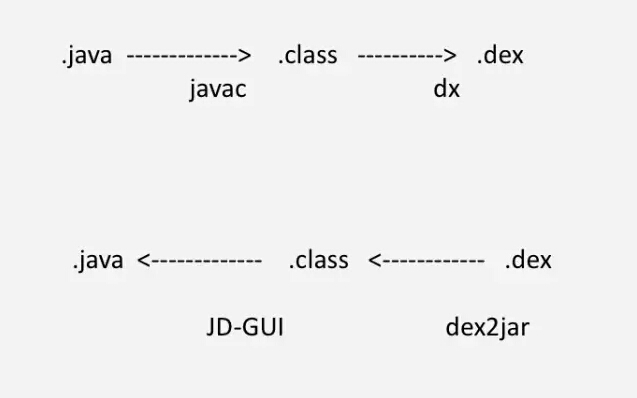
编译的过程是首先从 .java 文件到 class 文件,然后 class 文件再到 dex 文件。.java 文件到 class 文件是通过 javac 编译,然后再通过 Android SDK 下的一个工具 dx 将 class 文件编译成 dex 文件。
在 Android 的虚拟机里面,正常情况下编译完以后,Java 虚拟机里面执行的是 .class 文件(即 Java Bytecode),但是在 Android 的 Dalvik 虚拟机或者 ART 里,不能直接执行 Java Bytecode,因此需要将 Java Bytecode 做一次转换,转成 Dalvik Bytecode。该过程就是使用 dx 这个工具转换的,而且是在编译的时候完成。其实就是不同的格式表述,.class 文件只是用了另外一种字节码的格式来表述。这个东西看似很简单,但如果了解编译的过程,就可以做很多的事情。 class 文件生成了以后,还没有转成 dex 文件这一步,就可以通过 ASM 技术,对 Java Bytecode 进行改写,从而插入要监控的代码。
下面通过一个实际的例子来讲述。
先来看代码:
Example Java source: Foo.java
class Foo {public static void main(String[] args) {System.out.println("Hello, world"); } public int method(int i1, int i2) {int i3 = i1 * i2;return i3 * 2;}
}这段代码的功能很简单,里面有一个方法,传进来两个参数,先将这两个参数相乘,再把结果除以 2 返回。通过 javac 把它编译成 Java Bytecode,然后用 javap 可以看到 Java Bytecode 的指令。这是一个很简单的 Java Bytecode 指令,取得两个参数,然后做乘积。imul 指令就是 Java Bytecode 的一个基本指令,之后就是把两个参数压栈,imul 指令会 pop 出栈底的两个数。
$ javac Foo.java
$ javap -v Foopublic int method(int, int);flags: ACC_PUBLICCode:stack=2, locals=4, args_size=30: iload_11: iload_22: imul3: istore_34: iload_35: iconst_26: imul7: ireturnLineNumberTable:line 6: 0line 7: 4
可以看到,方法的名字和参数都没变。其实 Java Bytecode 和 Dalvik Bytecode 很大的一个区别就在这里,Java Bytecode 需要借助堆栈来模拟这种操作(乘法、除法),通过栈来临时存放这些变量,但在 Dalvik Bytecode 里就不是通过栈来实现,而是通过寄存器实现。看一个栈的操作示例:
Stack
Before After
value1 result
value2 ...
... ... (imul指令对栈的操作)先是传入两个变量 value1 和 value2,imul 执行完以后就把结果加到栈里边,这就是一个典型的栈操作。
因为 Java Bytecode 没有办法在安卓手机上运行,因此需要将 Java Bytecode 继续通过 dx 工具把它编译成 Dalvik Bytecode。很多时候大家都是通过编译工具进行编译,没有尝试通过手工进行编译,建议可以尝试一下。通过 dx 就可以把 class 文件编译成一个 dex 文件,然后通过 dexdump 命令,把 dex 文件 dump 出来。可以看到,刚才的 Java Bytecode 里几行乘法指令,在这就就变成了一行指令。

可以看到,首先指令长度变小了,第二 Dalvike Bytecode 引入了寄存器的概念。而 Java Bytecode 的函数调用全部是通过栈来模拟的。这种方式对代码性能,以及代码结构大小有影响,而且寄存器本身的性能要比栈高很多。
再看一下,刚刚那三行代码两次 pop 操作,一次乘积,一次 push 操作,现在变成这样一个操作。就是这个指令,经过目标计算器,源计算器,操作完以后,存在源计算机,现在变成这种形式。
下面来看一下 Java Bytecode 与 Dalvik Bytecode 的对比:
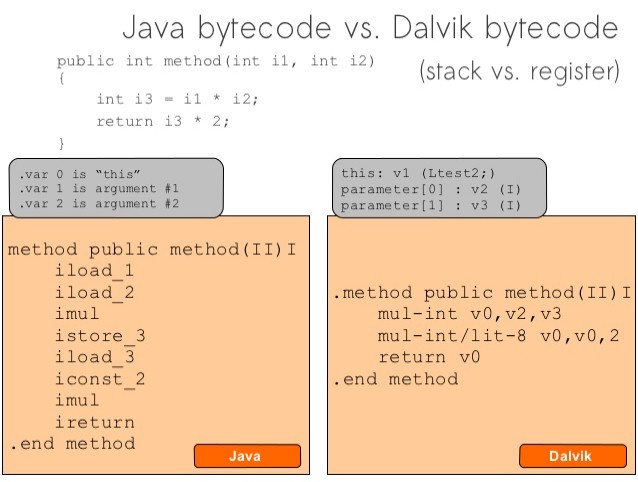
Java Bytecode 和 Dalvik Bytecode 有什么区别?前者用的是栈,后者用的是寄存器。
这些对于自动插码技术有什么作用?前面提到的指令级插码又有什么作用?其实这些是基本工作,首先要对Java Bytecode 非常的熟悉,之后要了解整个编译过程。

这个代码就是通过动作分析 Java Bytecode 注入的,反编译出来就是这样。我们需要分析一些关键的方法,还有特定方法,找到函数的头和尾,插入需要的代码,第一步为获取开始时间;第二,获取完成的时间,之后进行上报。像做一些错误处理,会对异常进行捕捉,这样就可以自动分析你的 Bytecode 来做注入。
还有一个特殊的情况,就是需要监控的是这个调用,或者说监控这个调用的反馈值,这些情况都会出现。但所有的变化都是基于对 Bytecode 上下文的理解,然后插入对应的指令。这个技术不是我们独创的,ASM 技术已经有很多年了,各位可以去看一些开源的 ASM 项目。
还有一个技术,Java Bytecode 注入是我们产品现在主要的注入方法,但是也还有很多其他注入的方法,下面要讲的就是另外一种的方式 —— 通过 .smali 注入,具体的逻辑如下图所示:
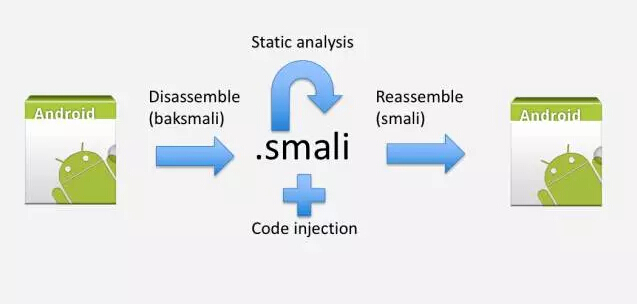
通过一些 smali 反编译工具,转成 smali 文件,静态分析这些文件,分析完以后会做代码的注入,然后重新打包,再加一个签名就可以了。smali 不是 Android 官方的 Bytecode,是一个开源的 Bytecode。
这些大家都不陌生,做 APP 开发很多时候会用这些工具帮助分析一些事情。同样你也可以借鉴一些新的思路,通过这种方式分析 APK。认为存在恶意行为就分析。另外还可以做动态调试,把一些参数打印出来。
比如说写了一个工程,可以做一个定制,写一个简单的SDK。分析一个 APP 的时候,需要分析其网络行为,就把 SDK 注入进去,然后打包,之后看网络访问过程当中访问的什么主机、IP。如果有加密,那就通过另外一个话题对流做解密,一般的情况下,传输的数据都可以看到。
2. APM 实现 —— native inline hook
因为 Android 中很多代码不一定是用 Java 写的,也可以用 C/C++ 写。这种代码不能通过 Bytecode 的方式来注入。看下面这张图
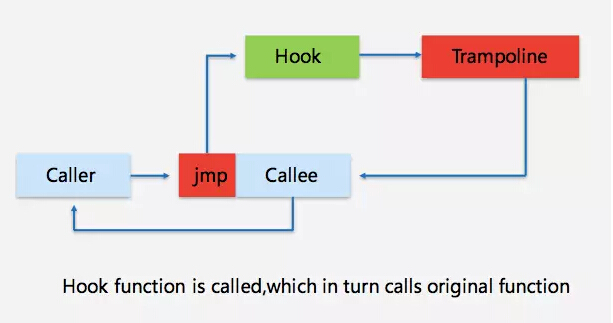
这是一个普通的调用关系,调用者调用被调用者执行,执行完以后返回。这是正常的处理流程。但如果要监测这个被调用的方法,想要拿到参数,以及这个方法执行多长时间,还想知道这个返回值,如何实现?逻辑上很简单,把被调用方法头几行指令做修改。把指令改成 JMP 指令,JMP 到这个监控方法里面,通过 hook 的方式做跳转。这里做参数、相关函数的记录,做完以后再重新按照这个轨迹返回。
如何做到这一步呢?首先,把头几行做跳转。这需要对 ARM 指令,对各种架构比较熟悉才能做到。大部分程序员都学过汇编指令,但遇到的时候觉得很复杂。实际上并不复杂,只是接触的少,其实 ARM 32 指令不多。根据后面 3 位,4 位可以做区分。还有一些分值指令,数学预算指令。那么,分析这些指令的时候,首先对于指令架构要很熟悉,而且,要知道源计算机,目标计算器在哪里。比如说,最终跳转指令的时候,要知道跳转怎么计算,24 位 offset 怎么跳转,24 位怎么转换为绝对地址。如果把基本概念弄明白,不要求会写,就可以做下面的事情了。
先看一下刚刚说的方法怎么做到的。
需要改写这个方法的头两行指令,头两行指令替换成这样的指令。PC 指令就是当前运行时的逻辑地址,PC 寄存器。因为 ARM 32 会做一个预加载,这个会指向下两行指令。如果将 PC 指令减 4,就是变为 PC 加 4,这个操作是把下一行指令移到 PC 寄存器中。如果改写 PC 寄存器就实现了跳转,虽然只有两行代码,但是可以想到这其实要花很长的时间。
这需要了解 ARM 指令,知道这个 ARM 指令执行的过程,还要知道通过修改 PC 指令实现跳转。通过改写头两行指令,就可以把它跳转到任何地址。而且这个地址就是 4 字节,32 位,4G 空间。可以跳转到任何函数,但这还没结束。后两行做了以后,要把头两行移到另外一个地方。但是,移动指令的时候因为一些指令本身就是依赖 PC 指令,所以要去做指令的修复。因此更多的工作其实就是在修复这些被移走的指令。下面的例子是一个 B 指令修改,是写实际代码的一部分。


来看一下这一行代码是什么意思。123,2 个 0 是 8 位,8123,高位是 0,0,F。如果是 31 到 32 位,我们现在取的值是实际上就是取这 4 位,1234,取 4 位的值,通过这一行指令取这个值。然后通过 4 个值区分这些指令类型。取出来了以后,如果这个是 A,可以看一下 B 指令的方式,1010,这个是 1010,一个是1,就是 BR 指令,跳出去再跳回来。如果无条件这里就是 0,1010 正好是多少就是 10,就是 A,如果是 B指令。B 指令跳转依赖寄存器,首先算出来这个地址,把绝对地址存在这里,头一行指令在这里。
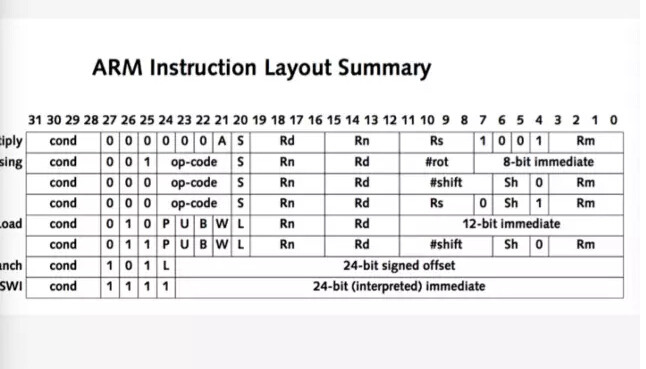
如果要真正把这个弄明白,可以通过编写 C 代码做到。如果做到这样觉得很有成就感,把系统的 malloc,或者是 new 给 hook 住,可以监测所有的 native 内存申请和释放。
将 hook 技术应用在产品上面,发现很多的产品都是依赖这个技术的。比如安全方面,很多产品也是通过这种方式做的。还有通过这种方式来做一些底层资源修改和调度,这个可以用在很多的方面。因为技术是为了产品服务的,只要把技术弄明白就可以了,最终还是会产品化。这是像我这种做很多年技术的人切身的体会。有时候也是会沉迷在技术里面,总觉得做一些产品的工作就是浪费时间。现在想想,并不如此。
最后一点,前面讲的这些,都是一些自动嵌码技术,包括 Java 应用,还有 C++ 应用。数据都是自动采集的。在编译时插码,在运行时使用 hook,这些都可以做,因为产品已经很成熟。听云现在运行着 5 亿终端,有一些大的电商类也已经在用听云的 SDK。
举个例子,想通过听云对 TCP 层的监测结果来观察负载均衡调度情况,同一个主机有一堆 IP,正常情况下是没有办法拿到这个结果的。我们不仅可以拿到 DNS 时间,还可以拿到 DNS 结果,真实 IP 是什么,通过这些情况可以看到负载均衡服务器,即调度出来的结果情况以及 IP 分布情况,另外还有 TCP 三次握手时间,SSL 握手时间等。
这些数据都非常的有用。安卓程序员经常纠结使用哪些网络库,是 urlconnection,还是 okhttp。分别都有什么优缺点。这个我们就给你们做了一个强大的技术验证。
第一个问题,比如说,在程序里面连着发了 10 个 request。现在 HTTP 访问的传输层都是基于 TCP,但每发一次 request 都要做一次 TCP 连接吗?仔细想想,对于同一个地址肯定没有必要,这样做就是浪费时间。然后遇到的就是 TCP 复用技术,通过这种技术,就可以监测对于一个同一个目标地址发生多少次 TCP connect 操作,这就知道在这个访问时间内有没有复用之前的连接。所以,就可以得出一个指标数据,即发生了多少次 TCP 连接。
下图是 APM 产品
通过这种技术可以监测一些关键指标数据,因为采取底层原数据,很多点就会把这个原数据还原出应用场景,客户想出来的场景比我们多。这些原数据都是最宝贵的数据,并且最关键的是不需要你再去做额外的工作,也是 APM 的价值所在。
三、总结
今天讲的内容比较抽象,讲的是研发过程中的一些经验,技巧和总结。这个技术可能对各位现在的工作不会有直接的帮助,因为太底层,但也希望可以给各位对自己工作的方式带去一定的思考。无论怎样,还是需要把底层的知识弄明白,毕竟这对于写代码有帮助。
转载于:https://my.oschina.net/osccreate/blog/795760
不止性能优化,移动端 APM 产品研发技能相关推荐
- 前端性能优化-服务端和网络优化-极客时间
前端性能优化 目录 前端性能优化 第六章:服务端和网络优化 6.1 CDN--如何合理配置CDN缓存 6.2 DNS--主流的DNS优化方法有哪些? 6.3 HTTP:如何减少 HTTP 请求 6.4 ...
- 从 FFmpeg 性能加速到端云一体媒体系统优化
简介:7 月 31 日,阿里云视频云受邀参加由开放原子开源基金会.Linux 基金会亚太区.开源中国共同举办的全球开源技术峰会 GOTC 2021 ,在大会的音视频性能优化专场上,分享了开源 FFmp ...
- 智能音箱场景下的性能优化
QCon是由InfoQ主办的综合性技术盛会,今年是Qcon举办的第10个年头,半吊子全栈工匠有幸作为演讲嘉宾分享一个近两年来的实践经验--智能音箱场景下的性能优化,隶属于曾波老师出品的"场景 ...
- 深度讲解:web前端性能优化
一.课程简介: 1.课程大纲 涉及到的分类 网络层面 构建层面 浏览器渲染层面 服务端层面 涉及到的功能点 资源的合并与压缩 图片编解码原理和类型选择 浏览器渲染机制 懒加载预加载 浏览器存储 缓存机 ...
- web前端性能优化总结
概括 涉及到的分类 网络层面 构建层面 浏览器渲染层面 服务端层面 涉及到的功能点 资源的合并与压缩 图片编解码原理和类型选择 浏览器渲染机制 懒加载预加载 浏览器存储 缓存机制 PWA Vue-SS ...
- 课时 17-深入理解 etcd:etcd 性能优化实践(陈星宇)
本文将主要分享以下五方面的内容: etcd 前节课程回顾复习: 理解 etcd 性能: etcd 性能优化 -server 端: etcd 性能优化 -client 端. etcd 前节课程回顾复习 ...
- 从零开始入门 K8s | etcd 性能优化实践
作者 | 陈星宇(宇慕) 阿里云基础技术中台技术专家 本文整理自<CNCF x Alibaba 云原生技术公开课>第 17 讲. 导读:etcd 是容器云平台用于存储关键元信息的组件.阿里 ...
- IT:前端进阶技术路线图(初级→中级→高级)之初级(研发工具/HTML/CSS/JS/浏览器)/中级(研发链路/工程化/库/框架/性能优化/工作原理)/高级(搭建/中后台/体验管理等)之详细攻略
IT:前端进阶技术路线图(初级→中级→高级)之初级(研发工具/HTML/CSS/JS/浏览器)/中级(研发链路/工程化/库/框架/性能优化/工作原理)/高级(搭建/Node/IDE/中后台/体验管理/ ...
- Unity移动端游戏性能优化简谱之 常见游戏内存控制
<Unity移动端游戏性能优化简谱>从Unity移动端游戏优化的一些基础讨论出发,例举和分析了近几年基于Unity开发的移动端游戏项目中最为常见的部分性能问题,并展示了如何使用UWA的性能 ...
最新文章
- vue 编写H5页面在公众号外部获取手机本地坐标经纬度
- 「懒人」LeCun想让计算机自己编程?网友:还差10个 GPT-3
- python coding_python开头的coding设置方法
- editplus 配置 golang 开发调试环境
- 作业 3 利用分支和循环结构解决问题
- How I can Built A-Z index site map in my website
- python 字符串前加r和f
- mybatis学习教程中级(十)mybatis和ehcache缓存框架整合(重点)
- .DateTimeToStr函数专用优化版
- python之路 day5
- vuex的计算属性_vue中vuex的五个属性和基本用法
- 在CentOS中安装MySql数据库教程
- Notepad++ 安装jsonview插件
- ios tableView截长屏图片,第三方分享
- 《单片机原理及应用(魏洪磊)》第七章第8题
- HTMl--基础样式的使用
- python智慧城市_智慧城市背景下Python机器学习项目实战案例分享
- 谈谈如何建立价值驱动的数据战略
- 龙芯电脑平台kubernetes集群编译及部署方案
- win10+vs2017配置MPI和OpenMP