梯度反传_反事实政策梯度解释
梯度反传
Among many of its challenges, multi-agent reinforcement learning has one obstacle that is overlooked: “credit assignment.” To explain this concept, let’s first take a look at an example…
在许多挑战中,多主体强化学习有一个被忽略的障碍:“学分分配”。 为了解释这个概念,让我们首先看一个例子……
Say we have two robots, robot A and robot B. They are trying to collaboratively push a box into a hole. In addition, they both receive a reward of 1 if they push it in and 0 otherwise. In the ideal case, the two robots would both push the box towards the hole at the same time, maximizing the speed and efficiency of the task.
假设我们有两个机器人,即机器人A和机器人B。他们正在尝试将盒子推入一个洞中。 此外,如果他们都将其推入,他们都将获得1的奖励,否则将获得0。 在理想情况下,两个机器人都将盒子同时推向Kong,从而最大程度地提高了任务的速度和效率。
However, suppose that robot A does all the heavy lifting, meaning robot A pushes the box into the hole while robot B stands idly on the sidelines. Even though robot B simply loitered around, both robot A and robot B would receive a reward of 1. In other words, the same behavior is encouraged later on even though robot B executed a suboptimal policy. This is when the issue of “credit assignment” comes in. In multi-agent systems, we need to find a way to give “credit” or reward to agents who contribute to the overall goal, not to those who let others do the work.
但是,假设机器人A完成了所有繁重的工作,这意味着机器人A将箱子推入Kong中,而机器人B空着站在边线上。 即使机器人B只是闲逛, 机器人A 和 机器人B都将获得1的奖励。换句话说, 即使机器人B执行了次优策略,以后也会鼓励相同的行为。 这就是“信用分配”问题出现的时候。在多主体系统中,我们需要找到一种方法,向为总体目标做出贡献的代理人而不是让他人完成工作的代理人给予“信用”或奖励。 。
Okay so what’s the solution? Maybe we only give rewards to agents who contribute to the task itself.
好的,那有什么解决方案? 也许我们只奖励那些为任务本身做出贡献的特工。
比看起来难 (It’s Harder than It Seems)
It seems like this easy solution may just work, but we have to keep several things in mind.
似乎这个简单的解决方案可能会奏效,但我们必须牢记几件事。
First, state representation in reinforcement learning might not be expressive enough to properly tailor rewards like this. In other words, we can’t always easily quantify whether an agent contributed to a given task and dole out rewards accordingly.
首先,强化学习中的状态表示可能不足以适当地调整这样的奖励。 换句话说,我们不能总是轻松地量化代理商是否为给定任务做出贡献并相应地发放奖励。
Secondly, we don’t want to handcraft these rewards, because it defeats the purpose of designing multi-agent algorithms. There’s a fine line between telling agents how to collaborate and encouraging them to learn how to do so.
其次,我们不想手工获得这些奖励,因为它违背了设计多主体算法的目的。 在告诉代理人如何合作与鼓励他们学习如何做之间有一条很好的界限。
一个答案 (One Answer)
Counterfactual policy gradients address this issue of credit assignment without explicitly giving away the answer to its agents.
反事实的政策梯度解决了这一信用分配问题,而没有向其代理商明确给出答案。
The main idea behind the approach? Let’s train agent policies by comparing its actions to other actions it could’ve taken. In other words, an agent will ask itself:
该方法背后的主要思想是什么? 让我们通过将代理的操作与它可能采取的其他操作进行比较来训练代理策略。 换句话说,座席会问自己:
“ Would we have gotten more reward if I had chosen a different action?”
“如果我选择其他动作, 我们会得到更多的回报吗?”
By putting this thinking process into mathematics, counterfactual multi-agent (COMA) policy gradients tackle the issue of credit assignment by quantifying how much an agent contributes to completing a task.
通过将这种思维过程纳入数学,反事实多主体(COMA)策略梯度通过量化代理对完成任务的贡献来解决信用分配问题。
组成部分 (The Components)
COMA is an actor-critic method that uses centralized learning with decentralized execution. This means we train two networks:
COMA是一种参与者批评方法,它使用集中式学习和分散式执行。 这意味着我们训练两个网络:
An actor: given a state, outputs an action
演员 :给定状态,输出动作
A critic: given a state, estimates a value function
评论家 :给定状态,估计价值函数
In addition, the critic is only used during training and is removed during testing. We can think of the critic as the algorithm’s “training wheels.” We use the critic to guide the actor throughout training and give it advice on how to update and learn its policies. However, we remove the critic when it’s time to execute the actor’s learned policies.
此外,注释器仅在训练期间使用,而在测试期间被删除 。 我们可以将批评者视为算法的“训练轮”。 我们使用评论家在整个培训过程中指导演员,并为演员提供有关如何更新和学习其政策的建议。 但是,在执行演员的学习策略时,我们会删除批评者。
For more background on actor-critic methods in general, take a look at Chris Yoon’s in-depth article here:
要获得有关演员批评方法的更多背景知识,请在此处查看Chris Yoon的深入文章:
Let’s start by taking a look at the critic. In this algorithm, we train a network to estimate the joint Q-value across all agents. We’ll discuss the critic’s nuances and how it’s specifically designed later in this article. However, all we need to know now is that we have two copies of the critic network. One is the network we are trying to train and the other is our target network, used for training stability. The target network’s parameters are copied from the training network periodically.
让我们先看一下评论家。 在此算法中,我们训练网络以估计所有代理之间的联合Q值 。 我们将在本文后面讨论评论家的细微差别以及它是如何专门设计的。 但是,我们现在需要知道的是,我们有批评者网络的两个副本。 一个是我们正在尝试训练的网络,另一个是我们用于训练稳定性的目标网络。 定期从训练网络复制目标网络的参数。
To train the networks, we use on-policy training. Instead of using one-step or n-step lookahead to determine our target Q-values, we use TD(lambda), which uses a mixture of n-step returns.
为了训练网络,我们使用了策略训练。 我们使用TD(lambda)而不是使用单步或n步前瞻来确定目标Q值,而是使用n步返回值的混合。
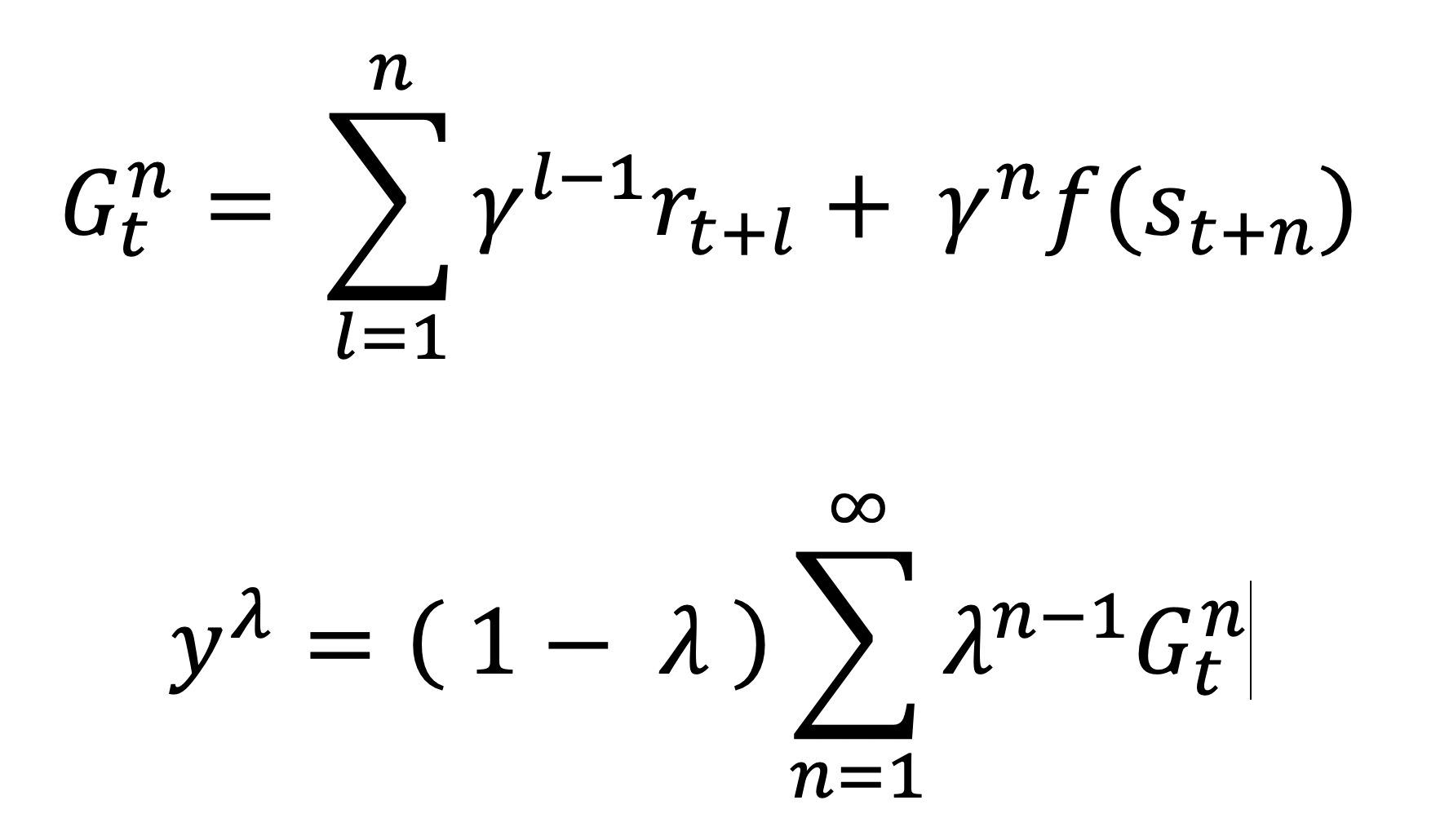
where gamma is the discount factor, r denotes a reward at a specific time step, f is our target value function, and lambda is a hyper-parameter. This seemingly infinite horizon value is calculated using bootstrapped estimates by a target network.
其中gamma是折现因子,r表示在特定时间步长的奖励,f是我们的目标值函数,lambda是超参数。 这个看似无限的地平线值是由目标网络使用自举估计来计算的。
For more information on TD(lambda), Andre Violante’s article provides a fantastic explanation:
有关TD(lambda)的更多信息, Andre Violante的文章提供了一个奇妙的解释:
Finally, we update the critic’s parameters by minimizing this function:
最后,我们通过最小化此函数来更新评论者的参数:

赶上 (The Catch)
Now, you may be wondering: this is nothing new! What makes this algorithm special? The beauty behind this algorithm comes with how we update the actor networks’ parameters.
现在,您可能想知道:这不是什么新鲜事! 是什么使该算法与众不同? 该算法背后的美在于我们如何更新角色网络的参数。
In COMA, we train a probabilistic policy, meaning each action in a given state is chosen with a specific probability that is changed throughout training. In typical actor-critic scenarios, we update the policy by using a policy gradient, typically using the value function as a baseline to create advantage actor-critic:
在COMA中,我们训练概率策略,这意味着在给定状态下的每个动作都以特定概率选择,该概率在整个训练过程中都会改变。 在典型的参与者批评者场景中,我们通过使用策略梯度来更新策略,通常使用价值函数作为基准来创建优势参与者批评者:
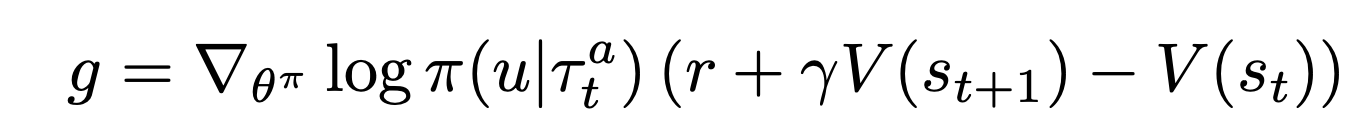
However, there’s a problem here. This fails to address the original issue we were trying to solve: “credit assignment.” We have no notion of “how much any one agent contributes to the task.” Instead, all agents are being given the same amount of “credit,” considering our value function estimates joint value functions. As a result, COMA proposes using a different term as our baseline.
但是,这里有一个问题。 这无法解决我们试图解决的原始问题:“信用分配”。 我们没有“任何一个特工为这项任务做出多少贡献”的概念。 取而代之的是,考虑到我们的价值函数估算联合价值函数 ,所有代理商都会获得相同数量的“信用”。 因此,COMA建议使用其他术语作为我们的基准。
To calculate this counterfactual baseline for each agent, we calculate an expected value over all actions that agent can take while keeping the actions of all other agents fixed.
为了计算每个业务代表的反事实基准 , 我们在保持所有其他业务代表的动作不变的情况下 , 计算了该业务代表可以采取的所有行动的期望值。

Let’s take a step back here and dissect this equation. The first term is just the Q-value associated with the joint state and joint action (all agents). The second term is an expected value. Looking at each individual term in that summation, there are two values being multiplied together. The first is the probability this agent would’ve chosen a specific action. The second is the Q-value of taking that action while all other agents kept their actions fixed.
让我们退后一步,剖析这个方程。 第一项只是与关节状态和关节动作(所有主体)相关的Q值。 第二项是期望值。 看一下该求和中的每个单独的项,有两个值相乘在一起。 首先是该特工选择特定动作的可能性。 第二个是在所有其他代理保持其动作固定的同时执行该动作的Q值。
Now, why does this work? Intuitively, by using this baseline, the agent knows how much reward this action contributes relative to all other actions it could’ve taken. In doing so, it can better distinguish which actions will better contribute to the overall reward across all agents.
现在,为什么这样做呢? 凭直觉,通过使用此基准,代理可以知道此操作相对于它可能已经执行的所有其他操作有多少奖励。 这样,它可以更好地区分哪些行为将更好地为所有代理提供总体奖励。
COMA proposes using a specific network architecture helps make computing the baseline more efficient [1]. Furthermore, the algorithm can be extended to continuous action spaces by estimating the expected value using Monte Carlo Samples.
COMA提出使用特定的网络体系结构有助于使基准线的计算效率更高[1]。 此外,通过使用蒙特卡洛样本估计期望值,可以将该算法扩展到连续动作空间。
结果 (Results)
COMA was tested on StarCraft unit micromanagement, pitted against various central and independent actor critic variations, estimating both Q-values and value functions. It was shown that the approach outperformed others significantly. For official reported results and analysis, check out the original paper [1].
COMA已在StarCraft单位的微观管理上进行了测试,与各种中央和独立演员评论家的变化进行了对比,从而估算了Q值和值函数。 结果表明,该方法明显优于其他方法。 有关官方报告的结果和分析,请查看原始论文[1]。
结论 (Conclusion)
Nobody likes slackers. Neither do robots.
没有人喜欢懒人。 机器人也没有。
Properly allowing agents to recognize their personal contribution to a task and optimizing their policies to best use this information is an essential part of making robots collaborate. In the future, better decentralized approaches may be explored, effectively lowering the learning space exponentially. However, this is easier said than done, as with all problems of these sorts. But of course, this is a strong milestone to letting multi-agents function at a far higher, more complex level.
适当地允许代理识别他们对任务的个人贡献并优化其策略以最佳地利用此信息,这是使机器人进行协作的重要组成部分。 将来,可能会探索更好的分散方法,从而有效地减少学习空间。 但是,对于所有这些问题,说起来容易做起来难。 但是,当然,这是使多代理在更高,更复杂的级别上起作用的重要里程碑。
From the classic to state-of-the-art, here are related articles discussing both multi-agent and single-agent reinforcement learning:
从经典到最新,以下是讨论多主体和单主体增强学习的相关文章:
翻译自: https://towardsdatascience.com/counterfactual-policy-gradients-explained-40ac91cef6ae
梯度反传
http://www.taodudu.cc/news/show-997375.html
相关文章:
- facebook.com_如何降低电子商务的Facebook CPM
- 西格尔零点猜想_我从埃里克·西格尔学到的东西
- 深度学习算法和机器学习算法_啊哈! 4种流行的机器学习算法的片刻
- 统计信息在数据库中的作用_统计在行业中的作用
- 怎么评价两组数据是否接近_接近组数据(组间)
- power bi 中计算_Power BI中的期间比较
- matplotlib布局_Matplotlib多列,行跨度布局
- 回归分析_回归
- 线性回归算法数学原理_线性回归算法-非数学家的高级数学
- Streamlit —使用数据应用程序更好地测试模型
- lasso回归和岭回归_如何计划新产品和服务机会的回归
- 贝叶斯 定理_贝叶斯定理实际上是一个直观的分数
- 文本数据可视化_如何使用TextHero快速预处理和可视化文本数据
- 真实感人故事_您的数据可以告诉您真实故事吗?
- k均值算法 二分k均值算法_使用K均值对加勒比珊瑚礁进行分类
- 衡量试卷难度信度_我们可以通过数字来衡量语言难度吗?
- 视图可视化 后台_如何在单视图中可视化复杂的多层主题
- python边玩边学_边听边学数据科学
- 边缘计算 ai_在边缘探索AI!
- 如何建立搜索引擎_如何建立搜寻引擎
- github代码_GitHub启动代码空间
- 腾讯哈勃_用Python的黑客统计资料重新审视哈勃定律
- 如何使用Picterra的地理空间平台分析卫星图像
- hopper_如何利用卫星收集的遥感数据轻松对蚱hopper中的站点进行建模
- 华为开源构建工具_为什么我构建了用于大数据测试和质量控制的开源工具
- 数据科学项目_完整的数据科学组合项目
- uni-app清理缓存数据_数据清理-从哪里开始?
- bigquery_如何在BigQuery中进行文本相似性搜索和文档聚类
- vlookup match_INDEX-MATCH — VLOOKUP功能的升级
- flask redis_在Flask应用程序中将Redis队列用于异步任务
梯度反传_反事实政策梯度解释相关推荐
- java+如何解决反爬虫_反爬虫,到底是怎么回事儿?
原标题:反爬虫,到底是怎么回事儿? 有位被爬虫摧残的读者留言问:「网站经常被外面的爬虫程序骚扰怎么办,有什么方法可以阻止爬虫吗? 」 这是个好问题,自从 Python 火了起来,编写爬虫程序的门口越来 ...
- 3. 机器学习中为什么需要梯度下降?梯度下降算法缺点?_浅谈随机梯度下降amp;小批量梯度下降...
机器学习三要素 上次的报告中,我们介绍了一种用于求解模型参数的迭代算法--梯度下降法.首先需要明确一点,即"梯度下降算法"在一个完整的统计学习流程中,属于什么?根据<统计学习 ...
- exe反编译_反编译Python生成exe软件(Py3-polySML)
反编译对象为一篇文献上的软件,反编译只是为了了解一些源代码的逻辑. 过程参考文章:python3.7.4反编译生成的.exe 反编译对象:polySML 此对象为python打包,且未进行加密加壳软件 ...
- java中反爬虫_反网络爬虫策略(转自Javaeye)
[随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战.搜索引擎(Search Engine),例如传统的通用搜索引 ...] 爬虫有好处也有坏处: 威胁主要是 ...
- torch编程-加载预训练权重-模型冻结-解耦-梯度不反传
1)加载预训练权重 net = torchvision.models.resnet50(pretrained=False) # 构建模型 pretrained_model = torch.load(p ...
- java 前端页面传过来的值怎么防止篡改_反爬虫,到底是怎么回事儿?
有位被爬虫摧残的读者留言问:「网站经常被外面的爬虫程序骚扰怎么办,有什么方法可以阻止爬虫吗? 」 这是个好问题,自从 Python 火了起来,编写爬虫程序的门口越来越低,爬取别人网站数据也越来越猖獗. ...
- 【Caffe笔记】二.Forward and Backward(前传/反传)
前传和后传是一个网络最重要的计算过程. 1.前传 前传过程为给定的待推断的输入计算输出,Caffe组合每一层的计算一得到整个模型的计算函数,自底向上进行. 2.反传 反传过程根据损失来计算梯度从而进行 ...
- 卷积神经网络的深入理解-基础篇(卷积,激活,池化,误差反传)
卷积神经网络的深入理解-基础篇 一.卷积(convolution) 1.无padding时 2.有padding时 3.卷积与全连接 通道数(一般一张彩色图像为三通道RGB) 二.激活(激活函数)(持 ...
- Caffe学习笔记(二):Caffe前传与反传、损失函数、调优
Caffe学习笔记(二):Caffe前传与反传.损失函数.调优 在caffe框架中,前传/反传(forward and backward)是一个网络中最重要的计算过程:损失函数(loss)是学习的驱动 ...
最新文章
- Window phone用手机来控制电脑的多媒体播放
- vue调用顺序(初学版) index.html → main.js → app.vue → index.js → components/组件 测试
- Java中如何实现代理机制(JDK、CGLIB)
- matlab length_MATLAB入门
- Java 正则提取银行短信内容
- 使用PHPWord生成word文档
- shell习题第26题:监控mysql服务
- jenkins+maven+svn+npm自动发布部署实践
- java开源社区 推荐_13 个最火的 Java 开源项目推荐!总有一个适合你!
- 网络工程师--网络规划和设计案例分析(1)
- 为解放程序员而生,网易重磅推“场景化云服务”,强势进军云计算市场
- 创建型模式之简单工厂模式
- Linux操作命令分类详解 - 压缩备份(四)
- word在任意页开始添加页码
- 通过piranha搭建lvs高可用集群
- springboot毕设项目东莞汉庭酒店的酒店管理系统的设计与实现4ccnv(java+VUE+Mybatis+Maven+Mysql)
- 电分糊涂日记之《电路频率响应》
- 快应用的用法和常见问题解答(下)
- JETSON产品组合: nano, TX, Xavier
- c语言iota怎么用,常量及iota的简单用法