Elasticsearch学习(2)—— 常见术语
为什么80%的码农都做不了架构师?>>> 
cluster (集群):一个或多个拥有同一个集群名称的节点组成了一个集群。每个集群都会自动选出一个主节点,如果该主节点故障,则集群会自动选出新的主节点来替换故障节点。
node (节点):一个节点是集群中的一个 Elasticsearch 运行实例。测试环境,多个节点可以同时启动在同一个服务器上,生产环境一般是一个服务器上一个节点。节点启动时将使用单播或者是组播来发现和自己配置的集群名称相同的集群,并尝试加入到该集群中。
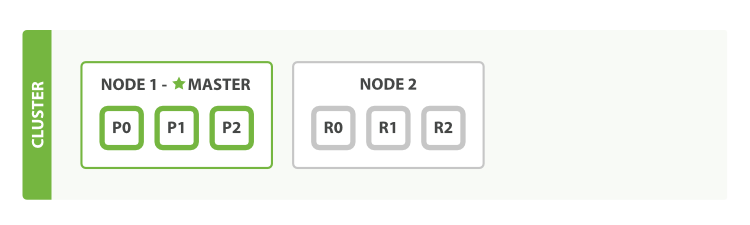
shard (分片):一个分片就是一个Lucene实例,它是 Elasticsearch 管理的底层 「工作单元」。一个索引是逻辑上的一个命名空间,指向主分片和副本分片。索引的主分片和副本分片数量必须明确指定好,在应用代码使用时只需要处理和索引的交互,不会涉及到和分片的交互。Elasticsearch 会在集群中的所有节点上设置好分片,但节点失效或加入新节点时会自动将移动节点分片。
primary shard (主分片):每个文档都会被保存在一个主分片上。当我们索引一个文档时,它将在一个主分片上进行索引,然后才放到该主分片的各副本分片上。默认情况下,一个索引有 5 个主分片。我们可以指定更少或更多的主分片来伸缩索引可处理的文档数。需要注意的是,一旦索引创建,就不能修改主分片个数。
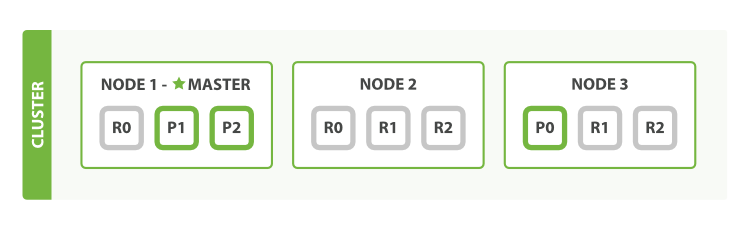
replica shard (副本分片):每个主分片可以拥有0个或多个副本分片,一个副本分片是主分片的一份拷贝。这样做有两个主要原因:
- 故障转移:当主分片失效时,一个副本分片会被提升为主分片。
- 提高性能:获取与搜索请求可以被主分片或副本分片处理。默认情况下,每个主分片都有一个副本分片,副本分片的数量可以动态调整。在同一个节点上,副本分片和其主分片不会同时运行。
单节点,三个主分片的原理图
两个节点,三个主分片,一个副本分片的原理图
三个节点,三个主分片,两个副本分片
索引中的主分片的数量在索引创建后就固定下来了,但是从分片的数量可以随时改变。
在ES集群中可以监控统计很多信息,其中最重要的就是:集群健康(cluster health)。它的 status 有 green、yellow、red 三种;
status 意义 green所有主分片和从分片都可用 yellow所有主分片可用,但存在不可用的从分片 red存在不可用的主要分片

index (索引):一个索引类似关系型数据库中的一个数据库,它可以映射为多种type。一个索引就是逻辑上的一个命名空间,对应到1或多个主分片上,可以拥有0个或多个副本分片。
type (类型):表示一类相似的document。Type由名称(如orderinfo,refundinfo)和mapping组成。类似于数据库中的schema,描述了文档可能具有的字段或属性 、每个字段的数据类型—比如 string, integer 或 date — 以及Lucene是如何索引和存储这些字段的。类型可以很好的抽象划分相似但不相同的数据。每个document的类型名被存储在一个叫 _type 的元数据字段上。
id:id 是用于标识文档的。文档 id 是自动生成的,如果显式不指定。
document (文档):一个文档就是一个保存在 Elasticsearch 中的 JSON 文本,可以把它理解为关系型数据库表中的一行。每个文档都是保存在索引中的,拥有一种type和 id。一个文档是一个 JSON Object (一些语言中的 hash / hashmap / associative array) 包含了 0 或多个field (键值对)。原始的 JSON 文本在索引后将被保存在 _source字段里,搜索完成后返回值中默认是包含该字段的。
document举例:
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 1,
"_source": {
"test_field1": "test field1",
"test_field2": "test field2"
}
}一个document不只包含了数据。它还包含了元数据(metadata) —— 关于文档的信息。有三个元数据元素是必须存在的,它们是:
名字 说明 _index文档存储的地方 _type文档代表的对象种类 _id文档的唯一编号 文档通过 _index, _type以及_id来确定它的唯一性。
其余可选的元数据类型:
名字 说明 _uid组合id,由_type和_id组成 _source文档的原始json数据,可以从这里获取每个字段的内容 _all整合所有字段内容到该字段,默认禁用 source field ( 源字段):默认情况下,在获取和搜索请求返回值中的 _source字段保存了 源 JSON 文本。这使得我们可以直接在返回结果中访问源数据,而不需要根据 id 再发一次检索请求。索引的 JSON 字符串将完整返回,无论是否是一个合法的 JSON。该字段的内容也不会描述数据如何被索引。
field (字段):一个文档包含了若干字段,或称之为键值对。字段的值可以是简单标量值,例如字符串、整型、日期,也可以是嵌套结构,例如数组或对象。一个字段类似于关系型数据库表中的一列。每个字段的映射都有一个字段类型 ( 不要和文档类型搞混了 ),它描述了这个字段可以保存的值类型,例如整型、字符串、对象。mapping还可以让我们定义一个字段的值如何进行分析。
字段类型:
一级分类 二级分类 具体类型 核心类型 字符串类型 string,text,keyword 整数类型 integer,long,short,byte 浮点类型 double,float,half_float,scaled_float 逻辑类型 boolean 日期类型 date 范围类型 range 二进制类型 binary 复合类型 数组类型 array 对象类型 object 嵌套类型 nested 地理类型 地理坐标类型 geo_point 地理地图 geo_shape 特殊类型 IP类型 ip 范围类型 completion 令牌计数类型 token_count 附件类型 attachment 抽取类型 percolator
mapping (映射):就像数据库中的schema,描述了文档可能具有的字段或属性,每个字段的数据类型以及Lucene是如何索引和存储这些字段的。Elasticsearch的mapping一旦创建,只能增加字段,而不能修改已经mapping的字段。修改mapping只能通过重新建立一个index,然后创建一个新的mapping。
设置mapping
POST /library #给索引为library创建映射关系
{
"settings":{//分片的设置
"number_of_shards" : 5,
"number_of_replicas" : 1
},
"mappings":{
"books":{ #索引为library的type类型为books
"properties":{ #这里往下就是映射关系
"title":{"type":"string"},
"name":{"type":"string","index":"not_analyzed"},
"publish_date":{"type":"date","index":"not_analyzed"},
"price":{"type":"double"},
"number":{
"type":"object",
"dynamic":true
}
}
}
}
}
获取mapping
GET library/_mapping
{
"library": {
"mappings": {
"books": {
"properties": {
"name": {
"type": "string",
"index": "not_analyzed"
},
"number": {
"type": "object",
"dynamic": "true"
},
"price": {
"type": "double"
},
"publish_date": {
"type": "date",
"format": "dateOptionalTime"
},
"title": {
"type": "string"
}
}
}
}
}
}
term (查询词):一个查询词是一个被 Elasticsearch 索引的确切值。查询词 foo,Foo,FOO 是不同的。查询词可以使用查询词查询接口进行获取。
"query": {
"term": {
"age": "39"
}
}类似的terms
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"price" : [20, 30]
}
}
}
}
analysis 分析:分析是将文本 ( text ) 转化为查询词 ( term ) 的过程。比如这三种短语:FOO BAR,Foo-Bar,foo,bar 都有可能被分解成查询词 foo 与 bar。可以使用不同的分析器,这些查询词实际上将被存储在索引中。一次对 FoO:bAR 的全文查询 ( 不是查询词查询 ) 可能会被分析为为查询词 foo,bar,可以匹配上保存在索引中的查询词。这就是分析处理过程(包含了索引与搜索),它使得 es 可以进行全文查询。
routing (路由):当我们索引一个document时,它将被保存在一个主分片上,分片的选择是通过路由值哈希得到的。默认情况下,路由值使用文档的 id,如果该文档指定了父文档,则路由值使用父文档 id。这是为了确保子文档和父文档被保存在相同的分片上。该值可以在索引时指定,也可以通过映射路由字段来指定。
当你索引一个文档,它被存储在单独一个主分片上。Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢?
进程不能是随机的,因为我们将来要索引文档。事实上,它根据一个简单的算法决定:
shard = hash(_routing) % number_of_primary_shards
_routing值是一个任意字符串,它默认是_id但也可以自定义。这个_routing字符串通过哈希函数生成一个数字,然后除以主分片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
=============================================================================
与数据库概念的映射关系:
|
Elasticsearch |
RDBMS |
|
Elasticsearch |
Relational DB |
|
Indices(索引) |
Databases |
|
Types(类型) |
Tables |
|
Documents(文档) |
Rows |
|
Fields(字段) |
Columns |
转载于:https://my.oschina.net/liyurong/blog/1841888
Elasticsearch学习(2)—— 常见术语相关推荐
- 数据库基础知识和常见术语学习
数据库基础知识和常见术语学习 什么是数据库 数据库系统 什么是数据库系统 数据库系统(DBS)的组成 数据库系统的特点 数据库管理系统(DBMS) 什么是数据库管理系统 数据库管理系统所提供的功能 数 ...
- ElasticSearch学习总结(三):查询总结
ElasticSearch学习总结(三):查询总结 本文主要对Elasticsearch中查询相关的知识做一个简单的总结,内容主要包括查询的评分机制,查询改写,过滤器,以及对常见的查询做一个简单的分类 ...
- Python基础概念_14_常见术语
常见术语 15 常见术语 15.1 简介 Python里有一些常见的专业名词.用语,我们一般统称为术语.为了更方便的学习python我们通过表格的方式列举了常用的术语和单词以及工具. 15.2 常见术 ...
- IdentityServer4系列 | 常见术语说明
一.前言 在上一篇中,我们IdentityServer4的说明,认识到是一个基于OpenID Connect协议标准的身份认证和授权程序,并简单的对基础知识的认识以及区别说明,从OAuth.OpenI ...
- HALCON 20.11:深度学习笔记(7)---术语表
HALCON 20.11:深度学习笔记(7)---术语表 HALCON 20.11.0.0中,实现了深度学习方法.下面,我们将描述深度学习环境中使用的最重要的术语: anchor (锚) Anchor ...
- Elasticsearch学习-Doc与Segment原理
Elasticsearch学习-Doc与Segment原理 0x00 系列文章目录 Elasticsearch学习-关于倒排索引.DocValues.FieldData和全局序号 Elasticsea ...
- 大数据常见术语,你了解多少?
大数据常见术语一览 主要内容包含以下(收藏,转发给你身边的朋友) 雪花模型.星型模型和星座模型 事实表 维度表 上钻与下钻 维度退化 数据湖 UV与PV 画像 ETL 机器学习 大数据杀熟 SKU与S ...
- 机器学习常见术语汇总
A 准确率(accuracy) 分类模型预测准确的比例.在多类别分类中,准确率定义如下: 在二分类中,准确率定义为: 激活函数(Activation function) 一种函数(例如 ReLU 或 ...
- 47个“企业数字化转型”常见术语合集,看完秒懂~
全文6.6K字,阅读大约需要:10分钟 如果大家近期有在关注数字化转型领域,那么你就会发现,我们在网上搜索一些数字化内容时,经常无意中会看到很多不熟悉的术语.而如果你在此之前没有掌握这块的基础知识,也 ...
- 黑马程序员--分布式搜索ElasticSearch学习笔记
写在最前 黑马视频地址:https://www.bilibili.com/video/BV1LQ4y127n4/ 想获得最佳的阅读体验,请移步至我的个人博客 SpringCloud学习笔记 消息队列M ...
最新文章
- Android 基础(十六) Toast
- 转 如何利用客户端缓存对网站进行优化?
- Ext RAD开发工具预览
- [转]数据库性能优化(老Key)
- rabbitMQ(二):Fanout Exchange
- 真正的出路只有一个(哈佛大学的幸福课)
- 信息学奥赛一本通(1111:不高兴的津津)
- Github出现连接超时
- 一文速览 | 对话生成预训练模型
- 微信状态栏隐藏 HTML,微信里几个实用的隐藏小技巧!
- c语言跳马思路,跳马问题 - 日拱一卒的个人空间 - OSCHINA - 中文开源技术交流社区...
- 戴尔服务器710u盘安装系统,联想G710笔记本U盘重装Win7系统教程
- 华为鸿蒙删除视频报错rm: local.mp4: Owner died
- TensorFlow2 -官方教程 :保存和恢复模型
- 融合办公时代来了?联想Filez带你正确解读“融合办公”新模式
- 此证书的签发者无效解决办法
- 我的同事妹妹深夜来我家问我MyBatis源码解析,我是这样给她讲的
- 2022—SWJTU-寒假ACM校队选拔赛第二场-题解
- ConvNeXt:手把手教你改模型
- 2021牛客暑期多校训练营2 K Stack