C语言-学习笔记完整版
C语言基础知识
- 标准输入输出I/O
- 格式控制符
- 代码风格
- 数据类型
- 整型
- 整数的存储方式
- 浮点型(实型)
- 字符类型
- 字符串
- 布尔类型
- 常量与变量
- 类型的转换
- 运算符
- 算术运算符
- 逻辑运算符
- 位运算符
- 特殊运算符
- 赋值运算符
- 复合运算符
- 条件运算符(三目运算符)
- sizeof 运算符
- return 运算符
- 优先级与结合性
- 控制流
- 二路分支
- 多路分支
- while 和 do...while循环
- for循环
- break 与 continue
- goto 语句
- 数组
- 数组(初级)
- 字符数组
- 指针
- 内存地址
- 基地址
- 指针的基础
- 指针的索引
- 野指针
- 空指针
- 数组与指针
- 数组指针和指针数组
- 数组指针
- 指针数组
- 数组进阶
- 数组名的含义
- 字符串常量
- 零长数组
- 变长数组
- 多维数组
- 内存管理
- 栈空间
- 静态变量
- 数据段与代码段
- 堆内存
- 总结
- 指针进阶
- char 型指针
- 指针函数和函数指针
- void 型指针
- const 指针
- 函数
- 函数入门
- 函数的定义
- 形参与实参
- 局部变量与栈内存
- 特殊函数
- 静态函数
- 递归函数
- 回调函数
- 指针函数和函数指针
- 内联函数
- 变参函数
- 作用域
- 函数声明的作用域
- 函数头中的作用域
- 局部作用域
- 全局作用域
- 作用域的临时掩盖
- static 关键字
- 存储期
- 自动存储期
- 静态存储期
- 自定义存储期
- 结构体
- 成员引用
- 结构体声明的变异
- 结构体尺寸
- 普通变量的M值
- 计算结构体的大小
- 可移植性
- 联合体与枚举
- 联合体概念
- 字节序
- 枚举概念
- 编译器与宏定义
- 编译器
- 编译过程
- 宏定义
- 无参宏
- 带参宏
- 无值宏
- 条件编译
- 头文件的作用
- 无值宏
- 条件编译
- 头文件的作用
标准输入输出I/O
标准输入 stdin 对应的是键盘文件
标准输出 stdout 对应的是终端《带缓冲区》(屏幕)
标准出错 stderr 对应的是终端《无缓冲区》(屏幕)Linux 下在
在Linux 也是文件 /dec/stdin /dec/stdout 文件(但不是设备文件,是链接文件)
![]()
因此,打开、读或者写 /dev/stdin和/dev/stdout 实际上是打开、读或者写这两个文件存放的地址对应的设备文件。
printf("hello world!\n");while(getchar() != '\n'); // 清空 由 scanf 所留在缓冲区的内容 // 如果不清空有可能会导致下一次使用标准输入缓冲区异常(有上一次的数据没有被读取)
以上语句中 \n 是一个换行符 ,说明是一行的结束
标准输出文件中默认使用缓冲 ,也就是当遇到 \n 的时候会进行刷新缓冲区(把数据输出)
当打印语句后面没有换行符时 , 需要等待缓冲区被装满或者被别的语句刷新或则程序正常退出
C语言的标准输入输出是分缓冲和无缓冲的。这里面缓冲分为全缓冲和行缓冲。
- 全缓冲: 全缓冲是指当缓冲区满了才进行 I/O 的读写操作。一般磁盘文件是全缓冲的(缓冲区一般为4096个字节)。
- 行缓冲: 行缓冲是指遇到换行符(即’\n’)后进行 I/O 操作,当然缓冲区满了也要进行操作。注意:换行符也被读入缓冲区。(缓冲区一般为1024个字节)
一般地,标准输入stdin和标准输出stdout为行缓冲,标准错误输出stderr无缓冲。但是ANSI C要求下列缓存特征(参考APUE):
- 当且仅当标准输入和标准输出并不涉及交互作用设备时,它们才是全缓存的。
- 标准出错决不会是全缓存的。
但是,很多系统是这么实现的:
- 涉及到交互时,标准输入输出为行缓冲,否则为全缓冲
- 标准错误输出总是无缓冲
格式控制符
十进制的整型: %d %md %ld %u (无符号) %lu
八进制: %o %#o # --> 输出进制的符号
十六进制: %x %#x %#X
字符: %c
字符串: %s
单精度浮点: %f %.nf --> n 表示精度
双精度: %lf
长双精度 : %Lf
地址: %p
代码风格
- 缩进:凡是右代码块的地方必须用缩进,代码块指的是一对大括号 { } 代表一个代码块
- 空格: 标点符号后面,一般加空格
- 空行: 一般在不同的逻辑段落中间加空行
- 符号(变量)命名: 尽可能顾名思义,避免使用无意义的字符 , 不可以使用关键字
数据类型
整型
![]()
注意:
整型在 32位系统以及64位系统中都占用 4字节
取值范围 2^32 ( 32位操作系统可寻址范围 4g )
$ getconf INT_MAX
2147483647
$ getconf INT_MIN
-2147483648
整型的修饰符:
- short 短整型,用于修饰整型的尺寸变为原本的一半,减少内存的开支,缩小取值范围
- long 长整型 , 用于修饰整型的尺寸使其尺寸变大(取决与系统), 增加内存开支, 扩大取值范围
- long long 长长整型 , 用于修饰整型的尺寸使其尺寸变大(取决与系统), 增加内存开支, 扩大取值范围 (在64位系统中 long 与 long long的大小一致)
- unsigned 无符号整型 , 用来修饰整型并去掉符号位,使得整型数据没有负数,可以提正整数的取值范围 (0 - 4294967295)
- 整型数据在二进制存储时最高位(第31位)表示符号位,如果为1 则表示负数反之则表示正数
整数的存储方式
原码: 正整数是直接使用原码进行存储的,比如100这个正整数,则直接把100 转换成二进制直接存储。
100 --> 0000 0000 0000 0000 0000 0000 0110 0100
**补码:**负数则是使用补码来存储, 补码 = 原码的绝对值 取反+ 1 取反加1时符号位不变
比如 -100 :
100 --> 1000 0000 0000 0000 0000 0000 0110 0100
取反-> 1111 1111 1111 1111 1111 1111 1001 1011
加1 --> 1111 1111 1111 1111 1111 1111 1001 1100
溢出:当超过取值范围时则会编程相邻的最小值/最大值
浮点型(实型)
概念:用来表达一个实数的数据类型
分类:
- 单精度浮点型 float , 典型尺寸 4 字节
- 双精度浮点型 double , 典型尺寸 8 字节
- 长双精度 long double , 典型尺寸 16 字节
占用的内存越多则精度越高
浮点数的存储: IEEE 浮点标准采用如下形式来表示一个浮点数
![]()
![]()
float f = 3.14; // 浮点数3.14 通过以上公式计算得到的二进制码被存放与内存f中
printf("f:%f\n" , f ); // 使用浮点的计算方法来解析内存f中的值(二进制)
printf("d:%d\n" , f );// 直接使用整型的计算方法来直接解析内存f 中的值 (二进制)//运行结果:
f:3.140000
d:1301103200x:0x 97ab 4260 -----1 00101111 01010110100001001100000所有的数据都会被转换成二进制进行存储,如果想到的到正确的数据,必须使用正确的理解方式(类型),来解析二进制数据。
字符类型
char c = 'K' ;
- 申请一片内存并且命名为 c
- 确定内存的大小为 char (1字节)
- 把字符‘K’的ASCII码值转换为二进制,并存储到该内存中
- 计算机中存储的所有数据都是以二进制的形式存在的, 因此字符必须映射某一个数字才能够被存放到计算机中,这个映射的表就成为 ASCII 表,可以使用man手册来
查看:man sacii
![]()
char c = '1' ;printf("字符:%c\n",c); // 以字符的形式来解析内存 c 的内容得到 对应的字符 1
printf("整型ASCII值:%d\n",c); //以十进制整型来解析内存c 的内容 ,得到1多对应的ASCII值//运行结果:
字符:1
整型ASCII值:49
**注意:**字符实质上是一个单字节的整型,因此支持所有整型的操作
char k = 'H' ;
printf("%c\n" , k + 1 );
printf("%c\n" , k - 1 );//运行结果:
I
G
字符串
字符串的表现形式有两种:
形式一 : 数组(可读 ,可写):(存储)
char s1 [] = “Hello” ; //使用一个数组来存放字符串 “Hello”
以上语句其实是把一个字符串常量 “Hello” , 赋值到数组 s1 所代表的内存当中
![]()
形式二 : 指针 (只读):(指向)
char * s2 = “Hello”; // 使用一个指针来指向常量字符串
![]()
char s1[] = "shiming";
char *p ="shiming" ;printf("s1地址:%p\n",s1); //s1的首地址:'s'的地址
printf("s1+1:%p\n",s1+1); //s1+1的地址:及'h'的地址
printf("s1+1:%s\n",s1+1); // 输出内容printf("p的地址:%x",&p); //指针p的地址
printf("shiming地址:%x\n",p); //指针p所存放的值,及"shiming"的首地址
printf("shiming地址:%x\n",p+1);printf("*P-x:%x\n",*p);
printf("*P-d:%d\n",*p);
printf("*P-x:%x\n",*p+1); *取值符号 &取址符号
printf("*P-d:%d\n",*p+1);//运行结果:
s1地址:0x7ffd8cdec640
s1+1:0x7ffd8cdec641
s1+1:himingp的地址:8cdec638 //栈区
shiming:1c747894 //常量区
shiming:1c747895*P-x:73 s ascii码十六进制
*P-d:115 s ascii码十进制
*P-x:74 i ascii码十六进制
*P-d:116 i ascii码十进制
布尔类型
概念: 布尔类型用来表示真/假 (非零则真) (==注意:==需要包含他的头文件: <stdbool.h>)
真: true 假: false
<stdbool.h>
bool a = 1 ; // 真
bool a = 0 ; // 假
bool a = true // 真
bool a = false // 假
bool a = true ;printf("sizeof(bool):%ld \n ",sizeof(bool) );
printf("sizeof(a):%ld \n ",sizeof(a) );
printf("sizeof(true):%ld \n ",sizeof(true) );
printf("sizeof(false):%ld \n ",sizeof(false) );
printf("false:%d \n ",false );
printf("true:%d \n ",true );//运行结果:
sizeof(bool):1
sizeof(a):1
sizeof(true):4
sizeof(false):4
false:0
true:1
常量与变量
概念: 不可以被改变的内存,被称为常量,可以被改变的内存则成为变量
int a = 100 ; // a是一个变量, 而 100 则是常量
float f = 3.1415; // f 是一个变量, 而 3.1415 则是常量
char s1[] = "abcdefg" ; // s1 是一个变量 , 而"abcdefg" 则是常量 (字符串常量)
常量类型:
- 100 : 整型常量
- 100L : 长整型 long
- 100LL : 长长整型 long long
- 100UL : 无符号的长整型 unsigned long
- 3.14 : 编译器默认升级为双精度浮点型
- 3.14L : 长的双精度浮点型
- ‘a’ : 字符常量
- “Hello” : 字符串常量(指针 char * )
类型的转换
概念: 不同的数据类型但是可以兼容的类型之间,如果出现在同一表达式中则会发生类型的转换。
数据类型之间转换的模式有两种:
隐式转换(自动):
若在表达式中用户没有手动进行转换,则系统会自动转为高精度的类型,
比如float + double + int --> 则系统会自动全部转为 double
强制转换(手动):
用户根据自己的需求进行强制的类型转换 (int )a --> 强制性把a 转换为整型
int a = 100 ;
char c = 'l' ;
float f = 3.14 ;
double d = 998654.145;int dd = (int)a + (int)c + (int)f + (int)d ;
低精度 -----------------------------------------------------------------------> 高精度
char --> short --> int --> long --> float --> double --> long double
注意:
不管是隐式转换还是强制转换, 准换的只是在运算的过程中 ,并不会影响到原本的数, 这是一个临时的转换。
整型的尺寸:
概念: 尺寸指的是某一个数据需要多少内存来存储(占用的内存空间)
在C语言中并没有规定某一个数据类型他的尺寸是多少,但是有个相对的大小约定
short 不可能比int 长
long 不可能比int 短
long 的长度等于系统的字长 (系统位数)
$ getconf LONG_BIT
64
$ uname -a
Linux PC-20210112EPXS 4.4.0-18362-Microsoft #836-Microsoft Mon May 05 16:04:00 PST 2020 x86_64 x86_64 x86_64 GNU/Linux
典型尺寸:
- char 占用 1 个字节
- short 占用 2 个字节
- int 占用 4 个字节
- double 占用4个字节
- long 占用 4(32位系统) / 8(64位系统) 个字节
问题:
相同的代码在不同(位数)的系统中,它所占用的尺寸会发生变化,有可能导致数据的精度出现问题, 严重的可能会导致程序无法运行。 因此,系统中会提供一些可移植类型。
可移植数据类型:
概念: 不管在什么系统中,数据的尺寸都是固定不不会发生变化的数据类型成为可移植数据类型。
关键字: typedef
typedef int TieZhu ; // 相当于用typedef 给 int 取个别名 叫 TieZhu
typedef int __int32_t ;
typedef long __long_64_t ;
系统提供了一些预定义的可以直数据类型:
/usr/include/x86_64-linux-gnu/bits/types.h/* Convenience types. */
typedef unsigned char __u_char;
typedef unsigned short int __u_short;
typedef unsigned int __u_int;
typedef unsigned long int __u_long;/* Fixed-size types, underlying types depend on word size and compiler. */
typedef signed char __int8_t; // 有符号8位整型
typedef unsigned char __uint8_t; // 无符号8位整型
typedef signed short int __int16_t;
typedef unsigned short int __uint16_t;
typedef signed int __int32_t;
typedef unsigned int __uint32_t;
#if __WORDSIZE == 64 // ---> 判断系统的位数(字长) 如果是 64位
typedef signed long int __int64_t; // 64位系统中 long int 就是 64位的有符号整型
typedef unsigned long int __uint64_t;// 64位系统中 long int 就是 64位的无符号整型
#else // ---> 判断系统的位数(字长) 如果不是 64位系统 则判断为 32 位系统
__extension__ typedef signed long long int __int64_t; // 在32位系统中 long long 才占用 64位
__extension__ typedef unsigned long long int __uint64_t;
#endif
运算符
算术运算符
% 取模(求余) 10%3=1
++ 自加 1 a++ , ++a
– 自减 1
注意:
- 取模运算的左右两个操作数必须是整型的
- 自加,自减既可以操作整型也可以操作浮点, 也可以操作指针
- ++i:先进行自加/自减的运算,然后再参与表达式的运算
- i++: 先参与表达式的运算 , 然后再进行自加/自减的运算
- 关系运算符的表达式值为布尔值
- 在数学中 100< a < 200 , 在代码中需要拆开 , a > 100 && a < 200
逻辑运算符
! 逻辑反 !(x>9) 如果 x 确实大于 9 则整个表达式为 假 ,反之为真
&& 逻辑与 ( a > 100 && a < 200 ) 该表达式两边同时为真则为真, 如果其中一个为假则整个表达式为假
|| 逻辑或 ( a > 100 || a < 200 ) 该表达式中其中一个为真则整个表达式为真
位运算符
~ 位逻辑反
int a = 3 ;
a -> 0000 0000 0000 0000 0000 0000 0000 0011
~a -> 1111 1111 1111 1111 1111 1111 1111 1100
& 位逻辑与 有零得零 --> 清零操作
int a = 3 ;
int b = 5 ;
a:0011
b:0101
a&b : 0001
| 位逻辑或 有一得一 --> 置1 操作
int a = 3 ;
int b = 5 ;
a:0011
b:0101
a|b : 0111
^ 位逻辑异或 相同得0 , 不同得1
int a = 3 ;
int b = 5 ;
a:0011
b:0101
a^b : 0110
<< 左移 >> 右移
a -> 0000 0000 0000 0000 0000 0000 0000 0011
a<<4 ->0000 0000 0000 0000 0000 0000 0011 0000
a>>4 ->0000 0000 0000 0000 0000 0000 0000 0000 //0011 舍去
![]()
![]() 注意:如果移动是一个有符号的数据,并右移运算时 ,移出去丢弃, ==空出来补符号位 负数补1
注意:如果移动是一个有符号的数据,并右移运算时 ,移出去丢弃, ==空出来补符号位 负数补1
特殊运算符
赋值运算符
= (左值=右值)
- 左值不能是常量 100 = a ;
- 不能直接对数组赋值
- 可以使用连续赋值 a = b = c = d = 100 ;
复合运算符
+= -= *= /= %= |= &= >>= …
- 但左右两边右相同的操作数时,可以使用符合运算符, 使得代码看起来更加简明,且可以在一定程度上提高效率。
条件运算符(三目运算符)
唯一一个需要三个操作数的运算符(表达式)
语法: 表达式1 ? 表达式2 : 表达式3
- 如果表达式1的值位真, 则整个表达式的值为表达式2 ,冒号左边
- 如果表达式1的值位假, 则整个表达式的值为表达式3 , 冒号右边
int a = 100 ; int b = 250 ;int max = a > b ? a : b ;
sizeof 运算符
注意该运算符看起来很像一个函数, 不要忘记它实际只是一个运算符
用来计算指定的 变量 或 变量类型 从而得到他在内从中所需要占用的字节
sizeof与strlen的区别:
strlen为函数,计算‘\0’前的字节大小,及实际装了多少东西
**sizeof为运算符,是计算变量或变量类型所占字节,及所用到的空间的大小**
return 运算符
优先级与结合性
当一个表达式中同时出现了多个运算符时,根据优先级以及结合性进行运算,比如先乘除后加减。。。
优先级:man operator:
![]()
控制流
二路分支
- if 语句: 表达一种 , 如果条件满足 则 执行某个代码块
- if-else 语句: 表达一种 ,如果 条将满足则执行某个代码块 否则执行另外一个代码块
注意:
if 语句可以单独使用, 但是else不可以单独只用, 必须在if后面配套使用
不管是if还是else , 建议给他们配一对大括号 { } 。 否则需要注意只能识别if / esle 后面的第一个逻辑行的语句
多路分支
逻辑: 根据不同的条件来执行不同的代码块
语法:
switch (表达式<判断的条件>)
{case <常量1> :// 代码块 1 break ;case <常量2> :// 代码块 2 break ;case <常量3> :// 代码块 3 break ;default :// 代码块 N
}
注意:
- switch(num )语句中的num , 它必须是一个整型的表达式,也就是所switch只能判断整型的数据
- case 语句中的 必须是整型常量,包括普通的字符。不包括被const修改的整型数据
- break 用来中断/跳出当前的循环。如果没有则会从条件满足的语句开始一条一条的往下执行,直到整个switch - case 结束或者遇到其它代码块中的break
- default 并不是必须存在,它一般放在最后面,用来提示用户表示都不满足以上条件。由于在最后面可以不添加break
const :
用来修饰一个变量使之不可被修改
作用:
修饰变量: 使得变量不能被修改
修饰指针:使得指针的指向不能改变或者指针所指向的内容不得改变
int const a = 100 ; // 定义了一个不可被修改的变量a
const int b = 200;a = 300 ; // 错误 assignment of read-only variable ‘a’
b = 250 ; // 错误 assignment of read-only variable ‘a’
while 和 do…while循环
逻辑: 使得程序中某一端代码块重复循环执行。
语法:
while( 表达式 )
{// 代码块
}do
{printf("num:%d\n" , num-- );
} while (num);
for循环
逻辑: 与while 类似, 都是让程序中某一段代码块重复运行,但是for相对与while来说更加紧凑。把所有的循环控制都集中到一行代码中
for(初始化语句 ; 判断语句 ; 表达式 (一般用于自加/自减))
{// 代码块
}
- 在for循环中直接定义并初始化只在C99的编译规则下可以这么干, 所以可以添加:

break 与 continue
break: 跳出循环结构 / 跳出当前层的循环
continue : 结束当前这一次循环,重新进入下一次的循环
for (int i = 0 ; i < num ; ++i ){while(1) // 在 循环体内部可以嵌套其它的循环{printf("你打我呀!!\n");break; // 跳出while这一层循环, 并不影响外面的for }if (i == 5){continue ; // 跳过当前这一次循环, 导致后面的代码在当次循环中不执行}printf("i:%d\n" , i );}
goto 语句
逻辑: 无条件跳转
语法:
int main(int argc, char const *argv[])
{标签://代码块goto 标签;return 0;
}
实例:
int main(int argc, char const *argv[])
{int num = 0 ;printf("请你来几拳!!!\n");scanf("%d" , &num);while(getchar() != '\n'); // 清空标准输入缓冲区for (int i = 0 ; i < num ; ++i ){goto Myoung; // 无条件跳转到标签为 Myoung 的位置}Myoung:printf("这里是标签的位置!!!\n");return 0;
}
数组
数组(初级)
基本概念:
逻辑: 一次性定义多个相同类型的变量,并且给他分配一片连续的内存
语法:
![]()
初始化:
只有在定义的时候赋值, 才可以称为初始化。数组只有在初始化的时候才可以统一赋值。
int arr [5] = {1,2,3,4,5} ; // 定义并初始化数组int arr [5] = {1,2,3} ; //可以, 不完全初始化
int arr [5] = {1,2,3,4,5,6,7,8,9} ; // 错误(但是可以用) , 越界初始化, 越界部分将会被编译器舍弃
int arr [ ] = {1,2,3,4,5,6,7,8,9} ; // 可以, 用户没有直接给定数组大小,// 但是有初始化, 因此数组的大小会在初始化时确定, 大小为 9
int arr [ ] ; // 错误的, 没有给定大小也没有初始化, 因此数组的内存大小无法确定系统无法分配
注意:
数组在定义的时候必须确定他的大小。
说白了就是中括号中[ ] 必须有数组的大小,如果没有就必须初始化
数组元素引用:
存储模式:一片连续的内存,按照数据的类型进行分割成若干个大小相同的格子元素的下标与偏移量:以数组开头为基础的偏移的量(数据类型大小)
字符数组
概念: 专门用来存放字符类型数据的数组, 称为字符数组
初始化+引用:
char ch1 [5] = {'H','e','l','l','o'} ; // 定义一个字符类型的数组并把'H','e','l','l','o' 一个一个存进去
char ch2 [6] = {"Hello","world","shiming",""," "," "} ; // 定义一个字符型的数组,并把 "Hello" 字符串存放到数组中
char ch3 [6] = "Hello" ; // 与ch2 一样, 大括号可以省略 //,因此该数组为字符串数组 ch3[1] = 'E' ; // 可以, 把数组中第二个元素‘e’修改为‘E’
ch3 = "Even" ; // 不可以, 只有在初始化的时候才能整体赋值printf("%s\n" , ch1); // 在访问ch1的时候并没有发现结束符,因此很有可能会把ch2的内容一并输出
**注意:**ch1 为字符数组, 它没有结束符,因此在打印输出的时候应该避免使用 %s 进行输出, 有可能会造成越界访问。
指针
内存地址
字节: 字节是内存容量的一个单位, byte , 一个字节byte 有 8个位 bit
地址: 系统位了方便区分每一个字节的数据, 而对内存进行了逐一编号, 而该编号就是内存地址。
32位系统可寻址范围 0x 0000 0000 ~ 0x FFFF FFFF (大约4g)
![]()
基地址
单字节的数据: char 它所在地址的编号就是该数据的地址
多字节的数据:int 它拥有4个连续的地址的编号 , 其中地址值最小的称为该变量的地址
![]()
![]()
指针的基础
指针的概念:
&a 就是a的地址 , 实质上也可以理解为他是一个指针 指向 a的地址。
专门用来存放地址的一个变量,因此指针的大小是恒定的 ,由系统的位数来决定。
指针的定义语法:
int a ; // 定义一片内存名字叫 a , 约定好该内存用来存放 整型数据
int * p ; // 定义一片内存名字叫 p , 约定好该内存用来存放 整型数据的地址
char * p1 ; // 定义一片内存名字叫 p1 , 约定好该内存用来存放 字符数据的地址
double * p2 ; // 定义一片内存名字叫 p2 , 约定好该内存用来存放 双精度数据的地址
注意:指针的类型,并不是用来决定该指针的大小,而是用来告诉编译器如果我们通过来指针来访问内存时需要访问的内存的大小尺寸
int a = 100 ;
int * p = &a ; // 定义并初始化double d = 1024.1234 ;
double * p1 = &d ;// 定义并初始化float f ;
float * p2 ;// 定义并没有初始化
p2 = &f ; // 给指针赋值.....
指针的索引
通过指针获得它所指向的数据(解引用/取目标)***** 取值符号
int a = 100 ;
int * p = &a ;*p = 250 ; // *p <==> a printf("*p:%d\n" , *p) ;输出结果:
*p:250
野指针
概念: 指向一块未知内存的指针, 被称为野指针。
危害:
- 引用野指针的时候,很大概率我们会访问到一个非法内存,通常会出现段错误(Segmentation fault (core dumped))并导致程序崩溃。
- 更加严重的后果,如果访问的时系统关键的数据,则有可能造成系统崩溃
产生原因:
- 定义时没有对他进行初始化
- 指向的内存被释放,系统已经回收, 后该指针并没有重新初始化
- 指针越界
如何防止:
- 定义时记得对他进行初始化
- 绝对不去访问被回收的内存地址, 当我们释放之后应该重新初始化该指针。
- 确认所申请的内存的大小,谨防越界
空指针
在很多的情况下我们一开始还不确定一个指针需要指向哪里,因此可以让该指针先指向一个不会破坏系统关键数据的位置, 而这个位置一般就是NULL (空)。因此指向该地址的指针都称之为空指针。
![]()
int * p1 = NULL ; // 定义一个指针, 并初始化为空指针( 指向 NULL )
*p1 = 250 ; // 段错误 , 该地址不允许写入任何东西
printf("%p -- %d \n" , NULL , NULL ); // (nul--0)输出结果:
段错误 (核心已转储)
数组与指针
示例1:
int arr [5] = {1,2,3,4,5} ;
int * p1 = &arr ;
int * p2 = arr ;printf("*p1:%d\n" , *(p1+1)) ;
printf("*p2:%d\n" , *(p2+1)) ;输出结果:
2
2
![]()
数组指针和指针数组
**数组的指针:**是一个指针,什么样的指针呢?—指向数组的指针。
**指针的数组:**是一个数组,什么样的数组呢?—装着指针的数组。
**明确一个优先级顺序:() >[] > ***
***p[n]:**根据优先级,先看[],则p是一个数组,再结合,这个数组的元素是指针类型,共n个元素,这是“指针的数组”,即指针数组。
**(*p)[n]:**根据优先级,先看括号内,则p是一个指针,这个指针指向一个一维数组,数组长度为n,这是“数组的指针”,即数组指针
int *p1[5]; int (*p2)[5];首先,对于语句*“int *p1[5]”**,因为“[]”的优先级要比“”要高,所以 p1 先与“[]”结合,构成一个数组的定义,数组名为 p1,而“int”修饰的是数组的内容,即数组的每个元素。也就是说,该数组包含 5 个指向 int 类型数据的指针,如图 1 所示,因此,它是一个指针数组。
其次,对于语句“int(p2)[5]”,“()”的优先级比“[]”高,“”号和 p2 构成一个指针的定义,指针变量名为 p2,而 int 修饰的是数组的内容,即数组的每个元素。也就是说,p2 是一个指针,它指向一个包含 5 个 int 类型数据的数组,如图 2 所示。很显然,它是一个数组指针,数组在这里并没有名字,是个匿名数组。
数组指针
专门用来指向一个数组的指针。
/*int * p ;
int (* p) [5] ; //定义一个 名为p 的指针, //并且确定他指向的类型为int [5] ,一个拥有5个元素的整型数组*/int arr [5] = {1,2,3,4,5} ;int (*p) [5] = arr ;printf("arr:%p\n" , &arr );printf("%p---%p---%d\n" ,p , (*p)[2], (*p)[2] ); // 3 * p ==> arr
printf("%p---%p---%d\n" ,p , (*p)[3], (*p)[3] ); // 4 * p ==> arr
printf("%p---%p---%d\n" ,p , (*p)[5], (*p)[5] ); // * p ==> arr
printf("%p---%p---%d\n" ,p , (*p)[6], (*p)[6] ); // * p ==> arr
printf("%p---%p---%d\n" , p+1 , (*(p+1))[2], (*(p+1))[2] ); // 已经越界访问 输出结果:
arr:0x7ffc7778dd90
0x7ffc7778dd90---0x3---3
0x7ffc7778dd90---0x4---4
0x7ffc7778dd90---0x7ffc---32764
0x7ffc7778dd90---0x8d529900----1923966720
0x7ffc7778dda4---0xdfe8bfe5----538394651注意:
以上代码中 p指向的是 一个整型数组并有5个元素。 因此在对p 进行加减运算时, 是加减一个数组 。
指针数组
专门用来存放指针的数组,称为指针数组。
int a = 100 ;
int b = 250 ;
int c = 550 ;
int d = 256 ;
int e = 998 ;int * p [5] = {&a, &b , &c , &d , &e} ; // 定义一个名字为 p的数组, 并且确定该数组中用来存放int * 整型地址for (size_t i = 0; i < 5; i++)
{printf("*p[%d]:%d \n" , i , *(p[i]) ); // p[0] --》 &a
}
数组进阶
数组名的含义
数组名在不同的场合下的含义有两种:
表示整个数组的首地址:
- 在数组定义的时候
- 在使用sizeof 运算符中 数组名表示整个数组的首地址(求得整个数组的大小)
- 在取地址符 中 &arr , arr 表示整个数组
表示整个数组首元素的首地址:
- 其它情况
int arr[10] ; // arr 表示整个数组的首地址
int len = sizeof arr ; // arr 表示整个数组的首地址 , sizeof 运算符后的括号可以省略
int (* p) [10] = &arr; //arr 表示整个数组的首地址int *p1 = arr ; // arr 表示数组的首元素的首地址*******************************************************************************
char arr[3] = {'a','b','c'};int *p1 = arr;int *p2;
p2 =&arr;int *p3 = &arr;int (* p) [3] = arr; //数组指针 printf("%c--%c\n",*p1, *p1+1);
printf("%c--%c\n",*p3, *p3+1);
printf("%c--%c\n",*p2, *p2+1); /***************************************************************/
printf("%c--%c\n",(*p)[0],(*p)[0]+1); /***数组指针只有(*p)[0]有效 ,下一个元素为(*p)[0]+1 而不是(*p)[1]**//****************************************************************/
printf("%c--%c\n",(*p)[0],(*p)[1]);
printf("%c--%c\n",(*p+1)[0],(*p+1)[1]);// 数组越界,(*p+1)实际上加了个arr大小的数组
printf("%c--%c\n",(*p)[0],(*p)[1]);输出结果:
a--b
a--b
a--b
a--ba--P
P--8
a--P
数组下标:
数组的下标实际上只是编译器提供一种简写,实际上如下
int a [100] ;
a[10] = 250 ; ====> *(a+10) = 250 ;
通过加法交换律,有如下结果:
a[10] = 250 ;
*(a+10) = 250 ;
*(10+a) = 250 ;
10[a] = 250 ;
字符串常量
字符串常量是一个被存放在常量区的字符串,实际上也可称为一个匿名数组。
匿名数组,同样满足数组名的含义。
char * msg2 = "Hello Myoung" ;// "Hello Myoung" 字符串常量首元素的首地址
char * msg1 = "Hello Myoung"+1 ;printf("%s\n", "Hello Myoung" ) ;// "Hello Myoung" 字符串常量首元素的首地址
printf("%s\n", &"Hello Myoung" ) ; // "Hello MyoungMyoung" 字符串常量的整个数组的地址printf("%c\n", "Hello Myoung"[6] ) ; // "Hello Myoung" 字符串常量首元素的首地址 [6]// [6] 相当于+6个单位(char) 得到 ‘M’
![]()
零长数组
(预习结构体)
概念: 数组的长度为0 , char arr [0] ;
用途:一般会放在结构体的末尾, 作为可变长度的入口。(数组是唯一一个允许越界访问的载体)
struct node
{int a;char b ;float c ;.....int len ;char arr[0] ;
}struct node *p = malloc(sizeof(struct node) + 20 ); // + 20 就是在原有的基础上增加20字节
p->len = 20 ; // 设置额外增长的长度为 20
strncpy(p->arr , 20 , "Hello FZ2105");
p->arr
![]()
变长数组
概念: 定义是, 使用一个变量作为数组的长度(元素的个数)。
重点: 变长数组并不是说在任意时候他的长度可以随意变化, 实际上只是在定义之前数组的长度是未知的有一个变量来决定, 但是定义语句过后变长数组的长度由定义那一刻变量的大小来决定。
int a = 200 ; // a 作为一个普通的变量 , 200 则可以作为arr 的长度
a = 99 ; // 99 可以作为 arr 的长度int arr[a]; // a 当前是 99 , 因此数组arr 的长度已经确定为 99 //从此以后该数组的长度已经确定为99 不会再变换a = 10 ; // a = 10 并不会影响数组的长度
注意:
- 因为数组的长度未确定,因此它不允许初始化。
- 在使用的时候可以通过该 变长数组来有限的节省内存空间。
多维数组
概念: 数组内部的成员也是数组
int a [2][3] ;
定义与初始化:
int arr[2][3] = { {1,2,3} , { 4,5,6} };
int arr1[2][3] = { 1,2,3,4,5,6};
3行2列
1 2 3
4 5 6如何引用:
arr[i] [j] = 100 ; // 数组:(通过下标来访问)
*(arr[i]+j) = 100 ; // 通过指针偏移来访问
*(*(arr+i)+j)
(*(arr+i))[j]
int arr[2][3] = { {1,2,3} , { 4,5,6} };int arr1[2][3] = { 1,2,3,4,5,6};int *p = arr ; // p指向数组arr 的首元素for (int i = 0; i < 2; i++){for (int j = 0; j < 3; j++){printf("arr[%d][%d]:%d\t" ,i ,j , arr[i][j] );}}printf("\n");for (int i = 0; i < 6 ; i++){ // *arr 得到元素1 的地址 + 1 则是加一个 int 类型printf("*(*(arr+%d)):%d\t" , i,*(*(arr)+i) );}printf("\n");for (int i = 0; i < 6 ; i++){ // arr 指的是首元素的首地址 {1,2,3} 的首地址 + 1则 + 3个整型printf("*(*(arr+%d)):%d\t" , i,*(*(arr+i)) );}for (int i = 0; i < 6 ; i++){ // p 只是一个普通的整型指针, 与二维数组没有任何的关系printf("*(p+%d):%d\n" , i ,*(p+i));}
内存管理
C语言进程的内存布局:
程序:就是我们写好的代码并编译完成的那个二进制文件,它被存放与磁盘(硬盘)中,它是死的。
进程:把磁盘中的二进制文件"拷贝"到内存(内存条)中取执行它,让运行起来,它是活的。
所有的程序被执行起来之后,系统会为他分配各种资源内存,用来存放该进程中用到的各种变量、常量、代码等等。这些不容的内容将会被存放到内存中不同的位置 (区域),不同的内存区域他的特性是有差别。每一个进程所拥有的内存都是一个虚拟的内存,所谓的虚拟内存是用物理内存中映射(投影)而来的,对于每一个进程而言所有的虚拟内存布局都是一样的。==让每个进程都以为自己独自拥有了完整的内存空间==。
物理内存(Physical Memory)
虚拟内存(Virtual Memory)
![]()
虚拟内存的布局(区域):
栈 (stack)
堆(heap)
数据段
代码段
![]()
![]()
栈空间
![]()
栈空间的特点:
- 空间非常有限,尤其在嵌入式的环境下,因此我们应该尽可能少去使用栈空间内存,特别是要存放比较大的数据。
ulimit -a
stack size (kbytes, -s) 8192 当前64位系统 默认只有8M栈内存
$ ulimit -s 10240 // 临时修改为 10M 重启后会回到默认值
- 每当一个函数被调用的时候, 栈空间会向下增长一段,用来存放该函数的局部变量
- 当一个函数退出的时候 , 栈空间会向上回缩一段,该空间的所有权将归还系统
- 栈空间的分配与释放,用户是无法干预的, 全部由系统来完成。
- 先进后出
静态变量
在C语言中有两种静态变量
全局变量: 定义在函数体之外的变量
静态的局部变量: 定义在函数体内部而且被 static 修饰的变量
int c ; // 在函数体之外,属于全局变量 --> 静态变量int func(int argc , char * argv[] ) // argc argv 属于main函数的局部变量
{int a ; // 局部变量static int b ; // 静态局部变量// 静态的局部变量 初始化语句只会被被执行一次}
为什么会有静态变量?
- 当我们需要把一个变量引用到不同的函数内部甚至不在同一个.c 文件中,可以全局变量来实现。
- 当我们需要一个局部变量用来记录某个值, 并希望这个值不会被重新初始化的情况下可以使用静态的局部变量。(static 修饰)
数据段与代码段
数据段有哪些内容:
- .bss 未初始化的静态数据 , 会被自动初始化为0
- .data 已初始化的静态数据
- .rodata 存放常量数据 “Hello Myoung” , 不允许修改的(只读)
代码段中有那些内容:
- 用户的代码 (比如我们自己写函数func…main)
- 系统初始化代码,由编译器为我们添加的
![]()
![]()
堆内存
堆内存,又称为动态内存、自由内存、简称堆。唯一一个由开发者随意分配与释放的内存空间。具体的申请大小,使用的时常都是由我们自己来决定。
堆内存空间的基本特性:
- 相对与栈空间来说 ,堆空间大很多(堆的大小受限于物理内存),系统不会对对空间进行限制。
- 相对与栈空间来说, 堆内存是从下往上增长的。
- 堆空间的内存称为匿名内存, 不像栈空间那样有个名字,只能通过指针来访问
- 堆空间内存的申请与释放都是由用户自己完成,用户申请之后需要手动去释放,直到程序退出。
如何申请堆空间内存:
malloc (只是申请内存而已,并不会/清空)
malloc (向系统申请内存)
头文件: #include <stdlib.h>
函数原型: void *malloc(size_t size);
参数分析: size --> 需要申请的内存 (字节为单位)
返回值: 成功 返回一个指向成功申请到内存的指针(入口地址) 失败 返回 NULL
calloc (会把内存进行清空)
calloc (向系统申请内存)
头文件: #include <stdlib.h>
函数原型: void *calloc(size_t nmemb, size_t size);
参数分析: nmemb – > N 块内存(连续的) size – > 每一块内存的大小尺寸
返回值: 成功 返回一个指向成功申请到内存的指针(入口地址) 失败 返回 NULL
realloc
realloc (重新申请空间)
头文件: #include <stdlib.h>
函数原型: void *realloc(void *ptr, size_t size);
参数分析: ptr --> 需要 扩容/缩小 的内存的入口地址 size --> 目前需要的大小
返回值: 成功 返回修改后的地址 失败 NULL
清空内存的值
包含头文件<string.h>
bzero
函数原型:extern void bzero(void *s, int n)
参数分析:
功 能: 置字节字符串s的前n个字节为零且包括‘\0’
memset
函数原型:extern void *memset(void *buffer, int c, int count)
功 能:把buffer所指内存区域的前count个字节设置成c的值。
bzero和memset区别
1、bzero()不是ANSI C函数,其起源于早期的Berkeley网络编程代码,但是几乎所有支持套接字API的厂商都提供该函数;
2、memset()为ANSI C函数,更常规、用途更广。(建议使用)
如何释放堆空间内存:
free
free(释放堆内存)
头文件: #include <stdlib.h>
函数原型: void free(void *ptr);
参数分析: ptr --> 需要释放的内存的入口地址
返回值; 无
内存拷贝函数:
memcpy
strcpy
strncpy
sprontf
…
总结
- 使用malloc 申请内存时 , 内存中的值时随机值 , 可以使用memset清空
- calloc 申请内存时 , 内存中的值会被初始化为 0
- free 只能释放堆空间的内存,不能释放其它区域的内存
释放内存的含义:
- 释放内存仅仅意为着,当前内存的所有权交回给系统
- 释放内存并不会清空内存的内容
- 也不会改变指针的指向,需要手动把指针指向NULL ,不然就成野指针了
指针进阶
char 型指针
从本质上来看,字符指针其实就是一个指针而已, 只不过该指针用来指向一个字符串/字符串数组。
char * msg = "Hello Myoung" ;
多级指针:
- 如果一个指针p1 它所指向的是一个普通变量的地址,那么p1就是一个一级指针
- 如果一个指针p2 它所指向的是一个指针变量的地址,那么p2就是一个二级指针
- 如果一个指针p3 它所指向的是一个指向二级指针变量的地址,那么p3就是一个三级指针
int a = 100 ;
int * p1 = &a ; // 那么p1就是一个一级指针
int ** p2 = &p1 ; // 那么p2就是一个二级指针
int *** p3 = &p2 ; // 那么p3就是一个三级指针
![]()
char * p1 ; // 第一部分: * p1 , 第二部分 char 说明p1 指向的类型为char
char **p2 ; // 第一部分: * p2 ,第二部分 char * 说明p2 指向的类型为char *
int **p3 ; // 第一部分: * p3 ,第二部分 int * 说明p3 指向的类型为int *
char (*p4) [3] ; // 第一部分: * p4 , 第二部分 char [3] , 说明p4 指向一个拥有3个元素的char 数组
char (*p5) (int , float) ; // 第一部分: * p5, 第二部分char (int , float) , 说明 // 说明该指针指向一个 拥有char类型返回, 并需要一个int 和 float 参数的函数void *(*p6) (void *); //第一部分: * p6, 第二部分 void * (void *)// 说明p6 指向一个 拥有 void * 返回并需要一个void * 参数的函数 函数指针)
指针函数和函数指针
指针函数:
int *fun(int x,int y);
int * fun(int x,int y);
int* fun(int x,int y); //如果 * 靠近返回值类型的话可能更容易理解其定义(返回值为int* 型)。函数指针:
int (*fun)(int x,int y); //fun地址在栈空间函数指针是需要把一个函数的地址赋值给它,有两种写法:
fun = &Function; //取地址运算符&不是必需的,因为一个函数标识符就表示了它的地址
fun = Function; //Function地址在断码段调用函数指针的方式也有两种:
x = (*fun)();
x = fun();
void 型指针
概念: 表示该指针的类型暂时是不确定
要点:
- void 类型的指针,是没有办法直接索引目标的。必须先进行强制类型转换。
- void 类型指针,无法直接进行加减运算。
void关键字的作用:
- 修饰指针,表示该指针指向了一个未知类型的数据。
- 修饰函数的参数列表, 则表示该函数不需要参数。
- 修饰函数的返回值,则表示该函数没有返回值。
void * p = malloc(4) ; // 使用malloc 来申请 4个字节的内存, 并让p来指向该内存的入口地址*(int *)p = 250 ; // 先使用(int*) 来强调p是一个整型地址 ,然后再解引用
printf("*p:%d\n", *(int*)p);// 输出时也应该使用对应的类型来进行输出*(float*)p = 3.14 ;
printf("*p:%f\n", *(float*)p);//注意:以上写法 void * p , 在实际开发中不应该出现。以上代码只是为了说明语法问题。
const 指针
const修饰指针有两种效果:
- 常指针 修饰的是指针本身, 表示该指针变量无法修改、不能去指别的了
char * const p ;char arr [] = "Hello" ; char msg [] = "Myoung" ; char * const p = arr ;// p = msg ; //编译报错:error: assignment of read-only variable ‘p’ 只读// p 被const 所修改, //说明P是一个常量 ,他的内容(所指向的地址)无法修改*(p + 1 ) = 'M' ; // p所指向的内容是可以通过p 来修改 (只要保持P所指向的地址不变即可) printf("%s\n" , p ); --->HMllo- 常目标指针 修饰的是指针所指向的目标,表示无法通过该指针来改变目标的数据
char const * p ;
const char * p ;
char arr [] = "Hello" ;
char msg [] = "Myoung" ; const char * p1 = arr ;
p1 = msg ; // p1 的指向是可以被修改的
// *(p1+1) = 'V' ; //编译报错:assignment of read-only location ‘*(p1 + 1)’// 常目标指针, 不允许通过该指针来它所指向的内容*(msg+1) = 'V' ; // 虽然p1不能修改所指向的内容, 但是内容本身是可以被修改的printf("%s\n" , p1 ); --->MVoung
总结:
- 常指针并不常见。
- 常目标指针,在实际开发过程中比较常见,用来限制指针的权限为 只读
![]()
函数
函数入门
在C语言的编程中,其实用到很多的函数,而每一个函数就可以理解为一个独立的模块, 因此C语言也称为模块化编程。
我们封装函数应该尽可能左到:低耦合,高内聚
对于函数的使用者来说,应该尽可能简单地去使用该函数接口,使用者只管往函数中输入需要的数据, 通过该函数获得一个结果即可。
![]()
例如使用美图软件进行修图。你只需要输入美图的级别1-10 级, 该软件则会输出一个美化之后的图像给你。
函数的定义
函数头: 函数对外公开的接口信息。 比如:void *calloc(size_t nmemb, size_t size);
- 函数的返回值 , 该函数运行结束后会返回什么东西给你 , 比如: void *
- 函数名, 命名规则跟变量一致。应该尽量顾名思义。比如: calloc
- 参数列表,告诉用户该函数需要输入的数据以及类型,有可能有多个也可能没有 , 比如(size_t nmemb, size_t size)
语法:
返回值类型 函数名 ( 参数1 , 参数2 ,参数3 , ... , 参数N )
{// 函数体return 返回值 ;
}
形参与实参
概念:
函数调用的时候传递的值,称为实参 max(123.034 , ‘C’ , “87”) ;
函数定义当中出现的参数列表,称为形参 max(float a , char b , char * c)
实参与形参的关系:
- 实参与形参应该是一一对应的。(顺序+类型)
- 形参的值是由实参进行初始化。
- 形参与实参是处于两个完全不相关的栈空间中。彼此是独立的
![]()
局部变量与栈内存
局部变量: 被函数体的一对大括号所包含的变量,称为局部变量(在函数体内部定义)
局部变量的特点:
- 属于函数内部的变量, 所存储的位置是该函数所拥有的栈空间
- 局部变量不会被其它函数所访问,因此不同的函数内部可以拥有完全一样的两个变量名字, 但是从内存来看它们是完全独立的。
- 当函数退出的时候, 局部变量所占用的内存,将会被系统回收,因此局部变量也称为临时变量。
- 形参当中的变量,虽然没有在大括号的范围内, 但是也是属于该函数的局部变量。
栈内存的特点:
- 当有一个函数被调用的时候,栈内存将会增长一段, 用来存放该函数的局部变量。
- 当函数退出时,他所占用的栈内存将会被释放回收。
- 系统分配栈空间遵循从上往下增长的原则。
- 栈空间的内存相对来说比较少, 不建议用来存放大量的数据。
![]()
特殊函数
静态函数
(static修饰)
背景: 普通的函数都是跨文件可见的,也就是比如a.c里面有个函数swap(), 在b.c中也可以调用该函数。
静态函数:只能够在当前定义的文件中使用,称为静态函数
static int func (int , int b )
{// 函数体 }
注意:
- 静态函数用来缩小可见范围,减少与其它文件中同名函数冲突的问题
- 静态函数一般会定义在头文件中, 然后被需要使用该函数的源文件包含即可。
递归函数
递归函数的概念: 如果一个函数的内部,包含了对自己的调用则称为递归函数。
递归的问题:
- 阶乘
- 幂运算
- 字符反转
要点:
- 只有可以被递归的问题,才可以使用递归函数来实现。
- 递归函数必须有一个可以直接退出的条件,否则会进入‘无限’递归,最后导致栈溢出。
- 递归函数包含了两个过程: 逐渐递进 , 逐步回归。
例子:
要求使用递归来输出n个自然数
思路: 先输出n-1个自然数, 最后才输出N
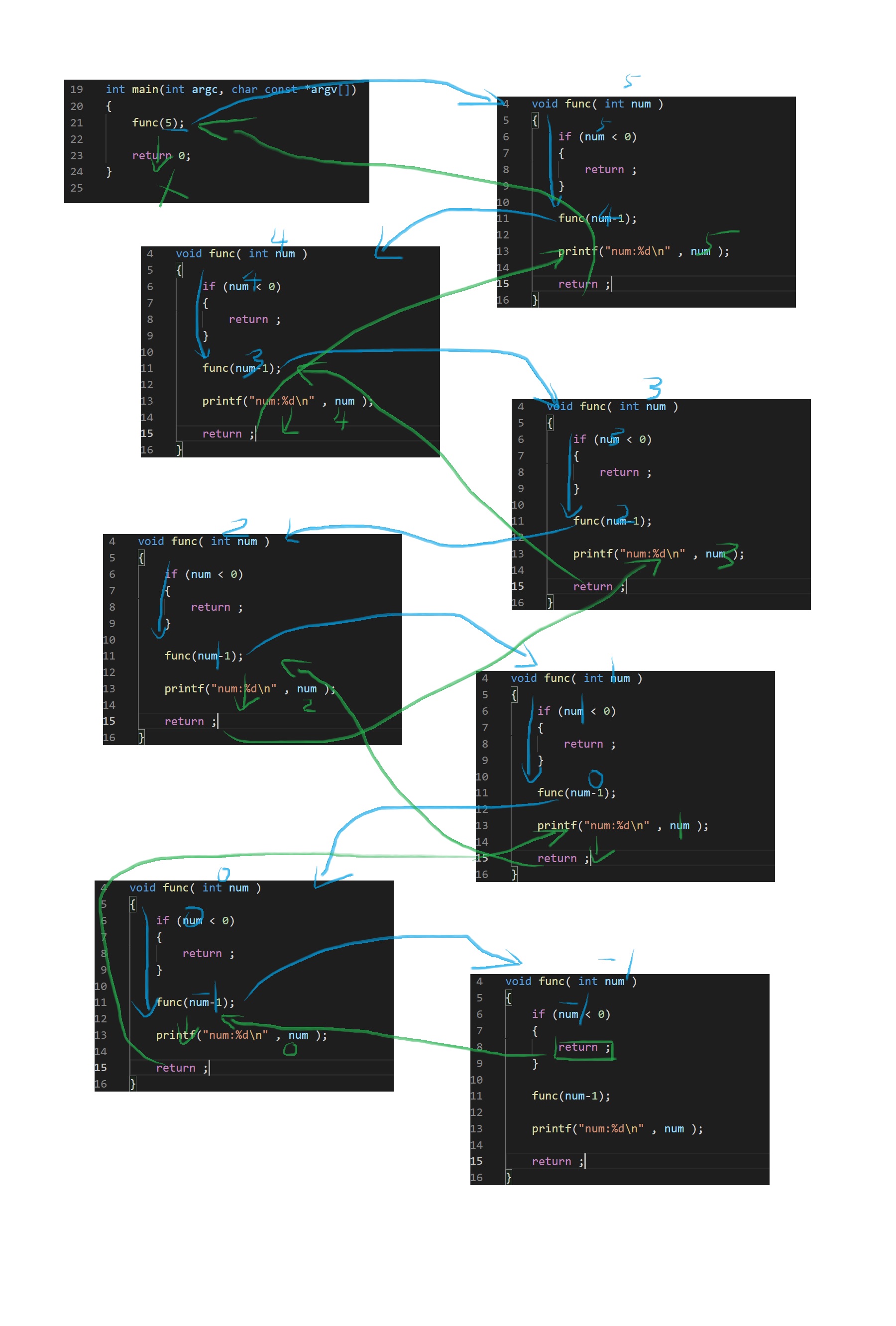
![]()
总结:
递归的时候函数的栈空间,会随之从上往下不断增长,栈空间会越来越少, 直到耗尽或者开始返回。
在一层一层递进的时候,问题的规模会随之缩小,当达到某一个条件的时候,则开始一层一层回归。
回调函数
概念:函数实现方不方便调用该函数,而由接口提供方来调用该函数,就称为回到函数。
例子:
#include <stdio.h>
#include <signal.h>void func(int num )
{printf("当前收到 3 号信号 , 军师让我蹲下 !!\n");
}int test( int num , void (*p)(int) )
{for (size_t i = 0; i < num ; i++){printf("num:%d\n" , num-- ); if (num == 50 ){p(1);}}return 0 ;
}int main(int argc, char const *argv[])
{void (*p)(int); // 定义一个函数指针p = func ; // 让指针p 指向函数 func test( 100 , p );return 0;
}
#include <stdio.h>
#include <signal.h>void func(int num )
{printf("当前收到 3 号信号 , 军师让我蹲下 !!\n");
}int main(int argc, char const *argv[])
{void (*p)(int); // 定义一个函数指针p = func ; // 让指针p 指向函数 func // 设置进程捕获信号 ,如果信号值 为 3的时候 , 会自行调用 p 所指向的函数 (代码/指令)signal( 3 , p ); //另外开一个终端 ~$ killall -3 a.out while(1); return 0;
}
总结:
- signal 函数是一个用于捕获信号的函数, 当他捕获到指定信号的时候则会执行用户所提供的函数。
- 由于signal函数是内核提供的函数,修改内核的代码不现实, 因此它提供的接口是一个函数指针,只要某个条件满足则会自动执行我们所给的函数。
- 使得不同软件模块的开发者的工作进度可以独立出来,不受时空的限制,需要的时候通过约定好的接口(或者标准)相互契合在一起
指针函数和函数指针
指针函数:
int *fun(int x,int y);
int * fun(int x,int y);
int* fun(int x,int y); //如果 * 靠近返回值类型的话可能更容易理解其定义(返回值为int* 型)。函数指针:
int (*fun)(int x,int y); //fun地址在栈空间函数指针是需要把一个函数的地址赋值给它,有两种写法:
fun = &Function; //取地址运算符&不是必需的,因为一个函数标识符就表示了它的地址
fun = Function; //Function地址在断码段调用函数指针的方式也有两种:
x = (*fun)();
x = fun();
内联函数
不适用内联函数的情况下,有可能某一个函数被多次重复调用则会浪费一定的时间在调用的过程中
(现场保护+恢复)![]()
如果使用内联函数就相当与把需要调用的函数的内容(指令)拷贝到需要调用的位置,可以节省函数调用的过程中浪费的时间
![]()
语法:与普通函数区别不大, 只是在前面增加了函数的修饰 inline
inline int max_value(int x, int y);
list.h:static inline void INIT_LIST_HEAD(struct list_head *list)
{list->next = list;list->prev = list;
}main.c:
#include <list.h>int main()
{INIT_LIST_HEAD ( *p ) ;// 当前这一行代码在编译完成后会被该函数实际的代码进行替换/*list->next = list;list->prev = list;*/return 0 ;
}
注意:内联函数在提高运行效率的过程中,消耗了更多的内存空间。
变参函数
指参数的个数以及类型是可以根据实际y应用有所变化的。
分析打印函数如何实现变参:
printf("%d%c%lf", 100, ‘x’, 3.14);
如上代码中, 各个参数入栈的顺序是从右往左进行的。
![]()
作用域
概念:
C语言中所有的标识符(变量/名字)都有可见范围。为了搞清楚这些标识符的可见范围我们来研究一下,而可见分为也被称为作用域。
在软件开发的过程中应该尽可能缩小标识符的可见范围,可以尽可能的降低同名冲突的问题。
函数声明的作用域
概念: 一般写在头文件内部, 或者源文件的头部。用来告诉编译器函数的模型。
main.c// 函数声明
bool swap( int * , int * );
int max( int a , int b , int c );
作用域:
只是当前文件可见。虽然写在函数体外但是并不是全局的。
函数头中的作用域
int max( int a , int b , int c ) // 函数头
{// 函数体
}
作用域:
max 默认是全局可见的
例外情况 被static 修饰则本文件可见
变量 a, b, c 是属于该函数的局部变量, 因此作用域在函数体内部
局部作用域
概念: 在代码块内不定义的变量 ,可见范围从定义语句开始直到该代码块的右括号右边结束 }
示例:
{int b = 250 ;{int c = 399 ;// c 作用域开始 // b =250int b = 249;}// c 作用域的结束// b =250 printf("c:%d\n" , c) ; // 已经离开了c的作用域因此不能使用
}例如实际中:for (size_t i = 0; i < argc ; i++){printf("argv[%ld]:%s\n" , i , argv[i]);}printf("%d" , i ); // i未定义, 已经离开的I的可见范围
注意:
- 代码块指的是一对 { } 所括起来的区域
- 代码块可互相嵌套,外层的标识符,可以被内层识别, 反之则不行
- 在内码块内部定义的标识符 , 在外面其它的代码块中是不可见,因此称为局部作用域
全局作用域
概念: 在代码块的外部定义,他的可见范围是可以跨文件可见的。
注意:
在函数体外部定义
不可以被static修饰, 修饰之后就变成本文件可见(可见范围被缩小)。
作用域的临时掩盖
如果有多个不同的作用域互相嵌套,小的作用域的作用范围会临时掩盖大的作用域(标识符名字相同)。临时失去大作用域的值。
int a = 1 ;{printf("1a:%d\n" , a);// 输出 为 1 , 使用的是外面大的作用域int a = 250 ; // 从这里开始 a 的值被临时覆盖为 250 外面的1临时失效printf("2a:%d\n" , a);// 输出 为 250 , 使用的是内部的小的作用域
}printf("3a:%d\n" , a); // 离开小的作用域后 ,a 恢复为 1
static 关键字
在C语言中非常重要的一个角色, 它在不同的场合表现的意义不一样。
- 把可见范围进行缩小为本文将可见:
修饰全局变量
修饰普通的函数(该函数只能在本文件.c中使用)
- 把变量的存储区修改为静态数据(数据段):
- 修饰局部变量, 使得局部变量的存储区从栈改为数据段
修饰全局变量
1)位置:静态局部变量被编译器放在全局存储区.data(注意:不在.bss已初始化段内,原因见3)),所以它虽然是局部的,但是在程序的整个生命周期中存在。
2)访问权限:静态局部变量只能被其作用域内的变量或函数访问。也就是说虽然它会在程序的整个生命周期中存在,由于它是static的,它不能被其他的函数和源文件访问。
3)值:静态局部变量如果没有被用户初始化,则会被编译器自动赋值为0,以后每次调用静态局部变量的时候都用上次调用后的值。这个比较好理解,每次函数调用静态局部变量的时候都修改它然后离开,下次读的时候从全局存储区读出的静态局部变量就是上次修改后的值。
存储期
概念:
C语言中, 每一个变量都有一个生命周期,所谓的生命周期指的是某一个变量的内存从申请到释放的过程。申请一个内存相当于某一个变量的诞生,释放掉该内存则是相当于消亡。
变量的生命周期有一下三种形式:
- 自动存储期
- 静态存储期
- 自定义存储期
![]()
自动存储期
在栈空间中分配的变量(内存) , 统统由系统统一管理,用户不需要担心,因此就称为自动存储期。
有一下几个概念是等价的:
- 自动化变量: 从存储期的角度来描述变量的存储特性
- 临时变量: 从存储期的角度来描述变量的存储特性
- 局部变量: 从作用域的角度来表述变量的空间特定
int main(int argc , char const * argv[]) // argc argv 自动存储期 / 局部变量
{int a ; // 自动存储期 / 局部变量 static int b ; // 静态存储期 局部变量 func(a , b);
}void func(int x , int y) // x, y 自动存储期 / 局部变量
{}
静态存储期
在数据段中分配的变量(内存) , 统统都称为静态存储期,静态存储期的内存, 在程序运行之初就已经分配好 , 不会随着程序的运行发生申请和释放的问题 ,直到整个程序退出才会释。 换句话说他的生命周期与进程一致。
静态存储期:
- 全局变量,static只是影响他的作用域,并不影响他的存储期
- static修饰的局部变量,对于局部变量而言static只是改变了变量的存储期,而没有改变他的作用域。
int a = 100 ;
static int b = 250 ; // a b 都属于静态存储期, 只不过b的作用域为本文件int main()
{int k ;int a = 350 ;static int k = 450 ; // 静态存储期
}
注意:
.bss 段 存放的是未初始化的静态变量(静态存储期) 初始值为 0
.data 段 已经初始化的静态变量 , 初始化语句只会被执行一次
静态数据从进程运行之初已经存在, 直到进程退出为止
自定义存储期
在堆内存中分配的变量(内存) , 都属于自定义存储期,他的申请与释放完全由用户自己把握。
如何申请:
malloc calloc realloc
如何释放:
- free
- 如何清空:
- bzero
- memset
注意:
- malloc 只负责申请空间, 并不会清空内存,因此一般使用bzero 清空
- calloc 负责申请内存,并会默认清空为 0 .
- free 只负责释放,也不会清空 更不会让指针指向空, 因此free之后最好让指针指向NULL
结构体
概念:
C语言提供了很多的基础数据类型,但是实际的生活/开发中,单纯一个基础数据类型,Int float double 不足以描述某一个事务。比如描述一本数:名字、作者、定价、版本…,因此需要一个综合的类型用来描述它。
我们作为开发者可以使用C语言预定提供的一些基础数据类型来自信组合成为一个新的数据类型(结构体)。在使用自己定义的数据类型之前需要先声明该类型的模样:
struct 结构体标签
{成员1 ;成员2 ;成员3 ; .........
};
注意:
- struct : 关键字 , 用来告诉编译器 我要声明的东西是一个自定义的类型*(结构体)
- 结构体标签:用来区分不同的结构体类型
- 成员:指结构体内部由哪些基础数据类型所构成, 可以是任何的数据类型
![]()
成员引用
结构体相当于一个数据的集合, 里面由多个不同类型的数据组合而成,每一个成员都可以通过成员引用符来单独引用语法
结构体变量名.成员 // 普通的结构体变量
结构体指针变量->成员 // 结构体指针的访问方法
// 修改结构体变量中某一个成员的值
c.Price = 5 ;// 如何引用printf("Book:%s \nPrice:%f \nName:%s\n" , c.Book, c.Price , c.Name);
对结构体的堆内存进行赋值需要注意:
![]()
![]()
由上图可知如果Book指向的是另外一个堆空间,那么在释放结构体的内存时,需要先释放Book 所指向的内存区。
// 结构体声明 --> 不占用内存空间
struct TieZhu
{int num ;char * Book ;float Price ;char Name [32] ;
};void main()
{// 结构体变量 定义与初始化struct TieZhu a = {123 , "Book" , 3.154 , "Even"} ;// 结构体指针struct TieZhu * p = calloc(1, sizeof(struct TieZhu));// 结构体数组int arr [10] ;struct TieZhu arr [10] ;//成员引用a.num = 245 ;p->num = 250 ;arr[0].num = 399 ;
}
结构体声明的变异
// 结构体声明 --> 不占用内存空间
struct TieZhu
{int num ;char * Book ;float Price ;char Name [32] ;
};
变异 1 :
在声明结构体类型时, 顺便定义了变量
struct TieZhu
{int num ;char * Book ;float Price ;char Name [32] ;
} Even , *Jacy ; // 在声明结构体类型时, 顺便定义了两个变量Even.num = 1024 ;
Jayc = &Even ; // 让指针Jacy 指向Even的地址
Jacy->Book = "Hello" ;
变异 2 :【推荐使用】
使用 typedef 来给结构体的类型取别名
Tz 相当于 struct TieZhu 可以直接定义普通结构体变量
P_Tz 相当于 struct TieZhu * 可以直接定义结构体指针变量
typedef struct TieZhu
{int num ;char * Book ;float Price ;char Name [32] ;
}Tz , * P_Tz ;
例子:
// 结构体声明 --> 不占用内存空间
typedef struct TieZhu
{char * Book ;float Price ;char Name [32] ;
}Tz , *P_Tz ;int main(int argc, char const *argv[])
{Tz b = {.Book = "Hello" ,.Name = "Even",.Price = 3.14 }; P_Tz p = &b ;printf("Name : %s \n" , b.Name );printf("Name : %s \n" , p->Name );return 0;
}
结构体数组:struct TieZhu arr[5] ; // 拥有5个结构体的元素的数组结构体数组指针:struct TieZhu(*p)[5] ; // 指向的是一个 拥有5个元素的结构体数组结构体指针数组:struct TieZhu * arr[5]; // 存放的是5个结构体类型的指针
预知结构体的内存:
![]()
结构体尺寸
CPU 字长
字长就是指CPU(处理器)在执行一条指令时,最大一个运算能力,这个运算能力由两部份决定一个就是处理器本身的运算能力, 另一个就系统的字长,比如常见的32位/64位系统,如果使用32位系统那么在处理数据的时候每一次最对多可以处理32位的数据(4字节) 。
![]()
地址对齐
地址对齐
每一款不同的处理器,存取内存数据都会有不同的策略,如果是 32 位的 CPU,一般来讲他在存取内存数据的时候,每次至少存取 4 个字节(即 32 位),也就是按 4 字节对齐来存取的。换个角度讲:CPU 有这个能力,他能一次存取 4 个字节。
接下来我们可以想到,为了更高效地读取数据,编译器会尽可能地将变量塞进一个 4字节单元里面,因为这样最省时间。如果变量比较大,4 个字节放不下,则编译器会尽可能地将变量塞进两个 4 字节单元里面,反正一句话:两个坑能装得下的就绝不用三个坑。这就是为什么变量的地址要对齐的最根本原因。
![]()
![]()
所谓地址对齐主要思想:
尽可能提高CPU的运行效率(仅能能的少取读取/写入内存)
一个数据如能使用一个单元来存放感觉对不使用两个, 两个能放绝对不用三个
普通变量的M值
概念: 一个数据它的大小是固定的(比如整型),如果这个数据他所存放的地址能够被某一个数所整除(4)那么 这个数就成为当前数据的M值。
可以根据具体的系统字长以及数据的大小可以计算得出M值。
int i ; // i 占用 4 字节, 如果i 存放在能被4整除的地址下则是地址对齐, 因此他的M值为4
char c ;// c占用 1 字节, 如果c 存放在能被1整除的地址下则是地址对齐, 因此他的M值为1
short s ;// s 占用 2 字节, 如果s 存放在能被2整除的地址下则是地址对齐, 因此他的M值为2
double d ; // d 占用 8 字节, 如果d 存放在能被4整除的地址下则是地址对齐, 因此他的M值为4
float f ;// f 占用 4 字节, 如果f 存放在能被4整除的地址下则是地址对齐, 因此他的M值为4 i:0x7fffc900a298
s:0x7fffc900a296
c:0x7fffc900a295
d:0x7fffc900a2a0
f:0x7fffc900a29c
注意:如果一个变量的大小超过4 (8/16/32) M值则按4计算即可
手残干预M值:
char c __attribute__((aligned(16))) ;
注意:
__attribute__ 机制是GNU特定语法,属于C语言标准的拓展。
__attribute__ 前后都有个两个下划线_
__attribute__ 右边由两对小括号 (( ))
__attribute__ 还支持其它的设置......
一个变量他的M值只能提升不允许降低 , 只能是2的N次幂
计算结构体的大小
结构体大小计算方法:
1、整体对齐: 以最大的类型的字节数为对齐字节数,成员按顺序填充
2、局部对齐: 填充时,与前面已分配好的的成员,最大字节对齐
3、结尾补齐: 补齐最大字节数,最终为最大字节的整数倍
由于存储变量地址对齐的问题,计算结构体大小的3条规则:
- 结构体变量的首地址,必须是结构体变量中的“最大基本数据类型成员所占字节数”的整数倍。(对齐)
- 结构体变量中的每个成员相对于结构体首地址的偏移量,都是该成员基本数据类型所占字节的整数倍。(对齐)
- 结构体变量的总大小,为结构体变量中“最大基本数据类型成员所占字节数”的整数倍(补齐)
struct Test1
{int b;double c; long d;
}Test1;
int main()
{printf("size = %d\n", sizeof(Test1));return 0;
}
![]()
![]()
可移植性
对于可移植的结构体来说一定要解决好该结构体在不同的操作系统(位数)如何统一 该结构体的大小。
方法有两个:
方法1 :
直接使用attribute 进行压实, 每一个成员之间没有留任何的空隙。
typedef struct node
{int i ;char c ;short s ;double d ;long double ld ;char kk ;float f ;
}__attribute__(( packed ));
方法2 :
对每一个成员进行压实
struct node
{int i __attribute__((aligned(4))) ;char c __attribute__((aligned(1)));short s __attribute__((aligned(2)));double d __attribute__((aligned(4)));long double ld __attribute__((aligned(4))) ;char kk __attribute__((aligned(1))) ;float f __attribute__((aligned(4)));
};
注意:
结构体的大小取决于多个因素
- 地址对齐,M值的问题, 默认情况下结构体的大小为成员中最大的倍数
- 结构体内部的每一个成员的大小都与系统的位数有关
- 如果需要实现可移植性,结构体的每一个成员需要使用可移植类型+attribute机制对结构体进行压实
联合体与枚举
联合体概念
联合体从表面上看与结构体非常类似,但是他们的本质完全不同。结构体每一个成员都有一个独立的内存空间, 但是联合体的每一个成员公用同一个内存空间因此联合体也被称为共同体。
语法:
union 联合体标签
{成员1 ;成员2 ;成员3 ;};
联合体标签 : 用来区分不同类型的联合体
成员: 联合体内存的各个成员
// 声明联合体
union node
{int i ;char c ;short s ;double d ;
};int main(int argc, char const *argv[])
{// 联合体变量定义union node data;printf("size:%ld\n" , sizeof(data));printf("i:%p\n" , &data.i );printf("c:%p\n" , &data.c );printf("s:%p\n" , &data.s );printf("d:%p\n" , &data.d );return 0;
}
注意:
联合体的尺寸取决于,联合体中成员宽度最宽的。
联合体中所有成员的内存地址(首地址)是同一个
在同一时间内,有效的成员只有一个
当我们给联合体某一个成员赋值的时候其它成员则失效(数据无效)
![]()
联合体的使用
联合体一般来说比较少使用, 如果要用很可能会出现在结构体内部,用来描述一种互斥的数据。
示例:
#include <stdio.h>
#include <string.h>// 声明结构体
typedef struct demo
{char Nmae[32];char Type ; // S 学生 T 老师 F 打饭阿姨 Q 清洁工union {float num ; // 成绩int i ; // 手抖值char c ; // 清洁能力}stat;
}Node ;int main(int argc, char const *argv[])
{Node data [3] ;// 把"Even" 拷贝到 结构体数据则第0 位, 希望拷贝32 字节strncpy(data[0].Nmae , "Even" , 32 );data[0].Type = 'Q' ;data[0].stat.c = 'A';// 学生strncpy((data+1)->Nmae , "Jacy" , 32 );(data+1)->Type = 'S' ;(data+1)->stat.num = 13.86 ;// 阿姨strncpy((data+2)->Nmae , "CuiHua" , 32 );(data+2)->Type = 'F' ;(data+2)->stat.i = 13 ;for (size_t i = 0; i < 3 ; i++){switch((data+i)->Type){case 'Q':printf("当前输出为清洁工:\n 名字:%s\t人猿类型:%c\t清洁能力:%c\n",(data+i)->Nmae ,(data+i)->Type , (data+i)->stat.c );break ;case 'S':printf("当前输出为学生:\n 名字:%s\t人猿类型:%c\t学习能力:%f\n",(data+i)->Nmae ,(data+i)->Type , (data+i)->stat.num );break ;case 'F':printf("当前输出为打饭阿姨:\n 名字:%s\t人猿类型:%c\t抖肉能力:%d\n",(data+i)->Nmae ,(data+i)->Type , (data+i)->stat.i );break ;}}return 0;
}
字节序
![]()
枚举概念
枚举本质上一种范围受到限制的整型,比我们可以使用 0 - 3 表示4种状态(比如某个硬件的状态:打开、运行、暂停、关闭)
枚举常量列表:
语法:
enum 枚举标签 { 常量1 , 常量2 ,常量3 ,常量4 ,} ;enum MIC { open , run , stop , close } ;
使用:
#include <stdio.h>// 声明枚举常量列表
enum MIC { open , run , stop , close } ;int main(int argc, char const *argv[])
{enum MIC stat = run ;switch(stat){case open:printf("麦克风状态为打开:%d\n" , open);break;case run:printf("麦克风状态为运行中:%d\n" , run);break;case stop:printf("麦克风状态为暂停:%d\n" , stop);break;case close:printf("麦克风状态为关闭:%d\n" , close);break;}return 0;
}
枚举常量的值可以手动修改:
// 声明枚举常量列表
enum MIC { open , run = 5 , stop , close } ;
总结:
- 默认情况下枚举常量实际它的值为整型值, 并首个元素默认为0
- 可以在声明枚 举常量列表的时候对给他进行赋值, 如果没有赋值则等于前一个常量值+1
- 在C语言中 枚举等价于整型,支持所有整型的操作
printf("%d\n" , run+stop);
枚举的作用提供了一个确定范围, 使用一个有意义的单词来表示一个整型数字提高代码的可读性
编译器与宏定义
比如一下宏, 如果需要使用则需要包含它所在的头文件
/usr/include/linux/input-event-codes.h
....
#define ABS_X 0x00
#define ABS_Y 0x01
#define ABS_Z 0x02
#define ABS_RX 0x03
#define ABS_RY 0x04
#define ABS_RZ 0x05
...
编译器
概念: 编译器是一个用来帮助我们把原码.c翻译成计算机能够之直接识别的二进制编码(.o文件)。使用不同的编译器(交叉编译概念)可以翻译出来不同机器的二进制编码。
gcc 编译器:
gcc hello.c -o hellogcc --> C语言编译器
hello.c --> 需要编译的原码
-o --> 指定输出文件名
hello --> 可执行文件的名字
编译过程
![]() 1.预处理
1.预处理
gcc hello.c -o hello.i -E
加上一个编译选项 -E 就可以使得 GCC 在进行完第一阶段的预处理之后停下来,生成
一个默认后缀名为.i 的文本文件
预处理是指在编译代码之前先进行预先的处理工作,这些工作包含哪些内容:
- 头文件被包含进来(复制): #include
- 宏定义会被替换:#define
- 取消宏定义: #undef
- 条件编译: #if #ifdef #ifndef #else #elif #endif
- 修改行号以及文件名: #line 998 “Hello.c”
- 清除注释
预处理大部分的工作是在处理以 # 开头的一些语句,从严格意义来讲这些语句并不属于C语言的范畴, 它们在编译的第一个阶段被所谓的 预处理器 来处理。
2.编译
gcc hello.i -o hello.s -S
加上一个编译选项 -S 就可以使得 gcc 在进行完第一和第二阶段之后停下来,生成一
个默认后缀名为.s 的文本文件。打开此文件看一看,你会发现这是一个符合 x86 汇编语言
的源程序文件。
经过预处理之后生成的.i 文件依然是一个文本文件,不能被处理器直接解释,我们需要
进一步的翻译。接下来的编译阶段是四个阶段中最为复杂的阶段,它包括词法和语法的分析,
最终生成对应硬件平台的汇编语言(不同的处理器有不同的汇编格式)。
汇编文件取决于所采用的编译器,如果用的是 GCC,那么将会生成 x86 格式的汇编文件,
如果用的是针对 ARM 平台的交叉编译器,那么将会生成 ARM 格式的汇编文件。(交叉编译工具链)
3.汇编
gcc hello.s -o hello.o -c
-c 则是让编译器在对汇编语言文件进行编译后停下来,这里会生成一个待链接的可执行文件
则会生成一个扩展名为.o 的文件,这个文件是一个 ELF 格式的可重定位(relocatable)文件,所谓的可重定位,指的是该文件虽然已经包含可以让处理器直接运行的指令流,但是程序中的所有的全局符号尚未定位,所谓的全局符号,就是指函数和全局变量,函数和全局变量默认情况下是可以被外部文件引用的,由于定义和调用可以出现在不同的文件当中,因此他们在编译的过程中需要确定其入口地址,比如 a.c 文件里面定义了一个函数 func( ),b.c 文件里面调用了该函数,那么在完成第三阶段汇编之后,b.o 文件里面的函数 func( )的地址将是 0,显然这是不能运行的,必须要找到 a.c 文件里面函数 func( )的确切的入口地址,然后将 b.c 中的“全局符号”func重新定位为这个地址,程序才能正确运行。因此,接下来需要进行第四个阶段:链接。
可以尝试使用命令readelf 来查看这个可重定位文件
$ readelf demo.o -a
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-68VXcrvY-1661591277904)(C:/Users/SM520/Desktop/Linux%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/clipboard.png)]
4.链接
gcc hello.o -o hello -lc -lgccgcc .....hello.o ....-o ......hello .....-lc --> -l 链接 c 标准C库-lgcc --> -l 链接 gcc 链接GCC 的库
有两个很重要的工作没完成,首先是重定位,其次是合并相同权限的
一个可执行镜像文件可以由多个可重定位文件链接而成,比如 a.o,b.o,c.o 这三个可重定位文件链接生成一个叫做 x 的可执行文件,这些文件不管是可重定位的,还是可执行的,它们都是 ELF 格式的,ELF 格式是是符合一定规范的文件格式,里面包含很多段(section),比如我们上面所述的 hello.c 编译生成的 hello.o 有如下的格式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mPGwCb6r-1661591277904)(C:/Users/SM520/Desktop/Linux%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/clipboard-16607190242192.png)]
宏定义
宏的概念:
宏(macro)其实就是一个特定的字符串,用来直接替换比如:
#define PI 3.14上面定义了一个宏 名为 PI ,在下面代码的引用过程中 PI 将会被直接替换为实际的值
int main(int argc, char const *argv[])
{printf("%f\n" , PI ); printf("%f\n" , 3.14 ); return 0;
}/
宏的作用:
- 使得程序的可读取有所提高,使用一个又有意义的单词来表示一个无意义数字(某个值)
- 方便对代码进行迭代更新, 如果代码中有多处使用到该值, 则只需要修改一处即可(定义)
- 提高程序的执行效率,可以使用宏来实现一个比较简单的操作。用来替代函数的调用
无参宏
意味着我们在使用该宏的时候不需要携带额外的参数
// 定义一个宏用来表示 人数
#define PEOPLE 10系统中有预定义一些宏:
比如一下宏, 如果需要使用则需要包含它所在的头文件
/usr/include/linux/input-event-codes.h
....
#define ABS_X 0x00
#define ABS_Y 0x01
#define ABS_Z 0x02
#define ABS_RX 0x03
#define ABS_RY 0x04
#define ABS_RZ 0x05
...
带参宏
意味着我们在使用这些宏的时候,需要额外传递参数
#define MAX(a,b) a>b? a:b int main(int argc, char const *argv[])
{printf("%d\n" , MAX(198,288) );//printf("%d\n" , 198>288? 198:288 ); --> 预处理后return 0;
}
带参宏的副作用
由于宏只是一个简单的文本替换,中间不涉及任何的计算以及语法检查(类型),因此在使用复杂宏的时候需要小心注意
#define MAX(a,b) a>b? a:b int x = 100 ;
int y = 200 ;
printf("%d\n" , MAX( x, y==200 ? 988:1024 ) );
// printf("%d\n" , x>y==200 ? 988:1024? x:y==200 ? 988:1024 );
从直观上来看不管 y==200 ? 988:1024 结果如何都应该比100 大 ,但是由于宏是直接的文本替换,导致替换之后三目运算符的运算结果出现了偏差。
由于带参宏的这个偏差出现的原因主要是优先级的问题,因此可添加括号来解决:
#define MAX(a,b) (a)>(b)? (a):(b)printf("%d\n" , (x)>(y==200 ? 988:1024)? (x):(y==200 ? 988:1024) );
注意:
宏只能写在同一行中(逻辑行),如果迫不得已需要使用多行来写一个宏则可以使用转义字符==’\‘==把换行符转义掉
![]()
如上 41 42 43 为3个物理行, 但是通过转义字符让这三个物理行被看作同一个逻辑行
无值宏
在定义宏的时候不需要给定某一个值,对于无值来说只是用来做一个简单的判断(是否有定义)
#define DE_BUG
条件编译
根据某一个条件来决定某一代码块是否需要编译。
语法:
形式1:
通过无值的宏来判断 , 则只能判断是否有定义
#ifdef // 判断某一个宏是否有定义// 代码块#endif // 判断语句的结束#ifdef DE_BUG // 如果定义了DE_BUG 宏则一下代码块会被编译,反之则不会被编译printf("new:%s--%d--%s--%d\n" , new->Name ,new->age ,new->skill , new->udel );
#endif
#ifdef DE_BUG // 判断是否定义了printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif#ifndef DE_BUG // 判断是否没定义 printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif
形式2 :
通过有值的宏来进行判断, 则可以通过值来判断(非零则真)
#define MACRO 0 // 非零则真
#define MACRO "Hello" // 错误的, 不允许出现字符串
#define MACRO 'A' // 允许#if MACRO // 只要判断MACRO为非零值则表示条件为真printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif
#if MACROprintf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#elseprintf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif#if MACRO1printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#elif MACRO2printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#elseprintf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif
注意:
- 在使用有值宏进行条件编译的时候, 宏的值只允许出现整型/字符
- 多路分支可以根据自己的需求继续延续下去
- 使用条件编译必须有结束的语句 #endif 与开头进行对应
条件编译的实际应用场景
除了打开代码进行修改宏的值或者重新定义或删除宏的定义,还可以通过编译命令来定义宏
$ gcc ifdef.c -DDE_BUG
-D --> 定义宏 define
DE_BUG --> 需要定义宏的名字为 DE_BUG
头文件的作用
一般来说我们C语言程序需要用到的很多的.c 文件,当某一些公共的资源需要在各个源文件中使用的时候,就可以把它写在头文件中,被其它的.c文件包含,可以避免编写同样的代码。
头文件内部放:
1) 普通函数声明
2) 宏定义
3) 结构体、共用体模板定义 (声明)
4) 枚举常量列表
5) static 函数和 inline 函数定义
6) 其他头文件
~$ gcc demo.c -I ../../.....
![]()
头文件格式:
#ifndef __DEMO_H // 判断是否有定义某个宏 ,用来防止头文件被多次包含出现的重定义问题 __
#define __DEMO_H //如果没有定义,说明前面没有包含过该头文件
//其它头文件
… …
// 结构体声明
… …
// 函数声明
… …
// 静态函数定义
… …
// 枚举
#endif // ifndef 的结束
由于项目中各个文件比较多,建议使用不同的文件夹来存放不同类型的文件:
bin : 二进制的可执行文件
inc : 用户自己写的头文件
src : 源文件
![]()
如何编译:
$ gcc src/*.c -o bin/Tiezhu -I./inc gcc 编译器 *
src/.c 需要编译的源文件路径 + 文件名
-o 指定声明文件的名字 后边必须接 目标文件的路径+名字
bin/Tiezhu 目标文件的路径 + 名字
-I./inc -I 指定头文件路径 后面必须接头文件所在的路径
目运算符的运算结果出现了偏差。
由于带参宏的这个偏差出现的原因主要是优先级的问题,因此可添加括号来解决:
#define MAX(a,b) (a)>(b)? (a):(b)printf("%d\n" , (x)>(y==200 ? 988:1024)? (x):(y==200 ? 988:1024) );
注意:
宏只能写在同一行中(逻辑行),如果迫不得已需要使用多行来写一个宏则可以使用转义字符==’\‘==把换行符转义掉
[外链图片转存中…(img-oP9Rgs0L-1661591277905)]
如上 41 42 43 为3个物理行, 但是通过转义字符让这三个物理行被看作同一个逻辑行
无值宏
在定义宏的时候不需要给定某一个值,对于无值来说只是用来做一个简单的判断(是否有定义)
#define DE_BUG
条件编译
根据某一个条件来决定某一代码块是否需要编译。
语法:
形式1:
通过无值的宏来判断 , 则只能判断是否有定义
#ifdef // 判断某一个宏是否有定义// 代码块#endif // 判断语句的结束#ifdef DE_BUG // 如果定义了DE_BUG 宏则一下代码块会被编译,反之则不会被编译printf("new:%s--%d--%s--%d\n" , new->Name ,new->age ,new->skill , new->udel );
#endif
#ifdef DE_BUG // 判断是否定义了printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif#ifndef DE_BUG // 判断是否没定义 printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif
形式2 :
通过有值的宏来进行判断, 则可以通过值来判断(非零则真)
#define MACRO 0 // 非零则真
#define MACRO "Hello" // 错误的, 不允许出现字符串
#define MACRO 'A' // 允许#if MACRO // 只要判断MACRO为非零值则表示条件为真printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif
#if MACROprintf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#elseprintf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif#if MACRO1printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#elif MACRO2printf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#elseprintf("__%s__%s__%d__\n", __FUNCTION__ , __FILE__ , __LINE__ );
#endif
注意:
- 在使用有值宏进行条件编译的时候, 宏的值只允许出现整型/字符
- 多路分支可以根据自己的需求继续延续下去
- 使用条件编译必须有结束的语句 #endif 与开头进行对应
条件编译的实际应用场景
除了打开代码进行修改宏的值或者重新定义或删除宏的定义,还可以通过编译命令来定义宏
$ gcc ifdef.c -DDE_BUG
-D --> 定义宏 define
DE_BUG --> 需要定义宏的名字为 DE_BUG
头文件的作用
一般来说我们C语言程序需要用到的很多的.c 文件,当某一些公共的资源需要在各个源文件中使用的时候,就可以把它写在头文件中,被其它的.c文件包含,可以避免编写同样的代码。
头文件内部放:
1) 普通函数声明
2) 宏定义
3) 结构体、共用体模板定义 (声明)
4) 枚举常量列表
5) static 函数和 inline 函数定义
6) 其他头文件
~$ gcc demo.c -I ../../.....
[外链图片转存中…(img-X0Pd2tyC-1661591277905)]
头文件格式:
#ifndef __DEMO_H // 判断是否有定义某个宏 ,用来防止头文件被多次包含出现的重定义问题 __
#define __DEMO_H //如果没有定义,说明前面没有包含过该头文件
//其它头文件
… …
// 结构体声明
… …
// 函数声明
… …
// 静态函数定义
… …
// 枚举
#endif // ifndef 的结束
由于项目中各个文件比较多,建议使用不同的文件夹来存放不同类型的文件:
bin : 二进制的可执行文件
inc : 用户自己写的头文件
src : 源文件
[外链图片转存中…(img-K11lAdO5-1661591277906)]
如何编译:
$ gcc src/*.c -o bin/Tiezhu -I./inc gcc 编译器 *
src/.c 需要编译的源文件路径 + 文件名
-o 指定声明文件的名字 后边必须接 目标文件的路径+名字
bin/Tiezhu 目标文件的路径 + 名字
-I./inc -I 指定头文件路径 后面必须接头文件所在的路径
C语言-学习笔记完整版相关推荐
- go语言基础学习笔记完整版
目录 背景 基础 helloworld 变量 常量 数据类型 基本数据类型与复杂数据类型 值类型与引用类型 查看变量类型 字符与字符串 类型转换 指针 打包 读取控制台数据 for-range遍历 生 ...
- Opencv学习笔记完整版
opencv下载 https://www.raoyunsoft.com/wordpress/index.php/2020/03/09/opencvdownload/ opencv下载 https:// ...
- jQuery——jQuery学习笔记(完整版)
文章目录 前言 一.关于jQuery 二.初步使用 三. jQuery选择器 四.JQUERY动画 五 .JQUERY属性操作 六.JQUERY位置操作 总结 一.关于jQuery 什么是jQuery ...
- Lawliet|C语言学习笔记4——选择结构
C语言学习笔记--选择结构 求一元二次方程的根 简约版 #include<stdio.h> #include<math.h> //程序中要调用求平方根函数sqrt int ma ...
- 梓益C语言学习笔记之链表&动态内存&文件
梓益C语言学习笔记之链表&动态内存&文件 一.定义: 链表是一种物理存储上非连续,通过指针链接次序,实现的一种线性存储结构. 二.特点: 链表由一系列节点(链表中每一个元素称为节点)组 ...
- c语言中void arrout,c语言学习笔记(数组、函数
<c语言学习笔记(数组.函数>由会员分享,可在线阅读,更多相关<c语言学习笔记(数组.函数(53页珍藏版)>请在人人文库网上搜索. 1.数组2010-3-29 22:40一维数 ...
- 韩顺平轻松搞定网页设计(html+css+js),韩顺平轻松搞定网页设计方案(html+css+js)之javascript现场授课笔记(完整版).doc...
2011韩顺平轻松搞定网页设计(html+css+js)之 javascript现场授课笔记(完整版) 视频18整和19的前半部分不用看 Javascript的基本介绍 JS是用于WEB开发的脚本语言 ...
- AI工程师职业规划和学习路线完整版
AI工程师职业规划和学习路线完整版 如何成为一名机器学习算法工程师 成为一名合格的开发工程师不是一件简单的事情,需要掌握从开发到调试到优化等一系列能 力,这些能力中的每一项掌握起来都需要足够的努力和经 ...
- go get 拉取指定版本_go语言学习笔记-基础知识-3
相关文档 go语言学习笔记-目录 1.简介 1.1 什么是GO Go 是一个开源的编程语言,它能让构造简单.可靠且高效的软件变得容易.Go是从2007年末由Robert Griesemer, Rob ...
- Ink脚本语言学习笔记(二)
目前想要基于Ink脚本语言和Unity新的UIToolkit做一套对话系统,本文对Ink脚本语言的使用方式做一下介绍和总结 Ink脚本语言学习笔记(一) 二.缝合(Weave) 目前没想好怎么翻译这个 ...
最新文章
- python中ret是什么意思_数据结构图在python中的应用
- Selenium Grid的使用(分布式测试)
- Luogu P4709 信息传递 (群论、生成函数、多项式指数函数)
- 贪心算法-02活动安排问题
- 2013 ACM区域赛长沙 K Pocket Cube hdu 4801
- 51单片机 16*64LED单红点阵屏驱动测试,上位机改字软件免费版
- 四步破解大亚DP607超级密码,别的光猫可能也适用!
- GDI+中发生一般性错误 Winform Image.Save(mstream, ImageFormat.Png)引发
- 关于android studio报错Attempt to invoke virtual method 'void android.widget.ListView.setAdapter(android.
- 燃气灶电气线路图及原理_燃气灶工作原理及部件构造
- 如何用CSS把正方形变成圆形
- Zebra打印机,中文转ZPL指令的.net实现,替换FNTHEX32.DLL
- Chromium扩展(Extension)的页面(Page)加载过程分析
- 【有利可图网】PS教程:制造低多边形熊猫头像
- connection reset by peer
- 教你玩转QQ的10大绝招
- oracle直接路径读,direct path read直接路径读
- MATLAB代码实现LU分解
- 山东省计算机等级考试初级试题,2013山东省计算机等级考试试题 二级ACCESS理论考试试题及答案...
- VC++钩子使用之全局键盘钩子