机器学习项目 - ctr 电商点击率预估
前言 : 我写的博客基本都以实战为主,每个都可以运行,直接看代码注释理解,不拖泥带水,学习会很快
第一章 腾讯移动App广告转化率预估 -----------------------

题目描述
计算广告是互联网最重要的商业模式之一,广告投放效果通常通过曝光、点击和转化各环节来衡量,大多数广告系统受广告效果数据回流的限制只能通过曝光或点击作为投放效果的衡量标准开展优化。
腾讯社交广告(http://ads.tencent.com)发挥特有的用户识别和转化跟踪数据能力,帮助广告主跟踪广告投放后的转化效果,基于广告转化数据训练转化率预估模型(pCVR,Predicted Conversion Rate),在广告排序中引入pCVR因子优化广告投放效果,提升ROI。
本题目以移动App广告为研究对象,预测App广告点击后被激活的概率:pCVR=P(conversion=1 | Ad,User,Context),即给定广告、用户和上下文情况下广告被点击后发生激活的概率。
数据描述
![]()
![]()
![]()
训练数据
从腾讯社交广告系统中某一连续两周的日志中按照推广中的App和用户维度随机采样。
每一条训练样本即为一条广告点击日志(点击时间用clickTime表示),样本label取值0或1,其中0表示点击后没有发生转化,1表示点击后有发生转化,如果label为1,还会提供转化回流时间(conversionTime,定义详见“FAQ”)。给定特征集如下:



特别的,出于数据安全的考虑,对于userID,appID,特征,以及时间字段,我们不提供原始数据,按照如下方式加密处理:

训练数据文件(train.csv)
每行代表一个训练样本,各字段之间由逗号分隔,顺序依次为:“label,clickTime,conversionTime,creativeID,userID,positionID,connectionType,telecomsOperator”。
当label=0时,conversionTime字段为空字符串。特别的,训练数据时间范围为第17天0点到第31天0点(定义详见下面的“补充说明”)。为了节省存储空间,用户、App、广告和广告位相关信息以独立文件提供(训练数据和测试数据共用),具体如下:

注:若字段取值为0或空字符串均代表未知。(站点集合ID(sitesetID)为0并不表示未知,而是一个特定的站点集合。)
测试数据
从训练数据时段随后1天(即第31天)的广告日志中按照与训练数据同样的采样方式抽取得到,测试数据文件(test.csv)每行代表一个测试样本,各字段之间由逗号分隔,顺序依次为:“instanceID,-1,clickTime,creativeID,userID,positionID,connectionType,telecomsOperator”。其中,instanceID唯一标识一个样本,-1代表label占位使用,表示待预测。
评估方式
通过Logarithmic Loss评估(越小越好),公式如下:
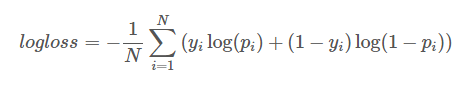 其中,N是测试样本总数,yi是二值变量,取值0或1,表示第i个样本的label,pi为模型预测第i个样本 label为1的概率。
其中,N是测试样本总数,yi是二值变量,取值0或1,表示第i个样本的label,pi为模型预测第i个样本 label为1的概率。
示例代码如下(Python语言):
import scipy as sp
def logloss(act, pred):epsilon = 1e-15pred = sp.maximum(epsilon, pred)pred = sp.minimum(1-epsilon, pred)ll = sum(act*sp.log(pred) + sp.subtract(1,act)*sp.log(sp.subtract(1,pred)))ll = ll * -1.0/len(act)return ll
提交格式
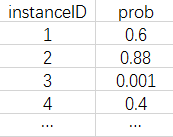
模型预估结果以zip压缩文件方式提交,内部文件名是submission.csv。每行代表一个测试样本,第一行为header,可以记录本文件相关关键信息,评测时会忽略,从第二行开始各字段之间由逗号分隔,顺序依次为:“instanceID, prob”,其中,instanceID唯一标识一个测试样本,必须升序排列,prob为模型预估的广告转化概率。示例如下:
第二章 CVR预估基线版本 -----------------------
2.1 基于AD统计的版本
# -*- coding: utf-8 -*-
"""
baseline 1: history pCVR of creativeID/adID/camgaignID/advertiserID/appID/appPlatform
"""import zipfile
import numpy as np
import pandas as pd
"""
pandas中关于DataFrame 去除省略号
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
"""
pd.set_option('display.max_columns', None)# 载入数据
dfTrain = pd.read_csv('data/train.csv')
dfTest = pd.read_csv('data/test.csv')
dfAd = pd.read_csv('data/ad.csv')# 处理数据
"""merger() 函数相当于数据库的左右连接,按照creativeID 相同的数据来凝结为一行"""
dfTrain = pd.merge(dfTrain, dfAd, on='creativeID')
dfTest = pd.merge(dfTest, dfAd,on='creativeID')
y_train = dfTrain['label'].values # [0 0 0 ... 0 0 0]# 创建模型
key = 'appID'"""
groupby(): 将数据进行排列分组,数据按照appid,
"""dfCvr = dfTrain.groupby(key).apply(lambda df: np.mean(df['label'])).reset_index()dfCvr.columns = [key, 'avg_cvr']
dfTest = pd.merge(dfTest, dfCvr, how='left', on=key)
dfTest['avg_cvr'].fillna(np.mean(dfTrain['label']), inplace=True)
proba_test = dfTest['avg_cvr'].values# submission
df = pd.DataFrame({"instanceID": dfTest['instanceID'].values, "proba": proba_test})
df.sort_values("instanceID", inplace=True)
print(df.head(10))
# df.to_csv("submission.csv", index=False)
# with zipfile.ZipFile('submission.zip', 'w') as fout:
# fout.write('submission.csv', compress_type=zipfile.ZIP_DEFLATED)得分
| Submission | 描述 | 初赛A | 初赛B | 决赛A | 决赛B |
|---|---|---|---|---|---|
| baseline 2.1 | ad 统计 | 0.10988 | - | - | - |
2.2 AD+LR版本
# -*- coding: utf-8 -*-
"""
baseline 2: ad.csv (creativeID/adID/camgaignID/advertiserID/appID/appPlatform) + lr
"""import zipfile
import pandas as pd
from scipy import sparse
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LogisticRegressionpd.set_option('display.max_columns', None)# 载入数据
dfTrain = pd.read_csv('data/train.csv')
dfTest = pd.read_csv('data/test.csv')
dfAd = pd.read_csv('data/ad.csv')# 处理数据
"""merger() 函数相当于数据库的左右连接,按照creativeID 相同的数据来凝结为一行"""
dfTrain = pd.merge(dfTrain, dfAd, on='creativeID')
dfTest = pd.merge(dfTest, dfAd,on='creativeID')
y_train = dfTrain['label'].values# feature engineering/encoding
enc = OneHotEncoder()
feats = ["creativeID", "adID", "camgaignID", "advertiserID", "appID", "appPlatform"]
for i, feat in enumerate(feats):x_train = enc.fit_transform(dfTrain[feat].values.reshape(-1, 1)) # (0, 2966) 1.0x_test = enc.transform(dfTest[feat].values.reshape(-1,1))if i == 0:X_train, X_test = x_train, x_testelse:X_train, X_test = sparse.hstack((X_train, x_train)), sparse.hstack((X_test, x_test))# 模型训练
lr = LogisticRegression()
lr.fit(X_train, y_train)
proba_test = lr.predict_proba(X_test)[:, 1]# submission
df = pd.DataFrame({"instanceID": dfTest["instanceID"].values, "proba": proba_test})
df.sort_values("instanceID", inplace=True)
df.to_csv('submission.csv', index=False)
with zipfile.ZipFile('submission.zip', 'w') as fout:fout.write('submission.csv', compress_type=zipfile.ZIP_DEFLATED)
得分
| Submission | 描述 | 初赛A | 初赛B | 决赛A | 决赛B |
|---|---|---|---|---|---|
| baseline 2.2 | ad + lr | 0.10743 | - | - | - |
第三章 特征工程与机器学习建模 -----------------------
3.1 代码实战
import os
import warningsimport numpy as np
# x-列最小值)/ (列最大值-列最小值), value在0-1, MinMaxScaler().fit_transform(iris.data)
import pandas as pd
import scipy as sp# 特征二值化 - 大于阀值转为1,小于等于阀值为0
pd.set_option('display.max_columns', None)# 随机森林建模&&特征重要度排序# 随机森林调参
from sklearn.model_selection import GridSearchCV
# Xgboost调参
import xgboost as xgb
# 我们可以看到正负样本数量相差非常大,数据严重unbalanced
from blagging import BlaggingClassifier""" 文件读取 """def read_csv_file(filname, logging=False):data = pd.read_csv(filname)if logging :print(data.head(5))print(data.columns.values)print(data.describe())print(data.info())return data""" 数据的处理 """# 第一类编码
def categories_process_first_class(cate):cate = str(cate)if len(cate) == 1:if int(cate) == 0:return 0else:return int(cate[0])# 第二类编码
def categories_process_second_class(cate):cate = str(cate)if len(cate) < 3:return 0else:return int(cate[1:])# 年龄切断处理def age_process(age):age = int(age)if age == 0:return 0if age < 15:return 1elif age < 25:return 2elif age < 40:return 3elif age < 60:return 4else:return 5# 省份数据处理def process_province(hometown):hometown = str(hometown)province = int(hometown[0:2])return province# 城市def process_city(hometown):hometown = str(hometown)if len(hometown) > 1:province = int(hometown[2:])else:province = 0return province# 几点钟def get_time_day(t):t = str(t)t = int(t[0:2])return t
# 一天切分成4段def get_time_hour(t):t = str(t)t = int(t[2:4])if t < 6:return 0if t < 12:return 1elif t < 18:return 2else:return 3# 评估与计算loglossdef logloss(act, pred):epsilon = 1e-15pred = sp.maximum(epsilon, pred)pred = sp.minimum(1-epsilon, pred)ll = sum(act*sp.log(pred) + sp.subtract(1, act)*sp.log(sp.subtract(1,pred)))ll = ll * -1.0 / len(act)return lltrain_data = read_csv_file('data/train.csv', logging=False) # 读取train_data和ad
ad = read_csv_file('data/ad.csv', logging=False)app_categories = read_csv_file('data/app_categories.csv', logging=False)
app_categories['app_categories_first_class'] = app_categories['appCategory'].apply(categories_process_first_class)
# ['appID' 'appCategory' 'app_categories_first_class' 'app_categories_second_class']
app_categories['app_categories_second_class'] = app_categories['appCategory'].apply(categories_process_second_class)
user = read_csv_file('data/user.csv', logging=False)
""" 画年龄分布柱状图
age_obj = user.age.value_counts()
plt.bar(age_obj.index, age_obj.values.tolist())
plt.show()
"""
# 用户信息处理
user['age_process'] = user['age'].apply(age_process)
user['hometown_province'] = user['hometown'].apply(process_province)
user['hometown_city'] = user['hometown'].apply(process_city)
user["residence_province"] = user['residence'].apply(process_province)
user["residence_city"] = user['residence'].apply(process_city)train_data['clickTime_day'] = train_data['clickTime'].apply(get_time_day)
train_data['clickTime_hour'] = train_data['clickTime'].apply(get_time_hour)#test_data
test_data = read_csv_file('./data/test.csv', False)
test_data['clickTime_day'] = test_data['clickTime'].apply(get_time_day)
test_data['clickTime_hour'] = test_data['clickTime'].apply(get_time_hour)# 全部合并
train_user = pd.merge(train_data, user, on='userID')
train_user_ad = pd.merge(train_user, ad, on='creativeID')
train_user_ad_app = pd.merge(train_user_ad, app_categories, on='appID')# 取出数据和 label
x_user_ad_app = train_user_ad_app.loc[:, ['creativeID','userID','positionID','connectionType','telecomsOperator','clickTime_day','clickTime_hour','age', 'gender' ,'education','marriageStatus' ,'haveBaby' , 'residence' ,'age_process','hometown_province', 'hometown_city','residence_province', 'residence_city','adID', 'camgaignID', 'advertiserID', 'appID' ,'appPlatform' ,'app_categories_first_class' ,'app_categories_second_class']]x_user_ad_app = x_user_ad_app.values
print(x_user_ad_app)
x_user_ad_app = np.array(x_user_ad_app, dtype='int32')
print(x_user_ad_app)
# 标签部分
y_user_ad_app = train_user_ad_app.loc[:, ['label']].values"""
# 随机森林建模&&特征重要度排序 用RF 计算特征重要度
feat_labels = np.array(['creativeID','userID','positionID','connectionType','telecomsOperator','clickTime_day','clickTime_hour','age', 'gender' ,'education','marriageStatus' ,'haveBaby' , 'residence' ,'age_process','hometown_province', 'hometown_city','residence_province', 'residence_city','adID', 'camgaignID', 'advertiserID', 'appID' ,'appPlatform' ,'app_categories_first_class' ,'app_categories_second_class'])# 随机森林
forest = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
forest.fit(x_user_ad_app, y_user_ad_app.reshape(y_user_ad_app.shape[0],))
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]for f in range(x_user_ad_app.shape[1]):print("%2d) %-*s %f" % (f+1, 30, feat_labels[indices[f]], importances[indices[f]]))plt.title('Feature Importances')
plt.bar(range(x_user_ad_app.shape[1]), importances[indices], color='lightblue', align='center')
plt.xticks(range(x_user_ad_app.shape[1]), feat_labels[indices], rotation=90)
plt.xlim(-1, x_user_ad_app.shape[1])
plt.tight_layout()
plt.savefig('random_forest.png', dpi=300)
plt.show()
""""""
随机森林调参param_grid = {'n_estimators': [10, 100, 500, 1000],'max_features': [0.6, 0.7, 0.8, 0.9]
}
rf = RandomForestClassifier()
rfc = GridSearchCV(rf, param_grid, scoring='neg_log_loss', cv=3, n_jobs=2)
rfc.fit(x_user_ad_app, y_user_ad_app.shape(y_user_ad_app[0],))
print(rfc.best_score_)
print(rfc.best_params_)
""""""
Xgboost 调参
"""
os.environ['OMP_NUM_THREADS'] = '8' # 开启并行训练
rng = np.random.RandomState(4315)
warnings.filterwarnings('ignore')param_grid = {"max_depth": [3,4,5,7,9],"n_estimators": [10, 50, 100, 400, 800, 1000, 1200],"learning_rate": [0.1, 0.2, 0.3],"gamma": [0, 0.2],"subsample": [0.8, 1],"colsample_bylevel": [0.8, 1]
}xgb_model = xgb.XGBClassifier()
rgs = GridSearchCV(xgb_model, param_grid, n_jobs=-1)
rgs.fit(x_user_ad_app, y_user_ad_app) # fit(x,y)
print(rgs.best_score_)
print(rgs.best_params_)# 正负样本比
positive_num = train_user_ad_app[train_user_ad_app['label'] == 1].values.shape[0]
negative_num = train_user_ad_app[train_user_ad_app['label'] == 0].values.shape[0]print(negative_num / float(positive_num))"""
我们用Bagging修正过后,处理不均衡样本的B(l)agging来进行训练和实验------------后面的这段程序就开始看不懂了--------------
"""# 处理unbalanced 的classifier
classifier = BlaggingClassifier(n_jobs=-1)
classifier.fit(x_user_ad_app, y_user_ad_app)
classifier.predict_proba(x_test_clean)
# 预测
test_data = pd.merge(test_data, user, on='userID')
test_user_ad = pd.merge(test_data, ad,on='creativeID')
test_user_ad_app = pd.merge(test_user_ad, app_categories, on='appID')x_test_clean = test_user_ad_app.loc[:, ['creativeID','userID','positionID','connectionType','telecomsOperator','clickTime_day','clickTime_hour','age', 'gender' ,'education','marriageStatus' ,'haveBaby' , 'residence' ,'age_process','hometown_province', 'hometown_city','residence_province', 'residence_city','adID', 'camgaignID', 'advertiserID', 'appID' ,'appPlatform' ,'app_categories_first_class' ,'app_categories_second_class']].valuesx_test_clean = np.array(x_test_clean, dtype='int32')result_predict_prob = []result_predict = []
for i in range(scale):result_indiv = clfs[i].predict(x_test_clean)result_indiv_proba = clfs[i].predict_proba(x_test_clean)[:,1]result_predict.append(result_indiv_proba)result_indiv_proba = np.reshape(result_predict_prob, [-1,scale])
result_predict = np.reshape(result_predict,[-1, scale])result_predict_prob = np.mean(result_predict_prob, axis=1)
result_predict = max_count(result_predict)result_predict_prob = np.array(result_predict_prob).reshape([-1,1])test_data['prob'] = result_predict_prob
test_data = test_data.loc[:,['instanceID','prob']]
test_data.to_csv('predict.csv',index=False)
print "prediction done!"
第四章 利用神经网络进行计算广告预测 - LR模型 FM模型 FNN模型 FNN1模型 FNN2模型 CCPM 模型
4.1 数据描述
make-ipinyou-data
This project is to formalise the iPinYou RTB data into a standard format for further
researches.
百度云数据地址
http://pan.baidu.com/s/1kTwX2mF
Step 0
Go to data.computational-advertising.org to download ipinyou.contest.dataset.zip .
Unzip it and get the folder ipinyou.contest.dataset .
Step 1
Update the soft link for the folder ipinyou.contest.dataset in original-data .
weinan@ZHANG:~/Project/make-ipinyou-data/original-data$ ln -sfn
~/Data/ipinyou.contest.dataset ipinyou.contest.dataset Under make-ipinyoudata/
original-data/ipinyou.contest.dataset there should be the original dataset
files like this: weinan@ZHANG:~/Project/make-ipinyou-data/originaldata/
ipinyou.contest.dataset$ ls algo.submission.demo.tar.bz2 README
testing2nd training3rd city.cn.txt region.cn.txt testing3rd
user.profile.tags.cn.txt city.en.txt region.en.txt training1st
user.profile.tags.en.txt files.md5 testing1st training2nd You do not need to
further unzip the packages in the subfolders.
Step 2
Under make-ipinyou-data folder, just run make all .
Note: The user agent parser used in formalizeua.py uses the python package useragents.
After the program finished, the total size of the folder will be 14G. The files under makeipinyou-
data should be like this: weinan@ZHANG:~/Project/make-ipinyou-data$ ls
1458 2261 2997 3386 3476 LICENSE mkyzxdata.sh python schema.txt 2259 2821
3358 3427 all Makefile original-data README.md Normally, we only do experiment
for each campaign (e.g. 1458 ). all is just the merge of all the campaigns. You can delete
all if you think it is unuseful in your experiment.
Use of the data
We use campaign 1458 as example here. weinan@ZHANG:~/Project/make-ipinyoudata/
1458$ ls featindex.txt test.log.txt test.yzx.txt train.log.txt
train.yzx.txt * train.log.txt and test.log.txt are the formalised string data for
each row (record) in train and test. The first column is whether the user click the ad or not.
The 14th column is the winning price for this auction. * featindex.txt maps the features
to their indexes. For example, 8:115.45.195.* 29 means that the 8th column in
train.log.txt with the string 115.45.195.* maps to feature index 29 . *
train.yzx.txt and test.yzx.txt are the mapped vector data for train.log.txt and
test.log.txt . The format is y:click, z:wining_price, and x:features. Such data is in the
standard form as introduced in iPinYou Benchmarking.
For any questions, please report the issues or contact Weinan Zhang.
4.2 代码实战
1. main.py
import numpy as np
from sklearn.metrics import roc_auc_scoreimport utils
from models import LR, FM, PNN1, PNN2, FNN, CCPMtrain_file = '../data/train.yx.txt'
test_file = '../data/test.yx.txt'
# fm_model_file = '../data/fm.model.txt'input_dim = utils.INPUT_DIMtrain_data = utils.read_data(train_file)
train_data = utils.shuffle(train_data)
test_data = utils.read_data(test_file)if train_data[1].ndim > 1:print 'label must be 1-dim'exit(0)
print('read finish')train_size = train_data[0].shape[0]
test_size = test_data[0].shape[0]
num_feas = len(utils.FIELD_SIZES)min_round = 1
num_round = 1000
early_stop_round = 50
batch_size = 1024field_sizes = utils.FIELD_SIZES
field_offsets = utils.FIELD_OFFSETSdef train(model):history_score = []for i in range(num_round):fetches = [model.optimizer, model.loss]if batch_size > 0:ls = []for j in range(train_size / batch_size + 1):X_i, y_i = utils.slice(train_data, j * batch_size, batch_size)_, l = model.run(fetches, X_i, y_i)ls.append(l)elif batch_size == -1:X_i, y_i = utils.slice(train_data)_, l = model.run(fetches, X_i, y_i)ls = [l]train_preds = model.run(model.y_prob, utils.slice(train_data)[0])test_preds = model.run(model.y_prob, utils.slice(test_data)[0])train_score = roc_auc_score(train_data[1], train_preds)test_score = roc_auc_score(test_data[1], test_preds)print('[%d]\tloss (with l2 norm):%f\ttrain-auc: %f\teval-auc: %f' % (i, np.mean(ls), train_score, test_score))history_score.append(test_score)if i > min_round and i > early_stop_round:if np.argmax(history_score) == i - early_stop_round and history_score[-1] - history_score[-1 * early_stop_round] < 1e-5:print('early stop\nbest iteration:\n[%d]\teval-auc: %f' % (np.argmax(history_score), np.max(history_score)))breakalgo = 'pnn2'if algo == 'lr':lr_params = {'input_dim': input_dim,'opt_algo': 'gd','learning_rate': 0.01,'l2_weight': 0,'random_seed': 0}model = LR(**lr_params)
elif algo == 'fm':fm_params = {'input_dim': input_dim,'factor_order': 10,'opt_algo': 'gd','learning_rate': 0.1,'l2_w': 0,'l2_v': 0,}model = FM(**fm_params)
elif algo == 'fnn':fnn_params = {'layer_sizes': [field_sizes, 10, 1],'layer_acts': ['tanh', 'none'],'drop_out': [0, 0],'opt_algo': 'gd','learning_rate': 0.1,'layer_l2': [0, 0],'random_seed': 0}model = FNN(**fnn_params)
elif algo == 'ccpm':ccpm_params = {'layer_sizes': [field_sizes, 10, 5, 3],'layer_acts': ['tanh', 'tanh', 'none'],'drop_out': [0, 0, 0],'opt_algo': 'gd','learning_rate': 0.1,'random_seed': 0}model = CCPM(**ccpm_params)
elif algo == 'pnn1':pnn1_params = {'layer_sizes': [field_sizes, 10, 1],'layer_acts': ['tanh', 'none'],'drop_out': [0, 0],'opt_algo': 'gd','learning_rate': 0.1,'layer_l2': [0, 0],'kernel_l2': 0,'random_seed': 0}model = PNN1(**pnn1_params)
elif algo == 'pnn2':pnn2_params = {'layer_sizes': [field_sizes, 10, 1],'layer_acts': ['tanh', 'none'],'drop_out': [0, 0],'opt_algo': 'gd','learning_rate': 0.01,'layer_l2': [0, 0],'kernel_l2': 0,'random_seed': 0}model = PNN2(**pnn2_params)if algo in {'fnn', 'ccpm', 'pnn1', 'pnn2'}:train_data = utils.split_data(train_data)test_data = utils.split_data(test_data)train(model)# X_i, y_i = utils.slice(train_data, 0, 100)
# fetches = [model.tmp1, model.tmp2]
# tmp1, tmp2 = model.run(fetches, X_i, y_i)
# print tmp1.shape
# print tmp2.shape
2. models.py
import sys
if sys.version[0] == '2':import cPickle as pkl
else:import pickle as pklimport numpy as np
import tensorflow as tfimport utilsdtype = utils.DTYPEclass Model:def __init__(self):self.sess = Noneself.X = Noneself.y = Noneself.layer_keeps = Noneself.vars = Noneself.keep_prob_train = Noneself.keep_prob_test = Nonedef run(self, fetches, X=None, y=None, mode='train'):feed_dict = {}if type(self.X) is list:for i in range(len(X)):feed_dict[self.X[i]] = X[i]else:feed_dict[self.X] = Xif y is not None:feed_dict[self.y] = yif self.layer_keeps is not None:if mode == 'train':feed_dict[self.layer_keeps] = self.keep_prob_trainelif mode == 'test':feed_dict[self.layer_keeps] = self.keep_prob_testreturn self.sess.run(fetches, feed_dict)def dump(self, model_path):var_map = {}for name, var in self.vars.iteritems():var_map[name] = self.run(var)pkl.dump(var_map, open(model_path, 'wb'))print('model dumped at', model_path)class LR(Model):def __init__(self, input_dim=None, output_dim=1, init_path=None, opt_algo='gd', learning_rate=1e-2, l2_weight=0,random_seed=None):Model.__init__(self)init_vars = [('w', [input_dim, output_dim], 'tnormal', dtype),('b', [output_dim], 'zero', dtype)]self.graph = tf.Graph()with self.graph.as_default():if random_seed is not None:tf.set_random_seed(random_seed)self.X = tf.sparse_placeholder(dtype)self.y = tf.placeholder(dtype)self.vars = utils.init_var_map(init_vars, init_path)w = self.vars['w']b = self.vars['b']xw = tf.sparse_tensor_dense_matmul(self.X, w)logits = tf.reshape(xw + b, [-1])self.y_prob = tf.sigmoid(logits)self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=self.y, logits=logits)) + \l2_weight * tf.nn.l2_loss(xw)self.optimizer = utils.get_optimizer(opt_algo, learning_rate, self.loss)config = tf.ConfigProto()config.gpu_options.allow_growth = Trueself.sess = tf.Session(config=config)tf.global_variables_initializer().run(session=self.sess)class FM(Model):def __init__(self, input_dim=None, output_dim=1, factor_order=10, init_path=None, opt_algo='gd', learning_rate=1e-2,l2_w=0, l2_v=0, random_seed=None):Model.__init__(self)init_vars = [('w', [input_dim, output_dim], 'tnormal', dtype),('v', [input_dim, factor_order], 'tnormal', dtype),('b', [output_dim], 'zero', dtype)]self.graph = tf.Graph()with self.graph.as_default():if random_seed is not None:tf.set_random_seed(random_seed)self.X = tf.sparse_placeholder(dtype)self.y = tf.placeholder(dtype)self.vars = utils.init_var_map(init_vars, init_path)w = self.vars['w']v = self.vars['v']b = self.vars['b']X_square = tf.SparseTensor(self.X.indices, tf.square(self.X.values), tf.to_int64(tf.shape(self.X)))xv = tf.square(tf.sparse_tensor_dense_matmul(self.X, v))p = 0.5 * tf.reshape(tf.reduce_sum(xv - tf.sparse_tensor_dense_matmul(X_square, tf.square(v)), 1),[-1, output_dim])xw = tf.sparse_tensor_dense_matmul(self.X, w)logits = tf.reshape(xw + b + p, [-1])self.y_prob = tf.sigmoid(logits)self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=self.y)) + \l2_w * tf.nn.l2_loss(xw) + \l2_v * tf.nn.l2_loss(xv)self.optimizer = utils.get_optimizer(opt_algo, learning_rate, self.loss)config = tf.ConfigProto()config.gpu_options.allow_growth = Trueself.sess = tf.Session(config=config)tf.global_variables_initializer().run(session=self.sess)class FNN(Model):def __init__(self, layer_sizes=None, layer_acts=None, drop_out=None, layer_l2=None, init_path=None, opt_algo='gd',learning_rate=1e-2, random_seed=None):Model.__init__(self)init_vars = []num_inputs = len(layer_sizes[0])factor_order = layer_sizes[1]for i in range(num_inputs):layer_input = layer_sizes[0][i]layer_output = factor_orderinit_vars.append(('w0_%d' % i, [layer_input, layer_output], 'tnormal', dtype))init_vars.append(('b0_%d' % i, [layer_output], 'zero', dtype))init_vars.append(('w1', [num_inputs * factor_order, layer_sizes[2]], 'tnormal', dtype))init_vars.append(('b1', [layer_sizes[2]], 'zero', dtype))for i in range(2, len(layer_sizes) - 1):layer_input = layer_sizes[i]layer_output = layer_sizes[i + 1]init_vars.append(('w%d' % i, [layer_input, layer_output], 'tnormal', dtype))init_vars.append(('b%d' % i, [layer_output], 'zero', dtype))self.graph = tf.Graph()with self.graph.as_default():if random_seed is not None:tf.set_random_seed(random_seed)self.X = [tf.sparse_placeholder(dtype) for i in range(num_inputs)]self.y = tf.placeholder(dtype)self.keep_prob_train = 1 - np.array(drop_out)self.keep_prob_test = np.ones_like(drop_out)self.layer_keeps = tf.placeholder(dtype)self.vars = utils.init_var_map(init_vars, init_path)w0 = [self.vars['w0_%d' % i] for i in range(num_inputs)]b0 = [self.vars['b0_%d' % i] for i in range(num_inputs)]xw = [tf.sparse_tensor_dense_matmul(self.X[i], w0[i]) for i in range(num_inputs)]x = tf.concat([xw[i] + b0[i] for i in range(num_inputs)], 1)l = tf.nn.dropout(utils.activate(x, layer_acts[0]),self.layer_keeps[0])for i in range(1, len(layer_sizes) - 1):wi = self.vars['w%d' % i]bi = self.vars['b%d' % i]l = tf.nn.dropout(utils.activate(tf.matmul(l, wi) + bi,layer_acts[i]),self.layer_keeps[i])l = tf.reshape(l, [-1])self.y_prob = tf.sigmoid(l)self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=l, labels=self.y))if layer_l2 is not None:# for i in range(num_inputs):self.loss += layer_l2[0] * tf.nn.l2_loss(tf.concat(xw, 1))for i in range(1, len(layer_sizes) - 1):wi = self.vars['w%d' % i]# bi = self.vars['b%d' % i]self.loss += layer_l2[i] * tf.nn.l2_loss(wi)self.optimizer = utils.get_optimizer(opt_algo, learning_rate, self.loss)config = tf.ConfigProto()config.gpu_options.allow_growth = Trueself.sess = tf.Session(config=config)tf.global_variables_initializer().run(session=self.sess)class CCPM(Model):def __init__(self, layer_sizes=None, layer_acts=None, drop_out=None, init_path=None, opt_algo='gd',learning_rate=1e-2, random_seed=None):Model.__init__(self)init_vars = []num_inputs = len(layer_sizes[0])embedding_order = layer_sizes[1]for i in range(num_inputs):layer_input = layer_sizes[0][i]layer_output = embedding_orderinit_vars.append(('w0_%d' % i, [layer_input, layer_output], 'tnormal', dtype))init_vars.append(('b0_%d' % i, [layer_output], 'zero', dtype))init_vars.append(('f1', [embedding_order, layer_sizes[2], 1, 2], 'tnormal', dtype))init_vars.append(('f2', [embedding_order, layer_sizes[3], 2, 2], 'tnormal', dtype))init_vars.append(('w1', [2 * 3 * embedding_order, 1], 'tnormal', dtype))init_vars.append(('b1', [1], 'zero', dtype))self.graph = tf.Graph()with self.graph.as_default():if random_seed is not None:tf.set_random_seed(random_seed)self.X = [tf.sparse_placeholder(dtype) for i in range(num_inputs)]self.y = tf.placeholder(dtype)self.keep_prob_train = 1 - np.array(drop_out)self.keep_prob_test = np.ones_like(drop_out)self.layer_keeps = tf.placeholder(dtype)self.vars = utils.init_var_map(init_vars, init_path)w0 = [self.vars['w0_%d' % i] for i in range(num_inputs)]b0 = [self.vars['b0_%d' % i] for i in range(num_inputs)]l = tf.nn.dropout(utils.activate(tf.concat([tf.sparse_tensor_dense_matmul(self.X[i], w0[i]) + b0[i]for i in range(num_inputs)], 1),layer_acts[0]),self.layer_keeps[0])l = tf.transpose(tf.reshape(l, [-1, num_inputs, embedding_order, 1]), [0, 2, 1, 3])f1 = self.vars['f1']l = tf.nn.conv2d(l, f1, [1, 1, 1, 1], 'SAME')l = tf.transpose(utils.max_pool_4d(tf.transpose(l, [0, 1, 3, 2]),num_inputs / 2),[0, 1, 3, 2])f2 = self.vars['f2']l = tf.nn.conv2d(l, f2, [1, 1, 1, 1], 'SAME')l = tf.transpose(utils.max_pool_4d(tf.transpose(l, [0, 1, 3, 2]), 3),[0, 1, 3, 2])l = tf.nn.dropout(utils.activate(tf.reshape(l, [-1, embedding_order * 3 * 2]),layer_acts[1]),self.layer_keeps[1])w1 = self.vars['w1']b1 = self.vars['b1']l = tf.nn.dropout(utils.activate(tf.matmul(l, w1) + b1,layer_acts[2]),self.layer_keeps[2])l = tf.reshape(l, [-1])self.y_prob = tf.sigmoid(l)self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=l, labels=self.y))self.optimizer = utils.get_optimizer(opt_algo, learning_rate, self.loss)config = tf.ConfigProto()config.gpu_options.allow_growth = Trueself.sess = tf.Session(config=config)tf.global_variables_initializer().run(session=self.sess)class PNN1(Model):def __init__(self, layer_sizes=None, layer_acts=None, drop_out=None, layer_l2=None, kernel_l2=None, init_path=None,opt_algo='gd', learning_rate=1e-2, random_seed=None):Model.__init__(self)init_vars = []num_inputs = len(layer_sizes[0])factor_order = layer_sizes[1]for i in range(num_inputs):layer_input = layer_sizes[0][i]layer_output = factor_orderinit_vars.append(('w0_%d' % i, [layer_input, layer_output], 'tnormal', dtype))init_vars.append(('b0_%d' % i, [layer_output], 'zero', dtype))init_vars.append(('w1', [num_inputs * factor_order, layer_sizes[2]], 'tnormal', dtype))init_vars.append(('k1', [num_inputs, layer_sizes[2]], 'tnormal', dtype))init_vars.append(('b1', [layer_sizes[2]], 'zero', dtype))for i in range(2, len(layer_sizes) - 1):layer_input = layer_sizes[i]layer_output = layer_sizes[i + 1]init_vars.append(('w%d' % i, [layer_input, layer_output], 'tnormal',))init_vars.append(('b%d' % i, [layer_output], 'zero', dtype))self.graph = tf.Graph()with self.graph.as_default():if random_seed is not None:tf.set_random_seed(random_seed)self.X = [tf.sparse_placeholder(dtype) for i in range(num_inputs)]self.y = tf.placeholder(dtype)self.keep_prob_train = 1 - np.array(drop_out)self.keep_prob_test = np.ones_like(drop_out)self.layer_keeps = tf.placeholder(dtype)self.vars = utils.init_var_map(init_vars, init_path)w0 = [self.vars['w0_%d' % i] for i in range(num_inputs)]b0 = [self.vars['b0_%d' % i] for i in range(num_inputs)]xw = [tf.sparse_tensor_dense_matmul(self.X[i], w0[i]) for i in range(num_inputs)]x = tf.concat([xw[i] + b0[i] for i in range(num_inputs)], 1)l = tf.nn.dropout(utils.activate(x, layer_acts[0]),self.layer_keeps[0])w1 = self.vars['w1']k1 = self.vars['k1']b1 = self.vars['b1']p = tf.reduce_sum(tf.reshape(tf.matmul(tf.reshape(tf.transpose(tf.reshape(l, [-1, num_inputs, factor_order]),[0, 2, 1]),[-1, num_inputs]),k1),[-1, factor_order, layer_sizes[2]]),1)l = tf.nn.dropout(utils.activate(tf.matmul(l, w1) + b1 + p,layer_acts[1]),self.layer_keeps[1])for i in range(2, len(layer_sizes) - 1):wi = self.vars['w%d' % i]bi = self.vars['b%d' % i]l = tf.nn.dropout(utils.activate(tf.matmul(l, wi) + bi,layer_acts[i]),self.layer_keeps[i])l = tf.reshape(l, [-1])self.y_prob = tf.sigmoid(l)self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=l, labels=self.y))if layer_l2 is not None:# for i in range(num_inputs):self.loss += layer_l2[0] * tf.nn.l2_loss(tf.concat(xw, 1))for i in range(1, len(layer_sizes) - 1):wi = self.vars['w%d' % i]# bi = self.vars['b%d' % i]self.loss += layer_l2[i] * tf.nn.l2_loss(wi)if kernel_l2 is not None:self.loss += kernel_l2 * tf.nn.l2_loss(k1)self.optimizer = utils.get_optimizer(opt_algo, learning_rate, self.loss)config = tf.ConfigProto()config.gpu_options.allow_growth = Trueself.sess = tf.Session(config=config)tf.global_variables_initializer().run(session=self.sess)class PNN2(Model):def __init__(self, layer_sizes=None, layer_acts=None, drop_out=None, layer_l2=None, kernel_l2=None, init_path=None,opt_algo='gd', learning_rate=1e-2, random_seed=None):Model.__init__(self)init_vars = []num_inputs = len(layer_sizes[0])factor_order = layer_sizes[1]for i in range(num_inputs):layer_input = layer_sizes[0][i]layer_output = factor_orderinit_vars.append(('w0_%d' % i, [layer_input, layer_output], 'tnormal', dtype))init_vars.append(('b0_%d' % i, [layer_output], 'zero', dtype))init_vars.append(('w1', [num_inputs * factor_order, layer_sizes[2]], 'tnormal', dtype))init_vars.append(('k1', [factor_order * factor_order, layer_sizes[2]], 'tnormal', dtype))init_vars.append(('b1', [layer_sizes[2]], 'zero', dtype))for i in range(2, len(layer_sizes) - 1):layer_input = layer_sizes[i]layer_output = layer_sizes[i + 1]init_vars.append(('w%d' % i, [layer_input, layer_output], 'tnormal',))init_vars.append(('b%d' % i, [layer_output], 'zero', dtype))self.graph = tf.Graph()with self.graph.as_default():if random_seed is not None:tf.set_random_seed(random_seed)self.X = [tf.sparse_placeholder(dtype) for i in range(num_inputs)]self.y = tf.placeholder(dtype)self.keep_prob_train = 1 - np.array(drop_out)self.keep_prob_test = np.ones_like(drop_out)self.layer_keeps = tf.placeholder(dtype)self.vars = utils.init_var_map(init_vars, init_path)w0 = [self.vars['w0_%d' % i] for i in range(num_inputs)]b0 = [self.vars['b0_%d' % i] for i in range(num_inputs)]xw = [tf.sparse_tensor_dense_matmul(self.X[i], w0[i]) for i in range(num_inputs)]x = tf.concat([xw[i] + b0[i] for i in range(num_inputs)], 1)l = tf.nn.dropout(utils.activate(x, layer_acts[0]),self.layer_keeps[0])w1 = self.vars['w1']k1 = self.vars['k1']b1 = self.vars['b1']z = tf.reduce_sum(tf.reshape(l, [-1, num_inputs, factor_order]), 1)p = tf.reshape(tf.matmul(tf.reshape(z, [-1, factor_order, 1]),tf.reshape(z, [-1, 1, factor_order])),[-1, factor_order * factor_order])l = tf.nn.dropout(utils.activate(tf.matmul(l, w1) + tf.matmul(p, k1) + b1,layer_acts[1]),self.layer_keeps[1])for i in range(2, len(layer_sizes) - 1):wi = self.vars['w%d' % i]bi = self.vars['b%d' % i]l = tf.nn.dropout(utils.activate(tf.matmul(l, wi) + bi,layer_acts[i]),self.layer_keeps[i])l = tf.reshape(l, [-1])self.y_prob = tf.sigmoid(l)self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=l, labels=self.y))if layer_l2 is not None:# for i in range(num_inputs):self.loss += layer_l2[0] * tf.nn.l2_loss(tf.concat(xw, 1))for i in range(1, len(layer_sizes) - 1):wi = self.vars['w%d' % i]# bi = self.vars['b%d' % i]self.loss += layer_l2[i] * tf.nn.l2_loss(wi)if kernel_l2 is not None:self.loss += kernel_l2 * tf.nn.l2_loss(k1)self.optimizer = utils.get_optimizer(opt_algo, learning_rate, self.loss)config = tf.ConfigProto()config.gpu_options.allow_growth = Trueself.sess = tf.Session(config=config)tf.global_variables_initializer().run(session=self.sess)
3. utils.py
import sys
if sys.version[0] == '2':import cPickle as pkl
else:import pickle as pklimport numpy as np
import tensorflow as tf
from scipy.sparse import coo_matrixDTYPE = tf.float32FIELD_SIZES = [0] * 26
with open('../data/featindex.txt') as fin:for line in fin:line = line.strip().split(':')if len(line) > 1:f = int(line[0]) - 1FIELD_SIZES[f] += 1
print('field sizes:', FIELD_SIZES)
FIELD_OFFSETS = [sum(FIELD_SIZES[:i]) for i in range(len(FIELD_SIZES))]
INPUT_DIM = sum(FIELD_SIZES)
# FIELD_SIZES = [94316, 99781, 6, 23, 34072, 12723]
# FIELD_OFFSETS = [sum(FIELD_SIZES[:i]) for i in range(6)]
# INPUT_DIM = sum(FIELD_SIZES)
OUTPUT_DIM = 1
STDDEV = 1e-3
MINVAL = -1e-3
MAXVAL = 1e-3def read_data(file_name):X = []y = []with open(file_name) as fin:for line in fin:fields = line.strip().split()y_i = int(fields[0])X_i = map(lambda x: int(x.split(':')[0]), fields[1:])y.append(y_i)X.append(X_i)y = np.reshape(np.array(y), [-1])X = libsvm_2_coo(X, (len(X), INPUT_DIM)).tocsr()return X, ydef read_data_tsv(file_name):data = np.loadtxt(file_name, delimiter='\t', dtype=np.float32)X, y = np.int32(data[:, :-1]), data[:, -1]X = libsvm_2_coo(X, (len(X), INPUT_DIM)).tocsr()return X, y/5def shuffle(data):X, y = dataind = np.arange(X.shape[0])for i in range(7):np.random.shuffle(ind)return X[ind], y[ind]def libsvm_2_coo(libsvm_data, shape):coo_rows = []coo_cols = []n = 0for d in libsvm_data:coo_rows.extend([n] * len(d))coo_cols.extend(d)n += 1coo_rows = np.array(coo_rows)coo_cols = np.array(coo_cols)coo_data = np.ones_like(coo_rows)return coo_matrix((coo_data, (coo_rows, coo_cols)), shape=shape)def csr_2_input(csr_mat):if not isinstance(csr_mat, list):coo_mat = csr_mat.tocoo()indices = np.vstack((coo_mat.row, coo_mat.col)).transpose()values = csr_mat.datashape = csr_mat.shapereturn indices, values, shapeelse:inputs = []for csr_i in csr_mat:inputs.append(csr_2_input(csr_i))return inputsdef slice(csr_data, start=0, size=-1):if not isinstance(csr_data[0], list):if size == -1 or start + size >= csr_data[0].shape[0]:slc_data = csr_data[0][start:]slc_labels = csr_data[1][start:]else:slc_data = csr_data[0][start:start + size]slc_labels = csr_data[1][start:start + size]else:if size == -1 or start + size >= csr_data[0][0].shape[0]:slc_data = []for d_i in csr_data[0]:slc_data.append(d_i[start:])slc_labels = csr_data[1][start:]else:slc_data = []for d_i in csr_data[0]:slc_data.append(d_i[start:start + size])slc_labels = csr_data[1][start:start + size]return csr_2_input(slc_data), slc_labelsdef split_data(data):fields = []for i in range(len(FIELD_OFFSETS) - 1):start_ind = FIELD_OFFSETS[i]end_ind = FIELD_OFFSETS[i + 1]field_i = data[0][:, start_ind:end_ind]fields.append(field_i)fields.append(data[0][:, FIELD_OFFSETS[-1]:])return fields, data[1]def init_var_map(init_vars, init_path=None):if init_path is not None:load_var_map = pkl.load(open(init_path, 'rb'))print('load variable map from', init_path, load_var_map.keys())var_map = {}for var_name, var_shape, init_method, dtype in init_vars:if init_method == 'zero':var_map[var_name] = tf.Variable(tf.zeros(var_shape, dtype=dtype), dtype=dtype)elif init_method == 'one':var_map[var_name] = tf.Variable(tf.ones(var_shape, dtype=dtype), dtype=dtype)elif init_method == 'normal':var_map[var_name] = tf.Variable(tf.random_normal(var_shape, mean=0.0, stddev=STDDEV, dtype=dtype),dtype=dtype)elif init_method == 'tnormal':var_map[var_name] = tf.Variable(tf.truncated_normal(var_shape, mean=0.0, stddev=STDDEV, dtype=dtype),dtype=dtype)elif init_method == 'uniform':var_map[var_name] = tf.Variable(tf.random_uniform(var_shape, minval=MINVAL, maxval=MAXVAL, dtype=dtype),dtype=dtype)elif isinstance(init_method, int) or isinstance(init_method, float):var_map[var_name] = tf.Variable(tf.ones(var_shape, dtype=dtype) * init_method)elif init_method in load_var_map:if load_var_map[init_method].shape == tuple(var_shape):var_map[var_name] = tf.Variable(load_var_map[init_method])else:print('BadParam: init method', init_method, 'shape', var_shape, load_var_map[init_method].shape)else:print('BadParam: init method', init_method)return var_mapdef activate(weights, activation_function):if activation_function == 'sigmoid':return tf.nn.sigmoid(weights)elif activation_function == 'softmax':return tf.nn.softmax(weights)elif activation_function == 'relu':return tf.nn.relu(weights)elif activation_function == 'tanh':return tf.nn.tanh(weights)elif activation_function == 'elu':return tf.nn.elu(weights)elif activation_function == 'none':return weightselse:return weightsdef get_optimizer(opt_algo, learning_rate, loss):if opt_algo == 'adaldeta':return tf.train.AdadeltaOptimizer(learning_rate).minimize(loss)elif opt_algo == 'adagrad':return tf.train.AdagradOptimizer(learning_rate).minimize(loss)elif opt_algo == 'adam':return tf.train.AdamOptimizer(learning_rate).minimize(loss)elif opt_algo == 'ftrl':return tf.train.FtrlOptimizer(learning_rate).minimize(loss)elif opt_algo == 'gd':return tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)elif opt_algo == 'padagrad':return tf.train.ProximalAdagradOptimizer(learning_rate).minimize(loss)elif opt_algo == 'pgd':return tf.train.ProximalGradientDescentOptimizer(learning_rate).minimize(loss)elif opt_algo == 'rmsprop':return tf.train.RMSPropOptimizer(learning_rate).minimize(loss)else:return tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)def gather_2d(params, indices):shape = tf.shape(params)flat = tf.reshape(params, [-1])flat_idx = indices[:, 0] * shape[1] + indices[:, 1]flat_idx = tf.reshape(flat_idx, [-1])return tf.gather(flat, flat_idx)def gather_3d(params, indices):shape = tf.shape(params)flat = tf.reshape(params, [-1])flat_idx = indices[:, 0] * shape[1] * shape[2] + indices[:, 1] * shape[2] + indices[:, 2]flat_idx = tf.reshape(flat_idx, [-1])return tf.gather(flat, flat_idx)def gather_4d(params, indices):shape = tf.shape(params)flat = tf.reshape(params, [-1])flat_idx = indices[:, 0] * shape[1] * shape[2] * shape[3] + \indices[:, 1] * shape[2] * shape[3] + indices[:, 2] * shape[3] + indices[:, 3]flat_idx = tf.reshape(flat_idx, [-1])return tf.gather(flat, flat_idx)def max_pool_2d(params, k):_, indices = tf.nn.top_k(params, k, sorted=False)shape = tf.shape(indices)r1 = tf.reshape(tf.range(shape[0]), [-1, 1])r1 = tf.tile(r1, [1, k])r1 = tf.reshape(r1, [-1, 1])indices = tf.concat([r1, tf.reshape(indices, [-1, 1])], 1)return tf.reshape(gather_2d(params, indices), [-1, k])def max_pool_3d(params, k):_, indices = tf.nn.top_k(params, k, sorted=False)shape = tf.shape(indices)r1 = tf.reshape(tf.range(shape[0]), [-1, 1])r2 = tf.reshape(tf.range(shape[1]), [-1, 1])r1 = tf.tile(r1, [1, k * shape[1]])r2 = tf.tile(r2, [1, k])r1 = tf.reshape(r1, [-1, 1])r2 = tf.tile(tf.reshape(r2, [-1, 1]), [shape[0], 1])indices = tf.concat([r1, r2, tf.reshape(indices, [-1, 1])], 1)return tf.reshape(gather_3d(params, indices), [-1, shape[1], k])def max_pool_4d(params, k):_, indices = tf.nn.top_k(params, k, sorted=False)shape = tf.shape(indices)r1 = tf.reshape(tf.range(shape[0]), [-1, 1])r2 = tf.reshape(tf.range(shape[1]), [-1, 1])r3 = tf.reshape(tf.range(shape[2]), [-1, 1])r1 = tf.tile(r1, [1, shape[1] * shape[2] * k])r2 = tf.tile(r2, [1, shape[2] * k])r3 = tf.tile(r3, [1, k])r1 = tf.reshape(r1, [-1, 1])r2 = tf.tile(tf.reshape(r2, [-1, 1]), [shape[0], 1])r3 = tf.tile(tf.reshape(r3, [-1, 1]), [shape[0] * shape[1], 1])indices = tf.concat([r1, r2, r3, tf.reshape(indices, [-1, 1])], 1)return tf.reshape(gather_4d(params, indices), [-1, shape[1], shape[2], k])
机器学习项目 - ctr 电商点击率预估相关推荐
- Kaggle实战:点击率预估
版权声明:本文出自程世东的知乎,原创文章,转载请注明出处:Kaggle实战--点击率预估. 请安装TensorFlow1.0,Python3.5 项目地址: chengstone/kaggle_cri ...
- Kaggle实战——点击率预估
<深度学习私房菜:跟着案例学Tensorflow>作者 版权声明:本文出自程世东的知乎,原创文章,转载请注明出处:Kaggle实战--点击率预估. 请安装TensorFlow1.0,Pyt ...
- Ctr点击率预估理论基础及项目实战
1.机器学习推荐算法模型回顾 召回(粗排) 利用业务规则结合机器学习推荐算法得到初始推荐结果,得到部分商品召回集 ALS\UserCF\ItemCF\FP-Growth\规则等方式召回 排序(精排) ...
- 一文总结排序模型CTR点击率预估
CTR点击率预估系列家谱 炼丹之前,先放一张CTR预估系列的家谱,让脉络更加清晰. (一)FiBiNET:结合特征重要性和双线性特征交互进行CTR预估 1.1 背景 本文发表在RecSys 2019 ...
- 推荐算法炼丹笔记:排序模型CTR点击率预估系列
微信公众号:炼丹笔记 CTR点击率预估系列家谱 炼丹之前,先放一张CTR预估系列的家谱,让脉络更加清晰. (一)FiBiNET:结合特征重要性和双线性特征交互进行CTR预估 1.1 背景 本文发表在 ...
- 推荐算法炼丹笔记:CTR点击率预估系列入门手册
CTR点击率预估系列家谱 炼丹之前,先放一张CTR预估系列的家谱,让脉络更加清晰. (一)FiBiNET:结合特征重要性和双线性特征交互进行CTR预估 1.1 背景 本文发表在RecSys 2019 ...
- CTR点击率预估干货分享
1.指标 广告点击率预估是程序化广告交易框架的非常重要的组件,点击率预估主要有两个层次的指标: 1.排序指标.排序指标是最基本的指标,它决定了我们有没有能力把最合适的广告找出来去呈现给最合适的用户. ...
- 推荐系统-排序层:主流CTR模型综述【Click-Through-Rate,点击率预估,指精排层的排序】【CTR 模型的输入(即训练数据)是:大量成对的 (features, label)数据】
一.CTR 模型建模 在讲 CTR 模型之前,我们首先要清楚 CTR 模型是什么,用来解决什么问题.所以我们先描述 CTR 问题,并对其进行数学建模. 一个典型的推荐系统架构如下图所示: 一般会划分为 ...
- 【Vue】实战项目:电商后台管理系统(Element-UI)(一)前后端搭建 - 登录界面 - 主页界面
文章目录 0. 项目介绍 电商管理系统(Element-UI) 开发模式 前端技术栈 后端技术栈 1. 配置--初始化 前端项目 ① 安装 Vue 脚手架 ② 通过 Vue 脚手架创建项目 ③ 配置 ...
- Golang实战项目-B2C电商平台项目(8)
Golang实战项目-B2C电商平台项目(8) 商品描述新增 商品描述表(tb_item_desc)和商品表(tb_item)具有主外键关系,商品的主键也是商品描述的主键,使用工具函数生成的主键也当作 ...
最新文章
- RTMPdump(libRTMP) 源代码分析 3: AMF编码
- 常见概率分布的Matplotlib实现
- 《铲子骑士》:“复古游戏”的集大成者
- 2012年I / O之后
- mysql sum很慢,可以在MySQL中加快sum()吗?
- 【数据结构与算法】【算法思想】分治算法
- 真正厉害的产品经理,都是“数据思维”的高手
- 使用static代码块实现线程安全的单例设计模式
- 云+AI+5G时代,华为云已准备好多元化云服务架构
- 应用内截屏的代码,在Activity中测试可用
- 如何获取系统Home(Launcher)应用判断用户是否处于home界面
- Debug日志正常,输出和HTML页面乱码
- JS 微信公众号如何跳转到另一个微信公众号的链接
- 开发集成云信IM小程序聊天室流程
- NTU RGB-D数据集申请
- struct的构造函数
- 11.4 使用Flask-PageDown支持富文本文章
- 多模态 |COGMEN: COntextualized GNN based Multimodal Emotion recognitioN论文详解
- 锁相环的组成和原理及应用
- 解决iTunes更新或者重现安装出现“指定账户已存在问题