每日7千次的跨部门任务调度,有赞怎么设计大数据开发平台?
随着公司规模的增长,对大数据的离线应用开发的需求越来越多,这些需求包括但不限于离线数据同步(MySQL/Hive/Hbase/Elastic Search 等之间的离线同步)、离线计算(Hive/MapReduce/Spark 等)、定时调度、运行结果的查询以及失败场景的报警等等。
在统一的大数据开发平台产生之前,面临一系列的问题:
- 多个开发和调度入口,不同的业务部门之间的项目或组件很难复用,同时带来繁重的运维成本
- Hadoop 的环境对业务团队的同事来讲不友好(除了要熟悉业务以外还需要对底层框架有比较深入的了解)
- 重复的开发工作(例如导表、调度等本来可以复用的模块,却需要在多个项目中重复实现)
- 频繁的跨部门需求沟通和讨论
为了解决上述遇到的各类问题,同时参考了业界其他公司的大数据解决方案,我们设计并实现了大数据开发平台(Data Platform,简称 DP),通过可视化的交互界面,解决离线大数据计算相关的各种环境和工具。
本文将介绍 DP 的系统设计以及在有赞的落地情况,内容包括:
- DP 的系统设计,包括架构设计,以及重点介绍了调度模块的设计
- 目前在有赞的落地现状
- 总结和展望
大数据开发平台的设计
架构设计
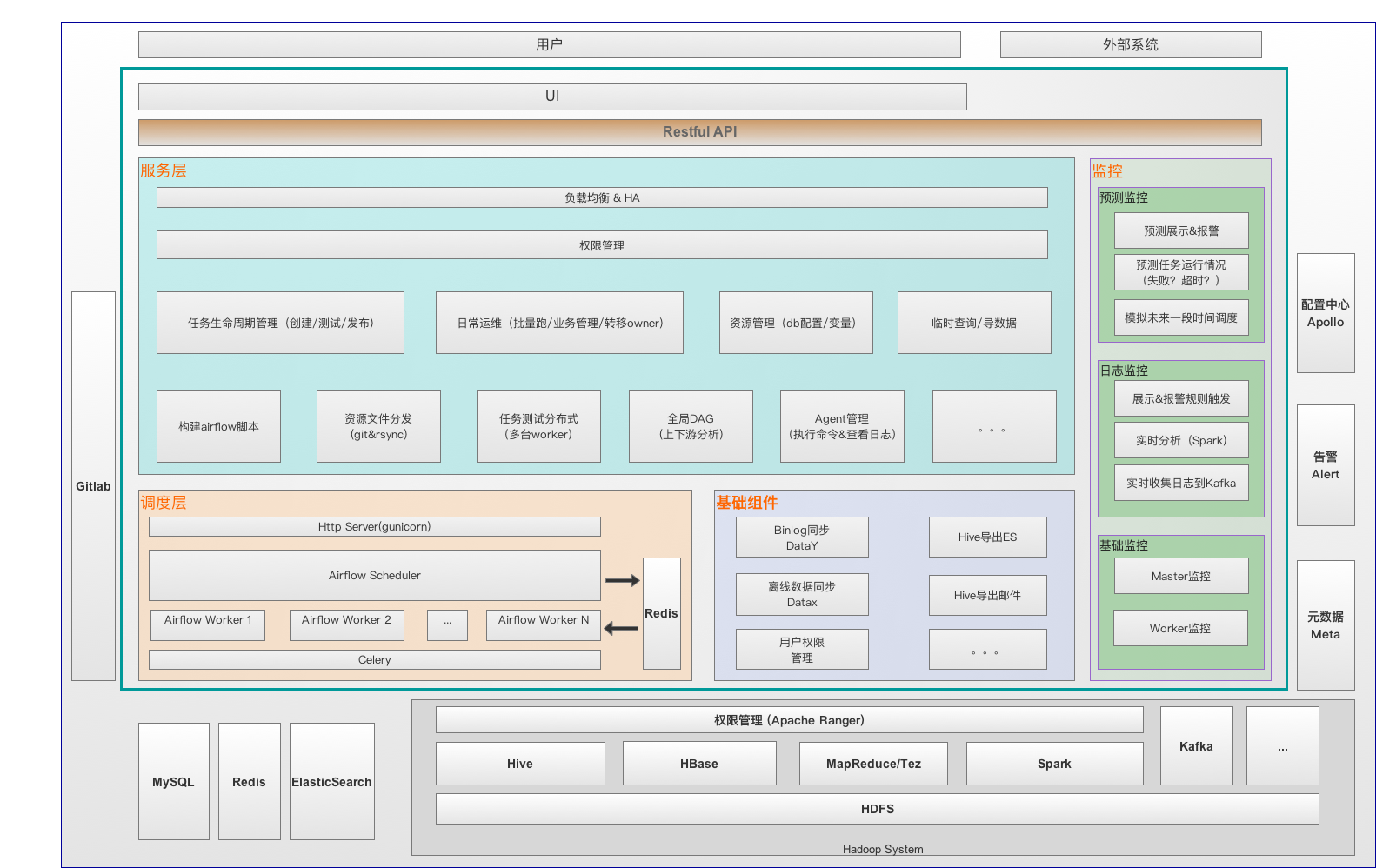
图1 DP系统架构图
大数据开发平台包括调度模块(基于开源airflow二次开发)、基础组件(包括公共的数据同步模块/权限管理等)、服务层(作业生命周期管理/资源管理/测试任务分发/Slave管理等)和监控(机器资源/日志/基于预测的监控)。这些模块具体功能和职责为:
任务调度模块:支持基于任务优先级的多队列、分布式调度。在开源的 airflow 基础上进行了二次开发,主要新增功能包括:
- 增加多种任务类型(datax/datay/导出邮件/导出es/Spark等)
- 根据任务的上下游关系以及重要程度,计算任务的全局优先级,根据全局优先级调度(优先级高的优先执行,低的则进入队列等待)
- 跨 Dag 的任务依赖关系展示(基于全局 Dag,通过任务的读写Hive表信息建立跨 Dag 的依赖关系)
- 一键 Clear 当前节点的所有依赖下游节点(支持跨Dag)
基础模块:包括离线的全量/增量数据同步、基于Binlog的增量同步、Hive 导出 ES /邮件、MySQL 同步到 Hbase (开发中)等,参考图2。

图2 DP支持的离线数据同步方式(箭头表示数据流向)
服务模块:负责作业的生命周期管理,包括作业的创建(修改)、测试、发布、运维等,服务部署采用 Master / Slave 模式,参考图3所示。其中
Master 节点支持 HA 以及热重启(重启期间另外一台提供服务,因此对用户是无感知的)。Master 节点的主要职责是作业的生命周期管理、测试任务分发、资源管理、通过心跳的方式监控 Slaves 等。
Slave 节点分布在调度集群中,与 Airflow 的 worker 节点公用机器。Slave 节点的主要职责是执行 Master 分发的命令(包括测试、机器监控脚本等)、更新资源(通过 Gitlab )等。
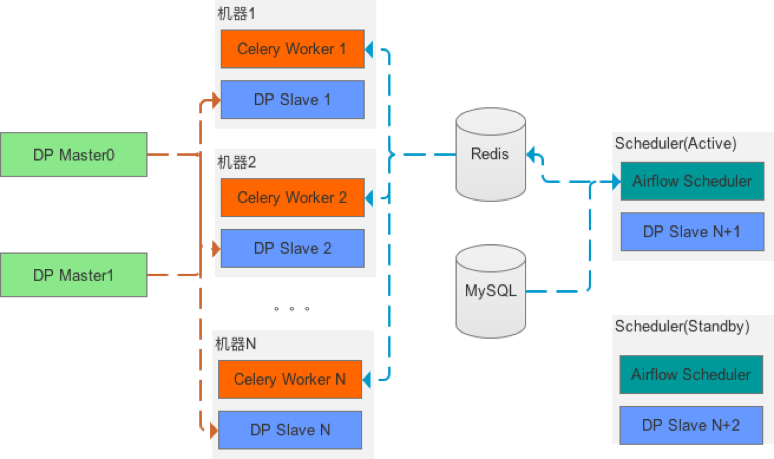
图3 DP 部署图
监控模块:对调度集群的机器、资源、调度任务进行全方位的监控和预警。按照监控的粒度和维度分成三类:
- 基础监控:结合运维监控(进程、IO等)和自定义监控(包括任务环比波动监控、关键任务的产出时间监控等)对DP的Master节点和Worker节点进行基础的监控和报警。
- 日志监控:通过将任务运行时产出的日志采集到 Kafka,然后经过 Spark Steaming 解析和分析,可以计算每个任务运行的起止时间、Owner、使用到的资源量( MySQL 读写量、 Yarn 的 CPU / Memory 使用量、调度 Slot 的占用情况等),更进一步可以分析Yarn任务的实时运行日志,发现诸如数据倾斜、报错堆栈信息等数据。最后将这些数据存储在 NoSQL(比如 Redis )以进一步的加工和展示。
- 任务预测监控:通过提前一段时间模拟任务的调度(不真正的跑任务),来预测任务的开始/结束时间,同时可以提早知道可能失败、超时的任务列表,进而在问题发生之前进行规避。
现阶段已经实现的功能:分析可能失败的任务列表(失败的原因可能是DB的配置发生更改、上游的节点失败等)并发送告警信息;基于过去一段时间的运行时间数据,模拟整个任务调度,可以计算出任务的开始/结束时间以及超时告警。
未来规划:任务的运行时长不是基于过去的数据,而是通过读取的数据量、集群资源使用率、任务计算复杂程度等多个特征维度来预测运行时长。
任务调度设计
大数据开发平台的任务调度是指在作业发布之后,按照作业配置中指定的调度周期(通过 crontab 指定)在一段时间范围内(通过开始/结束时间指定)周期性的执行用户代码。任务调度需要解决的问题包括:
- 如何支持不同类型任务?
- 如何提供任务调度的高并发(高峰时期每秒需要处理上百个任务执行)?
- 如何保证相对重要的任务(数据仓库任务)优先获取资源并执行?
- 如何在多台调度机器上实现负载均衡(主要指CPU/内存资源)?
- 如何保证调度的高可用?
- 任务调度的状态、日志等信息怎么比较友好的展示?
为了解决上述问题,我们调研了多种开源框架(Azkaban/Oozie/Airflow等),最终决定采用 Airflow + Celery + Redis + MySQL 作为 DP 的任务调度模块,并结合公司的业务场景和需求,做了一些深度定制,给出了如下的解决方案(参考图4):
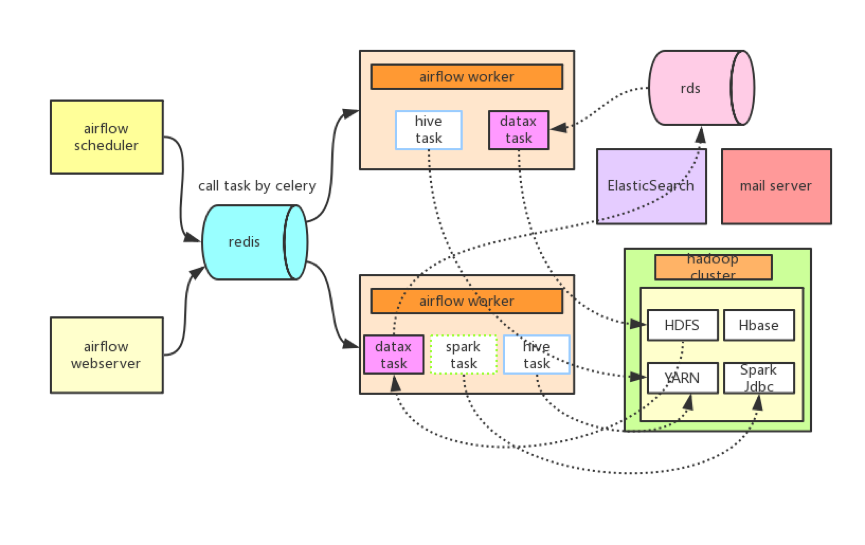
图4 基于Airflow + Celery + Redis + MySQL的任务调度
针对问题1,在 Airflow 原始的任务类型基础上,DP 定制了多种任务(实现 Operator ),包括基于 Datax 的导入导出任务、基于 Binlog 的 Datay 任务、Hive 导出 Email 任务、 Hive 导出 ElasticSearch 任务等等。
针对问题2,一方面通过 Airflow 提供的 Pool + Queue + Slot 的方式实现任务并发个数的管理,以及把未能马上执行的任务放在队列中排队。另一方面通过 Celery 可以实现了任意多台Worker的分布式部署(水平扩展),理论上调度没有并发上限。
针对问题3,在 Airflow 本身支持的优先级队列调度基础之上,我们根据任务的上下游关系以及标记重要的任务节点,通过全局DAG计算出每个节点的全局优先级,通过将该优先级作为任务调度的优先级。这样可以保证重要的任务会优先调度,确保重要任务产出时间的稳定性。
针对问题4,首先不同类型的任务需要耗费不同类型的资源,比如 Spark 任务是内存密集型、Datax 任务是 CPU 密集型等,如果将同一类任务集中在一台机器上执行,容易导致部分系统资源耗尽而另外一部分资源空闲,同时如果一台机器的并发任务数过多,容易引起内存 OOM 以及 CPU 不断地切换进程上下文等问题。因此我们的解决方式是:
将任务按照需要的资源量分成不同类型的任务,每种类型的任务放到一个单独的调度队列中管理。
每个队列设置不同的 Slot ,即允许的最大并发数
每台 Worker 机器同时配置多个队列
基于这些配置,我们可以保证每台 Worker 机器的 CPU /内存使用率保持在相对合理的使用率范围内,如图5所示
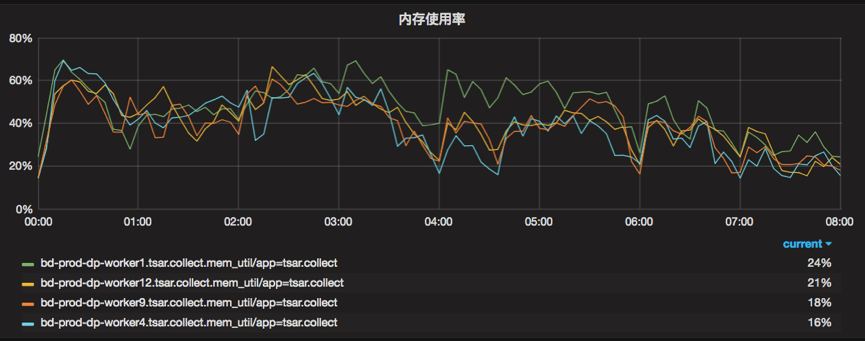
图5 调度Worker机器的内存使用情况
针对问题5,任务调度模块涉及到的角色包括 Scheduler (生产者)和 Worker (消费者),因为 Worker 本来就是分布式部署,因此部分机器不可用不会导致整个调度的不可用(其他节点可以继续服务)。而 Scheduler 存在单点问题,我们的解决方案是除了 Active Scheduler 节点之外,新增一个 Standby Scheduler(参考图3),Standby节点会周期性地监听 Active 节点的健康情况,一旦发现 Active Scheduler 不可用的情况,则 Standby 切换为 Active 。这样可以保证 Scheduler 的高可用。
针对问题6,Airflow 自带的 Web 展示功能已经比较友好了。
现状
DP项目从2017年1月开始立项开发,6月份正式投入生产,之后经过了N轮功能迭代,在易用性和稳定性方面有了显著提升,目前调度集群包括2台Master和13台 Slave(调度)节点(其中2台用于 Scheduler ,另外11台用于 Worker ),每天支持7k+的任务调度,满足数据仓库、数据中心、BI、商品、支付等多个产品线的应用。
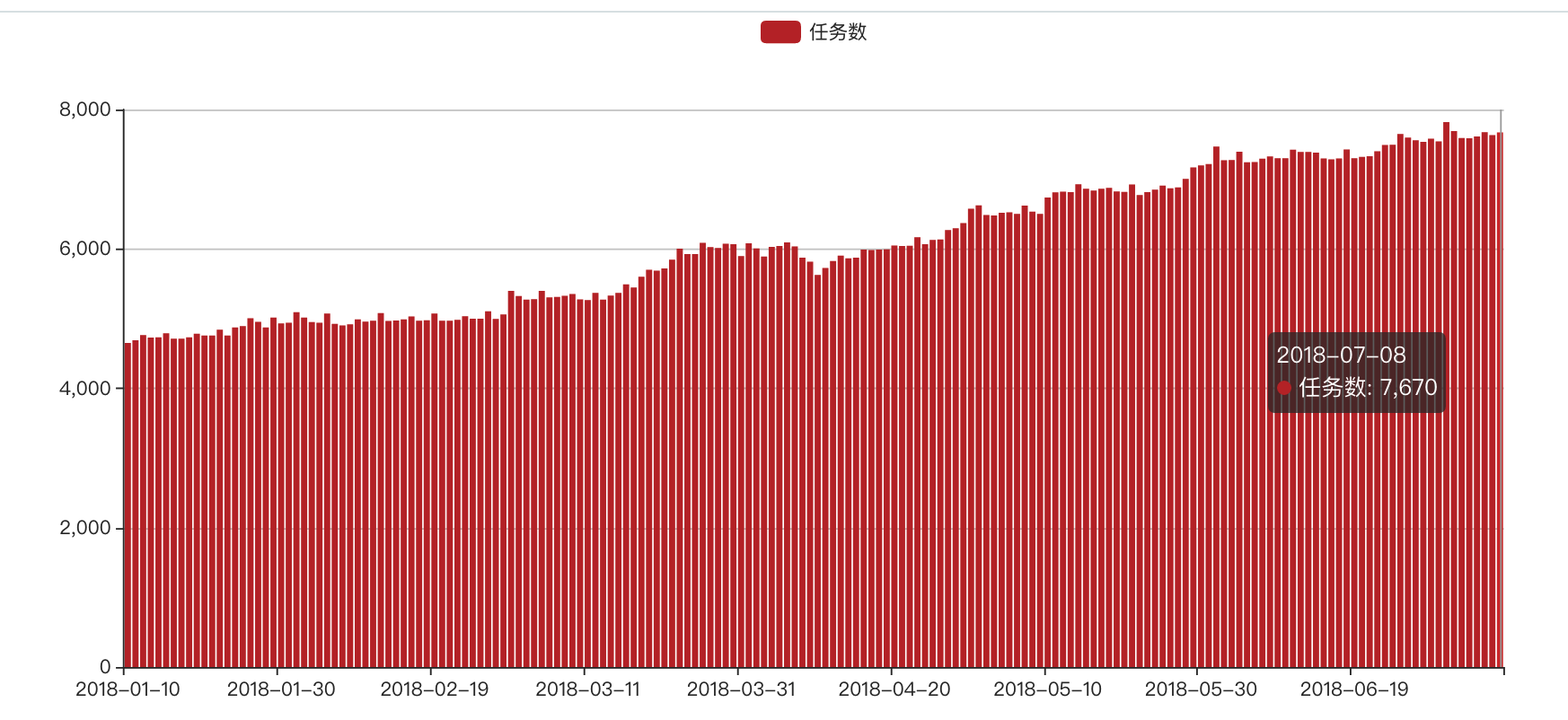
图6 DP调度任务数趋势图
目前DP支持的任务类型包括:
- 离线数据同步:
- 从 MySQL 到 Hive 的全量/增量数据同步(基于 Datax 二次开发)
- 从 Hive 到 MySQL 的全量/增量数据同步(基于 Datax 二次开发)
- 从 MySQL 通过 Binlog ,经过 Nsq/Hdfs/MapReduce 增量同步到 Hive( Datay ,自研)
- 从 MySQL 同步到 Hbase (基于 Datax 二次开发)
- 从 Hive 同步到 ElasticSearch (基于 Datax 二次开发)
- Hadoop 任务:
- Hive/MapReduce/Spark/Spark SQL
- 其他任务:
- 将 Hive 表数据以邮件形式导出(支持 PDF/Excel/Txt 格式的附件)
- Python/Shell/Jar 形式的脚本任务
总结和展望
DP 在经过一年半的不断功能迭代和完善之后,目前日均支持7k+的任务调度,同时在稳定性和易用性方面也有了较大的提升,可以满足用户日常对大数据离线开发的大部分使用场景。同时我们也意识到大数据开发这块还有很多可以挖掘和提升的点,未来我们可能会从这些方面进一步完善平台的功能和提升用户体验:
- 更加丰富的任务类型
- 进一步整合其他平台或工具,做到大数据开发的一站式体验
- 提供用户首页(空间),提供日常运维工具和管理页面,更加方便任务的集中管理
- 任务日志管理优化(包括快速定位出错信息/拉取和分析 Yarn 日志等)
作者简介:大数据平台是有赞共享技术的核心团队之一,该团队主要由数据技术、数据产品、算法挖掘、广告平台四个小团队组成,目前共有34位优秀的工程师组成。
每日7千次的跨部门任务调度,有赞怎么设计大数据开发平台?相关推荐
- 政法重点关注人员管控系统开发,跨部门大数据办案平台建设
政法大数据重点人员管控系统开发,重点关注人员联防联控平台建设方案 在综合运营指挥平台的过程中,社会生活部门的综合运营具有共同,未知和潜力性:有很多的关键人员不会被一些奇怪的"形象" ...
- 产品运营 跨境支付_精细化运营,大数据洞察跨境电商出口经营方向(上)
大数据洞察跨境电商出口经营方向 采购在线化成大趋势,信息化及数据管理能力应被重视 以1688跨境专供为代表的数字化供应链平台实力覆盖全球及各细分区域的热销品类, 拥有超过4000万的商品池, 2018 ...
- 频繁与交通部门合作,百度地图开挖大数据金矿
昨天,百度地图与成都交警.成都交投签署合作协议,建立战略合作伙伴关系,成都交警将向百度开放公共交通大数据,让百度地图给用户提供更加便利的地图服务,如实时路况:而百度则将提供云计算.大数据和人工智能等领 ...
- 每日新闻:钉钉蓝凌双剑合璧;腾讯大数据再下一城;西门子裁员2600人;苹果削减iPhone XS Max中组件 以降低成本...
关注中国软件网 最新鲜的企业级干货聚集地 洞察 今日热点 腾讯助力乌鲁木齐市打造数字政府 共建亚欧大数据中心 近日,腾讯公司与乌鲁木齐市政府签订战略合作协议,共建亚欧大数据中心.乌鲁木齐市委副书记.常 ...
- 这个年均开销3500万美元的 FBI 机密部门,将结合面部识别与大数据技术来调查案件...
撰者 | Thomas Brewster 译者 | Katie,责编 | Jerry 来源 | CSDN云计算 FBI+面部识别+大数据,瞄准恐怖犯罪事件 在发生大规模枪击或恐怖袭击后,调查人员可能会 ...
- 千锋教育浅谈大数据开发工程师就业方向
这个时代是大数据时代,也是大数据人才稀缺的时代.由于中国人才缺口比较大,大数据也迅速成为行业和市场的热点,更多的企业无论是对人才的招聘还是在培训都成了刚需,这也促使大数据人才的薪资在同岗位中是很高的, ...
- OPPO大数据离线任务调度系统OFLOW
1 离线调度系统 在整个大数据体系中,在原始数据被采集之后,需要使用各种逻辑进行整合和计算之后才能输出实际有效的数据,才能最终用于商业目的,实现大数据的价值.在整个处理流程中,无论是抽取.转换.装载( ...
- 政法委跨部门大数据协同办案平台建设,综治信息管控系统开发
政法委跨部门大数据协同办案平台建设,综治信息管控系统开发 政法跨部门大数据协同办案平台,通过运用云计算.大数据.人工智能等先进理念和技术,构建政法跨部门大数据办案平台,形成网络互联通.资源共享用的执法 ...
- 威海市商业银行建立了 PMO 跨部门协调与决策机制
中新经纬 12 月 1 日电 威海市商业银行紧抓 " 数字经济 " 新机遇,将 " 数字银行 " 建设提到战略的高度加以推进,制定了数字化转型三年规划,确定了 ...
最新文章
- 一个Java程序员应该掌握的10项技能
- NodeJs 创建一个简单的服务
- C#模拟最简单的交通信号灯
- 电脑忽然卡了,键盘鼠标也失灵,问题所在,如何处理?
- oracle统计每日归档大小,Oracle查询最近几天每小时归档日志产生数量的脚本写法...
- ui边框设计图_UI设计形状和对象基础知识:填充和边框
- 微信小程序引入npm
- java值传递和引用传递的例子,Java中的值传递和引用传递实例介绍
- Atitit 缓存实施遇到的问题与解决 s420 attilax 艾提拉总结 Atitit 缓存增加最佳实践与实施流程 1. 业务准确性问题正确性问题 1 1.1. 缓存key正确性问题 1
- STM32基础教程(CubeMX)—— LCD显示
- c语言ll 1 语法分析器,LL(1)语法分析器的设计与实现
- 如何自学VR虚拟现实技术?VR简单上手教程
- NetBeans IDE教程
- android studio连接本地SqlServer数据库报网络错误
- 扫呗扫码点餐,如何在扫呗后台给这个商户配一下支付授权地址
- 英语日常用语900句(5)
- 去加拿大跟Bengio读硕vs斯坦福全奖ML博士,选哪个?
- android 吐泡泡动画,android仿摩拜贴纸碰撞|气泡碰撞
- 【算法1-3】暴力枚举——First Step
- 个体工商户注册后,都需做哪些事呢?这3点很重要