大数据常用shell脚本之fl脚本
一、前置准备
CentOS7、jdk1.8、zookeeper-3.5.7、kafka-2.4.1、flume-1.9.0
想要完成本期视频中所有操作,需要以下准备:
Flume安装及基本使用-视频教程
Kafka集群环境搭建-视频教程
大数据常用shell脚本之分发脚本编写-视频教程
大数据常用shell脚本之zk脚本编写-视频教程
大数据常用shell脚本之ha-hadoop脚本编写-视频教程
大数据常用shell脚本之kf脚本编写-视频教程
二、简单了解
nohup可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思, 不挂断地运行命令。awk默认分隔符为空格,xargs表示取出前面命令运行的结果, 作为后面命令的输入参数。大家对kill -9 肯定非常熟悉,-后面的数字代表信号编号
kill 进程号相当于执行了kill -15 进程号,15代表SIGTERM信号后,大部分程序会先释放自己的资源,然后再停止,也就是说,SIGTERM多半是会被阻塞、忽略的。kill -9 进程号,9代表SIGKILL信号,即杀死信号。该信号不会被系统阻塞,所以能顺利杀掉进程。Taildir Source 相比 Exec Source、 Spooling Directory Source 的优势
TailDir Source: 断点续传、 多目录。
Exec Source:可以实时搜集数据, 但是在 Flume 不运行或者 Shell 命令出错的情况下, 数据将会丢失。
Spooling Directory Source:监控目录, 不支持断点续传。Kafka Channel省去了 Sink, 提高了效率。KafkaChannel数据存储在 Kafka 里面,所以数据是存储在磁盘中的。
flume采集流程:

三、脚本源码
#!/bin/bash#作者:小康
#描述:flume启动停止以及查看状态脚本
#微信公众号:小康新鲜事儿USAGE="使用方法:sh fl.sh start/stop/status"
if [ $# -ne 1 ];thenecho $USAGEexit 1
fi
SHELL_CALL=/home/xiaokang/bin/call-cluster.sh
FLUME_HOME=/opt/software/flume-1.9.0
AGENT_NAME=a1
CONF_FILE=/home/xiaokang/file-flume-kafka.properties
NODES=("hadoop01")
case $1 in
"start")#启动flumefor NODE in ${NODES[*]};doecho "--------$NODE启动flume--------"#ssh $NODE "nohup $FLUME_HOME/bin/flume-ng agent -n $AGENT_NAME -c $FLUME_HOME/conf -f $CONF_FILE -Dflume.root.logger=INFO,LOGFILE >$FLUME_HOME/flume-run.log 2>&1 &"ssh $NODE "nohup $FLUME_HOME/bin/flume-ng agent -n $AGENT_NAME -c $FLUME_HOME/conf -f $CONF_FILE >/dev/null 2>&1 &" done;;
"stop")#停止flumefor NODE in ${NODES[*]};doecho "--------$NODE停止flume,不要着急查看状态,停止较慢--------"ssh $NODE "ps -ef | grep $CONF_FILE | grep -v grep | awk '{print \$2}' | xargs kill" done;;
"status")echo "--------查看flume状态--------"$SHELL_CALL jps -l;;
*)echo $USAGE ;;
esac
echo "----------------------------------------------------------------------------------------"
echo "--------fl.sh脚本执行完成!--------"
echo -e "--------微信公众号:\033[5;31m 小康新鲜事儿 \033[0m--------"
echo "--------小康老师微信:k1583223--------"
echo "--------公众号内回复【大数据】,获取系列教程及随堂文档--------"
echo "----------------------------------------------------------------------------------------"
脚本下载地址:https://github.com/xiaokangxxs/notebook/blob/master/docs/Shell/fl.sh
四、测试使用
# 修改脚本权限
[xiaokang@hadoop01 bin]$ chmod 777 fl.sh
执行方式:
# 方式一
[xiaokang@hadoop01 bin]$ ./fl.sh start
# 方式二
[xiaokang@hadoop01 bin]$ sh fl.sh start
# 方式三
# 1.将shell脚本所在目录配置为环境变量(/etc/profile),记得source生效
export SHELL_HOME=/home/xiaokang/bin
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin:${HIVE_HOME}/bin:${HBASE_HOME}/bin:${KYLIN_HOME}/bin:${KAFKA_HOME}/bin:${SCALA_HOME}/bin:${SCALA_HOME}/sbin:${SPARK_HOME}/bin:${SHELL_HOME}/:$PATH
# 2.在任意目录都可以使用自己编写的shell脚本
[xiaokang@hadoop01 ~]$ fl.sh start
五、采集通道测试
官方文档参考文档:
TailDir Source:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#taildir-source
Kafka Channel:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#kafka-channel
模拟数据脚本makeData.sh:
#!/bin/bash#作者:小康
#描述:模拟数据,每2秒向app-familyaccount-20200524.log文件追加一行内容
#微信公众号:小康新鲜事儿for ((i=0;i<1124;i++));doecho "微信公众号:小康新鲜事儿----$i" >> /home/xiaokang/log/app-familyaccount-20200524.logsleep 2
done
exit 0
file-flume-kafka.properties文件内容如下:
a1.sources=r1
a1.channels=c1
# configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile =/opt/software/flume-1.9.0/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /home/xiaokang/app-familyaccount-20200524.log
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1
# configure channel
a1.channels.c1.type =org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers =hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.channels.c1.kafka.topic = topic-log
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
采集测试开始:
# 启动flume
[xiaokang@hadoop01 ~]$ fl.sh start
# 启动kafka集群,并创建主题topic-log
[xiaokang@hadoop01 ~]$ kf.sh start
[xiaokang@hadoop01 ~]$ kafka-topics.sh --create --zookeeper hadoop01:2181 --partitions 1 --replication-factor 1 --topic topic-log
# 启动一个kafka消费者,等待消费
[xiaokang@hadoop01 ~]$ kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic topic-log --from-beginning
# 执行模拟数据脚本
[xiaokang@hadoop01 ~]$ sh makeData.sh
通道打通后如下图所示:

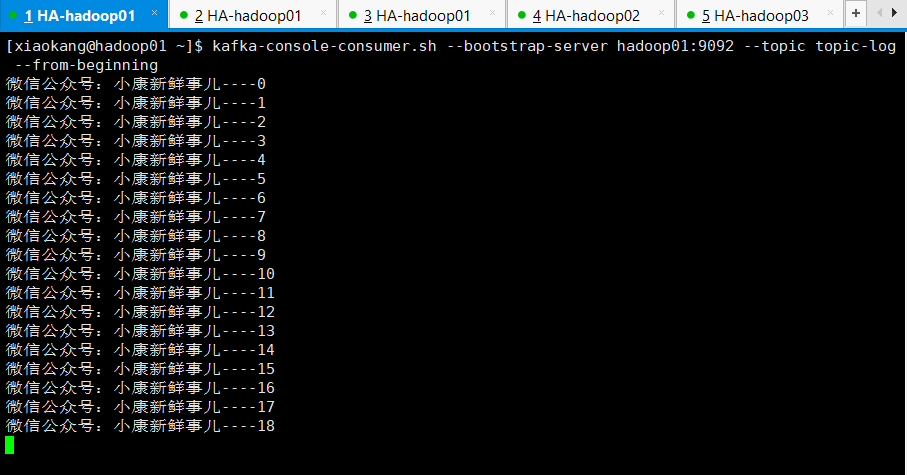
大数据常用shell脚本之fl脚本相关推荐
- 大数据常用shell脚本之zk脚本
一.前置准备 CentOS7.jdk1.8.zookeeper-3.5.7 想要完成本期视频中所有操作,需要以下准备: Zookeeper单机环境和集群环境搭建视频+图文教程 Hadoop完全分布式集 ...
- 大数据常用shell脚本之kf脚本
一.前置准备 CentOS7.jdk1.8.zookeeper-3.5.7.kafka-2.4.1 想要完成本期视频中所有操作,需要以下准备: Kafka集群环境搭建-视频教程 大数据常用shell脚 ...
- 大数据常用的软件工具有哪些?
众所周知,现如今,大数据越来越受到大家的重视,也逐渐成为各个行业研究的重点.正所谓"工欲善其事必先利其器",大数据想要搞的好,使用的工具必须合格.而大数据行业因为数据量巨大的特点, ...
- 大数据-常用压缩方式总结
转载声明 本文系转载自以下两篇文章: 压缩格式gzip/snappy/lzo/bzip2 比较与总结 作者: zzhongcy Snappy.Lzo.Gzip.Bzip2比较 作者: 心有余力 转载仅 ...
- 【大数据入门笔记系列】第一节 大数据常用组件
[大数据入门笔记系列]第一节 大数据常用组件 大数据释义 大数据组件 跳转 大数据释义 近些年来,坊间一直流传着这样的言论:"大数据时代,人人都在裸奔".对于外行人来说,对于&qu ...
- 大数据常用组件官网地址
大数据常用组件官网地址 数据采集传输 Flume 官网:https://flume.apache.org/ 下载地址:https://flume.apache.org/download.html Ka ...
- 大数据常用算法及场景
大数据常用算法及场景 大数据的挖掘是从海量.不完全的.有噪声的.模糊的.随机的大型数据库中发现隐含在其中有价值的.潜在有用的信息和知识的过程,也是一种决策支持过程.其主要基于人工智能,机器学习,模式学 ...
- 大数据常用数据库汇总
通常数据库分为关系型数据库和非关系型数据库,关系型数据库的优势到现在也是无可替代的,比如MySQL.SQL Server.Oracle.DB2.SyBase.Informix.PostgreSQL以及 ...
- 大数据云计算——shell组件
Shell的操作说明书:https://www.runoob.com/linux/linux-shell.html Shell的简介 Shell 是一个用 C 语言编写的程序,它是用户使用 Linux ...
最新文章
- 转载JQuery 获取设置值,添加元素详解
- android 百度导航滑动会异常,百度导航Android版问题集
- 转 从头到尾彻底解析Hash表算法
- python find
- 带头结点头部插入创建链表
- 第 三 十 八 天:Linux 的 LVM 逻 辑 卷 管 理
- [实战]java回调函数
- 数据可视化之多属性(字段)
- 物联网之智能家居系统设计和实现
- 信号完整性(SI)电源完整性(PI)学习笔记(十五)有损线、上升边退化与材料特性(二)
- 模拟人生显示无法连接服务器,模拟人生总是显示无法连接网络
- 不同因子影响下的不同情境的世界气温预测(的辣鸡tkinter UI可视化DEMO)
- mysql 1273错误
- 使用ffmpeg调整图像大小
- Mega RAID卡创建步骤
- VR,AR,MR的区别与联系
- 自然语言处理NLP文本分类顶会论文阅读笔记(二)
- java个人博客系统代码下载_java个人博客系统代码
- batch—size的大小对loss收敛的影响
- yocto linux dns,ZYNQ_LINUX的根文件系统设置为QSPI_FLASH,JFFS2。