Spring Data JPA 原理与实战第十一天 Session相关、CompletableFuture、LazyInitializationException
22 Session 的 open-in-view 对事务的影响是什么?
你好,欢迎来到第 22 讲,今天我们来学习 Session 的相关内容。
当我们使用 Spring Boot 加 JPA 的时候,会发现 Spring 帮我们新增了一个 spring.jpa.open-in-view 的配置,但是 Hibernate 本身却没有这个配置,不过其又是和 Hibernate 中的 Session 相关的,因此还是很重要的内容,所以这一讲我们来学习一下。
由于 Session 不是 JPA 协议规定的,所以官方对于这方面的资料比较少,从业者只能根据个人经验和源码来分析它的本质,那么接下来我就以我个人的经验为你介绍这部分的概念。首先了解 Session 是什么。
Session 是什么?
我们通过一个类的关系图来回顾一下,看看 Session 在什么样的位置上。
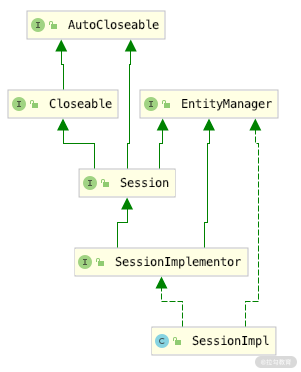
其中,SessionImpl 是 Hibernate 实现 JPA 协议的 EntityManager 的一种实现方式,即实现类;而 Session 是 Hibernate 中的概念,完全符合 EntityManager 的接口协议,同时又完成了 Hibernate 的特殊实现。
在 Spring Data JPA 的框架中,我们可以狭隘地把 Session 理解为 EntityManager,因为其对于 JPA 的任何操作都是通过 EntityManager 的接口进行的,我们可以把 Session 里面的复杂逻辑当成一个黑盒子。即使 SessionImpl 能够实现 Hibernate 的 Session 接口,但如果我们使用的是 Spring Data JPA,那么实现再多的接口也和我们没有任何关系。
除非你不用 JPA 的接口,直接用 Hibernate 的 Navite 来实现,但是我不建议你这么做,因为过程太复杂了。那么 SessionImpl 对使用 JPA 体系的人来说,它主要解决了什么问题呢?
SessionImpl 解决了什么问题?
我们通过源码来看一下,请看下面这张图。
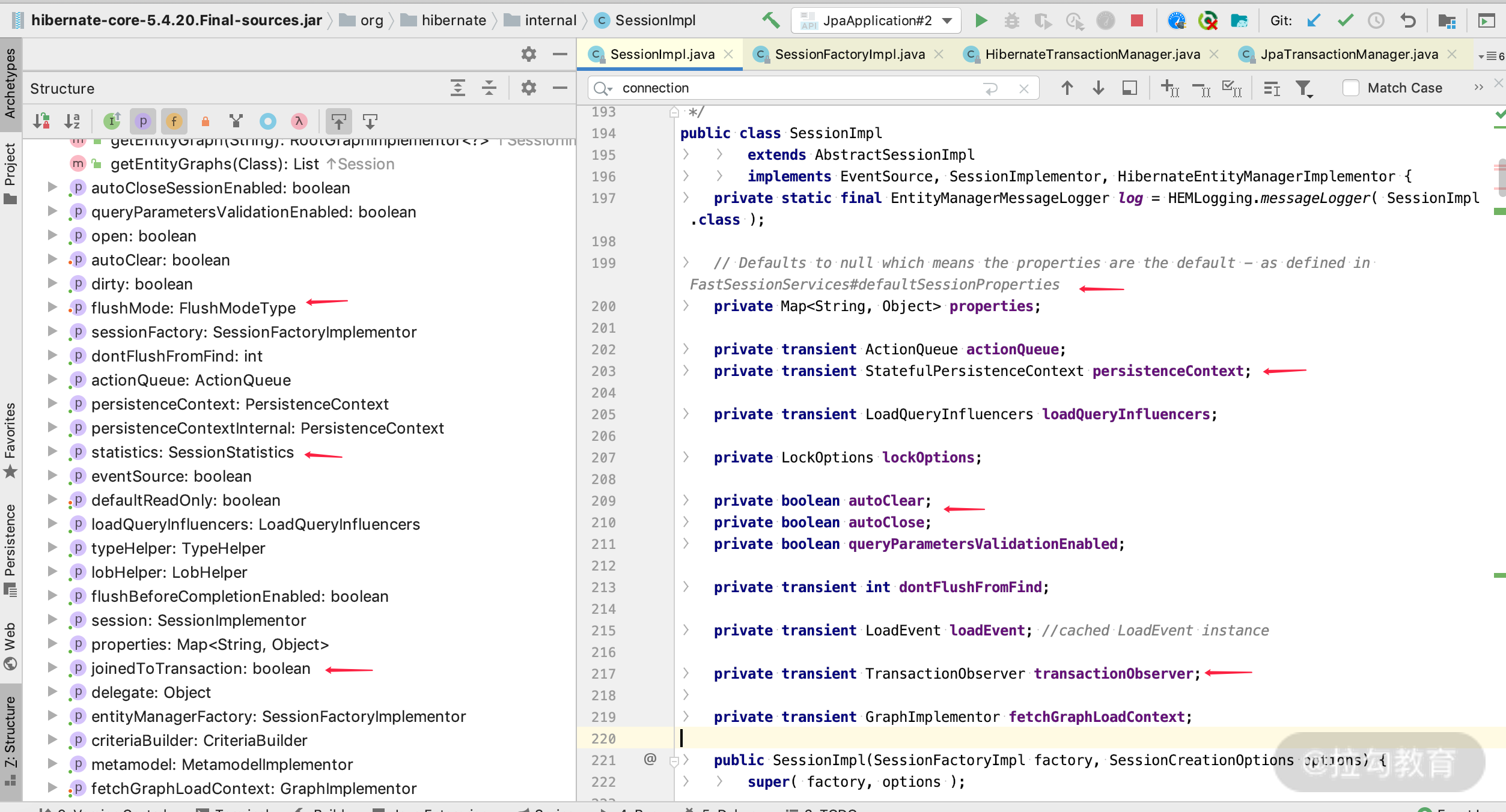
通过 SessionImpl 的源码和 Structure 的视图,我们可以“简单粗暴”地得出如下结论。
SessionImpl 是 EntityManager 的实现类,那么肯定实现了 JPA 协议规定的 EntityManager 的所有功能。比如我们上一课时讲解的 Persistence Context 里面 Entity 状态的所有操作,即管理了 Entity 的生命周期;EntityManager 暴露的 flushModel 的设置;EntityManager 对 Transaction 做了“是否开启新事务”“是否关闭当前事务”的逻辑。
如上图所示,实现 PersistenceContext 对象实例化的过程,使得 PersistenceContext 生命周期就是 Session 的生命周期。所以我们可以抽象地理解为,Sesession 是对一些数据库的操作,需要放在同一个上下文的集合中,就是我们常说的一级缓存。
Session 有 open 的话,那么肯定有 close。open 的时候做了“是否开启事务”“是否获取连接”等逻辑;close 的时候做了“是否关闭事务”“释放连接”等动作;
Session 的任何操作都离不开事务和连接,那么肯定用当前线程保存了这些资源。
当我们清楚了 SessionImpl、EntityManager 的这些基础概念之后,那么接着来看看 open-in-view 是什么,它都做了什么事情呢?
JPA 里面的 open-in-view 是做什么的?
open-in-view 是 Spring Boot 自动加载 Spring Data JPA 提供的一个配置,全称为 spring.jpa.open-in-view=true,它只有 true 和 false 两个值,默认是 true。那么它到底有什么威力呢?
open-in-view 的作用
我们可以在 JpaBaseConfiguration 中找到关键源码,通过源码来看一下 open-in-view 都做了哪些事情,如下所示。
public abstract class JpaBaseConfiguration implements BeanFactoryAware {
@Configuration(proxyBeanMethods = false)
@ConditionalOnWebApplication(type = Type.SERVLET)
@ConditionalOnClass(WebMvcConfigurer.class)
//这个提供了一种自定义注册OpenEntityManagerInViewInterceptor或者OpenEntityManagerInViewFilter的可能,同时我们可以看到在Web的MVC层打开session的两种方式,一种是Interceptor,另外一种是Filter;这两个类任选其一即可,默认用的是OpenEntityManagerInViewInterceptor.class;
@ConditionalOnMissingBean({ OpenEntityManagerInViewInterceptor.class, OpenEntityManagerInViewFilter.class })
@ConditionalOnMissingFilterBean(OpenEntityManagerInViewFilter.class)
//这里使用了spring.jpa.open-in-view的配置,只有为true的时候才会执行这个配置类,当什么都没配置的时候,默认就是true,也就是默认此配置文件就会自动加载;我们可以设置成false,关闭加载;
@ConditionalOnProperty(prefix = "spring.jpa", name = "open-in-view", havingValue = "true", matchIfMissing = true)
protected static class JpaWebConfiguration {private static final Log logger = LogFactory.getLog(JpaWebConfiguration.class);private final JpaProperties jpaProperties;protected JpaWebConfiguration(JpaProperties jpaProperties) {this.jpaProperties = jpaProperties;}
//关键逻辑在OpenEntityManagerInViewInterceptor类里面;加载OpenEntityManagerInViewInterceptor用来在MVC的拦截器里面打开EntityManager,而当我们没有配置spring.jpa.open-in-view的时候,看下面代码spring容器会打印warn日志警告我们,默认开启了open-in-view,提醒我们需要注意影响面,具体有哪些影响面,希望你可以在此篇文章中找到答案,并欢迎留言;@Beanpublic OpenEntityManagerInViewInterceptor openEntityManagerInViewInterceptor() {if (this.jpaProperties.getOpenInView() == null) {logger.warn("spring.jpa.open-in-view is enabled by default. "+ "Therefore, database queries may be performed during view "+ "rendering. Explicitly configure spring.jpa.open-in-view to disable this warning");}return new OpenEntityManagerInViewInterceptor();} //利用WebMvcConfigurer加载上面的OpenEntityManagerInViewInterceptor拦截器进入到MVC里面;@Beanpublic WebMvcConfigurer openEntityManagerInViewInterceptorConfigurer( OpenEntityManagerInViewInterceptor interceptor) {return new WebMvcConfigurer() {@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addWebRequestInterceptor(interceptor);}};}
}
.....//其他不重要的代码省略
通过上面的源码我们可以看到,spring.jpa.open-in-view 的主要作用就是帮我们加载 OpenEntityManagerInViewInterceptor 这个类,那么我们再打开这个类的源码,看看它帮我们实现的主要功能是什么?
OpenEntityManagerInViewInterceptor 源码分析
打开这一源码后,可以看到下图所示的界面。
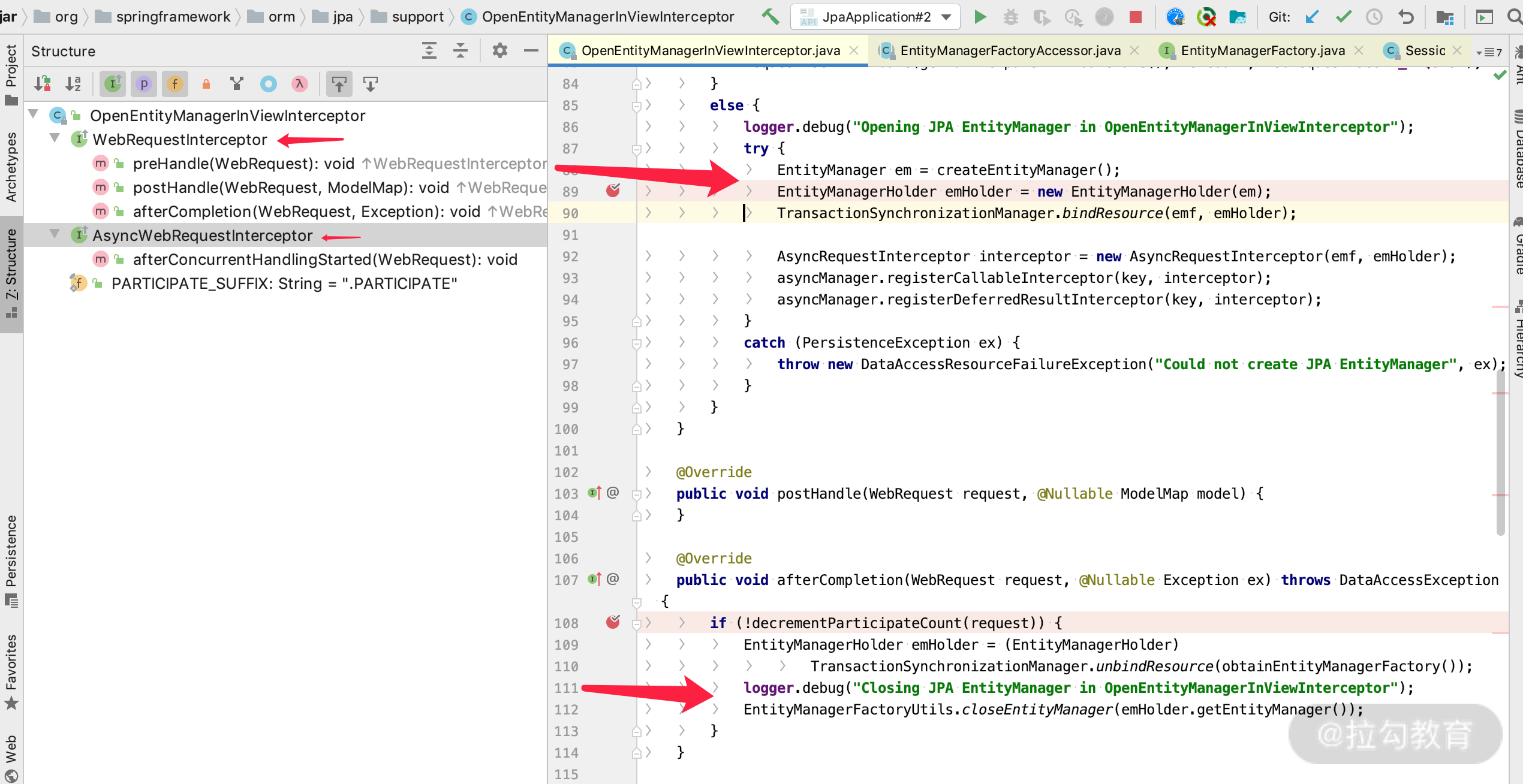
我们可以发现,OpenEntityManagerInViewInterceptor 实现了 WebRequestInterceptor 的接口中的两个方法:
public void preHandle(WebRequest request) 方法,里面实现了在每次的 Web MVC 请求之前,通过 createEntityManager 方法创建 EntityManager 和 EntityManagerHolder 的逻辑;
public void afterCompletion(WebRequest request, @Nullable Exception ex) 方法,里面实现了在每次 Web MVC 的请求结束之后,关闭 EntityManager 的逻辑。
我们如果继续看 createEntityManager 方法的实现,还会找到如下关键代码。
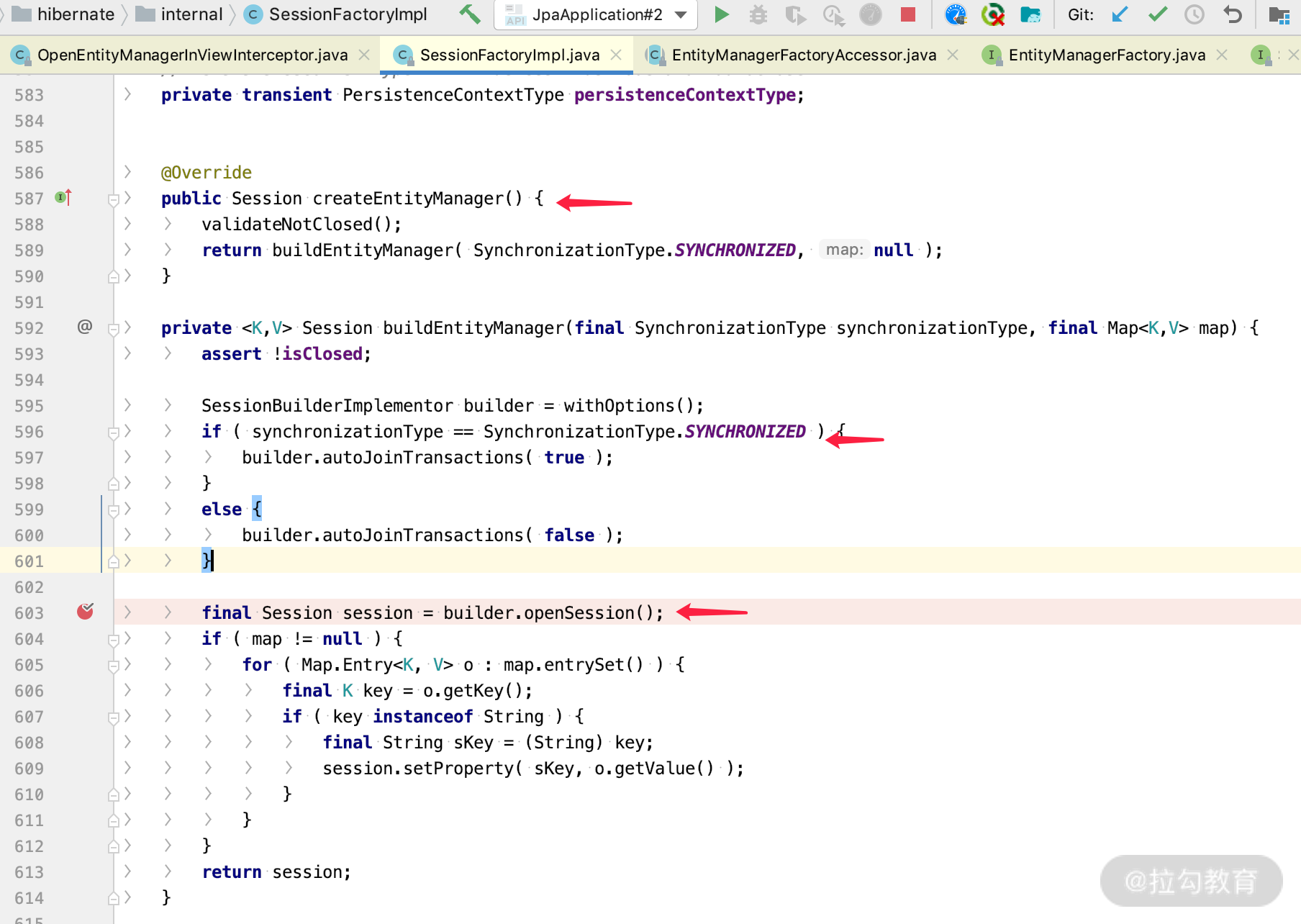
上图可以看到,我们通过 SessionFactoryImpl 中的 createEntityManager() 方法,创建了一个 EntityManager 的实现 Session;通过拦截器创建了 EntityManager 事务处理逻辑,默认是 Join 类型(即有事务存在会加入);而 builder.openSession() 逻辑就是 new SessionImpl(sessionFactory, this)。
所以这个时候可以知道,通过 open-in-view 配置的拦截器,会帮我们的每个请求都创建一个 SessionImpl 实例;而 SessionImpl 里面存储了整个 PersistenceContext 和各种事务连接状态,可以判断出来 Session 的实例对象比较大。
并且,我们打开 spring.jap.open-in-view=true 会发现,如果一个请求处理的逻辑比较耗时,牵涉到的对象比较多,这个时候就比较考验我们对 jvm 的内存配置策略了,如果配置不好就会经常出现内存溢出的现象。因此当处理比较耗时的请求和批量处理请求的时候,需要考虑到这一点。
到这里,经常看源码的同学就应该会好奇了,都有哪些时候需要调用 openSession 呢?那是不是也可以知道 EntityManager(Session) 的打开时机了?
EntityManager(Session) 的打开时机及扩展场景
我们通过 IDEA 开发者工具,直接点击右键查 public Session createEntityManager() 此方法被使用到的地方即可,如下图所示。
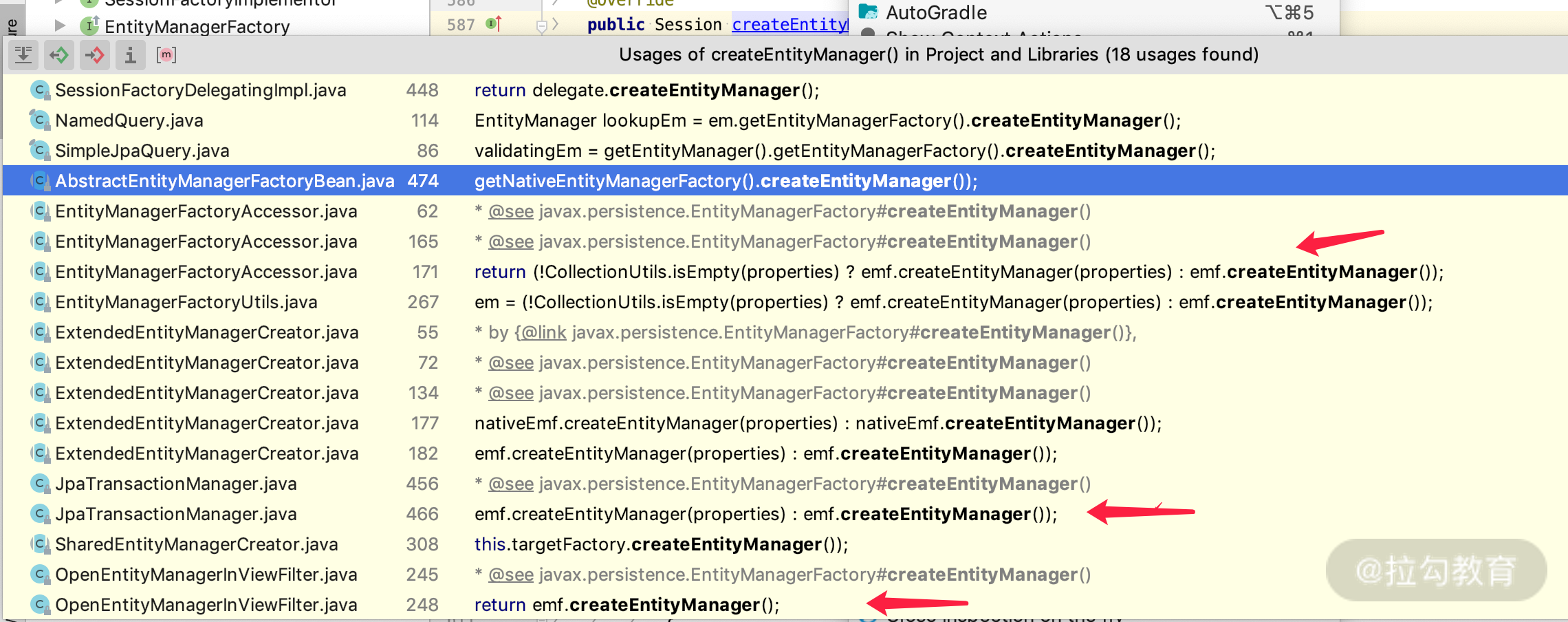
其中,EntityManagerFactoryAccessor 是 OpenEntityManagerInViewInterceptor 的父类,从图上我们可以看得出来,Session 的创建(也可以说是 EntityManager 的创建)对我们有用的时机,目前就有三种。
第一种:Web View Interceptor,通过 spring.jpa.open-in-view 控制。
第二种:Web Filter,这种方式是 Spring 给我们提供的另外一种应用场景,比如有些耗时的、批量处理的请求,我们不想在请求的时候开启 Session,而是想在处理简单逻辑后,需要用到延迟加载机制的请求时 Open Session。因为开启 Session 后,我们写框架代码的时候可以利用 lazy 机制。而这个时候我们就可以考虑使用 OpenEntityManagerInViewFilter,配置请求 filter 的过滤机制,实现不同的请求以及不同 Open Session 的逻辑了。
第三种:JPA Transaction,这种方式就是利用 JpaTransactionManager,实现在事务开启的时候打开 Session,在事务结束的时候关闭 Session。
所以默认情况下,Session 的开启时机有两个:每个请求之前、新的事务开启之前;而 Session 的关闭时机也是两个:每个请求结束之后、事务关闭之后。
此外,EntityManager(Session) 打开之后,资源存储在当前线程里面 (ThreadLoacal),所以一个 Session 中即使开启了多个事务,也不会创建多个 EntityManager 或者 Session。
而事务在关闭之前,也会检查一下此 EntityManager / Session 是不是我这个事务创建的,如果是就关闭,如果不是就不关闭,不过其不会关闭在事务范围之外创建的 EntityManager / Session。
这个机制其实还给我们一些额外思考:我们是不是可以自由选择开启 / 关闭 Session 呢?不一定是 view / filter / 事务,任何多事务组合的代码模块都可以。只要我们知道什么时间开启,保证一定能 close 就没有问题。
下面我们通过日志来看一下两种打开、关闭 EntityManager 的时机。
验证 EntityManager 的创建和释放的日志
第一步:我们新建一个 UserController 的方法,用来模拟请求两段事务的情况,代码如下所示。
@PostMapping("/user/info")
public UserInfo saveUserInfo(@RequestBody UserInfo userInfo) {UserInfo u2 = userInfoRepository.findById(1L).orElse(null);if (u2!=null) {u2.setLastName("jack"+userInfo.getLastModifiedTime());//更新u2,新开启一个事务userInfoRepository.save(u2);}//更新userInfo,新开启一个事务return userInfoRepository.save(userInfo);
}
可以看到,里面调用了两个 save 操作,没有指定事务。但是我之前讲过,因为 userInfoRepository 的实现类 SimpleJpaRepository 的 save 方法上面有 @Transactional 注解,所以每个 userInfoRepository.save() 方法就会开启新的事务。我们利用这个机制在上面的 Controller 里面模拟了两个事务。
第二步:打开 open-in-view,同时修改一些日志级别,方便我们观察,配置如下述代码所示。
## 打开open-in-view
spring.jpa.open-in-view=true
## 修改日志级别
logging.level.org.springframework.orm.jpa.JpaTransactionManager=trace
logging.level.org.hibernate.internal=trace
logging.level.org.hibernate.engine.transaction.internal=trace
第三步:启动项目,发送如下请求。
#### update
POST /user/info HTTP/1.1
Host: 127.0.0.1:8087
Content-Type: application/json
Cache-Control: no-cache
{"ages":10,"id":3,"version":0}
然后我们查看一下日志,关键日志如下图所示。

可以看到,我们请求了 user/info 之后就开启了 Session,然后在 Controller 方法执行的过程中开启了两段事务,每个事务结束之后都没有关闭 Session,而是等两个事务都结束之后,并且 Controller 方法执行完毕之后,才 Closing Session 的。中间过程只创建了一次 Session。
第四步:其他都不变的前提下,我们把 open-in-view 改成 false,如下面这行代码所示。
spring.jpa.open-in-view=false
我们再执行刚才的请求,会得到如下日志。
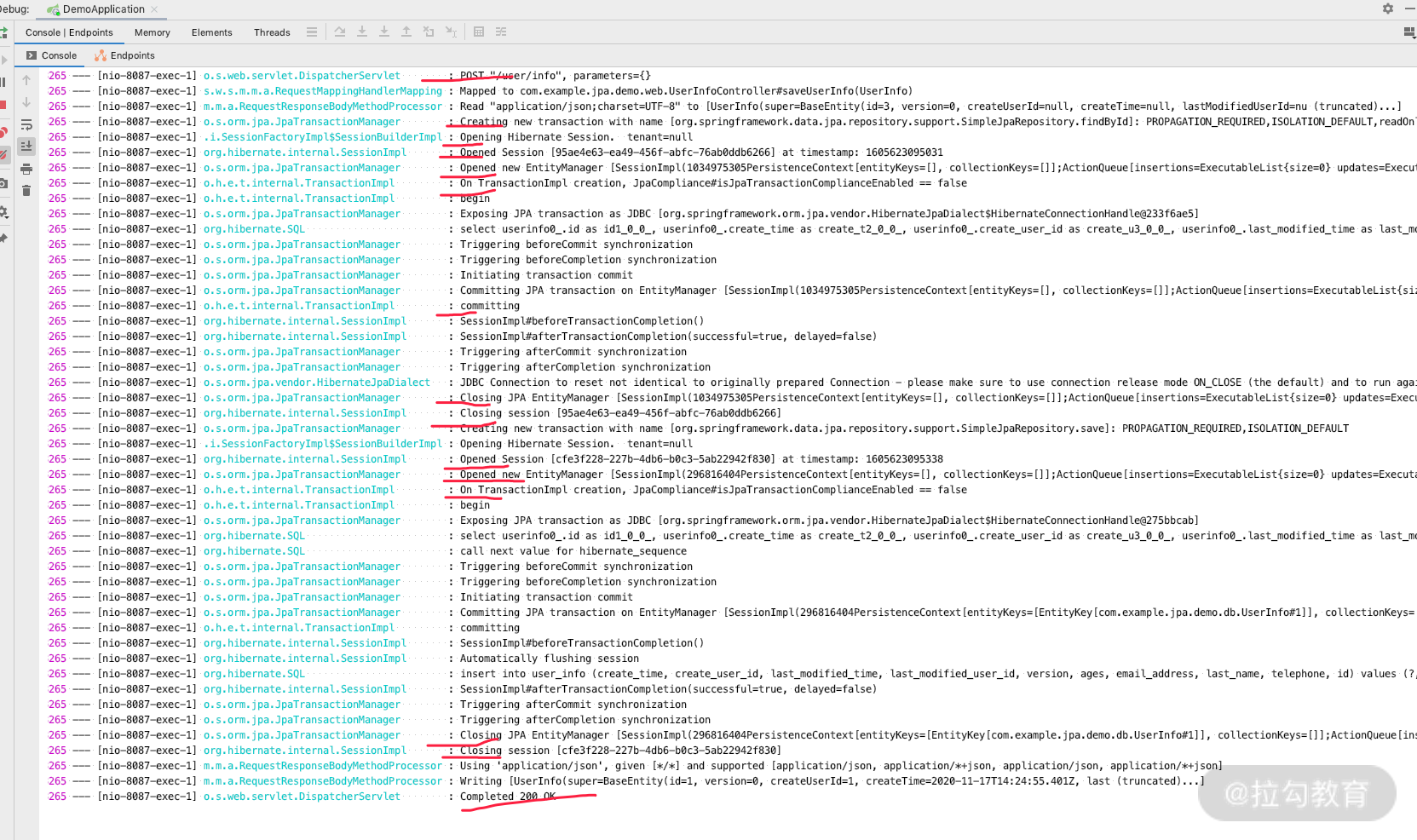
通过日志可以看到,其中开启了两次事务,每个事务创建之后都会创建一个 Session,即开启了两个 Session,每个 Session 的 ID 是不一样的;在每个事务结束之后关闭了 Session,关闭了 EntityManager。
通过上面的事例和日志,我们可以看到 spring.jpa.open-in-view 对 session 和事务的影响,那么它对数据库的连接有什么影响呢?我们看一下 hibernate.connection.handling_mode 这个配置。
hibernate.connection.handling_mode 详解
通过之前讲解的类 AvailableSettings,可以找到如下三个关键配置。
// 指定获得db连接的方式,hibernate5.2之后已经不推荐使用,改用hibernate.connection.handling_mode配置形式
String ACQUIRE_CONNECTIONS = "hibernate.connection.acquisition_mode";
// 释放连接的模式有哪些?hibernate5.2之后也不推荐使用,改用hibernate.connection.handling_mode配置形式
String RELEASE_CONNECTIONS = "hibernate.connection.release_mode";
//指定获取连接和释放连接的模式,hibernate5.2之后新增的配置项,代替上面两个旧的配置
String CONNECTION_HANDLING = "hibernate.connection.handling_mode";
那么 hibernate.connection.handling_mode 对应的配置有哪些呢?Hibernate 5 提供了五种模式,我们详细看一下。
PhysicalConnectionHandlingMode 的五种模式
在 Hibernate 5.2 里面,hibernate.connection.handling_mode 这个 Key 对应的值在 PhysicalConnectionHandlingMode 枚举类里面有定义,核心代码如下所示。
public enum PhysicalConnectionHandlingMode {IMMEDIATE_ACQUISITION_AND_HOLD( IMMEDIATELY, ON_CLOSE ),DELAYED_ACQUISITION_AND_HOLD( AS_NEEDED, ON_CLOSE ),DELAYED_ACQUISITION_AND_RELEASE_AFTER_STATEMENT( AS_NEEDED, AFTER_STATEMENT ),DELAYED_ACQUISITION_AND_RELEASE_BEFORE_TRANSACTION_COMPLETION( AS_NEEDED, BEFORE_TRANSACTION_COMPLETION ),DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION( AS_NEEDED, AFTER_TRANSACTION );private final ConnectionAcquisitionMode acquisitionMode;private final ConnectionReleaseMode releaseMode;PhysicalConnectionHandlingMode(ConnectionAcquisitionMode acquisitionMode,ConnectionReleaseMode releaseMode) {this.acquisitionMode = acquisitionMode;this.releaseMode = releaseMode;}
......//不重要代码先省略}
我们可以看到一共有五组值,也就是把原来的 ConnectionAcquisitionMode 和 ConnectionReleaseMode 分开配置的模式进行了组合配置管理,我们分别了解一下。
IMMEDIATE_ACQUISITION_AND_HOLD:立即获取,一直保持连接到 Session 关闭。 其可以代表如下几层含义:
Session 一旦打开就会获取连接;
Session 关闭的时候释放连接;
如果 open-in-view=true 的时候,也就是说即使我们的请求里面没有做任何操作,或者有一些耗时操作,会导致数据库的连接释放不及时,从而导致 DB 连接不够用,如果请求频繁的话,会产生不必要的 DB 连接的上下文切换,浪费 CPU 性能;
容易产生 DB 连接获取时间过长的现象,从而导致请求响应时间变长。
DELAYED_ACQUISITION_AND_HOLD:延迟获取,一直保持连接到 Session 关闭。 其可以代表如下几层含义:
表示需要的时候再获取连接,需要的时候是指进行 DB 操作的时候,这里主要是指事务打开的时候,就需要获取连接了(因为开启事务的时候要执行“AUTOCOMMIT=0”的操作,所以这里的按需就是指开启事务;我们也可以关闭事务开启的时候改变 AUTOCOMMIT 的行为,那么这个时候的按需就是指执行 DB 操作的时候,不一定开启事务就会获得 DB 的连接);
关闭连接的时机是 Session Colse 的时候;
一个 Session 里面只有一个连接,而一个连接里面可以有多段事务;比较适合一个请求有多段事务的场景;
这个配置解决了,当没有 DB 操作的时候,即没有事务的时候不会获取数据库连接的问题;从而可以减少不必要的 DB 连接切换;
但是一旦一个 Session 在进行了 DB 操作之后,又做了一些耗时的操作才关闭,那么也会导致 DB 连接释放不及时,从而导致 DB 连接的利用率低、高并发的时候请求性能下降。
DELAYED_ACQUISITION_AND_RELEASE_AFTER_STATEMENT:延迟获取,Statement 执行完释放。 其可以代表如下几层含义:
表示等需要的时候再获取连接,不是 session 一打开就会获取连接;
在每个 Statement 的 SQL 执行完就释放连接,一旦有事务每个 SQL 执行完释放满足不了业务逻辑,我们常用的事务模式就不生效了;
这种方式适合没有事务的情景,工作中不常见,可能分布式事务中有场景需要。
DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION:延迟获取,事务执行之后释放。 其可以代表如下几层含义:
表示等需要的时候再获取连接,不是 Session 一打开就会获取连接;
在事务执行完之后释放连接,同一个事务共享一个连接;
这种情况下 open-in-view 的模式对 DB 连接的持有和事务一样了,比较适合一个请求里面事务模块不多请求的情况;
如果事务都控制在 Service 层,这个配置就非常好用,其对 Connection 的利用率比较高,基本上可以做到不浪费;
这个配置不适合一个 Session 生命周期里面有很多独立事务的业务模块,因为这样就会使一个请求里面产生大量没必要的获取连接、释放连接的过程。
DELAYED_ACQUISITION_AND_RELEASE_BEFORE_TRANSACTION_COMPLETION:延迟获取,事务执行之前释放。 其可以代表如下几层含义:
表示等需要的时候再获取连接,不是 Session 一打开就会获取连接;
在事务执行完之前释放连接,这种不保险,也比较少用。
现在你知道了 handling_mode 的五种模式,那么通常会默认用哪一种呢?
默认的模式是哪个?如何修改默认值?
我们打开源码 HibernateJpaVendorAdapter 类里面可以看到如下加载方式。
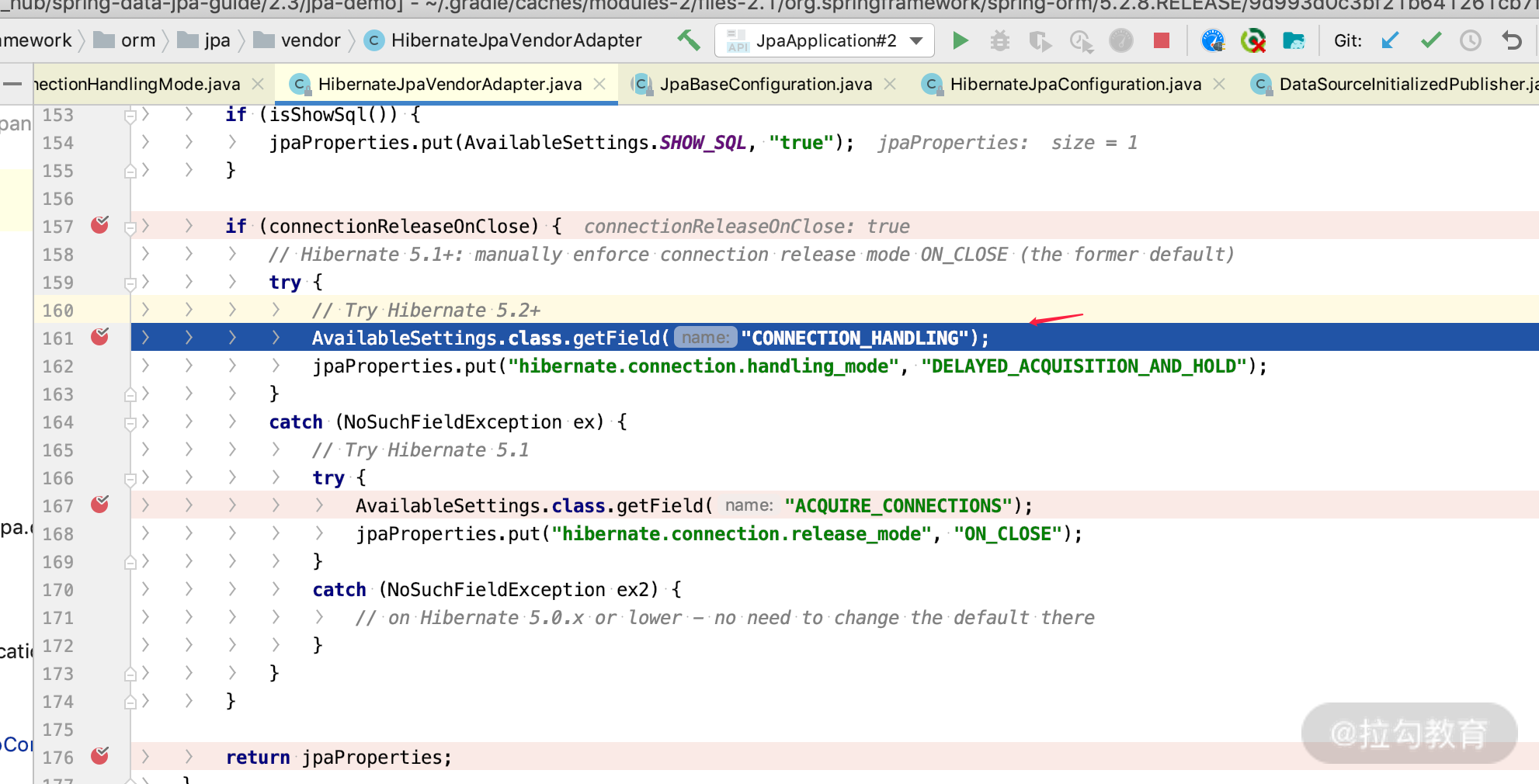
Hibernate 5.2 以上使用的是 DELAYED_ACQUISITION_AND_HOLD 模式,即按需获取、Session 关闭释放,如下面这段代码。
jpaProperties.put("hibernate.connection.handling_mode", "DELAYED_ACQUISITION_AND_HOLD");
而 Hibernate 5.1 以前是通过设置 release_mode 等于 ON_CLOSE 的方式,也是 Session 关闭释放,如下面这段代码。
jpaProperties.put("hibernate.connection.release_mode", "ON_CLOSE");
那么,如何修改默认值呢?直接在 application.properties 文件里面做如下修改即可。
## 我们可以修改成按需获取连接,事务执行完之后释放连接
spring.jpa.properties.hibernate.connection.handling_mode=DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION
说了这么多,我们通过日志来看一下常用的两个配置对数据库连接的影响是什么?
handling_mode 的配置对连接的影响
第一步:验证一下 DELAYED_ACQUISITION_AND_HOLD,即默认情况下,连接池的情况是什么样的?
我们对配置文件做如下配置。
## 在拦截MVC层开启Session,模拟默认情况,这条可以不需要配置,我只是为了给你演示得清晰一点
spring.jpa.open-in-view=true
## 采用默认情况DELAYED_ACQUISITION_AND_HOLD,这条也不需要配置,我只是为了演示得清晰一点
spring.jpa.properties.hibernate.connection.handling_mode=DELAYED_ACQUISITION_AND_HOLD
## 开启hikair的数据库连接池的监控:
logging.level.com.zaxxer.hikari=TRACE
在 UserInfoController 的如下方法里面,通过 Thread.sleep(2 分钟)模拟耗时操作,代码如下。
@PostMapping("/user/info")
public UserInfo saveUserInfo(@RequestBody UserInfo userInfo) throws InterruptedException {UserInfo u2 = userInfoRepository.findById(1L).orElse(null);if (u2!=null) {u2.setLastName("jack"+userInfo.getLastModifiedTime());userInfoRepository.save(u2);System.out.println("模拟事务执行完之后耗时操作........");Thread.sleep(1000*60*2L);System.out.println("耗时操作执行完毕.......");}return userInfoRepository.save(userInfo);
}
项目启动,我们做如下请求。
#### update
POST /user/info HTTP/1.1
Host: 127.0.0.1:8087
Content-Type: application/json
Cache-Control: no-cache
{"ages":10,"id":3,"version":0}
这个时候打开日志控制台,可以看到如下日志。
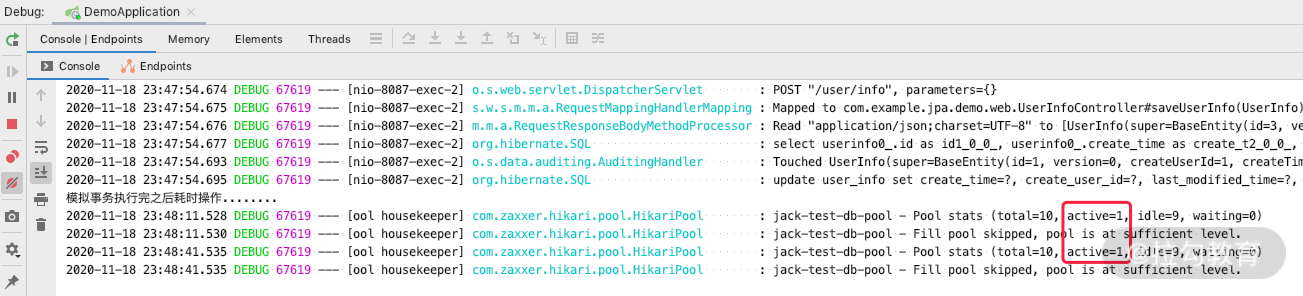
可以看到,我们在 save 之后,即事务提交之后,HikariPool 里面的数据库连接一直没有归还,而如果我们继续等待的话,在整个 Session 关闭之后,数据库连接才会归还到连接池里面。
试想一下,如果我们实际工作中有这样的耗时操作,是不是用不了几个这样的请求,连接池就不够用了?但其实数据库连接没做任何 DB 相关的操作,白白被浪费了。
第二步:验证一下 DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION 模式。
我们只需要对配置文件做如下修改。
spring.jpa.properties.hibernate.connection.handling_mode=DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION
其他代码都不变,我们再请求刚才的 API 请求,这个时候可以得到如下日志。
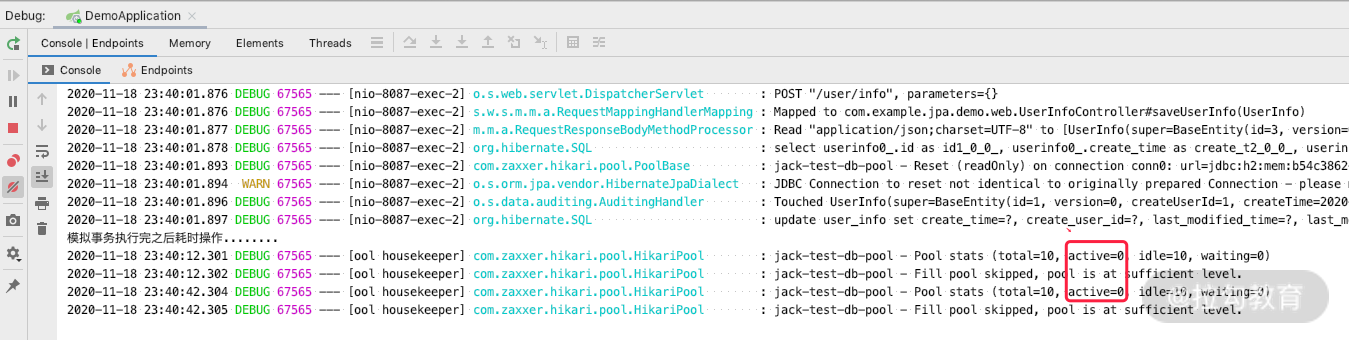
从日志中可以看到,当我们执行完 save(u2),事务提交之后,做一些耗时操作的时候,发现此时整个 Session 生命周期是没有持有数据库连接的,也就是事务结束之后就进行了释放,这样大大提高了数据库连接的利用率,即使大量请求也不会造成数据库连接不够用。
下面是我的一些 Hrkari 数据源连接池下, DB 连接获得的时间参考值。
其中,对连接的池的持有情况如下图所示,这是正常情况,几乎监控不到 DB 连接不够用的情况。

对 DB 连接利用率的监控,如下图所示,连接的 Creation、Acquire 基本上是正常的,但是连接的 Usage>500ms 就有些不正常了,说明里面有一些耗时操作。
![]()

所以,一般在实际工作中,我们会在 DELAYED_ACQUISITION_AND_HOLD 和 DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION 之间做选择;通过日志和监控,我们也可以看得出来 DELAYED_ACQUISITION_AND_HOLD 比较适合一个 Session 里面有大量事务的业务场景,这样不用频繁切换数据库连接。
而 DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION 比较适合日常的 API 业务请求,没有大量的事务,事务结束就释放连接的场景。
下面再结合我们前几讲的基础知识,总结一下 Session 需要关心的关键关系有哪些。
Session、EntityManager、Connection 和 Transaction 的关系
Connection 和 Transaction 的关系
事务是建立在 Connection 之上的,没有连接就没有事务。
以 MySQL InnoDB 为例,新开一个连接默认开启事务,默认每个 SQL 执行完之后自动提交事务。
一个连接里面可以有多次串行的事务段;一个事务只能属于一个 Connection。
事务与事务之间是相互隔离的,那么自然不同连接的不同事务也是隔离的。
EntityManager、Connection 和 Transaction 的关系
EntityManager 里面有 DataSource,当 EntityManager 里面开启事务的时候,先判断当前线程里面是否有数据库连接,如果有直接用。
开启事务之前先开启连接;关闭事务,不一定关闭连接。
开启 EntityManager,不一定立马获得连接;获得连接,不一定立马开启事务。
关闭 EntityManager,一定关闭事务,释放连接;反之不然。
Session、EntityManager、Connection 和 Transaction 的关系
Session 是 EntityManager 的子类,SessionImpl 是 Session 和 EntityManager 的实现类。那么自然 EntityManager 和 Connection、Transaction 的关系同样适用 Session、EntityManager、Connection 和 Transaction 的关系。
Session 的生命周期决定了 EntityManager 的生命周期。
Session 和 Transaction 的关系
在 Hibernate 的 JPA 实现里面,开启 Transaction 之前,必须要先开启 Session。
默认情况下,Session 的生命周期由 open-in-view 决定是请求之前开启,还是事务之前开启。
事务关闭了,Session 不一定关闭。
Session 关闭了,事务一定关闭。
总结
以上就是这一讲的内容了。本讲中我们通过源码分析了 spring.jpa.open-in-view 是什么、干什么用的,以及它对事务、连接池、EntityManager 和 Session 的影响。
到这一讲你应该已经掌握了 Spring Data JPA 的核心的原理里面最重要的五个时机,即 Session(Entity Manager)的 Open 和 Close 时机、数据库连接的获取和释放时机、事务的开启和关闭时机以及我们上一讲介绍的 Persistence Context 的创建和销毁时机、Flush 的触发时机。希望你可以好好掌握并牢记我在其中提到的要点。
那么 open-in-view 对 lazy 的影响是什么呢?我们将在第 24 讲详细介绍。而下一讲我会通过一个实际案例,和你一起通过原理分析一些疑难杂症。
关于每一讲的内容,希望你可以提出一些自己的看法,在下方留言,让志同道合之士一起讨论,共同成长。再见。
23 如何在 CompletableFuture 异步线程中正确使用 JPA?
你好,欢迎学习第 23 讲。通过前几讲对 Session 核心原理的学习,相信你已经可以解决实际工作中的一些疑难杂症了。这一讲我再给你举一个复杂点的例子,继续深度剖析如何利用 Session 原理解决复杂问题。那么,都有哪些问题呢?我们看一个例子。
CompletableFuture 的使用实际案例
在我们的实际开发过程中,难免会用到异步方法,我在这里列举一个异步方法的例子,经典地还原一些在异步方法里面经常会犯的错误。
我们模拟一个 Service 方法,通过异步操作,更新 UserInfo 信息,并且可能一个方法里面有不同的业务逻辑,会多次更新 UserInfo 信息,模拟的代码如下。
@RestController
public class UserInfoController {//异步操作必须要建立线程池,这个不多说了,因为不是本讲的重点,有兴趣的话你可以了解一下线程池的原理,我的Demo采用的是Spring异步框架字段的异步线程池@Autowiredprivate Executor executor;/*** 模拟一个业务service方法,里面有一些异步操作,一些业务方法里面可能修改了两次用户信息* @param name* @return*/@PostMapping("test/async/user")@Transactional // 模拟一个service方法,期待是一个事务public String testSaveUser(String name) {CompletableFuture<Void> cf = CompletableFuture.runAsync(() -> {UserInfo user = userInfoRepository.findById(1L).get();//..... 此处模拟一些业务操作,第一次改变UserInfo里面的值;try {Thread.sleep(200L);// 加上复杂业务耗时200毫秒} catch (InterruptedException e) {e.printStackTrace();}user.setName(RandomUtils.nextInt(1,100000)+ "_first"+name); //模拟一些业务操作,改变了UserInfo里面的值userInfoRepository.save(user);//..... 此处模拟一些业务操作,第二次改变UserInfo里面的值;try {Thread.sleep(300L);// 加上复杂业务耗时300毫秒} catch (InterruptedException e) {e.printStackTrace();}user.setName(RandomUtils.nextInt(1,100000)+ "_second"+name);//模拟一些业务操作,改变了UserInfo里面的值userInfoRepository.save(user);}, executor).exceptionally(throwable -> {throwable.printStackTrace();return null;});//... 实际业务中,可能还有会其他异步方法,我们举这一个例子已经可以说明问题了cf.isDone();return "Success";
}
}
为了便于测试,我们在 UserInfoController 里面模拟了一个复杂点的 Service 方法,上面的代码很多是为了方便给你演示和做测试,实际工作中可能代码会不一样、会演变,但是你通过实质分析,就会发现解决思路是一样的。
我们在 testSaveUser 方法里面开了一个异步线程,异步线程采用 CompletableFuture 方法,在里面执行了两次 UserInfo 的 Save 操作,实际工作中可能不会有像我的 Demo 那么简单的 Save,因为我把中间的业务计算省去了,这不影响我们分析问题。
那么上面的代码问题的表象是什么呢?
表现出来的问题现状是什么样的?
那么实际工作中,我们如果写出来类似的代码,会发生什么样的问题呢?
整个请求非常正常,永远都是 200;也没有任何报错信息,但是发现数据库里面第二次的 save(user) 永远不生效,永远不会出现 name 包含 "_second" 的记录,这个是必现的;
整个请求非常正常,永远都是 200;也没有任何报错信息,有的时候会发现数据库里面没有任何变化,甚至第一次 save(user) 都没有生效,但是这个是偶发的。
实际工作中我们肯定会通过 QA 或者自己多次测试,发现以上现象就会感觉非常奇怪,那么我们来分步拆解一下,看看怎么解决?
步骤拆解
有一定经验的开发者,遇到类似问题,第一步应该想到是不是发生什么异常了?日志信息去哪里了?那么我们需要先看一下 CompletableFuture 的用法,是不是发生异常的时候我们漏掉了什么环节?
CompletableFuture 使用最佳实践
CompletableFuture 主要的功能是实现了 Future 和 CompletionStage 的接口,主要的方法如下述代码所示。
//通过给定的线程池,异步执行 Runnable方法,不带返回结果
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
//通过给定的线程池,异步执行Runnable方法,带返回结果
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
//当上面的异步方法执行完之后需要执行的回调方法
public CompletableFuture<Void> thenAccept(Consumer<? super T> action)
//阻塞等待 future执行完结果
boolean isDone();
//阻塞获取结果
V get();
//当异步操作发生异常的时候执行的方法
public CompletionStage<T> exceptionally(Function<Throwable, ? extends T> fn);
以上我只是列举了一些和我们案例相关的关键方法,而 CompletableFuture 还有更多的方法,其功能也非常强大,所以一般开发过程中用此类的场景还非常多。
其实上面的 Demo 只是利用 runAsync 做了异步操作,并利用 isDone 做了阻塞等待的动作,而没有使用 Exceptionally 处理异常信息。
所以如果我们想打印异常信息,基本上可以利用 Exceptionally。我们改进一下 Demo 代码,把异常信息打印一下,看看是否发生了异常。变动的代码如下所示。
CompletableFuture<Void> cf = CompletableFuture.runAsync(() -> {......这里的代码不变,我们不做copy了
}, executor).exceptionally(e -> {log.error(e);//把异常信息打印出来return null;
});
那么我们再请求上面的 Controller 方法的时候,发现控制台就会打印出如下所示的 Error 信息。
java.util.concurrent.CompletionException: org.springframework.orm.ObjectOptimisticLockingFailureException: Object of class [com.example.jpa.demo.db.UserInfo] with identifier [1]: optimistic locking failed; nested exception is org.hibernate.StaleObjectStateException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect) : [com.example.jpa.demo.db.UserInfo#1]at java.base/java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:314)at java.base/java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:319)at java.base/java.util.concurrent.CompletableFuture$AsyncRun.run$$$capture(CompletableFuture.java:1739)at java.base/java.util.concurrent.CompletableFuture$AsyncRun.run(CompletableFuture.java)at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167)at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)at java.base/java.lang.Thread.run(Thread.java:844)
Caused by: org.springframework.orm.ObjectOptimisticLockingFailureException: Object of class [com.example.jpa.demo.db.UserInfo] with identifier [1]: optimistic locking failed; nested exception is org.hibernate.StaleObjectStateException: Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect) : [com.example.jpa.demo.db.UserInfo#1]at org.springframework.orm.jpa.vendor.HibernateJpaDialect.convertHibernateAccessException(HibernateJpaDialect.java:337)at org.springframework.orm.jpa.vendor.HibernateJpaDialect.translateExceptionIfPossible(HibernateJpaDialect.java:255)at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:212)at com.sun.proxy.$Proxy116.save(Unknown Source)at com.example.jpa.demo.web.UserInfoController.lambda$testSaveUser$0(UserInfoController.java:57)at java.base/java.util.concurrent.CompletableFuture$AsyncRun.run$$$capture(CompletableFuture.java:1736)... 4 more
通过报错信息,可以发现其实就是发生了乐观锁异常,导致上面实例中的第二次 save(user) 必然失败;而第一次 save(user) 的失败,主要是因为在并发的情况下有其他请求线程改变了 UserInfo 的值,也就是改变了 Version。
我们来看一下完整的 UserInfo 对象实体。
@Entity
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@ToString(callSuper = true)
@Table
@EntityListeners({AuditingEntityListener.class})
public class UserInfo{@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;@Versionprivate Integer version;@CreatedByprivate Integer createUserId;@CreatedDateprivate Instant createTime;@LastModifiedByprivate Integer lastModifiedUserId;@LastModifiedDateprivate Instant lastModifiedTime;private String name;private Integer ages;private String lastName;private String emailAddress;private String telephone;
}
看过前面课时的同学应该知道,我们通过 @Version 乐关锁机制就是防止数据被覆盖;而实际生产过程中其实很难发现类似问题。
所以当我们使用任何的异步线程处理框架的时候,一定要想好异常情况下怎么打印日志,否则就像黑洞一样,完全不知道发生了什么。
那么既然知道发生了乐观锁异常,这里就有个疑问了:我们不是在 UserInfoController 的 testSaveUser 方法上面加了 @Transaction 的注解了吗?为什么事务没有回滚?
通过日志查看事务的执行过程
我们看看异步请求的情况下,事务应该怎么做呢?先打开事务的日志,看看上面方法的事务执行过程是什么样的。
## 我们在db的连接中开启logger=Slf4JLogger&profileSQL=true看一下每个事务里执行的sql有哪些
spring.datasource.url=jdbc:mysql://localhost:3306/test?logger=Slf4JLogger&profileSQL=true
## 打开下面这些类的日志级别,观察一下事务的开启和关闭时机
logging.level.org.springframework.orm.jpa=DEBUG
logging.level.org.springframework.transaction=DEBUG
logging.level.org.springframework.orm.jpa.JpaTransactionManager=trace
logging.level.org.hibernate.engine.transaction.internal.TransactionImpl=DEBUG
再请求一下刚才的测试接口:POSThttp://127.0.0.1:8087/test/async/user?name=jack就会产生下图所示的日志。
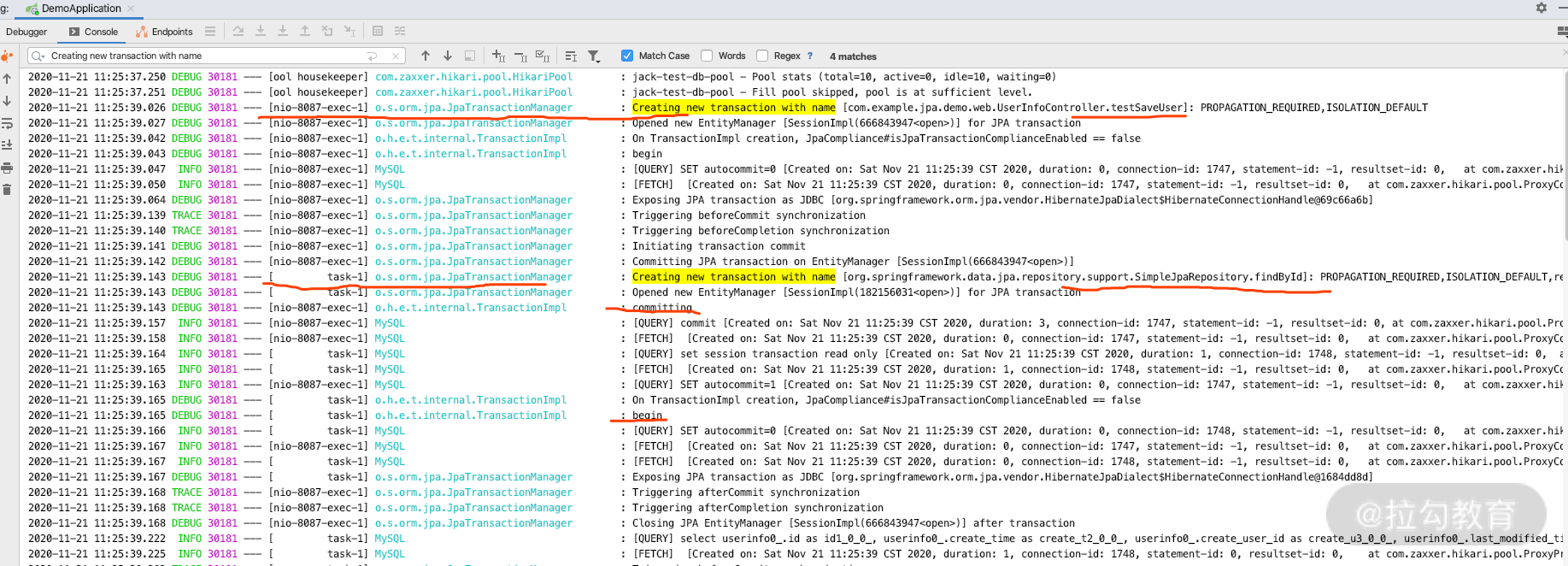
先看一下上半部分,通过日志我们可以看到,首先执行这个方法的时候开启了两个事务,分别做如下解释。
线程 1:[nio-8087-exec-1] 开启了 UserInfoController.testSaveUser 方法上面的事务,也就是 http 的请求线程,开启了一个 Controller 请求事务。这是因为我们在 testSaveUser 的方法上面加了 @Transaction 的注解,所以开启了一个事务。
而通过日志我们也可以发现,事务 1 里面什么都没有做,随后就进行了 Commit 操作,所以我们可以看得出来,默认不做任何处理的情况下,事务是不能跨线程的。每个线程里面的事务相互隔离、互不影响。
线程 2:[ task-1],通过异步线程池开启了 SimpleJpaRepository.findById 方法上面的只读事务。这是因为默认的 SimpleJpaRepository 类上面加了 @Transaction(readOnly=true) 产生的结果。而我们通过 MySQL 的日志也可以看得出来,此次事务里面只做了和我们代码相关的 select user_info 的操作。
我们再看一下后半部分的日志,如图所示。
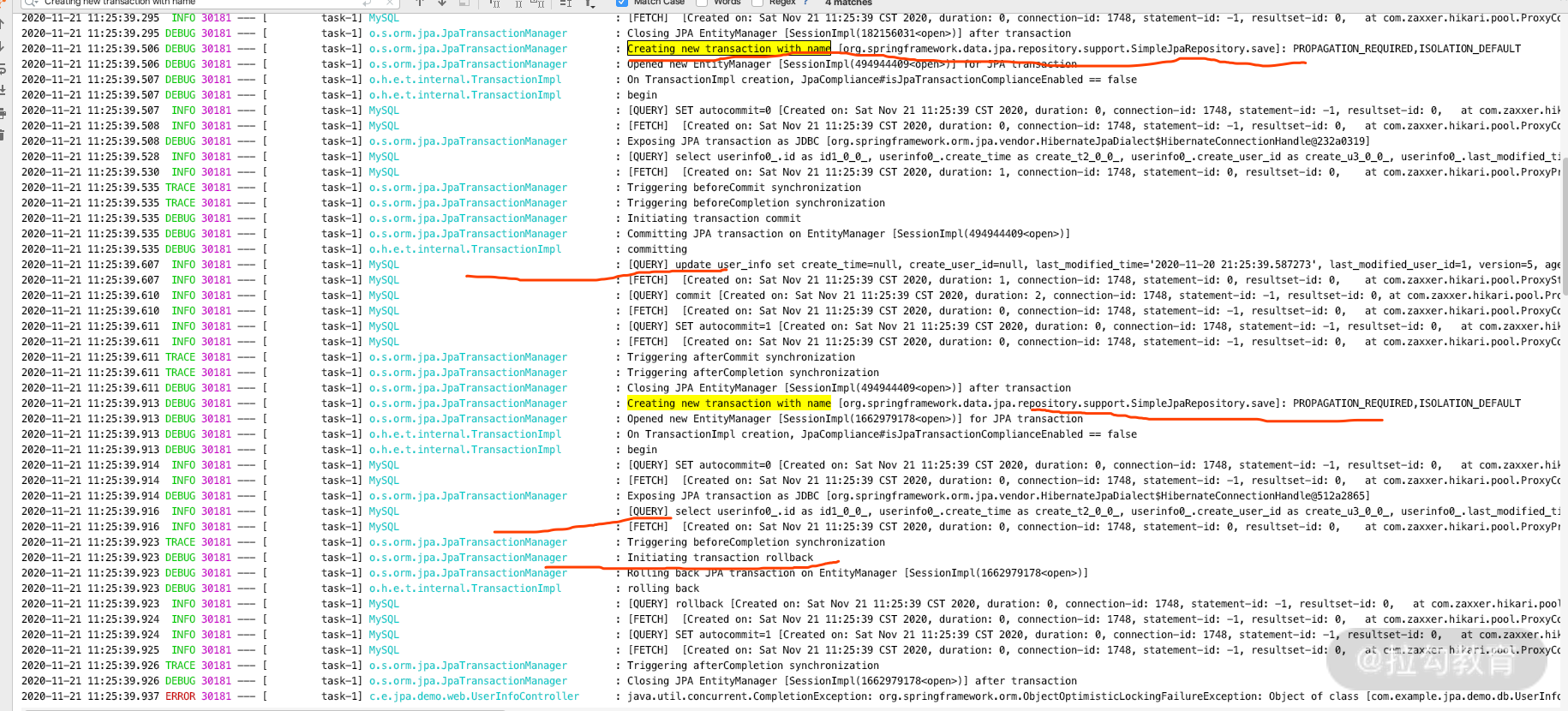
通过后半部分日志,我们可以看到两次 save(user) 方法,也分别开启了各自的事务,这是因为 SimpleJpaRepository.save 方法上面有 @Transaction 注解起了作用,而第二次事务因为 JPA 的实现方法判断了数据库这条数据的 Version 和我们 UserInfo 的对象中的 Version 不一致,从而第二次进行了回滚操作。
两次 save(user) 的操作里面分别有一次 Select 和 Update 语义,正是我们之前所说的 Save 方法的原理。两次事务,分别开启了两个 Session,所以对象对于这两次 Session 来说分别是从游离态(Detached)转成持久态(Persistent)的过程,所以两个独立的事务里面,一次 Select,一次 Update。
通过日志可以看到,上面一个简单的方法中一共发生了四次事务,都是采用的默认隔离级别和传播机制。那么如果我们想让异步方法里面只有一个事务应该怎么办呢?
异步事务的正确使用方法
既然我们知道异步方法里面的事务是独立的,那么直接把异步的代码块用独立的事务包装起来即可,做法有如下几种。
第一种处理方法:把其中的异步代码块,移到一个外部类里面。我们这里放到 UserInfoService 中,同时方法中加上 @Transaction 注解用来开启事务,加上 @Retryable 注解进行乐观锁重试,代码如下。
//加上事务,这样可以做到原子性,解决事务加到异常方法之外没有任何作用的问题
@Transactional
//加上重试机制,这样当我们发生乐观锁异常的时候,重新尝试下面的逻辑,减少请求的失败次数
@Retryable(value = ObjectOptimisticLockingFailureException.class,backoff = @Backoff(multiplier = 1.5,random = true))
public void businessUserMethod(String name) {UserInfo user = userInfoRepository.findById(1L).get();//..... 此处模拟一些业务操作,第一次改变UserInfo里面的值;try {Thread.sleep(200L);// 加上复杂业务耗时200毫秒} catch (InterruptedException e) {e.printStackTrace();}user.setName(RandomUtils.nextInt(1,100000)+ "_first"+name); //模拟一些业务操作,改变了UserInfo里面的值userInfoRepository.save(user);//..... 此处模拟一些业务操作,第二次改变UserInfo里面的值;try {Thread.sleep(300L);// 加上复杂业务耗时300毫秒} catch (InterruptedException e) {e.printStackTrace();}user.setName(RandomUtils.nextInt(1,100000)+ "_second"+name);//模拟一些业务操作,改变了UserInfo里面的值userInfoRepository.save(user);
}
那么 Controller 里面只需要变成如下写法即可。
/*** 模拟一个业务service方法,里面有一些异步操作,一些业务方法里面可能修改了两次用户信息* @param name* @return*/
@PostMapping("test/async/user")
@Transactional // 模拟一个service方法,期待是一个事务
public String testSaveUser(String name) {CompletableFuture<Void> cf = CompletableFuture.runAsync(() -> {userInfoService.businessUserMethod(name);}, executor).exceptionally(e -> {log.error(e);//把异常信息打印出来return null;});//... 实际业务中,可能还有会其他异步方法,我们举这个例子已经可以说明问题了cf.isDone();return "Success";
}
我们再次发起一下请求,看一下日志。
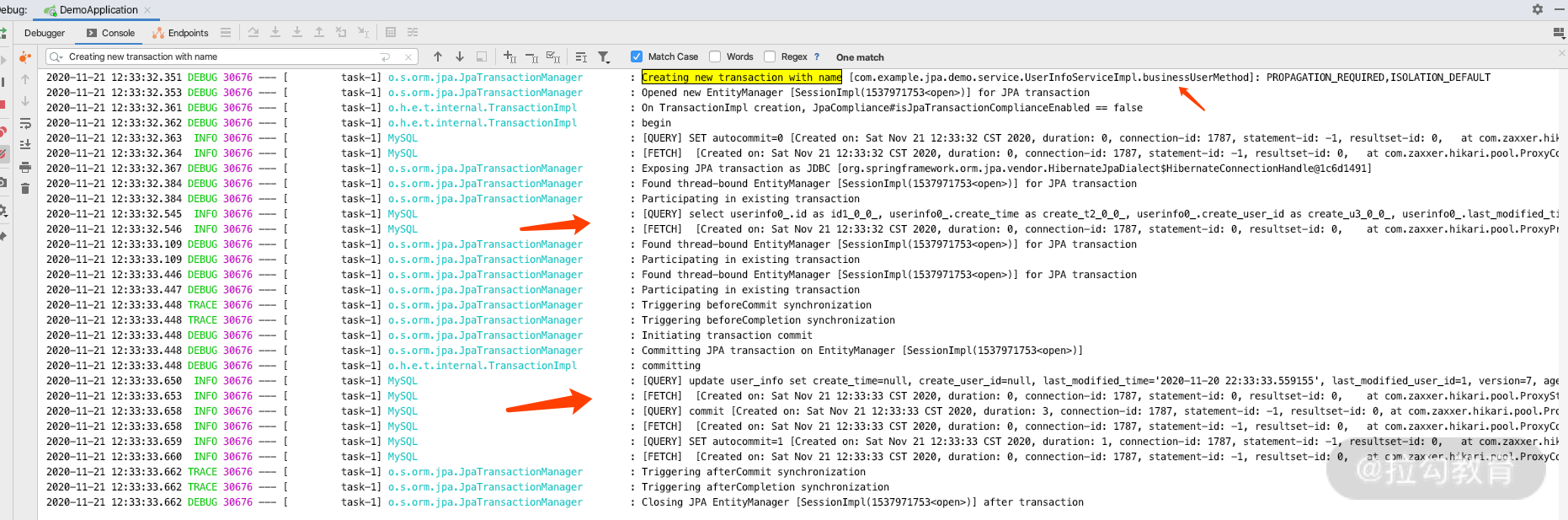
通过上图的日志,我们可以知道两个重要信息:
这个时候只有 UserInfoServiceImpl.businessUserMethod 开启了一个事务,这是因为 findById 和 Save 方法中,事务的传播机制都是“如果存在事务就利用当前事务”的原理,所以就不会像我们上面一样创建四次事务了;
而此时两次 save(user) 只产生了一个 update 的 sql 语句,并且也很难出现乐观锁异常了,因为这是 Session 的机制,将两次对 UserInfo 实体的操作进行了合并;所以当我们使用 JPA 的时候某种程度上也会降低 db 的压力,增加代码的执行性能。
而另外一个侧论,就是当事务的生命周期执行越快的时候,发生异常的概率就会越低,因为可以减少并发处理的机会。
第二种处理方法:可以利用“19 | 如何搞清楚事务、连接池的关系?正确配置是怎样的?”讲过的 TransactionTemplate 方法开启事务,这里不再重复讲述了。
第三种处理方法:我们可以建一个自己的 TransanctionHelper,并带上重试机制,代码如下:
/*** 利用spring进行管理*/
@Component
public class TransactionHelper {/*** 利用spring 机制和jdk8的Consumer机制实现只消费的事务*/@Transactional(rollbackFor = Exception.class) //可以根据实际业务情况,指定明确的回滚异常@Retryable(value = ObjectOptimisticLockingFailureException.class,backoff = @Backoff(multiplier = 1.5,random = true))public void transactional(Consumer consumer,Object o) {consumer.accept(o);}
}
那么 Controller 里面的写法可以变成如下方式,也可以达到同样效果。
@PostMapping("test/async/user")
public String testSaveUser(String name) {CompletableFuture<Void> cf = CompletableFuture.runAsync(() -> {transactionHelper.transactional((param)->{ // 通过lambda实现事务管理UserInfo user = userInfoRepository.findById(1L).get();//..... 此处模拟一些业务操作,第一次改变UserInfo里面的值;try {Thread.sleep(200L);// 加上复杂业务耗时200毫秒} catch (InterruptedException e) {e.printStackTrace();}user.setName(RandomUtils.nextInt(1,100000)+ "_first"+name); //模拟一些业务操作,改变了UserInfo里面的值userInfoRepository.save(user);//..... 此处模拟一些业务操作,第二次改变UserInfo里面的值;try {Thread.sleep(300L);// 加上复杂业务耗时300毫秒} catch (InterruptedException e) {e.printStackTrace();}user.setName(RandomUtils.nextInt(1,100000)+ "_second"+name);//模拟一些业务操作,改变了UserInfo里面的值userInfoRepository.save(user);},name);}, executor).exceptionally(e -> {log.error(e);//把异常信息打印出来return null;});//... 实际业务中,可能还有会其他异步方法,我们举一个例子已经可以说明问题了cf.isDone();return "Success";
}
这种方式主要是通过 Lambda 表达式解决事务问题。
总之,不管是以上哪种方法,都可以解决我们所说的异步事务的问题。所以搞清楚事务的背后实现逻辑,就很容易解决类似问题了。
还有一个问题就是,为什么当异步方法中是同一个事务的时候,第二次 save(user) 就成功了?而异步代码块里面的两个 save(user) 分别在两个事务里面,第二次就不成功了呢?我们利用前两个课时讲过的 Persistence Context 和实体的状态来分析一下。
Session 的机制与 Repository.save(entity) 是什么关系?
我们在学习 Persistence Context 的时候,知道 Entity 有不同的状态。
在一个 Session 里面,如果我们通过 findById(id) 得到一个 Entity,它就会变成 Manager(persist) 持久态。那么同一个 Session 里面,同一个 Entity 多次操作 Hibernate 就会进行 Merge 操作。
所以上面的实例中,当我们在 businessUserMethod 方法上面加 @Transaction 的时候,会造成异步代码的整块逻辑处于同一个事务里面,而按照我们上一讲介绍的 Session 原理,同一个事务就会共享同一个 Session,所以同一个事务里面的 findById、save、save 的多次操作都是同一个实例。
什么意思呢?我们可以通过设置 Debug 断点,查看一下对象的内存对象地址是否一样,就可以看得出来。如下图所示,findById 之后和两次 save 之后都是同一个对象。
![]()

而如果我们跨 Session 传递实体对象,那么在一个 Session 里面持久态的对象,对于另外一个 Session 来说就是一个Detached(游离态)的对象。
而根据 Session 里面的 Persistenc Context 的原理,一旦这个游离态的对象进行 db 操作,Session 会 Copy 一个新的实体对象。也就是说,当我们不在异步代码中加事务的时候,即去掉异步代码块businessUserMethod 方法中的@Transaction 注解,findById 之后就会产生一个新的事务、新的 Session,那么返回的就是对象 1;第一次 Save 之后,由于又是一个新的事务、新的 Session,那么返回的实体 u2 就是对象 2。
我们知道这个原理之后,对代码做如下改动。
// @Transactional 去掉事务public void businessUserMethod(String name) {UserInfo user = userInfoRepository.findById(1L).get();user.setName(RandomUtils.nextInt(1,100000)+ "_first"+name); //模拟一些业务操作,改变了UserInfo里面的值UserInfo u2 = userInfoRepository.save(user);user.setName(RandomUtils.nextInt(1,100000)+ "_second"+name); //模拟一些业务操作,改变了UserInfo里面的值UserInfo u3 = userInfoRepository.save(u2);// 第二次save采用第一次save的返回结果,这样里面带有了最新的version的值,所以也就会保存成功
}
异步里面调用这个方法也是成功的,因为乐观锁的原理是 Version 变了,我们用最新的对象,也就是最新的 Version 就可以了。
我们设置一个断点看一下 user、u2、u3 在不同的 Session 作用域之后,就变成不同的实例了,如下所示。

问题分析完了,那么这些内容带给我们哪些思考呢?
思考
在上面 Demo 中的异步场景下设置 open-in-view 等于 true / false,会对上面的测试结果有影响吗?
答案是肯定没有影响的,spring.jpa.open-in-view 的本质还是开启 Session,而保持住 Session 的本质还是利用 ThreadLocal,也就是必须为同一个线程的情况下才适用。所以异步场景不受 spring.jpa.open-in-view 控制。
如果是大量的异步操作 db connection 的持有模式,应该配置成哪一种比较合适?
答案是DELAYED_ACQUISITION_AND_RELEASE_AFTER_TRANSACTION,因为这样可以做到对 db 连接最大的利用率。用的时候就获取,事务提交完就释放,这样就不用关心业务逻辑执行多长时间了。
总结
上面的例子折射出来的是一些 JPA 初学者最容易犯的错误,我们通过前几讲对原理知识的学习,解决了工作中最常见、最容易犯错的,如异步问题和事务问题。其中关键的几个问题你一定要好好思考,尤其是在开发业务代码的时候。
我们的一个请求,开启了几次事务?在什么时机开始的?
我们的一个请求,开启了几次 Session?在什么时机开启的?
事务和 Session 分别会对实体的状态有什么影响?
上面的几个问题是对一个高级 Java 工程师最基础的要求,如果你想晋级资深开发工程师,还需要知道:
我们的一个请求,对 db 连接池里面的连接持有时间是多久?
我们的一个请求,性能指标都有哪些决定因素?
针对以上问题,你可以回过头去文中找答案,并且希望你深入钻研,遇到问题做到心中有数。
本讲内容就到这里了,下一讲我们来聊聊 Lazy 的核心原理和问题。欢迎你对本讲内容提出问题和建议,如果本专栏对你有帮助,就动动手指分享吧。我们下一讲再见。
24 为什么总会遇到 Lazy Exception?如何解决?
你好,欢迎学习第 24 讲。在我们的实际工作中,经常会遇到 Lazy Exception,所谓的 Lazy Exception 具体一点就是 LazyInitializationException。我经常看到有些同事会遇到这一问题,而他们的处理方式都很复杂,并非最佳实践。那么这一讲,我们就来剖析一下这一概念的原理以及解决方式。
我们先从一个案例入手,看一下什么是 LazyInitializationException。
什么是 LazyInitializationException 异常?
这是一个重现 Lazy 异常的例子,下面我将通过 4 个步骤带你一起看一下什么是 Lazy 异常。
第一步:为了方便我们测试,我们把 spring.jpa.open-in-view 设置成 false,代码如下。
spring.jpa.open-in-view=false
第二步:新建一个一对多的关联实体:UserInfo 用户信息,一个用户有多个地址 Address。代码如下所示。
@Entity
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@Table
public class UserInfo extends BaseEntity {private String name;private Integer ages;private String lastName;private String emailAddress;private String telephone;//假设一个用户有多个地址,取数据的方式用lazy的模式(默认也是lazy的);采用CascadeType.PERSIST方便插入演示数据;@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.LAZY)private List<Address> addressList;
}
@Entity
@Table
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
public class Address extends BaseEntity {private String city;//维护关联关系的一方,默认都是lazy模式@ManyToOneprivate UserInfo userInfo;
}
第三步:我们再新建一个 Controller,取用户的基本信息,并且查看一下 Address 的地址信息,代码如下。
@GetMapping("/user/info/{id}")
public UserInfo getUserInfoFromPath(@PathVariable("id") Long id) {UserInfo u1 = userInfoRepository.findById(id).get();//触发lazy加载,取userInfo里面的地址信息System.out.println(u1.getAddressList().get(0).getCity());return u1;
}
第四步:启动项目,我们直接发起如下请求。
### get user info的接口
GET /user/info/1 HTTP/1.1
Host: 127.0.0.1:8087
Content-Type: application/json
Cache-Control: no-cache
然后我们就可以如期得到 Lazy 异常,如下述代码所示。
org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: com.example.jpa.demo.db.UserInfo.addressList, could not initialize proxy - no Sessionat org.hibernate.collection.internal.AbstractPersistentCollection.throwLazyInitializationException(AbstractPersistentCollection.java:606) ~[hibernate-core-5.4.20.Final.jar:5.4.20.Final]at org.hibernate.collection.internal.AbstractPersistentCollection.withTemporarySessionIfNeeded(AbstractPersistentCollection.java:218) ~[hibernate-core-5.4.20.Final.jar:5.4.20.Final]at org.hibernate.collection.internal.AbstractPersistentCollection.initialize(AbstractPersistentCollection.java:585) ~[hibernate-core-5.4.20.Final.jar:5.4.20.Final]at org.hibernate.collection.internal.AbstractPersistentCollection.read(AbstractPersistentCollection.java:149) ~[hibernate-core-5.4.20.Final.jar:5.4.20.Final]at org.hibernate.collection.internal.PersistentBag.get(PersistentBag.java:561) ~[hibernate-core-5.4.20.Final.jar:5.4.20.Final]at com.example.jpa.demo.web.UserInfoController.getUserInfoFromPath(UserInfoController.java:29) ~[main/:na]
通过上面的异常信息基本可以看到,我们的 UserInfo 实体对象加载 Address 的时候,产生了 Lazy 异常,是因为 no session。那么发生异常的根本原因是什么呢?它的加载原理是什么样的?我们接着分析。
Lazy 加载机制的原理分析
我们都知道 JPA 里有 Lazy 的机制,所谓的 Lazy 就是指,当我们使用关联关系的时候,只有用到被关联关系的一方才会请求数据库去加载数据,也就是说关联关系的真实数据不是立马加载的,只有用到的时候才会加载。
而 Hibernate 的实现机制中提供了 PersistentCollection 的机制,利用代理机制改变了关联关系的集合类型,从而实现了懒加载机制,我们详细看一下。
PersistentCollection 集合类
PersistentCollection 是一个集合类的接口,实现类包括如下几种,如下图所示。
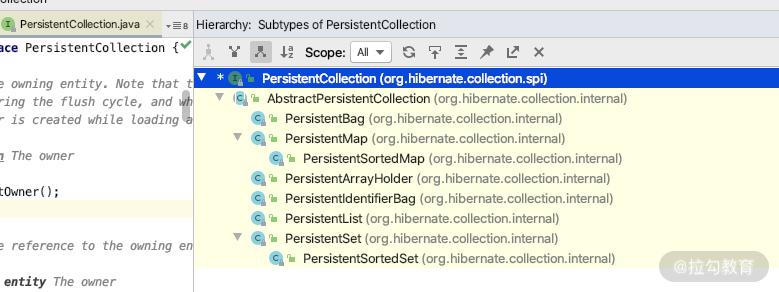
也就是说 Hibernate 通过 PersistentCollection 的实现类 AbstractPersistentCollection 的所有子类,对 JDK 里面提供的 List、Map、SortMap、Array、Set、SortedSet 进行了扩展,从而实现了具有懒加载的特性。所以在 Hibernate 里面支持的关联关系的类型只有下面五种。
java.util.Listjava.util.Setjava.util.Mapjava.util.SortedSetjava.util.SortedMap
关于这几种类型,Hibernate 官方也提供了扩展 AbstractPersistentCollection 的方法,不是本讲的重点,我就不多介绍了。
下面我们以 PersistentBag 为例,介绍一下 Lazy 原理的关键之处。
PersistentBag 为例详解原理
通过 PersistentBag 的关键源码,我们来看一下集合类 List 是怎么实现的,代码如下所示。
//PersistentBag继承AbstractPersistentCollection,从而继承了PersistenceCollection的一些公共功能、session的持有、lazy的特性、entity的状态转化等功能;同时PersistentBag也实现了java.util.List的所有方法,即对List进行读写的时候包装lazy逻辑
public class PersistentBag extends AbstractPersistentCollection implements List {//PersistentBag构造方法,当初始化实体对象对集合初始化的时候,把当前的Session保持住public PersistentBag(SessionImplementor session) {this( (SharedSessionContractImplementor) session );}// 从这个方法可以看出来其对List和ArrayList的支持@SuppressWarnings("unchecked")public PersistentBag(SharedSessionContractImplementor session, Collection coll) {super( session );providedCollection = coll;if ( coll instanceof List ) {bag = (List) coll;}else {bag = new ArrayList( coll );}setInitialized();setDirectlyAccessible( true );}//以下是一些关键的List的实现方法,基本上都是在原有的List功能的基础上增加调用父类AbstractPersistentCollection里面的read()和write()方法@Override@SuppressWarnings("unchecked")public Object remove(int i) {write();return bag.remove( i );}@Override@SuppressWarnings("unchecked")public Object set(int i, Object o) {write();return bag.set( i, o );}@Override@SuppressWarnings("unchecked")public List subList(int start, int end) {read();return new ListProxy( bag.subList( start, end ) );}@Overridepublic boolean entryExists(Object entry, int i) {return entry != null;}// toString被调用的时候会触发read()@Overridepublic String toString() {read();return bag.toString();}.....//其他方法类似,就不一一举例了
}
那么我们再看一下 AbstractPersistentCollection 的关键实现,在 AbstractPersistentCollection 中会有大量通过 Session 来初始化关联关系的方法,这些方法基本是利用当前 Session 和当前 Session 中持有的 Connection 来重新操作 DB,从而取到数据库里面的数据。
所以我们发生的 LazyInitializationExcetion 基本都是从这个类里面抛出来的,从源码里面可以看到其严重依赖当前的 Session,关键源码如下图所示。
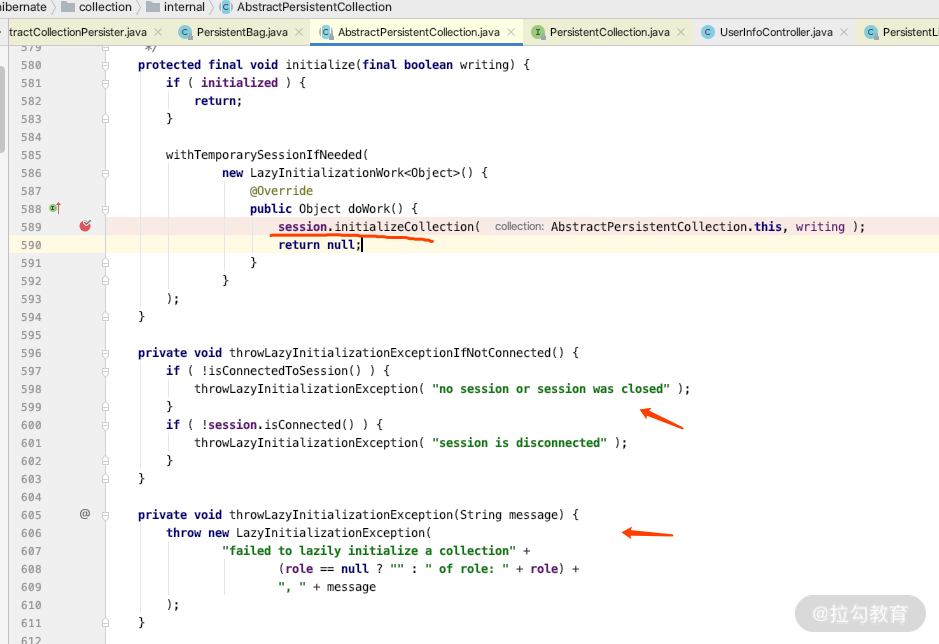
所以在默认的情况下,如果我们把 Session 关闭了,想利用 Lazy 的机制加载管理关系,就会发生异常了。我们通过实例看一下,在上面例子的 Controller 上加一个 debug 断点,可以看到如下图显示的内容:我们的 Address 指向了 PersistentBag 代理实例类。
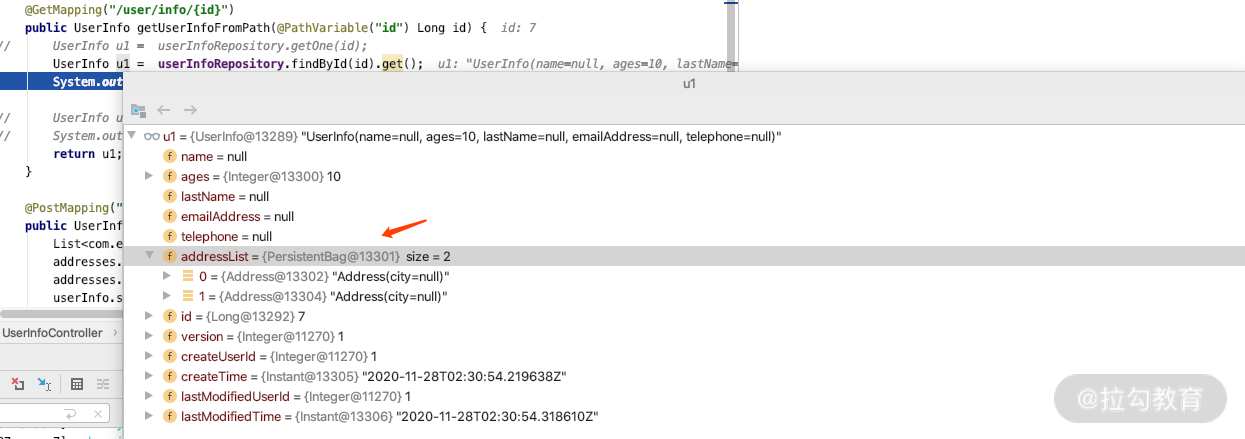
同时我们再设置断点的话也可以看到,PersistentBag 被初始化的时候,会传进来 Session 的上下文,即包含 Datasource 和需要执行 Lazy 的 sql。
而需要执行 Lazy 的 sql,我们通过 debug 的栈信息可以看到其中有个 instantiate,有兴趣的同学可以 debug 看一下,关键断点信息如下图所示。
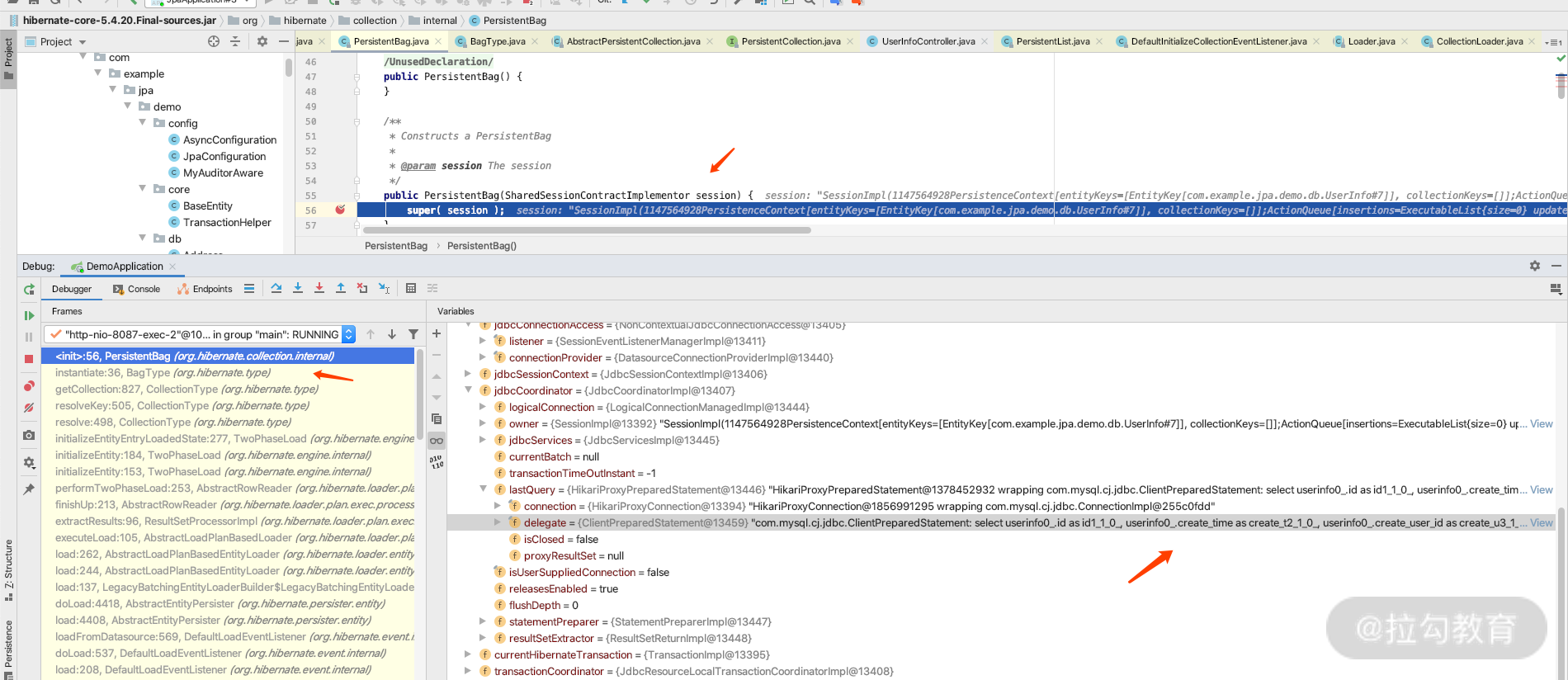
再继续 debug 的话,也会看到调用 AbstractPersistentCollection 的初始化 Lazy 的方法,如下所示。
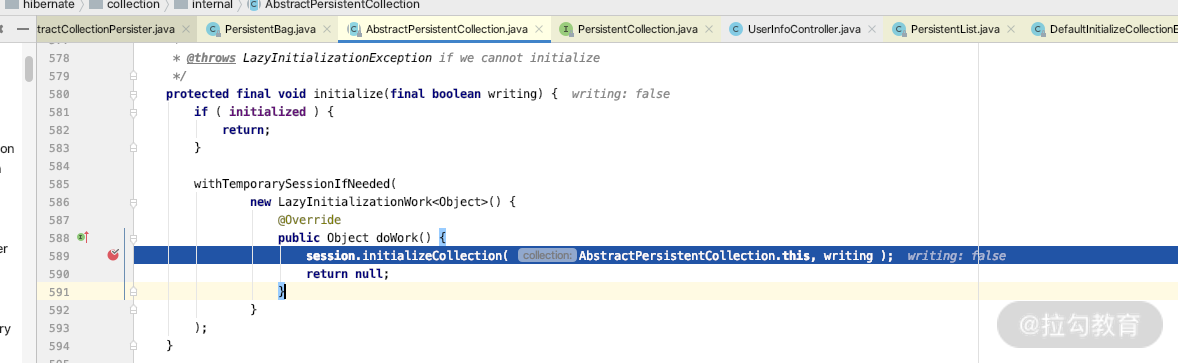
通过源码分析和实例讲解,你已经基本上知道了 Lazy 的原理,也就是需要 Lazy 的关联关系会初始化成 PersistentCollection,并且依赖持有的 Session。而当操作 List、Map 等集合类的一些基本方法的时候会触发 read(),并利用当前的 Session 进行懒加载。
那么在实际工作中,哪些场景可能会产生 Lazy 异常呢?
Lazy 异常的常见场景与解决方法
场景一:跨事务,事务之外的场景
我们在前面的课时讲过 Session 和事务之间的关系,当 spring.jpa.open-in-view=false 的时候,每个事务就会独立持有 Session;那么当我们在事务之外操作 lazy 的关联关系的时候,就容易发生 Lazy 异常。
正如上面列举的 Demo 一样,一开始我就将 open-in-view 设置成了 false,而 userInfoRepository.findById(id) 又是一个独立事务,方法操作结束之后事务结束,事务结束之后 session close。所以当我们再操作 UserInfo 中 Address 对象的时候,就发生了 Lazy 异常。
实际工作中这种情况比较多见,应该如何解决呢?
第一种方式:简单粗暴地设置为 spring.jpa.open-in-view=true
通过上面的分析,我们可以知道无非就是 Session 的关闭导致了 Lazy 异常,所以简单粗暴的办法就是加大 Session 的生命周期,将 Session 的生命周期和请求的生命周期设置成一样。但是 open-in-view 可能会带来的副作用你必须要牢记于心,有以下几点。
它对 Connection 的影响是什么?连接池有没有很好地监控?利用率是怎么样的?
实体的状态在整个 Session 的生命周期之间的变更都是有效的,数据的更新是不是预期的,你要心里有数。
N+1 的 SQL 是不是我们期望的?(这个下一讲我会详细介绍)性能有没有影响?等等。
第二种方式:也是简单粗暴改成 Eager 模式
我们直接采用 Eager 的模式,这样也不会有 Lazy 异常的问题。如下述代码所示。
public class UserInfo extends BaseEntity {private String name;//直接采用eager模式@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)private List<Address> addressList;
但是这种做法我不推荐你使用,因为本来我不想查 Address 信息,这样会白白地触发对 Address 的查询,导致性能有点浪费。
第三种方式:将可能发生 Lazy 的操作和取数据放在同一个事务里面
这种方式怎么理解呢?我们改造一下上面 Demo 的 Controller 的写法,代码如下所示。
@RestController
@Log4j2
public class UserInfoController {@Autowiredprivate UserInfoService userInfoService;@GetMapping("/user/info/{id}")public UserInfo getUserInfoFromPath(@PathVariable("id") Long id) {//controller里面改调用service方法,这个service明确地返回了UserInfo和Address信息UserInfo u1 = userInfoService.getUserInfoAndAddress(id);System.out.println(u1.getAddressList().get(0).getCity());return u1;}
Service 的实现如下所示,我们在里面用事务包装,利用事务,让可能触发 Lazy 的操作提前在事务里面发生。
/*** 我们把逻辑封装在service方法里面,方法名字语义要清晰,就是说这个方法会取UserInfo的信息和Address的信息* @param id*/
@Override
@Transactional
public UserInfo getUserInfoAndAddress(Long id) {UserInfo u1 = userInfoRepository.findById(id).get();u1.getAddressList().size();//在同一个事务里面触发lazy;不需要查询address的地方就不需要触发了return u1;
}
这个时候就要求我们对方法名的语义和注释比较清晰了,这个方法还有个缺点,就是 Service 返回的依然还是 UserInfo 的实体,如果在关联关系多的情况下,依然有犯错的可能性发生。
第四种方式:Service 层之外都用 DTO 或者其他 POJO,而不是 Entity
这种是最复杂的,但却是最有效的、不会出问题的方式,我们在 Service 层返回 DTO,改造一下 Service 方法,代码如下所示。
@Transactional
public UserInfoDto getUserInfoAndAddress(Long id) {UserInfo u1 = userInfoRepository.findById(id).get();//按照业务要求,需要什么返回什么就可以了,让实体在service层之外是不可见的return UserInfoDto.builder().name(u1.getName()).addressList(u1.getAddressList()).build();/
}
而 UserInfoDto 也就是根据我们的业务需要创建不同的 DTO 即可。例如,我们只需要 name 和 address 的时候,代码如下。
@Data
@Builder
public class UserInfoDto {private String name;private List<Address> addressList;
}
除了 DTO 我们还可以采用任何语义的 POJO,宗旨就是 Entity 对 Service 层之外是不可见的。也可以采用“04 | 如何利用 Repository 中的方法返回值解决实际问题?”讲过的 Projection 的方式,返回接口类型的 POJO,这样控制的粒度更细,读写都可以分开。
将 Entity 控制在 Service 层还有个好处就是,有的时候我们会使用各种 RPC 框架进行远程方法调度,可以直接调用 Service 方法通过 TCP 协议,例如 Dubbo,这样也就天然支持了。
场景二:异步线程的时候
既然跨事务容易发生问题,那么异步线程的时候更容易发生 Lazy 异常,你可以先自己想一想该怎么解决。
异步线程的时候,我们再套用上面的四种方式,你会发现,其中的第一种就不适用了,因为异步开启的事务和 DB 操作默认是不受 open-in-view 控制的。所以我们可以明确地知道,开启的异步方法会用到实体参数的哪些关联关系,是否需要按照上面的第三种和第四种方式进行提前处理呢?这些都是需要我们心中有数的,而不是简单地把异步开启就完事了。
场景三:Controller 直接返回实体也会产生 Lazy Exception
工作中我们经常为了省事,直接在 Contoller 里面返回 Entity,这个时候很容易发生 Lazy 异常,例如下面这个场景。
@GetMapping("/user/info/{id}")
public UserInfo getUserInfoFromPath(@PathVariable("id") Long id) {return userInfoRepository.findById(id).get();//controller层直接将UserInfo返回给view层了;
}
类似上面的 Contoller,我们直接将 UserInfo 实体对象当成 VO 对象,且直接当成返回结果了,当我们请求上面的 API 的时候也会发生 Lazy 异常,我们看下代码。
o.hibernate.LazyInitializationException : failed to lazily initialize a collection of role: com.example.jpa.demo.db.UserInfo.addressList, could not initialize proxy - no Sessionorg.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: com.example.jpa.demo.db.UserInfo.addressList, could not initialize proxy - no Session
此 VO 发生的异常与其他 Lazy 异常不同的时候,我们仔细观察,会发现如下信息。
Resolved [org.springframework.http.converter.HttpMessageNotWritableException: Could not write JSON: failed to lazily initialize a collection of role: com.example.jpa.demo.db.UserInfo.addressList
通过日志可以知道,此时发生 Lazy 异常的主要原因是 JSON 系列化的时候会触发 Lazy 加载。这个时候就有了第五种解决 Lazy 异常的方式,就是利用 @JsonIgnoreProperties("addressList") 排除我们不想序列化的属性即可。
但是这种方式的弊端是用这个集合的只能全局配置,没办法有特例配置。因此最佳实践还是采用上面所说的第一种方式和第四种方式。
场景四:自定义的拦截器和 filter 中无意的 toString 操作
第四个 Lazy 异常的场景就是我们打印一些日志,或者无意间触发 toString 的操作也会发生 Lazy 异常,这种处理方法也很简单(第六种处理 Lazy 异常的方式):toString 里面排除掉不需要 Lazy 加载的关联关系即可。如果我们用 lombok 的话,直接 @ToString(exclude = "addressList") 排除掉就好了,完整例子如下所示。
@ToString(exclude = "addressList")
@JsonIgnoreProperties("addressList")
public class UserInfo extends BaseEntity {
......}
以上介绍的四个 Lazy 异常的场景和六种处理方式,你在实际工作中可以灵活运用,其中最主要的是要知道背后的原理和触发 Lazy 产生的性能影响是什么(意外的 SQL 执行)。
Hibernate 官方还提供了第七种处理 Lazy 异常的方式:利用 Hibernate 的配置,我们来了解一下。
hibernate.enable_lazy_load_no_trans 配置
Hibernate 官方提供了 hibernate.enable_lazy_load_no_trans 配置,是否允许在关闭之后依然支持 Lazy 加载,此非 JPA 标准,所以你在用的时候需要关注版本变化。
其使用方法很简单,我们直接在 application.properties 里面增加如下配置即可,请看下面的代码。
## 运行在session关闭之后,重新lazy操作
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
此时我们不需要做任何其他修改,当在事务之外,甚至是 Session 之外,触发 Lazy 操作的时候也不会报错,也会正常地进行取数据。
但是我建议你不要用这个方法,因为一旦开启了这个对 Lazy 的操作就不可控了,会发生预期之外的 Lazy 异常,然后你只能通过我们上面所说的处理 Lazy 异常的第三种和第四种方式解决成预期之内的,否则的话,还会带来很多预期之外的 SQL 执行。这就会造成一种误解,即使用 Hibernate 或者 JPA 会导致性能变差,其实本质原因是我们不了解原理,没能正确使用。
所以到目前为止,Spring Data JPA 中,hibernate.enable_lazy_load_no_trans 默认是 false,这和 spring.jpa.open-in-view 默认是 true 是相同的道理。所以如果我们都采用 Spring Boot 的默认配置,一般是没有任何问题的;而有的时候为了更优的配置,我们需要知道底层的原理,这样才能判断出来我们业务场景的最佳实践是什么。
以上我重点介绍了 LazyInitializationException,其实 JPA 里面的异常类型还非常多,下面简单介绍一下。
Javax.persistence.PersistenceException 异常类型
我们顺藤摸瓜,可以看到 LazyInitializationException 是 HibernateException 里面的,也可以看到 HibernateException 的父类 Javax.persistence.PersistenceException 下面有很多细分的异常,如下图所示。
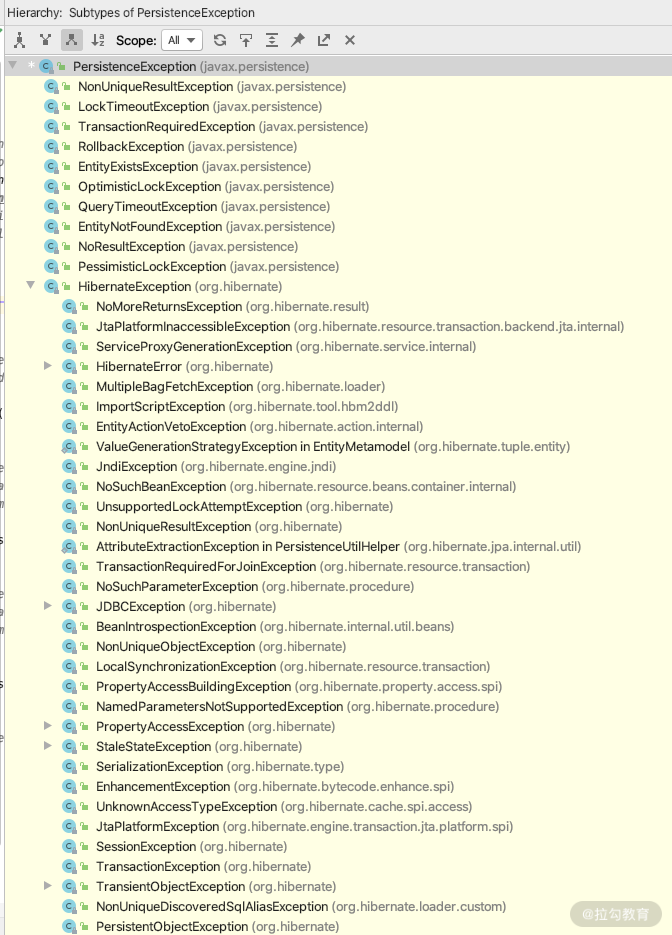
当我们遇到异常的时候不要慌张,仔细看日志基本就能知道是什么问题了。
另外需要注意的是,当我们遇到上面这些异常的时候,不同的异常有不同的处理方式,比如 OptimisticLockException 就需要进行重试;而针对 NoSuchBeanException 的异常,就要检查我们的实体配置是否妥当。
你通过上面的异常 Hierarchy 做到心中有数就好了,遇到实际情况再实际分析即可。
总结
所以为什么我们总会遇到 Lazy Exception 呢?当我们知道原理之后是不是应对起来就非常游刃有余了?而 spring.jpa.open-in-view 设置 true/false 是个权衡性的问题,没有绝对的对和错,就看我们的使用场景是什么样的了。
总之遇到问题不要慌,看一下源码,想一下我们讲的原理知识,或许你就能找到答案。下一讲我们来聊聊经典的 N+1 的 SQL 问题。到时见。
点击下方链接查看源码(不定时更新)
https://github.com/zhangzhenhuajack/spring-boot-guide/tree/master/spring-data/spring-data-jpa
Spring Data JPA 原理与实战第十一天 Session相关、CompletableFuture、LazyInitializationException相关推荐
- Spring Data JPA 原理与实战第二天 掌握Repoitory和DQM
02 Spring Data Common 之 Repoitory 如何全面掌握? 通过上一课时,我们知道了 Spring Data 对整个数据操作做了很好的封装,其中 Spring Data Com ...
- 终于有人把Spring Data JPA 讲明白了!
01 什么是JPA? JPA的全称是 Java Persistence API , 中文的字面意思就是Java 的持久层 API , JPA 就是定义了一系列标准,让实体类和数据库中的表建立一个对应的 ...
- Spring Data JPA 实战
课程介绍 <Spring Data JPA 实战>内容是基于作者学习和工作中实践的总结和升华,有一句经典的话:"现在的开发人员是站在巨人的肩上,弯道超车".因现在框架越 ...
- SpringBoot 实战 (八) | 使用 Spring Data JPA 访问 Mysql 数据库
微信公众号:一个优秀的废人 如有问题或建议,请后台留言,我会尽力解决你的问题. 前言 如题,今天介绍 Spring Data JPA 的使用. 什么是 Spring Data JPA 在介绍 Spri ...
- 【SpringBoot框架篇】11.Spring Data Jpa实战
文章目录 1.简介 1.1.JPA 1.2.Spring Data Jpa 1.3.Hibernate 1.4.Jpa.Spring Data Jpa.Hibernate三者之间的关系 2.引入依赖 ...
- 01 | Spring Data JPA 初识
课程正式开始了,这里我会以一个案例的形式来和你讲解如何通过 Spring Boot 结合 Spring Data JPA 快速启动一个项目.如何使用 UserRepository 完成对 User 表 ...
- Spring Data JPA 从入门到精通~默认数据源的讲解
默认数据源 spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://1 ...
- 【笔记】Spring - Spring Data JPA
相关 官方文档⭐️: https://docs.spring.io/spring-data/jpa/docs/2.6.0/reference/html/#preface 翻译: https://blo ...
- springdatajpa命名规则_简单了解下spring data jpa
公司准备搭建一个通用框架,以后项目就用统一一套框架了 以前只是听过jpa,但是没有实际用过 今天就来学习下一些简单的知识 什么是JPA 全称Java Persistence API,可以通过注解或者X ...
最新文章
- AlexeyAB DarkNet YOLOv3框架解析与应用实践(三)
- 如何防止按钮提交表单
- shell批量插入数据
- Python入门100题 | 第055题
- linux下能ping ip不能ping域名详解
- php ci url,URL路由设置-CI(codeigniter)PHP框架再探
- 如何将数据写入excel中,而不覆盖原有数据
- Linux下如何安装软件
- 【SpringBoot 2】(四)详析SpringBoot的常用注解
- 【软件质量】CMM与CMMI
- 已然是身份的象征了?Coach品牌再入天猫 只有目标用户才有机会看到
- 中日文字编码转换_关于编码你必须知道的知识和技巧
- 跳槽失败到月薪50K,AI工程师是这样炼成的!
- “地球观光之旅”来到这座赛博朋克的城市了!
- 1056 组合数的和 (15 分)—PAT (Basic Level) Practice (中文)
- java实现 图片转ico
- PLC温室大棚自动控制系统
- petalinux 前端包管理器(dnf)
- 关于安装anaconda错误:failed to create anaconda menus
- 灌区续建配套与信息化改造工程--设备选型