- snullnet0 是连接到 sn0 接口的网络. 同样, snullnet1 是连接到 sn1. 这些网络的地址应当仅仅在第 3 个 octet 的最低有效位不同. 这些网络必须有 24 位的子网掩码.
- local0 是分配给 sn0 接口的 IP 地址; 它属于 snullnet0. 陪伴 sn1 的地址是 local1. local0 和 local1 必须在它们的第 3 octet 的最低有效位和第 4 octet 上不同.
- remote0 是在 snullnet0 的主机, 并且它的第 4 octet 与 local1 的相同. 任何发送给 remote0 的报文到达 local1, 在它的网络地址被接口代码改变之后. 主机 remote1 属于 snullnet1, 它的第 4 octet 与 local0 相同.
snull 接口的操作在图
主机如何看它的接口
中描述, 其中每个接口的关联的主机名印在接口名的旁边.
图 17.1. 主机如何看它的接口
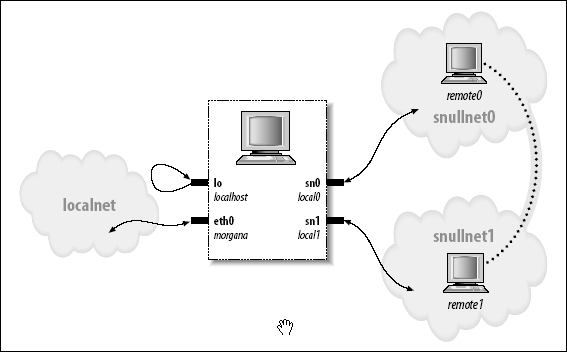
下面是网络编号的可能值. 一旦你把这些行放进 /etc/networks, 你可以使用名子来调用你的网络. 这些值选自保留做私人用途的编号范围.
snullnet0 192.168.0.0
snullnet1 192.168.1.0
下面的是一些可能的主机编号, 可放进 /etc/hosts 里面:
192.168.0.1 local0
192.168.0.2 remote0
192.168.1.2 local1
192.168.1.1 remote1
这些编号的重要特性是 local0 的主机部分与 remote1 的主机部分相同, local1 的主机部分和 remote0 的主机部分相同. 你可以使用完全不同的编号, 只要保持着这种关系.
但是要小心, 如果你的计算机以及连接到一个网络上. 你选择的编号可能是真实的互联网或者内联网的编号, 把它们安排给你的接口会阻止和这些真实的主机间的通讯. 例如, 尽管刚刚展示的这些编号不是可以路由的互联网编号, 它们也可能被你的私有网络已经在使用.
不管你选择什么编号, 你可以正确设置这些接口来操作, 通过发出下面的命令:
ifconfig sn0 local0
ifconfig sn1 local1
你可能需要添加网络掩码 255.255.255.0 参数, 如果选择的地址范围不是 C 类范围.
在此, 接口的"远程"端点能够到达了. 下面的屏幕拷贝显示了一个主机如何到达 remote0 和 remote1 的, 通过 snull 接口.
morgana% ping -c 2 remote0
64 bytes from 192.168.0.99: icmp_seq=0 ttl=64 time=1.6 ms
64 bytes from 192.168.0.99: icmp_seq=1 ttl=64 time=0.9 ms
2 packets transmitted, 2 packets received, 0% packet loss
morgana% ping -c 2 remote1
64 bytes from 192.168.1.88: icmp_seq=0 ttl=64 time=1.8 ms
64 bytes from 192.168.1.88: icmp_seq=1 ttl=64 time=0.9 ms
2 packets transmitted, 2 packets received, 0% packet loss
注意, 你不能到达属于这两个网络的任何其他主机, 因为报文被你的计算机丢弃了, 在地址被修改和收到报文之后. 例如, 一个发向 192.168.0.32 的报文将离开 sn0 并以 192.168.1.32 的目的地址出现在 sn1, 这并不是这台主机的本地地址.
17.1.2. 报文的物理传送
只考虑数据传送的话, snull 接口属于以太网一类的.
snull 模拟以太网是因为大量的现存网络 -- 至少一个工作站所连接的网段 -- 是基于以太网技术的, 它可能是 10base-T, 100base-T, 或者 千兆网. 另外, 内核为以太网设备提供了一些通用的接口, 没有理由不用它. 一个以太网设备的优势是如此的强以至于 plip 接口( 使用打印机端口的接口 )都声明自己是一个以太网设备.
snull 使用以太网设置的最后一个优势是你可以运行 tcpdump 在接口上来观察过往的报文. 使用 tcpdump 来观察接口是得知两个接口如何工作的有用途径.
如同我们之前提到的, snull 只处理 IP 报文. 这个限制来自这样的事实, snull 监听报文并且甚至修改它们, 以便使代码工作. 代码修改了每个报文的源, 目的和 IP header 的校验和, 并不检查它是否实际承载着 IP 信息.
这种快而脏的数据修改毁坏了非 IP 报文. 如果你想通过 snull 递交其他协议, 你必须修改模块的源代码.
17.2. 连接到内核
我们从分析 snull 的源码来查看网络驱动的结构开始. 把几个驱动的源码留在手边, 对于下面的讨论和得知真实世界中的 Linux 网络驱动如何运行是会有帮助的.
17.2.1. 设备注册
当一个驱动模块加载进一个运行着的内核中, 它请求资源并提供功能; 这里没有新内容. 并且在资源是如何请求上也没有新东西. 驱动应当探测它的设备和它的硬件位置( I/O 端口和 IRQ 线 ) -- 但是不注册它们 --如在第 10 章的" 安装一个中断处理程序 "中所述. 一个网络驱动通过它的模块初始化函数注册的方式与字符和块驱动是不同的. 因为没有对等的主次编号给网络接口, 一个网络驱动不请求这样一个号. 相反, 驱动为每个刚刚探测到的接口在一个全局的网络设备列表里插入一个数据结构.
每个接口由一个结构 net_device 项来描述, 它在 里定义. snull 驱动留有指向两个这样结构的指针, 在一个简单数组里.
struct net_device *snull_devs[2];
net_device 结构, 如同许多其他内核结构, 包含一个 kobject, 以及因此它可被引用计数并通过 sysfs 输出. 如同别的这样的结构, 它必须动态分配. 进行这种分配的内核函数是 alloc_netdev, 它有下列原型:
struct net_device *alloc_netdev(int sizeof_priv,
const char *name,
void (*setup)(struct net_device *));
这里, sizeof_priv 是驱动的的"私有数据"区的大小; 对于网络驱动, 这个区是同 net_device 结构一起分配的. 实际上, 这两个是是在一个大内存块中一起分配的, 但是驱动作者应当假装不知道这一点. name 是这个接口的名子, 如同用户空间看到的一样; 这个名子可以有一个 printf 风格的 %d 在里面. 内核用下一个可用的接口号来替换这个 %d. 最后, setup 是一个初始化函数的指针, 被调用来设置 net_device 结构的剩余部分. 我们即将进入这个初始化函数, 但是现在, 为强化起见, snull 以这样的方式分配它的两个设备结构:
snull_devs[0] = alloc_netdev(sizeof(struct snull_priv), "sn%d",
snull_init);
snull_devs[1] = alloc_netdev(sizeof(struct snull_priv), "sn%d",
snull_init);
if (snull_devs[0] == NULL || snull_devs[1] == NULL)
goto out;
象通常一样, 我们必须检查返回值来确保分配成功.
网络子系统为各种接口提供了一些帮助函数, 包裹着 alloc_netdev. 最通用的是 alloc_etherdev, 定义在 :
struct net_device *alloc_etherdev(int sizeof_priv);
这个函数分配一个网络设备使用 eth%d 作为参数 name. 它提供了自己的初始化函数 ( ether_setup )来设置几个 net_device 字段, 使用对以太网设备合适的值. 因此, 没有驱动提供的初始化函数给 alloc_etherdev; 驱动应当只完成它要求的初始化, 直接在一个成功的分配之后. 其他类型驱动的编写者可能想利用这些帮助函数的其中一个, 例如 alloc_fcdev ( 定义在 ) 为 fiber-channel 设备, alloc_fddidev () 为 FDDI 设备, 或者 aloc_trdev () 为令牌环设备.
snull 可以顺利使用 alloc_etherdev; 我们选择使用 alloc_netdev 来代替, 作为演示低层接口的方式, 并且给我们控制安排给接口的名子.
一旦 net_device 结构完成初始化, 完成这个过程就只是传递这个结构给 register_netdev. 在 snull 中, 调用看来如同这样:
for (i = 0; i name);
一些经常的注意问题这里提一下: 在你调用 register_netdev 时, 你的驱动可能会马上被调用来操作设备. 因此, 你不应当注册设备直到所有东西都已经完全初始化.
17.2.2. 初始化每一个设备
我们已经看到了 net_device 结构的分配和注册, 但是我们越过了中间的完全初始化这个结构的步骤. 注意 net_device 结构在运行时一直是放在一起; 它不能如同一个 file_operations 或者 block_device_opreations 结构一样在编译时设置. 必须在调用 register_netdev 之前完成初始化. net_device 结构又大又复杂; 幸运的是, 内核负责了一些以太网范围中的缺省值, 通过 ether_setup 函数(由 alloc_etherdev 调用).
因为 snull 使用 alloc_netdev, 它有单独的初始化函数. 该函数的核心( snull_init )如下:
ether_setup(dev); /* assign some of the fields */
dev->open = snull_open;
dev->stop = snull_release;
dev->set_config = snull_config;
dev->hard_start_xmit = snull_tx;
dev->do_ioctl = snull_ioctl;
dev->get_stats = snull_stats;
dev->rebuild_header = snull_rebuild_header;
dev->hard_header = snull_header;
dev->tx_timeout = snull_tx_timeout;
dev->watchdog_timeo = timeout;
/* keep the default flags, just add NOARP */
dev->flags |= IFF_NOARP;
dev->features |= NETIF_F_NO_CSUM;
dev->hard_header_cache = NULL; /* Disable caching */
上面的代码是对 net_device 结构的例行初始化; 大部分是存储我们的各种驱动函数指针. 代码的单个不寻常的特性是设置 IFF_NOARP 在 flags 里面. 这个指出该接口不能使用 ARP. ARP 是一个低层以太网协议; 它的工作是将 IP 地址转变成以太网介质存取控制 (MAC) 地址. 因为由 snull 模拟的远程系统并不存在, 就没人回答对它们的 ARP 请求. 不想因为增加 ARP 实现使 snull 变复杂, 我们选择标识接口作为不能处理这个协议. 其中的对 hard_header_cache 赋值是同样理由: 它关闭了这个接口的(不存在的) ARP 回答. 这个主题在本章后面的" MAC 地址解析"一节中详述.
代码初始化也设置了几个和发送超时的处理有关的几个变量( tx_timeout 和 watchdog_time ). 我们在"发送超时"一节完整地涉及这个主题.
我们现在看结构 net_device 的另一个成员, priv. 它的角色近似于我们用在字符驱动上的 private_data 指针. 不同于 fops->private_data, 这个 priv 指针是随 net_device 结构一起分配的. 也不鼓励直接存取 priv 成员, 由于性能和灵活性的原因. 当一个驱动需要存取私有数据指针, 应当使用 netdev_priv 函数. 因此, snull 驱动充满着这样的声明:
struct snull_priv *priv = netdev_priv(dev);
snull 模块声明了一个 snull_priv 数据结构来给 priv 使用:
struct snull_priv {
struct net_device_stats stats;
int status;
struct snull_packet *ppool;
struct snull_packet *rx_queue; /* List of incoming packets */
int rx_int_enabled;
int tx_packetlen;
u8 *tx_packetdata;
struct sk_buff *skb;
spinlock_t lock;
};
这个结构包括, 还有其他东西, 一个 net_device_stats 结构的实例, 这是放置接口统计量的标准地方. 下面的在 snull_init 中的各行分配并初始化 dev->priv:
priv = netdev_priv(dev);
memset(priv, 0, sizeof(struct snull_priv));
spin_lock_init(&priv->lock);
snull_rx_ints(dev, 1); /* enable receive interrupts */
17.2.3. 模块卸载
模块卸载时没什么特别的. 模块的清理函数只是注销接口, 进行任何需要的内部清理, 释放 net_device 结构回系统.
void snull_cleanup(void)
{
int i;
for (i = 0; i
对 unregister_netdev 的调用从系统中去除了接口; free_netdev 归还 net_device 结构给内核. 如果某个地方有对这个结构的引用, 它可能继续存在, 但是你的驱动不需要关心这个. 一旦你已经注销了接口, 内核不再调用它的方法.
注意我们的内部清理( 在 snull_teardown_pool 里所做的 )直到已经注销了设备后才能进行. 它必须, 但是, 在我们返回 net_device 结构给系统之前进行; 一旦我们已调用了 free_netdev, 我们再不能对这个设备或者我们的私有数据做任何引用.
17.3. net_device 结构的详情
net_device 结构处于网络驱动层的非常核心的位置并且值得完全的描述. 这个列表描述了所有成员, 更多的是提供了一个参考而不是用来备忘. 本章剩下的部分简要地描述了每个成员, 一旦它用在例子代码上, 因此你不需要不停地回看这一节.
17.3.1. 全局信息
结构 net_device 的第一部分是由下面成员组成:
char name[IFNAMSIZ];
设备名子. 如果名子由驱动设置, 包含一个 %d 格式串, register_netdev 用一个数替换它来形成一个唯一的名子; 分配的编号从 0 开始.
unsigned long state;
设备状态. 这个成员包括几个标志. 驱动正常情况下不直接操作这些标志; 相反, 提供了一套实用函数. 这些函数在我们进入驱动操作后马上讨论这些函数.
struct net_device *next;
全局列表中指向下一个设备的指针. 这个成员驱动不能动.
int (*init)(struct net_device *dev);
一个初始化函数. 如果设置了这个指针, 这个函数被 register_netdev 调用来完成对 net_device 结构的初始化. 大部分现代的网络驱动不再使用这个函数; 相反, 初始化在注册接口前进行.
17.3.2. 硬件信息
下面的成员包含了相对简单设备的低层硬件信息. 它们是早期 Linux 网络的延续; 大部分现代驱动确实使用它们(可能的例外是 if_port ). 我们为完整起见在这里列出.
unsigned long rmem_end;
unsigned long rmem_start;
unsigned long mem_end;
unsigned long mem_start;
设备内存信息. 这些成员持有设备使用的共享内存的开始和结束地址. 如果设备有不同的接收和发送内存, mem 成员由发送内存使用, rmem 成员由接收内存使用. rmem 成员在驱动之外从不被引用. 惯例上, 设置 end 成员, 所以 end - start 是可用的板上内存的数量.
unsigned long base_addr;
网络接口的 I/O 基地址. 这个成员, 如同前面的, 由驱动在设备探测时赋值. ifconfig 目录可用来显示或修改当前值. base_addr 可以当系统启动时在内核命令行中显式赋值( 通过 netdev= 参数), 或者在模块加载时. 这个成员, 象上面描述过的内存成员, 内核不使用它们.
unsigned char irq;
安排的中断号. 当接口被列出时 ifconfig 打印出 dev->irq 的值. 这个值常常在启动或者加载时间设置并且在后来由 ifconfig 打印.
unsigned char if_port;
在多端口设备中使用的端口. 例如, 这个成员用在同时支持同轴线(IF_PORT_10BASE2)和双绞线(IF_PORT_100BSAET)以太网连接. 完整的已知端口类型设置定义在 .
unsigned char dma;
设备分配的 DMA 通道. 这个成员只在某些外设总线时有意义, 例如 ISA. 它不在设备驱动自身以外使用, 只是为了信息目的( 在 ifconfig ) 中.
17.3.3. 接口信息
有关接口的大部分信息由 ether_setup 函数正确设置(或者任何其他对给定硬件类型适合的设置函数). 以太网卡可以依赖这个通用的函数设置大部分这些成员, 但是 flags 和 dev_addr 成员是特定设备的, 必须在初始化时间明确指定.
一些非以太网接口可以使用类似 ether_setup 的帮助函数. deviers/net/net_init.c 输出了一些类似的函数, 包括下列:
void ltalk_setup(struct net_device *dev);
设置一个 LocalTalk 设备的成员
void fc_setup(struct net_device *dev);
初始化光通道设备的成员
void fddi_setup(struct net_device *dev);
配置一个光纤分布数据接口 (FDDI) 网络的接口
void hippi_setup(struct net_device *dev);
预备给一个高性能并行接口 (HIPPI) 的高速互连驱动的成员
void tr_setup(struct net_device *dev);
处理令牌环网络接口的设置
大部分设备会归于这些类别中的一类. 如果你的是全新和不同的, 但是, 你需要手工赋值下面的成员:
unsigned short hard_header_len;
硬件头部长度, 就是, 被发送报文前面在 IP 头之前的字节数, 或者别的协议信息. 对于以太网接口 hard_header_len 值是 14 (ETH_HLEN).
unsigned mtu;
最大传输单元 (MTU). 这个成员是网络层用作驱动报文传输. 以太网有一个 1500 字节的 MTU (ETH_DATA_LEN). 这个值可用 ifconfig 改变.
unsigned long tx_queue_len;
设备发送队列中可以排队的最大帧数. 这个值由 ether_setup 设置为 1000, 但是你可以改它. 例如, plip 使用 10 来避免浪费系统内存( 相比真实以太网接口, plip 有一个低些的吞吐量).
unsigned short type;
接口的硬件类型. 这个 type 成员由 ARP 用来决定接口支持什么样的硬件地址. 对以太网接口正确的值是 ARPHRD_ETHER, 这是由 ether_setup 设置的值. 可认识的类型定义于 .
unsigned char addr_len;
unsigned char broadcast[MAX_ADDR_LEN];
unsigned char dev_addr[MAX_ADDR_LEN];
硬件 (MAC) 地址长度和设备硬件地址. 以太网地址长度是 6 个字节( 我们指的是接口板的硬件 ID ), 广播地址由 6 个 0xff 字节组成; ether_setup 安排成正确的值. 设备地址, 另外, 必须以特定于设备的方式从接口板读出, 驱动应当将它拷贝到 dev_addr. 硬件地址用来产生正确的以太网头, 在报文传递给驱动发送之前. snull 设备不使用物理接口, 它创造自己的硬件接口.
unsigned short flags;
int features;
接口标志(下面详述)
这个 flags 成员是一个位掩码, 包括下面的位值. IFF_ 前缀代表 "interface flags". 有些标志由内核管理, 有些由接口在初始化时设置来表明接口的能力和其他特性. 有效的标志, 对应于 , 有:
IFF_UP
对驱动这个标志是只读的. 内核打开它当接口激活并准备号传送报文时.
IFF_BROADCAST
这个标志(由网络代码维护)说明接口允许广播. 以太网板是这样.
IFF_DEBUG
这个标识了调试模式. 这个标志用来控制你的 printk 调用的复杂性或者用于其他调试目的. 尽管当前没有 in-tree 驱动使用这个标志, 它可以通过 ioctl 来设置和重置, 你的驱动可用它. misc-progs/netifdebug 程序可以用来打开或关闭这个标志.
IFF_LOOPBACK
这个标志应当只在环回接口中设置. 内核检查 IFF_LOOPBACK , 以代替硬连线 lo 名子作为一个特殊接口.
IFF_POINTOPOINT
这个标志说明接口连接到一个点对点链路. 它由驱动设置或者, 有时, 由 ifconfig. 例如, plip 和 PPP 驱动设置它.
IFF_NOARP
这个说明接口不能进行 ARP. 例如, 点对点接口不需要运行 ARP, 它只能增加额外的流量却没有任何有用的信息. snull 在没有 ARP 能力的情况下运行, 因此它设置这个标志.
IFF_PROMISC
这个标志设置(由网络代码)来激活混杂操作. 缺省地, 以太网接口使用硬件过滤器来保证它们只接收广播报文和直接到接口硬件地址的报文. 报文嗅探器, 例如 tcpdump, 在接口上设置混杂模式来存取在接口发送介质上经过的所有报文.
IFF_MULTICAST
驱动设置这个标志来表示接口能够组播发送. ether_setup 设置 IFF_MULTICAST 缺省地, 因此如果你的驱动不支持组播, 必须在初始化时清除这个标志.
IFF_ALLMULTI
这个标志告知接口接收所有的组播报文. 内核在主机进行组播路由时设置它, 前提是 IFF_MULTICAST 置位. IFF_ALLMULTI 对驱动是只读的. 组播标志在本章后面的"组播"一节中用到.
IFF_MASTER
IFF_SLAVE
这些标志由负载均衡代码使用. 接口驱动不需要知道它们.
IFF_PORTSEL
IFF_AUTOMEDIA
这些标志指出设备可以在多个介质类型间切换; 例如, 无屏蔽双绞线 (UTP) 和 同轴以太网电缆. 如果 IFF_AUTOMEDIA 设置了, 设备自动选择正确的介质. 特别地, 内核一个也不使用这 2 个标志.
IFF_DYNAMIC
这个标志, 由驱动设置, 指出接口的地址能够变化. 目前内核没有使用.
IFF_RUNNING
这个标志指出接口已启动并在运行. 它大部分是因为和 BSD 兼容; 内核很少用它. 大部分网络驱动不需要担心 IFF_RUNNING.
IFF_NOTRAILERS
在 Linux 中不用这个标志, 为了 BSD 兼容才存在.
当一个程序改变 IFF_UP, open 或者 stop 设备方法被调用. 进而, 当 IFF_UP 或者任何别的标志修改了, set_multicast_list 方法被调用. 如果驱动需要进行某些动作来响应标志的修改, 它必须在 set_multicast_list 中采取动作. 例如, 当 IFF_PROMISC 被置位或者复位, set_multicast_list 必须通知板上的硬件过滤器. 这个设备方法的责任在"组播"一节中讲解.
结构 net_device 的特性成员由驱动设置来告知内核关于任何的接口拥有的特别硬件能力. 我们将谈论一些这些特性; 别的就超出了本书范围. 完整的集合是:
NETIF_F_SG
NETIF_F_FRAGLIST
2 个标志控制发散/汇聚 I/O 的使用. 如果你的接口可以发送一个报文, 它由几个不同的内存段组成, 你应当设置 NETIF_F_SG. 当然, 你不得不实际实现发散/汇聚 I/O( 我们在"发散/汇聚"一节中描述如何做 ). NETIF_F_FRAGLIST 表明你的接口能够处理分段的报文; 在 2.6 中只有环回驱动做这一点.
注意内核不对你的设备进行发散/汇聚 I/O 操作, 如果它没有同时提供某些校验和形式. 理由是, 如果内核不得不跨过一个分片的("非线性")的报文来计算校验和, 它可能也拷贝数据并同时接合报文.
NETIF_F_IP_CSUM
NETIF_F_NO_CSUM
NETIF_F_HW_CSUM
这些标志都是告知内核, 不需要给一些或所有的通过这个接口离开系统的报文进行校验. 如果你的接口可以校验 IP 报文但是别的不行, 就设置 NETIF_F_IP_CSUM. 如果这个接口不曾要求校验和, 就设置 NETIF_F_NO_CSUM. 环回驱动设置了这个标志, snull 也设置; 因为报文只通过系统内存传送, 对它们来说没有机会( 1 跳 )被破坏, 没有必要校验它们. 如果你的硬件自己做校验, 设置 NETIF_F_HW_CWSUM.
NETIF_F_HIGHDMA
设置这个标志, 如果你的设备能够对高端内存进行 DMA. 没有这个标志, 所有提供给你的驱动的报文在低端内存分配.
NETIF_F_HW_VLAN_TX
NETIF_F_HW_VLAN_RX
NETIF_F_HW_VLAN_FILTER
NETIF_F_VLAN_CHALLENGED
这些选项描述你的硬件对 802.1q VLAN 报文的支持. VLAN 支持超出我们本章的内容. 如果 VLAN 报文使你的设备混乱( 其实不应该 ), 设置标志 NETIF_F_VLAN_CHALLENGED.
NETIF_F_TSO
如果你的设备能够进行 TCP 分段卸载, 设置这个标志. TSO 是一个我们在这不涉及的高级特性.
17.3.4. 设备方法
如同在字符和块驱动的一样, 每个网络设备声明能操作它的函数. 本节列出能够对网络接口进行的操作. 有些操作可以留作 NULL, 别的常常是不被触动的, 因为 ether_setup 给它们安排了合适的方法.
网络接口的设备方法可分为 2 组: 基本的和可选的. 基本方法包括那些必需的能够使用接口的; 可选的方法实现更多高级的不是严格要求的功能. 下列是基本方法:
int (*open)(struct net_device *dev);
打开接口. 任何时候 ifconfig 激活它, 接口被打开. open 方法应当注册它需要的任何系统资源( I/O 口, IRQ, DMA, 等等), 打开硬件, 进行任何别的你的设备要求的设置.
int (*stop)(struct net_device *dev);
停止接口. 接口停止当它被关闭. 这个函数应当恢复在打开时进行的操作.
int (*hard_start_xmit) (struct sk_buff *skb, struct net_device *dev);
起始报文的发送的方法. 完整的报文(协议头和所有)包含在一个 socket 缓存区( sk_buff ) 结构. socket 缓存在本章后面介绍.
int (*hard_header) (struct sk_buff *skb, struct net_device *dev, unsigned short type, void *daddr, void *saddr, unsigned len);
用之前取到的源和目的硬件地址来建立硬件头的函数(在 hard_start_xmit 前调用). 它的工作是将作为参数传给它的信息组织成一个合适的特定于设备的硬件头. eth_header 是以太网类型接口的缺省函数, ether_setup 针对性地对这个成员赋值.
int (*rebuild_header)(struct sk_buff *skb);
用来在 ARP 解析完成后但是在报文发送前重建硬件头的函数. 以太网设备使用的缺省的函数使用 ARP 支持代码来填充报文缺失的信息.
void (*tx_timeout)(struct net_device *dev);
由网络代码在一个报文发送没有在一个合理的时间内完成时调用的方法, 可能是丢失一个中断或者接口被锁住. 它应当处理这个问题并恢复报文发送.
struct net_device_stats *(*get_stats)(struct net_device *dev);
任何时候当一个应用程序需要获取接口的统计信息, 调用这个方法. 例如, 当 ifconfig 或者 netstat -i 运行时. snull 的一个例子实现在"统计信息"一节中介绍.
int (*set_config)(struct net_device *dev, struct ifmap *map);
改变接口配置. 这个方法是配置驱动的入口点. 设备的 I/O 地址和中断号可以在运行时使用 set_config 来改变. 这种能力可由系统管理员在接口没有探测到时使用. 现代硬件正常的驱动一般不需要实现这个方法.
剩下的设备操作是可选的:
int weight;
int (*poll)(struct net_device *dev; int *quota);
由适应 NAPI 的驱动提供的方法, 用来在查询模式下操作接口, 中断关闭着. NAPI ( 以及 weight 成员) 在"接收中断缓解"一节中涉及.
void (*poll_controller)(struct net_device *dev);
在中断关闭的情况下, 要求驱动检查接口上的事件的函数. 它用于特殊的内核中的网络任务, 例如远程控制台和使用网络的内核调试.
int (*do_ioctl)(struct net_device *dev, struct ifreq *ifr, int cmd);
处理特定于接口的 ioctl 命令. (这些命令的实现在"定制 ioclt 命令"一节中描述)相应的 net_device 结构中的成员可留为 NULL, 如果接口不需要任何特定于接口的命令.
void (*set_multicast_list)(struct net_device *dev);
当设备的组播列表改变和当标志改变时调用的方法. 详情见"组播"一节, 以及一个例子实现.
int (*set_mac_address)(struct net_device *dev, void *addr);
如果接口支持改变它的硬件地址的能力, 可以实现这个函数. 很多接口根本不支持这个能力. 其他的使用缺省的 eth_mac_adr 实现(在 deivers/net/net_init.c). eth_mac_addr 只拷贝新地址到 dev->dev_addr, 只在接口没有运行时作这件事. 使用 eth_mac_addr 的驱动应当在它们的 open 方法中自 dev->dev_addr 里设置硬件 MAC 地址.
int (*change_mtu)(struct net_device *dev, int new_mtu);
当接口的最大传输单元 (MTU) 改变时动作的函数. 如果用户改变 MTU 时驱动需要做一些特殊的事情, 它应当声明它的自己的函数; 否则, 缺省的会将事情做对. snull 有对这个函数的一个模板, 如果你有兴趣.
int (*header_cache) (struct neighbour *neigh, struct hh_cache *hh);
header_cache 被调用来填充 hh_cache 结构, 使用一个 ARP 请求的结果. 几乎全部类似以太网的驱动可以使用缺省的 eth_header_cache 实现.
int (*header_cache_update) (struct hh_cache *hh, struct net_device *dev, unsigned char *haddr);
在响应一个变化中, 更新 hh_cache 结构中的目的地址的方法. 以太网设备使用 eth_header_cache_update.
int (*hard_header_parse) (struct sk_buff *skb, unsigned char *haddr);
hard_header_parse 方法从包含在 skb 中的报文中抽取源地址, 拷贝到 haddr 的缓存区. 函数的返回值是地址的长度. 以太网设备通常使用 eth_header_parse.
17.3.5. 公用成员
结构 net_device 剩下的数据成员由接口使用来持有有用的状态信息. 有些是 ifconfig 和 netstat 用来提供给用户关于当前配置的信息. 因此, 接口应当给这些成员赋值:
unsigned long trans_start;
unsigned long last_rx;
保存一个 jiffy 值的成员. 驱动负责分别更新这些值, 当开始发送和收到一个报文时. trans_start 值被网络子系统用来探测发送器加锁. last_rx 目前没有用到, 但是驱动应当尽量维护这个成员以备将来使用.
int watchdog_timeo;
网络层认为一个传送超时发生前应当过去的最小时间(按 jiffy 计算), 调用驱动的 tx_timeout 函数.
void *priv;
filp->private_data 的对等者. 在现代的驱动里, 这个成员由 alloc_netdev 设置, 不应当直接存取; 使用 netdev_priv 代替.
struct dev_mc_list *mc_list;
int mc_count;
处理组播发送的成员. mc_count 是 mc_list 中的项数目. 更多细节见"组播"一节.
spinlock_t xmit_lock;
int xmit_lock_owner;
xmit_lock 用来避免对驱动的 hard_start_xmit 函数多个同时调用. xmit_lock_owner 是已获得 xmit_lock 的CPU号. 驱动应当不改变这些成员的值.
结构 net_device 中有其他的成员, 但是网络驱动用不着它们.
17.4. 打开与关闭
我们的驱动可以在模块加载时或者内核启动时探测接口. 在接口能够承载报文前, 但是, 内核必须打开它并分配一个地址给它. 内核打开或者关闭一个接口对应 ifconfig 命令.
当 ifconfig 用来给接口安排一个地址, 它做 2 个任务. 第一, 它通过 ioctl(SIOCSIFADDR)( Socket I/O Control Set Interface Address) 来安排地址. 接着它设置 dev->flag 的 IFF_UP 位, 通过 ioctl(SIOCSIFFLAGS) ( Socket I/O Control Set Interface Flags) 来打开接口.
目前为止, ioctl(SIOCSIFADDR) 不做任何事. 没有驱动函数被调用 -- 这个任务是独立于设备的, 并且是内核实现它. 后面的命令 (ioctl(SIOCSIFFLAGS)), 但是, 为设备调用 open 方法.
相似地, 当接口关闭, ifconfig 使用 ioctl(SIOCSIFFLAGS) 来清除 IFF_UP, 并且 stop 方法被调用.
2 个设备方法都返回 0 在成功时, 并且出错时返回负值.
目前为止的实际代码, 驱动不得不进行许多与字符和块驱动同样的任务. open 请求任何它需要的系统资源并且告知接口启动; stop 关闭接口并释放系统资源. 网络驱动必须进行一些附加的步骤在 open 时, 但是.
第一, 硬件 (MAC) 地址需要从硬件设备拷贝到 dev->dev_addr, 在接口可以和外部世界通讯之前. 硬件地址接着在 open 时拷贝到设备. snull 软件接口在 open 里面安排它; 它只是使用了一个长为 ETH_ALEN 的字符串伪造了一个硬件号, ETH_ALEN 是以太网硬件地址长度.
open 方法应当也启动接口的发送队列( 允许它接受发送报文 ), 一旦它准备好启动发送数据. 内核提供了一个函数来启动队列:
void netif_start_queue(struct net_device *dev);
snull 的 open 代码看来如下:
int snull_open(struct net_device *dev)
{
/* request_region(), request_irq( ), .... (like fops->open) */
/*
* Assign the hardware address of the board: use "\0SNULx", where
* x is 0 or 1. The first byte is '\0' to avoid being a multicast
* address (the first byte of multicast addrs is odd).
*/
memcpy(dev->dev_addr, "\0SNUL0", ETH_ALEN);
if (dev == snull_devs[1])
dev->dev_addr[ETH_ALEN-1]++; /* \0SNUL1 */
netif_start_queue(dev);
return 0;
}
如你所见, 在缺乏真实硬件的情况下, 在 open 方法中没什么可做. stop 方法也一样; 它只是反转 open 的操作. 因此, 实现 stop 的函数常常称为 close 或者 release.
int snull_release(struct net_device *dev)
{
/* release ports, irq and such -- like fops->close */
netif_stop_queue(dev); /* can't transmit any more */
return 0;
}
函数:
void netif_stop_queue(struct net_device *dev);
是 netif_start_queue 的对立面; 它标志设备为不能再发送任何报文. 这个函数必须在接口关闭( 在 stop 方法中 )时调用, 但以可用于暂时停止发送, 如下一节中解释的.
17.5. 报文传送
网络接口进行的最重要任务是数据发送和接收. 我们从发送开始, 因为它稍微易懂一些.
传送指的是通过一个网络连接发送一个报文的行为. 无论何时内核需要传送一个数据报文, 它调用驱动的 hard_start_stransmit 方法将数据放在外出队列上. 每个内核处理的报文都包含在一个 socket 缓存结构( 结构 sk_buff )里, 定义见. 这个结构从 Unix 抽象中得名, 用来代表一个网络连接, socket. 如果接口与 socket 没有关系, 每个网络报文属于一个网络高层中的 socket, 并且任何 socket 输入/输出缓存是结构 struct sk_buff 的列表. 同样的 sk_buff 结构用来存放网络数据历经所有 Linux 网络子系统, 但是对于接口来说, 一个 socket 缓存只是一个报文.
sk_buff 的指针通常称为 skb, 我们在例子代码和文本里遵循这个做法.
socket 缓存是一个复杂的结构, 内核提供了一些函数来操作它. 在"Socket 缓存"一节中描述这些函数; 现在, 对我们来说一个基本的关于 sk_buff 的事实就足够来编写一个能工作的驱动.
传给 hard_start_xmit 的 socket 缓存包含物理报文, 它应当出现在媒介上, 以传输层的头部结束. 接口不需要修改要传送的数据. skb->data 指向要传送的报文, skb->len 是以字节计的长度. 如果你的驱动能够处理发散/汇聚 I/O, 情形会稍稍复杂些; 我们在"发散/汇聚 I/O"一节中说它.
snull 报文传送代码如下; 网络传送机制隔离在另外一个函数里, 因为每个接口驱动必须根据特定的在驱动的硬件来实现它:
int snull_tx(struct sk_buff *skb, struct net_device *dev)
{
int len;
char *data, shortpkt[ETH_ZLEN];
struct snull_priv *priv = netdev_priv(dev);
data = skb->data;
len = skb->len;
if (len data, skb->len);
len = ETH_ZLEN;
data = shortpkt;
}
dev->trans_start = jiffies; /* save the timestamp */
/* Remember the skb, so we can free it at interrupt time */
priv->skb = skb;
/* actual deliver of data is device-specific, and not shown here */ snull_hw_tx(data, len, dev);
return 0; /* Our simple device can not fail */
}
传送函数, 因此, 只对报文进行一些合理性检查并通过硬件相关的函数传送数据. 注意, 但是, 要小心对待传送的报文比下面的媒介(对于 snull, 是我们虚拟的"以太网")支持的最小长度要短的情况. 许多 Linux 网络驱动( 其他操作系统的也是 )已被发现在这种情况下泄漏数据. 不是产生那种安全漏洞, 我们拷贝短报文到一个单独的数组, 这样我们可以清楚地零填充到足够的媒介要求的长度. (我们可以安全地在堆栈中放数据, 因为最小长度 -- 60 字节 -- 是太小了).
hard_start_xmit 的返回值应当为 0 在成功时; 此时, 你的驱动已经负责起报文, 应当尽全力保证发送成功, 并且必须在最后释放 skb. 非 0 返回值指出报文这次不能发送; 内核将稍后重试. 这种情况下, 你的驱动应当停止队列直到已经解决导致失败的情况.
"硬件相关"的传送函数( snull_hw_tx )这里忽略了, 因为它完全是来实现了 snull 设备的戏法, 包括假造源和目的地址, 对于真正的网络驱动作者没有任何吸引力. 当然, 它呈现在例子源码里, 给那些想进入并看看它如何工作的人.
17.5.1. 控制发送并发
hard_start_xmit 函数由一个 net_device 结构中的自旋锁(xmit_lock)来保护避免并发调用. 但是, 函数一返回, 它有可能被再次调用. 当软件完成指导硬件报文发送的事情, 但是硬件传送可能还没有完成. 对 snull 这不是问题, 它使用 CPU 完成它所有的工作, 因此报文发送在传送函数返回前就完成了.
真实的硬件接口, 另一方面, 异步发送报文并且具备有限的内存来存放外出的报文. 当内存耗尽(对某些硬件, 会发生在一个单个要发送的外出报文上), 驱动需要告知网络系统不要再启动发送直到硬件准备好接收新的数据.
这个通知通过调用 netif_stop_queue 来实现, 这个前面介绍过的函数来停止队列. 一旦你的驱动已停止了它的队列, 它必须安排在以后某个时间重启队列, 当它又能够接受报文来发送了. 为此, 它应当调用:
void netif_wake_queue(struct net_device *dev);
这个函数如同 netif_start_queue, 除了它还刺探网络系统来使它又启动发送报文.
大部分现代的网络硬件维护一个内部的有多个发送报文的队列; 以这种方式, 它可以从网络上获得最好的性能. 这些设备的网络驱动必须支持在如何给定时间有多个未完成的发送, 但是设备内存能够填满不管硬件是否支持多个未完成发送. 任何时候当设备内存填充到没有空间给最大可能的报文时, 驱动应当停止队列直到有空间可用.
如果你必须禁止如何地方的报文传送, 除了你的 hard_start_xmit 函数( 也许, 响应一个重新配置请求 ), 你想使用的函数是:
void netif_tx_disable(struct net_device *dev);
这个函数非常象 netif_stop_queue, 但是它还保证, 当它返回时, 你的 hard_start_xmit 方法没有在另一个 CPU 上运行. 队列能够用 netif_wake_queue 重启, 如常.
17.5.2. 传送超时
与真实硬件打交道的大部分驱动不得不预备处理硬件偶尔不能响应. 接口可能忘记它们在做什么, 或者系统可能丢失中断. 设计在个人机上运行的设备, 这种类型的问题是平常的.
许多驱动通过设置定时器来处理这个问题; 如果在定时器到期时操作还没结束, 有什么不对了. 网络系统, 本质上是一个复杂的由大量定时器控制的状态机的组合体. 因此, 网络代码是一个合适的位置来检测发送超时, 作为它正常操作的一部分.
因此, 网络驱动不需要担心自己去检测这样的问题. 相反, 它们只需要设置一个超时值, 在 net_device 结构的 watchdog_timeo 成员. 这个超时值, 以 jiffy 计, 应当足够长以容纳正常的发送延迟(例如网络媒介拥塞引起的冲突).
如果当前系统时间超过设备的 trans_start 时间至少 time-out 值, 网络层最终调用驱动的 tx_timeout 方法. 这个方法的工作是是进行清除问题需要的工作并且保证任何已经开始的发送正确地完成. 特别地, 驱动没有丢失追踪任何网络代码委托给它的 socket 缓存.
snull 有能力模仿发送器上锁, 由 2 个加载时参数控制的:
static int lockup = 0;
module_param(lockup, int, 0);
static int timeout = SNULL_TIMEOUT;
module_param(timeout, int, 0);
如果驱动使用参数 lockup=n 加载, 则模拟一个上锁, 一旦每 n 个报文传送了, 并且 watchdog_timeo 成员设为给定的时间值. 当模拟上锁时, snull 也调用 netif_stop_queue 来阻止其他的发送企图发生.
snull 发送超时处理看来如此:
void snull_tx_timeout (struct net_device *dev)
{
struct snull_priv *priv = netdev_priv(dev);
PDEBUG("Transmit timeout at %ld, latency %ld\n", jiffies, jiffies - dev->trans_start);
/* Simulate a transmission interrupt to get things moving */
priv->status = SNULL_TX_INTR;
snull_interrupt(0, dev, NULL);
priv->stats.tx_errors++;
netif_wake_queue(dev);
return;
}
当发生传送超时, 驱动必须在接口统计量中标记这个错误, 并安排设备被复位到一个干净的能发送新报文的状态. 当一个超时发生在 snull, 驱动调用 snull_interrupt 来填充"丢失"的中断并用 netif_wake_queue 重启队列.
17.5.3. 发散/汇聚 I/O
网络中创建一个发送报文的过程包括组合多个片. 报文数据必须从用户空间拷贝, 由网络协议栈各层使用的头部必须同时加上. 这个组合可能要求相当数量的数据拷贝. 但是, 如果注定要发送报文的网络接口能够进行发散/汇聚 I/O, 报文就不需要组装成一个单个块, 大量的拷贝可以避免. 发散/汇聚 I/O 也从用户空间启动"零拷贝"网络发送.
内核不传递发散的报文给你的 hard_start_xmit 方法除非 NETIF_F_SG 位已经设置到你的设备结构的特性成员中. 如果你已设置了这个标志, 你需要查看一个特殊的 skb 中的"shard info"成员来确定是否报文由一个单个片段或者多个组成, 并且如果需要就找出发散的片段. 一个特殊的宏定义来存取这个信息; 它是 skb_shinfo. 发送潜在的分片报文的第一步常常是看来如此的东东:
if (skb_shinfo(skb)->nr_frags == 0) {
/* Just use skb->data and skb->len as usual */
}
nr_frags 成员告知多少片要用来建立这个报文. 如果它是 0, 报文存于一个单个片中, 可以如常使用 data 成员来存取. 但是, 如果它是非 0, 你的驱动必须历经并安排发送每一个单独的片. skb 结构的 data 成员方便地指向第一个片(在不分片情况下, 指向整个报文). 片的长度必须通过从 skb->len ( 仍然含有整个报文的长度 ) 中减去 skb->data_len 计算得来. 剩下的片会在称为 frags 的数组中找到, frags 在共享的信息结构中; frags 中每个入口是一个 skb_frag_struct 结构:
struct skb_frag_struct { struct page *page;
__u16 page_offset;
__u16 size;
};
如你所见, 我们又一次遇到 page 结构, 不是内核虚拟地址. 你的驱动应当遍历这些分片, 为 DMA 传送映射每一个, 并且不要忘记第一个分片, 它由 skb 直接指着. 你的硬件, 当然, 必须组装这些分片并作为一个单个报文发送它们. 注意, 如果你已经设置了NETIF_F_HIGHDMA 特性标志, 一些或者全部分片可能位于高端内存.
17.6. 报文接收
从网络上接收报文比发送它要难一些, 因为必须分配一个 sk_buff 并从一个原子性上下文中递交给上层. 网络驱动可以实现 2 种报文接收的模式: 中断驱动和查询. 大部分驱动采用中断驱动技术, 这是我们首先要涉及的. 有些高带宽适配卡的驱动也可能采用查询技术; 我们在"接收中断缓解"一节中了解这个方法.
snull 的实现将"硬件"细节从设备独立的常规事务中分离. 因此, 函数 snull_rx 在硬件收到报文后从 snull 的"中断"处理中调用, 并且报文现在已经在计算机的内存中. snull_rx 收到一个数据指针和报文长度; 它唯一的责任是发走这个报文和运行附加信息给上层的网络代码. 这个代码独立于获得数据指针和长度的方式.
void snull_rx(struct net_device *dev, struct snull_packet *pkt)
{
struct sk_buff *skb;
struct snull_priv *priv = netdev_priv(dev);
/*
*
The packet has been retrieved from the transmission
*
medium. Build an skb around it, so upper layers can handle it
*/
skb = dev_alloc_skb(pkt->datalen + 2);
if (!skb) {
if (printk_ratelimit())
printk(KERN_NOTICE "snull rx: low on mem - packet dropped\n"); priv->stats.rx_dropped++; goto out;
}
memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);
/* Write metadata, and then pass to the receive level */
skb->dev = dev;
skb->protocol = eth_type_trans(skb, dev);
skb->ip_summed = CHECKSUM_UNNECESSARY; /* don't check it */
priv->stats.rx_packets++;
priv->stats.rx_bytes += pkt->datalen;
netif_rx(skb);
out:
return;
}
这个函数足够普通以作为任何网络驱动的一个模板, 但是在你有信心重用这个代码段前需要一些解释.
第一步是分配一个缓存区来保存报文. 注意缓存分配函数 (dev_alloc_skb) 需要知道数据长度. 函数用这些信息来给缓存区分配空间. dev_alloc_skb 使用 atomic 优先级调用 kmalloc , 因此它可以在中断时间安全使用. 内核提供了其他接口给 socket 缓存分配, 但是它们不值得在此介绍; socket 缓存在"socket 缓存"一节中详细介绍.
当然, dev_alloc_skb 的返回值必须检查, snull 这样做了. 我们调用 printk_ratelimit 在抱怨失败之前, 但是. 每秒钟产生成百上千的控制台消息是完全陷死系统和隐藏问题的真正源头的好方法; printk_ratelimit 帮助阻止这个问题, 通过在有太多输出到了控制台时返回 0, 事情需要慢下来一点.
一旦有一个有效的 skb 指针, 通过调用 memcpy, 报文数据被拷贝到缓存区; skb_put 函数更新缓存中的数据末尾指针并返回指向新建空间的指针.
如果你在编写一个高性能驱动, 为一个可以进行完全总线占据 I/O 的接口, 一个可能的优化值得在此考虑下. 一些驱动在报文接收前分配 sokcet 缓存, 接着使接口将报文数据直接放入 socket 缓存空间. 网络层通过在可 DMA 的空间( 如果你的设备设置了 NETIF_F_HIGHDMA 标志, 这个空间有可能在高端内存)中分配所有 socket 缓存来配合这个策略. 这样避免了单独的填充 socket 缓存的拷贝操作, 但是需要小心缓存区的大小, 因为你无法提前知道进来的报文大小. change_mtu 方法的实现在这种情况下也重要, 因为它允许驱动对最大报文大小改变作出响应.
网络层在搞懂报文的意思前需要清楚一些事情. 为此, dev 和 protocol 成员必须在缓存向上传递前赋值. 以太网支持代码输出一个帮助函数( eth_type_trans ), 它发现一个合适值来赋给 protocol. 接着我们需要指出校验和要如何进行或者已经在报文上完成( snull 不需要做任何校验和 ). 对于 skb->ip_summed 可能的策略有:
CHECKSUM_HW
设备已经在硬件里做了校验. 一个硬件校验的例子使 APARC HME 接口.
CHECKSUM_NONE
校验和还没被验证, 必须由系统软件来完成这个任务. 这个是缺省的, 在新分配的缓存中.
CHECKSUM_UNNECESSARY
不要做任何校验. 这是 snull 和 环回接口的策略.
你可能奇怪为什么校验和状态必须在这里指定, 当我们已经在我们的 net_device 结构的特性成员中设置了标志. 答案是特性标志告诉内核我们的设备如何对待外出的报文. 它不用于进入的报文, 相反, 进入报文必须单独标记.
最后, 驱动更新它的统计计数来记录收到一个报文。 统计结构由几个成员组成; 最重要的是 rx_packet, rx_bytes, 和 tx_bytes, 分别含有收到的报文数目, 发送的数目, 和发送的字节总数. 所有的成员在"统计信息"一节中完全描述.
报文接收的最后一步由 netif_rx 进行, 它递交 socket 缓存给上层. 实际上 netif_rx 返回一个整数; NET_RX_SUCCESS(0) 意思是报文成功接收; 任何其他值指示错误. 有 3 个返回值 (NET_RX_CN_LOW, NET_RX_CN_MOD, 和 NET_RX_CN_HIGH )指出网络子系统的递增的拥塞级别; NET_RX_DROP 意思是报文被丢弃. 一个驱动在拥塞变高时可能使用这些值来停止输送报文给内核, 但是, 实际上, 大部分驱动忽略从 netif_rx 的返回值. 如果你在编写一个高带宽设备的驱动, 并且希望正确处理拥塞, 最好的办法是实现 NAPI, 我们在快速讨论中断处理后讨论它.
17.7. 中断处理
大部分硬件接口通过一个中断处理来控制. 硬件中断处理器来发出 2 种可能的信号: 一个新报文到了或者一个外出报文的发送完成了. 网络接口也能够产生中断来指示错误, 例如状态改变, 等等.
通常的中断过程能够告知新报文到达中断和发送完成通知的区别, 通过检查物理设备中的状态寄存器. snull 接口类似地工作, 但是它的状态字在软件中实现, 位于 dev->priv. 网络接口的中断处理看来如此:
static void snull_regular_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
int statusword;
struct snull_priv *priv;
struct snull_packet *pkt = NULL;
/*
*
As usual, check the "device" pointer to be sure it is
*
really interrupting.
*
Then assign "struct device *dev"
*/
struct net_device *dev = (struct net_device *)dev_id;
/* ... and check with hw if it's really ours */
/* paranoid */
if (!dev)
return;
/* Lock the device */
priv = netdev_priv(dev);
spin_lock(&priv->lock);
/* retrieve statusword: real netdevices use I/O instructions */
statusword = priv->status;
priv->status = 0;
if (statusword & SNULL_RX_INTR) {
/* send it to snull_rx for handling */
pkt = priv->rx_queue;
if (pkt) {
priv->rx_queue = pkt->next;
snull_rx(dev, pkt);
}
}
if (statusword & SNULL_TX_INTR) {
/* a transmission is over: free the skb */
priv->stats.tx_packets++;
priv->stats.tx_bytes += priv->tx_packetlen;
dev_kfree_skb(priv->skb);
}
/* Unlock the device and we are done */
spin_unlock(&priv->lock);
if (pkt) snull_release_buffer(pkt); /* Do this outside the lock! */
return;
}
中断处理的第一个任务是取一个指向正确 net_device 结构的指针. 这个指针通常来自作为参数收到的 dev_id 指针.
中断处理的有趣部分处理"发送结束"的情况. 在这个情况下, 统计量被更新, 调用 dev_kfree_skb 来返回 socket 缓存给系统. 实际上, 有这个函数的 3 个变体可以调用:
dev_kfree_skb(struct sk_buff *skb);
这个版本应当在你知道你的代码不会在中断上下文中运行时调用. 因为 snull 没有实际的硬件中断, 我们使用这个版本.
dev_kfree_skb_irq(struct sk_buff *skb);
如果你知道会在中断处理中释放缓存, 使用这个版本, 它对这个情况做了优化.
dev_kfree_skb_any(struct sk_buff *skb);
如果相关代码可能在中断或非中断上下文运行时, 使用这个版本.
最后, 如果你的驱动已暂时停止了发送队列, 这常常是用 netif_wake_queue 重启它的地方.
报文的接收, 相比于发送, 不需要特别的中断处理. 调用 snull_rx (我们已经见过)就是全部所需.
17.8. 接收中断缓解
当一个网络驱动如我们上面所述编写出来, 你的接口收到每个报文都中断处理器. 在许多情况下, 这是希望的操作模式, 它不是个问题. 然而, 高带宽接口能够在每秒内收到几千个报文. 这个样子的中断负载下, 系统的整体性能会受损害.
作为一个提高高端 Linux 系统性能的方法, 网络子系统开发者已创建了一种可选的基于查询的接口(称为 NAPI). [
52
]"查询"可能是一个不妥的字在驱动开发者看来, 他们常常看到查询是不灵巧和低效的. 查询是低效的, 但是, 仅仅在接口没有工作做的时候被查询. 当系统有一个处理大流量的高速接口时, 会一直有更多的报文来处理. 在这种情况下没有必要中断处理器; 时常从接口收集新报文是足够的.
停止接收中断能够减轻相当数量的处理器负载. 适应 NAPI 的驱动能够被告知不要输送报文给内核, 如果这些报文只是在网络代码里因拥塞而被丢弃, 这样能够在最需要的时候对性能有帮助. 由于各种理由, NAPI 驱动也比较少可能重排序报文.
不是所有的设备能够以 NAPI 模式操作, 但是. 一个 NAPI 适应的接口必须能够存储几个报文( 要么在接口卡上, 要么在内存内 DMA 环). 接口应当能够禁止中断来接收报文, 却可以继续因成功发送或其他事件而中断. 有其他微妙的事情使得编写一个适应 NAPI 的驱动更有难度; 详情见内核源码中的 Documentation/networking/NAPI_HOWTO.txt.
相对少有驱动实现 NAPI 接口. 如果你在编写一个驱动给一个可能产生大量中断的接口, 但是, 花点时间来实现 NAPI 会被证明是很值得的.
snull 驱动, 当用非零的 use_napi 参数加载时, 在 NAPI 模式下操作. 在初始化时, 我们不得不建立一对格外的结构 net_device 的成员:
if (use_napi) {
dev->poll = snull_poll;
dev->weight = 2;
}
poll 成员必须设置为你的驱动的查询函数; 我们简短看一下 snull_poll. weight 成员描述接口的相对重要性: 有多少流量可以从接口收到, 当资源紧张时. 如何设置 weight 参数没有严格的规则; 依照惯例, 10 MBps 以太网接口设置 weight 为 16, 而快一些的接口使用 64. 你不能设置 weight 为一个超过你的接口能够存储的报文数目的值. 在 snull, 我们设置 weight 为 2, 作为一个演示不同报文接收的方法.
创建适应 NAPI 的驱动的下一步是改变中断处理. 当你的接口(它应当在接收中断使能下启动)示意有报文到达, 中断处理不应当处理这个报文. 相反, 它应当禁止后面的接收中断并告知内核到时候查询接口了. 在 snull的"中断"处理里, 响应报文接收中断的代码已变为如下:
if (statusword & SNULL_RX_INTR) {
snull_rx_ints(dev, 0); /* Disable further interrupts */
netif_rx_schedule(dev);
}
当接口告诉我们有报文来了, 中断处理将其留在接口中; 此时需要的所有东西就是调用 netif_rx_schedule, 它使得我们的 poll 方法在后面某个时候被调用.
poll 方法有下面原型:
int (*poll)(struct net_device *dev, int *budget);
snull 的 poll 方法实现看来如此:
static int snull_poll(struct net_device *dev, int *budget)
{
int npackets = 0, quota = min(dev->quota, *budget);
struct sk_buff *skb;
struct snull_priv *priv = netdev_priv(dev);
struct snull_packet *pkt;
while (npackets rx_queue) {
pkt = snull_dequeue_buf(dev);
skb = dev_alloc_skb(pkt->datalen + 2);
if (! skb) {
if (printk_ratelimit())
printk(KERN_NOTICE "snull: packet dropped\n"); priv->stats.rx_dropped++; snull_release_buffer(pkt); continue;
}
memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);
skb->dev = dev;
skb->protocol = eth_type_trans(skb, dev);
skb->ip_summed = CHECKSUM_UNNECESSARY; /* don't check it */
netif_receive_skb(skb);
/* Maintain stats */
npackets++;
priv->stats.rx_packets++;
priv->stats.rx_bytes += pkt->datalen;
snull_release_buffer(pkt);
}
/* If we processed all packets, we're done; tell the kernel and reenable ints */
*budget -= npackets;
dev->quota -= npackets;
if (! priv->rx_queue) {
netif_rx_complete(dev);
snull_rx_ints(dev, 1);
return 0;
}
/* We couldn't process everything. */
return 1;
}
函数的中心部分是关于创建一个保持报文的 skb; 这部分代码和我们之前在 snull_rx 中见到的一样. 但是, 有些东西不一样:
- budget 参数提供了一个我们允许传给内核的最大报文数目. 在设备结构里, quota 成员给出了另一个最大值; poll 方法必须遵守这两个限制中的较小者. 它也应当以实际收到的报文数目递减 dev->quota 和 *budget. budget 值是当前 CPU 能够从所有接口收到的最多报文数目, 而 quota 是一个每接口值, 常常在初始化时安排给接口以 weight 为起始.
- 报文应当用 netif_receive_skb 递交内核, 而不是 netif_rx.
- 如果 poll 方法能够在给定的限制内处理所有的报文, 它应当重新使能接收中断, 调用 netif_rx_complete 来关闭 查询, 并且返回 0. 返回值 1 指示有剩下的报文需要处理.
网络子系统保证任何给定的设备的 poll 方法不会在多于一个处理器上被同时调用. 但是, poll 调用仍然可以与你的其他设备方法的调用并发.
[
52
] NAPI 代表"new API"; 网络黑客们精于创建接口却疏于给它们起名.
17.9. 连接状态的改变
网络连接, 根据定义, 打交道本地系统之外的世界. 因此, 它们常常受外界事件的影响, 并且它们可能是短暂的东西. 网络子系统需要知道网络连接的上或下, 它提供了几个驱动可用来传达这种信息的函数.
大部分涉及实际的物理连接的网络技术提供有一个载波状态; 载波存在说明硬件存在并准备好. 以太网适配器, 例如, 在电线上感知载波信号; 当一个用户绊倒一根电缆, 载波消失, 连接断开. 缺省地, 网络设备假设有载波信号存在. 驱动可以明确改变这个状态, 但是, 使用这些函数:
void netif_carrier_off(struct net_device *dev);
void netif_carrier_on(struct net_device *dev);
如果你的驱动检测到它的一个设备载波丢失, 它应当调用 netif_carrier_off 来通知内核这个改变. 当载波回来时, 应当调用 netif_carrier_on. 一些驱动也调用 netif_carrier_off 当进行大的配置改变时(例如媒介类型); 一旦适配器已经完成复位它自身, 新载波被检测并且恢复流量.
一个整数函数也存在:
int netif_carrier_ok(struct net_device *dev);
它可用于测试当前载波状态( 如同设备结构中所反映的 );
17.10. Socket 缓存
我们现在已经涵盖到了大部分关于网络接口的问题. 还缺乏的是对 sk_buff 结构的详细描述.这个结构处于 Linux 内核网络子系统的核心, 我们现在介绍这个结构的重要成员和操作它们的函数.
尽管没有严格要求去理解 sk_buff 的内部, 能够查看它的内容的能力在你追踪问题和试图优化代码时是有帮助的. 例如, 如果你看 loopback.c, 你会发现一个基于对 sk_buff 内部了解的优化. 这里适用的通常的警告是: 如果你编写利用 sk_buff 结构的知识的代码, 你应当准备好在以后内核发行中它坏掉. 仍然, 有时性能优势值得额外的维护开销.
我们这里不会描述整个结构, 只是那些在驱动里可能用到的. 如果你想看到更多, 你可以查看 , 那里定义了结构和函数原型. 关于如何使用这些成员和函数的额外的细节可以通过搜索内核源码很容易获取.
17.10.1. 重要成员变量
这里介绍的成员是驱动可能需要存取的. 以非特别的顺序列出它们.
struct net_device *dev;
接收或发送这个缓存的设备
union { /* ... */ } h;
union { /* ... */ } nh;
union { /*... */} mac;
指向报文中包含的各级的头的指针. union 中的某个成员都是一个不同数据结构类型的指针. h 含有传输层头部指针(例如, struct tcphdr *th); nh 包含网络层头部(例如 struct iphdr *iph); 以及 mac 包含链路层头部指针(例如 struct ethkr * ethernet).
如果你的驱动需要查看 TCP 报文的源和目的地址, 可以在 skb->h.th 中找到. 看头文件来找到全部的可以这样存取的头部类型.
注意网络驱动负责设置进入报文的 mac 指针. 这个任务正常是由 eth_type_trans 处理, 但是 非以太网驱动不得不直接设置 skb->mac.raw, 如同"非以太网头部"一节所示.
unsigned char *head;
unsigned char *data;
unsigned char *tail;
unsigned char *end;
用来寻址报文中数据的指针. head 指向分配内存的开始, data 是有效字节的开始(并且常常稍微比 head 大一些), tail 是有效字节的结尾, end 指向 tail 能够到达的最大地址. 查看它的另一个方法是可用缓存空间是 skb->end - skb->head, 当前使用的空间是 skb->tail - skb->data.
unsigned int len;
unsigned int data_len;
len 是报文中全部数据的长度, 而 data_len 是报文存储于单个片中的部分的长度. 除非使用发散/汇聚 I/O, data_len 成员的值为 0.
unsigned char ip_summed;
这个报文的校验和策略. 由驱动在进入报文上设置这个成员, 如在"报文接收"一节中描述的.
unsigned char pkt_type;
在递送中使用的报文分类. 驱动负责设置它为 PACKET_HOST (报文是给自己的), PACKET_OTHERHOST (不, 这个报文不是给我的), PACKET_BROADCAST, 或者 PACKET_MULTICAST. 以太网驱动不显式修改 pkt_type, 因为 eth_type_trans 为它们做.
shinfo(struct sk_buff *skb);
unsigned int shinfo(skb)->nr_frags;
skb_frag_t shinfo(skb)->frags;
由于性能的原因, 有些 skb 信息存储于一个分开的结构中, 它在内存中紧接着 skb. 这个"shared info"(这样命名是因为它可以在网络代码中多个 skb 拷贝中共享)必须通过 shinfo 宏定义来存取. 这个结构中有几个成员, 但是大部分超出本书的范围. 我们在"发散/汇聚 I/O"一节中见过 nr_frags 和 frags.
在结构中剩下的成员不是特别有趣. 它们用来维护缓存列表, 来统计 socket 拥有的缓存大小, 等等.
17.10.2. 作用于 socket 缓存的函数
使用一个 sk_buff 结构的网络驱动利用正式接口函数来操作它. 许多函数操作一个 socket 缓存; 这里是最有趣的几个:
struct sk_buff *alloc_skb(unsigned int len, int priority);
struct sk_buff *dev_alloc_skb(unsigned int len);
分配一个缓存区. alloc_skb 函数分配一个缓存并且将 skb->data 和 skb->tail 都初始化成 skb->head. dev_alloc_skb 函数是使用 GFP_ATOMIC 优先级调用 alloc_skb 的快捷方法, 并且在 skb->head 和 skb->data 之间保留了一些空间. 这个数据空间用在网络层之间的优化, 驱动不要动它.
void kfree_skb(struct sk_buff *skb);
void dev_kfree_skb(struct sk_buff *skb);
void dev_kfree_skb_irq(struct sk_buff *skb);
void dev_kfree_skb_any(struct sk_buff *skb);
释放缓存. kfree_skb 调用由内核在内部使用. 一个驱动应当使用一种 dev_kfree_skb 的变体: 在非中断上下文中使用 dev_kfree_skb, 在中断上下文中使用 dev_kfree_skb_irq, 或者 dev_kfree_skb_any 在任何 2 种情况下.
unsigned char *skb_put(struct sk_buff *skb, int len);
unsigned char *__skb_put(struct sk_buff *skb, int len);
更新 sk_buff 结构中的 tail 和 len 成员; 它们用来增加数据到缓存的结尾, 每个函数的返回值是 skb->tail 的前一个值(换句话说, 它指向刚刚创建的数据空间). 驱动可以使用返回值通过引用 memcpy(skb_put(...), data, len) 来拷贝数据或者一个等同的东东. 两个函数的区别在于 skb_put 检查以确认数据适合缓存, 而 __skb_put 省略这个检查.
unsigned char *skb_push(struct sk_buff *skb, int len);
unsigned char *__skb_push(struct sk_buff *skb, int len);
递减 skb->data 和递增 skb->len 的函数. 它们与 skb_put 相似, 除了数据是添加到报文的开始而不是结尾. 返回值指向刚刚创建的数据空间. 这些函数用来在发送报文之前添加一个硬件头部. 又一次, __skb_push 不同在它不检查空间是否足够.
int skb_tailroom(struct sk_buff *skb);
返回可以在缓存中放置数据的可用空间数量. 如果驱动放了多于它能持有的数据到缓存中, 系统傻掉. 尽管你可能反对说一个 printk 会足够来标识出这个错误, 内存破坏对系统是非常有害的以至于开发者决定采取确定的动作. 实际中, 你不该需要检查可用空间, 如果缓存被正确地分配了. 因为驱动常常在分配缓存前获知报文的大小, 只有一个严重坏掉的驱动会在缓存中安放太多的数据, 这样出乱子就可当作一个应得的惩罚.
int skb_headroom(struct sk_buff *skb);
返回 data 前面的可用空间数量, 就是, 可以 "push" 给缓存多少字节.
void skb_reserve(struct sk_buff *skb, int len);
递增 data 和 tail. 这个函数可用来在填充数据前保留空间. 大部分以太网接口保留 2 个字节在报文的前面; 因此, IP 头对齐到 16 字节, 在 14 字节的以太网头后面. snull 也这样做, 尽管没有在"报文接收"一节中展现这个指令以避免在那时引入过多概念.
unsigned char *skb_pull(struct sk_buff *skb, int len);
从报文的头部去除数据. 驱动不会需要使用这个函数, 但是为完整而包含在这儿. 它递减 skb->len 和递增 skb->data; 这是硬件头如何从进入报文开始被剥离.
int skb_is_nonlinear(struct sk_buff *skb);
返回一个真值, 如果这个 skb 分离为多个片为发散/汇聚 I/O.
int skb_headlen(struct sk_buff *skb);
返回 skb 的第一个片的长度(由 skb->data 指着).
void *kmap_skb_frag(skb_frag_t *frag);
void kunmap_skb_frag(void *vaddr);
如果你必须从内核中的一个非线性 skb 直接存取片, 这些函数为你映射以及去映射它们. 使用一个原子性 kmap, 因此你不能一次映射多于一个片.
内核定义了几个其他的作用于 socket 缓存的函数, 但是它们是打算用于高层网络代码, 驱动不需要它们.
17.11. MAC 地址解析
以太网通讯的一个有趣的方面是如何将 MAC 地址( 接口的唯一硬件 ID )和 IP 编号结合起来. 大部分协议有类似的问题, 但我们这里集中于类以太网的情况. 我们试图提供这个问题的完整描述, 因此我们展示三个情形: ARP, 无 ARP 的以太网头部( 例如 plip), 以及非以太网头部.
17.11.1. 以太网使用 ARP
处理地址解析的通常方法是使用 Address Resolution Protocol (ARP). 幸运的是, ARP 由内核来管理, 并且一个以太网接口不需要做特别的事情来支持 ARP. 只要 dev->addr 和 dev->addr_len 在 open 时正确的赋值了, 驱动就不需要担心解决 IP 编号对应于 MAC 地址; ether_setup 安排正确的设备方法给 dev->hard_header 和 dev_rebuild_header.
尽管通常内核处理地址解析的细节(并且缓存结果), 它需要接口驱动来帮助建立报文. 毕竟, 驱动知道物理层头部细节, 然而网络代码的作者已经试图隔离内核其他部分. 为此, 内核调用驱动的 hard_header 方法使用 ARP 查询的结果来布置报文. 正常地, 以太网驱动编写者不需要知道这个过程 -- 公共的以太网代码负责了所有事情.
17.11.2. 不考虑 ARP
简单的点对点网络接口, 例如 plip, 可能从使用以太网头部中受益, 而避免来回发送 ARP 报文的开销. snull 中的例子代码也属于这一类的网络设备. snull 不能使用 ARP 因为驱动改变发送报文中的 IP 地址, ARP 报文也交换 IP 地址. 尽管我们可能轻易实现了一个简单 ARP 应答发生器, 更多的是演示性的来展示如何直接处理网络层头部.
如果你的设备想使用通常的硬件头而不运行 ARP, 你需要重写缺省的 dev->hard_header 方法. 这是 snull 的实现, 作为一个非常短的函数:
int snull_header(struct sk_buff *skb, struct net_device *dev,
unsigned short type, void *daddr, void *saddr,
unsigned int len)
{
struct ethhdr *eth = (struct ethhdr *)skb_push(skb,ETH_HLEN);
eth->h_proto = htons(type);
memcpy(eth->h_source, saddr ? saddr : dev->dev_addr, dev->addr_len);
memcpy(eth->h_dest, daddr ? daddr : dev->dev_addr, dev->addr_len);
eth->h_dest[ETH_ALEN-1] ^= 0x01; /* dest is us xor 1 */
return (dev->hard_header_len);
}
这个函数仅仅用内核提供的信息并把它格式成标准以太网头. 它也翻转目的以太网地址的 1 位, 理由下面叙述.
当接口收到一个报文, eth_type_trans 以几种方法来使用硬件头部. 我们已经在 snull_rx 看到这个调用.
skb->protocol = eth_type_trans(skb, dev);
这个函数抽取协议标识( ETH_P_IP, 在这个情况下 )从以太网头; 它也赋值 skb->mac.raw, 从报文 data (使用 skb_pull)去掉硬件头部, 并且设置 skb->pkt_type. 最后一项在 skb 分配是缺省为 PACKET_HOST(指示报文是发向这个主机的), eth_type_trans 改变它来反映以太网目的地址: 如果这个地址不匹配接收它的接口地址, pkt_type 成员被设为 PACKET_OTHERHOST. 结果, 除非接口处于混杂模式或者内核打开了报文转发, netif_rx 丢弃任何类型为 PACKET_OTHERHOST 的报文. 因为这样, snull_header 小心地使目的硬件地址匹配接收接口.
如果你的接口是点对点连接, 你不会想收到不希望的多播报文. 为避免这个问题, 记住, 第一个字节的最低位(LSB)为 0 的目的地址是方向一个单个主机(即, 要么 PACKET_HOST, 要么 PACKET_OTHERHOST). plip 驱动使用 0xfc 作为它的硬件地址的第一个字节, 而 snull 使用 0x00. 两个地址都导致一个工作中的类似以太网的点对点连接.
17.11.3. 非以太网头部
我们刚刚看过硬件头部除目的地址外包含了一些信息, 最重要的是通讯协议. 我们现在描述硬件头部如何用来封装相关的信息. 如果你需要知道细节, 你可从内核源码里抽取它们或者从特定传送媒介的技术文档中. 大部分驱动编写者能够忽略这个讨论只是使用以太网实现.
值得一提的是不是所有信息都由每个协议提供. 一个点对点连接例如 plip 或者 snull 可能在不失去通用性的情况下避免传送这个以太网头部. hard_header 设备方法, 由 snull_header 实现所展示的, 接收自内核的递交的信息( 协议级别和硬件地址 ). 它也在 type 参数中接收 16 位协议编号; IP, 例如, 标识为 ETH_P_IP. 驱动应该正确递交报文数据和协议编号给接收主机. 一个点对点连接可能它的硬件头部的地址, 只传送协议编号, 因为保证递交是独立于源和目的地址的. 一个只有 IP 的连接甚至可能不发送任何硬件头部.
当报文在连接的另一端被收到, 接收函数应当正确设置成员 skb->protocol, skb->pkt_type, 和 skb->mac.raw.
skb->mac.raw 是一个字符指针, 由在高层的网络代码(例如, net/ipv4/arp.c)所实现的地址解析机制使用. 它必须指向一个匹配 dev->type 的机器地址. 设备类型的可能的值在 中定义; 以太网接口使用 ARPHRD_ETHER. 例如, 这是 eth_type_trans 如何处理收到的报文的以太网头:
skb->mac.raw = skb->data;
skb_pull(skb, dev->hard_header_len);
在最简单的情况下( 一个没有头的点对点连接 ), skb->mac.raw 可指向一个静态缓存, 包含接口的硬件地址, protocol 可设置为 ETH_P_IP, 并且 packet_type 可让它是缺省的值 PACKET_HOST.
因为每个硬件类型是独特的, 给出超出已经讨论的特别的设备是困难的. 内核中满是例子, 但是. 例如, 可查看 AppleTalk 驱动( drivers/net/appletalk/cops.c), 红外驱动(例如, driver/net/irds/smc_ircc.c), 或者 PPP 驱动( drivers/net/ppp_generic.c).
17.12. 定制 ioctl 命令
我们硬件看到给 socket 实现的 ioctl 系统调用; SIOCSIFADDR 和 SIOCSIFMAP 是 "socket ioctls" 的例子. 现在我们看看网络代码如何使用这个系统调用的 3 个参数.
当 ioctl 系统调用在一个 socket 上被调用, 命令号是 中定义的符号中的一个, 并且 sock_ioctl 函数直接调用一个协议特定的函数(这里"协议"指的是使用的主要网络协议, 例如, IP 或者 AppleTalk).
任何协议层不识别的 ioctl 命令传递给设备层. 这些设备有关的 ioctl 命令从用户空间接收一个第 3 个参数, 一个 struct ifreq*. 这个结构定义在 . SIOCSIFADDR 和 SIOCSIFMAP 命令实际上在 ifreq 结构上工作. SIOCSIFMAP 的额外参数, 定义为 ifmap, 只是 ifreq 的一个成员.
除了使用标准调用, 每个接口可以定义它自己的 ioctl 命令. plip 接口, 例如, 允许接口通过 ioctl 修改它内部的超时值. socket 的 ioctl 实现认识 16 作为接口私有的个命令: SIOCDEVPRIVATE 到 SIOCDEVPRIVATE+15.[
53
]
当这些命令中的一个被识别, dev->do_ioctl 在相关的接口驱动中被调用. 这个函数接收与通用 ioctl 函数使用的相同的 struct ifreq * 指针.
int (*do_ioctl)(struct net_device *dev, struct ifreq *ifr, int cmd);
ifr 指针指向一个内核空间地址, 这个地址持有用户传递的结构的一个拷贝. 在 do_ioctl 返回之后, 结构被拷贝回用户空间; 因此, 驱动可以使用这些私有命令接收和返回数据.
设备特定的命令可以选择使用结构 ifreq 中的成员, 但是它们已经传达一个标准意义, 并且不可能驱动使这个结构适应自己的需要. 成员 ifr_data 是一个 caddr_t 项( 一个指针 ), 是打算用做设备特定的需要. 驱动和用来调用它的 ioctl 命令的程序应当一致地使用 ifr_data. 例如, ppp-stats 使用设备特定的命令来从 ppp 接口驱动获取信息.
这里不值得展示一个 do_ioctl 的实现, 但是有了本章的信息和内核例子, 你应当能够在你需要时编写一个. 注意, 但是, plip 实现使用 ifr_data 不正确, 不应当作为一个 ioctl 实现的例子.
[
53
] 注意, 根据 , SIOCDEVPRIVATE 命令是被不赞成的. 应当使用什么来代替它们是不明确的, 但是, 并且不少在目录树中的驱动还使用它们.
17.13. 统计信息
驱动需要的最后一个方法是 get_stats. 这个方法返回一个指向给设备的统计的指针. 它的实现非常简单; 展示过的这个即便在几个接口由同一个驱动管理时都好用, 因为统计量驻留于设备数据结构内部.
struct net_device_stats *snull_stats(struct net_device *dev)
{
struct snull_priv *priv = netdev_priv(dev);
return &priv->stats;
}
需要返回有意义统计的真正工作是分布在整个驱动中的, 有各种成员量被更新. 下列列表展示了最有趣的结构 net_device_stats 中的成员:
unsigned long rx_packets;
unsigned long tx_packets;
接口成功传送的进入和出去报文的总和.
unsigned long rx_bytes;
unsigned long tx_bytes;
接口接收和发送的字节数.
unsigned long rx_errors;
unsigned long tx_errors;
接收和发送的错误数. 报文发送可能出错的事情是没有结束的, net_device_stats 结构包括 6 个计数器给特定的接收错误以及有 5 个给发送错误. 完整列表看 . 如果可能, 你的驱动调用维护详细的错误统计, 因为它们是对系统管理员试图追踪问题的最大帮助.
unsigned long rx_dropped;
unsigned long tx_dropped;
在接收和发送中丢失的报文数目. 当没有可用内存给报文数据时丢弃报文. tx_dropped 极少使用.
unsigned long collisions;
由于介质拥塞引起的冲突数目.
unsigned long multicast;
收到的多播报文数目.
值得重复一下, get_stats 方法可以在任何时候调用 -- 即便在接口关闭时 -- 因此只要 net_device 结构存在驱动必须保持统计信息.
17.14. 多播
一个多播报文是一个会被多个主机接收的网络报文, 但不是所有主机. 这个功能通过给一组主机分配特殊的硬件地址来获得. 发向一个特殊地址的报文应当被那个组当中的所有主机接收. 在以太网的情况下, 一个多播地址在目的地址的第一个字节的最低位为 1, 而每个设备板在它自己的硬件地址的这一位上为 0.
处理主机组和硬件地址的技巧由应用程序和内核处理, 接口驱动不必处理这个问题.
多播报文的传送是一个简单问题, 因为它们看起来就如同其他的报文. 接口发送它们通过通讯媒介, 不查看目的地址. 内核必须要安排一个正确的硬件目的地址; hard_header 设备方法, 如果定义了, 不必查看它安排的数据.
内核来跟踪在任何给定时间对哪些多播地址感兴趣. 这个列表可能经常改变, 因为它是在任何给定时间和按照用户意愿运行的应用程序的功能. 驱动的工作是接收感兴趣的多播地址列表并递交给内核任何发向这些地址的报文. 驱动如何实现多播列表是依赖于底层硬件是如何工作的. 典型地, 在多播的角度上, 硬件属于 3 类中的 1 种:
- 不能处理多播的接口. 这样的接口要么接收特别地发向它们的硬件地址(加上广播报文)的报文, 要么接收每一个报文. 它们只能通过接收每一个报文来接收多播报文, 因此, 潜在地压垮操作系统, 使用大量的"不感兴趣"报文. 你不经常认为这样的接口是有多播能力的, 驱动不会在 dev->flags 设置 IFF_MULTICAST.
点对点接口是特殊情况, 因为它们一直接收每个报文, 不进行任何硬件过滤.
- 能够区别多播报文和其他报文(主机到主机, 或者广播). 这些接口能够被命令来接收每个多播报文, 让软件决定地址是否是主机感兴趣的. 这种情况下的开销是可接受的, 因为在一个典型网络上的多播报文的数目是少的.
- 可以进行硬件检测多播地址的接口. 可以传递一个多播地址的列表给这些接口, 这些地址的报文接收, 并忽略其他多播地址的报文. 对内核这是优化的情况, 因为它不浪费处理器时间来丢弃接口收到的"不感兴趣"的报文.
内核尽力利用高级接口的能力, 通过支持第 3 种设备类型, 它是最通用的. 因此, 内核通知驱动, 在任何有效多播地址列表发生改变时, 并且它传递新的列表给驱动, 因此它能够根据新的信息来更新硬件过滤器.
17.14.1. 多播的内核支持
对多播报文的支持有几项组成:一个设备方法, 一个数据结构, 以及设备标识:
void (*dev->set_multicast_list)(struct net_device *dev);
设备方法, 在与设备相关的机器地址改变时调用. 它也在 dev->flags 被修改时调用, 因为一些标志(例如, IFF_PROMISC) 可能也要求你重新编程硬件过滤器. 这个方法接收一个 struct net_device 指针作为一个参数, 并返回 void. 一个对实现这个方法不感兴趣的驱动可以听任它为 NULL.
struct dev_mc_list *dev->mc_list;
所有设备相关的多播地址的列表. 这个结构的实际定义在本节的末尾介绍.
int dev->mc_count;
链表里的项数. 这个信息有些重复, 但是用 0 来检查 mc_count 是检查这个列表的有用的方法.
IFF_MULTICAST
除非驱动在 dev->flags 中设置这个标志, 接口不会被要求来处理多播报文. 然而, 内核调用驱动的 set_multicast_list 方法, 当 dev->flags 改变时, 因为多播列表可能在接口未激活时改变了.
IFF_ALLMULTI
在 dev->flags 中设置的标志, 网络软件来告知驱动从网络上接收所有多播报文. 这发生在当多播路由激活时. 如果标志设置了, dev->ma_list 不该用来过滤多播报文.
IFF_PROMISC
在 dev->flags 中设置的标志, 当接口在混杂模式下. 接口应当接收每个报文, 不管 dev->ma_list.
驱动开发者需要的最后一点信息是 struct dev_mc_list 的定义, 在 :
struct dev_mc_list { struct dev_mc_list *next; /* Next address in list */
__u8 dmi_addr[MAX_ADDR_LEN]; /* Hardware address */
unsigned char dmi_addrlen; /* Address length */
int dmi_users; /* Number of users */
int dmi_gusers; /* Number of groups */
};
因为多播和硬件地址是独立于真正的报文发送, 这个结构在网络实现中是可移植的, 每个地址由一个字符串和一个长度标识, 就像 dev->dev_addr.
17.14.2. 典型实现
描述 set_multicast_list 的设计的最好方法是给你看一些伪码.
下面的函数是一个典型函数实现在一个全特性(ff)驱动中. 这个驱动是全模式的, 它控制的接口有一个复杂的硬件报文过滤器, 它能够持有一个主机要接收的多播地址表. 表的最大尺寸是 FF_TABLE_SIZE.
所有以 ff_ 前缀的函数是给特定硬件操作的占位者:
void ff_set_multicast_list(struct net_device *dev) { struct dev_mc_list *mcptr;
if (dev->flags & IFF_PROMISC) {
ff_get_all_packets();
return;
}
/* If there's more addresses than we handle, get all multicast
packets and sort them out in software. */
if (dev->flags & IFF_ALLMULTI || dev->mc_count > FF_TABLE_SIZE) {
ff_get_all_multicast_packets();
return;
}
/* No multicast? Just get our own stuff */
if (dev->mc_count == 0) {
ff_get_only_own_packets();
return;
}
/* Store all of the multicast addresses in the hardware filter */
ff_clear_mc_list();
for (mc_ptr = dev->mc_list; mc_ptr; mc_ptr = mc_ptr->next)
ff_store_mc_address(mc_ptr->dmi_addr);
ff_get_packets_in_multicast_list();
}
这个实现可以简化, 如果接口不能为进入报文存储多播表在硬件过滤器中. 这种情况下, FF_TABLE_SIZE 减为 0, 并且代码的最后 4 行不需要了.
如同前面提过的, 不能处理多播报文的接口不需要实现 set_multicast_list 方法来获取 dev->flags 改变的通知. 这个办法可能被称为一个"非特性的"(nf)实现. 实现非常简单, 如下面代码所示:
void nf_set_multicast_list(struct net_device *dev)
{
if (dev->flags & IFF_PROMISC)
nf_get_all_packets();
else
nf_get_only_own_packets();
}
实现 IFF_PROMISC 是非常重要的, 因为不这样用户就不能运行 tcpdump 或任何其他网络分析器. 如果接口运行一个点对点连接, 另一方面, 根本没有必要实现 set_multicast_list, 因为用户接收每个报文.
17.15. 几个其他细节
本节涵盖了几个其他主题, 对网络驱动作者感兴趣的. 在每种情况, 我们试着简单指点你正确的方向. 获取了一个主题的完整描绘可能还需要花费一些时间深入内核源码.
17.15.1. 独立于媒介的接口支持
媒介独立接口(或 MII) 是一个 IEEE 802.3 标准, 描述以太网收发器如何与网络控制器接口; 很多市场上的产品遵守这个接口. 如果你在编写一个驱动为一个 MII 兼容控制器, 内核输出了一个通用 MII 支持层, 可能会使你易做一些.
为使用通用 MII 层, 你应当包含 . 你需要填充一个 mii_if_info 结构使用收发器的物理 ID 信息, 如是否全双工有效. 还要求 mii_if_info 结构的 2 个方法:
int (*mdio_read) (struct net_device *dev, int phy_id, int location);
void (*mdio_write) (struct net_device *dev, int phy_id, int location, int val);
如你可能预料的, 这些方法应当实现与你的特殊 MII 接口的通讯.
通用的 MII 代码提供一套函数, 来查询和改变收发器的操作模式; 许多设计成与 ethtool 工具一起工作( 下一节描述 ). 在 和 drivers/net/mii.c 中查看细节.
17.15.2. ethtool 支持
ethtool 是一个实用工具, 设计来给系统管理员以大量的控制网络接口的操作. 用 ethtool, 可能来控制各种接口参数, 包括速度, 介质类型, 双工模式, DMA 环设置, 硬件校验和, LAN 唤醒操作, 等等, 但是只有当 ethtool 被驱动支持. ethtool 可以从 http://sf.net/projects/gkernel/. 下载.
对 ethtool 支持的相关声明可在 中找到. 它的核心是一个 ethtool_ops 类型的结构, 里面包含一个全部 24 个不同方法来支持 ethtool. 大部分这些方法是相对直接地; 细节看 . 如果你的驱动使用 MII 层, 你能使用 mii_ethtool_gset 和 mii_ethtool_sset 来实现 get_settings 和 set_settings 方法, 分别地.
对于和你的设备一起工作的 ethtool, 你必须放置一个指向你的 ethtool_ops 结构的指针在 net_devcie 结构中. 宏定义 SET_ETHTOOL_OPS( 在 中定义)应当用作这个目的. 注意你的 ethtool 方法可能会在接口关闭时被调用.
Netpoll
17.15.3. netpoll
"netpoll" 是相对迟的增加到网络协议栈中; 它的目的是使内核能够发送和接收报文, 在完整的网络和I/O子系统不可用的情况下. 它用来给如远程网络控制台和远程内核调试等特色使用的. 无论如何, 你的驱动不必支持 netpoll, 但是它可能使你的驱动在某些情况下更有用. 在大部分情况下支持 netpoll 也相对容易.
实现 netpoll 的驱动应当实现 poll_controller 方法. 它的工作是跟上控制器上可能发生的任何东西, 在缺乏设备中断时. 几乎所有的 poll_controller 方法采用下面形式:
void my_poll_controller(struct net_device *dev)
{
disable_device_interrupts(dev);
call_interrupt_handler(dev->irq, dev, NULL);
reenable_device_interrupts(dev);
}
poll_controller 方法, 实际上, 是简单模拟自给定设备的中断.
17.16. 快速参考
本节提供了本章中介绍的概念的参考. 也解释了每个驱动需要包含的头文件的角色. 在 net_device 和 sk_buff 结构中成员的列表, 但是, 这里没有重复.
#include
定义 struct net_device 和 struct net_device_stats 的头文件, 包含了几个其他网络驱动需要的头文件.
struct net_device *alloc_netdev(int sizeof_priv, char *name, void (*setup)(struct net_device *);
struct net_device *alloc_etherdev(int sizeof_priv);
void free_netdev(struct net_device *dev);
分配和释放 net_device 结构的函数
int register_netdev(struct net_device *dev);
void unregister_netdev(struct net_device *dev);
注册和注销一个网络设备.
void *netdev_priv(struct net_device *dev);
获取网络设备结构的驱动私有区域的指针的函数.
struct net_device_stats;
持有设备统计的结构.
netif_start_queue(struct net_device *dev);
netif_stop_queue(struct net_device *dev);
netif_wake_queue(struct net_device *dev);
控制传送给驱动来发送的报文的函数. 没有报文被传送, 直到 netif_start_queue 被调用. netif_stop_queue 挂起发送, netif_wake_queue 重启队列并刺探网络层重启发送报文.
skb_shinfo(struct sk_buff *skb);
宏定义, 提供对报文缓存的"shared info"部分的存取.
void netif_rx(struct sk_buff *skb);
调用来通知内核一个报文已经收到并且封装到一个 socket 缓存中的函数.
void netif_rx_schedule(dev);
来告诉内核报文可用并且应当启动查询接口; 它只是被 NAPI 兼容的驱动使用.
int netif_receive_skb(struct sk_buff *skb);
void netif_rx_complete(struct net_device *dev);
应当只被 NAPI 兼容的驱动使用. netif_receive_skb 是对于 netif_rx 的 NAPI 对等函数; 它递交一个报文给内核. 当一个 NAPI 兼容的驱动已耗尽接收报文的供应, 它应当重开中断, 并且调用 netif_rx_complete 来停止查询.
#include
由 netdevice.h 包含, 这个文件声明接口标志( IFF_ 宏定义 )和 struct ifmap, 它在网络驱动的 ioctl 实现中有重要地位.
void netif_carrier_off(struct net_device *dev);
void netif_carrier_on(struct net_device *dev);
int netif_carrier_ok(struct net_device *dev);
前 2 个函数可用来告知内核是否接口上有载波信号. netif_carrier_ok 测试载波状态, 如同在设备结构中反映的.
#include
ETH_ALEN
ETH_P_IP
struct ethhdr;
由 netdevice.h 包含, if_ether.h 定义所有的 ETH_ 宏定义, 用来代表字节长度( 例如地址长度 )以及网络协议(例如 IP). 它也定义 ethhdr 结构.
#include
struct sk_buff 和相关结构的定义, 以及几个操作缓存的内联函数. 这个头文件由 netdevice.h 包含.
struct sk_buff *alloc_skb(unsigned int len, int priority);
struct sk_buff *dev_alloc_skb(unsigned int len);
void kfree_skb(struct sk_buff *skb);
void dev_kfree_skb(struct sk_buff *skb);
void dev_kfree_skb_irq(struct sk_buff *skb);
void dev_kfree_skb_any(struct sk_buff *skb);
处理 socket 缓存的分配和释放的函数. 通常驱动应当使用 dev_ 变体, 其意图就是此目的.
unsigned char *skb_put(struct sk_buff *skb, int len);
unsigned char *__skb_put(struct sk_buff *skb, int len);
unsigned char *skb_push(struct sk_buff *skb, int len);
unsigned char *__skb_push(struct sk_buff *skb, int len);
添加数据到一个 skb 的函数; skb_put 在 skb 的尾部放置数据, 而 skb_push 放在开始. 正常版本进行检查以确保有足够的空间; 双下划线版本不进行检查.
int skb_headroom(struct sk_buff *skb);
int skb_tailroom(struct sk_buff *skb);
void skb_reserve(struct sk_buff *skb, int len);
进行 skb 中的空间管理的函数. skb_headroom 和 skb_tailroom 说明在开始和结尾分别有多少空间可用. skb_reserve 可用来保留空间, 在一个必须为空的 skb 开始.
unsigned char *skb_pull(struct sk_buff *skb, int len);
skb_pull "去除" 数据从一个 skb, 通过调整内部指针.
int skb_is_nonlinear(struct sk_buff *skb);
如果这个 skb 是为发散/汇聚 I/O 分隔为几个片, 函数返回一个真值.
int skb_headlen(struct sk_buff *skb);
返回 skb 的第一个片的长度, 由 skb->data 指向.
void *kmap_skb_frag(skb_frag_t *frag);
void kunmap_skb_frag(void *vaddr);
提供对非线性 skb 中的片直接存取的函数.
#include
void ether_setup(struct net_device *dev);
为以太网驱动设置大部分方法为通用实现的函数. 它还设置 dev->flags 和安排下一个可用的 ethx 给 dev->name, 如果名子的第一个字符是一个空格或者 NULL 字符.
unsigned short eth_type_trans(struct sk_buff *skb, struct net_device *dev);
当一个以太网接口收到一个报文, 这个函数被调用来设置 skb->pkt_type. 返回值是一个协议号, 通常存储于 skb->protocol.
#include
SIOCDEVPRIVATE
前 16 个 ioctl 命令, 每个驱动可为它们自己的私有用途而实现. 所有的网络 ioctl 命令都在 sockios.h 中定义.
#include
struct mii_if_info;
声明和一个结构, 支持实现 MII 标准的设备的驱动.
#include
struct ethtool_ops;
声明和结构, 使得设备与 ethtool 工具一起工作.
|