HA(高可用)集群之AIS(corosync),高可用httpd+NFS
**高可用集群的定义**
高可用集群,High Availability Cluster,简称HA Cluster;集群就是一组计算机,它们作为一个整体向用户提供各种资源,集群里的host就是节点(node)。
**高可用集群的特点**
高可用服务:
通常使用集群方式实现,这也是集群的最大作用和体现。
确保服务实时可用,不会因为软硬件故障问题导致服务出现终止和不可用的情形。
衡量标准:
系统的可靠性(reliability)和可维护性(maintainability)来衡量。
通常使用平均无故障时间(MTTF)来衡量系统的可靠性,用平均修复时间(MTTR)来衡量系统的可维护性。
计算公式 HA=MTTF/(MTTF+MTTR)
集群服务与资源:
可以在节点之间进行故障转移的服务或应用程序,并可以互联在节点之间通信。
服务通常包括多种资源,多种资源组成某种服务。(vip,mysqld,nfs)
资源的管理
资源的隔离与脑裂:
由于软硬件故障导致节点宕机,发生资源的互相争用,就会出现故障节点或资源并存的情形。
在故障的节点控制相同的集群资源情况下,实施资源隔离,防止脑裂发生(fencing,stonith机制)
集群健康状态检测:
通过集群管理和监控工具以及预定义的脚本来配置常见的服务或应用程序,监控,故障转移等。
heartbeat,用于在集群环境中的各节点之间相互感知对方的存在。
可以基于串口、多播、广播和组播的通信机制。一旦心跳失败,就会发生相应的资源转移,集群重构等。
**高可用集群的实现**
通过VRRP实现方式:keepalived
OpenAIS:corosync
**AIS的层次结构**
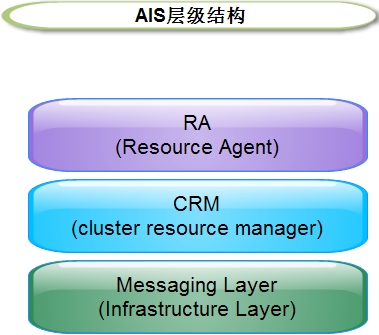
Messaging Layer:用于在各节点之间传递心跳信息,也称为心跳层。节点之间传递心跳信息可以通过广播,组播,单播等方式。
CRM:集群资源管理层,真正实现集群服务的层。每个节点都运行一个资源管理器Cluster Resource Manager),为实现高可用提供核心组件,包括资源定义,属性等。
RA:资源代理层,集群资源代理,能够管理本节点上的属于集群资源的启动,停止和状态信息的脚本。
**AIS的实现**
Messaging Layer:
heartbeat v1,heartbeat v2,heartbeat v3
corosync(openais)
cman(openais)
CRM:
heartbeat v1:haresources,配置接口:配置文件haresources;
heartbeat v2:crm,在集群中的每一个节点运行一个crmd(5560/tcp)守护进程,有命令行工具可与之通信(rmsh,GUI接口hb_gui);
heartbeat v3:pacemaker,配置接口:crmsh,pcs;GUI:hawk(suse);
rgmanager(cman)
RA:
LSB
service(heartbeat legacy)
OCF
STONITH
Systemd
**组合方式**
heartbeat v2+haresource
heartbeat v3+pacemaker
corosync+pacemaker
cman+rgmanager
**资源类型**
primitive:主资源、基本资源,在集群中只能运行一个实例,也就是说同一时刻只能运行在一个节点上,如服务的IP地址;
group:资源组;
clone:克隆资源(可同时运行在多个节点上),要先定义为primitive后才能进行clone;
master/slave:只能运行于2个节点上,一主一从;
**资源粘连性stickiness**
表示资源是否倾向于留在当前节点
>0:倾向于留在当前节点;
<0:倾向于离开当前节点;
=0:由HA决定去留;
INFINITY:正无穷大,一定留在当前节点;
-INFINITY:负无穷大,一定离开当前节点;
**资源约束**
location straint,资源对节点的倾向性
资源的启动要有先后次序,需要对资源进行约束。
资源约束用以指定在那些集群节点上运行资源,以何种顺序装载资源,以及特定资源依赖于哪些其他资源;
pacemaker提供了三种资源约束方法:
location(位置约束):定义资源是否倾向于在哪些节点上运行;
colocation(排列约束):定义资源之间是否倾向于在某个节点上同时运行;
order(顺序约束):定义集群资源在节点上启动的顺序;
**法定票数quorum**
集群服务中的每个node都有自己的票数,票数是由DC负责统计,形成CIB(集群信息库),然后同步集群信息库到各节点上,只有quorum大于总票数的二分之一,集群服务才可以继续运行,当quorum小于总票数的二分之一时,会有以下动作:
ignore(忽略):当集群服务只有两个节点时,无论哪个节点挂掉,都切换node,所以忽略法定票数;
freeze(冻结):已经启动的资源继续运行,不允许新的资源启动;
stop(停止):停止集群服务,默认值;
suicide(自杀):将所有节点全部隔离;
**隔离fencing**
多台node在块级别共享存储写同一个文件时,文件系统就会崩溃,所以资源转移之前需要先完成其他节点的隔离,隔离有两个级别:
资源隔离:让被隔离主机不能再使用这个资源。如让隔离的主机不能访问共享存储;
主机隔离:直接让被隔离的主机关机。如通过STONITH让主机断电,强行关闭;
**如何避免脑裂**
在主备节点之间建立冗余物理连接同时传送控制信息
一旦发生脑裂,借助额外设备强制性的关闭其中一个节点;(STONITH,“爆头”,shoot the other node in the head)
实现HA集群高可用httpd服务
(1)两个测试节点,分别为node1.tz.com和node2.tz.com,ip地址分别为172.16.61.7和172.16.61.6、
(2)集群服务为httpd
(3)vip:172.16.61.9
(4)CentOS 7
**准备工作**
(1)所有节点的主机名必须互相进行解析,且与当前主机名相同
[root@node1 ~]# tail -2 /etc/hosts 172.16.61.7 node1.tz.com node1 172.16.61.6 node2.tz.com node2[root@node2 ~]# tail -2 /etc/hosts 172.16.61.6 node2.tz.com node2 172.16.61.7 node1.tz.com node1
(2)设定两个节点之间可以给予密钥进行ssh互信
[root@node1 ~]# ssh-keygen -t rsa [root@node1 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub 172.16.61.6[root@node2 ~]# ssh-keygen -t rsa -b 1024 [root@node2 ~]# ssh-copy-id -i /root/.ssh/id_rsa.pub 172.16.61.7
(3)两个节点之间时间必须同步
[root@node1 ~]# crontab -l */5 * * * * /usr/sbin/ntpdate 172.16.0.1 &> /dev/null[root@node2 ~]# crontab -l */5 * * * * /usr/sbin/ntpdate 172.16.0.1 &> /dev/null[root@node1 ~]# date;ssh root@172.16.61.6 'date' 2016年 02月 25日 星期四 11:03:47 CST 2016年 02月 25日 星期四 11:03:47 CST
**安装集群服务**
[root@node1 ~]# yum install -y corosync pacemaker;ssh 172.16.61.6 'yum install -y corosync pacemaker' #安装corosync+pacemakeryum install crmsh-2.1.4-1.1.x86_64.rpm ;ssh root@172.16.61.6 'yum install crmsh-2.1.4-1.1.x86_64.rpm' #安装crmsh,crm管理工具
**配置corosync**
[root@node1 corosync]# sed 's@^[[:space:]]\+\#.*@@' corosync.conf
# Please read the corosync.conf.5 manual page
totem {version: 2crypto_cipher: aes256 #对称加密算法crypto_hash: sha1 #消息认证摘要算法secauth:on #开启安全认证cluster_name: mycluster #定义集群名称interface {ringnumber: 0 #环号bindnetaddr: 172.16.0.0 #绑定的网络地址mcastaddr: 239.255.61.1 #多播地址mcastport: 5405 #多播端口ttl: 1 }
}logging {fileline: offto_stderr: noto_logfile: yeslogfile: /var/log/cluster/corosync.logto_syslog: nodebug: offtimestamp: onlogger_subsys {subsys: QUORUMdebug: off}
}nodelist { #定义节点node {ring0_addr:172.16.61.7 #ring0接口地址nodeid:1}node {ring0_addr:172.16.61.6nodeid:2}
}quorum {provider: corosync_votequorum #定义投票系统}[root@node1 corosync]# corosync-keygen -l #避免熵池阻塞,使用简单的随机数生成key
Corosync Cluster Engine Authentication key generator.
Gathering 1024 bits for key from /dev/urandom.
Writing corosync key to /etc/corosync/authkey.[root@node1 corosync]# scp -p corosync.conf authkey node2:/etc/corosync/ #将定义好的配置文件和密钥文件保持原有权限复制到node2上[root@node1 corosync]# systemctl start corosync #启动服务
[root@node1 corosync]# systemctl start pacemaker[root@node2 corosync]# systemctl start corosync
[root@node2 corosync]# systemctl start pacemaker[root@node1 corosync]# crm #在crm命令行接口中输入status查看状态
crm(live)# status
Last updated: Thu Feb 25 14:40:28 2016
Last change: Thu Feb 25 14:05:32 2016
Stack: corosync
Current DC: node1.tz.com (1) - partition with quorum
Version: 1.1.12-a14efad
2 Nodes configured
0 Resources configuredOnline: [ node1.tz.com node2.tz.com ] #在线的主机
**配置资源**
[root@node1 corosync]# yum install -y httpd #安装httpd服务 [root@node2 corosync]# yum install -y httpd [root@node1 corosync]# echo "<h1>node1</h1>" > /var/www/html/index.html #提供测试页 [root@node2 corosync]# echo "<h1>node2</h1>" > /var/www/html/index.html[root@node1 corosync]# crm crm(live)configure# property stonith-enabled=false #设置全局属性,因为没有stonith设备,所以要把此项改为false,因为默认值为true crm(live)# configure #进入configure接口进行资源管理 crm(live)configure# crm(live)configure# primitive webip ocf:heartbeat:IPaddr params ip="172.16.61.9" #添加名称为webip的资源,此资源为了实现配置访问web的vip crm(live)configure# show #show查看资源 node 1: node1.tz.com node 2: node2.tz.com primitive webip IPaddr \params ip=172.16.61.9 property cib-bootstrap-options: \have-watchdog=false \dc-version=1.1.12-a14efad \cluster-infrastructure=corosync \cluster-name=mycluster \stonith-enabled=false crm(live)configure# verify #检查配置是否有错 crm(live)configure# commit #提交此配置才能生效crm(live)# status #在全局中使用status可以查看资源是否运行 Last updated: Thu Feb 25 15:27:24 2016 Last change: Thu Feb 25 15:26:02 2016 Stack: corosync Current DC: node1.tz.com (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 1 Resources configuredOnline: [ node1.tz.com node2.tz.com ]webip (ocf::heartbeat:IPaddr): Started node1.tz.com #webip已经运行在node1上crm(live)configure# primitive webserver systemd:httpd #以systemd代理方式添加httpd服务。 crm(live)# status Last updated: Thu Feb 25 15:31:42 2016 Last change: Thu Feb 25 15:31:30 2016 Stack: corosync Current DC: node1.tz.com (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 2 Resources configuredOnline: [ node1.tz.com node2.tz.com ]webip (ocf::heartbeat:IPaddr): Started node1.tz.com webserver (systemd:httpd): Started node2.tz.com #没有添加约束规则服务会默认平均分散到各个节点上crm(live)configure# group webservice webip webserver #把两个依赖资源定义为一个组资源,谁在前谁先启动 crm(live)configure# verify crm(live)configure# commit crm(live)configure# cd crm(live)# status Last updated: Thu Feb 25 15:35:30 2016 Last change: Thu Feb 25 15:35:25 2016 Stack: corosync Current DC: node1.tz.com (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 2 Resources configuredOnline: [ node1.tz.com node2.tz.com ]Resource Group: webservice #此时两个资源已经添加到组资源中并在一个节点中启动webip (ocf::heartbeat:IPaddr): Started node1.tz.com webserver (systemd:httpd): Started node1.tz.com
**测试结果**
crm(live)node# standby #在node1中使用standby,使当前节点离线 crm(live)# status Last updated: Thu Feb 25 15:45:19 2016 Last change: Thu Feb 25 15:44:30 2016 Stack: corosync Current DC: node1.tz.com (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 2 Resources configuredNode node1.tz.com (1): standby Online: [ node2.tz.com ]Resource Group: webservice #组资源已经转移到node2上webip (ocf::heartbeat:IPaddr): Started node2.tz.com webserver (systemd:httpd): Started node2.tz.com
再次请求资源:
crm(live)node# online #因为没有定义位置倾向性,online node1后该组资源依然在node2上 crm(live)node# cd crm(live)# status Last updated: Thu Feb 25 15:46:39 2016 Last change: Thu Feb 25 15:46:34 2016 Stack: corosync Current DC: node1.tz.com (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 2 Resources configuredOnline: [ node1.tz.com node2.tz.com ]Resource Group: webservicewebip (ocf::heartbeat:IPaddr): Started node2.tz.com webserver (systemd:httpd): Started node2.tz.com
**管理资源**
crm(live)# resource #使用resource接口管理资源 crm(live)resource# statusResource Group: webservicewebip (ocf::heartbeat:IPaddr): Started webserver (systemd:httpd): Started crm(live)resource# stop webservice #关闭组资源crm(live)# configure crm(live)configure# delete webservice #删除组资源方式一 crm(live)configure# edit #使用编辑命令调用vim进行资源管理 node 1: node1.tz.com \attributes standby=off node 2: node2.tz.com primitive webip IPaddr \params ip=172.16.61.9 primitive webserver systemd:httpd property cib-bootstrap-options: \have-watchdog=false \dc-version=1.1.12-a14efad \cluster-infrastructure=corosync \cluster-name=mycluster \stonith-enabled=false # vim: set filetype=pcmk:crm(live)configure# verify crm(live)configure# commit #提交配置选型,此时组资源已经被删除,但primitive资源还在 crm(live)configure# show node 1: node1.tz.com \attributes standby=off node 2: node2.tz.com primitive webip IPaddr \params ip=172.16.61.9 primitive webserver systemd:httpd property cib-bootstrap-options: \have-watchdog=false \dc-version=1.1.12-a14efad \cluster-infrastructure=corosync \cluster-name=mycluster \stonith-enabled=false
**进行资源监控**
资源的operations:start,stop,monitor
start:资源启动时的属性,例如,timeout
stop:资源停止时的属性,例如,timeout
monitor:
interval:监控采样的时间间隔
timeout:超时时长
crm(live)# status #删除之前定义的资源 Last updated: Thu Feb 25 17:34:44 2016 Last change: Thu Feb 25 17:34:37 2016 Stack: corosync Current DC: node1.tz.com (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 0 Resources configuredOnline: [ node1.tz.com node2.tz.com ]crm(live)configure# primitive webip ocf:heartbeat:IPaddr params ip="172.16.61.9" op monitor interval=15s timeout=20s #对webip资源进行monitor的operations,并指明监控时间间隔为15s,超时时长为20s crm(live)configure# primitive webserver systemd:httpd op monitor interval=20s timeout=20s #对webserver进行monitor监控,时间间隔为20s,超时时长为20s crm(live)configure# verify crm(live)configure# commitcrm(live)configure# colocation ip-with-server INF: webserver webip #定义排列约束 crm(live)configure# verify crm(live)configure# commit crm(live)configure# order webip-before-webserver mandatory: webip webserver #定义顺序约束 crm(live)configure# verify crm(live)configure# commit crm(live)configure# show node 1: node1.tz.com \attributes standby=off node 2: node2.tz.com \attributes standby=off primitive webip IPaddr \params ip=172.16.61.9 \op monitor interval=15s timeout=20s primitive webserver systemd:httpd \op monitor interval=20s timeout=20s colocation ip-with-server inf: webserver webip order webip-before-webserver Mandatory: webip webserver property cib-bootstrap-options: \have-watchdog=false \dc-version=1.1.12-a14efad \cluster-infrastructure=corosync \cluster-name=mycluster \stonith-enabled=false \default-resource-stickiness=0crm(live)# status Last updated: Thu Feb 25 18:16:11 2016 Last change: Thu Feb 25 18:16:07 2016 Stack: corosync Current DC: node1.tz.com (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 2 Resources configuredOnline: [ node1.tz.com node2.tz.com ] #资源已经启动webip (ocf::heartbeat:IPaddr): Started node1.tz.com webserver (systemd:httpd): Started node1.tz.com[root@node1 ~]# killall httpd; systemctl start nginx.service #在node1上手动停掉httpd并瞬间启动nginx crm(live)# status Last updated: Thu Feb 25 18:21:53 2016 Last change: Thu Feb 25 18:16:07 2016 Stack: corosync Current DC: node1.tz.com (1) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 2 Resources configuredOnline: [ node1.tz.com node2.tz.com ] #资源切换到node2上webip (ocf::heartbeat:IPaddr): Started node2.tz.com webserver (systemd:httpd): Started node2.tz.com Failed actions:webserver_start_0 on node1.tz.com 'not running' (7): call=54, status=complete, exit-reason='none', last-rc-change='Thu Feb 25 18:19:49 2016', queued=2001ms, exec=2ms
实现HA集群高可用httpd服务+NFS文件存储
**准备工作**
额外提供一台主机作为NFS
IP:172.16.61.2
**配置NFS服务**
[root@localhost ~]# mkdir -pv /data/web #创建一个文件作为共享文件 mkdir: 已创建目录 "/data" mkdir: 已创建目录 "/data/web" [root@localhost ~]# echo "/data/web/ 172.16.0.1/16(rw,no_root_squash)" > /etc/exports #定义共享文件 [root@localhost ~]# echo "<h1>NFS</h1>" > /data/web/index.html #提供资源测试页 [root@localhost ~]# systemctl start nfs-server #启动nfs服务[root@node1 ~]# mount -t nfs 172.16.61.2:/data/web /var/www/html #测试node1是否可以挂载NFS [root@node1 ~]# cat /var/www/html/index.html <h1>NFS</h1> [root@node2 ~]# mount -t nfs 172.16.61.2:/data/web /var/www/html #测试node2是否能够正常挂载NFS [root@node2 ~]# cat /var/www/html/index.html <h1>NFS</h1>
**配置高可用资源**
crm(live)configure# primitive webstore ocf:heartbeat:Filesystem params device="172.16.61.2:/data/web" directory="/var/www/html" fstype="nfs" op start timeout=60s op stop timeout=60s op monitor interval=20s timeout=20s crm(live)configure# verify crm(live)configure# commitcrm(live)configure# group webservice webip webstore webserver #将三个资源定义到一个组内 crm(live)configure# order web-webstore-before-webserver mandatory: (webip webstore) webserver #定义顺序约束 crm(live)configure# verify crm(live)configure# commit crm(live)configure# show node 1: node1.tz.com \attributes standby=off node 2: node2.tz.com \attributes standby=off primitive webip IPaddr \params ip=172.16.61.9 \op monitor interval=15s timeout=20s primitive webserver systemd:httpd \op monitor interval=20s timeout=20s primitive webstore Filesystem \params device="172.16.61.2:/data/web" directory="/var/www/html" fstype=nfs \op start timeout=60s interval=0 \op stop timeout=60s interval=0 \op monitor interval=20s timeout=40s group webservice webip webstore webserver order web-webstore-before-webserver Mandatory: ( webip webstore ) webserver property cib-bootstrap-options: \have-watchdog=false \dc-version=1.1.12-a14efad \cluster-infrastructure=corosync \cluster-name=mycluster \stonith-enabled=false \default-resource-stickiness=0 \last-lrm-refresh=1456401974
**测试**
crm(live)# node standby #使node1离线
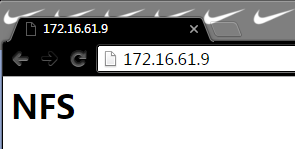
转载于:https://blog.51cto.com/tz666/1745107
HA(高可用)集群之AIS(corosync),高可用httpd+NFS相关推荐
- 高可用集群技术之corosync应用详解(一)
Corosync概述: Corosync是集群管理套件的一部分,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等.它是一个新兴的软件,2008年推出,但其实它并不是一个真正意义 ...
- HA集群之三:corosync+pacemaker实现httpd服务的高可用
一.基础概念 1.集群的组成结构 HA Cluster: Messaging and Infrastructure Layer|Heartbeat Layer 集群信息事务层 Membership L ...
- k8s高可用集群多个主节点_k8s-高可用集群实现(keepalived)
一 环境规划 大致拓扑: 我这里是etcd和master都在同一台机器上面 二 系统初始化 三 安装k8s和docker 四 安装keepalived 在三台master节点上安装 yum -y in ...
- linux高可用集群(HA)原理详解
高可用集群 一.什么是高可用集群 高可用集群就是当某一个节点或服务器发生故障时,另一个节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服 ...
- HA集群实现原理 切换 JAVA_HA(一)高可用集群原理
高可用集群原理 LVS集群DR模式简单的架构图如下所示: 在上图的架构中,当Director服务器因软件.硬件.人为原因造成故障时,整个集群服务不可用,因此,需要再添加一台服务器实现Director服 ...
- 基于Kubeadm部署Kubernetes1.13.3 HA 高可用集群
Table of Contents 目录 基于Kubeadm部署Kubernetes1.13.3 HA 高可用集群 01. 部署目的 1.1 Kubernetes的特性 1.2 贴微服务,开发环境快速 ...
- Web服务器群集——LVS-DR+Keepalived高可用集群
LVS-DR+Keepalived高可用集群 什么是高可用集群? 高可用集群的衡量标准 自动切换/故障转移(FailOver) 自动侦测 脑裂 常见解决方案 Keepalived Keepalived ...
- k8s高可用集群_搭建高可用集群(实现方式介绍)---K8S_Google工作笔记0054
技术交流QQ群[JAVA,C++,Python,.NET,BigData,AI]:170933152 然后我们来说搭建高可用集群,为什么要搭建高可用集群. 因为,首先我们说master节点是用来管理其 ...
- 搭建Eureka高可用集群
做的快哭了已经 文章目录 Eureka可用高集群的搭建 一.Eureka的工作原理 二.Eureka中服务提供者与服务消费者的关系 三.搭建Eureka-Server和Eureka-Client 四. ...
最新文章
- 全栈工程师的学习笔记与工作记录
- ThinkPHP下隐藏index.php以及URL伪静态
- nohup不输出日志信息的方法,及linux重定向学习
- .gitignore总结
- Sass--伪类嵌套
- jquery取复制函数注意点
- 【C语言】中的stdbool.h头文件
- VirtuoZo数字摄影测量(三)——影像匹配、DEM生成和正射影像拼接
- mac os 录屏快捷键_免费的录屏软件有哪些?不限制时长的录制软件
- 有些软件,听着听着就没了...
- 小程序 实现手写签名功能
- QListWidget自定义item的两种方式(二)——使用QWidget作为item
- Python 爬取“微博树洞”详细教程
- ISCC 2022 部分
- bugkuctf 游戏通关玄学式速通
- antd vue table ellipsis属性不生效
- vue高德地图点击放大Maker
- 声网 Token 鉴权机制,以及常见的问题
- 神州战神win10+ubuntu双系统制作
- android中基于蓝牙开发的demo