Warp : Haskell 的高性能 Web 服务器(译文)
Warp : Haskell 的高性能 Web 服务器(译文)
按
GHC 7.8 马上就要发布了。一个很大的改进就是加入了本文所说的并行 IO 管理器。从此之后 Haskell 在高性能服务器领域将不再会有对手。即使nginx和Erlang也无法撼动了。绝对在 c1000k 竞赛中遥遥领先。
Kazu Yamamoto 和 Michael Snoyman 是网络编程和高手,这篇文章记录了他们创造荣耀的过程。我的翻译想必是错误百出,建议英语过了三级的同学都去看原文,原文绝对精彩。原文在:POSA:Warp。话说AOSA每篇文章都相当不错。
Warp
作者: Kazu Yamamoto, Michael Snoyman and Andreas Voellmy
Warp 是 Haskell(一种纯函数式编程语言)的一个高性能的 HTTP 服务器端程序库。Yesod 和 mighty都是用 Warp 来实现的,Yesod 是一个 web 应用框架,mighty 则是一个 HTTP 服务器。我们做过测试,mighty 的性能可以与 nginx 相提并论了。这篇文章将会阐述 Warp 的架构以及为什么它能达到这样的性能。Warp能运行在 Linux,BSD 系列,Mac 和 Windows 上,但简单起见,我们只谈 Linux 环境。
Haskell 中的网络编程
很多人会觉得 FP 语言都是慢如蜗牛而且很不实用。其实不然,Haskell 就提供的一个近于完美的网络编程方法,这得力于 Haskell 的旗舰编译器 GHC。GHC 提供了轻量且强健的用户态线程。这一节我们就来回顾一下常见的几种服务器端网络编程模型,然后和 Haskell 比较一下。我们得到的结论是:Haskell 的便捷的抽象能力让程序员第一次有机会编写出清晰,简单的代码,同时GHC 精致的多核运行时系统又能把代码的运行速度提高到和 NB 的 C 程序员手写优化过的代码一样快。这在以前是不可想象的。
多线程
传统的网络服务器程序会用多线程来处理并发。在这种架构下,每个连接会起一个系统线程或 OS 进程来处理。这一架构的变种也有用线程池的,也就是预先起一大堆线程(或进程)。Apache 是就是一个典型的例子。
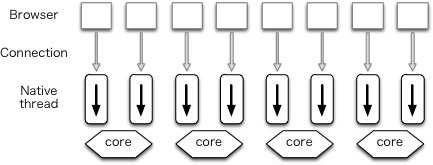 Native threads
Native threads
这种架构是优点在于,开发者可以写出简单的代码,只需在熟悉的控制流下编写处理输入,生成输出的代码就行了。这种架构也能利用现代 CPU 的多核能力。其缺点则是连接数一多,系统进程,系统线程频频进行上下文切换,性能会下滑得很厉害。
事件驱动
高性能服务器领域,事件驱动模型最近变得很流行了。这个架构下,多个连接是用一个进程(线程)来处理的。lighttpd 是用这个架构的一下例子。
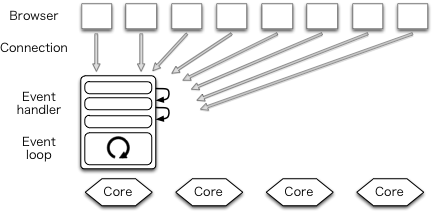 Event driven
Event driven
由于没有进程切换,上下文切换也就很少,性能自然也就上去了。这是其优点。
不过,这个架构也让网络编程变得异常复杂。这样说吧,事件驱动架构把程序的控制流反转了,程序员得把他们自然的逻辑分解重构成各种不阻塞的事件处理函数。程序员不能调用阻塞的 IO 函数,只能使用一些比较复杂的异步调用,常用的异常处理方法也不能用了。
每核一进程
很多聪明的家伙马上就想到了:在 N 个核的每个核上创建一个事件驱动的进程,每个进程称为一个worker。这需要在多个进程之间共享一个端口,用预创建(Prefork)就可以共享端口。
传统的多进程方式下,有新的连接进来了才 fork,预创建的话连接还没进来就先创建好进程了。这个 Prefork 和 Apache 的 prefork 模式名字一样,但其实不是一回事。
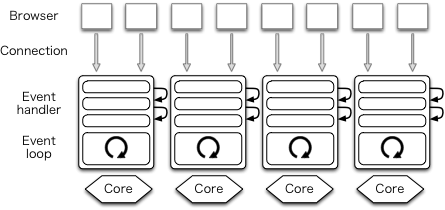 One process per core
One process per core
nginx 用的就是这个架构。Node.js 从前只用事件驱动,现在它也实现了这种预创建的技术。不过这种技术无法解决程序不易读写的问题,还是有很多的回调函数要写。
用户态线程
GHC 的用户态线程可以解决程序结构不清晰的问题。具体来说,我们可以为每一个 HTTP 连接创建一个用户态线程。每个用户态线程的处理逻辑和传统的阻塞方式一样。我们的程序又回到朴素的简单的状态,但是 GHC 又能将我们的代码转换成复杂的异步 IO,并跑在多个核上。
深入一点细节的话,GHC 把用户态线程分用到少量的系统线程上。GHC 的多核运动时能轻巧的调度海量用户态线程,不会引起系统级上下文切换。
GHC 的用户态线程是很轻量的,当代的机器跑 100000 个用户线程是毫无压力。而且相当健壮,异步的异常能被妥善处理。见Warp 的架构 和 文件描述符计时器。此外,GHC 的调度器能在多核之间做负载均衡调度,充分利用多核。
用户调用的接口,逻辑上是阻塞的 IO 调用,比如读写 socket,实际上最终运行的是异步版本的 IO 调用:如果此次调用数据 ready 的话,用户线程当然不阻塞直接继续运行了;如果数据不 ready 需要等待的话,线程实际上在其需要的数据条件上注册一下告诉调度器说它在等这个事件。调度器会监测各种 IO 事件并通知各等待着的线程,让他们重新运行起来。这一切都发生在 Haskell 的运行时,对用户是透明的,完全不用程序员参与。
Haskell 里面几乎所有数据结构都是不可修改的,这也意味着,多数函数都是线程安全的。GHC 在什么是时候会切换用户线程呢?答案是在分配内存的时候。Haskell 的数据不可修改使得实际上新的数据,新的内存是不停的在分配的,所以这个粒度是足够的。不明白的话可以参看一下:such data allocation occurs regularly enough for context switching。
在 Haskell 之前其实有很多语言已经实现用户态线程了,但它们未得到广泛应用可能是因为它们要么不轻量,要么不健壮。另外有些语言则是实现了协程(coroutine)库,协程调度则是非抢占(non-preemptive)式的。Erlang 和 Haskell 一样,提供的是轻量级线程,Go 语言则使用轻量级协程(goroutine)。
作者写这篇文章的时候 mighty 使用 prefork 技术来利用多核,因为 Warp 还不支持。下图展示了这一架构。每个用户连接用一个用户态线程来处理,每个用户态线程又是在一个系统线程上跑,N 个核上又跑着 N 个系统线程。 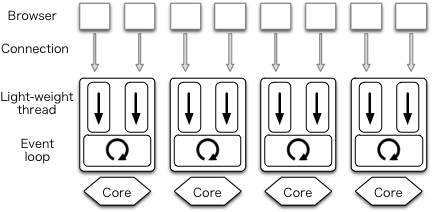
我们发现 GHC 运动时库中的 IO manager 组件是一个性能瓶颈。为了解决这个问题,我们开发了一版parallel IO manager,通过在每个核上都跑一个事件注册表和事件监测器极大的提升了在多核上的可扩展性。使用了这个并行 IO 调度器的 Haskell 程序跑在多核上时,会起多个 IO 调度器来利用多核。每个用户态线程会被调度到其中的一下核上。
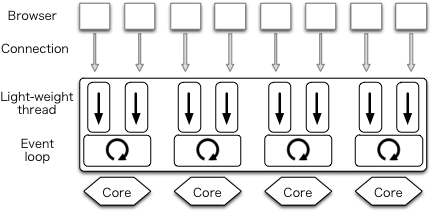 User threads in a sigle process
User threads in a sigle process
包含这个新的并行 IO 调度器的 GHC 新版本会在 2013 年秋天发布(译者注:已然跳票,我都要穿冬衣了也还没用上 7.8)。Warp 不用任何修改就能用上多核了,mighty 用的 prefork 也可以退休了。
Warp 的架构
Warp 是个网络应用接口(Web Application Interface,WAI) 的引擎。它是运行在 HTTP 协议上的 WAI 应用。上面提到的 Yesod 和 mighty 就是 WAI 应用的例子。
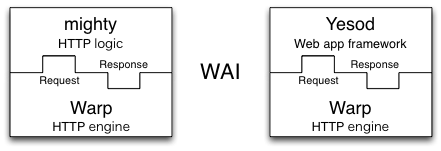 Web Application Interface (WAI)
Web Application Interface (WAI)
WAI 应用的类型如下:
type Application = Request -> ResourceT IO Response
Haskell 中,函数的参数类型是用右向箭头隔开的,最右边的一个类型则是函数的返回类型。上面的定义的含义是:WAI 应用接收一个 Request 并返回一个 Response,ResouceT IO 表示这个地方可能需要用到可控的 IO。
一个连接过来后,一个专门的用户态线程就会创建(spawn)来处理之。这个线程先接收客户端的 HTTP 请求,解析成一下Request,然后 Warp 把这个Request 传给这个 WAI 应用,并等待它的一个Response返回。最后,Warp 根据Response生成 HTTP 返回,并通过网络发送给客户端。如下图。
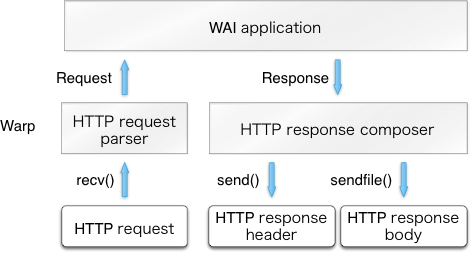 The architecture of Warp
The architecture of Warp
用户线程不断的重复上面的步骤,直到该连接被客户端断掉或者收到了错误的请求,或者这个用户线程很久没有收到一定量网络数据,也会被一个特殊的管理线程给喀嚓掉。
Warp 的性能表现
在介绍我们如何改善了 Warp 的性能前呢,我们先来看一下我们优化后的结果。下面的结果是用 2.8.4 的mighty(采用 Warp 1.3.8.1) 和 1.4.0 的nginx跑出来的。
压测的环境如下:
- 1Gpbs 以太网连接的 “12 核” 两台机器(Intel Xeon E5645, 双网卡, 双 CPU,每个 CPU 带 6 个核)
- 一台运行 Linux 3.2.0(Ubuntu 12.04 LTS)
- 另一台跑的是 FreeBSD 9.1
测试工具我们用过不少,早前我们用的是httperf,不过我们发现其用的是select调用,而且是单线程的,很快就测试就跟不上多核 HTTP 服务器的性能了。所以我们就切换到weighttp上,它用的是libev(和 epoll 是一路的)能跑在多核上。在 FreeBSD 上我们这样起了一个weighttp:
weighttp -n 100000 -c 1000 -t 10 -k http://<ip_address>:<port_number>/
这样我们就用 10 个线程起了 1000 个 HTTP 连接,每个连接发送 100 个请求来测试。
被测试的网络服务器则是跑在 Linux 上。对于每个请求,它返回一个index.html。用的是nginx的默认index.html,大小为 151 字节。
Linux/FreeBSD 都有许多参数可以调。最好仔细调一下这些参数。ApacheBench & HTTPerf是一个不错的教程。对mighty和nginx下面的东东一定是要调一下的:
- 打开文件描述符缓存
- 关闭日志
- 关闭限速
跑的结果:
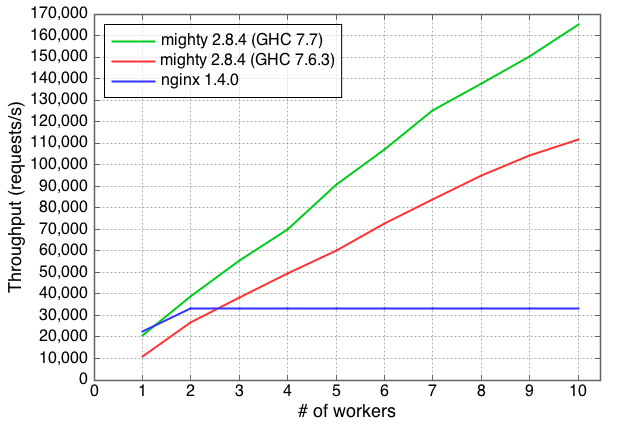 Performance of Warp and
Performance of Warp and nginx
x 轴是 worker 数,y 轴是每秒的吞吐量。
mighty 2.8.4 (GHC 7.7): 用 GHC 7.7.20130504 (可以看成是 GHC 7.8)编译的。用上了并行的 IO manager,只起了一个 worker。给 GHC 的运行时参数是
+RTS -qa -A128m -N<x>, 是机器核数,128m 是 GC 的内存分配空间大小。mighty 2.8.4 (GHC 7.6.3): 用当前稳定版 GHC 7.6.3 编译的结果。
关键点
在实现高性能的 Haskell 服务器上我们总结了 4 个关键点:
- 系统调用调得越少越好
- 减少重复计算,优化每个函数实现
- 不要用锁
- 使用正确的数据结构很重要
系统调用调得越少越好
尽管系统调用在现代操作系统上一般都不怎么耗时,但只要调用得够多,也能成为一个大问题。实际上 Warp 处理每个请求调用了几个系统调用,有用recv(),send()和sendfile() (这货能让文件拷贝一点不走用户空间)。其他的系统调用如open(),stat(),close() 就被优化掉了。下面有一节 (文件描述符计时器) 会再说这个细节。
我们用strace命令来跟踪最后调的系统调用。我们发现nginx居然用了一个我们不知道的accept4。
在 Haskell 的标准网络库里,监听一个 socket 是会用上非阻塞的标志的,不过新连接过来时也要将这个进来的 socket 再设置一下这个非阻塞标志。标准库是这么搞的:调用了两次fcntl(),一次获取当前标志,另一次再设置新的非阻塞标志。
Linux 下即使监听的 socket 是有非阻塞标志,新连接过来的 socket 也是默认不设置非阻塞标志的。accept()已经是这样的了,所以就有这个accept4(),它可以在新连接过来时设置好非阻塞标志,这样那两次fcntl()调用就避免了。这一改动已经合到标准库里了。
减少重复计算,优化每个函数实现
GHC 有提供调优手段,不过限制不少。只有单进程程序的调优才准确。这样我们只能搞点非常规手段了。
mighty考虑了这种情况。当我们配置mighty的 worker 数 N 多于 2 时,它会创建 N 个工作进程,父进程只用来收发控制信号。不过如果 N 为 1,则根本就不多创建进程了,初始进程就用来服务 HTTP 请求。另外如果有设置调试模式的话,mighty也会保持在终端运行(不变成后台进程)。
调优mighty的时候我们震惊的发现标准库里的时间格式化函数占了程序的多数时间。我们知道,HTTP 服务器是要在 Header 里返回 Date:,Last-Modified: 等的:
Date: Mon, 01 Oct 2012 07:38:50 GMT
所以呢,我们就重实现了一下专门的 GMT 时间格式化函数。用 Haskell 的一个标准性能测试库criterion测试结果显示,我们的函数快不少。这样就够了么?其实在同一秒内有多个 HTTP 请求,我们需要多次格式化时间么,其实是不需要的,所以我们缓存一秒内的时间格式化结果就行了。
减少重复计算,优化函数实现在实现解析器和Composer for HTTP response header上还会再讲。
不要用锁
不必要的锁是程序的罪恶源泉。有时候我们不知不觉就用了不少锁,假如运行时和库用了锁。要实现高性能服务器的话,我们就要找出这些锁来,尽可能地避免之。需要指出的是,锁在并行 IO manager 中更加致命。怎么找锁,怎么避免的话题放在连接计时器和内存分配章节。
使用正确的数据结构很重要
Haskell 处理字符串的标准库是 String,String不过是 Unicode 字符的链表。链表是 FP 的心脏,所以String还是很方便的。不过对于我们的高性能服务器来说,链表的性能远远不行,Unicode 也太复杂了,HTTP 其实是一面向字节流的协议。
所以,我们用ByteString来处理字节串(或 buffer)。ByteString是带元数据的字节数组。有元数据的话,我们切分字符串基本就不用拷贝字节了。下面实现解析器部分还会细讲。
关于数据结构的例子还有Builder和双重IORef。见Composer for HTTP response header和连接计时器。
HTTP request parser
除了高效的并发和多核环境下的 I/O 之外,其它方面也是要考虑的。在每个核上 Warp 也自然要都高效才行。这里最重要的就是 HTTP 的 request 解析了。它需要从 socket 中的字节流解析岀请求行(request line)和诸多 header,不过 body 就留给应用自己处理。它解析出的信息要传给应用(Yesod 应用也好,mighty应用也好)去构建 response.
处理这个请求 body 也颇考验功力。Warp 完全支持 HTTP 的流水线(pipelining)和分块(chunked)。这样 Warp 就得“组块”(de-chunk)被分块的请求。支持流水线时,会在一个连接里传送多个请求,Warp 就必须保证应用不会拿到过多的数据,把下一个的 request 的一部分数据也给偷走了,也要保证不残留数据,不然下一个 request 就不知道从哪开始读数据了。
举个简单的例子,假设用户发了这样个请求过来:
POST /some/path HTTP/1.1 Transfer-Encoding: chunked Content-Type: application/x-www-form-urlencoded0008 message= 000a helloworld 0000GET / HTTP/1.1
HTTP 解析器得提取/some/path和Content-Type出来传给应用。应用开始读数据话话,Warp 还得把 chunk 头(0008,0001和0000)给屏蔽掉,把真正的内容(message=helloworld)传给应用。也不能多读,读完0000这个 chunk 尾巴就该收手了,不要影响下一下流水线请求(GET / HTTP/1.1)。
实现解析器
Haskell 的强大解析能力是名声在外的。传统上解析用的是组合子(combinator)来组织程序,比如Parsec和Attoparsec。Parsec和Attoparsec的文本解析模块是基于 Unicode 的,显然在 HTTP 头这种纯 ASCII 的协议解析上面毫无必要,而且开销太大了。
Attoparsec其实也是提供了二进制解析接口的,避开 Unicode 开销,这已经是性能极好的库了。但是比手工裸写的解析器还是有差距的,Warp 里我们就自己手动解析。
这里我们小小科普一下,我们的字节数据是怎么在内存里放的。答案是ByteString,ByteString其实由三部分组成的:指向一块内存的指针,数据开始的 offset,和数据的大小。
初看之下这个 offset 信息是多余的,指针的位置就可以当成是我们数据的开始位置。有这一个 offset 的好处是我们可以多个ByteString之间共享那一块内存的不同部分(所谓的切分,splicing)。那这些数据共享会不会引起篡改问题呢?Haskell 的所有数据结构都是不可变的,因此也就没有篡改这一说了。当没有ByteString引用那块内存时,它也就被回收了。
这种安排正合我们的意,客户端来了一个请求,Warp 分配一下比较大(目前为 4096 字节)的一个 chunk 来存放请求行和请求 header,大部分情况下都能放下。然后 Warp 就用我们手写的解析器来解析。来看一下为什么能解析得飞快:
在内存块中我们只用查找换行符就行了,bytestring 库中的查找函数是用 C 函数中的像
memchr来实现的,非常之快。(有些多行的 header 要复杂一些,不过原理是一样的)解析过程根本不用再分配内存了,字符串切分直接指向原来的大内存块(见下图)。这里我们可以自豪一下,这里的做法比 C 语言里面的一般字符串处理还高效。C 语言里,字符串是用结尾的,切分字符串导致内存的不断分配和拷贝。
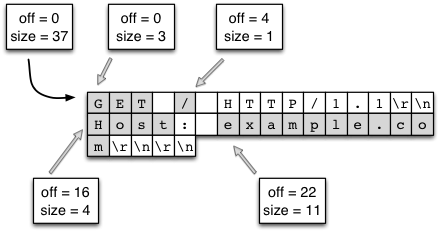 Splicing ByteStrings
Splicing ByteStrings
切行切完了,用相同的技术我们又在行内切 key/value 对。请求行要切得比较细。比如有一个请求行是这样的:
GET /buenos/d%C3%ADas HTTP/1.1
切分需要如下步骤:
分出请求的 method,path 和 version。
path 要用
/给切成小块:["buenos", "d%C3%ADas"]。URL decode 一下 path 的每一块
["buenos", "d\195\173as"].UTF8 decode 一下 path 的第一块,整出一下 Unicode
text文本:["buenos", "días"]。
这个解析过程也很快:
和换行符切分一样,
/查找也是飞快的。URL decode 用的是打表,没有分支,每次都是一个内存寻址就行了。
text库处理 UTF-8很高效。其内存也很紧凑。Haskell 还有延时示值的特性,比如你不需要用到 path,那么相应的解析代码就不会执行。
最后还剩的就是“合块”了,这个就更简单了。解析一个 16 进制数字,再读这么多个数字的字节,最后再合在一起。这里也没有内存的拷贝。
Conduit
本文提到很多次替应用解析 request body 的事,也提到应用生成 response 传回给 server,server 再把数据组织起来发送给 socket。还有一个模块我们还没提到的是 中间件(middleware)。它处在应用和我们的 server 之间,能够对 request 和 response 做修改。
看一下中间件的定义吧:
type Middleware = Application -> Application
直观的看中间件就是把一个应用给改造一下,预处理一下 request,修改一下 response。可能给个例子大家就很好理解了,比可一个 gzip 中间件,它呢自动的压缩应用返回的 response,并加上相应的 HTTP header。
中间件需要就是修改应用的输入输出流。传统上 Haskell 对付这个问题的方法自然的 lazy I/O,输入输出都被抽象成一个延时求值的数据结构,处理逻辑都是在操作这个数据结构就行了。可惜的是对于一个高吞吐的服务器,lazy I/O 的问题在于其资源释放的不及时上。如比负载一高可能文件描述符释放不了用耗尽了。
我们可以用偏底层的抽象来直接读写数据,不过这和 Haskell 的高级抽象能力就背离了。不仅代码难以分析,一些个常见问题也不方便处理。例如,我们经常要缓冲(buffering)数据,先读进来一大块数据进来(如处理 request header),剩下的数据交给另一个模块(web应用)去读。
为了解决这一矛盾,我们决定在conduit包上实现 WAI 协议(Warp 自然也是)。conduit包提供了数据流的抽象,并和 lazy I/O 很大部分是兼容的,也提供了缓冲的方法,还保证资源的立即释放。异常处理也不会混在数据处理中,被隔离到它 IO 处理中,到它该去的地方。
Warp 把客户端来的字节流组成一个Source,给客户端的字节流则组成一个Sink。给Application一个Source,它也返回一个Source。中间件能拦截 request 和 response的Source,并施加修改。下图展示了中间件在应用间的关系,使用conduit包让程序的组合变得很简单。
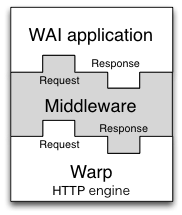 Middlewares
Middlewares
还用 gzip 中间件的这个例子,刚开始有一个Source是应用的输出,它接到gzip conduit上,Source不断输出字节,couduit中的zlib包不断读入这些字节,然后输出压缩后的字节,又接到 Warp 或者别的中间件上。最终 Warp 把压缩后的数据通过 socket 传给客户端。在这过程中,只消耗了最少的内存,网络断开的话,剩余的压缩都不会继续。这样 CPU 和垃圾收集器的开销都已经是最小的了。
说起 conduit,这又是一个很大的话题,这里就不多说了,只要知道用 conduit 是 Warp 获得高性能的一个重要因素就行了。
Slowloris 攻击防护
有一个问题是值得我们关注的: slowloris 攻击(慢速连接攻击)。这是一种拒绝服务攻击(Denial of Service,DOS)。攻击者通过慢速发送请求,可以在同样的硬件和带宽的发起更多连接,不管这些连接上有没有数据在传送,每个连接都会消耗服务器的一定资源。当这种连接太多时,服务器的资源就会不够。因此,要是一个连接长时间不发送一定量的数据,我们得把这个连接给断了。
下面我们讲讲超时管理器,它是 slowloris 攻击检测中的核心。每个连接上有个计时器,每当有数据来这个计时器就被更新一下。Warp 中这是在 conduit 这一级就做好了。上面提到输入数据是一个Source,每当一个新数据 chunk 来了,计时器就更新一下。这个更新就只是一个内存修改,所以是很快的,slowloris 检测基本对我们的性能不会有太大的反作用。
HTTP response composer
这节谈谈 Warp 中的 HTTP response 组织。一个 WAI Response 可以有三种情况:
ResponseFile Status ResponseHeaders FilePath (Maybe FilePart) ResponseBuilder Status ResponseHeaders Builder ResponseSource Status ResponseHeaders (Source (ResourceT IO) (Flush Builder))
ResponseFile:结果是个静态文件,ResponseBuilder 和 ResponseSource:结果是内存中动态生成的。每个结果都有Status和ResponseHeaders。ResponseHeaders就是 key/value header 对的一下列表。
Composer for HTTP response header
以前我们用Builder来生成 HTTP response。首先,把Status和每个ResponseHeaders分别转成Builder,这些都是 O(1) 的复杂度。最后把这些Builder复制到最终的 buffer 中,复杂度为 O(n)。
说起来这Builder的性能应该是足够了,但对于我们的超高性能服务器来讲稍有不逮。现在我们是直接用 C 的memcpy()来搞。
Composer for HTTP response body
ResponseBuilder和ResponseSource包含的Builder已经是一个ByteString的列表了,我们把 header 的ByteString附到这个列表的最前面,然后send()它们,这过程只用一个定长比较少的内存。
ResponseFile呢,Warp 用send()发送 header,用sendfile()发送 body。如果这里有缓存,open(),stat(),close()和其它一些系统调用都不用了可能。ResponseFile还有其它的一些优化细节,我们再讲讲。
Sending header and body together
我们测 Warp 发送静态文件时发现,要是并发请求多的话,结果很快,但如果只有一个连接的话,Warp 其实是不快的。
用tcpdump来观测发现,Warp 用writev()来发送 header,用sendfile()来发送 body。header 和 body 是走两个 TCP 包。
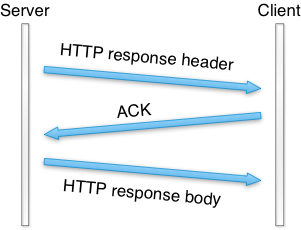 Packet sequence of old Warp
Packet sequence of old Warp
为了能够在一个 TCP 包中就发送完,我们改了一下 Warp,把writev()调用改成send(),在send()加上MSG_MORE标志位,然后接上一个sendfile(),header 和 body 就在一个 TCP 包里就发送了。提高了 100 倍的性能。
超时和清理
这节阐述连接超和缓存文件描述符。
连接计时器
为了防备 slowloris 攻击,用户长时间不多发点数据连接就被掐断了。Haskell 有个库函数叫timeout:
timeout :: Int -> IO a -> IO (Maybe a)
第一个参数是超时毫秒数,第二个参数是一个 IO 操作。timeout函数返回一个 IO 类型的 Maybe a。Maybe 又是啥:
data Maybe a = Nothing | Just a
Nothing 说明有错误(不过没说原因),Just则是一个成功的结果a。所以 IO 操作没有在指定时间完成的话,timeout函数返回一个Nothing,反之则返回一个包在Just中的结果。这里也可以看出 Haskell 描述的方式多么流畅。
timeout对大多数人来说足够了,对于我们的高性能服务器来说,又不够。原因呢,timeout函数会起一个用户态线程,虽然上面我们说用户态线程很轻量,可是也还是有开销的,尤其调用太多次的话。我们要把这个超时处理中的用户态线程的创建给优化掉。做法是把超时统一给一个用户态线程管理。看一下要点:
- 双重
IORef - 安全交换与合并算法
假设每个连接的状态要么是Active,要么是Inactive。超时管理器不断的检查每个连接的状态,如果是Active,超时管理器就把它标记成Inactive,超时管理器就把相应的用户态处理线程给杀了。
每个状态是们保存在IORef里的。IORef是个引用,里面的数据是可以修改的(译注:和别的 Haskell 数据结构不同)。每个用户线程要不断的更新其状态为Active,不然就被杀了。
超时管理器用一下IORef的列表保存这个状态。每创建一个用户态线程,也要创建一下相应的IORef放到该列表中,状态为Active。这个列表是个关键的数据结构,对它要进行原子以保证一致性。
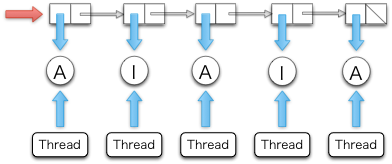 A list of status.
A list of status. A and I indicates Active and Inactive, respectively
一般 Haskell 用MVar来保证一致性,但是MVar用锁来保证一致性,太慢了。我们只好用IORef,并用atomicModifyIORef操作来保证一致性。atomicModifyIORef 是用 CAS(Compare-and-Swap)来实现的,比锁要快。
下面是我们交换和合并算法的一个大概:
do xs <- atomicModifyIORef ref (\ys -> ([], ys)) -- swap with an empty list, []xs' <- manipulates_status xsatomicModifyIORef ref (\ys -> (merge xs' ys, ()))
超时管理器先用一个空表把列表换出来,然后修改列表的状态,杀死Inactive的线程。此时并不影响新线程的加入(译注:加入到原来的空表中),它们可以用atomicMonifyIORef加入状态。最后超时管理器又原子地把两部分列表合并起来。Haskell 是延时求值的,这样这次合并操作是 O(1) 就返回了,实际的 O(n) 合并只有在下次读这个列表时才真正进行。
文件描述符计时器
考虑这种情况:Warp 需要用sendfile()发送一整个文件。不幸的是,Linux 平台下,先得调stat()函数得到文件大小,传给sendfile(FreeBSD/MacOS 可以用一个 magic number 0 表示整个文件)。
如果 WAI 应用事先知道文件大小,Warp 就不用调stat()了。缓存这个文件大小很容易,要注意的是内存中的大小可能会和实际不一致(修改过的话)。不过这个并不是个大问题,比如我们设置一个 10 秒种的缓存超时时间就没啥问题了。10 秒后缓存会被清理,不会泄漏。
sendfile要用文件描述符,调用open(),多次调用sendfile(),再close()是可以的。接下来,我们来讨论一下怎么缓存文件描述符,避免重复调用open()和close()。缓存的过程是这样的:先用open()打开一个文件描述符,后来如果别的线程也要用这个文件的话就直接能重用,过了一段时间没人用就可以把它关闭了。
有个简单的策略是引用计数,但我们不确定能不能实现一下健壮的引用计数器。如果用户线程发生异常,没有及时减掉引用计数器怎么办?文件描述符就泄漏了。我们发现连接超时管理器上的机制也能用在这里,也不需要引用计数器,不过重用也没这么简单就是。
每个线程有个自己的状态,状态是不共享的,文件描述符是需要共享的。所以得有个办法能快速查找某文件的对应描述符,列表是不能用了,太慢。一个文件可能同时被打开多次,我们就用了一个multimap 来存文件对应的描述符。
我们的 multimap 是查找时间复杂度为 O(log N),修改的复杂度为 O(N) 的红黑树。红黑树是二分查找娄,查找时间自然就是 O(log N),N 为节点数。把树变成个有序列表则要 O(N)。修改文件描述符用这样变换实现的。
未来展望
对于如何进一步优化 Warp,我们有许多想法,这里拿两个来讲一下。
内存分配
每次收发数据包,都需要分配内存 buffer。这些 buffer 以钉住(pinned)的形式分配,这样这些 buffer 可以在 C 和 Haskell 之间共享。我们希望每次系统调用收发的数据能多一点,这些 buffer 一般会是中等大小的。不幸的是,GHC 分配稍大一点(64 位机上是大于 409 字节)的钉住内存会用到运行时的一个锁。当内存频繁分配,机器超过 16 核时就成为了我们的系统瓶颈。
我们开始分析 HTTP response header 生成时,这种针住大内存的分配对性能的影响。GHC 对我们的提供了 eventlog 工具,它能记录每个事件的时间戳。在内存分配的前后我们挂上函数记录用户事件的时间,然后和mighty编译在一起,得到的事件日志(event log)结果如下:
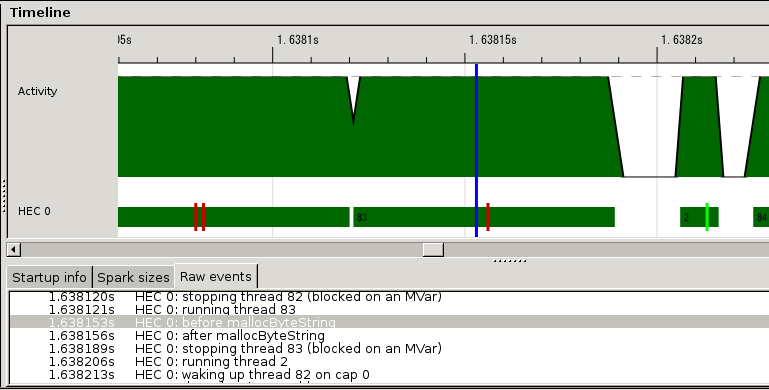 eventlog
eventlog
小红块就是我们挂上的事件,它们之间的时间自然就是内存分配的时间了。粗略估计大概占到 HTTP 会话中的 1/10。怎么实现一个无锁的内存分配算法,还在讨论中。
新式惊群
惊群(Thundering herd)是一下历久弥新的问题。
假设多个进程或系统线程预创建着监听同一个 socket。他们都在这个 socket 上accept()。一个连接进来,老版本的 Linux 和 FreeBSD 会唤醒所有这些进程,但只有一个进程拿到这个连接,其它进程接着 sleep。这样的上下文切换是个严重的性能问题。这就是所谓的惊 群。较新版本的 Linux 和 FreeBSD 只唤醒一个进程,所以这个问题已经成为历史了。
不过呢,新的网络服务器又开始用epoll系列函数。如果多 worker 共享一个 socket,用epoll系函数操作这个 socket,惊群问题又回到了我们眼前。这是因为epoll系函数会通知(唤醒)所有进程。nginx和mighty都是这种新式惊群的受害者。
如果用了并行的 IO manager 的话,这种新式惊群就没有了。在新的架构下,只有一个 IO manager 用epoll监听 socket,再将建立好的连接交给其它 IO manager 处理。
结论
Warp 是一个面面倶到的网络服务器库。为各种用途都提供了高效的 HTTP 通信方案。为了取得目前的高效,它在诸多级别上都做了大量的优化工作,如网络通信层,线程管理层,请求解析层。
Haskell 也被证明是写这种代码的惊艳的语言。默认数据只读等特性也让编写线程安全,少数据复制的代码成为可能。
多线程的运行时库使得写事件驱动的代码很简单。GHC 的强大优化能力也意味着我们可以写高阶抽象的代码,又能收获极致的性能。我们的性能如此之高,代码量却相对不多(写这篇文章时有 1300 行代码)。如果你有志于写可维护,高性能,并行化的代码,Haskell 绝对你是不该错过的。
Warp : Haskell 的高性能 Web 服务器(译文)相关推荐
- nginx高性能WEB服务器系列之九--nginx运维故障日常解决方案
nginx系列友情链接: nginx高性能WEB服务器系列之一简介及安装 https://www.cnblogs.com/maxtgood/p/9597596.html nginx高性能WEB服务器系 ...
- 分享关于搭建高性能WEB服务器的一篇文章
这篇文章主要介绍了Centos5.4+Nginx-0.8.50+UWSGI-0.9.6.2+Django-1.2.3搭建高性能WEB服务器的相关资料,需要的朋友可以参考下(http://m.0813s ...
- LEMP构建高性能WEB服务器(第三版)
LEMP 自动化编译脚本下载:http://docs.linuxtone.org/autoinstall/ (定期更新,欢迎多测试,找bug) 介绍参考:http://bbs.linuxtone.or ...
- nginx高性能WEB服务器系列之七--nginx反向代理
nginx系列友情链接: nginx高性能WEB服务器系列之一简介及安装 https://www.cnblogs.com/maxtgood/p/9597596.html nginx高性能WEB服务器系 ...
- Nginx高性能Web服务器实战教程PDF
网站 更多书籍点击进入>> CiCi岛 下载 电子版仅供预览及学习交流使用,下载后请24小时内删除,支持正版,喜欢的请购买正版书籍 电子书下载(皮皮云盘-点击"普通下载" ...
- 服务器后端开发系列——《实战Nginx高性能Web服务器》
1.高性能Web服务器Nginx的配置与部署研究(1)Nginx简介及入门示例 内容:概述Nginx的背景知识和简单的入门实例. 2.高性能Web服务器Nginx的配置与部署研究(2)Nginx入门级 ...
- Nginx高性能Web服务器详解
Nginx高性能Web服务器详解 1. 什么是Nginx 1.1 优点 1.2 缺点 2. Nginx负载均衡策略 2.1 轮询策略 2.2 加权轮询策略 2.3 IP hash策略 3. 常用指令 ...
- [nginx] LEMP构建高性能WEB服务器(第三版)
LEMP 自动化编译脚本下载:http://docs.linuxtone.org/autoinstall/ (定期更新,欢迎多测试,找bug) 介绍参考:http://bbs.linuxtone.or ...
- 基于linuxunix高性能web服务器架构思路分析
随着21世纪互联网的快速发展以及web2.0的诞生,最初web服务器已经不能满足我们的需求.而现在我们要考虑的不再仅仅是web服务器以及数据库服务器这么简单,我们所需要考虑的就是设计出一套高性能web ...
最新文章
- 物化视图基于rowID快速刷新
- zabiix监控磁盘io
- AIProCon在线大会笔记之华为涂丹丹:华为云EI,行业智能化升级新引擎
- android事件分发 入口(dispatchTouchEvent)
- mac运行python速度慢_python-3.x – Pygame简单循环在Mac上运行得非常慢
- 分析一下shell(转)
- .NET Core快速入门教程 1、开篇:说说.NET Core的那些事儿
- data fastboot 擦除_fastboot擦除恢复等待设备【专业修复数据】
- 常用的分布式唯一ID生成方案
- (转)淘淘商城系列——分布式文件系统FastDFS
- jwt如何防止token被窃取_如何使用 NodeJS 实现 JWT 原理
- url传值的一个问题解决
- mac vulkan_在 macOS 上开发 Vulkan 程序
- Moo Slidebox
- 服务器winsxs文件夹怎么清理工具,winsxs文件夹怎么清理 winsxs文件夹清理方法教程...
- 在编译命令行中添加 /D_SCL_SECURE_NO_DEPRECATE
- STAF 删除文件操作
- 计算机绘图快捷键,计算机绘图常用软件快捷键大全
- 04_UUID128修改与广播名
- 程序语言Python Tutorial(一):激发你的欲望 程序语言