基于OpenVINO与PP-Strucutre的文档智能分析 - 飞桨AI Studio
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
基于OpenVINO与PP-Strucutre的文档智能分析
本示例包含以下部分组成:
- 项目说明
- 环境准备
- 模型训练与验证
- 模型部署
一、项目说明
金融、医疗、科研等行业等行业用户在处理一些书面文档信息提取任务的时候,例如:技术文档翻译,历史数据电子化保存和金融报表录入等, 往往需要通过人工的方式逐字逐句地进行数据录入。利用人工智能技术可以这些非结构化的文档图片快速地转化为结构化的字符和图表,并基于word或excel形式进行保存,大大提高关键信息提取的效率,优化人力成本。
本项目将基于飞桨PP-Structure和英特尔OpenVINO的文档图片自动识别解决方案,主要内容包括:PP-Structure系统如何帮助开发者更好的完成版面分析、表格识别等文档理解相关任务,实现文档图片一键格式化;如何使用OpenVINO快速部署OCR,版面分析,表格识别等在内的PP-Structure系列模型,优化CPU推理任务性能,从而大大减少了手工录入数据的时间开销,助力企业办公智能化转型。

1. PP-Strucutre简介
PP-Structure是PaddleOCR团队自研的智能文档分析系统,旨在帮助开发者更好的完成版面分析、表格识别等文档理解相关任务。
PP-StructureV2系统流程图如下所示,文档图像首先经过图像矫正模块,判断整图方向并完成转正,随后可以完成版面信息分析与关键信息抽取2类任务。
版面信息抽取任务中,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别,如,将表格区域送入表格识别模块进行结构化识别,将文本区域送入OCR引擎进行文字识别,最后使用版面恢复模块将其恢复为与原始图像布局一致的word或者pdf格式的文件;
关键信息抽取任务中,首先使用OCR引擎提取文本内容,然后由语义实体识别模块获取图像中的语义实体,最后经关系抽取模块获取语义实体之间的对应关系,从而提取需要的关键信息。
本项目将主要面向版面恢复(信息抽取)任务进行演示。下图展示了版面信息抽取任务的整体流程,图片先有版面分析划分为图像、文本、标题和表格四种区域,然后对图像、文本和标题三种区域进行OCR的检测识别,对表格进行表格识别,其中图像还会被存储下来以便使用。
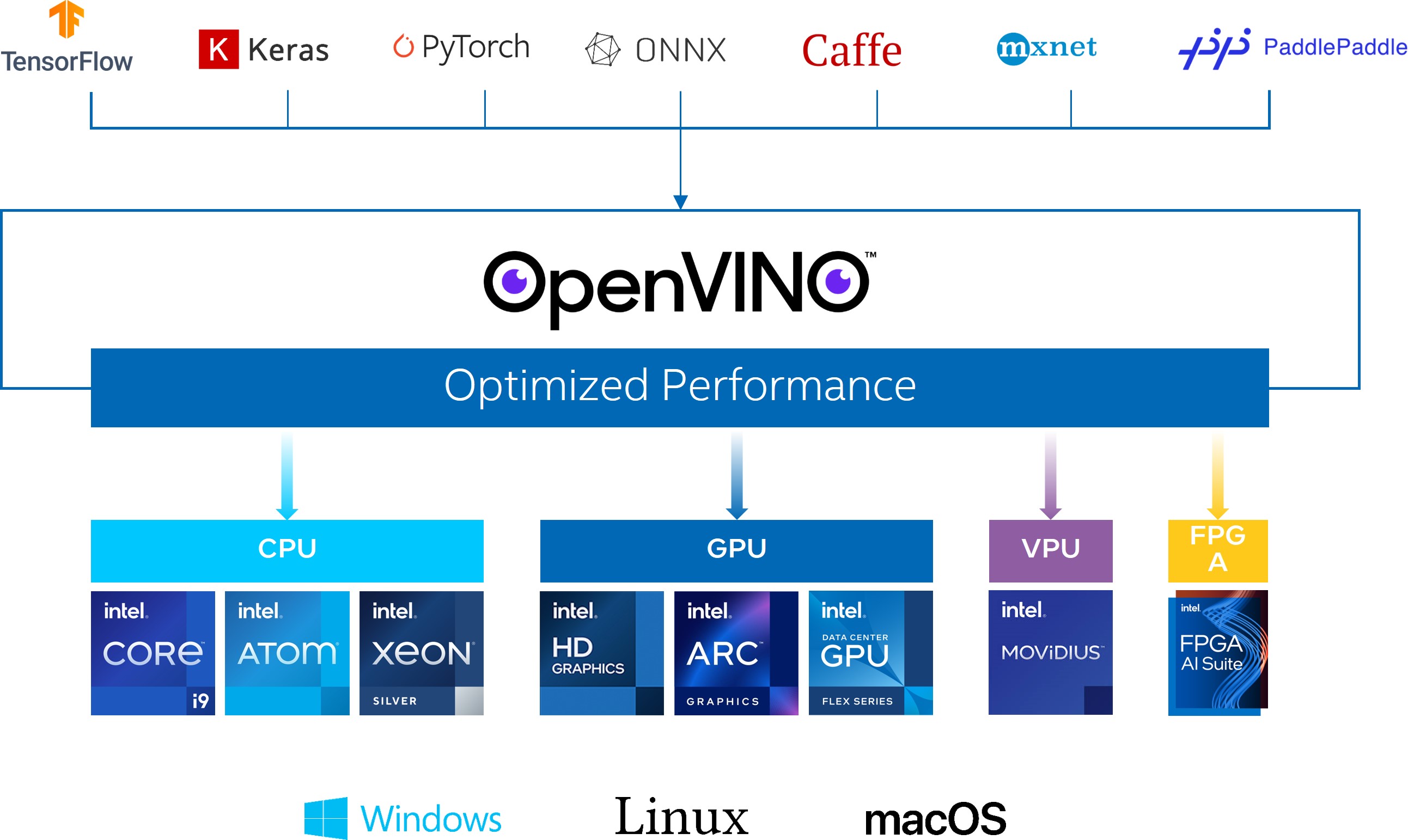
2. OpenVINO简介
OpenVINO作为Intel原生的深度学习推理框架,可以最大化的提升人工智能神经网络在Intel平台上的执行性能,实现一次编写,任意部署的开发体验。OpenVINO在2022.1版本后,就可以直接支持飞桨模型,大大提升了模型在Intel异构硬件上的推理性能与部署便捷性,带来更高的生产效率,更广阔的兼容性以及推理性能的优化。
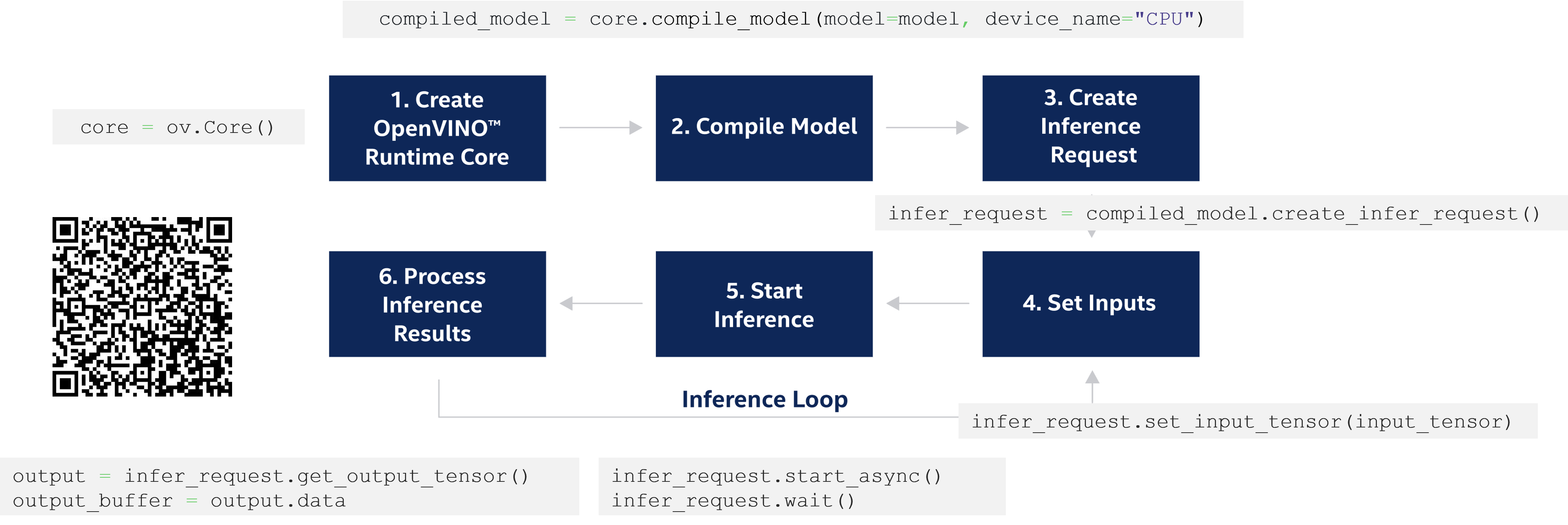
2.1 OpenVINO runtime接口介绍
OpenVINO runtime api的调用流程可以参考以下链接及示意图:
2.2 OpenVINO新版本重要特性
以下是本次演示中新版OpenVINO的特性介绍:
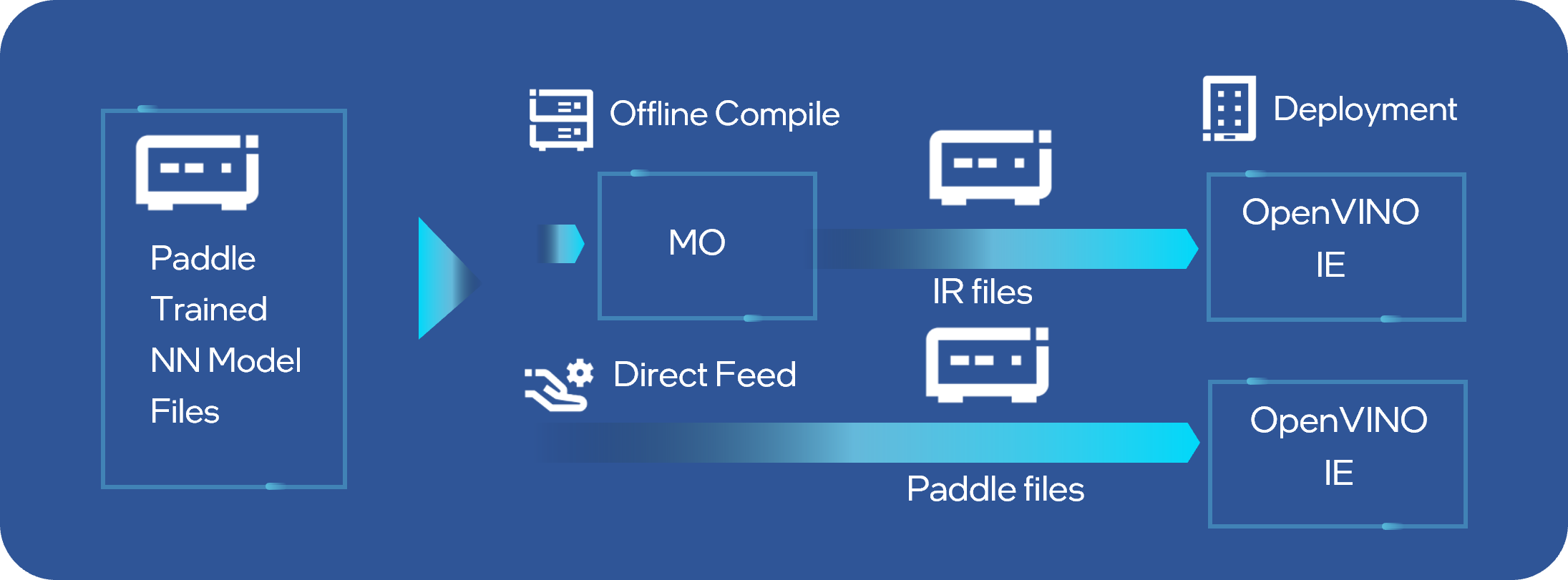
- 直接支持PaddlePaddle模型:目前OpenVINO 2022.1发行版中已完成对PaddlePaddle模型的直接支持,作为国内最受欢迎的深度学习框架之一,之前OpenVINO在对Paddle模型做适配的时候,需要将Paddle模型转化为ONNX格式,再通过MO工具对ONNX模型进行优化和加速部署。现在MO工具已经可以直接完成对Paddle模型的离线转化,同事runtime api接口也可以直接读取加载Paddle模型到指定的硬件设备,省去了离线转换的过程,大大提升了Paddle开发者在Intel平台上部署的效率。经过性能和准确性验证,在OpenVINO™ 2022.1发行版中,会有 13个模型涵盖5大应用场景的Paddle模型将被直接支持,其中不乏像PPYolo和PPOCR这样非常受开发者欢迎的网络。
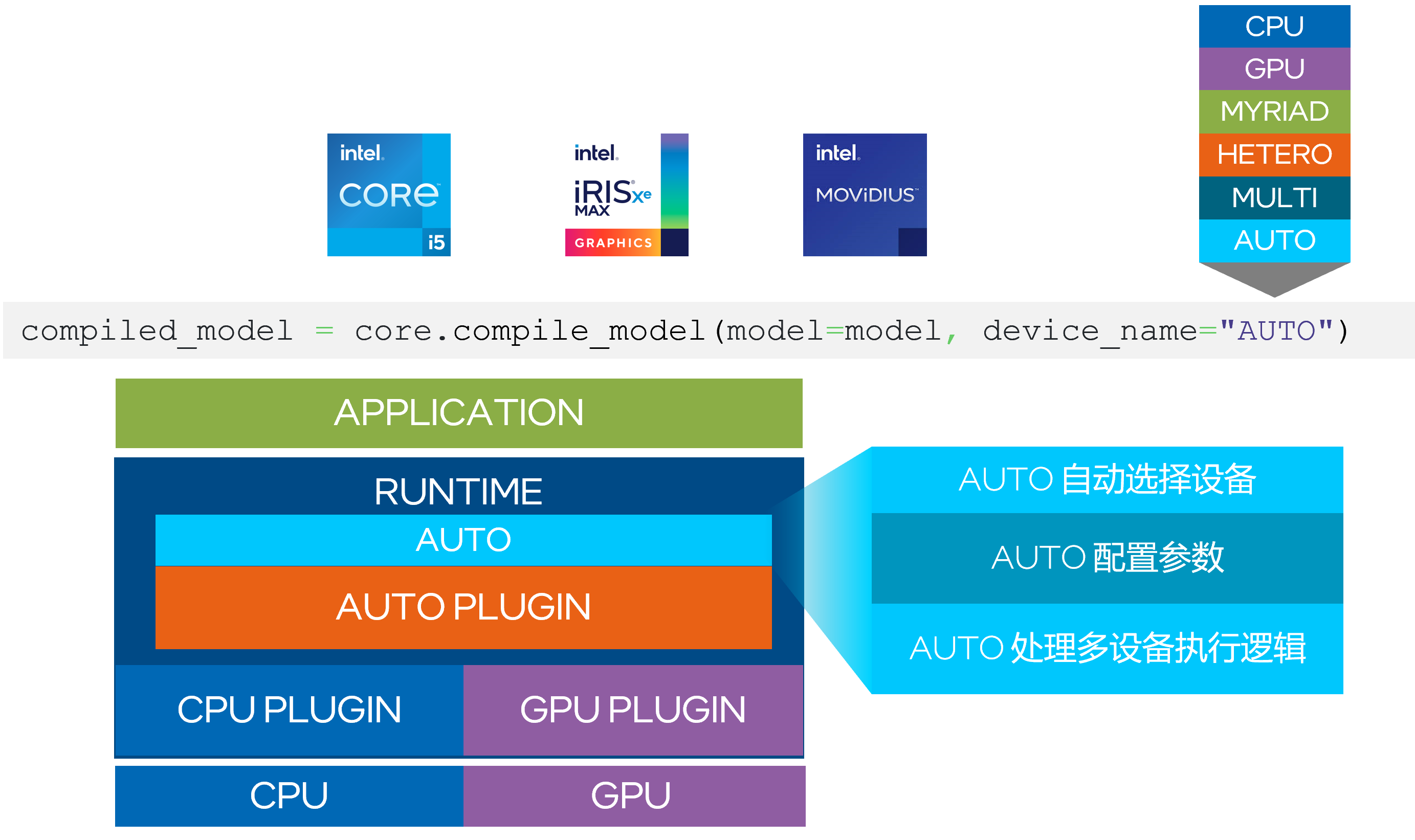
- Auto Device plugin:Intel CPU平台上往往都会配备一个iGPU, 以及VPU这样的外置协处理器,如何充分发挥Intel平台下不同算力单元的能力,成为OpenVINO开发者们必修的功课之一。在2022.1版本之前,小伙伴们必须自己手动选择相应的部署设备,并配置设备中的相关资源。目前在新版本中,当开发者将定义的设备设置为“Auto”后,该接口会搜索系统中所有的算力单元以及其规格属性,根据模型的精度、网络结构以及用户指定性能要求等信息,选取并配置合适的算力单元进行部署,降低不同设备平台间的移植难度与部署难度。
除了自动选择部署硬件以外,Auto Device plugin还将进一步优化GPU/VPU的第一次推理延迟。由于CPU在延迟上有着先天的优势,AUTO Device plugin的策略是默认将第一次推理任务加载到CPU上运行,同时在GPU/VPU等性能更强的协处理器上编译加载执行网络,待CPU完成第一次推理请求后,再将任务无感地迁移到GPU/VPU等硬件设备中完成后续的推理任务。
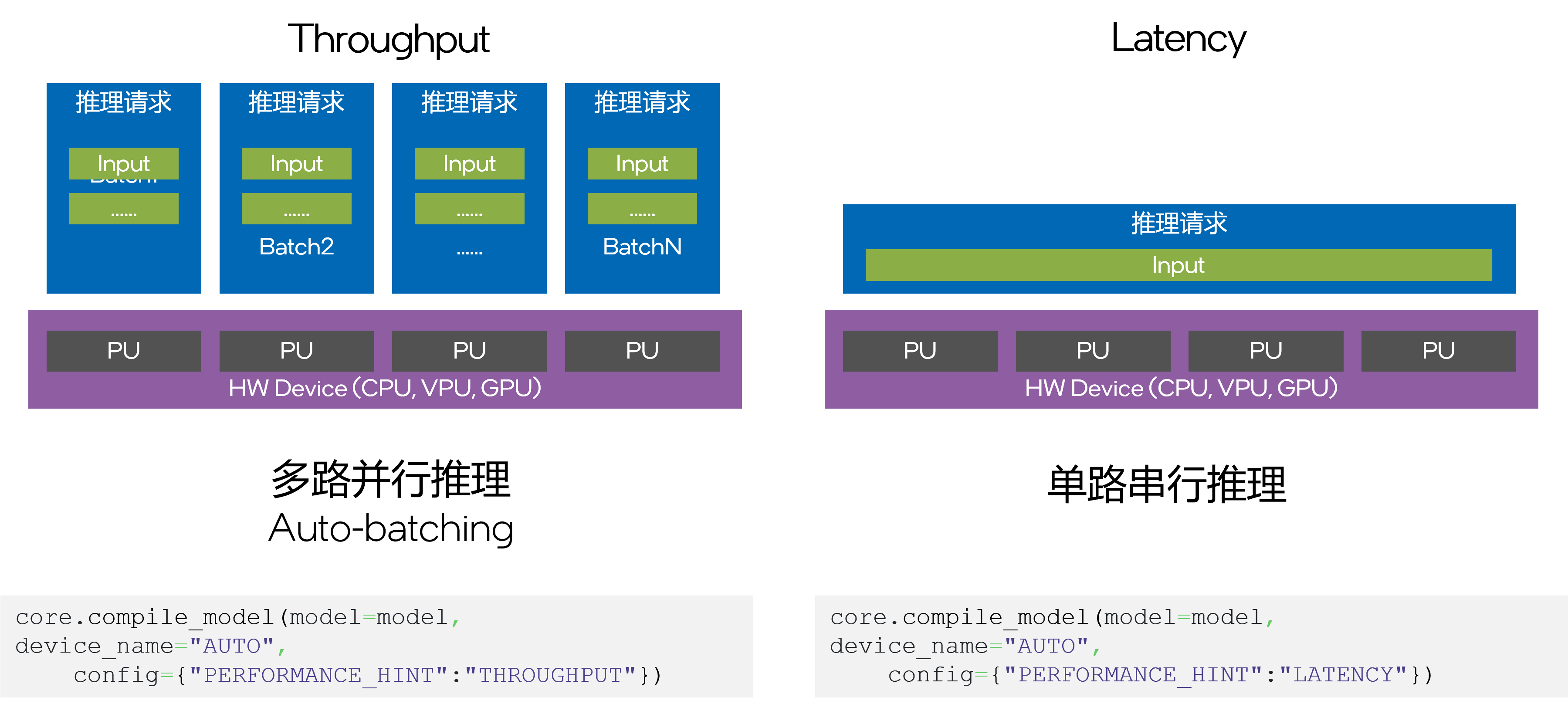
- PERFORMANCE_HINT:由于不同的硬件平台间存在配置和性能差异,想要让应用程序能够全面地适配不同的硬件平台,就需要事先根据硬件特性为你的推理任务配置不同的参数,例如绑定线程数,streams,推理请求数,batch size等,这个过程包含大量的验证和调试工作,非常耗时耗力。为了让开发者尽可能用一套代码来适配不同的Intel硬件平台。OpenVINO 2022.1发行版中引入了全新的PERFORMANCE_HINT功能,用户只需指定他的推理任务需求:延迟优先还是推理优先。compile_model便可以自动进行相应的硬件参数配置,达到相对较优的性能目标。此外针对GPU这样并行计算能力较强的设备,新的Auto Batching功能还可以通过将PERFORMANCE_HINT指定为吞吐量模式,来隐式地开启该功能,并自动配置batch size大小,充分激活GPU硬件性能,优化内存资源占用。
二、环境准备
1. 下载并安装OpenVINO工具套件
!python3 -m pip install --upgrade pip
!python3 -m pip install openvino-dev==2022.3.0
2. 安装PaddleOCR及PP-structure相关依赖
!tar -xzf /home/aistudio/PaddleOCR-2.6.0.tar.gz
!pip install -r /home/aistudio/PaddleOCR-2.6.0/requirements.txt --user
!pip install -r /home/aistudio/PaddleOCR-2.6.0/ppstructure/recovery/requirements.txt
3. 安装PaddleDetection相关依赖
!tar -xzf /home/aistudio/PaddleDetection-2.5.0.tar.gz
!pip install -r /home/aistudio/PaddleDetection-2.5.0/requirements.txt
4. 安装Paddle2ONXX
!pip install paddle2onnx
三、模型训练与验证
本示例将主要介绍版面恢复任务全流程开发过程,该任务相较与传统的OCR,跟进一步引入了版面分析和表格结构识别能力,因此在本章节中将重点说明这个两个模型的训练与验证方式。如果希望直接体验预测过程,可以跳过该章节,下载我们提供的预训练模型。
1. 版面分析
版面分析指的是对图片形式的文档进行区域划分,定位其中的关键区域,如文字、标题、表格、图片等。版面分析算法基于PaddleDetection的轻量模型PP-PicoDet进行开发,包含英文、中文、表格版面分析3类模型。其中,英文模型支持Text、Title、Tale、Figure、List5类区域的检测,中文模型支持Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation10类区域的检测,表格版面分析支持Table区域的检测,版面分析效果如下图所示:

1.1 数据准备
这里以中文文档版面分析数据集CDLA为例主要面向中文文献类(论文)场景,包含10个类:{Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation}
# 解压数据集
!tar -xvf /home/aistudio/data/data194517/cdla.tar.gz -C ./data
解压之后的目录结构:
|-cdla|- train.json|- train/JEGPImages|- train_0199.jpg|- train_0044.jpg| ...|- val.json|- val/JEGPImages|- val_0014.jpg|- val_0022.jpg| ...
数据分布:
| File or Folder | Description | num |
|---|---|---|
train/
|
训练集图片 | 5000 |
val/
|
验证集图片 | 1000 |
train.json
|
训练集标注文件 | - |
val.json
|
验证集标注文件 | - |
标注格式:
json文件包含所有图像的标注,数据以字典嵌套的方式存放,包含以下key:
info,表示标注文件info。
licenses,表示标注文件licenses。
images,表示标注文件中图像信息列表,每个元素是一张图像的信息。如下为其中一张图像的信息:
{file_name:"JPEGImages/val_0301.jpg"height:1754width:1240date_captured:nullid:0 }annotations,表示标注文件中目标物体的标注信息列表,每个元素是一个目标物体的标注信息。如下为其中一个目标物体的标注信息:
{'segmentation': # 物体的分割标注'area': 60518.099043117836, # 物体的区域面积'iscrowd': 0, # iscrowd'image_id': 341427, # image id'bbox': [50.58, 490.86, 240.15, 252.16], # bbox [x1,y1,w,h]'category_id': 1, # category_id'id': 3322348 # image id }
更多数据集:
我们提供了CDLA(中文版面分析)、TableBank(表格版面分析)等数据集的下连接,处理为上述标注文件json格式,即可以按相同方式进行训练。
| dataset | 简介 |
|---|---|
| cTDaR2019_cTDaR | 用于表格检测(TRACKA)和表格识别(TRACKB)。图片类型包含历史数据集(以cTDaR_t0开头,如cTDaR_t00872.jpg)和现代数据集(以cTDaR_t1开头,cTDaR_t10482.jpg)。 |
| IIIT-AR-13K | 手动注释公开的年度报告中的图形或页面而构建的数据集,包含5类:table, figure, natural image, logo, and signature |
| CDLA | 中文文档版面分析数据集,面向中文文献类(论文)场景,包含10类:Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation |
| TableBank | 用于表格检测和识别大型数据集,包含Word和Latex2种文档格式 |
| DocBank | 使用弱监督方法构建的大规模数据集(500K文档页面),用于文档布局分析,包含12类:Author、Caption、Date、Equation、Figure、Footer、List、Paragraph、Reference、Section、Table、Title |
1.2 模型训练
使用PaddleDetection版面分析配置文件启动训练
- 修改配置文件
如果你希望训练自己的数据集,需要修改配置文件中的数据配置、类别数。
以configs/picodet/legacy_model/application/layout_analysis/picodet_lcnet_x1_0_layout.yml 为例,修改的内容如下所示。
metric: COCO
# 类别数
num_classes: 11TrainDataset:!COCODataSet# 修改为你自己的训练数据目录image_dir: train# 修改为你自己的训练数据标签文件anno_path: train.json# 修改为你自己的训练数据根目录dataset_dir: /root/cdla/data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']EvalDataset:!COCODataSet# 修改为你自己的验证数据目录image_dir: val# 修改为你自己的验证数据标签文件anno_path: val.json# 修改为你自己的验证数据根目录dataset_dir: /root/cdla/TestDataset:!ImageFolder# 修改为你自己的测试数据标签文件anno_path: /root/cdla/val.json
- 开始训练,在训练时,会默认下载PP-PicoDet预训练模型,这里无需预先下载。
**注意:**如果训练时显存out memory,将TrainReader中batch_size调小,同时LearningRate中base_lr等比例减小。发布的config均由8卡训练得到,如果改变GPU卡数为1,那么base_lr需要减小8倍。
# 单卡训练
!export CUDA_VISIBLE_DEVICES=0
!python3 PaddleDetection-2.5.0/tools/train.py \-c PaddleDetection-2.5.0/configs/picodet/legacy_model/application/layout_analysis/picodet_lcnet_x1_0_layout.yml \--eval
# 多卡训练,通过--gpus参数指定卡号
!export CUDA_VISIBLE_DEVICES=0,1,2,3
!python3 -m paddle.distributed.launch --gpus '0,1,2,3' PaddleDetection-2.5.0/tools/train.py \-c PaddleDetection-2.5.0/configs/picodet/legacy_model/application/layout_analysis/picodet_lcnet_x1_0_layout.yml \--eval
1.3 模型评估和导出
模型评估
训练中模型参数默认保存在output/picodet_lcnet_x1_0_layout目录下。在评估指标时,需要设置weights指向保存的参数文件。评估数据集可以通过 configs/picodet/legacy_model/application/layout_analysis/picodet_lcnet_x1_0_layout.yml 修改EvalDataset中的 image_dir、anno_path和dataset_dir 设置。
# GPU 评估, weights 为待测权重
!python3 PaddleDetection-2.5.0/tools/eval.py \-c PaddleDetection-2.5.0/configs/picodet/legacy_model/application/layout_analysis/picodet_lcnet_x1_0_layout.yml \-o weights=./output/picodet_lcnet_x1_0_layout/best_model
模型导出
版面分析模型转inference模型步骤如下, 转换成功后,在目录下有三个文件:
output_inference/picodet_lcnet_x1_0_layout/├── model.pdiparams # inference模型的参数文件├── model.pdiparams.info # inference模型的参数信息,可忽略└── model.pdmodel # inference模型的模型结构文件
!python3 PaddleDetection-2.5.0/tools/export_model.py \-c PaddleDetection-2.5.0/configs/picodet/legacy_model/application/layout_analysis/picodet_lcnet_x1_0_layout.yml \-o weights=output/picodet_lcnet_x1_0_layout/best_model \--output_dir=output_inference/
2. 表格识别
表格识别主要包含三个模型
- 单行文本检测-DB
- 单行文本识别-CRNN
- 表格结构和cell坐标预测-SLANet
2.1 流程说明
具体流程图如下:
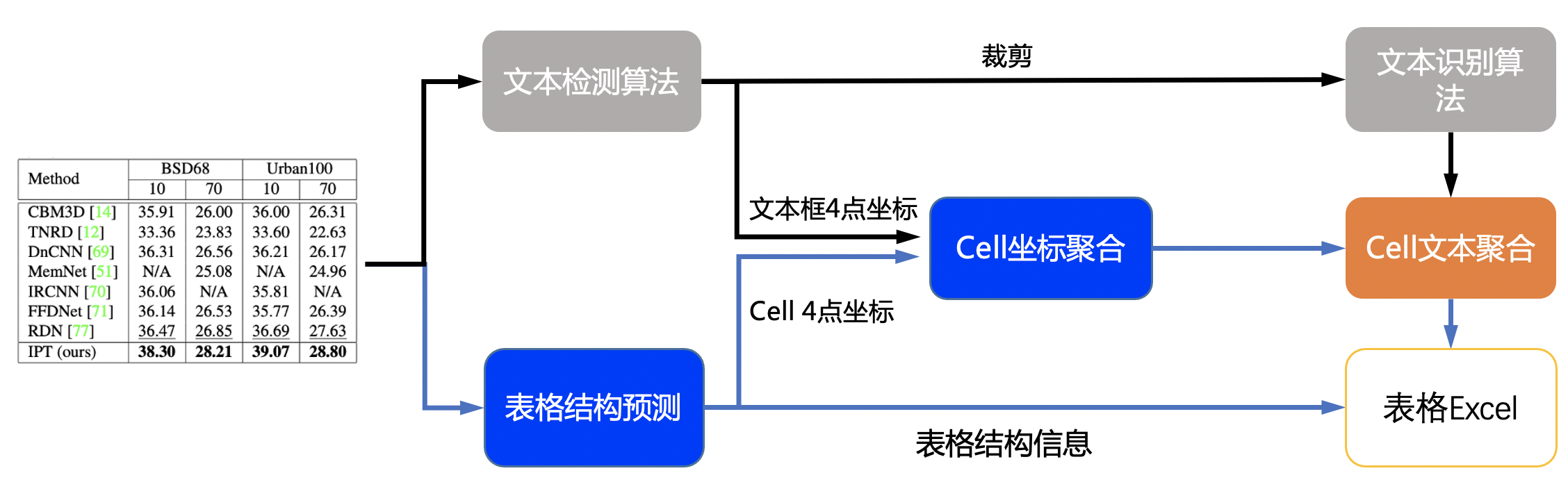
- 图片由单行文字检测模型检测到单行文字的坐标,然后送入识别模型拿到识别结果。
- 图片由SLANet模型拿到表格的结构信息和单元格的坐标信息。
- 由单行文字的坐标、识别结果和单元格的坐标一起组合出单元格的识别结果。
- 单元格的识别结果和表格结构一起构造表格的html字符串。
文本检测模型的训练、评估和推理流程可参考 detection
文本识别模型的训练、评估和推理流程可参考 recognition
以下主要展示表格结构识别模型的训练和导出方法。
2.2 数据准备
数据集格式
PaddleOCR 表格识别模型数据集格式如下:
img_label # 每张图片标注经过json.dumps()之后的字符串
...
img_label
每一行的json格式为:
{'filename': PMC5755158_010_01.png, # 图像名'split': ’train‘, # 图像属于训练集还是验证集'imgid': 0, # 图像的index'html': {'structure': {'tokens': ['<thead>', '<tr>', '<td>', ...]}, # 表格的HTML字符串'cells': [{'tokens': ['P', 'a', 'd', 'd', 'l', 'e', 'P', 'a', 'd', 'd', 'l', 'e'], # 表格中的单个文本'bbox': [x0, y0, x1, y1] # 表格中的单个文本的坐标}]}
}
训练数据的默认存储路径是 PaddleOCR/train_data,如果您的磁盘上已有数据集,只需创建软链接至数据集目录:
# linux and mac os
ln -sf <path/to/dataset> <path/to/paddle_ocr>/train_data/dataset
# windows
mklink /d <path/to/paddle_ocr>/train_data/dataset <path/to/dataset>
数据下载
公开数据集下载可参考 PaddleOCR-2.6.0/doc/doc_ch/dataset/table_datasets.md。
数据集生成
使用TableGeneration可进行扫描表格图像的生成。
TableGeneration是一个开源表格数据集生成工具,其通过浏览器渲染的方式对html字符串进行渲染后获得表格图像。部分样张如下:
| 类型 | 样例 |
|---|---|
| 简单表格 |
|
| 彩色表格 |
|
# 解压Pubtabnet数据集
!tar -xvf /home/aistudio/data/data199057/pubtabnet.tar.gz -C ./data
2.3 模型训练
PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以SLANet模型训练PubTabNet英文数据集为例:
启动训练
如果您安装的是cpu版本,请将配置文件中的 use_gpu 字段修改为false
正常启动训练后,会看到以下log输出:
[2022/08/16 03:07:33] ppocr INFO: epoch: [1/400], global_step: 20, lr: 0.000100, acc: 0.000000, loss: 3.915012, structure_loss: 3.229450, loc_loss: 0.670590, avg_reader_cost: 2.63382 s, avg_batch_cost: 6.32390 s, avg_samples: 48.0, ips: 7.59025 samples/s, eta: 9 days, 2:29:27
[2022/08/16 03:08:41] ppocr INFO: epoch: [1/400], global_step: 40, lr: 0.000100, acc: 0.000000, loss: 1.750859, structure_loss: 1.082116, loc_loss: 0.652822, avg_reader_cost: 0.02533 s, avg_batch_cost: 3.37251 s, avg_samples: 48.0, ips: 14.23271 samples/s, eta: 6 days, 23:28:43
[2022/08/16 03:09:46] ppocr INFO: epoch: [1/400], global_step: 60, lr: 0.000100, acc: 0.000000, loss: 1.395154, structure_loss: 0.776803, loc_loss: 0.625030, avg_reader_cost: 0.02550 s, avg_batch_cost: 3.26261 s, avg_samples: 48.0, ips: 14.71214 samples/s, eta: 6 days, 5:11:48
log 中自动打印如下信息:
| 字段 | 含义 |
|---|---|
| epoch | 当前迭代轮次 |
| global_step | 当前迭代次数 |
| lr | 当前学习率 |
| acc | 当前batch的准确率 |
| loss | 当前损失函数 |
| structure_loss | 表格结构损失值 |
| loc_loss | 单元格坐标损失值 |
| avg_reader_cost | 当前 batch 数据处理耗时 |
| avg_batch_cost | 当前 batch 总耗时 |
| avg_samples | 当前 batch 内的样本数 |
| ips | 每秒处理图片的数量 |
PaddleOCR支持训练和评估交替进行, 可以在 configs/table/SLANet.yml 中修改 eval_batch_step 设置评估频率,默认每1000个iter评估一次。评估过程中默认将最佳acc模型,保存为 output/SLANet/best_accuracy 。
如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
提示: 可通过 -c 参数选择 configs/table/ 路径下的多种模型配置进行训练,PaddleOCR支持的表格识别算法可以参考前沿算法列表:
注意,预测/评估时的配置文件请务必与训练一致。
# GPU训练 支持单卡,多卡训练
# 训练日志会自动保存为 "{save_model_dir}" 下的train.log#单卡训练(训练周期长,不建议)
!python3 PaddleOCR-2.6.0/tools/train.py -c PaddleOCR-2.6.0/configs/table/SLANet.yml
#多卡训练,通过--gpus参数指定卡号
!python3 -m paddle.distributed.launch --gpus '0,1,2,3' PaddleOCR-2.6.0/tools/train.py -c PaddleOCR-2.6.0/configs/table/SLANet.yml
断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
!python3 tools/train.py -c configs/table/SLANet.yml -o Global.checkpoints=./your/trained/model
更换Backbone 训练
PaddleOCR将网络划分为四部分,分别在ppocr/modeling下。 进入网络的数据将按照顺序(transforms->backbones->necks->heads)依次通过这四个部分。
├── architectures # 网络的组网代码
├── transforms # 网络的图像变换模块
├── backbones # 网络的特征提取模块
├── necks # 网络的特征增强模块
└── heads # 网络的输出模块
如果要更换的Backbone 在PaddleOCR中有对应实现,直接修改配置yml文件中Backbone部分的参数即可。
如果要使用新的Backbone,更换backbones的例子如下:
- 在
ppocr/modeling/backbones文件夹下新建文件,如my_backbone.py。 - 在 my_backbone.py 文件内添加相关代码,示例代码如下:
import paddle
import paddle.nn as nn
import paddle.nn.functional as Fclass MyBackbone(nn.Layer):def __init__(self, *args, **kwargs):super(MyBackbone, self).__init__()# your init codeself.conv = nn.xxxxdef forward(self, inputs):# your network forwardy = self.conv(inputs)return y
- 在
ppocr/modeling/backbones/\__init\__.py文件内导入添加的MyBackbone模块,然后修改配置文件中Backbone进行配置即可使用,格式如下:
Backbone:
name: MyBackbone
args1: args1
2.4 模型评估与导出
模型评估
训练中模型参数默认保存在Global.save_model_dir目录下。在评估指标时,需要设置Global.checkpoints指向保存的参数文件。评估数据集可以通过 configs/table/SLANet.yml 修改Eval中的 label_file_list 设置。
# GPU 评估, Global.checkpoints 为待测权重
!python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/table/SLANet.yml -o Global.checkpoints={path/to/weights}/best_accuracy
模型导出
转换成功后,在目录下有三个文件:
inference/SLANet/├── inference.pdiparams # inference模型的参数文件├── inference.pdiparams.info # inference模型的参数信息,可忽略└── inference.pdmodel # inference模型的program文件
!python3 tools/export_model.py -c configs/table/SLANet.yml -o Global.pretrained_model=./pretrain_models/SLANet/best_accuracy Global.save_inference_dir=./inference/SLANet/
四、 模型部署
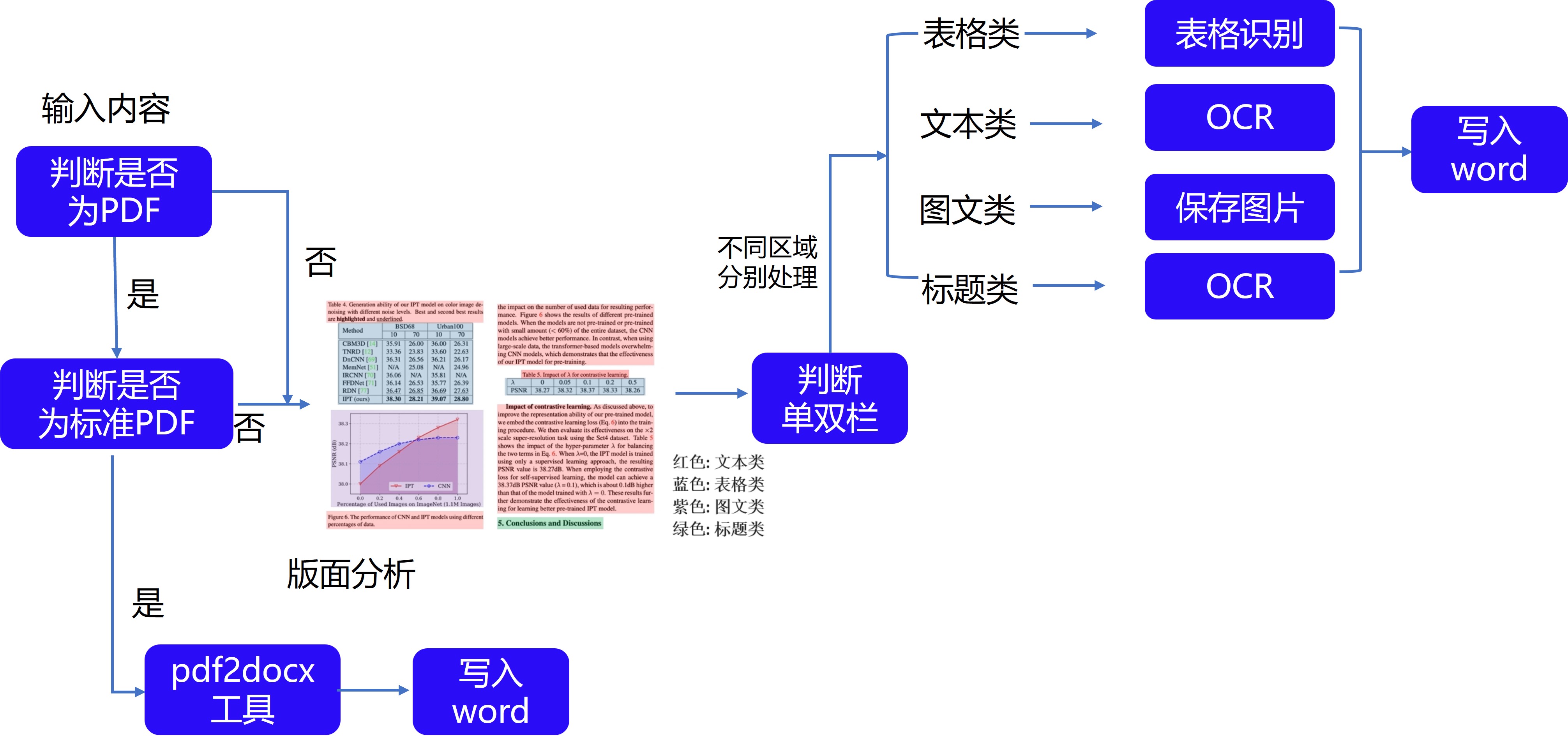
本示例将基于OpenVINO实现文档图片版面分析任务部署,主要流程可参考下图所示:
1. 预训练模型下载
本任务需要同时用到结构化分析模型和OCR模型,如表格识别需要使用表格识别模型进行结构化解析,同时也要用到OCR模型对表格内的文字进行识别,请根据具体需求选择合适的模型。
结构化分析相关模型下载可以参考:
- PP-Structure 模型库
以下以英文模型为例:
!cd /home/aistudio && mkdir models# 下载解压版面分析模型
!wget https://paddleocr.bj.bcebos.com/ppstructure/models/layout/picodet_lcnet_x1_0_fgd_layout_infer.tar -P ./models
!tar -xvf ./models/picodet_lcnet_x1_0_fgd_layout_infer.tar -C ./models/# 下载解压文本检测模型
!wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar -P ./models
!tar -xvf ./models/en_PP-OCRv3_det_infer.tar -C ./models/# 下载解压文本识别模型
!wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar -P ./models
!tar -xvf ./models/en_PP-OCRv3_rec_infer.tar -C ./models/# 下载解压版表格结构识别模型
!wget https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/en_ppstructure_mobile_v2.0_SLANet_infer.tar -P ./models
!tar -xvf ./models/en_ppstructure_mobile_v2.0_SLANet_infer.tar -C ./models/
2. 模型转换
鉴于当前版本的OpenVINO还不支持直接读取表格识别模型,需要通过paddle2onnx工具将其进行转换为onnx格式
!paddle2onnx --model_dir ./models/en_ppstructure_mobile_v2.0_SLANet_infer --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./models/en_ppstructure_mobile_v2.0_SLANet_infer/inference.onnx
3. 运行版面恢复任务
使用下载的模型恢复给定文档的版面,以英文模型为例,执行如下命令:
3.1 添加OpenVINO后端代码
!cp -f ./openvino/predict_layout.py ./PaddleOCR-2.6.0/ppstructure/layout
!cp -f ./openvino/predict_structure.py ./PaddleOCR-2.6.0/ppstructure/table
!cp -f ./openvino/predict_cls.py ./openvino/predict_det.py ./openvino/predict_rec.py ./openvino/utility.py ./PaddleOCR-2.6.0/tools/infer
3.2 执行版面恢复脚本
!python3 ./PaddleOCR-2.6.0/ppstructure/predict_system.py \--image_dir=./PaddleOCR-2.6.0/ppstructure/docs/table/1.png \--det_model_dir=./models/en_PP-OCRv3_det_infer \--rec_model_dir=./models/en_PP-OCRv3_rec_infer \--rec_char_dict_path=./PaddleOCR-2.6.0/ppocr/utils/en_dict.txt \--table_model_dir=./models/en_ppstructure_mobile_v2.0_SLANet_infer \--table_char_dict_path=./PaddleOCR-2.6.0/ppocr/utils/dict/table_structure_dict.txt \--layout_model_dir=./models/picodet_lcnet_x1_0_fgd_layout_infer \--layout_dict_path=./PaddleOCR-2.6.0/ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt \--vis_font_path=./PaddleOCR-2.6.0/doc/fonts/simfang.ttf \--recovery=True \--use_gpu=False \--use_openvino=True \--output=./output/
鉴于aistudio上为Anaconda的虚拟环境,可能会出现OpenVINO库运行出错的情况,建议使用本地环境进行测试。
运行完成后,恢复版面的docx文档会保存到output字段指定的目录下
字段含义:
- image_dir:测试文件,可以是图片、图片目录、pdf文件、pdf文件目录
- det_model_dir:OCR检测模型路径
- rec_model_dir:OCR识别模型路径
- rec_char_dict_path:OCR识别字典,如果更换为中文模型,需要更改为"…/ppocr/utils/ppocr_keys_v1.txt",如果您在自己的数据集上训练的模型,则更改为训练的字典的文件
- table_model_dir:表格识别模型路径
- table_char_dict_path:表格识别字典,如果更换为中文模型,不需要更换字典
- layout_model_dir:版面分析模型路径
- layout_dict_path:版面分析字典,如果更换为中文模型,需要更改为"…/ppocr/utils/dict/layout_dict/layout_cdla_dict.txt"
- recovery:是否进行版面恢复,默认False
- use_openvino:是否开启OpenVINO推理后端,默认False
- output:版面恢复结果保存路径
3.3 性能比较
基于11th Gen Intel Core i7-11800H处理器的运行结果比较:
使用默认推理后端:
配置方法:–use_openvino=False
[2023/03/19 23:18:40] ppocr INFO: Predict time : 13.955s
打开OpenVINO推理后端:
配置方法:–use_openvino=True
[2023/03/19 23:19:42] ppocr INFO: Predict time : 3.280s
鉴于硬件性能和配置参数可能存在差异,该比较数据仅供参考。
精彩课程回顾
为了让小伙伴们更便捷地应用范例教程,OpenVINO AI软件工程师Ethan于3月23日(周四)20:15为大家深度解析了从数据准备、方案设计到模型优化部署的开发全流程,手把手教大家进行代码实践。
视频回顾请点击链接
基于OpenVINO与PP-Strucutre的文档智能分析 - 飞桨AI Studio相关推荐
- 【机器学习】百度飞桨AI Studio平台项目:基于卷积神经网络分类方法的人脸颜值打分
基于卷积神经网络分类方法的人脸颜值打分 说在前面 实验数据 解决过程 1.Precondition 2.Dataset Preparation 3.Network Configuration 4.Mo ...
- PP飞桨 AI studio Notebook基础操作学习
目录 执行和调试 多文件代码编辑 上传Notebook Notebook快捷键 Notebook中使用Shell命令 使用pip来安装自己需要的package (但不支持apt-get) 查看当前环境 ...
- 文档智能不再难!百度开源十一边形战士文心ERNIE-Layout
文档智能(DI, Document Intelligence)主要指对于网页.数字文档或扫描文档所包含的文本以及丰富的排版格式等信息,通过人工智能技术进行理解.分类.提取以及信息归纳的过程.文档智能技 ...
- 【OpenVINO+paddle】一切皆可二次元-CPU部署飞桨AnimeGAN实现所有照片二次元化
[OpenVINO+paddle]一切皆可二次元-CPU部署飞桨GAN实现所有照片二次元化 在这篇文章中我将小喵咪.小姐姐.钢铁侠图片二次元化,事实上你可以尝试任何一张你感兴趣的图像.在这里你将会使用 ...
- 基于C++的OpenCV项目实战——文档照片转换成扫描文件
基于C++的OpenCV项目实战--文档照片转换成扫描文件 一.背景 前段时间都是基于Python的OpecCV进行一些学习和实践,但小的知识点并没有应用到实际的项目中:并且基于Python的版本的移 ...
- 刷新4项文档智能任务纪录,百度TextMind打造ERNIE-Layout登顶文档智能权威榜单
来源:机器之心本文约2300字,建议阅读5分钟 文档智能国际权威榜单文档视觉问答 DocVQA 迎来了新霸主. 百度提出跨模态文档理解模型 ERNIE-Layout,首次将布局知识增强技术融入跨模态文 ...
- 从微信AI首席顾问到金融文档智能,一位中科院计算机科学家AI产品化实践
从微信AI首席顾问到金融文档智能,一位中科院计算机科学家AI产品化实践 本文作者:伊莉 2017-08-14 10:18 导语:"我的研究思路是扎根某一领域,如金融,并探索一些实际问题,再从 ...
- AI论文解读丨融合视觉、语义、关系多模态信息的文档版面分析架构VSR
摘要:文档版式分析任务中,文档的视觉信息.文本信息.各版式部件间的关系信息都对分析过程具有很重要的作用.本文提出一种融合视觉.文本.关系多模态信息的版式分析架构VSR. 本文分享自华为云社区<论 ...
- 文档智能理解:通用文档预训练模型与数据集
向AI转型的程序员都关注了这个号???????????? 机器学习AI算法工程 公众号:datayx 预训练模型到底是什么,它是如何被应用在产品里,未来又有哪些机会和挑战? 预训练模型把迁移学习很 ...
最新文章
- 关于 typedef typedef struct typedef union理解 --写给不长脑子的我
- Java自动装箱/拆箱 - Java那些事儿
- # 利用fragment实现界面跳转
- Acwing第 5 场周赛【未完结】
- HDU - 6582 Path(最短路+最大流)
- python的pwntools工具的日常使用
- 从Java程序员进阶架构师,必看的书单推荐!
- 头条终面:写个消息中间件
- [HDU6315]Naive Operations(线段树+树状数组)
- VueCli4学习笔记
- java读取配置文件的详细写法,Properties配置文件读取相关java知识
- Facebook高管:文字分享将枯竭 5年后或许全是视频
- 华为交换机命令基础入门学习,菜鸟也能看得懂!
- WIN10/WIN11 优启动 GHOST
- 基础连接已关闭解决办法_手机wifi连不上怎么办 手机wifi连不上解决办法【详解】...
- 编译原理知识点总结——识别单词的DFA
- Cloud Foundry 峰会进入中国 全球专家与你面对面
- 学无止境的CSS(xHTML+CSS技巧教程资源大全)
- 谈谈红楼梦(第16-18回)
- Sabre选择DXC Technology来助力改变未来旅游业,作为两家公司续约多年期协议的一部分