自我监督学习和无监督学习_弱和自我监督的学习-第3部分
自我监督学习和无监督学习
有关深层学习的FAU讲义 (FAU LECTURE NOTES ON DEEP LEARNING)
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. Try it yourself! If you spot mistakes, please let us know!
这些是FAU YouTube讲座“ 深度学习 ”的 讲义 。 这是演讲视频和匹配幻灯片的完整记录。 我们希望您喜欢这些视频。 当然,此成绩单是使用深度学习技术自动创建的,并且仅进行了较小的手动修改。 自己尝试! 如果发现错误,请告诉我们!
导航 (Navigation)
Previous Lecture / Watch this Video / Top Level / Next Lecture
上一个讲座 / 观看此视频 / 顶级 / 下一个讲座

Welcome back to deep learning! So today, we want to start talking about ideas that are called self-supervised learning. We want to obtain labels by self-supervision and will look into what this term actually means, what the core ideas are in the next couple of videos.
欢迎回到深度学习! 因此,今天,我们要开始谈论被称为自我监督学习的想法。 我们希望通过自我监督来获得标签,并将研究该术语的实际含义,接下来的两个视频中的核心思想。

So, this is part three of weakly and self-supervised learning. Today, we actually start talking about self-supervised learning. There are a couple of views around self-supervised learning and you can essentially split them into two parts. You can say, one is how to get the self-supervised labels and the other part is that you work on the losses in order to embed those labels. We have particular losses that are suited for the self-supervision. So, let’s start with the definition. The motivation is you could say that classically people in machine learning believed that supervision is, of course, the approach that produces the best results. But, we have these massive amounts of labels that we need. So, you could actually very quickly then come to the conclusion that the AI revolution will not be supervised. This is very clearly visible in the following statement by Yann LeCun. “Most of human and animal learning is unsupervised learning. If intelligence was a cake, unsupervised learning would be the cake, supervised learning would be the icing on the cake, and reinforcement learning would be the cherry on the cake.” Of course, this is substantiated by observations in biology and how humans and animals learn.
因此,这是弱和自我监督学习的第三部分。 今天,我们实际上开始谈论自我监督学习。 关于自我监督学习,有两种观点,您基本上可以将其分为两部分。 您可以说,一个是如何获得自我监督的标签,另一部分是您要处理损失以嵌入这些标签。 我们有适合自我监督的特殊损失。 因此,让我们从定义开始。 您可以说,这样做的动机是,机器学习的人们通常认为,监督当然是产生最佳结果的方法。 但是,我们有大量需要的标签。 因此,您实际上可以很快得出结论,即不会监督AI革命。 Yann LeCun在以下声明中非常清楚地看到了这一点。 “大多数人类和动物学习都是无监督的学习。 如果说智力是蛋糕,那么无监督学习将是蛋糕,监督学习将锦上添花,强化学习将是蛋糕上的樱桃。” 当然,这可以通过生物学观察以及人类和动物的学习方式得到证实。

The idea of self-supervision is that you try to use information that you already have about your problem to come up with some surrogate labels that allow you to do training processes. The key ideas here on this slide by Yann LeCun can be summarized as follows: You try to predict the future from the past, you can predict the future also from the recent past, you predict the past from the present or the top from the bottom. Also, an option could be to predict the occluded from the visible. You pretend that there is a part of the input that you don’t know and predict that. This essentially allows you to come up with a surrogate task. With the surrogate task, you can already perform training. The nice thing is you don’t need any label at all because you intrinsically use the structure of the data.
自我监督的想法是,您尝试使用已经存在的有关问题的信息来提出一些替代标签,以便您进行培训。 Yann LeCun在这张幻灯片上的关键思想可以总结如下:您试图根据过去来预测未来,也可以根据最近的过去来预测未来,您可以根据现在或顶部来预测未来。 。 同样,可以选择从可见区域中预测遮挡物。 您假装输入中有一部分是您不知道和无法预测的。 本质上,这使您可以提出代理任务。 使用代理任务,您已经可以执行培训。 令人高兴的是,您根本不需要任何标签,因为您本质上使用了数据结构。

Essentially, self-supervised learning is an unsupervised learning approach. But every now and then, you need to make clear that you’re doing something new in a domain that has been researched on for many decades. So, you may not refer to the term unsupervised anymore and Yann LeCun actually proposed the term self-supervised learning. He realized that unsupervised is a loaded and confusing term. So although the ideas have already been around before, the term self-supervised learning has been established. It makes sense to use this term to concentrate on a particular kind of unsupervised learning. So, you could say it’s a subcategory of unsupervised learning. It uses pretext surrogates of pseudo tasks in a supervised fashion. This essentially means you can use all of the supervised learning methods and you have labels that are automatically generated. They can then be used as a measurement of correctness to create a loss in order to train your weights. The idea is then that this is beneficial for downstream tasks like retrieval, supervised, or semi-supervised classification, and so on. By the way in this kind of broad definition, you could also argue that generative models like generative adversarial networks are also some kind of self-supervised learning method. So essentially, Yann LeCun had this very nice idea to frame this kind of learning in a new way. If you do so, this is, of course, very helpful because you can make clear that you’re doing something new and you’re different from the many unsupervised learning approaches that have been out there for a very long time.
本质上,自我监督学习是一种无监督的学习方法。 但是,每时每刻,您都需要弄清楚自己在一个已经研究了数十年的领域中正在做新的事情。 因此,您可能不再引用“无监督学习”一词,而Yann LeCun实际上提出了“自我监督学习”一词。 他意识到无人监管是一个繁琐而令人困惑的术语。 因此,尽管这些想法早已存在,但已经建立了术语“自我监督学习”。 使用该术语专注于特定种类的无监督学习是有意义的。 因此,您可以说这是无监督学习的子类别。 它以监督方式使用伪任务的借记代理。 这实际上意味着您可以使用所有有监督的学习方法,并且具有自动生成的标签。 然后可以将它们用作正确性的度量标准,以创建损失以训练您的体重。 然后的想法是,这对于下游任务(如检索,监督或半监督分类等)是有益的。 顺便说一下,在这种广义的定义中,您还可以争辩说,诸如生成对抗网络之类的生成模型也是某种自我监督的学习方法。 因此,从本质上讲,Yann LeCun有一个非常好的主意,可以用一种新的方式来构架这种学习。 如果这样做的话,这当然是非常有用的,因为您可以清楚地知道自己正在做新的事情,并且与很长一段时间以来出现的许多无监督学习方法不同。

So, let’s look into some of these ideas. There are, of course, these pretext tasks and you can work with generation-based methods. So, you can use GANs, you can do things like super-resolution approaches. There, you downsample and try to predict the higher resolution image. You can do inpainting approaches or colorization. Of course, this also works with videos. You can work with context-based methods. Here, you try to solve things like the jigsaw puzzle or clustering. In semantic label-based methods, you can do things like trying to estimate moving objects or predict the relative depth. Then there’s also cross-modal methods where you try to use information from more than one modality. You have a linked sensor system, let’s say you have a depth camera and an RGB camera. Then, you can link the two and try to predict the one from the other. If you have an attached sensor, let’s say you have a car, you’re moving, and you have a GPS sensor or any other sensory system that will tell you how your car is moving, then you can try to predict the ego-motion from the actual video sequence.
因此,让我们研究其中的一些想法。 当然,有这些借口任务,您可以使用基于世代的方法。 因此,您可以使用GAN,还可以执行诸如超分辨率方法之类的事情。 在那里,您可以降低采样率并尝试预测更高分辨率的图像。 您可以进行修补方法或着色。 当然,这也适用于视频。 您可以使用基于上下文的方法。 在这里,您尝试解决诸如拼图或聚类之类的问题。 在基于语义标签的方法中,您可以执行一些操作,例如尝试估计移动的对象或预测相对深度。 然后还有跨模式方法,您尝试使用来自多个模式的信息。 您有一个链接的传感器系统,假设您有一个深度相机和一个RGB相机。 然后,您可以将两者链接起来,并尝试相互预测。 如果您有一个附加的传感器,比如说您有一辆汽车,正在行驶,并且有一个GPS传感器或任何其他传感系统可以告诉您汽车的行驶方式,那么您可以尝试预测自我运动根据实际的视频序列

So let’s look into this in a bit of more detail and look at image-based self-supervised learning techniques to refine representation learning, the first idea, the generative ones. You can, for example, do image colorization where it is very easy to generate labels.
因此,让我们更详细地研究这一点,并研究基于图像的自我监督学习技术,以完善表示学习,第一个想法和生成性学习。 例如,您可以在很容易生成标签的地方进行图像着色。

You start with color images, compute essentially the average over the channels that gives you a gray value image. Then, you try to predict the original color again. You can use a kind of scene and encoder/decoder approach in order to predict the correct color maps.
您从彩色图像开始,本质上计算通道的平均值,从而获得灰度图像。 然后,您尝试再次预测原始颜色。 您可以使用一种场景和编码器/解码器方法来预测正确的颜色图。

Furthermore, you can also go into inpainting. You can occlude parts of the image and then try to predict those. This then essentially results in the task that you try to predict a complete image where you then compare to the actual full image to the prediction that was created by your generator. You can train these things for example in a GAN-type of loss setting. We have a discriminator that then tells you whether this was a good inpainting result or not.
此外,您还可以进行修补。 您可以遮挡图像的某些部分,然后尝试进行预测。 然后,这实际上会导致您尝试预测完整图像的任务,然后将其与实际完整图像进行比较,以与生成器创建的预测进行比较。 您可以例如在GAN类型的损失设置中训练这些东西。 我们有一个鉴别器,然后告诉您这是否是一个好的修复结果。

There are also ideas about spatial context. Here, a very common approach is to solve a jigsaw puzzle. You take a patch or actually, you take nine patches of the image and you essentially try to predict whether you have the center patch, let’s say, for the face of the cat here, you have one. Then, you want to predict what is the ID of the patch that is shown. So, you put in two images and try to predict the correct location of the second patch. Notice that this is a bit tricky because there is a trivial solution possible. This happens if you have boundary patterns that are continuing. If you have continuing textures, then it may occur that the actual patch can very easily be detected in the next patch because the texture is continued. So, you should use large enough gaps in order to get around this problem. Color may be tricky too. You can use chromatic aberration and pre-process the images by shifting green and magenta towards gray, or you randomly drop two of the color channels in order to avoid that you’re only learning about color.
也有关于空间背景的想法。 在这里,一种非常常见的方法是解决拼图游戏。 您拍摄了一个补丁,或者实际上是拍摄了九个补丁,您实际上是在尝试预测是否有中心补丁,例如,对于这里的猫,您有一个。 然后,您要预测显示的补丁程序的ID是什么。 因此,您放入了两个图像并尝试预测第二个补丁的正确位置。 请注意,这有点棘手,因为可能有一个简单的解决方案。 如果您有连续的边界图案,则会发生这种情况。 如果您有连续的纹理,则由于纹理是连续的,因此很可能在下一个补丁中很容易检测到实际补丁。 因此,您应该使用足够大的间隙以解决此问题。 颜色可能也很棘手。 您可以使用色差并通过将绿色和洋红色移向灰色来对图像进行预处理,或者您可以随机放弃两个颜色通道,以免仅学习颜色。
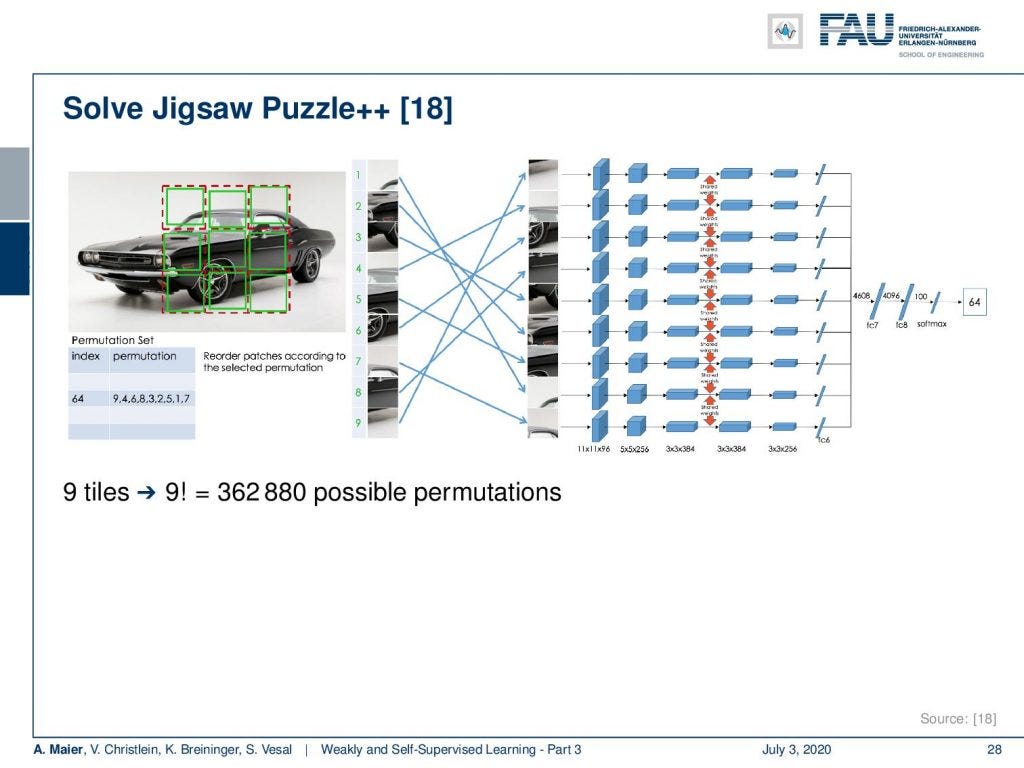
There’s an improved version of the jigsaw puzzle. In jigsaw puzzle++, the idea is that you essentially randomize the order of the patches and you try to predict the correct location of each patch. Now, the cool thing about this is if you have 9 tiles then you have 9! possible permutations. This is more than 300-thousand. So, we can create plenty of labels for this task and you see that it’s actually key that you do it in the right way. So, it’s not just that you have a lot of permutations.
拼图游戏有一个改进的版本。 在Jigsaw Puzzle ++中,其想法是实质上将补丁的顺序随机化,然后尝试预测每个补丁的正确位置。 现在,这很酷的事情是,如果您有9个图块,那么您就有9个! 可能的排列。 这是三十万。 因此,我们可以为此任务创建大量标签,并且您会发现,正确地执行它实际上是关键。 因此,不仅仅是您有很多排列。

You also want to make sure that there is an appropriate average Hamming distance. You can see if you actually obey this idea, then this makes a difference. If you have a too low average Hamming distance, the jigsaw task accuracy is not very high. If you increase it, the jigsaw task accuracy also increases. There’s a very high likelihood that this high accuracy then will also go to the actual task of interest. So here, this is a detection task and with a high jigsaw task accuracy, you also build a better detector.
您还想确保有适当的平均汉明距离。 您可以查看您是否确实遵守了这个想法,那么就有所不同。 如果平均汉明距离过低,则拼图任务的准确性不是很高。 如果增加它,则拼图任务的准确性也会提高。 那么,这种高准确性也很有可能会用于您感兴趣的实际任务。 因此,在这里,这是一个检测任务,并且拼图任务的准确性较高,您还可以构建更好的检测器。

Well, which other ideas could we be interested in? Of course, you can do similar things with rotation. Then, you try to predict the correct rotation of the image. This is also a very cheap label that you can generate.
好吧,我们还对哪些其他想法感兴趣? 当然,您可以旋转进行类似的操作。 然后,您尝试预测图像的正确旋转。 这也是可以生成的非常便宜的标签。

Let’s look a bit into context similarity. Here, the idea is that you want to figure out whether this image is from the same or a different context. So, you can pick an input patch, then you augment it. You use different ways of augmentation like changes in color contrast, slight movement, and general pixel transformations: You can also add noise and this gives you essentially for every patch a large number of other patches that should show the same content. Now, you can repeat that with other patches and this allows you to build a large database. With those patches, you can then train whether it’s the same patch or not, and you can then discriminate these several good classes and train your system similarly.
让我们看一下上下文相似性。 在这里,您的想法是要弄清楚此图像是来自相同还是不同的上下文。 因此,您可以选择一个输入色块,然后对其进行扩充。 您可以使用不同的增强方式,例如颜色对比度的变化,轻微的移动和一般的像素转换:您还可以添加噪点,这实际上为每个色块提供了大量其他应显示相同内容的色块。 现在,您可以使用其他补丁重复该操作,这将允许您构建大型数据库。 有了这些补丁,您就可以训练它是否是相同的补丁,然后可以区分这几个好的类,并以类似的方式训练您的系统。

A different approach is that you use clustering. This is work by my colleague Vincent Christlein. He was interested in building better features for writer identification. So, he started with detecting key points. The key points then allow you to extract patches. At the same time, the key points if detected with algorithms like SIFT, come with a feature descriptor. On the future descriptor, you can then perform clustering and the clusters that you get are probably already quite good training samples. So, you use the cluster-ID in order to train for example a ResNet for the prediction of the respective patch. This way, you can use a completely unlabeled data set, do the clustering, generate pseudo labels, and train your system. Vincent has shown that this actually gives quite a bit of performance in order to improve representation learning.
另一种方法是使用群集。 这是我的同事Vincent Christlein的作品。 他对建立更好的作者识别功能感兴趣。 因此,他从检测关键点开始。 然后,关键点使您可以提取补丁。 同时,如果使用SIFT之类的算法检测到关键点,则会附带一个特征描述符。 在将来的描述符上,您可以执行聚类,并且获得的聚类可能已经是很好的训练样本。 因此,您可以使用cluster-ID来训练例如ResNet来预测各个补丁。 这样,您可以使用完全未标记的数据集,进行聚类,生成伪标签并训练系统。 文森特(Vincent)已表明,这实际上可以提供很多性能,以改善表示学习。

This idea has then been developed further. You can do it in an alternating manner. This idea is called DeepCluster. Now, you take some input, you have a convnet, and you then essentially start from an untrained Network. You do clustering on the generated features and with the clustering, e.g. simply k-means, you can then generate pseudo labels that allow backpropagation and the training of the representation learning. Now, of course, if you start with random initialization, the clustering is probably not very good. So, you want to alternate between the classification and the clustering. Then, this allows you to build also a very powerful convolutional neural network. There are also some problems with trivial solutions that you want to avoid. So, you want to reassign empty clusters and, of course, you can use tricks like weighting the contribution of an input by the inverse of the size of its assigned cluster.
然后,这一想法得到了进一步发展。 您可以交替进行。 这个想法称为DeepCluster。 现在,您输入一些信息,您有了一个卷积网络,然后您实际上是从未经培训的网络开始的。 您可以对生成的特征进行聚类,并通过聚类(例如简单地使用k均值)进行聚类,然后可以生成允许反向传播和训练表示学习的伪标签。 现在,当然,如果您从随机初始化开始,则集群可能不是很好。 因此,您要在分类和聚类之间交替。 然后,这使您还可以构建非常强大的卷积神经网络。 您还需要避免一些琐碎的解决方案问题。 因此,您想重新分配空集群,当然,您可以使用一些技巧,例如按输入分配的集群大小的倒数加权输入的贡献。

You can even build on this idea further. This leads to self-labeling with optimal transport in [24]. Here, they essentially further developed DeepCluster. Instead of using clustering, they’re using the Sinkhorn-Knopp algorithm in order to determine pseudo labels. The idea here is that you try to predict the optimal transport. Here, we can see this example of an optimal transport problem. Let’s say, you have supplies in Warehouse A and Warehouse B. Each of them have 25 laptops and you have a need in each of Shop 1 and Shop 2 of 25 laptops. Then, you can see that you want to ship those laptops to the respective shops. Of course, you take the closest one and all of the laptops from Warehouse A, in this case, go to Shop 1 and all of the laptops of Warehouse B go to Shop 2.
您甚至可以进一步建立这个想法。 这导致了[24]中具有最佳运输的自标记。 在这里,他们实质上进一步开发了DeepCluster。 他们没有使用聚类,而是使用Sinkhorn-Knopp算法来确定伪标签。 这里的想法是您尝试预测最佳传输。 在这里,我们可以看到最佳运输问题的示例。 假设您在仓库A和仓库B中都有耗材。它们每个都有25台笔记本电脑,而25台笔记本电脑中的1号店和2号店都需要。 然后,您会看到想要将这些笔记本电脑运送到各自的商店。 当然,您要拿走仓库A中最接近的一台笔记本电脑,在这种情况下,请转到商店1,仓库B的所有笔记本电脑都应转到商店2。

The nice thing about this algorithm is that you can find a linear version of this. So, you can essentially express all of this with linear algebra and then this means that you can also embed it into a neural network. If you compare DeepCluser to the optimal transport, then you may want to keep in mind if you don’t have a separate clustering loss, this can lead to degenerate solutions. Also, keep in mind that the clustering approach minimizes the same cross-entropy loss that the network also seeks to optimize.
该算法的优点是您可以找到该算法的线性版本。 因此,您基本上可以使用线性代数表达所有这些内容,然后这意味着您也可以将其嵌入神经网络。 如果将DeepCluser与最佳传输进行比较,那么如果没有单独的群集丢失,则可能要记住,这可能导致解决方案退化。 另外,请记住,聚类方法可将网络也试图优化的交叉熵损失降至最低。

Well, there’s a couple of more ideas. We know these recipes like multi-task learning. You can also do multi-task learning for self-supervised learning. An example here is that you use synthetic imagery. So, you have some synthetic images where you can generate the depth, the surface normal, or also the contours. Then, you can use those as labels in order to train your network and produce a good representation. Additionally, you can also minimize the feature space domain differences between real and synthetic data in a kind of GAN setup. This leads also to very good representation learning.
好吧,还有更多其他想法。 我们知道这些食谱如多任务学习。 您也可以进行多任务学习以进行自我监督学习。 这里的一个示例是您使用合成图像。 因此,您具有一些合成图像,可以在其中生成深度,表面法线或轮廓。 然后,您可以将它们用作标签,以训练网络并产生良好的表示。 此外,您还可以通过一种GAN设置最小化真实数据和合成数据之间的特征空间域差异。 这也导致非常好的表示学习。

Next time, we want to talk about ideas on how to work with the losses and make them more suited towards the self-supervised learning task. We will see that in particular, the contrastive losses are very useful for this. So, thank you very much for listening and see you in the next video. Bye-bye!
下次,我们想讨论有关如何处理损失并使它们更适合自我监督学习任务的想法。 我们将特别看到对比损失对此非常有用。 因此,非常感谢您的收听,并在下一个视频中与您相见。 再见!

If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep LearningLecture. I would also appreciate a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced. If you are interested in generating transcripts from video lectures try AutoBlog.
如果你喜欢这篇文章,你可以找到这里更多的文章 ,更多的教育材料,机器学习在这里 ,或看看我们的深入 学习 讲座 。 如果您希望将来了解更多文章,视频和研究信息,也欢迎关注YouTube , Twitter , Facebook或LinkedIn 。 本文是根据知识共享4.0署名许可发布的 ,如果引用,可以重新打印和修改。 如果您对从视频讲座中生成成绩单感兴趣,请尝试使用AutoBlog 。
翻译自: https://towardsdatascience.com/weakly-and-self-supervised-learning-part-3-b8186679d55e
自我监督学习和无监督学习
相关文章:
- 聊天工具机器人开发_聊天机器人-精致的交流工具? 还是您的客户服务团队不可或缺的成员?...
- 自我监督学习和无监督学习_弱和自我监督的学习-第4部分
- ai星际探索 爪子_探索AI地牢
- 循环神经网络 递归神经网络_递归神经网络-第5部分
- 用于小儿肺炎检测的无代码AI
- 建筑业建筑业大数据行业现状_建筑—第2部分
- 脸部识别算法_面部识别技术是种族主义者吗? 先进算法的解释
- ai人工智能对话了_产品制造商如何缓解对话式AI中的偏见
- 深度神经网络 轻量化_正则化对深度神经网络的影响
- dbscan js 实现_DBSCAN在PySpark上的实现
- 深度学习行人检测简介_深度学习简介
- ai初创企业商业化落地_初创企业需要问的三个关于人工智能的问题
- scikit keras_使用Scikit-Learn,Scikit-Opt和Keras进行超参数优化
- 异常检测时间序列_DeepAnT —时间序列的无监督异常检测
- 机器学习 结构化数据_聊天机器人:根据结构化数据创建自然语言
- mc2180 刷机方法_MC控制和时差方法
- 城市ai大脑_激发AI研究的大脑五个功能
- 神经网络算法优化_训练神经网络的各种优化算法
- 算法偏见是什么_人工智能中的偏见有什么作用?
- 查看-增强会话_会话助手平台-Hinglish Voice等!
- 可解释ai_人工智能解释
- 机器学习做自动聊天机器人_聊天机器人业务领袖指南
- 神经网络 代码python_详细使用Python代码和数学构建神经网络— II
- tensorflow架构_TensorFlow半监督对象检测架构
- 最牛ai波士顿动力上台阶_波士顿动力的位置如何使美国成为人工智能的关键参与者...
- 阿里ai人工智能平台_AI标签众包平台
- 标记偏见_人工智能的偏见
- lstm预测单词_从零开始理解单词嵌入| LSTM模型|
- 动态瑜伽 静态瑜伽 初学者_使用计算机视觉对瑜伽姿势进行评分
- 全自动驾驶论文_自动驾驶汽车:我们距离全自动驾驶有多近?
自我监督学习和无监督学习_弱和自我监督的学习-第3部分相关推荐
- 监督学习与无监督学习的区别_机器学习
最近发现很多人还是不能真正分清机器学习的学习方法,我以个人的愚见结合书本简单说一下这个 机器学习中,可以根据学习任务的不同,分为监督学习(Supervised Learning),无监督学习(Unsu ...
- 监督学习和无监督学习_机器学习的要素是什么? 有监督学习和无监督学习两大类...
如前所述,机器学习是AI的一个子集,通常分为两大类:有监督学习和无监督学习. 监督学习 教学AI系统的常用技术是通过使用大量带标签的示例来训练它们.这些机器学习系统被馈入大量数据,这些数据已被注释以突 ...
- 监督学习和无监督学习_一篇文章区分监督学习、无监督学习和强化学习
经过之前的一些积累,终于有勇气开始进军机器学习了!说实话,机器学习 这个概念是我入行的最纯粹的原因,包括大学选专业.学习 Python 语言-这些有时间仔细梳理下经历再写,总之这个系列的文章就是我自学 ...
- 机器学习一 -- 什么是监督学习和无监督学习?
机器学习中的监督学习和无监督学习 说在前面 最近的我一直在寻找实习机会,很多公司给了我第一次电话面试的机会,就没有下文了.不管是HR姐姐还是第一轮的电话面试,公司员工的态度和耐心都很值得点赞,我也非常 ...
- 机器学习系列(一), 监督学习和无监督学习
常见的机器学习任务,可以分为监督学习和无监督学习两类 1,监督学习 监督学习的样本集是既有特征也有结果的数据,即已知输入与输出值.监督学习的任务时根据这些已知特征和结果的数据,训练模型,使得模型能够根 ...
- 理解监督学习、无监督学习、半监督学习、强化学习
目录 监督学习 回归问题 分类问题 无监督学习 半监督学习 强化学习 参考链接 监督学习 监督学习简单来说就是我们给学习算法一个数据集. 这个数据集由"正确答案"组成,然后使用已知 ...
- Chapter1:监督学习、无监督学习:AndrewNg吴恩达《机器学习》笔记
文章目录 Chapter 1 Introduction 1.1 Welcome 1.2 Definition 1.2.1 定义1: --from **Arthur Samuel** 1.2.2 定义2 ...
- 机器学习-什么是机器学习、监督学习和无监督学习
目录 什么是机器学习 监督学习和无监督学习 什么是机器学习 让计算机在没有被显式编程的情况下,具备自我学习的能力,针对某件事情,计算机会从经验中学习,并且越做越好. 监督学习和无监督学习 1. 监督学 ...
- 监督学习和无监督学习对比总结
机器学习 机器学习简单来说就是让机器进行自我学习,举个例子作为学生的我们经常参加考试,考试在考场上遇到的题目我们未必做过,但是在考试之前我们会刷很多的题目,通过刷题总结解题方法,这样上了考场也能以不变 ...
- 吴恩达机器学习之引言:入门、机器学习是什么、监督学习、无监督学习、推荐Octave软件进行开发
吴恩达机器学习栏目清单 专栏直达:https://blog.csdn.net/qq_35456045/category_9762715.html 文章目录 引言(Introduction) 1.1 欢 ...
最新文章
- Excel函数应用教程:数据库函数
- 趣学python3(25)-del,deepcopy以及内存引用计数
- 【Python】箱图boxplot--统计数据、观察数据利器
- 基本数据类型_JavaScript基本数据类型
- 53-java中的queue
- python字典值的和计算_第一章Python数据结构和算法(字典的运算)
- 如何在运行时确定对象类型(RTTI)
- oracle4.0,OracleTM Application Server 4.0简 介
- 钉钉电脑版如何申请调休 钉钉电脑版申请调休方法
- 统计方形++(洛谷P2241题题解,Java语言描述)
- C++ - 深入理解new
- 目标跟踪入门篇—相关滤波
- Android: 例如用户模块 保持登录后数据实时同步改变
- C++实现binary文件读取(可对‘bil‘,‘bsq‘ float32,double,unchar,unit16,unit8等格式进行读取)
- c语言输出最小值流程图,C语言实用程序设计100例流程图
- 超简单实用操作!用Python让Excel飞起来【附详细教程】
- 字幕文件srt格式解析
- Openbravo3.0 客户端代码开发与API
- java503错误是什么_java - Tomcat 503错误 - 堆栈内存溢出
- IFA与“色“俱进,三星“量子点+曲面”如何掀起新变革?
热门文章
- Android基于mAppWidget实现手绘地图(九)–如何处理地图对象的touch事件
- selenium webdriver - 截图
- 七月算法机器学习 10 聚类算法与应用
- 黑马程序员 re模块的高级用法 学习笔记
- vs中无法加入断点进行调试的解决方案
- matlab·计算机视觉·工具箱
- 190101每日一句
- Atitit 信息处理设备与历史与趋势 目录 1. It设备简史与艾提拉觉得常见重要的设备 2 2. 第一部分 IT萌芽期(约公元前4000年至1945年) 2 2.1. 苏美尔人的象形文字(约公元
- Atitit 项目培训与学校的一些思路总结
- atitit.错误:找不到或无法加载主类 的解决 v4 qa15.doc