Kafka(六)Kafka基本客户端命令操作
转载自:https://blog.51cto.com/littledevil/2147950
主题管理
创建主题
如果配置了auto.create.topics.enable=true(这也是默认值)这样当生产者向一个没有创建的主题发送消息就会自动创建,其分区数量和副本数量也是有默认配置来控制的。
# 我们这里创建一个3个分区每个分区有2个副本的主题
kafka-topics.sh --create --zookeeper 172.16.48.171:2181/kafka --replication-factor 2 --partitions 3 --topic KafkaTest| --create | 表示建立 |
| --zookeeper |
表示ZK地址,可以传递多个,用逗号分隔 --zookeeper IP:PORT,IP:PORT,IP:PORT/kafka |
| --replication-factor | 表示副本数量,这里的数量是包含Leader副本和Follower副本,副本数量不能超过代理数量 |
| --partitions | 表示主题的分区数量,必须传递该参数。Kafka的生产者和消费者采用多线程并行对主题的消息进行处理,每个线程处理一个分区,分区越多吞吐量就会越大,但是分区越多也意味着需要打开更多的文件句柄数量,这样也会带来一些开销。 |
| --topic | 表示主题名称 |

在Zookeeper中可以看到如下信息

删除主题
删除有两种方式手动和自动
手动方式需要删除各个节点日志路径下的该主题所有分区,并且删除zookeeper上/brokers/topics和/config/topics下的对应主题节点
自动删除就是通过脚本来完成,同时需要配置服务器配置文件中的delete.topic.enable=true,默认为false也就是说通过命令删除主题只会删除ZK中的节点,日志文件不会删除需要手动清理,如果配置为true,则会自动删除日志文件。
kafka-topics.sh --delete --zookeeper 172.16.48.171:2181/kafka --topic KafkaTest
下面的两句话就是说该主题标记为删除/admin/delete_topics节点下。实际数据没有影响因为该参数没有设置为true。
查看主题
# 列出所有主题
kafka-topics.sh --list --zookeeper 172.16.48.171:2181/kafka
下面是从ZK中看到的所有主题

# 查看所有主题信息
kafka-topics.sh --describe --zookeeper 172.16.48.171:2181/kafka
# 查看特定主题信息
kafka-topics.sh --describe --zookeeper 172.16.48.171:2181/kafka --topic BBB
Replicas:是AR列表,表示副本分布在哪些代理上,且该列表第一个元素就是Leader副本所在代理
ISR:该列表是显示已经同步的副本集合,这个列表的副本都是存活的
# 通过--describe 和 --under-replicated-partitions 可以查看正在同步的主题或者同步可能发生异常,
# 也就是ISR列表长度小于AR列表,如果一切正常则不会返回任何东西,也可以通过 --tipic 指定具体主题
kafka-topics.sh --describe --zookeeper 172.16.48.171:2181/kafka --under-replicated-partitions# 查看哪些主题建立时使用了单独的配置
kafka-topics.sh --describe --zookeeper 172.16.48.171:2181/kafka --topics-with-overrides这里只有一个内部主题__comsumer_offsets使用了非配置文件中的设置

配置管理
所谓配置就是参数,比如修改主题的默认参数。
主题级别的
# 查看配置
kafka-configs.sh --describe --zookeeper 172.16.48.171:2181/kafka --entity-type topics --entity-name BB这里显示 Configs for topic 'BBB' are 表示它的配置有哪些,这里没有表示没有为该主题单独设置配置,都是使用的默认配置。

# 增加一个配置
kafka-configs.sh --zookeeper 172.16.48.171:2181/kafka --entity-type topics --entity-name BBB --alter --add-config flush.messages=2
如果修改的话还是相同的命令,只是把值修改一下

# 删除配置
kafka-configs.sh --zookeeper 172.16.48.171:2181/kafka --entity-type topics --entity-name BBB --alter --delete-config flush.messages
客户端级别
这个主要是设置流控
# 设置指定消费者的流控 --entity-name 是客户端在创建生产者或者消费者时是指定的client.id名称
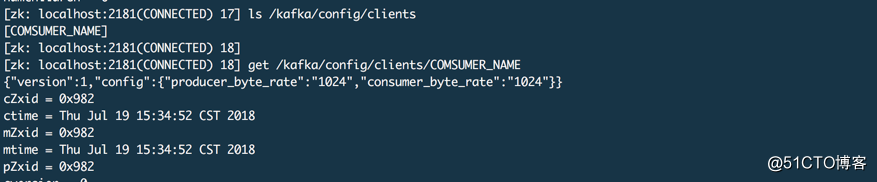
kafka-configs.sh --zookeeper 172.16.48.171:2181/kafka --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=1024' --entity-type clients --entity-name COMSUMER_NAME
下图为ZK中对应的信息
分区管理
分区平衡
Leader副本在集群中应该是均衡分布,因为Leader副本对外提供读写服务,尽可能不让同一个主题的多个Leader副本在同一个代理上,但是随着时间推移比如故障转移等情况发送,Leader副本可能不均衡。有两种方式设置自动平衡,自动和手动。
自动就是在配置文件中增加 auto.leader.rebalance.enable = true 如果该项为false,当某个节点故障恢复并重新上线后,它原来的Leader副本也不会转移回来,只是一个Follower副本。
手动就是通过命令来执行
kafka-preferred-replica-election.sh --zookeeper 172.16.48.171:2181/kafka分区迁移
当下线一个节点需要将该节点上的分区副本迁移到其他可用节点上,Kafka并不会自动进行分区迁移,如果不迁移就会导致某些主题数据丢失和不可用的情况。当增加新节点时,只有新创建的主题才会分配到新节点上,之前的主题分区不会自动分配到新节点上,因为老的分区在创建时AR列表中没有这个新节点。
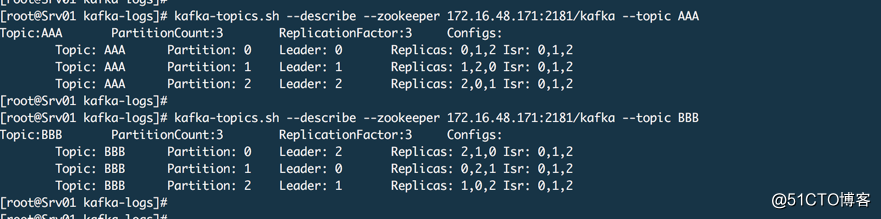
上面2个主题,每个主题3个分区,每个分区3个副本,我们假设现在代理2要下线,所以我们要把代理2上的这两个主题的分区数据迁移出来。
# 1. 在KAFKA目录的config目录中建立topics-to-move.json文件
{"topics":[{"topic":"AAA"},{"topic":"BBB"}],"version":1
}# 2. 生成分区分配方案,只是生成一个方案信息然后输出
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --topics-to-move-json-file ./topics-to-move.json --broker-list "1,2" --generate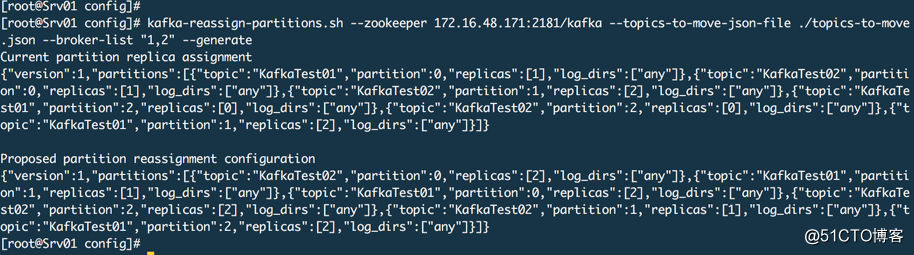
这个命令的原理是从zookeeper中读取主题元数据信息及制定的有效代理,根据分区副本分配算法重新计算指定主题的分区副本分配方案。把【Proposed partition reassignment configuration】下面的分区方案保存到一个JSON文件中,partitions-reassignment.json 文件名无所谓。
# 3. 执行方案
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --reassignment-json-file ./partitions-reassignment.json --execute
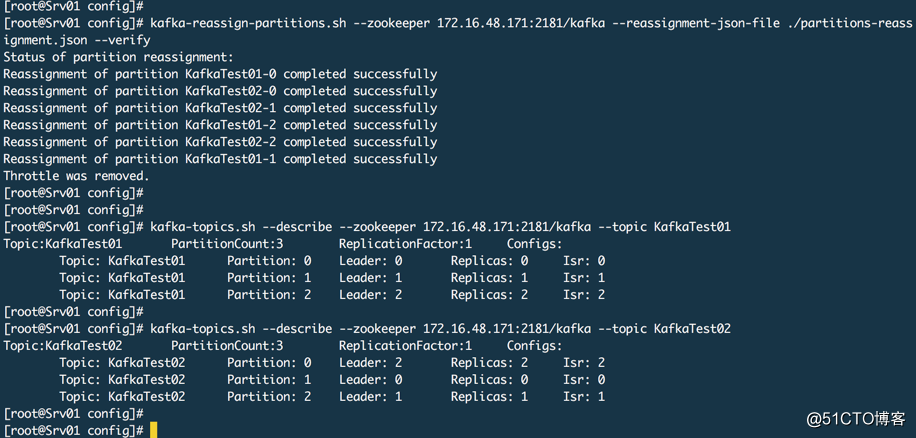
# 4. 查看进度
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --reassignment-json-file ./partitions-reassignment.json --verify
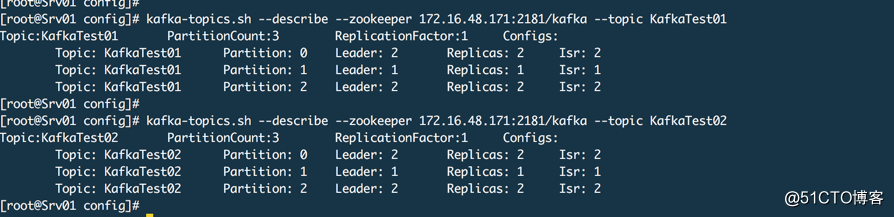
查看结果,这里已经没有代理0了。
集群扩容
上面演示了节点下线的数据迁移,这里演示一下集群扩容的数据迁移。我们还是用上面两个主题,假设代理0又重新上线了。其实扩容就是上面的反向操作
# 1. 建立JSON文件
# 该文件和之前的相同# 2. 生成方案并保存到一个JSON文件中
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --topics-to-move-json-file ./topics-to-move.json --broker-list "0,1,2" --generate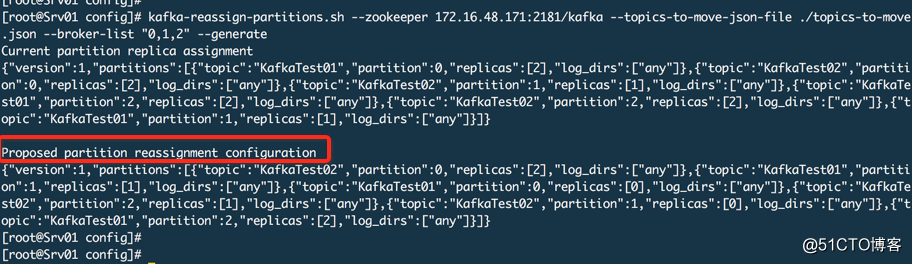
# 3. 数据迁移,这里通过--throttle做一个限流操作,如果数据过大会把网络堵塞。
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --reassignment-json-file ./partitions-reassignment.json --execute --throttle 1024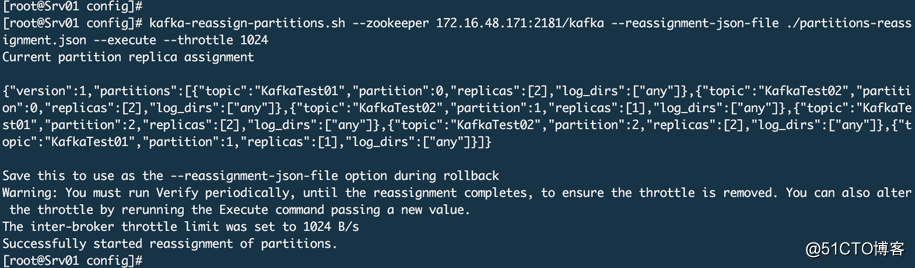
查看进度和结果
增加分区
通常在需要提供吞吐量的时候我们会增加分区,然后如果代理数量不扩大,同时生产者和消费者线程不增大,你扩展了分区也没有用。
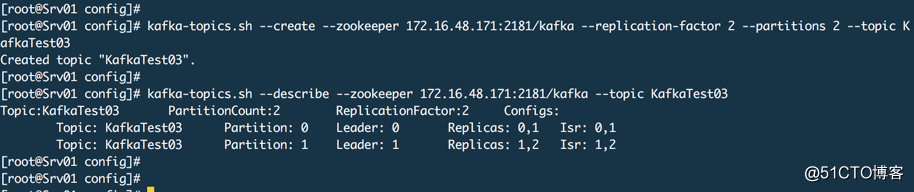
kafka-topics.sh --alter --zookeeper 172.16.48.171:2181/kafka --partitions 3 --topic KafkaTest03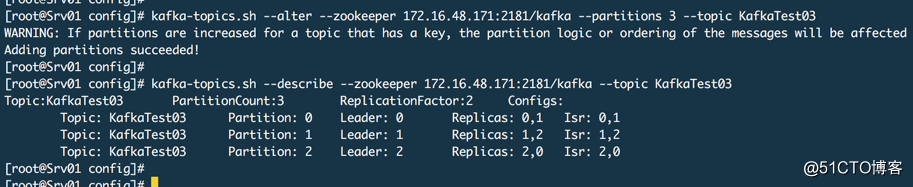
增加副本
集群规模扩大并且想对所有主题或者指定主题提高可用性,那么可以增加原有主题的副本数量

上面是3个分区,每个分区1个副本,我们现在把每个分区扩展为3个副本
# 1. 创建JSON文件 replica-extends.json
{"version": 1,"partitions": [{"topic": "KafkaTest04","partition": 0,"replicas": [0,1,2]},{"topic": "KafkaTest04","partition": 1,"replicas": [0,1,2]},{"topic": "KafkaTest04","partition": 2,"replicas": [0,1,2]}]
}# 2. 执行分区副本重新分配命令
kafka-reassign-partitions.sh --zookeeper 172.16.48.171:2181/kafka --reassignment-json-file ./replica-extends.json --execute
查看状态

查看结果

镜像操作
Kafka有一个镜像工具kafka-mirror-maker.sh,用于将一个集群数据同步到另外一个集群中,这个非常有用,比如机房搬迁就需要进行数据同步。该工具的本质就是创建一个消费者,在源集群中需要迁移的主题消费数据,然后创建一个生产者,将消费的数据写入到目标集群中。
首先创建消费者配置文件mirror-consumer.properties(文件路径和名称是自定义的)
# 源kafka集群代理地址列表
bootstrap.servers=IP1:9092,IP2:9092,IP3:9092
# 消费者组名
group.id=mirror其次创建生产者配置文件mirror-producer.properties(文件路径和名称是自定义的)
# 目标kafka集群地址列表
bootstrap.servers=IP1:9092,IP2:9092,IP3:9092运行镜像命令
# 通过 --whitelist 指定需要镜像的主题,通过 --blacklist 指定不需要镜像的主题
kafka-mirror-maker.sh --consumer.config PATH/mirror-consumer.properties --producer.config PATH/mirror-producer.properties --whitelist TOPIC由于镜像操作是启动一个生产者和消费者,所以数据同步完成后这个生产者和消费者并不会关闭,它会依然等待新数据,所以同步完成以后你需要自己查看,确认完成了则关闭生产者和消费者。
Kafka(六)Kafka基本客户端命令操作相关推荐
- Zookeeper03之客户端命令操作
前面两篇文章给大家介绍了zookeeper的集群搭建,本篇文章来介绍下zookeeper的客户端命令操作 Zookeeper01之介绍和安装环境准备 Zookeeper02之集群环境搭建 bin目 ...
- 大数据面试重点之kafka(六)
大数据面试重点之kafka(六) Kafka分区分配算法 可回答:Kafka的partition分区策略问过的一些公司:阿里云,小米参考答案: 1.生产者分区分配策略 生产者在将消息发送到某个Topi ...
- ACL+SASL的认证配置后的Kafka命令操作(Windows版)
ACL+SASL的认证配置后的Kafka命令操作 Windows环境 背景 版本 操作 配置文件准备 Zookeeper配置文件 Clients配置文件 Kafka Server配置文件 JAAS配置 ...
- kafka实战教程(python操作kafka),kafka配置文件详解
全栈工程师开发手册 (作者:栾鹏) 架构系列文章 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是否容忍重复?消息的吞吐量 ...
- Apache Kafka 入门 - Kafka命令详细介绍
Apache Kafka 入门 Apache Kafka 入门大概分为5篇博客,内容都比较基础,计划包含以下内容: Kafka的基本配置和运行 Kafka命令详细介绍 Kafka-manager的基本 ...
- 【Kafka】kafka 客户端 控制台 flink 都无法消费的情况
本文为博主九师兄(QQ:541711153 欢迎来探讨技术)原创文章,未经允许博主不允许转载.有问题可以先私聊我,本人每天都在线,会帮助需要的人. 文章目录 1.概述 1.概述 首先参考文章: Kaf ...
- linux下zookeeper启动命令,For Linux Zookeeper客户端命令行操作指令
目录 客户端命令行操作 1.启动客户端 2.停止客户端 3.显示所有操作命令 4.查看当前节点信息 ls ~ 详细信息 ls2 5.分别创建两个普通节点 6.获取节点的值 7.创建短暂节点 ~ cr ...
- java day47【redis概念 、下载安装 、 命令操作 、持久化操作 、使用Java客户端操作redis】...
第一章 Redis 1. 概念: redis是一款高性能的NOSQL系列的非关系型数据库 1.1.什么是NOSQL NoSQL(NoSQL = Not Only SQL),意即"不仅仅是S ...
- ZooKeeper进阶之客户端命令行操作
一 Znode数据结构 ZK有一个最开始的节点 / ZK的节点叫做znode节点 每个znode节点都可存储数据 每个znode节点(临时节点除外)都可创建自己的子节点 多个znode节点共同形成了z ...
最新文章
- 窥见人工智能四十年 2019 CCF-GAIR全球人工智能与机器人峰会今日开幕
- Android4.0-4.4 加入支持状态栏显示耳机图标方法(支持带不带MIC的两种耳机自己主动识别)...
- Python:操作文件
- 易语言 精易模块 操作json数据
- 【ok】李宏毅机器学习12: 对称矩阵
- mysql dba系统学习(20)mysql存储引擎MyISAM
- json支持的最大长度_Swifter.Json 可能是 .Net 平台迄今为止性能最佳的 Json 序列化库【开源】...
- Azkaban通过API动态传递参数
- 数据加密类型及创建和申请CA证书
- 存储类型auto,static,extern,register的区别 转
- Tomcat修改源码,重新编译
- 在Flash中接收来自页面(.NET)的值的方法.
- 国外游戏开发商吐槽:开发VR游戏付账单的钱都赚不到
- 「力扣」509. 斐波那契数【动态规划】详解!
- 互联网晚报 | 9/28星期三 | 微信退群可选保留聊天记录 ;iPhone 14 Pro被吐槽信号差;贾跃亭率获1亿美元融资...
- 地铁供电系统原理图_地铁供电系统的运行方式及特点分析吴迪原稿(图文高清版)...
- 创建加密访问网站,端口443
- CDR制作印章的流程
- 设为首页 加入收藏 html,JS设为首页和加入收藏的代码
- 如何查看网页元素的名称ID和其他信息
热门文章
- java 柱状图 宽度_Java实现 LeetCode 84 柱状图中最大得矩形
- kafka学习_Kafka 学习笔记01
- 耳机不分主从是什么意思_无延时音质好的蓝牙耳机能代替有线耳机吗—DOSS T60上手体验...
- 笔记本电脑如何保养_电脑保养只是吹一吹?别再被骗了,电脑没做这些就等于没保养...
- 【LeetCode笔记】剑指 Offer 57-. 和为s的两个数字 (Java、对撞双指针)
- python3如何安装selenium_Mac-Firefox浏览器+selenium+Python3环境安装
- oracle主从表分离怎么实时更新数据_高可用数据库UDB主从复制延时的解决
- python怎么定义正方形函数_python – Matplotlib自定义图例以显示正方形而不是矩形...
- hashmap 扩容是元素还是数组_曹工说JDK源码(1)--ConcurrentHashMap,扩容前大家同在一个哈希桶,为啥扩容后,你去新数组的高位,我只能去低位?...
- 5分钟k线数据 存储_成功率极高的“分时K线战法”:15分钟K线战法+30分钟K线战法...