聚类算法当中的K-means算法如何去做天猫淘宝的推广任务

 data-size="normal">
data-size="normal">
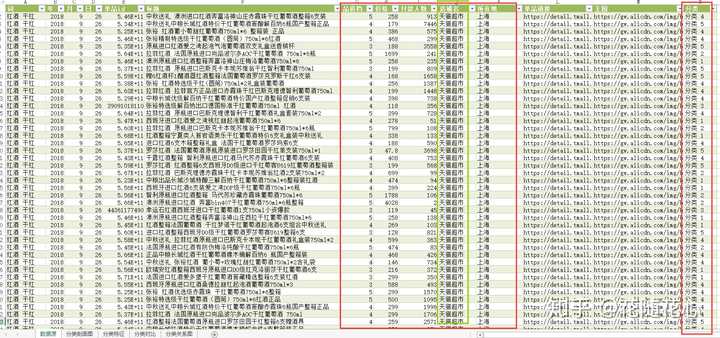
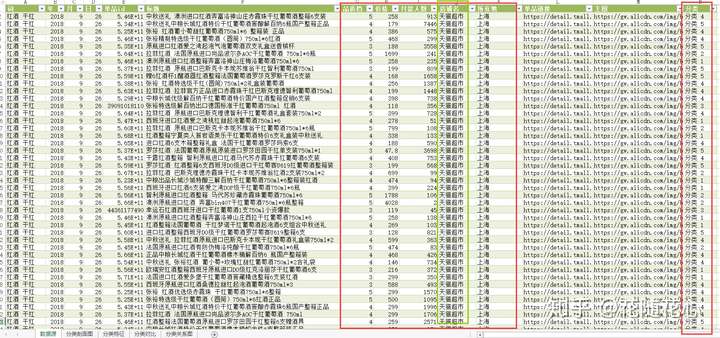
这个入口是全网人气新品池,我们今天所获取到的数据都是来源于这里。无论是C店还是B店,统统都有机会进来。这个平台最有价值的数据,就是可以告诉我们自己的新品究竟算是什么品质的,俗称档次,如图所示
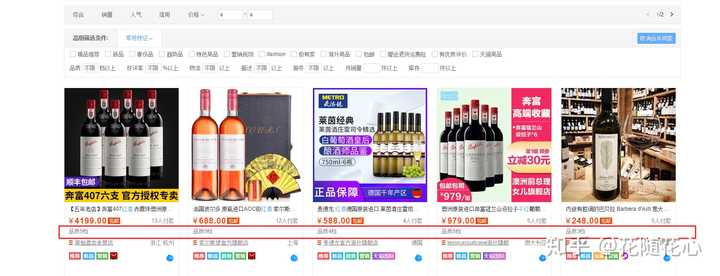
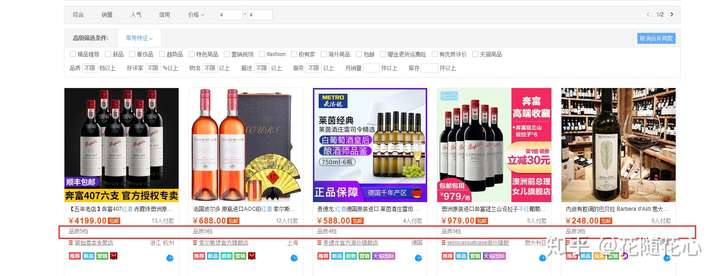
不同档位的产品,,平台的推荐力度不同,并且这里是达人们经常选品的地方,如果能进来这里,实际上也算是多了一层曝光。
从营销的角度来讲,实际上让产品尽量得到足够多的曝光才是当务之急的事情。除了达人会主动推荐外,手淘首页也会进行推荐。
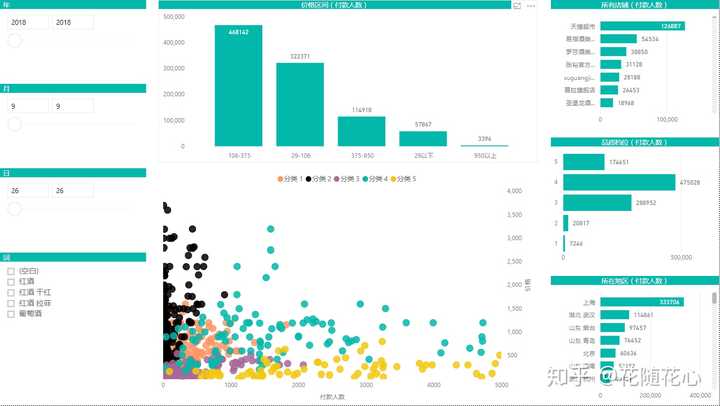
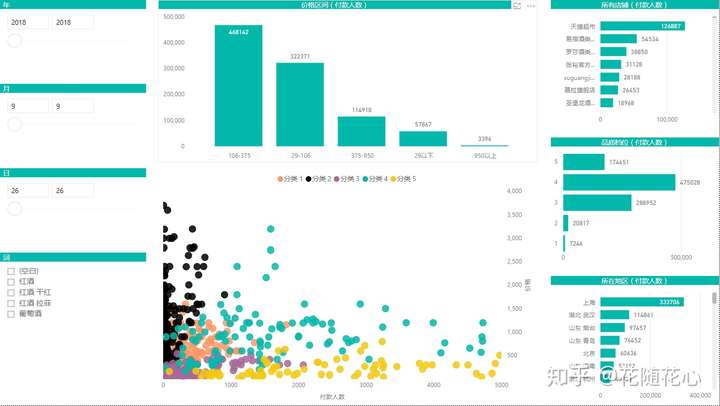
这份数据图表就是今天的案例13。重点部分内容就是这个散点图。我们之前做过很多散点图的同学应该都很清楚,散点图本身不难,但如果想要让散点图里头的数据都能够自动分好类的话,似乎不是那么容易的事情。
正如上面这张图所示,我把获取到的快选池新品数据,按不同的关键词进行分类,不同关键词下都可以将数据自动分成5个类别,也就是5种不同的数据。
之所以进行分类,是因为可以更好的区别不同类别的数据特征。因此,为了达到这个效果,我使用了聚类算法当中的K-means算法。不懂算法的同学不要紧,因为微软已经帮我们做好了一个专门来用进行数据挖掘的套件。我们暂且先来看看,究竟这些不同类别的数据都有什么特征。
数据源当中,我使用了品质档、价格、付款人数、所在地,通过K-means算法进行聚类,最后得到5个不同的类别。这些类别的名字分别从1-5进行取名。
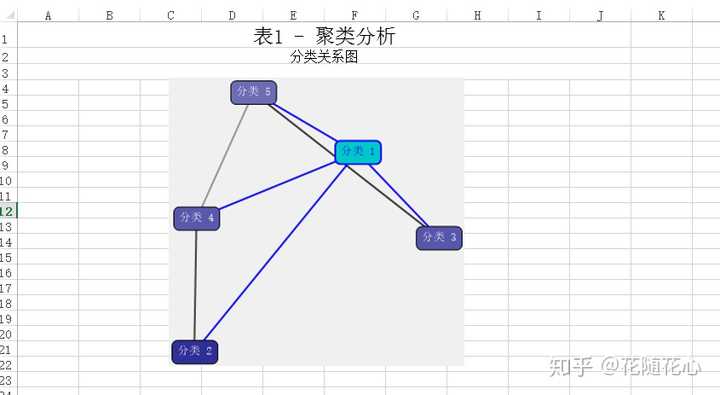
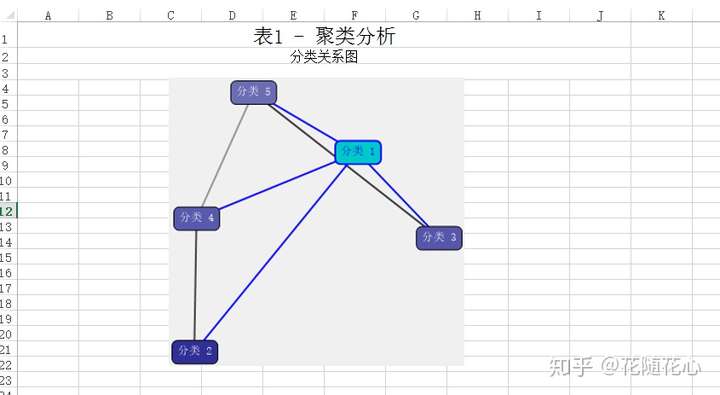
通过这个关系图,我们可以很明显看得出来,实际上分类1的数据可以直接连接分类2、3、4、5,说明其重要性不言而喻。
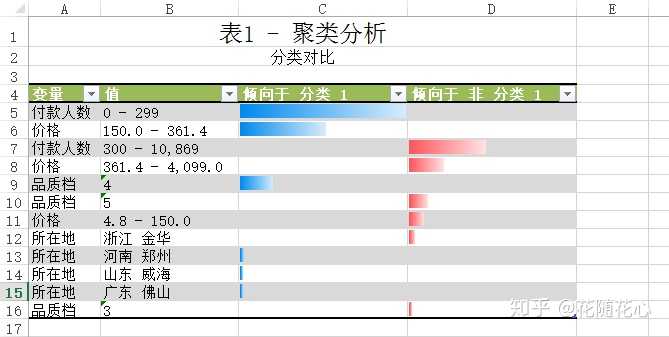
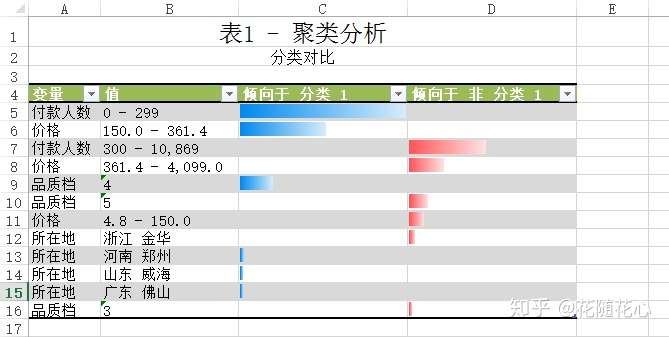
暂且从分类1的角度来看数据,从上面这个图可以看出,分类1的一些特征,比如付款人数在0-299这个范围,价格150.0-361.4这个范围,其他的以此类推,最关键的地方在于这些数据背后的产品,基本上代表的就是第4档位的产品。
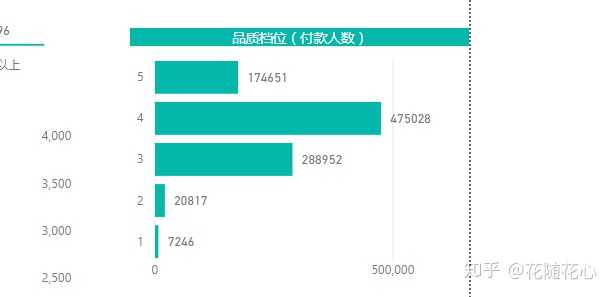
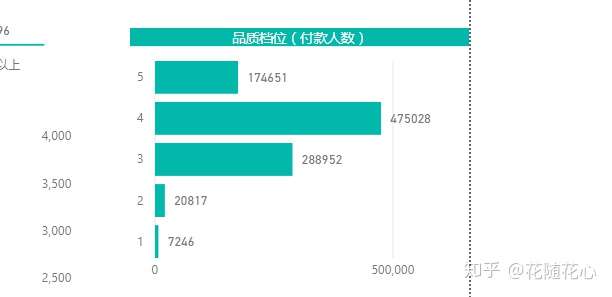
而实际上,这个档次的产品的销量是最好的。那么也就是我们这里的分类1的产品代表的就是最好的。
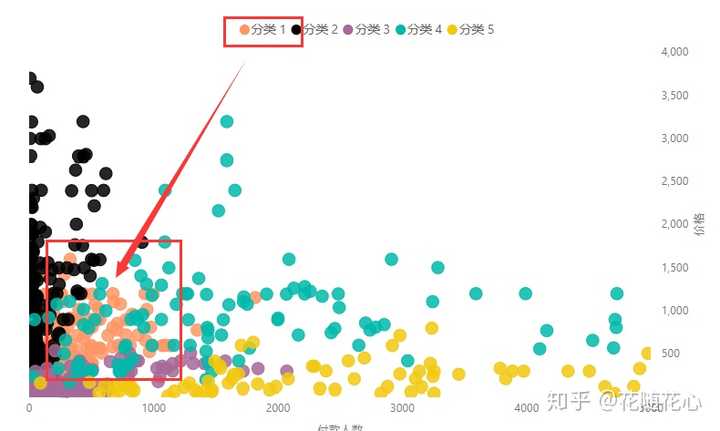
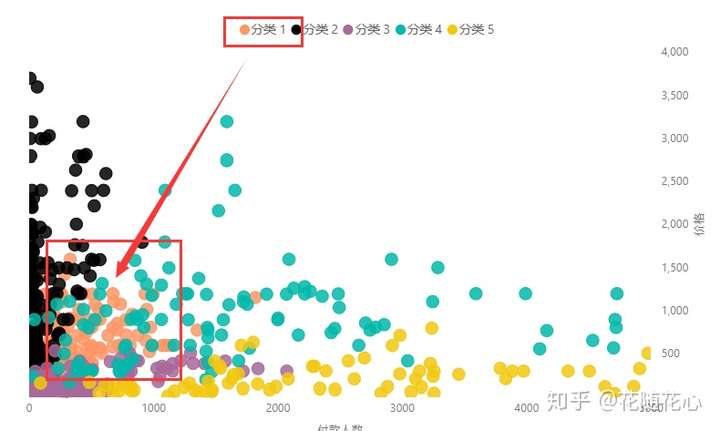
从散点图我们可以看出来,实际上这个分类被其他分类给包裹住了,哈哈。如果没有事先进行数据挖掘的话,我们将看到一堆小圈圈在浮动。
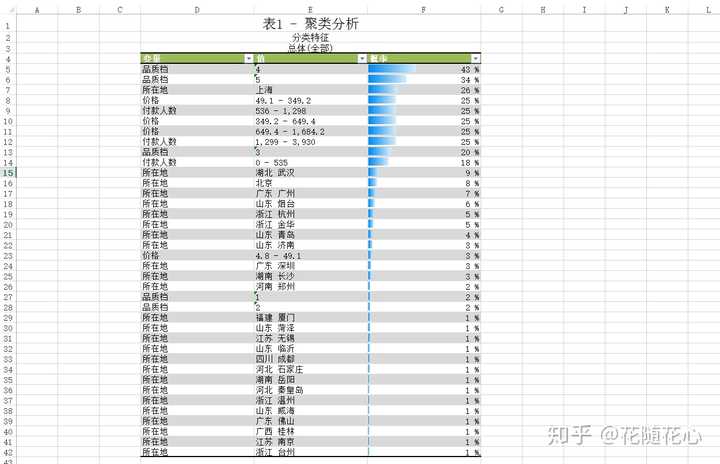
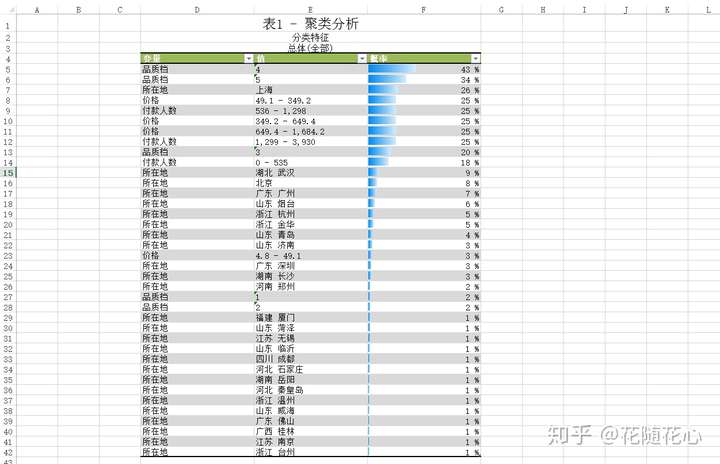
这个是分类特征图,基本上可以快速告诉我们数据的很多信息了。比如,档次上来讲就是集中在4和5,所在地上海就是个热门区域。
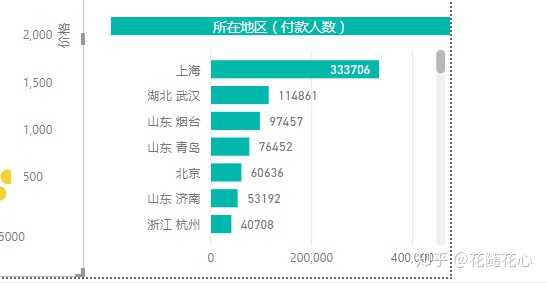
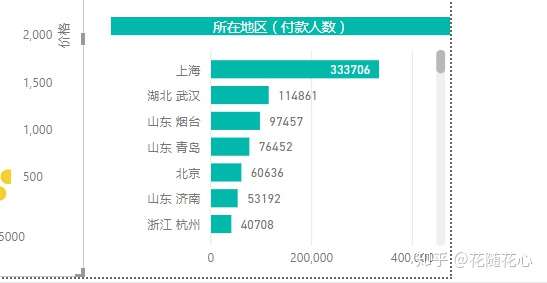
通过我们自己做的PBI图表,也是可以看得出来的,这里可能更加明显。
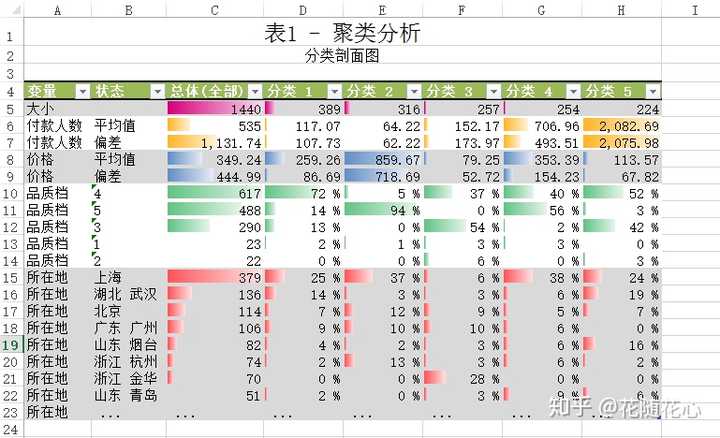
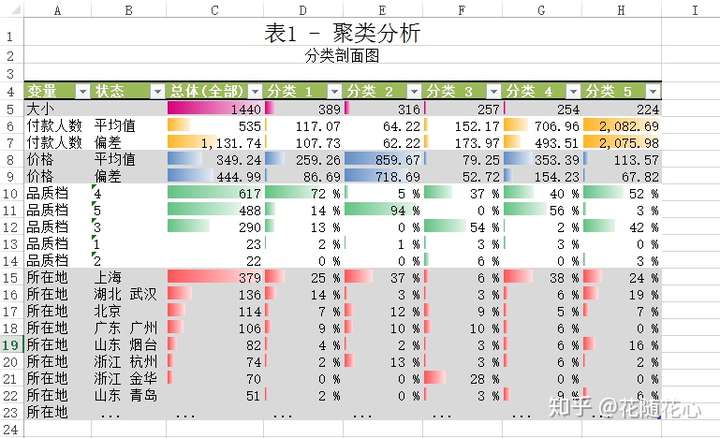
这个数据挖掘套件的好处在于,还能告诉我们不同类别的具体特征,比如从付款人数的平均值来看,分类1在117.07,分类2在64.22,分类3在152.17等等。这样子看数据是不是很方便了。
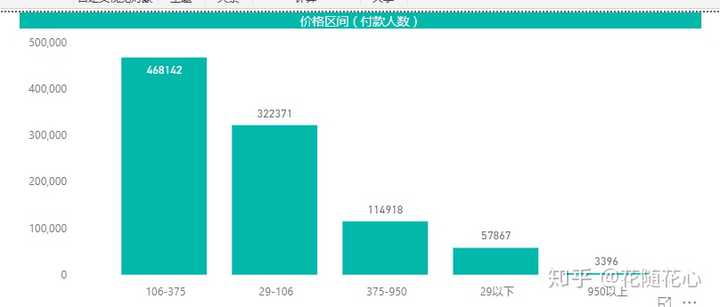
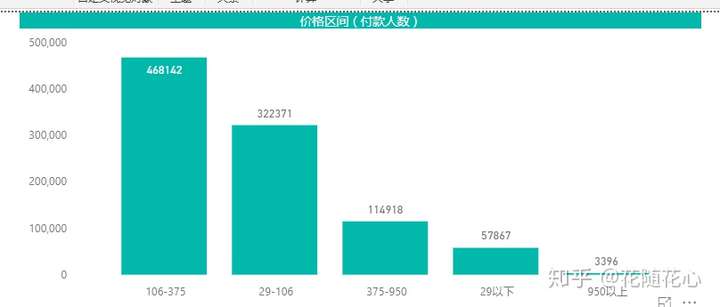
结合价格区间,我们也可以看出这些产品的价格段分布,基本上在106-375之间。因此,我们的定价这块应该着重考虑这个价格段的。
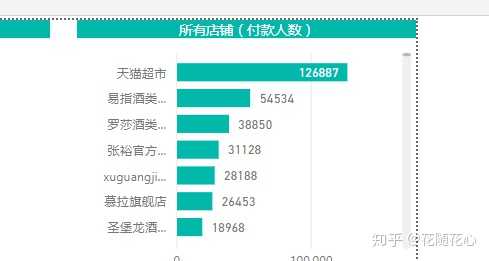
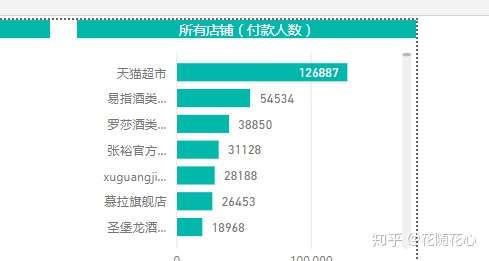
因为红酒属于标品,因此大品牌特别多,我们可以看出来官方超市是第一位的,其次是上面这些品牌。
最后,说一下这次用到的数据,主要来自于花老师自己研发的数据分析工具箱当中的其中一项功能,如图所示
目前为止,这个是第5代版本,一共有15个免费功能,当然随着我后面的不断更新,肯定会加入更多实用功能进来,尽请期待!
希望我今天的分享能对大家有所帮助,谢谢!不废话,关注知乎专栏花随花心,送数据分析工具箱!
收藏感谢
收起
聚类算法当中的K-means算法如何去做天猫淘宝的推广任务相关推荐
- kmeans改进 matlab,基于距离函数的改进k―means 算法
摘要:聚类算法在自然科学和和社会科学中都有很普遍的应用,而K-means算法是聚类算法中经典的划分方法之一.但如果数据集内相邻的簇之间离散度相差较大,或者是属性分布区间相差较大,则算法的聚类效果十分有 ...
- 算法基础:k最近邻算法
本博客所有内容均整理自<算法图解>,欢迎讨论交流~ 了解过机器学习这个概念,一定知道有一种名为k最近邻的算法,简称KNN. 对于k最近邻算法的定义,百度百科是这样给出的:K最近邻(k-Ne ...
- 机器学习算法系列之K近邻算法
本系列机器学习的文章打算从机器学习算法的一些理论知识.python实现该算法和调一些该算法的相应包来实现. 目录 K近邻算法 一.K近邻算法原理 k近邻算法 通俗解释 近邻距离的度量 k值的选择 KN ...
- k means算法C语言伪代码,K均值算法(K-Means)
1. K-Means算法步骤 算法步骤 收敛性定义,畸变函数(distortion function): 伪代码: 1) 创建k个点作为K个簇的起始质心(经常随机选择) 2) 当任意一个点的蔟分配结果 ...
- k均值聚类算法(K Means)及其实战案例
算法说明 K均值聚类算法其实就是根据距离来看属性,近朱者赤近墨者黑.其中K表示要聚类的数量,就是说样本要被划分成几个类别.而均值则是因为需要求得每个类别的中心点,比如一维样本的中心点一般就是求这些样本 ...
- Udacity机器人软件工程师课程笔记(二十一) - 对点云进行集群可视化 - 聚类的分割 - K-means|K均值聚类, DBSCAN算法
聚类的分割 1.K-均值聚类 (1)K-均值聚类介绍 k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心 ...
- 5 模式识别-动态聚类算法(K均值算法、迭代自组织的数据分析ISOData算法)
武汉理工大学资源 郭志强 动态聚类算法:先选取初始的中心(每个类别的初始中心),然后把所有的样本进行聚类分析,聚类完成后,就去判断这个聚类结果合不合理(满不满足设计指标要求),如果合理就输出聚类结果( ...
- (学习笔记)聚类算法 - k均值算法(k-means)
聚类之K均值算法 聚类介绍 k均值算法步骤 Python实现 参考文献 聚类介绍 聚类是一种经典的无监督学习方法. 聚类的目的是将数据集中的样本划分为若干个通常是不相交的子集,每个子集被称为簇,以此来 ...
- 【数据聚类】基于改进的粒子群算法优化K-means算法实现数据分类含Matlab源码
1 简介 针对传统的K-means算法对初始聚类中心的选取敏感,容易收敛到局部最优的缺点,提出一种基于改进粒子群优化算法(PSO)的K-means优化聚类算法.该算法利用PSO算法强大的全局搜索能力对 ...
最新文章
- const(常量)和#define(宏定义)区别
- model.fit() 参数详解【TensorFlow2入门手册】
- linux mysql安装失败 lib冲突问题_Linux 安装 Mysql 冲突 问题
- 这个 Python 代码自动补全神器搞得我卧槽卧槽的
- ModuleNotFoundError: No module named ‘Crypto‘ 踩坑
- 如何更高效地使用 OkHttp
- 超好用的代码格式化工具Astyle使用
- Cplex安装教程与使用介绍
- Centos7搭建coreseek
- 通过ajax异步请求下载文件的方法
- 【松果圆桌派】全年线下客流量超4000万,COMMUNE的场景体验式玩法是如何打造的?
- 聊聊HotSpot VM的Native Memory Tracking
- 二维数组的花式遍历技巧盘点
- 用python进行列联表卡方检验
- 计算机组成原理中的直接映像,计算机组成原理--cache存储器的直接映像与变换...
- mitm 和嗅探攻击_中间人攻击(MITM)第2部分-数据包嗅探器
- 队伍不好带!周鸿祎要拆分360业务 鼓励内部创业
- 牛客 刺客信条 (bfs、dijkstra)+堆优化、dfs三种求解
- 三万块钱6天的区块链培训,我学会了搭建区块链系统框架?
- 中国农大博士计算机专业考试大纲,中国农业大学考博经验