MOOC 数据结构 | 3. 树(上)
1.什么是树
客观世界中许多事物存在层次关系
- 人类社会家谱
![]()
- 社会组织架构
- 图书信息管理
为什么数据结构中要采用树?社会管理等要采用层次结构?
分层次组织在管理上具有更高的效率!
举例分析:
数据管理的基本操作之一:查找
如何实现有效率的查找?
查找(Searching)
查找:根据某个给定关键字K,从集合R中找出关键字与K相同的记录
静态查找:集合中记录是固定的
- 没有插入和删除操作,只有查找 (如查字典)
动态查找:集合中记录是动态变化的
- 除查找,还可能发生插入和删除
静态查找
在数组中查找元素。
方法1:顺序查找
![]() 将元素放在数组中,在数组外用一个结构来指向该数组:
将元素放在数组中,在数组外用一个结构来指向该数组:
![]()
该结构有两个分量:指针指向数组的头,元素的个数:
![]()
可以看到,数组元素的存放是从1开始的:
![]()
之所以这样设计是为了介绍一种技巧:哨兵。
哨兵的作用是不用每次都去判断下标是否到达了边界。
如下是无哨兵和有哨兵的区别:
typedef struct LNode *List;
struct LNode{ElementType Element[MAXSIZE];int Length;
};//顺序查找的一种实现(无“哨兵”)
int SequentialSearch(List Tbl, ElementType K)
{/*在Element[1]~Element[n]中查找关键字为K的数据元素*/int i;for(i = Tbl->Length; i>0 && Tbl->Element[i] != K; i--);return i; /*查找成功返回所在单元下标;不成功返回0*/
}![]()
typedef struct LNode *List;
struct LNode{ElementType Element[MAXSIZE];int Length;
};int SequentialSearch(List Tbl, ElementType K)
{/*在Element[1]~Element[n]中查找关键字为K的数据元素*/int i;Tbl->Element[0] = K; /*建立哨兵*/for(i = Tbl->Length; Tbl->Element[i] != K; i--);return i; /*查找成功返回所在单元下标;不成功返回0*/
}上述例子中,可以看到将关键字K放到了下标0位置处。
顺序查找时间复杂度为O(n),平均时间复杂度为 (最好情况是第一个就是,最坏情况最后一个才是)。
方法2:二分查找(Binary Search)
假设n个数据元素的关键字满足有序(比如:小到大) 并且是连续存放(数组),那么可以进行二分查找。
【例】假设有13个元素,按关键字由小到大顺序存放。二分查找关键字为444的数据元素过程如下:
![]()
1、left = 1,right = 13;mid = (1+13)/2 = 7: 100 < 444;
缩小查找范围:
![]()
2、left = mid + 1 = 8,right = 13;mid = (8+13)/2=10: 321 < 444;
又缩小范围:
![]()
3、left = mid + 1 = 11,right = 13;mid = (11+13)/2 = 12: 查找结束;
【例】仍然以上面13个数据元素构成的有序线性表为例,二分查找关键字为43的数据元素如下:
![]()
1、left =1, right =13;mid = (1+13)/2 = 7: 100 > 43;
缩小范围:
![]()
2、left = 1,right = mid-1 = 6;mid = (1+6)/2 = 3: 39 < 43;
所以要挪动left的位置:
![]()
3、left = mid +1 = 4,right = 6;mid = (4+6)/2 = 5: 51 > 43;
说明要寻找的值落在51前面,修改right值:
![]()
4、left = 4,right = mid - 1 = 4;mid = (4+4)/2 = 4: 45 > 43;
![]()
5、left = 4,right = mid -1 = 3;left > right? 查找失败,结束;
二分查找算法
typedef struct LNode *List;
struct LNode{ElementType Element[MAXSIZE];int Length;
};int BinarySearch(List Tbl, ElementType K)
{/*在表Tbl中查找关键字为K的数据元素*/int left, right, mid, NoFound = -1;left = 1; /*初始左边界,数组中是从下标1开始存放数据的*/right = Tbl->Length; /*初始右边界*/while(left <= right){mid = (right - left)/2 + left; /*防止溢出,计算中间元素坐标*/if (K < Tbl->Element[mid]) right = mid-1; /*调整右边界*/else if (K > Tbl->Element[mid]) left = mid+1; /*调整左边界*/else return mid; /*查找成功,返回数据元素的下标*/}return NoFound; /*查找不成功,返回-1*/
}查找过程中每次都是除以2, 除以2,.... 除以多少次等于1,即,所以结果就是x = logN。
二分查找算法具有对数的时间复杂度O(logN)
【※】11个元素的二分查找判定树
从下标为1的地方开始放元素,放到下标为11的地方。二分查找某个元素的过程一定是按照这样的层次结构来的:
![]()
- 判断树上每个结点需要的查找次数刚好为该结点所在的层数; (比如位于4号位置,则比较3次)
- 查找成功时查找次数不会超过判定树的深度
- n个结点的判断树的深度为
- ASL = (4*4 + 4*3 + 2*2 + 1)/ 11 = 3 (平均成功查找次数)
2. 树的定义
树(Tree):n ( n≥0)个结点构成的有限集合。
当n = 0时,称为空树;
对于任一棵非空树(n>0),它具备以下性质:
- 树中有一个称为“根(Root)”的特殊结点,用
表示;
- 其余结点可分为m(m>0)个互不相交的有限集
其中每个集合本身又是一棵树,称为原来树的“子树(SubTree)”
![]()
上图树T的根就是A,由如下四个子树构成:
![]()
2.1 ※树与非树?
![]() (多了C-D的连线,无法切分为不相交的集合)
(多了C-D的连线,无法切分为不相交的集合)
![]() (多了C-E的连线)
(多了C-E的连线)![]()
![]() (多了D-G的连线)
(多了D-G的连线)
![]()
- 子树是不相交的;
- 除了根结点外,每个结点有且仅有一个父结点;
- 一棵N个结点的树有N-1条边。 (每个结点都有向上的一根连接父结点的线,除了根结点,所以是N-1)
树是保证结点连通的最小的连接方式(即边最少)。
2.2 ※树的一些基本术语
![]()
- 结点的度(Degree):结点的子树个数 --如上图:结点A的度为3,B为2,C为1,D为3,F为0,...
- 树的度:树的所有结点中最大的度数 --如上图:A和D的度都为3,所以树的度为3
- 叶结点(Leaf):度为0的结点
- 父结点(Parent):有子树的结点是其子树的根结点的父结点
- 子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点。
- 兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点。
- 路径和路径长度:从结点
到
的路径为一个结点序列
是
的父结点。路径所包含边的个数为路径的长度。
- 祖先结点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点。
- 子孙结点(Descendant):某一结点的子树中的所有结点是这个结点的子孙。
- 结点的层次(Level):规定根结点在1层,其他任一结点的层数是其父结点的层数加1。
- 树的深度(Depth):树中所有结点中的最大层次是这棵树的深度。
3. 树的表示
![]()
如图的一棵树,能否用数组实现?
==>用数组实现:就是把这些结点按顺序用数组存起来,难度大,因为难以分清结点的父结点和子孙结点等。
用链表实现:
==>每个结点用个结构来表示
![]()
存在的问题:每个结点的结构不同,不知道结点有几个子孙结点,为程序实现带来了难度。
另一种思路:每个结点的结构设计为相同的,如都同A一样,设计为3个指针域,那么假设有n个结点,就一共需要3n-1个指针域,但是n个结点实际上就只有n-1个指针域不为空。这种思路也不行。
下面介绍一种方法:
3.1 儿子-兄弟表示法
树上的结点结构统一。
![]()
FirstChild指针指向第一个儿子,NextSibiling指向下一个兄弟结点。
例如:
![]()
![]() 将这个表示方法旋转45°
将这个表示方法旋转45°
![]()
旋转45°后的这棵树每个结点都有两个指针,每个结点最多两个儿子,这种树叫做二叉树。
4. 二叉树
4.1 二叉树的定义
二叉树T:一个有穷的结点集合。
这个集合可以为空
若不为空,则它是由根结点和称为其左子树和右子树
的两个不相交的二叉树组成。
□二叉树具体五种基本形态
![]()
□ 二叉树的子树有左右顺序之分
(这也是与度为2的树的区别)
![]()
4.2 特殊二叉树
- 斜二叉树(Skewed Binary Tree)
![]()
- 完美二叉树(Perfect Binary Tree) / 满二叉树(Full Binary Tree)
![]()
- 完全二叉树(Complete Binary Tree)
有n个结点的二叉树,对树中结点按从上至下、从左到右顺序进行编号,编号为( 1 ≤
≤ n)结点与满二叉树中编号为
结点在二叉树中位置相同
![]() (这是一棵完全二叉树)
(这是一棵完全二叉树)
![]() 所以,
所以,![]() 不是完全二叉树。
不是完全二叉树。
4.3 二叉树的几个重要性质
- 一个二叉树第 i 层的最大结点数为
- 深度为k的二叉树有最大结点总数为:
(
)---完美二叉树可以达到
- 对任何非空二叉树T,若
表示叶结点的个数、
是度为2的非叶结点个数,那么两者满足关系
![]() (
(表示只有一个儿子的结点)
该结论的证明:
结点总个数:
总的边数:(每个结点有向上的边一条除了根结点) (不同类型结点向下的边的条数)
4.4 二叉树的抽象数据类型定义
|
类型名称:二叉树 数据对象集:一个有穷的结点集合 若不为空,则由根结点和其左、右二叉子树组成。 操作集:BT∈BinTree,Item∈ElementType,重要操作有:
|
常用的遍历方法有:
- void PreOrderTraversal(BinTree BT): 先序----根、左子树、右子树
- void InOrderTraversal(BinTree BT): 中序---左子树、根、右子树
- void PostOrderTraversal(BinTree BT):后序---左子树、右子树、根
- void LevelOrderTraversal(BinTree BT):层次遍历,从上到下,从左到右
4.4 二叉树的存储结构
1. 顺序存储结构
完全二叉树:按从上至下、从左到右顺序存储n个结点的完全二叉树的结点父子关系:
![]()
![]()
- 非根结点(序号i > 1)的父结点的序号是
; ------如C结点,它的父结点是4/2 = 2 ,即B;如S结点,它的父结点5/2 = 2,即B
- 结点(序号为
)的左孩子结点的序号是
,(若
,否则没有左孩子); -----如S结点,5*2 = 10大于9,就不存在
- 结点(序号为
,(若
,否则没有右孩子);
一般二叉树也可以采用这种结构,但会造成空间浪费......
![]() 补全为完全二叉树--->
补全为完全二叉树--->![]()
补全为完全二叉树后可以用数组存储,但是有很多都是空的,会造成空间浪费。
![]()
2.链表存储
![]()
数据结构定义:
typedef struct TreeNode *BinTree;
typedef BinTree Position;
struct TreeNode
{ElementType Data;BinTree Left;BinTree Right;
};![]()
4.5 二叉树的遍历
4.5.1 二叉树的递归遍历
(1)先序遍历
遍历过程为:
①访问根结点;
②先序遍历其左子树; ---递归地遍历左子树
③先序遍历其右子树。 ---递归地遍历右子树
void PreOrderTraversal(BinTree BT)
{if(BT){printf("%d", BT->Data);PreOrderTraversal(BT->Left);PreOrderTraversal(BT->Right);}
}![]() (左边部分的顺序是:ABDFE,右边是CGHI)
(左边部分的顺序是:ABDFE,右边是CGHI)
先序遍历===> A B D F E C G H I
A (B D F E) (C G H I)
(2) 中序遍历
遍历过程为:
①中序遍历其左子树;
②访问根结点;
③中序遍历其右子树。
void InOrderTraversal(BinTree BT)
{if(BT){InOrderTraversal(BT->Left);printf("%d",BT->Data);InOrderTraversal(BT->Right);}
}![]() (左边部分的顺序:D B E F,右边顺序:G H C I)
(左边部分的顺序:D B E F,右边顺序:G H C I)
中序遍历==> D B E F A G H C I
(D B E F) A (G H C I)
(3)后序遍历
遍历过程为:
①后序遍历其左子树;
②后序遍历其右子树;
③访问根结点。
void PostOrderTraversal(BinTree BT)
{if(BT){PostOrderTraversal(BT->Left);PostOrderTraversal(BT->Right);printf("%d", BT->Data);}
}![]() (根结点左边部分顺序:D E F B 右边部分:H G I C)
(根结点左边部分顺序:D E F B 右边部分:H G I C)
后序遍历==> D E F B H G I C A
(D E F B) (H G I C) A
归纳总结:
![]()
每个结点都会被碰到三次,第一次碰到就输出的叫做先序,第二次碰到输出的叫做中序,第三次碰到输出的叫做后序。
4.5.2 二叉树的非递归遍历
※ 中序遍历非递归遍历算法
![]()
一开始碰到A的时候不能输出,那么遍历完了怎么知道又回到这里来了呢?所以用堆栈。
碰到A,因为是中序,所以A入栈;因为是中序,先遍历左子树,所以B入栈;继续往左,D入栈;再往左没有了,所以就要往回走,往回走就是pop一个元素,也就是D被pop出来被打印。D无右孩子,又往回走,所以pop B,B打印出来;B因为有右孩子,所以碰到了F,此时还不能print F,所以F 入栈;再往左走,碰到E,E入栈;E无左子树,所以堆栈抛出E,E无右子树,所以往回走,抛出F, F无右孩子,所以继续抛出堆栈中的A。
- 遇到一个结点,就把它压栈,并去遍历它的左子树;
- 当左子树遍历结束后,从栈顶弹出这个结点并访问它;
- 然后按其右指针再去中序遍历该结点的右子树。
void InOrderTraversal(BinTree BT)
{BinTree T = BT;Stack S = CreatStack(MaxSize); /*创建并初始化堆栈S*/while( T || !IsEmpty(S) ){while(T) /*一直向左并将沿途结点压入堆栈*/{Push(S,T); //-->第一次碰到该结点T = T->Left;}if (!IsEmpty(S)){T = Pop(S); /*结点弹出堆栈*/ //---->第二次碰到该结点printf("%5d", T->Data); /*访问(打印)结点*/T = T->Right; /*转向右子树*/}}
}※ 先序遍历的非递归遍历算法?
void PreOrderTraversal(BinTree BT)
{BinTree T = BT;Stack S = CreatStack(MaxSize); /*创建并初始化堆栈S*/while( T || !IsEmpty(S) ){while(T) /*一直向左并将沿途结点压入堆栈*/{printf("%5d", T->Data); /*访问(打印)结点*/Push(S,T);T = T->Left;}if (!IsEmpty(S)){T = Pop(S); /*结点弹出堆栈*/T = T->Right; /*转向右子树*/}}
}※ 后序遍历的非递归算法 (自己编写)
void PostOrderTraversal(BinTree BT)
{BinTree T = BT;Stack S = CreatStack(MaxSize);BinTree PrePop; //记录上次出栈的结点while( T || !isEmpty(S)) /*若树的结点未访问完或堆栈不空*/{while(T) /*先遍历左子树*/{Push(S,T); T = T->Left;}T = Pop(S); /*while结束,说明左子树已经遍历完毕,就要往回走,就弹出栈顶结点*//*栈顶结点是否能输出,取决于该结点是否有右孩子,如果没有,就可以直接输出*///此处分两种情况:1是该结点右结点为空;2是该结点的右结点上次已经访问(输出)过,即是下面的返回结束往回走了 if( !T->Right || T->Right == PrePop) {printf("%5d", T->Data);PrePop = T;T = NULL; //将结点置为空,以便可以继续从堆栈中弹出结点} else /*如果有右孩子且该右孩子未被访问过,则该结点重新入栈,并转向右子树*/{T = Push(S,T); T = T->Right; /*转向右子树*/}}
}4.5.3 层序遍历
二叉树遍历的核心问题:二维结构的线性化
- 从结点访问其左、右儿子结点
- 访问左儿子后,右儿子结点怎么办?
- 需要一个存储结构保存暂时不访问的结点
- 存储结构:堆栈(保存自己)、队列(保存右孩子)
※队列实现:遍历从根结点开始,首先将根结点入队,然后开始执行循环:结点出队、访问该结点、其左右儿子入队
视频描述:层序遍历二叉树的过程
步骤如下:
1、初始状态
![]()
2、从根结点开始,把A放到队列中
![]()
3、接下来开始做循环:队列中抛出一个元素(A),把左右儿子放进去(B C)---遍历的结果就为A了
![]()
4、又从队列中抛出第一个元素B,输出B,然后把B的左右儿子(D F)放入队列
![]()
5、再从中抛出元素C,将其左右儿子(G I)放入队列
![]()
6、抛出D,D没有左右儿子就没有元素要放到队列中
![]()
7、进一步循环,抛出F,将F的左儿子E放入队列
![]()
8、.....
层序遍历=> A B C D F G I E H
访问顺序:
![]()
层序基本过程:先根结点入队,然后:
①从队列中取出一个元素;
②访问该元素所指结点;
③若该元素所指结点的左、右孩子结点非空,则将其左、右孩子的指针顺序入队。
void LevelOrderTraversal(BinTree BT)
{Queue Q;BinTree T;if (!BT) return; /*若是空树,则直接返回*/Q = CreatQueue(MaxSize); /*创建并初始化队列Q*/AddQ(Q, BT); //根结点放入队列中while(!IsEmpty(Q)){T = DeleteQ(Q);printf("%d\n",T->Data); /*访问取出队列的结点*/if(T->Left) AddQ(Q, T->Left);if(T->Right) AddQ(Q, T->Right);}
}【例】遍历二叉树的应用:输出二叉树中的叶子结点
- 在二叉树的遍历算法中增加检测结点的“左右子树是否都为空”。
void PreOrderPrintLeaf(BinTree BT)
{if (BT){if(!BT->Left && !BT->Right)printf("%d", BT->Data);PreOrderPrintLeaf(BT->Left);PreOrderPrintLeaf(BT->Right);}
}中序遍历和后序遍历也类似,在printf前加入判断语句即可。
【例】求二叉树的高度。
![]()
(利用后序遍历来实现)
int PostOrderGetHeight(BinTree BT)
{int HL, HR, MaxH;if(BT){HL = PostOrderGetHeight(BT->Left); /*求左子树的深度*/HR = PostOrderGetHeight(BT->Right); /*求右子树的深度*/MaxH = (HL > HR)? HL : HR; /*取左右子树较大的深度*/return (MaxH + 1); /*返回树的深度*/}else return 0;
}【例】二元运算表达式树及其遍历
![]()
叶结点代表运算数,非叶结点是运算符号。
※三种遍历可以得到三种不同的访问结果:
- 先序遍历得到前缀表达式:++a*bc*+*defg
- 中序遍历得到中缀表达式:a+b*c+d*e+f*g ----->!!!!中缀表达式会受到运算符优先级的影响!!!!如果给定一个表达式树,要求输出正确的中缀表达示,可通过加括号的方式解决该问题(输出左子树的时候加左括号,左子树输出完毕加右括号)
- 后序遍历得到后序表达式:abc*+de*f+g*+
【例】由两种遍历序列确定二叉树
已知三种遍历中的任意两种遍历序列,能够唯一确定一个二叉树呢?
答案是:必须要有中序遍历才行!
没有中序的困扰:
- 先序遍历序列:A B
- 后序遍历序列:B A
这样确定的二叉树不是唯一的。比如:![]()
![]() 两棵树都是满足条件的。
两棵树都是满足条件的。
因为先序是:根、左、右;后序是:左、右、根。难区分左和右分别是哪些,左、右的边界在哪里也不知道。
※ 先序和中序遍历序列来确定一棵二叉树
【分析】
- 根据先序遍历序列第一个结点确定根结点;
- 根据根结点在中序遍历序列分割出两个子序列
- 对左子树和右子树分别递归使用相同的方法继续分解。
![]()
中序遍历序列中根据根结点就找到左子树的结点个数,在先序序列中就可以从根结点往后数,得到左子树的边界。再根据先序序列中左子树的第一个结点,得到左子树的根结点,在中序序列中就得到了左子树的根结点,从而可以得到左子树的左子树和右子树。依此类推。
【例】先序序列:a b c d e f g h i j
中序序列: c b e d a h g i j f
==>根据先序序列可知,a是整棵树的根,然后到中序序列中找到a,所以可以知道左子树为cbde,到先序序列中从根结点往后数4个,可以知道是bcde。所以知道了左子树的先序序列和中序序列。同理右子树也相同。
![]()
※ 类似地,后序和中序遍历序列也可以确定一棵二叉树。
5. 小白专场:树的同构
5.1 题目
03-树1 树的同构 (25 分)
给定两棵树T1和T2。如果T1可以通过若干次左右孩子互换就变成T2,则我们称两棵树是“同构”的。例如图1给出的两棵树就是同构的,因为我们把其中一棵树的结点A、B、G的左右孩子互换后,就得到另外一棵树。而图2就不是同构的。
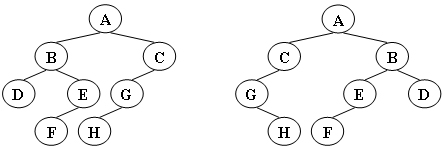
图1
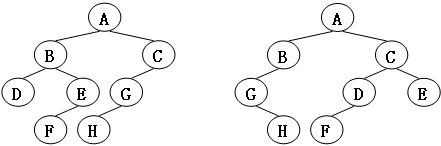
图2
现给定两棵树,请你判断它们是否是同构的。
输入格式:
输入给出2棵二叉树树的信息。对于每棵树,首先在一行中给出一个非负整数N (≤10),即该树的结点数(此时假设结点从0到N−1编号);随后N行,第i行对应编号第i个结点,给出该结点中存储的1个英文大写字母、其左孩子结点的编号、右孩子结点的编号。如果孩子结点为空,则在相应位置上给出“-”。给出的数据间用一个空格分隔。注意:题目保证每个结点中存储的字母是不同的。
输出格式:
如果两棵树是同构的,输出“Yes”,否则输出“No”。
输入样例1(对应图1):
8
A 1 2
B 3 4
C 5 -
D - -
E 6 -
G 7 -
F - -
H - -
8
G - 4
B 7 6
F - -
A 5 1
H - -
C 0 -
D - -
E 2 -
输出样例1:
Yes
输入样例2(对应图2):
8
B 5 7
F - -
A 0 3
C 6 -
H - -
D - -
G 4 -
E 1 -
8
D 6 -
B 5 -
E - -
H - -
C 0 2
G - 3
F - -
A 1 4
输出样例2:
No
限制:
时间限制: 400 ms
内存限制: 64 MB
代码长度限制: 16 KB
5.2 题意理解
给定两棵树T1和T2。如果T1可以通过若干次左右孩子互换就变成T2,那我们称两棵树是“同构”的。现给定两棵树,请你判断它们是否是同构的。
输入格式:输入给出2棵二叉树的信息:
- 先在一行中给出该树的结点数,随后N行
- 第i行对应编号第i个结点,给出该结点中存储的字母、其左孩子结点的编号、右孩子结点的编号。
- 如果孩子结点为空,则在相应位置上给出“-”。
###输入样例:
8 (第一棵树)
A 1 2
B 3 4
C 5 -
D - -
E 6 -
G 7 -
F - -
H - -
=======>输入数据每一行对应一个结点,编号依次是:![]() 对应的二叉树为:
对应的二叉树为:![]()
8 (第二棵树)
G - 4
B 7 6
F - -
A 5 1
H - -
C 0 -
D - -
E 2 -
=======>同理,输入数据每一行的编号依次:![]() ,对应的二叉树为:
,对应的二叉树为:![]()
可见,不要求根结点作为第一个结点输入。
5.3 求解思路
- 二叉树表示
- 建二叉树
- 通过判别
5.3.1 二叉树表示
(1)最常见的表示方法(链表):
![]()
(2)用数组表示(补全成完全二叉树):
![]()
(3)用结构数组表示二叉树:静态链表 (物理上的存储是数组,思想上是链表的思想)
![]()
每一列是数组的一个分量,包含了三个信息:结点本身的信息保存的字母,Left和Right指向左右儿子的位置的下标。用-1表示指向空的结点。
数据结构定义:
#define MaxTree 10
#define ElementType char
#define Tree int
#define Null -1 //为了区分关键字NULL(0),自定义的代表的是-1struct TreeNode
{ElementType Element;Tree Left;Tree Right;
}T1[MaxTree], T2[MaxTree];Left和Right是下标,不是指针,所以没有左右孩子时,Left和Right都为-1,而不是NULL。
数组中ABCD的顺序不一定,可以随意变换。如上面的那棵树,还可以表示成:
![]()
同样一棵树在结构数组中的静态链表表示方法不唯一,这就是灵活性。
如何通过静态链表确定根结点呢?
上面的四个结点分别放在0、1、3、4下标对应的位置上,哪些在结构体数组中出现,哪个没出现。B的左右孩子时4和3下标对应的结点,A的右孩子是0对应的结点,也就是0、3和4被用到了,只有1没有被用到。所以1对应的结点就是根结点。
5.3.2 程序框架搭建
![]()
![]()
int main()
{Tree R1,R2;R1 = BuildTree(T1); //T1和T2是此前定义的结构数组,全局变量R2 = BuildTree(T2);if(Isomorphic(R1,R2))printf("Yes\n");else printf("No\n");return 0;
}
5.3.3 如何建二叉树
按照题目意思以及输入样例:
8
A 1 2
B 3 4
C 5 -
D - -
E 6 -
G 7 -
F - -
H - -先输入结点的个数,然后依次输入结点存储的字母,结点的左右孩子结点的编号,所以代码如下:
Tree BuildTree(struct TreeNode T[])
{...scanf("%d\n", &N); //输入结点的个数if(N){......for(i = 0; i < N; i++){scanf("%c %c %c\n", &T[i].Element, &cl, &cr); //将左右孩子编号以字符形式输入,之后再处理成整型......}......Root = ??? //如何确定根结点是哪个?T[i]中没有任何结点的left(cl)和right(cr)指向它。只有一个。}return Root;
}BuildTree函数的目的是创建一棵树,返回树的根结点。那么这个根结点是什么呢?可以按照之前说的,扫描一遍这个结构数组,看哪个下标对应的结点没有任何结点指向它。
Tree BuildTree(struct TreeNode T[])
{...scanf("%d\n", &N); //输入结点的个数if(N){for(i = 0; i < N; i++) check[i] = 0; //数组check对应于n个结点for(i = 0; i < N; i++){scanf("%c %c %c\n", &T[i].Element, &cl, &cr); //将左右孩子编号以字符形式输入,之后再处理成整型if(cl != "-") //左儿子不为空{T[i].Left = cl-'0';check[T[i].Left] = 1; //如果某个结点的left指向了某个位置,就将该位置的check设置为1.}elseT[i].Left = Null;if(cr != '-') //右儿子对应的编号{T[i].Right = cr-'0';check[T[i].Right] = 1;}elseT[i].Right = Null;}//循环结束后,check数组中对应的值还是为0的就是根结点for(i = 0; i < N; i++)if(!check[i]) break; Root = i }return Root;
}5.3.4 如何判别两二叉树同构
int Isomorphic(Tree R1, Tree R2)
{if(R1 == Null) && (R2 == Null) //两棵树都是空的return 1;if((R1 == Null) && (R2 != Null)) || ((R1 != Null) && (R2 == Null))) //其中一棵树为空,另一棵树不为空return 0; if(T1[R1].Element != T2[R2].Element) //根结点不同return 0; if((T1[R1].Left == Null) && (T2[R2].Left == Null)) //都没有左孩子return Isomorphic(T1[R1].Left, T2[R2].Left);if(((T1[R1].Left != Null) && (T2[R2].Left != Null)) && (T1[T1[R1].Left].Element == T2[T2[R2].Left].Element)) //如果左孩子同时不为空,且Element都相同return (Isomorphic(T1[R1].Left, T2[R2].Left) && Isomorphic(T1[R1].Right, T2[R2].Right)); //判断左边同构,右边是否同构else //这个else包含的情况://1、两棵根结点的左子树的Element不同,则判断左边和右边同构,右边和左边同构。//2、一棵树的左子树为空,另一棵树的右子树为空,也要这样判断return (Isomorphic(T1[R1].Left, T2[R2].Right) && Isomorphic(T1[R1].Right, T2[R2].Left));
}5.3.5 完整代码
#include <stdio.h>
#include <stdlib.h>#define MaxTree 10
#define ElementType char
#define Tree intstruct TreeNode
{ElementType element;Tree left;Tree right;
}T1[MaxTree], T2[MaxTree];Tree buildTree(struct TreeNode T[]);
int isomorphic(Tree t1, Tree t2);int main()
{Tree r1,r2;r1 = buildTree(T1);r2 = buildTree(T2);if (isomorphic(r1, r2))printf("Yes\n");elseprintf("No\n");return 0;
}Tree buildTree(struct TreeNode T[])
{int n;scanf("%d\n", &n);Tree root = -1;if(n) {Tree check[MaxTree];int i;char cl,cr;for(i = 0; i < n; i++)check[i] = 0;for(i = 0; i < n; i++) {scanf("%c %c %c\n", &T[i].element, &cl, &cr);if(cl != '-') {T[i].left = cl - '0';check[T[i].left] = 1;} else {T[i].left = -1;}if(cr != '-') {T[i].right = cr - '0';check[T[i].right] = 1;} else {T[i].right = -1;}}for (i = 0; i < n; i++){if(!check[i])break;}root = i;}return root;
}int isomorphic(Tree r1, Tree r2)
{if(r1 == -1 && r2 == -1)return 1;if((r1 == -1 && r2 != -1) || (r1 != -1 && r2 == -1))return 0;if(T1[r1].element != T2[r2].element)return 0;if(T1[r1].left == -1 && T2[r2].left == -1)return isomorphic(T1[r1].right, T2[r2].right);if((T1[r1].left != -1) && (T2[r2].left != -1)&& T1[T1[r1].left].element == T2[T2[r2].left].element)return isomorphic(T1[r1].left, T2[r2].left) && isomorphic(T1[r1].right, T2[r2].right);elsereturn isomorphic(T1[r1].left, T2[r2].right) && isomorphic(T1[r1].right, T2[r2].left);}
ctrl+z 结束输入。
运行结果:
![]()
MOOC 数据结构 | 3. 树(上)相关推荐
- MOOC 数据结构 | 4. 树(中)
1. 什么是二叉搜索树 查找问题: 静态查找与动态查找 针对动态查找,数据如何组织? 二叉搜索树:一棵二叉树,可以为空:如果不为空,满足以下性质: 非空左子树的所有键值小于其根结点的键值. 非空右子树 ...
- 浙大2020年Mooc数据结构笔记--第三讲 树(下)
浙大2020年Mooc数据结构笔记–第三讲 树(下) 〇.前言 这几天开始跟着学数据结构,鉴于当初数据结构实在学的太弱,加之这项工作算是为大家之后复习.机试铺路.确实是一个迫切需要做的大规模工作.行胜 ...
- 【图解数据结构】树和二叉树全面总结(上)
目录 一.前言 二.树的概念和定义 三.二叉树 1.基本概念 2.基本形态 3.性质 4.满二叉树 5.完全二叉树 四.存储结构 1.顺序存储 2.二叉链表 3.三叉链表 一.前言 学习目标:理解树和 ...
- 数据结构显示树的所有结点_您需要了解的有关树数据结构的所有信息
数据结构显示树的所有结点 When you first learn to code, it's common to learn arrays as the "main data struct ...
- 数据结构-王道-树和二叉树
[top] 树和二叉树 树:是\(N(N\geq0)\)个结点的有限集合,\(N=0\)时,称为空树,这是一种特殊情况.在任意一棵非空树中应满足: 有且仅有一个特定的称为根的结点. 当\(N>1 ...
- (八)数据结构之“树”
数据结构之"树" 树是什么? 什么是深度/广度优先遍历? 深度优先遍历算法口诀 广度优先遍历算法口诀 二叉树的先中后序遍历 二叉树是什么 先序遍历算法口诀(根 > 左 > ...
- 数据结构之树:树的介绍——9
数据结构之树,介绍篇 树的基本定义 介绍:树(tree)是计算机中非常重要的数据结构,它的外形看起来像一颗倒挂着的的树,使用树这种结构可以描述生活中很多的事物,如族谱,单位的组织架构,xml,html ...
- 【数据结构】 树与二叉树的基本概念、结构特点及性质
前言:本章内容主要是数据结构中树与二叉树的基本概念.结构特点及性质的引入. 文章目录 树的概念 树的特点: 树的常用术语: 树的表示: 代码创建: 树在实际中的应用: 二叉树的概念 特殊的二叉树 满二 ...
- 【技术点】数据结构--B树系列之B+树(五)
文章目录 前言 B+树的结构 Key & Data 叶子节点保存数据:减少I/O的设计 中间节点的索引作用 链表的作用:范围查询 B+树的操作 插入 删除 B+树总结 B*树 总结 前言 前面 ...
最新文章
- eselasticsearch入门_ElasticSearch入门学习-基础示例(1)
- 参数无效_Shell 脚本启动如何传递参数
- JDK的安装与环境变量配置
- Web安全实战训练营
- 编程方法学4:计算机科学发展简史
- ORACLE TEXT LEXER PREFERENCE(三)
- PythonGIS可视化—Matplot basemap工具箱
- php workman 多线程,workerman如何多线程
- java定时任务什么时间e结束_Java定时任务
- js实战代码系列—带你玩jQuery带你飞
- 骁龙865确定:年底发布 支持5G!
- 防止按钮连续重复点击
- .NET笔试题(关于迭代的:遍历XML中的FileName)
- 全面了解CCD摄像机
- A.7链表练习题——集合的交差并
- 9.高性能计算 期末复习
- Uniapp 应用消息通知插件 Ba-Notify
- Kafka从入门到精通学习笔记
- 魔点人脸识别闸机系统落地郑州中心客运站
- 网络安全 期末复习 (山东农业大学)