机器学习管道模型_使用连续机器学习来运行您的ml管道
机器学习管道模型

使用连续机器学习来运行ML管道 (Using Continuous Machine Learning to Run Your ML Pipeline)
CI/CD is a key concept that is becoming increasingly popular and widely adopted in the software industry nowadays. Incorporating continuous integration and deployment for a software project that doesn’t contain a machine learning component is fairly straightforward because the stages of the pipeline are somewhat standard, and it is unlikely that the CI/CD pipeline will change a lot over the course of development. But, when the project involves a machine learning component, this may not be true. As opposed to traditional software development, building a pipeline for a machine learning components may involve a lot of changes over time, mostly in response to observations made during past iterations of development. Therefore, for ML projects, notebooks are widely used to get started with the project, and once a stable foundation (base code for different stages of the ML pipeline) is available to build upon, the code is pushed to a version control system, and the pipeline is migrated to a CI/CD tool such as Jenkins or TravisCI.
CI / CD是一个关键概念,在当今的软件行业中正变得越来越流行和广泛采用。 对于不包含机器学习组件的软件项目,将持续集成和部署整合起来非常简单,因为管道的各个阶段都是标准的,并且CI / CD管道在整个开发过程中不太可能发生很大变化。 但是,当项目涉及机器学习组件时,情况可能并非如此。 与传统的软件开发相反,为机器学习组件建立管道可能会随着时间的流逝而发生很多变化,这主要是响应于在过去的开发迭代中所做的观察。 因此,对于ML项目,笔记本被广泛用于该项目的入门,并且一旦可以建立稳定的基础(用于ML管道的不同阶段的基础代码),该代码就会被推送到版本控制系统中,并且管道将迁移到CI / CD工具,例如Jenkins或TravisCI。
There are two major concerns/problems that I focussed on for this blog:
我在此博客中重点关注两个主要问题/问题:
- For machine learning projects, developers should be able to quickly make changes to their pipeline without affecting other people who are working on the same project. External tools such as Jenkins might be difficult to configure such levels of flexibility and independence.对于机器学习项目,开发人员应该能够快速更改其管道,而不会影响从事同一项目的其他人。 诸如Jenkins之类的外部工具可能难以配置这种级别的灵活性和独立性。
- Another concern that arises in machine learning projects is tracking what logic, dataset, and pipeline were used to get a certain model/performance. If, after performing an experiment, the developer makes an observation that the performance has degraded, they should be able to quickly go back to the previous setup. This problem is even more pronounced when multiple developers/teams make changes to the same branch of code. Tracking who made changes to which part of the code/pipeline/dataset becomes very important in this case.机器学习项目中出现的另一个问题是跟踪使用什么逻辑,数据集和管道来获得特定的模型/性能。 如果在执行实验后,开发人员发现性能有所下降,则他们应该能够快速返回到先前的设置。 当多个开发人员/团队对同一代码分支进行更改时,此问题甚至更加明显。 在这种情况下,跟踪谁对代码/管道/数据集的哪个部分进行了更改非常重要。
Continuous Machine Learning [CML] addresses the above two concerns. As indicated in their website (https://cml.dev/), “CML helps bring your favorite DevOps tools to machine learning”. CML is built as a plugin to Git Actions (which is a CI/CD tool, similar to Jenkins or TravisCI). The CI/CD pipeline is specified as a YAML file, and is committed along with the code to the version control system (GitHub). Configuring a pipeline using CML is very simple. Here is the documentation of CML which explains the process of setting up a pipeline quite well.
连续机器学习[CML]解决了以上两个问题。 如其网站( https://cml.dev/ )所示,“ CML帮助将您喜欢的DevOps工具引入机器学习”。 CML是作为Git Actions(这是一种CI / CD工具,类似于Jenkins或TravisCI)的插件而构建的。 CI / CD管道被指定为YAML文件,并与代码一起提交到版本控制系统(GitHub)。 使用CML配置管道非常简单。 这是CML的文档,它很好地解释了建立管道的过程。
Let me demonstrate the working of a simple pipeline that I set up for running the following stages of an ML pipeline, which in the end produces three models that predict the popularity of movie based on past data (movie attributes and popularity data). The models are built using scikit-learn, and the dataset is prepared by gathering data from three sources: Kafka stream data from a sample movie streaming service, a Kaggle IMDb movie dataset and an API that provides movie attribute information. The goal of this demonstration is to be able to run the stages of an ML pipeline using CML and observe the outcome of an execution of the pipeline without leaving the version control system on making a code commit.
让我演示一个简单的管道的工作原理,该管道是为运行ML管道的以下阶段而设置的,最后,该管道产生了三个模型,这些模型根据过去的数据(电影属性和受欢迎程度数据)来预测电影的受欢迎程度。 这些模型是使用scikit-learn构建的,数据集是通过收集来自以下三个来源的数据来准备的:来自示例电影流服务的Kafka流数据,Kaggle IMDb电影数据集和提供电影属性信息的API。 该演示的目标是能够使用CML运行ML管道的各个阶段,并观察管道执行的结果,而无需在提交代码提交时离开版本控制系统。
The Python script that I’m going to run as a pipeline was downloaded from a Google Colab notebook, and so, for now, it is a monolithic script comprising around 8 steps of an ML pipeline together namely:
我要作为管道运行的Python脚本是从Google Colab笔记本下载的,因此,到目前为止,它是一个整体脚本,包括ML管道的大约8个步骤,即:
- Data collection数据采集
- Data preprocessing数据预处理
- Feature extraction特征提取
- Data cleaning and encoding数据清理和编码
- Normalization正常化
- Splitting the dataset into train and test将数据集拆分为训练和测试
- Training and evaluating accuracy using baseline models使用基线模型训练和评估准确性
- Training and evaluating accuracy using three models使用三种模型训练和评估准确性
The data from the Kafka stream has one entry per instance of a user watching a movie on the streaming platform.
对于流式传输平台上观看电影的用户实例,Kafka流中的数据只有一个条目。

After obtaining data from the other two sources, the final processed, cleaned, encoded and normalized dataset with a usable set of features looks like this:
从其他两个来源获取数据后,具有一组可用功能的最终处理,清理,编码和规范化数据集如下所示:

This dataset is split in an 80–20 manner into training and test datasets. Using this split, models are built using three algorithms (linear regression, decision tree, random forest), and they are evaluated offline to calculate the mean absolute error. At the end of this demonstration, I want to observe these metrics and the distribution of the errors after every code commit.
该数据集以80–20的方式分为训练和测试数据集。 使用此拆分,使用三种算法(线性回归,决策树,随机森林)构建模型,并对其进行脱机评估以计算平均绝对误差。 在本演示的最后,我想观察这些指标以及每次提交代码后错误的分布。
Now, let’s move on to our demonstration. To make GitHub Actions recognize that there is a pipeline to run, create a YAML file in “.github/workflows”. Whenever you make a commit that has a workflow, GitHub Actions will automatically take that workflow and run it. The YAML file below tells GitHub Actions to run the job for every commit. CML provides a docker image with Python3 and the CML library. So, our job has to be run within this docker container so that we have access to CML’s capabilities. The run block of the job has the sequence of steps that we want our pipeline to execute. For this example, a single script is being run, but if this monolithic script is broken down into smaller ones where a step of the pipeline executes using the output of the previous one, you can expect a series of scripts run one by one (Example: data collection, data preprocessing/cleaning, feature extraction, model building, model serialization, etc). At the end of the YAML file, there are couple of CML commands that help transfer the outputs of the script back to GitHub Actions.
现在,让我们继续进行演示。 为了使GitHub Actions知道有运行的管道,请在“ .github / workflows”中创建一个YAML文件。 每当您提交具有工作流程的提交时,GitHub Actions都会自动采用该工作流程并运行它。 下面的YAML文件告诉GitHub Actions为每次提交运行作业。 CML提供了带有Python3和CML库的docker映像。 因此,我们的工作必须在此docker容器中运行,以便我们可以访问CML的功能。 作业的运行块具有我们希望管道执行的步骤序列。 在此示例中,正在运行一个脚本,但是如果将此整体脚本分解为较小的脚本,在该脚本中使用上一个脚本的输出执行流水线的一步,则可以预期一系列脚本逐个运行(示例:数据收集,数据预处理/清理,特征提取,模型构建,模型序列化等)。 在YAML文件的末尾,有几个CML命令可帮助将脚本的输出传输回GitHub Actions。

The following is a code snippet from the python script executed in the job above. This portion is responsible for consolidating the offline evaluation metrics of three baseline models, a linear regression model, a decision tree model and a random forest model.
以下是在以上作业中执行的python脚本的代码段。 这部分负责合并三个基线模型,线性回归模型,决策树模型和随机森林模型的离线评估指标。

Once the above code changes are made, and the code is committed to the repository, GitHub Actions starts a run of the workflow by detecting our YAML configuration.
完成上述代码更改并将代码提交到存储库后,GitHub Actions会通过检测我们的YAML配置来启动工作流程的运行。

Once you click on a workflow run, you will be able to see some steps that are run by default to setup CML, start a docker container to run the pipeline and checkout the latest code. Then, the task that we configured in our pipeline is run. Finally, after completing our task, the docker container is stopped and the resources are cleaned up.
单击工作流程运行后,您将可以查看默认情况下运行的某些步骤来设置CML,启动docker容器以运行管道并签出最新代码。 然后,运行我们在管道中配置的任务。 最后,在完成我们的任务之后,docker容器将停止并清理资源。

Once the job completes, CML in coordination with GitHub Actions posts a comment to the pull request’s conversation tab with the contents that were exported from the CML docker container. These correspond to the CML commands that were configured in the YAML file after the execution of the python script.
作业完成后,CML与GitHub Actions协作,将具有从CML docker容器导出的内容的注释发布到拉取请求的对话选项卡。 这些对应于在执行python脚本后在YAML文件中配置的CML命令。
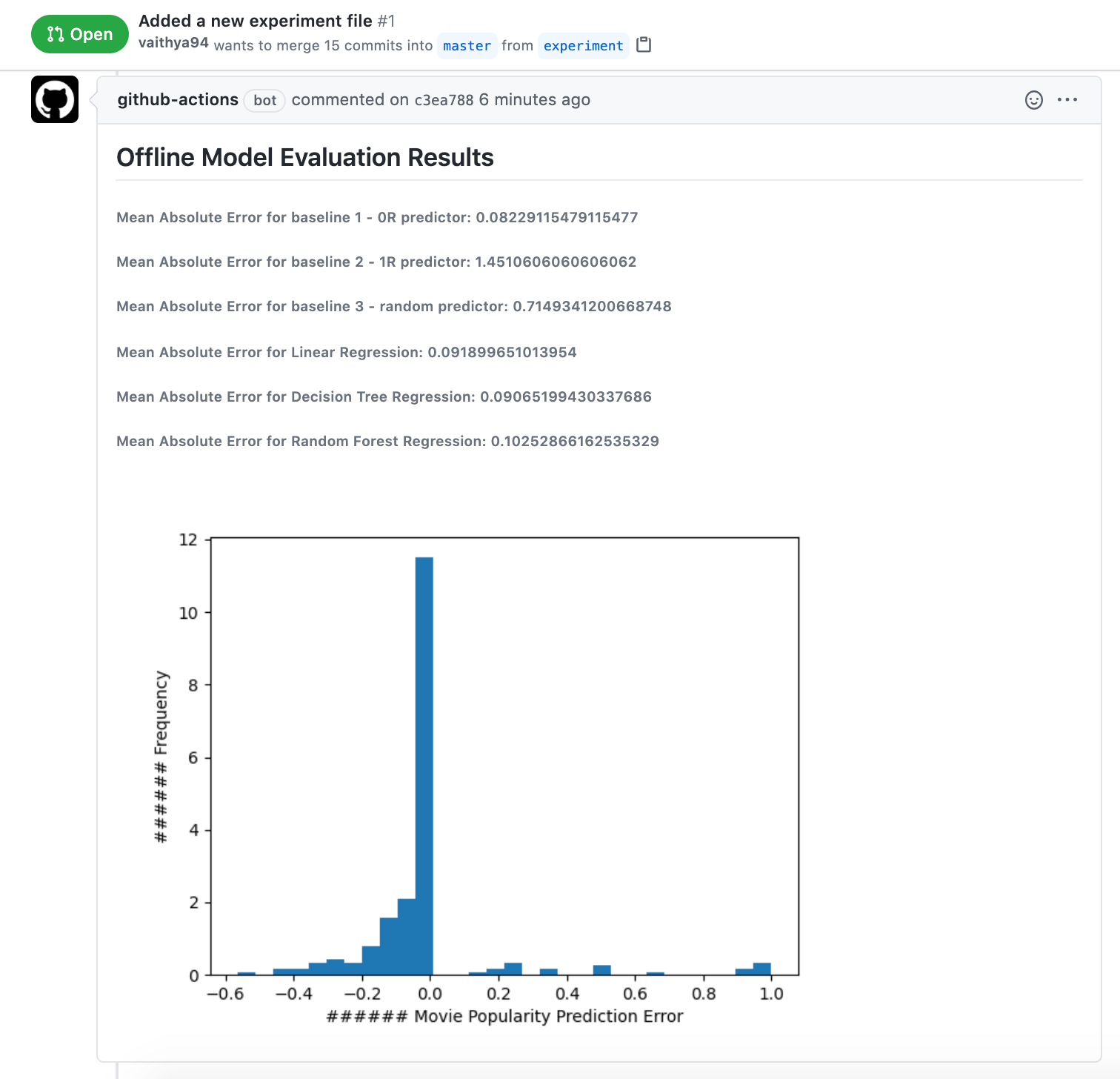
By doing this, for every change made to the dataset / the ML logic / the pipeline, we get a response back in the same place where the change was made (the pull request). If the dataset is not present in the Git repository, CML has the support to retrieve the dataset using DVC (Data Version Control), or retrieve it from an S3 bucket. The pipeline that I used for this demonstration can be easily expanded to deploy a docker container to a virtual machine and serve an API that gives movie popularity predictions given a movie name.
这样,对于数据集/ ML逻辑/管道所做的每一次更改,我们都会在更改发生的同一位置(拉取请求)获得响应。 如果Git存储库中不存在数据集,则CML支持使用DVC(数据版本控制)检索数据集,或从S3存储桶中检索数据集。 我在此演示中使用的管道可以轻松扩展,以将docker容器部署到虚拟机,并提供一个给定电影名称的API,以提供电影流行度预测。
长处 (Strengths)
- Making changes to the pipeline follows the same way as changing code. Therefore, there is no additional effort in trying to configure the pipeline using a separate CI/CD tool. The pipeline resides with the code.对管道进行更改的方式与更改代码相同。 因此,在尝试使用单独的CI / CD工具配置管道时无需付出额外的努力。 管道与代码一起驻留。
- A second benefit of co-locating the pipeline and the code is now your pipeline inherits all the benefits that the version control system provides. Now, we can easily track what changes were made to the pipeline, who made the changes, which version of the dataset is compatible with which version of the code/pipeline, etc.将管道和代码放在同一位置的第二个好处是,管道现在继承了版本控制系统提供的所有好处。 现在,我们可以轻松跟踪对管道进行了哪些更改,进行了哪些更改,数据集的哪个版本与代码/管道的哪个版本兼容等。
- The third benefit is that now we can quickly perform experiments with the code and the pipeline, get back the results without leaving the version control system, and adapt accordingly.第三个好处是现在我们可以使用代码和管道快速进行实验,无需离开版本控制系统即可获取结果并进行相应调整。
- Unlike Jenkins where some level of proficiency is needed with how Jenkins works, what plugins are available, what capabilities are provided to run commands etc, CML has a simple YAML configuration which is more user friendly. You can just copy paste the commands to run the scripts of your pipeline, and you have a pipeline ready.与Jenkins不同,Jenkins需要对Jenkins的工作水平,可用的插件,提供的运行命令的功能有一定水平的了解,CML具有简单的YAML配置,对用户更友好。 您可以复制粘贴命令来运行管道的脚本,然后就可以使用管道了。
- Different developers working on the same project can branch out and modify the pipeline of their branch without blocking others’ progress.在同一个项目上工作的不同开发人员可以分支并修改分支的管道,而不会妨碍其他人的进度。
- We do not need to manage a separate CI/CD server where the builds run (and where the pipeline resides).我们不需要管理运行构建(管道所在)的单独CI / CD服务器。
- It has support to deploy containers to resources provisioned using cloud providers.它支持将容器部署到使用云提供商配置的资源上。
局限性 (Limitations)
- CML is fairly new, and hence there may not be widespread support especially when we think about the availability of plugins. We may have to use commands and scripts to run whatever we want.CML是相当新的,因此可能没有广泛的支持,尤其是当我们考虑插件的可用性时。 我们可能必须使用命令和脚本来运行我们想要的任何东西。
- It is difficult to have a lot of logic in the pipeline. For example, in Jenkins, you can use an “Execute Shell” block and write code with “If” conditions that perform certain actions if some conditions are satisfied. But, with CML, you can only execute commands. It may be difficult to handle errors that may arise from running the commands. Therefore, graceful handling of exceptions is absent.流水线中很难包含很多逻辑。 例如,在Jenkins中,您可以使用“ Execute Shell”块并编写具有“ If”条件的代码,如果满足某些条件,这些条件将执行某些操作。 但是,使用CML,您只能执行命令。 处理因运行命令而引起的错误可能很困难。 因此,缺少对异常的优雅处理。
- CML only supports publishing text files, images, etc. from the pipeline to GitHub. It is an overhead to keep writing intermediate results from the pipeline into a text file so that it can be accessed from the pull request.CML仅支持将文本文件,图像等从管道发布到GitHub。 始终将管道中的中间结果写入文本文件是开销,因此可以从拉取请求中访问它。
翻译自: https://medium.com/@karthik.vaithyanathan/using-continuous-machine-learning-to-run-your-ml-pipeline-eeeeacad69a3
机器学习管道模型
http://www.taodudu.cc/news/show-4735661.html
相关文章:
- Gitlab-Runner原理与实现
- 大数据处理架构演进历程,文末留言有机会获取Flink图书
- Pytorch基本操作(5)——torchvision中的Dataset以及Dataloader
- 【Java学习-J.160331.0.4】笔记3-Linux基础
- dpdk基础教程——流水线模型 ip_pipeline
- Scrapy图片自动下载配置
- Games101 计算机图形学课程笔记: Lecture 08 Shading 2 (Shading, Pipeline and Texture Mapping)
- 《Real-Time Rendering 4th Edition》读书笔记--简单粗糙翻译 第二章 渲染管线 The Graphics Rendering Pipeline
- ValueError: [E030] Sentence boundaries unset. You can add the 'sentencizer' component to the pipelin
- cs python课程 加州大学_cs选uci还是ucsd呢?
- Rails的静态资源管理(三)—— 开发环境的Asset Pipelin
- Jenkins 环境变量的作用范围及设置与获取,包括在Sharedlibraries与pipelin之间的传递
- 时间序列 工具库学习(6) Darts模块-使用DataTransformer和Pipelin进行数据预处理
- 云原生CI/CD:Tekton/pipelin之pipeline概念篇
- Codeforces 1207 C. Gas Pipelin(线性DP)
- NASA Ames Stereo Pipelin(ASP)软件学习过程(一)
- mysql 垃圾_垃圾mysql pipelin
- Jenkins Pipelin扩展
- MATLAB代码:基于Stackelberg博弈的光伏用户群优化定价模型
- 【8】疯壳开源蓝牙智能健康手表(心率血压血氧心电监测可定制)_蓝牙
- 平价款的血糖血压监测工具,用它养成健康生活习惯,dido F50S Pro上手
- 许奔创新社-第26问:专家们创新时为何需要外行来指手画脚?
- Android多媒体之SoundPool+pcm流的音频操作
- note10 android10,「上手」都说它是年度Android机皇,Galaxy Note10到底怎么样?
- JAVA高考加油,给高考学子加油打气的祝福语
- 我的择业思考:在AI最火的时候来到工业界!
- 嵌入式分享合集73
- 手机里舍不的删除的40条搞笑短信(转自Baidu贴吧)
- 初见倾心,土曼第三代智能手表T-Ripple新体验
- 别玩手机了,你没时间了!
机器学习管道模型_使用连续机器学习来运行您的ml管道相关推荐
- 机器学习结构化学习模型_生产化机器学习模型
机器学习结构化学习模型 The biggest issue in the life-cycle of ML project isn't to create a good algorithm or to ...
- 机器学习 建立模型_建立生产的机器学习系统
机器学习 建立模型 When businesses plan to start incorporating machine learning to enhance their solutions, t ...
- 机器学习模型_如何口述机器学习模型原理
点击上方"机器学习与统计学",选择"置顶"公众号 重磅干货,第一时间送达 作者:Ricky翘 zhuanlan.zhihu.com/p/34128571 有时 ...
- python支持向量机模型_【Spark机器学习速成宝典】模型篇08支持向量机【SVM】(Python版)...
目录 什么是支持向量机(SVM) 引例 假定有训练数据集 ,其中,x是向量,y=+1或-1.试学习一个SVM模型. 分析:将线性可分数据集区分开的超平面有无数个,但是SVM要做的是求解一个最优的超平面 ...
- 使用机器学习预测天气_如何使用机器学习预测着陆
使用机器学习预测天气 Based on every NFL play from 2009–2017 根据2009-2017年每场NFL比赛 Ah, yes. The times, they are c ...
- 使用机器学习预测天气_如何使用机器学习根据文章标题预测喜欢和分享
使用机器学习预测天气 by Flavio H. Freitas Flavio H.Freitas着 如何使用机器学习根据文章标题预测喜欢和分享 (How to predict likes and sh ...
- 机器学习 伪标签_伪英语—机器学习打字练习
机器学习 伪标签 Articles in this series:1. Introduction2. Pseudo-English (You are here)3. Keyboard Input (C ...
- 机器学习 多变量回归算法_如何为机器学习监督算法识别正确的自变量?
机器学习 多变量回归算法 There is a very famous acronym GIGO in the field of computer science which I have learn ...
- 机器学习偏差方差_机器学习101 —偏差方差难题
机器学习偏差方差 Determining the performance of our model is one of the most crucial steps in the machine le ...
最新文章
- AI视频行为分析系统项目复盘——技术篇4:deepsort原理图
- 大火的Apache Spark也有诸多不完美
- 人类史上最伟大的 PPT,马斯克的 39 页火星计划PPT
- 反垃圾邮件网关市场分析
- Redis之GEO存储地理位置信息
- php发送https请求,php post 请求https接口
- bugku- web -login3
- java object对象的方法_Java常见对象Object类中的个别方法
- ASP.NET抓取网页内容
- 分享两款迷你FTP服务器
- 1.node.js 概述
- webpack安装_初识webpack
- AI一分钟|亚马逊回应中国代工厂违规事件;特斯拉将开启全自动驾驶功能;小米CDR招股书看点...
- echarts官网demo
- win10 电脑开机底部任务栏无反应(鼠标一直转圈,部分图标不显示)
- 兼容android模拟器的微信apk,Android模拟器中安装apk的方法
- 华为交换机 查ip冲突_怎么查看华为交换机已绑定的ip与mac
- 中国电信无线网服务器,中国电信网上营业厅
- oracle 列转行字符串,oracle 字符串列转行
- 罗克韦尔自动化发布2019年企业责任报告,并启动新的企业责任与可持续发展在线内容中心