机器学习知识点(人工智能篇)
转载请标明出处:
http://blog.csdn.net/djy1992/article/details/75257551
本文出自:【奥特曼超人的博客】
AI(Artificial Intelligence),即人工智能。人工智能领域的研究包括机器人、语音识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。
可观看上篇文章:CSDN观点:人工智能会不会取代开发它的人?
所谓的人工智能,是可以对人的意识、思维的信息过程的模拟。
机器学习简史:拍拍贷AI中心数据研发负责人:王春平
一、机器学习简介
谢谢!首先今天特别荣幸能够到兴业这边来跟大家一起做这样一个简单的分享。之前听兴业的朋友讲,在机器学习这个话题方面我们应该是第一次做相关的分享。所以我会从相对广一点的角度去和大家探讨这个主题,并融入我个人在这个领域里工作和学习的一些体会。后续的“无界”论坛再推出系列专题。如果各位在某一个方面感觉特别有兴趣或者是觉得我这里漏掉了什么东西,会后我们可以进一步交流。
这是今天要讲的整体框架:首先是一个简单的介绍,然后把一些相对经典的模型串到一起,试图从中间找一些共通的地方,接下来介绍机器学习应用过程中一些比较常见的套路,还有就是讲讲我个人对人工智能未来发展趋势的看法。

在简介这块,我其实是想做这样一件事情:把机器学习这样一个名词放到一个相对比较大一点的背景来看,它在用数据来驱动业务、在金融方面的数据挖掘或者选股等等这样一些事情中间,是处于一种什么样的位置?我们所说的用数据来驱动业务,其实这个业务可以是任何东西,比如说今天大家关注的可能是金融业务,我所在的拍拍贷是互联网金融业务。从咱们在前两年就开始兴起的一个很热的概念——大数据,到现在热的一个概念——人工智能,然后到我们真正关注的业务,这三者之间其实有很强烈的关系,也可以说大数据和人工智能先后成为热点也是有一定内在联系的。
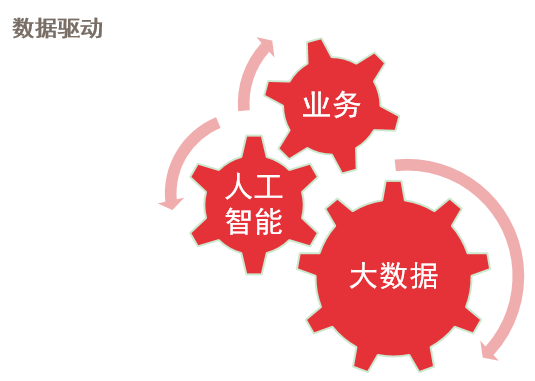
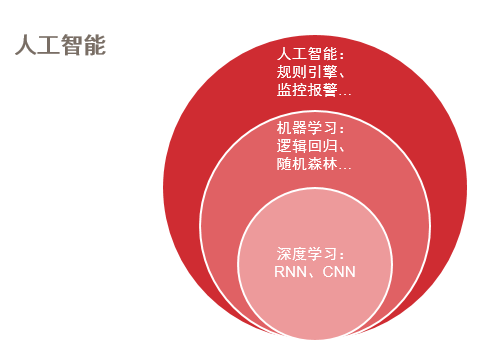
我们认为首先你需要在业务过程中去积累大量的数据,因为当你的数据量足够大,我们才可以用它去做一些事情。现在人工智能其实可以更多的看作是工具类的东西,利用大数据这样一个原料,回归到我们所关注的这个业务问题,解决一些实际的问题。这个人工智能领域呢,它是一个相对比较宽的概念,最近这一两年人工智能再次火爆可能是因为AlphaGo引起了热潮。AlphaGo更多的是和深度学习有关系,但其实人工智能相对来说是一个比较广义的概念,任何可以用机器来代替人做事情我们都可以把它认为是人工智能。它可以包括你写的一些简单的规则引擎,做一些预警和监控等等,也包括今天我们要关注的机器学习这样一个话题。在机器学习里边的一个类别就是现在很热的深度学习。
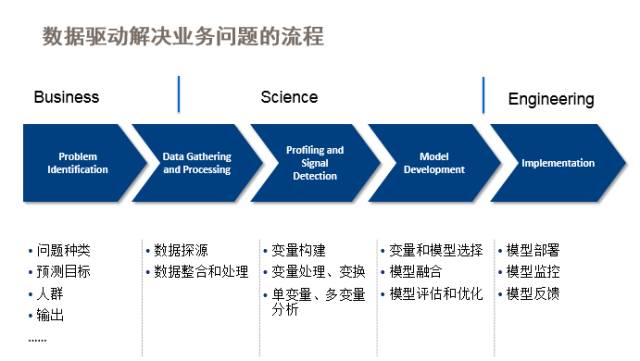
从我个人理解,机器学习跟广义的人工智能的区别在于它是需要从大量的数据里面去学出来一些东西,然后再去运用,而不仅仅是应用一些专家的经验。这是它在整个业务和人工智能中的一个定位,然后我们可以再看一下在整个流程里面它是什么样的状态。当我们想用数据驱动的方式去解决一个业务问题的时候,一般会要走过这样几个大的步骤:首先我们需要关注这个问题本身是什么,比如我现在看一个金融上的问题,我需要去预测一个股票它在明天是涨还是跌,这是一个比较明确的问题。但是很多时候这个问题没有那么清晰明确,所以你可能先要去看这个问题种类。要预测的是什么,关注的人群或者样本集是什么。然后最终希望这个问题带来的输出是什么,等等。这个其实是商业和技术的一个结合,需要两拨人去共同探讨的事情,中间会经过若干个比较偏科研的步骤。你真的需要知道要解决什么问题以后,然后要建模,学出来一些我们可以应用到业务上的一些规律或者模型。最终会涉及到一个比较偏电子工程的事情是要把学出来这些东西真正部署到线上的系统。假如说我这个系统是一个高频交易系统,那我学出来的这个交易的逻辑,我就要把它应用过去。假如说是拍拍贷,我学出来的是一个评价借款人信用状况的模型,那我需要把它应用到整个借款流程,比如说我们APP里面有一个环节里需要做的打分这件事情。
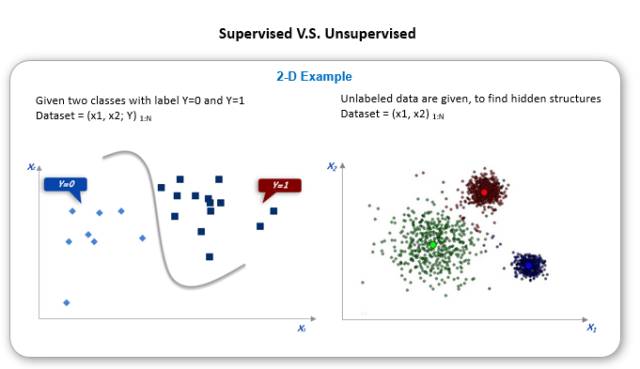
我们今天主要探讨的更多的是科研这一块,也就是和模型的构建比较相关的话题。在整个机器学习概念里面,按照学习的时候有没有老师来教,可以把它分成三个大的类别。一个是就像我在课堂上听讲一样,老师会教我这个是苹果,那个是iPhone,那个是桔子等等,对出现的每个样本都有一个明确的标签,这个叫做监督学习(Supervised Learning)。假如说有一些问题是完全没有老师,要靠自己去探索的,叫非监督式学习(Unsupervised Learning)。然后还有一种在一般做数据分析的时候用的不是很多,但是在比如说机器人或者是AlphaGo里面会涉及的比较多的是增强学习(Reinforcement Learning)。这其实是跟小孩子学东西的过程比较相近,它是一开始没有老师告诉你任何措施,让你在实践中做对的事情得到奖励,做错的事情去得到惩罚。通过环境对它的反馈让它来不断增强自己对环境的认识。
这三类问题之下,我们最常用,大家用起来感觉最得心应手的应该是第一个:监督学习。监督学习的好处是它对一般问题定义是比较清楚的,然后你有一个明确的要预测的一个目标。比如说它是一个分类问题:你要知道这个人是一个未来预期的用户,或者是一个会有良好信用的用户。或者你要知道这些股票明天是会跌或者涨。这些都是有明确的标签,这种叫分类问题(Classification)。如果是有明确的预测目标,但是这个目标是一个连续的数,比如说你想预测的是股票的价格,那它可以是一个回归问题(Regression)。
像后面提及的非监督学习,它之所以叫非监督,一是这个数据本身的理解不是那么清楚,还有就是有些情况下它的标签获取很困难就。就这种问题本身没有那么的明确,所以它是一个非监督的。我可能拿到这个数据以后先做一些分析来看一看它是什么样的,它里头其实是比较包罗万象的,不像监督学习,有比较清晰的一个方向。所以非监督学习可以根据学习的目的分成几类。比如说如果我只是想知道现在的这个人群大概是分成几个群体,但是其实我也不知道应该分成几个群体,不知道什么是对的,这个就是分群(clustering)。分段(segmentation)有点像是切分成几个集合。然后还有一个很重要的也是做降维(dimensional regression),因为现在是一个数据爆炸时代,对于很多人来说,其实数据不是太少而是太多,有可能有成千上万甚至10万级这样的数据维度,特别是在图像数据、自然语音数据这样一些比较复杂的数据类型或者是网络的一些访问日志等等这样的数据,维度相当高。如果让它直接做一些前面的监督的话其实是需要特别含量的数据才有可能去决出一个可以用的模型。所以降维这件事情是机器学习方面的一个蛮大的工作。然后下面这个是文本方面的主题模型(topic modeling):一篇文章你可以把它降低到一些主题或者是一些主题的混合。然后还可以做的事情是:有一堆的照片或者视频,但是我不知道这些照片中会发生什么比较异常的行为,但是我想知道哪些是异常的,如果全部靠人看的话这就太不经济了,所以异常发现(abnormal detection)也是一个很大的一个类别,而且在安保这些方面使用的是比较多。

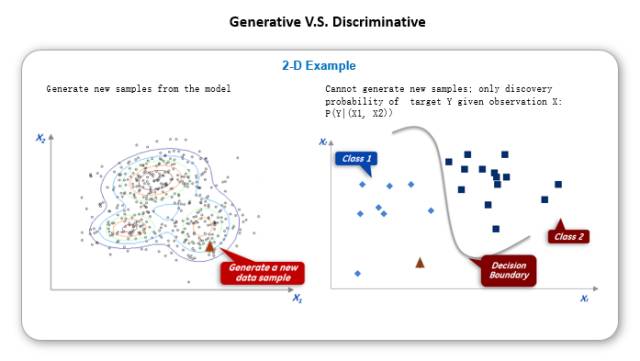
这些具体的方法我们就不会再仔细的讲了,如果有兴趣的话我们可以在以后的分享里面再讨论。稍微回顾一下,简单概括一下刚才的各种纷繁复杂的方法或者分支。首先我们考虑,它是监督学习还是非监督的。下面是一个简单的展示图,左边是表示一个用来测试一个分类的问题,然后右边是我有一堆的数据,但是完全不知道应该分几类,只是稍微去分一下,看一下每一类是不是有相对比较特别一点。这就是监督学习和非监督学习的区别和直观体验。
这里还有一个简单的,和前面有点不一样的分类方式,前面始终在说问题是怎么分类的,这是在定义要解决的问题的时候就已经决定了,而不是我们一定要选择的。但是判别模型(Discriminative model)和生成模型(generative model)这两个分类更多的指选择怎么建模型。这是对于有监督的情况下,可以从这两方面去考虑。当你有一个学习目标的时候,假如说我只想了解一个条件概率的话,也就是给出自变量X,我想知道Y是什么样的情况,这个就是叫判别模型。有些时候我同时也关心X自己的分布情况,所以我们可能关心的是X和Y的联合分布,这时用的是生成模型。一般来说判别模型直接做条件概率效果会比较好,特别是当训练集和预测集比较一致的情况下。但是对一些比较特殊情况,比如说X里面有一些变量缺失,如果你有一个联合分布,对X本身的分布有方法可以学出来的话,就可以生成一个新数据集,做真实值指补充等等,这算一些好处。当然生成模型还有一些别的比较好的特性,如果大家有兴趣的话,我们以后可以展开。现在先预热一下,简单介绍一下机器学习大概的情况。
二、机器学习经典模型
下面我们就来讲一下模型框架以及经典的机器学习模型。
模型框架不是从大家在实际用的时候调用程序包的场景来讲,而是说如果我真的要去理解这个模型的话,我们从什么方面考虑会有利于比较不同模型。所以先来讲机器学习模型会包括什么东西。
首先我们需要对这个模型做一些假设:要把模型假定成一个概率问题呢,还是优化问题呢?即模型假设(Model Assumption)。
当你已经假设好这个模型的条件以后,接下来的工作就是该怎么样去解出来这中间的一些参数或者是这个结果,利用已知的数据去推演必需的东西,这里就会涉及到比较多的大家经常听见的名词,比如说EM算法、贝叶斯推断、Gibbs采样等等,我们称之为模型推演(Model Inference)。
如果已经学出来这个模型,下一步就是模型应用层面(Model Application)。因为我们做所有的机器学习的目的都是为了把它用到新的样本上面去,所以如何把它应用到新的样本集以及在新的样本上的适应能力就是大家特别关注的问题,这里就涉及到这个模型本身是归纳的(inductive)还是传导的(transductive)。归纳是指可以从已知的这些数据里面去推出来一个函数表达式,然后带入相关数据,那就可以算出最新的数据。在选模型或者是做模型的设置的时候,这是一个需要考虑的点,大概会是三大步骤。
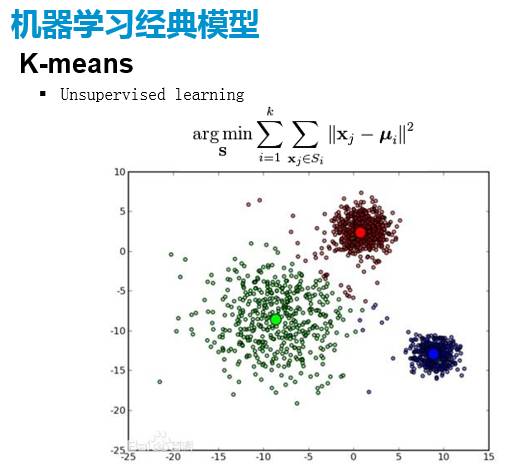
接下来呢我们可以来看一些很简单的算法,但其实也是很经典的。比如说你要做非监督模型,你要做一下聚类,那肯定Kmeans是一个逃不掉东西。它的基本思想很简单,就是说我有一堆数据想要分堆,假设我是要分成三个堆,那我就先随机的设三个点,然后通过迭代来实现每个点到它的中心的距离平方和是最小的,就是相当于找到这三个最有代表性的中心点。它是一个很典型的非监督学习,它没有对数据的分布做任何的假设,没有认为它是某种的分布,或者说,不管是什么样的分布,我都去做这件事情。优化的目标就是要使得它的这三个点是最有代表性的,所以他是把这个问题最终变成了一个做优化求解。当你要有新的数据加进来的时候,也是可以带入距离的公式,去找到哪个点是对于这个点来说最有代表性的一个中心点。
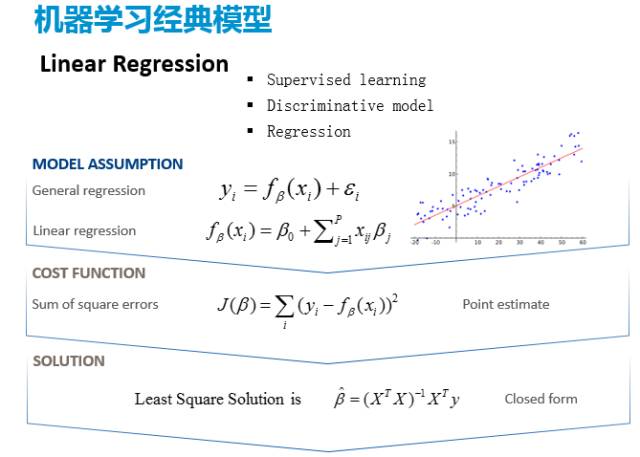
还有一个大家也是很熟悉的,就是线性回归(linear regression)问题,它是监督学习,是有明确的目标的。假如说是一个比较一般的回归的话, Y就是X的一个很一般的函数,f(x)就会变成一个简单的线性加和的关系,这就是我们的模型假设。其实这里头你还可以有不同的假设,比如说我现在是假设它有个函数,是有噪声的,然后我可以进一步假设这个噪声的分布,比如说是高斯,接下来的话我要怎么去解这个问题就是我们刚才讲的第二步,要去做这个模型的迭代升级的工作。一般来说,对线性回归最常见的一个求解的方式就是把它的目标函数写成误差的平方和。这样做的好处是可以得到一个闭式解,可以最终写出来,并不需要用迭代的方式去求。后面当我们讲到一些套路的时候,其实就比如说对于这个线性回归,我也可以通过一些方式在后面在做一些小小的变种,使它具有一些更好的性质。
还有一个比较经典的就是用来做分类的逻辑回归(logistic regression)。它也是一个监督学习方法,这个模型的假设是基于一个概率。所以它跟线性回归其实是不太一样的,输出也是一个概率值,我们在用它的时候也是得到的这个概率。比如说我们这里关心的一个问题是这个借款人他最终会不会按时还款,然后这个模型打分出来的结果就是这个人按时还款的概率值是多少。有了这样的一个模型的函数以后,接下来就是要解决我该怎么样去求解,因为这里存在一个待定系数:β。对于一个概率问题,一般最常用的一个方式是求log后的likelihood,最终其实也是把这样一个概率形式的模型转化成一个优化损失函数(cost function)问题。那其实大家会发现所有的套路基本上都是这样子:假如说你是要做一个点估计,就是说想估计出来这个参数的一个最优的值的话,基本上套路都是会先假定这个函数形式,找到它的损失函数,去把它变成一个优化问题来解。

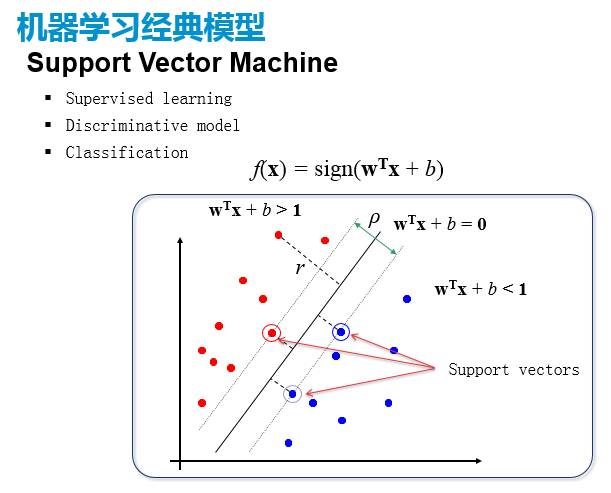
接下来是支持向量机(support Vector Machine),它也是一个分类问题,但是它跟逻辑回归不太一样的是它没有做任何概率上的假设,它本身就上来就是一个优化问题:要在这个平面上面要去找一条线,能够把我这两个类别给它分开,使得它的边缘(margin)最大,边缘就是这个离的最近的这个点到这条线之间的距离。这个是一个完全可以分开成两类的案例,实际中应用过程之中,它可能过拟合。它也是一个优化问题,优化的目标是最大化这个边缘。
神经网络是一个监督学习,可以用来做回归或分类问题。它的思想就是我的一个输入有很多,然后输出只有一个。这是我的自变量X和因变量Y(见图),但是我认为中间有很多的隐藏层,这里是一层,如果它有很多层的话就是现在比较流行的深度学习(deep learning)架构。每一层其实都是下面一层的一个线性表达函数,这样一层一层垒起来最终要去优化的就是因变量Y和实际上我们观察到Y的误差,也是最小化这个误差,就可以把它的损失函数写出来,转化成优化问题。为什么大家都那么喜欢把它转成优化问题?因为如果它是一个凸问题的话,是已经有很好的解决方案的,相信在座的各位可能都知道,就基本上相当于是把前期的比较麻烦的东西转化到套路上面。

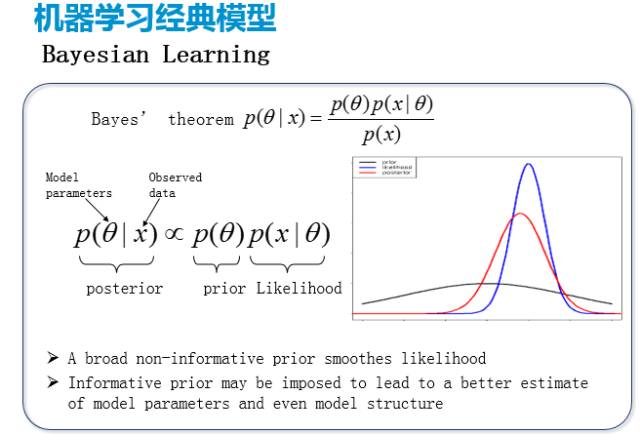
还有一类套路不太一样的模型——贝叶斯思想,前面我们讲的基本上都是点估计。就是我要认为我有一个未知的参数,那我就去估计它的最好值。然后贝叶斯其实是有点不太一样,是我开始有一个想法,比如说现在想估计的是某一个系数,我一开始什么都不知道,它可能是等于0.1,可能等于0.9且中间的概率都差不多。但是当我看见了一些数据以后,我的看法就会越来越集中在某一个值上。当我看了一百万个数据以后基本上就确定它是在我这点上面,但是它其实还是一个很窄的分布。贝叶斯认为没有什么东西是确定的,所有能确定的就是它有一个概率,然后有一个分布,但是你看了更多的数据以后,你对这个东西的认识就会变得越来越清晰。大概是这样一个想法,所以贝叶斯的学习的框架就不再是一个点估计了,它会认为我再怎么学我学出来的使用还是关于这个变量的一个分布,所以它的最终输出都会是一个分布。

三、机器学习的一些常见讨论
接下来给大家简单介绍一下机器学习的一些常见的套路,这些套路对于大多数的模型都是可以用到的,而且是很可能会碰到的一些问题。一个最常见的问题就是过拟合(overfitting)。所谓过拟合是说我过度信任了看见的这些数据,认为看见的数据就是我所有的真实,而且我可能用一个特别复杂的模型去拟合它。当模型足够复杂的时候,数据量如果相对较少,你可以找到一个函数特别好,可以完美地把它组合出来,但是这个对于后面再用新的数据就完全没有用,因为他把噪声给完美的学下来了。
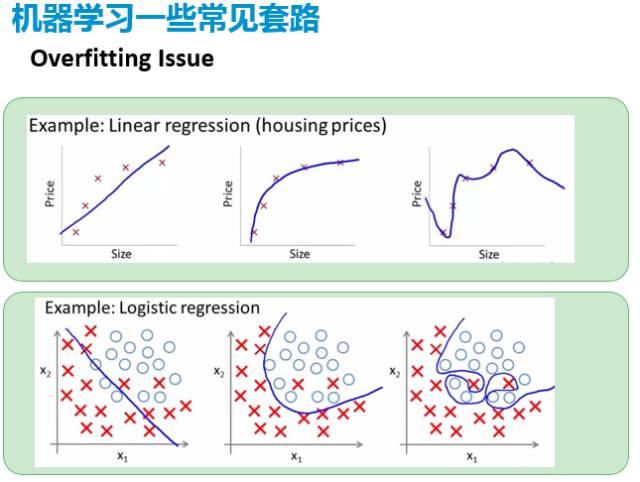
如果这个噪声是一个随机项,也没什么意义,所以对付这个过拟合的话有一个比较常见的套路,就是给他加这个正则约束项。比如说像刚才提到的那个线性回归,假如说我们不加任何调整项的话,它可以直接是一个闭式的解,很简单。但是同时也会出现一个问题,就是有可能系数会特别大。所以一般来说的话,会希望去加一些惩罚项,使得这些系数不会是一些太大的数,因为太大的数有很多问题,它们可能正负抵消。要去“惩罚”它,可以有很多不同的方式,现在比较流行的比如说加一个L1范数或者是在一个L2范数或者是两个结合起来,等等。这些惩罚项的选取是对于有不同特点的数据,或者真正的需求不一样的模型会有所不同。

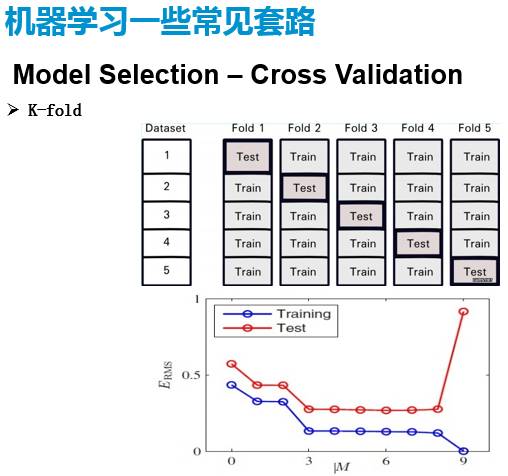
还有一个很常见的方法就是交叉验证(cross validation)。因为我们很多的模型里面都会有一些参数需要选择,其实选参数的时候如果自己手动拍进去不是特别有道理。现在也有一些可能比较好的选参方法,但是绝对可行的,而且比较万能的,就是这个交叉验证。把所有的训练集分成很多组,然后每次把每一个组用来做验证集,其他组做训练集。比如说一共有五个的话就有五个测试集,有五组结果,去不停地调参数。比如说这个案例里面它就是把这个叫做M的变量调来调去的,就会发现在训练集上误差是越来越小,在测试集上误差有可能先小后大。在这个测试集的跳变点附近,一般来说就是比较优化的选择。
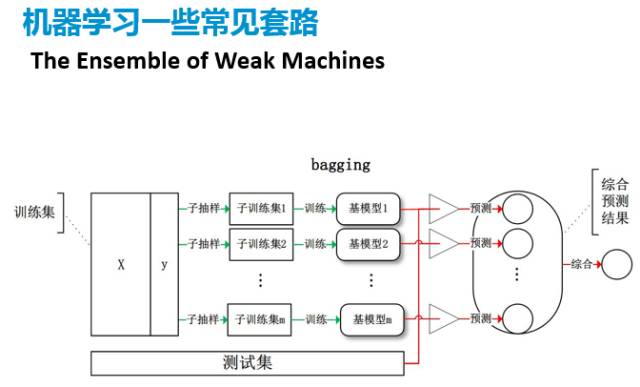
还有一个现在特别热门的方向,这个套路是假如说我有一些弱的分类器或是弱的模型,那我们把它集成(Ensemble)起来去解决一些问题,这里面包括Bagging、Boosting、Stacking等等各种不同的方式,即分类器集成。
我们首先来讲一下Bagging。这个图看起来很复杂,但是简单的来说就是我原来可能只有一千个数据,就很难去检验我这个数据,或者检验这个模型受不同数据的影响会比较大,因为我不是有十万或一百万的数据,不能做各种不同的抽样。假如我只有一千个数据,那我每次都从这1000个数据中分出来不同的数据,来做各个子集。这些数据其实都来自同一个地方,训练出来很多个模型,然后再把它组合起来,简单来说是这样。然后子集的生成都是随机的,没有什么特殊的关照。我们现在比较流行的随机森林(random forest)应该是基于这个思想。
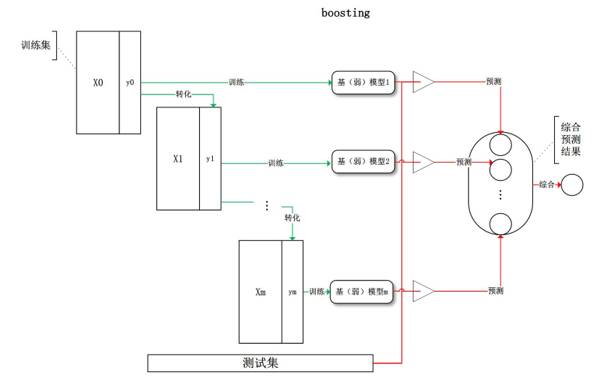
然后还有一个方法是Boosting,Boosting和Bagging主要的区别是,Bagging是随机的分很多类再结合起来,Boosting其实是从每一次都是弱分类器分好以后,原来很不好的结果权重加重,再继续分。它也是做很多很多次,最后也是结合起来。
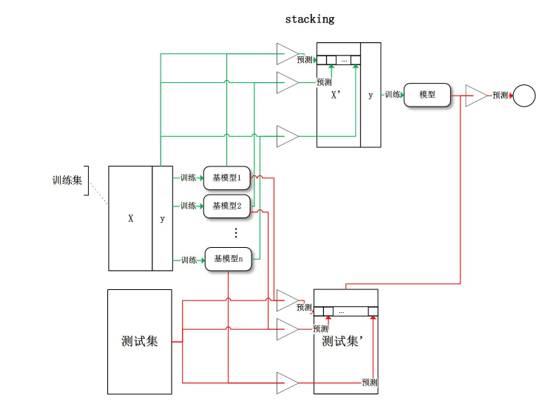
还有一个是Stacking,这个看图的话就更要晕过啦。简单的来讲就是假如有好几个传感器,比如说有的时候做GBBoost,随机森林,等等各种分类器,我都把它用来在训练集上学习,得到一个模型并且预测出来一些结果。然后根据预测出来的结果,我再在上面用对应的方法学出来的模型,相当于是在模型上面套一层模型。这个模型的输入是上面这些模型的输出,就是相当于是看哪个模型应该有更多的权重,而不是直接把每个模型的输出平均起来,可能做的比较好的模型权重相对比较高,所以这个方式一般来说会大大提高表现。特别是当基模型之间的差异度比较大的时候。如果基模型都差不多,那无论怎么样平均结果也都差不多。这是一些简单套路,后期还有更多套路,这几个是比较通用的。
四、机器学习未来发展趋势
最后简单说一下我个人对机器学习发展趋势的理解。其实我在准备PPT的时候在网上搜了一下,发现搜出来的结果可以说是五花八门的。有的人可能是学者型的,他完全讲的就是学术上的趋势。有的可能是属于那种偏社会学的,他讲的趋势可能是更多的对未来社会方方面面的影响。我这边是想作为一个在这个行业里面,自己本身是在做这方面事情的人来谈谈这方面的体验。
其中一个趋势便是通用化越来越强。像以前做机器学习的人,基本上做文本的人专门做文本,做图像的专门做图像,做声音的人专门做声音,做结构化数据的人专门做结构化数据。然后每一种方法对应的数据源本上都是有很特殊的提取,预测的方法。但是现在随着深度学习不断的变热起来,被大家所理解。其实有很多不同数据源,它的算法框架上很接近,就越来越通用化。
还有一个趋势是工具化。越来越多的开源的工具性的产品使得机器学习这件事情的成本大大降低。以前可能都需要写代码,甚至是最开始可能需要自己去推导我刚才讲到的那些模型的假设,根据模型的假设具体做优化。发展到后面可以写一些代码来调包。现在像TPOT这种软件,甚至是可以完全窗口化,拖拖拽拽就可以训练模型,或者是你什么都不干,它自己自动用很多种模型都跑一遍,所有的参数都调一遍。所以整体上来说是有一个用户门槛降低的趋势。
还有一个就是随着机器计算的成本变得越来越低,现在有点往暴力化的方向发展。以前可能更多的是专家的经验建一些变量,调参可能也需要有一些技术。但是未来的话,感觉哪怕对于不太懂的人,假如说他有足够的时间,足够强的机器去算的话,也可以通过暴力的方式,做出一些比较好的模型。这些趋势当然并不是说就不需要一些比较多的人去真正做一些模型的选择,或者是变量的选择。只是很多人群其实可以用到机器学习的很多的工具,去解决很多日常生活中比较基本的问题。

我今天大概就到这里吧,然后如果有对于某一个话题比较感兴趣的来宾的话,我们可以线下再做一些沟通。时间差不多了,谢谢大家!
|| 版权声明:本文为博主杜锦阳原创文章,转载请注明出处。
http://www.taodudu.cc/news/show-3218705.html
相关文章:
- 1.1 机器学习介绍
- 如何判断机器具有智能?
- 神经网络、机器学习和人工智能的基本介绍
- 人工智能的介绍和发展
- AI: 如何快速开发智能机器人 Bot Intelligence
- 人工智能—机器学习常见算法
- 全球及中国智能机器人产业整体运营状况与投资产值分析报告2022版
- unitoy机器人怎么联网_unitoy智能机器人配网
- 妲己机器人需要什么条件才能使用_回顾腾讯智能机器人妲己功能介绍
- 了解一下智能机器人中,用到的三项关键技术
- 智能机器人品牌简介
- 互联网java工程师面试突击第三季知识点总结
- 分布式存储系统——《MySQL海量数据存储与优化》
- MySQL高级系列(四)—— MySQL集群架构
- mysql-分库分表概述
- MySQL分库分表设计
- MySQL分库分表
- MySQL高级笔记
- MySQL集群架构(三):分库分表
- 江苏机考-信息技术基础部分总结
- 问题集
- 去中心化(Dapp)是什么意思?
- MySQL海量数据存储与优化(上)
- 当我们浏览器访问某个网站时,中间经历了什么,如何到达对方的?
- 有没有好奇过,用浏览器访问某个网站时,中间经历了什么,如何到达对方的?(初学版)
- 计算机网络知识串讲复习(超全)
- 作为初学者,物理层与数据链路层要了解哪些
- 网络编程 之 网络协议(一)
- 7层OSI模型学习指南
- 【网络】网络编程
机器学习知识点(人工智能篇)相关推荐
- 人工智能(10)---机器学习知识体系篇(初级篇,中级篇,高级篇)
机器学习知识体系篇(初级篇,中级篇,高级篇) 下面是自己总结一套人工智能机器学习整个知识体系,一起学习,有总结不到位的希望大家给出纠正! 一 人工智能基础语法篇 二 人工智能中级篇 三 人工智能高级篇
- 计算机视觉、机器学习、人工智能领域知识汇总
http://blog.csdn.net/zouxy09 2012年8月21号开始了我的第一篇博文,也开始了我的研究生生涯.怀着对机器学习和计算机视觉等等领域的懵懂,从一个电子材料的领域跨入这个高速发 ...
- 一份为高中生准备的机器学习与人工智能入门指南
翻译 | AI科技大本营 参与 | 林椿眄 作为一名高中生,我在过去的一年里自学了机器学习与人工智能的相关课程,在这里和大家分享下我自己的学习心得,希望能够对那些机器学习或人工智能初学者有所帮助,这也 ...
- 干货丨数据科学、机器学习、人工智能,究竟有什么区别?
来源:雷锋网 原标题What's the difference between data science, machine learning, and artificial intelligence, ...
- 2017回顾与2018前瞻:机器学习与人工智能
隔一年,科技媒体 KDnuggets 最近向大数据.数据科学.人工智能和机器学习领域的一些顶尖专家征询了他们对于 2017 年这些领域最重要的发展,以及 2018 年的主要发展趋势的看法.这篇文章是本 ...
- 一天1个机器学习知识点(四)
陆陆续续整理的机器学习的知识点,资料大多数来自网上,不做盈利目的,如果侵权请告知即删!如果文章中有错误的地方还请各位同学指正,,一起学习,一起进步! 每天都在更新中,记得收藏,每天进步一点点!! 一天 ...
- 一天1个机器学习知识点(三)
陆陆续续整理的机器学习的知识点,资料大多数来自网上,不做盈利目的,如果侵权请告知即删!如果文章中有错误的地方还请各位同学指正,,一起学习,一起进步! 每天都在更新中,记得收藏,每天进步一点点!! 一天 ...
- 一天1个机器学习知识点(二)
陆陆续续整理的机器学习的知识点,资料大多数来自网上,不做盈利目的,如果侵权请告知即删!如果文章中有错误的地方还请各位同学指正,,一起学习,一起进步! 每天都在更新中,记得收藏,每天进步一点点!! 一天 ...
- 机器学习和人工智能的初学指南
摘要: 作者自学机器学习和人工智能,站在一个初学者的角度来回顾这些经历并编写这篇适合初学者的指南. 我自学过一年机器学习和人工智能,我认为初学者在该领域还没有一个学习的途径,这是我创建这个指南的目的. ...
最新文章
- 8道Python基础面试练习题
- Android平台使用PocketSphinx做离线语音识别,小范围语音99%识别率
- 树莓派如何卸载mysql_树莓派安装MySQL数据库与卸载
- 数据类型_分享redis中除5种基础数据类型以外的高级数据类型
- [转]数据库分库分表
- php协程和goroutine,golang中四种方式实现子goroutine与主协程的同步
- jsf 写一个action_一个JSF清单示例
- 我们可以用SharePoint做什么
- Nginx安装及配置文件解释
- android jar包 权限,Android系统启动执行jar程序
- Java开发笔记(一百四十七)通过JDBC管理数据库
- 国家应统一手机快充标准
- 增删改查oracle sql,oracle sql增删改查
- 将城市按照拼音首字母进行分类
- CSS-table样式+
- .bat文件和脚本文件
- Poi 、Jacob 统计word文档字数实现方式
- MSP430F5438A+TM1650四位数码管显示+16位AD转换器ADS1110
- 网工必须要了解BGP外部网关路由选择协议
- Runtime Error! R6025-pure virtual function call 问题怎么解决