Adaptable DL with nGraph™ Compiler and ONNX*
2019独角兽企业重金招聘Python工程师标准>>> 
Adaptable Deep Learning Solutions with nGraph™ Compiler and ONNX*
Artificial intelligence methods and deep learning techniques based on neural networks continue to gain adoption in more industries. As neural networks’ architectures grow in complexity, they gain new capabilities, and the number of possible solutions for which they may be used also grows at an increasing rate. With so many constantly-changing variables at play, finding some common ground for developers to collaborate to improve or adapt their solutions is important. Community-supported projects like ONNX are introducing standards that help frameworks interoperate and accommodate new architectures. Intel’s open-source nGraph Library and Compiler suite was an early supporter of ONNX. The nGraph team has already released a Python importer for running inference with ONNX-formatted models and is planning to support the newly-released ONNXIFI interface soon.
Given that algorithms are increasingly making use of a larger landscape of data of increasing quality, it may be difficult to predict what your future machine-learning requirements may be. At Intel, we are primed to give machine learning and AI developers maximum flexibility for software integration: freedom to create or use an optimized or scalable end-to-end system with any framework while also avoiding hardware lock-in. Using the most efficient and flexible implementations of algorithms for whatever part of the stack you are working on—from the cloud to bare metal—is increasingly important.
Many businesses offer services that harness deep learning in processing user requests. A common use case starts with training a specialized neural network on a big data set in a lab or on a large computing cluster. The trained network becomes part of a solution, which must then be deployed on scalable and affordable cloud edge infrastructure. Cloud infrastructure equipped with dedicated neural network accelerator hardware or GPUs is still rare and expensive; most data centers offer servers based on Intel CPUs. In this blog, we present a general overview of ONNX and nGraph and share some example code that can help anyone become acquainted with some of the work done thus far.
What is ONNX?
The Open Neural Network Exchange (ONNX) is a standard file format for storing neural networks. Models trained in a variety of frameworks can be exported to an ONNX file and later read with another framework for further processing. ONNX is an open standard backed by large industry players such as Microsoft, Facebook, and Amazon, as well as a broad community of users. Support for ONNX is being built into a growing number of deep learning frameworks including PyTorch*, Microsoft*’s Cognitive Toolkit (CNTK), Caffe2*, and Apache MXNet*. Tools to use ONNX with many other frameworks like TensorFlow*, Apple* CoreML, Chainer*, and SciKit-Learn* are also under active development. ONNX files are useful for analysis and visualization of networks in tools such as Netron.
ONNX is aiming to be the standard solution for interoperability between different types of deep-learning software and exchange of models by the Machine Learning community. Thanks to ONNX, we can use any one of the compatible frameworks for designing, training, debugging, and deploying our neural networks. When the model is ready, we can export it to an ONNX file and run inference in an application.
What is nGraph?
nGraph is a Compiler, Library and runtime suite of tools (APIs) for custom deep learning solutions. The nGraph Compiler is Intel’s computational graph compiler for Neural Networks, able to transform a deep learning model into an executable, optimized function which runs efficiently on a variety of hardware, including Intel® Architecture Processors (CPUs), Intel® Nervana™ Neural Network Processor (Intel® Nervana™ NNP), graphics cards (GPUs) and other backends. nGraph provides both a C++ API for framework developers and a Python API which can be used to run inference on models imported from ONNX.
nGraph uses the Intel® Math Kernel Library for Deep Neural Networks (Intel MKL-DNN), and provides a significant performance boost on CPUs, such as those running in a cloud datacenter.
nGraph can also be used as a backend by deep learning frameworks such as MXNet*, TensorFlow* and neon™. Because nGraph optimizes the computation of an entire graph, in some scenarios, it can outperform even versions of frameworks optimized to use MKL-DNN directly.
Using nGraph-ONNX
The following example shows how easy it is to export a trained model from PyTorch to ONNX and use it to run inference with nGraph. More information about exporting ONNX models from PyTorch can be found here.
Start by exporting the ResNet-50 model from PyTorch’s model zoo to an ONNX file:
from torch.autograd import Variable
import torch.onnx
import torchvision
# ImageNet input has 3 channels and 224x224 resolution
imagenet_input = Variable(torch.randn(1, 3, 224, 224))
# Download ResNet (or construct your model)
model = torchvision.models.resnet50(pretrained=True)
# Export model to an ONNX file
torch.onnx.export(model, imagenet_input, 'resnet.onnx')
This should create a resnet.onnx file containing the model. Try opening the file in Netron to inspect it. For detailed information about exporting ONNX files from frameworks like PyTorch Caffe2, CNTK, MXNet, TensorFlow, and Apple CoreML, tutorials are located here.
After the export is complete, you can import the model to nGraph using the ngraph-onnx companion tool which is also open source and available on GitHub.
from ngraph_onnx.onnx_importer.importer import import_onnx_file
# Import the ONNX file
models = import_onnx_file('resnet.onnx')
# Import produces a list of models defined in the ONNX file
[{'inputs': [<Parameter: '0' ([1, 3, 224, 224], float)>],
'name': 'output',
'output': <Add: 'output' ([1, 1000])>}]
nGraph’s Python API is easy to use and allows you to run inference on the imported model:
import ngraph as ng
# Create an nGraph runtime environment
runtime = ng.runtime(backend_name='CPU')
# Select the first model and compile it to a callable function
model = models[0]
resnet = runtime.computation(model['output'], *model['inputs'])
# Load your input as a numpy array (here we just use dummy data)
import numpy as np
picture = np.ones([1, 3, 224, 224])
# Run inference on the input data
resnet(picture)
During the first run, your model is compiled to an executable function which will be called on every subsequent call to inference. For optimal results, set up a server which loads and compiles the model and waits for incoming requests.
Performance advantages of using nGraph
Depending on the hardware platform and framework you’re using, performance benefits of using nGraph can be quite significant. Figure 1 below presents a comparison of running inference on a ResNet-50 model natively in PaddlePaddle, PyTorch, Caffe2 and CNTK with running the ONNX version of the same model in nGraph. See the Configuration Details in the footnotes for how we achieved these numbers.
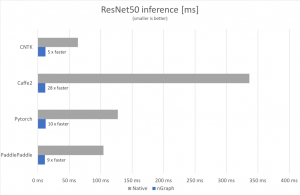 Figure 1: Inference latency for ResNet50 using various frameworks compared to running the same model via ONNX in nGraph. Batch size=1, input size=3x224x224. Smaller bar (shorter inference time) is better
Figure 1: Inference latency for ResNet50 using various frameworks compared to running the same model via ONNX in nGraph. Batch size=1, input size=3x224x224. Smaller bar (shorter inference time) is better
In conclusion, we are excited about the results we’ve obtained thus far: vastly improved latency performance over native implementations of inference solutions across multiple frameworks. Inference applications that are designed, built, tested, and deployed to make use of ONNX and our nGraph Python APIs provide a significant performance advantage and can help developers adapt and evolve their AI platforms and solutions anywhere on the stack.
Configuration Details
Hardware configuration:
2S Intel(R) Xeon(R) Platinum 8180 CPU @ 2.50GHz (28 cores), HT enabled, turbo enabled, 384GB (12 * 32GB) DDR4 ECC SDRAM RDIMM @ 2666MHz (Micron* part no. 36ASF4G72PZ-2G6D1), 960GB SSD 2.5in SATA 3.0 6Gb/s Intel SSDSC2KB96, ethernet adapter: Intel PCH Integrated 10 Gigabit Ethernet Controller
Software configuration:
Ubuntu 16.04.4 LTS (GNU/Linux 4.4.0-127-generic x86_64).
Software Release Versions:
ngraph - commit 6ccfbeb
ngraph-onnx - commit 6ad1f49
onnx - commit 410530e
Caffe2 - version 0.8.1, commit 2063fc7
CNTK - version 2.5.1
PyTorch - version 0.4.0-cp35-cp35m-linux_x86_64
PaddlePaddle - commit 94a741d
Measurement:
inference on ResNet-50 with batch size 1, median performance based on 10000 repeats
Scripts:
https://github.com/NervanaSystems/ngraph-onnx/tree/pub_blog_benchmarks/benchmarks
Prerequisites:
Please make sure the following are installed on your system:
- git
- git-lfs
- Docker
Command lines:
git clone -b pub_blog_benchmarks \
https://github.com/NervanaSystems/ngraph-onnx/
cd ngraph-onnx/benchmarks
./run_benchmarks.sh -s 10000
转载于:https://my.oschina.net/u/2306127/blog/1916671
Adaptable DL with nGraph™ Compiler and ONNX*相关推荐
- 微软医疗ai_微软ai运行时内部的外观
微软医疗ai Today, I want to wear my software archeology hat, and share with you one story about the AI e ...
- 深度学习编译器综述The Deep Learning Compiler
深度学习编译器综述The Deep Learning Compiler The Deep Learning Compiler: A Comprehensive Survey 参考文献: https:/ ...
- 全文翻译(全文合集):TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
全文翻译(全文合集):TVM: An Automated End-to-End Optimizing Compiler for Deep Learning 摘要 人们越来越需要将机器学习应用到各种各样 ...
- 全文翻译(一):TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
全文翻译(一):TVM: An Automated End-to-End Optimizing Compiler for Deep Learning 摘要 人们越来越需要将机器学习应用到各种各样的硬件 ...
- 传统编译器和DL编译器的调研和理解
文章目录 Part One : 传统编译器 1.1 前端 1.2 中端 常见的优化 1.3 后端 指令的选择 寄存器分配 指令重排 1.4 总结 Part Two:深度学习编译器 2.1 为什么需要 ...
- 全文翻译(四) TVM An Automated End-to-End Optimizing Compiler
全文翻译(四) TVM An Automated End-to-End Optimizing Compiler 6.3 嵌入式GPU评估 对于移动GPU实验,在配备ARM Mali-T860MP4 G ...
- 全文翻译(三) TVM An Automated End-to-End Optimizing Compiler
全文翻译(三) TVM An Automated End-to-End Optimizing Compiler 5. 自动化优化 考虑到一组丰富的调度原语,剩下的问题是为DL模型的每一层,找到最佳的算 ...
- 全文翻译(二): TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
全文翻译(二): TVM: An Automated End-to-End Optimizing Compiler for Deep Learning 3.优化计算图 计算图是在DL框架中表示程序的常 ...
- NNVM Compiler,AI框架的开放式编译器
NNVM Compiler,AI框架的开放式编译器 深度学习已变得无处不在且不可或缺.在多种平台(例如手机,GPU,IoT设备和专用加速器)上部署深度学习工作负载的需求不断增长.宣布了TVM堆栈,以弥 ...
- 开放神经网络交换(ONNX)工具
开放神经网络交换(ONNX)工具 开放神经网络交换(ONNX)是一个开放的生态系统,它使人工智能开发人员能够在项目发展过程中选择正确的工具.ONNX为人工智能模型提供了一种开源格式,包括深度学习和传统 ...
最新文章
- 计算机视觉一些项目实战技术
- 微信开放JS-SDK,助力网页开发[转自微信官方]
- 大合集!80 篇 CVPR2020 论文分方向整理: 目标检测/图像分割/姿态估计等(附链接&下载)...
- 解决sublime text3安装Package Control问题
- 【Android 插件化】“ 插桩式 “ 插件化框架 ( 类加载器创建 | 资源加载 )
- VMware中的ubuntu虚拟机开机黑屏,无法打开桌面
- 【SpringBoot零基础案例05】【IEDA 2021.1】若SpringBoot项目两种配置文件同时存在,哪种文件配置起作用?
- MMDB ip地址库操作
- ApacheCN 数据库译文集 20211112 更新
- Kali Linux 秘籍 翻译完成!
- java可变参数学习
- js定义php中变量,JavaScript 变量
- 华为鸿蒙os2.0游戏,华为鸿蒙os2.0系统下载-华为鸿蒙系统官方下载入口2.0下载 - 一游网手机游戏...
- IDEA配置Android-SDK
- 永久免费虚拟主机、免费云服务器,白嫖党福利!
- 随机生成50道加减算术题
- centos 中 Discuz 论坛模板配置问题
- JAVA毕设项目html5在线医疗系统(Vue+Mybatis+Maven+Mysql+sprnig+SpringMVC)
- Android开发者账号申请注册及上传
- 一大法器-----正则表达式
热门文章
- ssh-keygen 指定路径
- 量化交易:金融算法交易的前沿发展
- Python: PS 滤镜--碎片特效
- 深度学习笔记----拓扑结构动态变化网络(Dropout,Drop Connect, Stochastic Depth, BranchyNet,Blockdrop,SkipNet)
- Real Time Transfer (RTT)
- 股票大作手杰西·利弗莫尔语录集锦
- 智能建造与建筑工业化协同发展主战场之一:攻克核心工业软件
- Windows 10 word无法创建工作文件,找不到临时环境变量
- 开奖及送福利|周日晚八点,红包雨任性下
- fastdb学习记录#1 table、宏、query、cursor