机器学习源代码_机器学习中程序源代码的静态分析
机器学习源代码
Machine learning has firmly entrenched in a variety of human fields, from speech recognition to medical diagnosing. The popularity of this approach is so great that people try to use it wherever they can. Some attempts to replace classical approaches with neural networks turn up unsuccessful. This time we'll consider machine learning in terms of creating effective static code analyzers for finding bugs and potential vulnerabilities.
从语音识别到医学诊断,机器学习已在各个领域牢牢扎根。 这种方法的普及是如此之大,以至于人们尝试在任何可能的地方使用它。 用神经网络代替经典方法的一些尝试失败了。 这次,我们将在创建有效的静态代码分析器以发现错误和潜在漏洞方面考虑机器学习。
The PVS-Studio team is often asked if we want to start using machine learning to find bugs in the software source code. The short answer is yes, but to a limited extent. We believe that with machine learning, there are many pitfalls lurking in code analysis tasks. In the second part of the article, we will tell about them. Let's start with a review of new solutions and ideas.
经常会询问PVS-Studio团队是否要开始使用机器学习来查找软件源代码中的错误。 简短的答案是肯定的,但在一定程度上是有限的。 我们相信,在机器学习中,代码分析任务有很多隐患。 在本文的第二部分,我们将介绍它们。 让我们从回顾新的解决方案和想法开始。
新方法 (New Approaches)
Nowadays there are many static analyzers based on or using machine learning, including deep learning and NLP for error detection. Not only did enthusiasts double down on machine learning potential, but also large companies, for example, Facebook, Amazon, or Mozilla. Some projects aren't full-fledged static analyzers, as they only find some certain errors in commits.
如今,有许多基于或使用机器学习的静态分析器,包括深度学习和用于错误检测的NLP。 发烧友不仅在机器学习潜能上加倍,而且在大型公司(例如,Facebook,Amazon或Mozilla)上也加倍。 有些项目不是成熟的静态分析器,因为它们只能在提交中发现某些错误。
Interestingly, almost all of them are positioned as game changer products that will make a breakthrough in the development process due to artificial intelligence.
有趣的是,几乎所有产品都被定位为改变游戏规则的产品,由于人工智能,它们将在开发过程中取得突破。

Let's look at some of the well-known examples:
让我们看一些著名的例子:
- DeepCode
深度密码 - Infer, Sapienz, SapFix
推断,Sapienz,SapFix - Embold
包容 - Source{d}
来源{d} - Clever-Commit, Commit Assistant
聪明的提交,提交助理 - CodeGuru
CodeGuru
深度密码 (DeepCode)
Deep Code is a vulnerability-searching tool for Java, JavaScript, TypeScript, and Python software code that features machine learning as a component. According to Boris Paskalev, more than 250,000 rules are already in place. This tool learns from changes, made by developers in the source code of open source projects (a million of repositories). The company itself says that their project is some kind of Grammarly for developers.
Deep Code是针对Java,JavaScript,TypeScript和Python软件代码的漏洞搜索工具,该工具将机器学习作为组件。 根据鲍里斯·帕斯卡列夫(Boris Paskalev)的说法,已经制定了超过25万条规则。 该工具从开发人员在开放源代码项目(一百万个存储库)的源代码中进行的更改中学习。 该公司本身说,他们的项目对开发人员来说是一种文法。

In fact, this analyzer compares your solution with its project base and offers you the intended best solution from the experience of other developers.
实际上,该分析仪会将您的解决方案与其项目基础进行比较,并根据其他开发人员的经验为您提供预期的最佳解决方案。
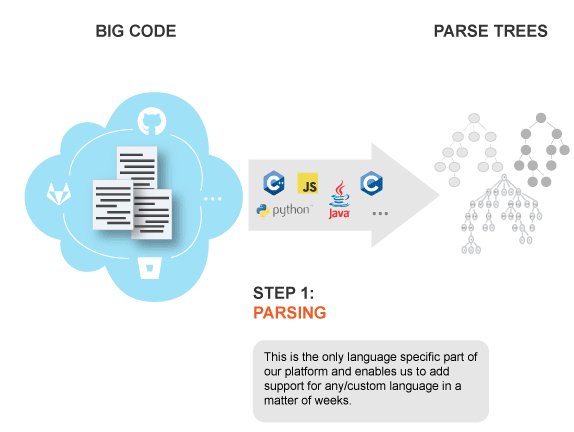
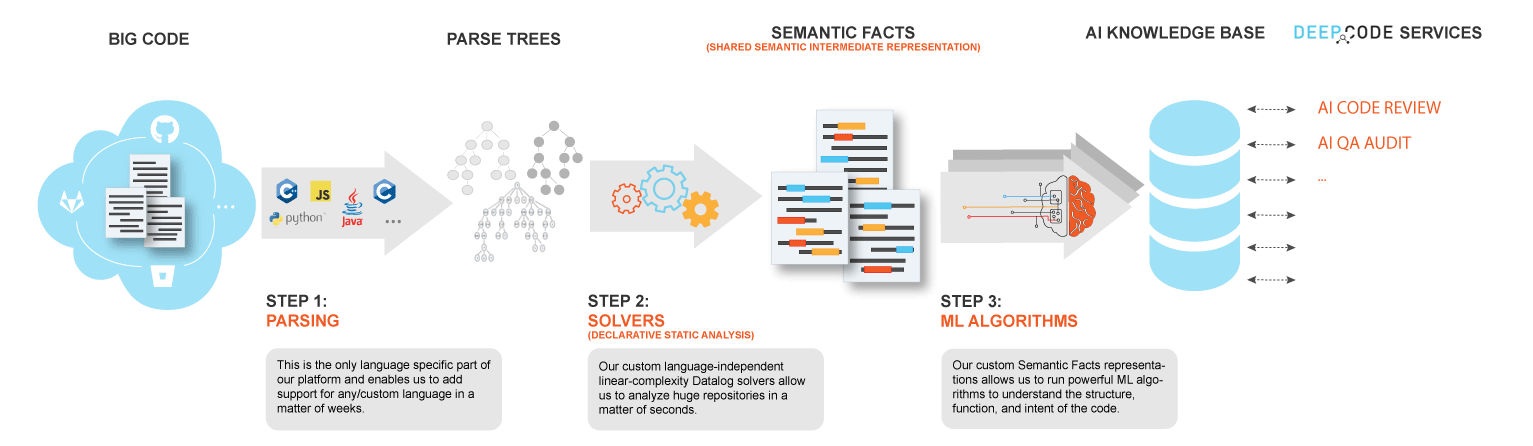
In May 2018, developers said that the support of C++ is on its way, but so far, this language is not supported. Although, as stated on the site, the new language support can be added in a matter of weeks due to the fact that the language depends only on one stage, which is parsing.
在2018年5月,开发人员表示正在支持C ++,但到目前为止,尚不支持该语言。 尽管如该网站上所述,由于该语言仅取决于解析的一个阶段,因此可以在几周内添加新的语言支持。
A series of posts about basic methods of the analyzer is also available on the site.
该站点上还提供了一系列有关分析仪基本方法的帖子。
推断 (Infer)
Facebook is quite zealous in its attempts to introduce new comprehensive approaches in its products. Machine learning didn't stay on the sidelines either. In 2013, they bought a startup that developed a static analyzer based on machine learning. And in 2015, the source code of the project became open.
Facebook非常热衷于在其产品中引入新的综合方法。 机器学习也不是一成不变的。 2013年,他们购买了一家初创公司,该公司开发了基于机器学习的静态分析器。 并且在2015年,该项目的源代码公开了 。
Infer is a static analyzer for projects in Java, C, C++, and Objective-C, developed by Facebook. According to the site, it's also used in Amazon Web Services, Oculus, Uber, and other popular projects.
Infer是用于Facebook开发的Java,C,C ++和Objective-C项目的静态分析器。 据该网站称,它还用于Amazon Web Services,Oculus,Uber和其他受欢迎的项目。
Currently, Infer is able to find errors related to null pointer dereference and memory leaks. Infer is based on Hoare's logic, separation logic and bi-abduction, as well as abstract interpretation theory. Usage of these approaches allows the analyzer to break the program into chunks and analyze them independently.
当前,Infer能够找到与空指针取消引用和内存泄漏有关的错误。 推断基于Hoare的逻辑,分离逻辑和双绑架,以及抽象解释理论。 通过使用这些方法,分析人员可以将程序分解为多个块,并进行独立分析。
You can try using Infer on your projects, but developers warn that while with Facebook projects it generates about 80% of useful warnings, a low number of false positives isn't guaranteed on other projects. Here are some errors that Infer can't detect so far, but developers are working on implementing these warnings:
您可以尝试在项目上使用Infer,但开发人员警告说,尽管在Facebook项目中,它会生成约80%的有用警告,但不能保证其他项目上的误报率较低。 这是到目前为止Infer尚无法检测到的一些错误,但是开发人员正在着手实施以下警告:
- array index out of bounds;
数组索引超出范围; - type casting exceptions;
类型转换异常; - unverified data leaks;
未验证的数据泄漏; - race condition.
比赛条件。
汁液修复 (SapFix)
SapFix is an automated editing tool. It receives information from Sapienz, a testing automation tool, and the Infer static analyzer. Based on recent changes and messages, Infer selects one of several strategies to fix bugs.
SapFix是一种自动编辑工具。 它从测试自动化工具Sapienz和推断静态分析器接收信息。 根据最近的更改和消息,Infer选择了几种解决错误的策略之一。
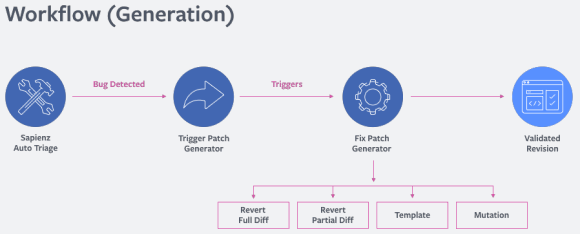
In some cases, SapFix rolls back all changes or parts of them. In other cases, it tries to solve the problem by generating a patch from its set of fixing patterns. This set is formed from patterns of fixes collected by programmers themselves from a set of fixes that were already made. If such a pattern doesn't fix an error, SapFix tries to adjust it to the situation by making small modifications in an abstract syntax tree until the potential solution is found.
在某些情况下,SapFix会回滚所有更改或部分更改。 在其他情况下,它试图通过根据其固定样式集生成补丁来解决该问题。 该集合是由程序员自己从已经制定的一组修复程序中收集的修复程序模式组成的。 如果这种模式不能解决错误,则SapFix会尝试通过在抽象语法树中进行一些小的修改来适应情况,直到找到可能的解决方案为止。
But one potential solution is not enough, so SapFix collects several solutions' on the grounds of a couple of points: whether there are compilation errors, whether it crashes, whether it introduces new crashes. Once the edits are fully tested, patches are reviewed by a programmer, who will decide which of the edits best solves the problem.
但是一个潜在的解决方案还不够,因此SapFix基于以下几点收集了几种解决方案:是否存在编译错误,是否崩溃,是否引入了新的崩溃。 一旦对编辑进行了完整的测试,程序员将检查补丁,由程序员决定哪个编辑最能解决问题。
包容 (Embold)
Embold is a start-up platform for static analysis of software source code that was called Gamma before the renaming. Static analyzer works based on the tool's own diagnostics, as well as using built-in analyzers, such as Cppcheck, SpotBugs, SQL Check and others.
Embold是一个用于静态分析软件源代码(在重命名之前称为Gamma)的启动平台。 静态分析器基于工具自身的诊断程序以及内置分析器(例如Cppcheck,SpotBugs,SQL Check等)运行。
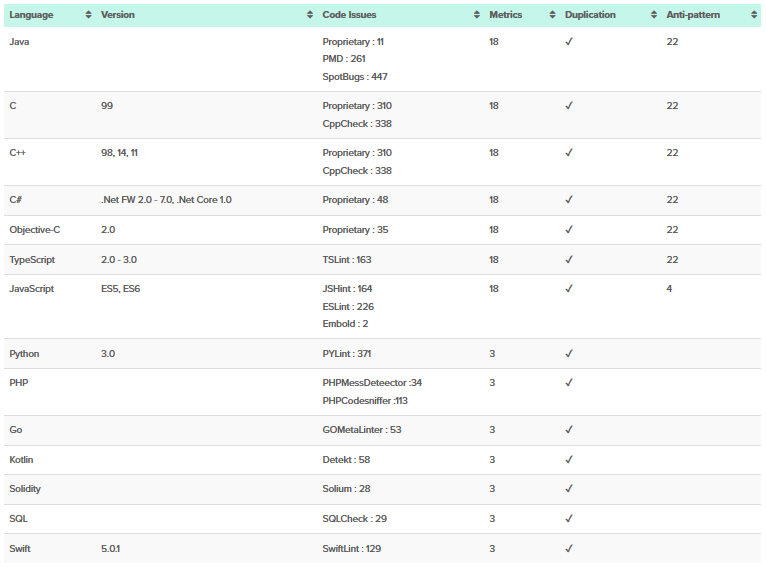
In addition to diagnostics themselves, the platform focuses on vivid infographics on the load of codebase and convenient viewing of found errors, as well as searching for possible refactoring. Besides, this analyzer has a set of anti-patterns that allows you to detect problems in the code structure at the class and method level, and various metrics to calculate the quality of a system.
除了诊断本身之外,该平台还专注于代码库负载的生动信息图表,方便查看发现的错误,以及搜索可能的重构。 此外,此分析器还具有一组反模式,使您可以在类和方法级别检测代码结构中的问题,并使用各种度量来计算系统质量。

One of the main advantages is the intelligent system of offering solutions and edits, which, in addition to conventional diagnostics, checks edits based on information about previous changes.
主要优点之一是提供解决方案和编辑的智能系统,除了常规诊断程序外,该系统还基于有关先前更改的信息检查编辑。

With NLP, Embold breaks the code apart and searches for interconnections and dependencies between functions and methods, saving refactoring time.
使用NLP,Emold将代码分开,并搜索函数和方法之间的互连和依赖关系,从而节省了重构时间。
In this way, Embold basically offers convenient visualization of your source code analysis results by various analyzers, as well as by its own diagnostics, some of which are based on machine learning.
这样,Embold基本上可以通过各种分析器以及它自己的诊断程序(它们中的某些诊断程序是基于机器学习的)来方便地可视化源代码分析结果。
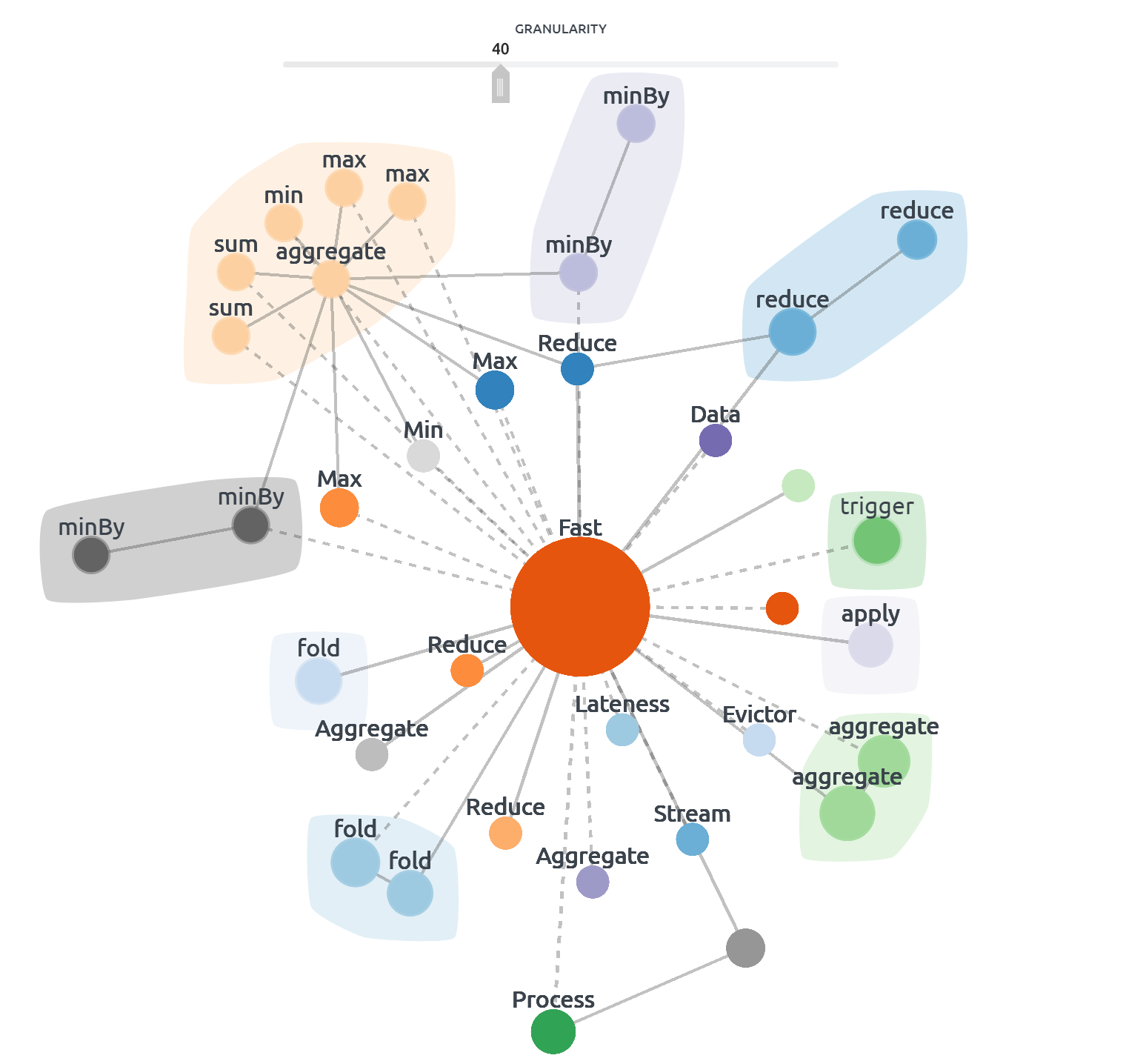
来源{d} (Source{d})
Source{d} is the most open tool in terms of the ways of its implementation compared to the analyzers we've reviewed. It is also an open source code solution. On their website, in exchange for your mail address, you can get a product leaflet describing the technologies they use. Besides, the website gives a link to the database of publications related to machine learning usage for code analysis, as well as the repository with dataset for code-based learning. The product itself is a whole platform for analyzing the source code and the software product, and is focused not on developers, but rather on managers. Among its capabilities is calculation of technical debt size, bottlenecks in the development process and other global statistics on the project.
与我们分析过的分析仪相比,Source {d}在实现方式上是最开放的工具。 这也是一个开放源代码解决方案 。 在他们的网站上,以您的邮件地址作为交换,您可以获取描述其使用技术的产品传单。 此外,该网站还提供了与机器学习用法有关的出版物数据库链接的代码分析,以及带有基于代码的学习数据集的存储库 。 产品本身是一个用于分析源代码和软件产品的完整平台,并且不针对开发人员,而是针对管理人员。 它的功能包括计算技术债务规模,开发过程中的瓶颈以及该项目的其他全局统计信息。
Their approach to code analysis through machine learning is based on Natural Hypothesis, as outlined in the article "On the Naturalness of Software".
他们通过机器学习进行代码分析的方法基于自然假说,如“ 软件的自然性 ”一文中所述。
«Programming languages, in theory, are complex, flexible and powerful, but the programs that real people actually write are mostly simple and rather repetitive, and thus they have usefully predictable statistical properties that can be captured in statistical language models and leveraged for software engineering tasks.»«从理论上讲,编程语言是复杂,灵活和强大的,但实际的人实际上编写的程序大多是简单且相当重复的,因此它们具有有用的可预测统计属性,可以将其捕获在统计语言模型中并用于软件工程。任务。”
Based on this hypothesis, the larger the code base is, the greater the statistical properties are, and the more accurate the metrics, achieved through learning, will be.
基于此假设,代码库越大,统计属性越大,通过学习获得的度量标准越准确。
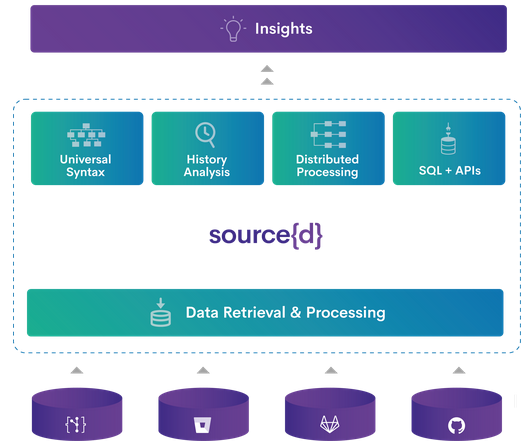
To analyze the code in source{d}, the Babelfish service is used, which can parse the code file in any of the available languages, get an abstract syntax tree and convert it into a universal syntax tree.
为了分析source {d}中的代码,使用了Babelfish服务,该服务可以解析任何可用语言的代码文件,获取抽象语法树并将其转换为通用语法树。
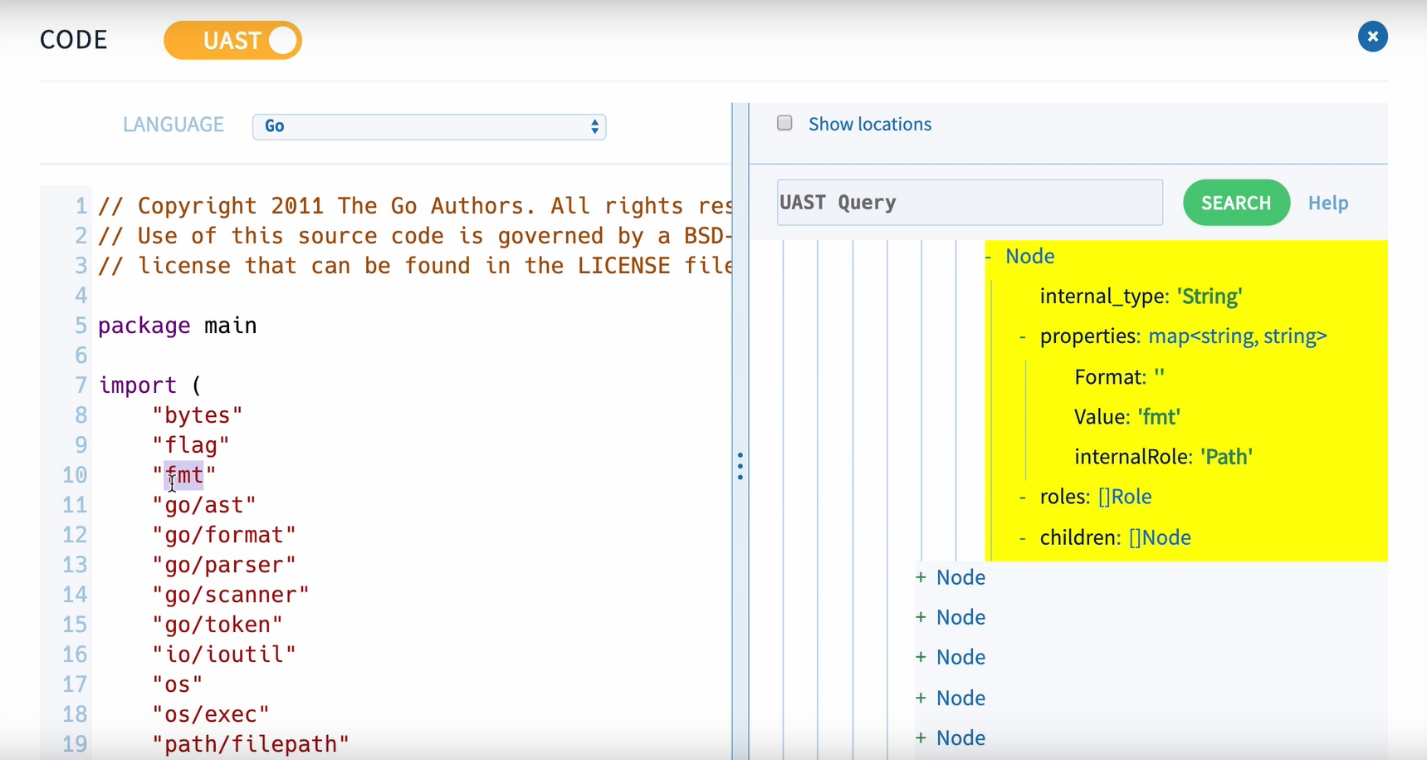
However, source{d} doesn't search for errors in code. Based on the tree using ML on the entire project, source{d} detects code formatting, style applied in the project and in a commit. If the new code doesn't correspond to the project code style, it makes some edits.
但是,source {d}不会在代码中搜索错误。 基于在整个项目上使用ML的树,source {d}可以检测代码格式,在项目和提交中应用的样式。 如果新代码与项目代码样式不符,则会进行一些编辑。


Learning focuses on several basic elements: spaces, tabulation, line breaks, etc.
学习侧重于几个基本元素:空格,制表符,换行符等。

Read more about this in their publication: "STYLE-ANALYZER: fixing code style inconsistencies with interpretable unsupervised algorithms".
在其出版物中阅读有关此内容的更多信息:“ 样式分析器:使用可解释的无监督算法修复代码样式不一致 ”。
All in all, source{d} is a wide platform for collecting diverse statistics on the source code and the project development process: from efficiency calculations of developers to time costs for code review.
总而言之,source {d}是一个广泛的平台,用于收集有关源代码和项目开发过程的各种统计信息:从开发人员的效率计算到代码审查的时间成本。
聪明地做 (Clever-Commit)
Clever-Commit is an analyzer created by Mozilla in collaboration with Ubisoft. It's based on a CLEVER (Combining Levels of Bug Prevention and Resolution Techniques) study by Ubisoft and its child product Commit Assistant, which detects suspicious commits that are likely to contain an error. Since CLEVER is based on code comparison, it can both point at dangerous code and make suggestions for possible edits. According to the description, in 60-70% of cases Clever-Commit finds problem places and offers correct edits with the same probability. In general, there is little information about this project and about the errors it is able to find.
Clever-Commit是由Mozilla与Ubisoft合作创建的分析器。 它基于Ubisoft及其子产品Commit Assistant进行的CLEVER (错误预防和解决技术的组合级别)研究,该研究检测可能包含错误的可疑提交。 由于CLEVER基于代码比较,因此它既可以指向危险代码,也可以为可能的编辑提供建议。 根据描述,Clever-Commit在60-70%的情况下会发现问题所在,并以相同的概率提供正确的编辑。 通常,关于该项目及其能够找到的错误的信息很少。
CodeGuru (CodeGuru)
Recently CodeGuru, which is a product from Amazon, has fallen into line with analyzers using machine learning. It is a machine learning service that allows you to find errors in the code, as well as identify costly areas in it. The analysis is available only for Java code so far, but authors promise to support other languages in future. Although it was announced quite recently, Andy Jassy, CEO AWS (Amazon Web Services) says it has been used in Amazon for a long time.
最近,来自亚马逊的产品CodeGuru已与使用机器学习的分析仪相一致。 它是一种机器学习服务,可让您查找代码中的错误以及确定其中的昂贵区域。 到目前为止,该分析仅适用于Java代码,但作者承诺将来会支持其他语言。 尽管它是在最近宣布的,但AWS(Amazon Web Services)首席执行官Andy Jassy表示,它已经在Amazon中使用了很长时间。
The website says that CodeGuru was learning on the Amazon code base, as well as on more than 10 000 open source projects.
该网站说CodeGuru正在Amazon代码库以及超过10 000个开源项目上学习。
Basically, the service is divided into two parts: CodeGuru Reviewer, taught using the search for associative rules and looking for errors in code, and CodeGuru Profiler, monitoring performance of applications.
基本上,该服务分为两个部分:使用搜索关联规则并查找代码错误的CodeGuru Reviewer和用于监视应用程序性能的CodeGuru Profiler。
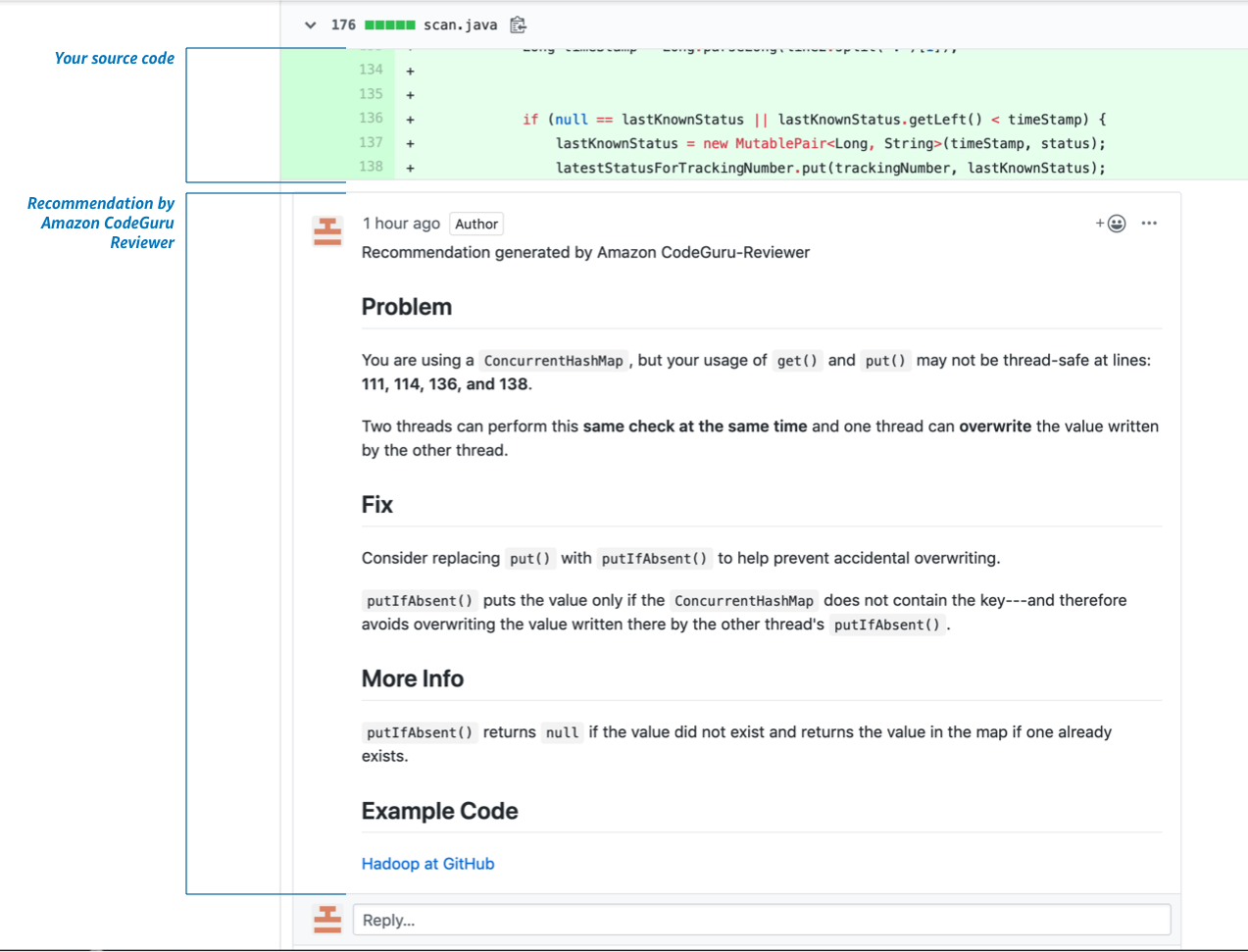
In general, there is not much available information about this project. As the website states, the Reviewer analyzes Amazon code bases and searches for pull requests, containing API AWS calls in order to learn how to catch deviations from «best practices». Next, it looks at the changes made and compares them to data from the documentation, which is analyzed at the same time. The result is a «best practices» model.
通常,关于此项目的可用信息很少。 如网站所述,Reviewer会分析Amazon代码库并搜索包含API AWS调用的请求请求,以了解如何发现与“最佳实践”的差异。 接下来,它查看所做的更改并将它们与文档中的数据进行比较,并同时进行分析。 结果就是“最佳实践”模型。
It is also said that recommendations for user's code tend to improve after receiving feedback on them.
还可以说,在收到用户代码的建议后,对它们的建议往往会有所改善。
The list of errors that Reviewer responds to is fairly blurred, as no specific error documentation has been published:
Reviewer响应的错误列表相当模糊,因为尚未发布任何特定的错误文档:
- «Best Practices» AWS
«最佳实践»AWS - Concurrency
并发 - Resource leaks
资源泄漏 - Leak of confidential information
机密信息泄漏 - General «best practices» of coding
一般的“最佳做法”编码
我们的怀疑论 (Our Skepticism)
Now let's consider error searching from the point of view of our team, which has been developing static analyzers for many years. We see a number of high-level problems of learning method application, which we'd like to cover. To begin with, we'll divide all ML approaches into two types:
现在让我们从我们的团队的角度考虑错误搜索,该团队已经开发了很多年的静态分析仪。 我们看到了许多高级的学习方法应用问题,我们将介绍这些问题。 首先,我们将所有ML方法分为两种类型:
- Those which manually teach a static analyzer to search for various problems, using synthetic and real code examples;
那些通过合成和真实代码示例手动教静态分析仪来搜索各种问题的人员; - Those which teach algorithms on a large number of open source code and revision history (GitHub), after which the analyzer will begin to detect bugs and even offer edits.
那些在大量开放源代码和修订历史(GitHub)上教授算法的人,之后分析器将开始检测错误,甚至提供编辑。
We will talk about each direction separately, as they have different drawbacks. After that, I think, readers will get why we don't deny the possibilities of machine learning, but still don't share the enthusiasm.
我们将分别讨论每个方向,因为它们具有不同的缺点。 在那之后,我认为,读者会明白为什么我们不否认机器学习的可能性,但仍然没有分享热情。
注意。 (Note.)
We look from the perspective of developing a universal static general purpose analyzer. We are focused on developing the analyzer, which any team will be able to use, not the one focused on a specific code base.
我们从开发通用静态通用分析器的角度来看。 我们专注于开发任何团队都可以使用的分析器,而不是专注于特定代码库的分析器。
静态分析仪的手动教学 (Manual Teaching of a Static Analyzer)
Let's say we want to use ML to start looking for the following kinds of flaws in the code:
假设我们要使用ML开始寻找代码中的以下类型的缺陷:
if (A == A)It is strange to compare a variable with itself. We can write many examples of correct and incorrect code and teach the analyzer to search for such errors. Additionally, you can add real examples of already found bugs to the tests. Well, the question is where to find such examples. Ok, let's assume it's possible. For example, we have a number of examples of such errors: V501, V3001, V6001.
将变量与自身进行比较很奇怪。 我们可以编写许多正确和不正确的代码示例,并教会分析仪搜索此类错误。 此外,您可以将已经发现的错误的真实示例添加到测试中。 好吧,问题是在哪里可以找到这样的例子。 好吧,让我们假设这是可能的。 例如,我们有许多此类错误的示例: V501 , V3001 , V6001 。
So is it possible to identify such defects in code by using the ML algorithms? Yes, it is. The thing is — why do we need it?
那么可以通过使用ML算法来识别代码中的此类缺陷吗? 是的。 问题是-为什么我们需要它?
See, to teach the analyzer we'll need to spend a lot of efforts on preparing the examples for teaching. Another option is to mark the code of real applications, indicating the fragments where the analyzer has to issue a warning. In any case, a lot of work will need to be done, as there should be thousands of examples for learning. Or tens of thousands.
看,要教分析器,我们需要花费大量的精力来准备用于教学的示例。 另一个选择是标记实际应用程序的代码,指示分析仪必须发出警告的片段。 在任何情况下,都需要完成大量工作,因为应该有成千上万的学习示例。 或成千上万。
After all, we want to detect not only (A == A) cases, but also:
毕竟,我们不仅要检测(A == A)情况,而且要检测:
- if (X && A == A)
如果(X && A == A) - if (A + 1 == A + 1)
如果(A + 1 == A +1) - if (A[i] == A[i])
如果(A [i] == A [i]) - if ((A) == (A))
如果((A)==(A)) - and so on.
等等。

Let's look at the potential implementation of such a simple diagnostic in PVS-Studio:
让我们看一下在PVS-Studio中这种简单诊断的潜在实现:
void RulePrototype_V501(VivaWalker &walker,const Ptree *left, const Ptree *right, const Ptree *operation)
{if (SafeEq(operation, "==") && SafeEqual(left, right)){walker.AddError("Oh boy! Holy cow!", left, 501, Level_1, "CWE-571");}
}And that's it! You don't need any base of examples for ML!
就是这样! 您不需要ML的任何示例基础!
In the future, the diagnostic has to learn to take into account a number of exceptions and issue warnings for (A[0] == A[1-1]). As we know, it can be easily programmed. On the contrary, in this case, things are going to be bad with the base of examples.
将来,诊断人员必须学会考虑许多例外情况并发出(A [0] == A [1-1])的警告。 众所周知,可以很容易地对其进行编程。 相反,在这种情况下,以示例为基础的事情将变得很糟糕。
Note that in both cases we'll need a system of testing, documentation and so on. As for labor contribution on creating a new diagnostic, the classic approach, where the rule is rigidly programmed in the code, takes the lead.
请注意,在两种情况下,我们都需要一个测试系统,文档等。 至于创建新诊断程序所需的人工,经典方法是在代码中严格编程规则。
Ok, it's time for another rule. For example, the one where the result of some functions must be used. There is no point in calling them and not using their result. Here are some of such functions:
好的,现在该是另一个规则了。 例如,必须使用某些函数的结果的那个。 调用它们而不使用它们的结果是没有意义的。 以下是一些此类功能:
- malloc
分配 - memcmp
记忆体 - string::empty
字符串::空
This is what the PVS-Studio V530 diagnostic does.
这就是PVS-Studio V530诊断程序的工作。
So what we want is to detect calls to such functions, whose result isn't used. To do this, you can generate a lot of tests. And we think everything will work well. But again it is not clear why it is needed.
因此,我们想要的是检测对此类函数的调用,其结果未使用。 为此,您可以生成许多测试。 而且我们认为一切都会很好。 但是同样不清楚为什么需要它。
The V530 diagnostic implementation with all exceptions took 258 lines of code in the PVS-Studio analyzer, 64 of which are comments. There is also a table with functions annotations, where it's noted that their result must be used. It is much easier to top up this table than to create synthetic examples.
除所有异常外,V530诊断实施在PVS-Studio分析仪中使用了258行代码,其中有64行是注释。 还有一个带有函数注释的表,其中指出必须使用它们的结果。 与创建综合示例相比,为该表充值要容易得多。
Things will get even worse with diagnostics that use data flow analysis. For example, the PVS-Studio analyzer can track the value of pointers, which allows you to find such a memory leak:
使用数据流分析的诊断情况将变得更糟。 例如,PVS-Studio分析器可以跟踪指针的值,这使您可以找到这种内存泄漏:
uint32_t* BnNew() {uint32_t* result = new uint32_t[kBigIntSize];memset(result, 0, kBigIntSize * sizeof(uint32_t));return result;
}std::string AndroidRSAPublicKey(crypto::RSAPrivateKey* key) {....uint32_t* n = BnNew();....RSAPublicKey pkey;pkey.len = kRSANumWords;pkey.exponent = 65537; // Fixed public exponentpkey.n0inv = 0 - ModInverse(n0, 0x100000000LL);if (pkey.n0inv == 0)return kDummyRSAPublicKey; // <=....
}The example is taken from the article "Chromium: Memory Leaks". If the condition (pkey.n0inv == 0) is true, the function exits without freeing the buffer, the pointer to which is stored in the n variable.
该示例摘自文章“ Chromium:内存泄漏 ”。 如果条件(pkey.n0inv == 0)为true,则函数退出而不释放缓冲区,该缓冲区的指针存储在n变量中。
From the PVS-Studio's point of view, there is nothing complicated here. The analyzer has studied the BnNew function and remembered that it returned a pointer to the allocated memory block. In another function, it noticed that the buffer might not free and the pointer to it gets lost at the moment of exiting the function.
从PVS-Studio的角度来看,这里没有什么复杂的。 分析器研究了BnNew函数,并记住它返回了指向已分配内存块的指针。 在另一个函数中,它注意到缓冲区可能无法释放,并且在退出该函数时会丢失指向该缓冲区的指针。
It's a common algorithm of tracking values working. It doesn't matter how the code is written. It doesn't matter what else is in the function that doesn't relate to the pointer work. The algorithm is universal and the V773 diagnostic finds a lot of errors in various projects. See how different the code fragments with detected errors are!
这是跟踪值工作的常用算法。 编写代码的方式无关紧要。 与指针工作无关的函数中还有什么没关系。 该算法具有通用性,并且V773诊断程序会在各种项目中发现很多错误。 看看检测到错误的代码片段有多不同!
We aren't experts in ML, but we have a feeling that big problems are right around the corner here. There is an incredible number of ways you can write code with memory leaks. Even if the machine learned well how to track values of variables, it would need to understand that there are calls to functions as well.
我们不是ML方面的专家,但是我们感觉到这里即将出现大问题。 您可以使用多种方式编写带有内存泄漏的代码。 即使机器很好地学习了如何跟踪变量的值,也需要了解对函数的调用。
We suspect it would require so many examples for learning that the task becomes ungraspable. We're not saying it's unrealistic. We doubt that the cost of creating the analyzer will pay off.
我们怀疑这将需要大量的示例来学习,以至于任务变得无法掌握。 我们并不是说这是不现实的。 我们怀疑创建分析仪的成本是否会得到回报。
比喻。 (Analogy.)
What comes to my mind is the analogy with a calculator, where instead of diagnostics, one has to program arithmetic actions. We are sure, that you can teach an ML based calculator to sum up numbers well by feeding it the results of operations 1+1=2, 1+2=3, 2+1=3, 100+200=300 and so on. As you understand, the feasibility of developing such a calculator is a big question (unless it is allocated a grant :). A much simpler, faster, more accurate and reliable calculator can be written using the simple operation "+" in the code.
我想到的是与计算器的类比,在计算器中,必须编写算术动作而不是诊断。 我们相信,您可以教一个基于ML的计算器,通过向其提供操作1 + 1 = 2、1 + 2 = 3、2 + 1 = 3、100 + 200 = 300等的结果来很好地求和。 如您所知,开发这种计算器的可行性是一个大问题(除非为其分配了赠款:)。 使用代码中的简单操作“ +”可以编写一个更简单,更快,更准确和可靠的计算器。
结论 (Conclusion)
Well, this way will work out. But using it, in our opinion, doesn't make practical sense. Development will be more time-consuming, but the result — less reliable and accurate, especially when it comes to implementing complex diagnostics based on data flow analysis.
好吧,这种方式可以解决。 但是我们认为使用它没有实际意义。 开发将更加耗时,但结果-可靠性和准确性将降低,尤其是在基于数据流分析实施复杂诊断时。
学习大量的开源代码 (Learning on Large Amount of Open Source Code)
Okay, we've sorted out with manual synthetic examples, but there's also GitHub. You can track commit history and deduce code changing/fixing patterns. Then you can point not only at fragments of suspicious code, but even suggest a way to fix the code.
好的,我们整理了人工综合示例,但还有GitHub。 您可以跟踪提交历史记录并推断代码更改/修复模式。 然后,您不仅可以指向可疑代码的片段,甚至可以提出修复代码的方法。
If you stop at this detail level, everything looks good. The devil, as always, is in the details. So let's talk right about these details.
如果您停止在此详细信息级别,那么一切看起来都会很好。 一如既往,魔鬼在细节中。 因此,让我们谈谈这些细节。
第一个细微差别。 数据源。 (The first nuance. Data source.)
GitHub edits are quite random and diverse. People are often lazy to make atomic commits and make several edits in the code at the same time. You know how it happens: you would fix the bug, and at the same time refactor it a bit («And here I will add handling of such a case ...»). Even a person may then be incomprehensible, whether these fixed are related to each other, or not.
GitHub的编辑是相当随机和多样的。 人们通常懒于进行原子提交并同时在代码中进行多次编辑。 您知道它是如何发生的:您将修复该错误,并同时对其进行一些重构(«这里我将添加对这种情况的处理...»)。 甚至一个人都可能无法理解,无论这些固定的彼此是否相关。
The challenge is how to distinguish actual errors from adding new functionality or something else. You can, of course, get 1000 people who will manually mark the commits. People will have to point out: here an error was fixed, here is refactoring, here is some new functionality, here the requirements have changed and so on.
面临的挑战是如何通过添加新功能或其他方法来区分实际错误。 当然,您可以得到1000个人来手动标记提交。 人们必须指出:这里的错误已修复,这里的重构,这里是一些新功能,这里的需求已发生变化,等等。
Is such a markup possible? Yep! But notice how quickly the spoofing happens. Instead of «the algorithm learns itself on the basis of GitHub» we are already discussing how to puzzle hundreds of people for a long time. The work and cost of creating the tool is increasing dramatically.
这样的标记可能吗? 是的 但是请注意欺骗发生的速度。 我们已经在讨论如何长时间困扰数百人,而不是“该算法是基于GitHub进行学习的”。 创建该工具的工作和成本急剧增加。
You can try to identify automatically where the bugs were fixed. To do this, you should analyze the comments to the commits, pay attention to small local edits, which most likely are those very bug fixes. It's hard to tell how well you can automatically search for error fixes. In any case, this is a big task that requires separate research and programming.
您可以尝试自动确定错误的修复位置。 为此,您应该分析对提交的注释,注意小的本地编辑,这很可能是那些非常小的错误修复。 很难说出您可以自动搜索错误修复的程度。 无论如何,这是一项艰巨的任务,需要单独的研究和编程。
So, we haven't even got to learning yet, and there are already nuances :).
因此,我们甚至还没有开始学习,并且已经有了细微差别:)。
第二个细微差别。 发展滞后。 (The second nuance. A lag in development.)
Analyzers that will learn based on such platforms, as GitHub will always be subject to such a syndrome, as «mental retardation delay». This is because programming languages change over time.
将基于GitHub等平台学习的分析人员将始终遭受“精神发育迟缓”这样的综合症。 这是因为编程语言会随着时间而变化。
Since C# 8.0 there have been Nullable Reference types, helping to fight against Null Reference Exceptions (NRE). In JDK 12, a new switch operator (JEP 325) appeared. In C++17, there is a possibility to perform compile-time conditional constructs (constexpr if). And so on.
由于C#8.0也已经被可空引用类型,有助于对空引用异常(NRE)战斗。 在JDK 12中,出现了一个新的切换运算符( JEP 325 )。 在C ++ 17中,有可能执行编译时条件构造( constexpr if )。 等等。
Programming languages are evolving. Moreover, the ones, like C++, develop very fast. New constructions appear, new standard functions are added and so on. Along with the new features, there are new error patterns that we would also like to identify with static code analysis.
编程语言在不断发展。 而且,像C ++这样的程序开发非常快。 出现新的结构,添加新的标准功能,等等。 除了新功能之外,我们还希望通过静态代码分析来识别新的错误模式。
At this point, the ML method faces a problem: the error pattern is already clear, we would like to detect it, but there no code base for learning.
此时,ML方法面临一个问题:错误模式已经很清楚,我们希望检测到它,但是没有学习的代码库。
Let's look at this problem using a particular example. Range-based for loop appeared in C++11. You can write the following code, traversing all elements in the container:
让我们用一个特定的例子来看这个问题。 基于范围的for循环出现在C ++ 11中。 您可以编写以下代码,遍历容器中的所有元素:
std::vector<int> numbers;
....
for (int num : numbers)foo(num);The new loop has brought the new error pattern with it. If we change the container inside the loop, this will lead to invalidation of «shadow» iterators.
新循环带来了新的错误模式。 如果我们在循环内更改容器,这将导致«shadow»迭代器失效。
Let's take a look at the following incorrect code:
让我们看一下下面的错误代码:
for (int num : numbers)
{numbers.push_back(num * 2);
}The compiler will turn it into something like this:
编译器会将其转换为以下内容:
for (auto __begin = begin(numbers), __end = end(numbers); __begin != __end; ++__begin) { int num = *__begin; numbers.push_back(num * 2);
}During push_back , __begin and __end iterators can be invalidated, if the memory is relocated inside the vector. The result will be the undefined behavior of the program.
在push_back期间,如果将内存重新放置在向量中,则__begin和__end迭代器可以无效。 结果将是程序的未定义行为。
Therefore, the error pattern has long been known and described in literature. The PVS-Studio analyzer diagnoses it with the V789 diagnostic and has already found real errors in open source projects.
因此,错误模式早已为人所知并在文献中有所描述。 PVS-Studio分析仪使用V789诊断程序对其进行诊断,并且已经在开源项目中发现了真正的错误 。
How soon will GitHub get enough new code to notice this pattern? Good question… It's important to bear in mind that if there is a range-based for loop, it doesn't mean that all programmers will immediately begin to use it at once. It may be years before there is a lot of code using the new loop. Moreover, many errors must be made, and then they must be fixed so that the algorithm can notice the pattern in the edits.
GitHub多久会获得足够的新代码来注意到这种模式? 一个好问题……要记住,如果有一个基于范围的for循环,那并不意味着所有程序员都会立即立即开始使用它。 使用新循环可能需要很多年的代码。 此外,必须犯许多错误,然后必须将其修复,以便算法可以注意到编辑中的模式。
How many years will it take? Five? Ten?
需要多少年? 五? 十?
Ten is too many, or is it a pessimistic prediction? Far from it. By the time the article was written, it had been eight years since a range-based for loop appeared in C++11. But so far in our database there are only three cases of such an error. Three errors is not much and not few. One should not draw any conclusion from this number. The main thing is to confirm that such an error pattern is real and it makes sense to detect it.
十个太多了,还是悲观的预测? 离得很远。 在撰写本文时,距离基于范围的for循环在C ++ 11中出现已有八年了。 但是到目前为止,在我们的数据库中,只有三种情况出现这种错误。 三个错误不是很多,也不是少数。 不应从这一数字得出任何结论。 最主要的是要确认这种错误模式是真实的,并且有必要进行检测。
Now compare this number, for example, with this error pattern: pointer gets dereferenced before the check. In total, we have already identified 1,716 such cases when checking open-source projects.
现在,例如,将此数字与以下错误模式进行比较: 指针在check之前被取消引用 。 在检查开源项目时,我们总共已经确定了1,716个此类案例。
Perhaps we shouldn't look for errors in range-based for loops at all? No. It's just that programmers are inertial, and this operator is becoming popular very slowly. Gradually, there will be both more code with it and errors, respectively.
也许我们根本不应该在基于范围的for循环中寻找错误? 不。只是程序员是惯性的,而此运算符的普及速度非常缓慢。 逐渐地,将分别有更多的代码和错误。
This is likely to happen only 10-15 years after the C++11 appeared. This leads to a philosophical question. Suppose we already know the error pattern, we'll just wait for many years until we have many errors in open source projects. Will it be so?
这很可能仅在C ++ 11出现10-15年后才发生。 这导致了一个哲学问题。 假设我们已经知道错误模式,我们将等很多年直到开源项目中出现很多错误。 会这样吗?
If «yes», it is safe to diagnose «mental development delay» for all ML based analyzers.
如果“是”,则可以安全地诊断所有基于ML的分析仪的“心理发育延迟”。
If «no», what should we do? There are no examples. Write them manually? But in this way, we get back to the previous chapter, where we've given a detailed description of the option when people would write a whole pack of examples for learning.
如果«否»,我们该怎么办? 没有例子。 手动写吗? 但是,通过这种方式,我们回到了上一章,在该章中,当人们编写一整套用于学习的示例时,我们对该选项进行了详细描述。
This can be done, but the question of expediency arises again. The implementation of the V789 diagnostic with all exceptions in the PVS-Studio analyzer takes only 118 lines of code, of which 13 lines are comments. That is, it is a very simple diagnostic, which can be easily programmed in a classic way.
可以做到,但是权宜之计再次出现。 在PVS-Studio分析仪中实施V789诊断的所有例外情况仅需要118行代码,其中13行是注释。 也就是说,这是一个非常简单的诊断程序,可以通过经典方式轻松进行编程。
The situation will be similar to any other innovations that appear in any other languages. As they say, there is something to think about.
这种情况将类似于以任何其他语言出现的任何其他创新。 正如他们所说,有些事情要考虑。
第三个细微差别。 文档。 (The third nuance. Documentation.)
An important component of any static analyzer is the documentation describing each diagnostic. Without it, it will be extremely difficult or impossible to use the analyzer. In PVS-Studio documentation, we have a description of each diagnostic, which gives an example of erroneous code and how to fix it. We also give the link to CWE, where one can read an alternative problem description. And still, sometimes users don't understand something, and they ask us clarifying questions.
任何静态分析仪的重要组成部分都是描述每种诊断的文档。 没有它,使用分析仪将非常困难或不可能。 在PVS-Studio 文档中 ,我们提供了每个诊断的描述,其中提供了错误代码及其修复方法的示例。 我们还提供了CWE的链接,您可以在其中阅读另一种问题描述。 而且,有时用户听不懂某些内容,他们问我们一些问题。
In the case of ML based static analyzers, the documentation issue is somehow hushed up. It is assumed that the analyzer will simply point to a place that seems suspicious to it and may even suggest how to fix it. The decision to make an edit or not is up to the person. That's where the trouble begins… It is not easy to make a decision without being able to read, which makes the analyzer seem suspicious of a particular place in the code.
对于基于ML的静态分析器,文档问题被以某种方式掩盖了。 假定分析仪将仅指向对其似乎可疑的地方,甚至可能会建议如何修复它。 是否进行编辑取决于个人。 麻烦就从那开始了。。。如果不阅读就很难做出决定,这使得分析仪似乎对代码中的特定位置产生了怀疑。
Of course, in some cases, everything will be obvious. Suppose the analyzer points to this code:
当然,在某些情况下,一切都会很明显。 假设分析器指向以下代码:
char *p = (char *)malloc(strlen(src + 1));
strcpy(p, src);And suggest that we replace it with:
并建议我们将其替换为:
char *p = (char *)malloc(strlen(src) + 1);
strcpy(p, src);It is immediately clear that the programmer made a typo and added 1 in the wrong place. As a result, less memory will be allocated than necessary.
显然,程序员打错了字并在错误的位置加了1。 结果,将分配比必要更少的内存。
Here it's all clear even without documentation. However, this will not always be the case.
即使没有文档,这里也很清楚。 但是,情况并非总是如此。
Imagine that the analyzer «silently» points to this code:
假设分析仪“静静地”指向以下代码:
char check(const uint8 *hash_stage2) {....return memcmp(hash_stage2, hash_stage2_reassured, SHA1_HASH_SIZE);
}And suggests that we change the char type of the return value for int:
并建议我们将返回值的char类型更改为int:
int check(const uint8 *hash_stage2) {....return memcmp(hash_stage2, hash_stage2_reassured, SHA1_HASH_SIZE);
}There is no documentation for the warning. Apparently, there won't be any text in the warning's message either, if we're talking about a completely independent analyzer.
没有用于警告的文档。 显然,如果我们谈论的是完全独立的分析仪,则警告消息中也不会包含任何文本。
What shall we do? What's the difference? Is it worth making such a replacement?
我们该怎么办? 有什么不同? 这样的替换值得吗?
Actually, I could take a chance and agree to fix the code. Although agreeing to fixes without understanding them is a cruddy practice… :) You can look into the description of the memcmp function and find out that the function really returns values like int: 0, more than zero and less than zero. But it may still be unclear why make edits, if the code is already working well.
实际上,我可以借此机会同意修复代码。 尽管在不了解修补程序的情况下同意进行修补是一种不明智的做法……:)您可以查看memcmp函数的描述,并发现该函数确实返回诸如int :0,大于零和小于零的值。 但是,如果代码已经运行良好,可能尚不清楚为什么要进行编辑。
Now, if you don't know what the edit is, check out the description of the V642 diagnostic. It immediately becomes clear that this is a real bug. Moreover, it can cause a vulnerability.
现在,如果您不知道编辑的内容,请查看V642诊断程序的描述。 显而易见,这是一个真正的错误。 而且,它可能导致漏洞。
Perhaps, the example seemed unconvincing. After all, the analyzer suggested a code that is likely to be better. Ok. Let's look at another example of pseudocode, this time, for a change, in Java.
也许,这个例子似乎令人信服。 毕竟,分析人员提出了可能更好的代码。 好。 这次,让我们看一下伪代码的另一个示例,以进行Java中的更改。
ObjectOutputStream out = new ObjectOutputStream(....);
SerializedObject obj = new SerializedObject();
obj.state = 100;
out.writeObject(obj);
obj.state = 200;
out.writeObject(obj);
out.close();There's an object. It's serializing. Then the state of the object changes, and it re-serializes. It looks fine. Now imagine that, all of a sudden, the analyzer doesn't like the code and it wants to replace it with the following:
有一个物体。 正在序列化。 然后,对象的状态更改,然后重新序列化。 看起来不错。 现在想象一下,分析器突然不喜欢该代码,并且希望将其替换为以下代码:
ObjectOutputStream out = new ObjectOutputStream(....);
SerializedObject obj = new SerializedObject();
obj.state = 100;
out.writeObject(obj);
obj = new SerializedObject(); // The line is added
obj.state = 200;
out.writeObject(obj);
out.close();Instead of changing the object and rewriting it, a new object is created and it will be serialized.
无需更改对象并重写它,而是创建一个新对象并将其序列化。
There is no description of the problem. No documentation. The code has become longer. For some reason, a new object is created. Are you ready to make such an edit in your code?
没有问题的描述。 没有文档。 代码变得更长了。 由于某种原因,将创建一个新对象。 您准备好在代码中进行这样的编辑了吗?
You'll say it's not clear. Indeed, it is incomprehensible. And it will be so all the time. Working with such a «silent» analyzer will be an endless study in an attempt to understand why the analyzer doesn't like anything.
您会说不清楚。 确实,这是无法理解的。 一直如此。 用这样的“静音”分析仪进行工作将是一项无休止的研究,旨在了解为什么分析仪不喜欢任何东西。
If there is documentation, everything becomes transparent. The class java.io.ObjectOuputStream that is used for serialization, caches the written objects. This means that the same object will not be serialized twice. The class serializes the object once, and the second time just writes in the stream a reference to the same first object. Read more: V6076 — Recurrent serialization will use cached object state from first serialization.
如果有文档,一切将变得透明。 用于序列化的类java.io.ObjectOuputStream缓存写入的对象。 这意味着同一对象不会被序列化两次。 该类一次将对象序列化,第二次仅将对同一第一个对象的引用写入流中。 : V6076 —循环序列化将使用第一次序列化中的缓存对象状态。
We hope we managed to explain the importance of documentation. Here comes the question. How will the documentation for the ML based analyzer appear?
我们希望我们能够解释文档的重要性。 问题来了。 基于ML的分析器的文档将如何显示?
When a classic code analyzer is developed, everything is simple and clear. There is a pattern of errors. We describe it in the documentation and implement the diagnostic.
当开发经典的代码分析器时,一切都变得简单明了。 有一种错误模式。 我们在文档中对其进行描述并实施诊断。
In the case of ML, the process is reverse. Yes, the analyzer can notice an anomaly in the code and point to it. But it knows nothing about the essence of the defect. It doesn't understand and won't tell you why you can't write code like that. These are too high-level abstractions. This way, the analyzer should also learn to read and
如果是ML,则过程相反。 是的,分析仪可以注意到代码中的异常并指向该异常。 但是它对缺陷的本质一无所知。 它不理解,也不会告诉您为什么不能编写这样的代码。 这些都是太高级的抽象。 这样,分析仪还应该学习阅读和
理解 (understand)
documentation for functions.
功能文档。
As I said, since the documentation issue is avoided in articles on machine learning, we are not ready to dwell on it further. Just another big nuance that we've spoken out.
如我所说,由于有关机器学习的文章中避免了文档问题,因此我们不准备进一步讨论它。 这只是我们所说的另一个细微差别。
注意。 (Note. )
You could argue that documentation is optional. The analyzer can refer to many examples of fixes on GitHub and the person, looking through the commits and comments to them, will understand what is what. Yes, it is so. But the idea doesn't look attractive. Here the analyzer is the bad dude, which will rather puzzle a programmer than help him.
您可能会认为文档是可选的。 分析人员可以参考GitHub上的许多修复示例,而该人员可以通过查看对它们的提交和注释来了解什么。 是的,是这样。 但是这个想法看起来并不吸引人。 分析器在这里是坏家伙,宁可让程序员困惑也不愿帮助他。
第四点细微差别。 高度专业的语言。 (Fourth nuance. Highly specialized languages.)
The approach described is not applicable to highly specialized languages, for which static analysis can also be extremely useful. The reason is that GitHub and other sources simply don't have a large enough source code base to provide effective learning.
所描述的方法不适用于高度专业化的语言,对于这些语言而言,静态分析也可能非常有用。 原因是GitHub和其他源代码根本没有足够大的源代码库来提供有效的学习。
Let's look at this using a concrete example. First, let's go to GitHub and search for repositories for the popular Java language.
我们来看一个具体的例子。 首先,让我们转到GitHub并搜索流行的Java语言的存储库。
Result: language:«Java»:
结果:语言:«Java»:
3,128,884 (3,128,884)
available repository results
可用的存储库结果
Now take the specialized language «1C Enterprise» used in accounting applications produced by the Russian company 1C.
现在采用俄罗斯1C公司生产的用于会计应用程序的专用语言“ 1C企业”。
Result: language:«1C Enterprise»:
结果:语言:«1C Enterprise»:
551 (551 )
available repository results
可用的存储库结果
Maybe analyzers are not needed for this language? No, they are. There is a practical need to analyze such programs and there are already appropriate analyzers. For example, there is SonarQube 1C (BSL) Plugin, produced by the company "Silver Bullet".
也许这种语言不需要分析器? 不,是他们。 实际需要分析此类程序,并且已经有合适的分析器。 例如,有由“ Silver Bullet ”公司生产的SonarQube 1C(BSL)插件。
I think no specific explanations are needed as to why ML approach will be difficult for specialized languages.
我认为,对于专用语言为何ML方法将变得困难,因此无需进行任何具体说明。
第五个细微差别。 C,C ++,#include (The fifth nuance. C, C++, #include)
.
。
Articles on ML-based static code analysis are mostly about such languages such as Java, JavaScript, and Python. This is explained by their extreme popularity. As for C and C++, they are kind of ignored, even though you can't call them unpopular.
有关基于ML的静态代码分析的文章主要涉及Java,JavaScript和Python等语言。 这是因为它们极受欢迎。 对于C和C ++,即使您不能称呼它们不受欢迎,它们也会被忽略。
We suggest that it's not about their popularity/promising outlook, but it's about the problems with C and C++ languages. And now we're going to bring one uncomfortable problem out to the light.
我们建议,这与它们的流行/前景无关,而与C和C ++语言的问题有关。 现在,我们要揭露一个令人不舒服的问题。
An abstract c/cpp file can be very difficult to compile. At least you can't load a project from GitHub, choose a random cpp file and just compile it. Now we will explain what all this has to do with ML.
抽象的c / cpp文件可能很难编译。 至少您不能从GitHub加载项目,选择随机的cpp文件并进行编译。 现在,我们将说明ML与这一切有关。
So we want to teach the analyzer. We downloaded a project from GitHub. We know the patch and assume it fixes the bug. We want this edit to be one example for learning. In other words, we have a .cpp file before and after editing.
因此,我们想教分析器。 我们从GitHub下载了一个项目。 我们知道该补丁,并假设它已修复该错误。 我们希望此编辑成为学习的一个例子。 换句话说,在编辑前后,我们都有一个.cpp文件。
That's where the problem begins. It's not enough just to study the fixes. Full context is also required. You need to know the declaration of the classes used, you need to know the prototypes of the functions used, you need to know how macros expand and so on. And to do this, you need to perform full file preprocessing.
这就是问题的开始。 仅研究修补程序是不够的。 还需要完整的上下文。 您需要了解所用类的声明,需要了解所用函数的原型,需要了解宏的扩展方式等等。 为此,您需要执行完整文件预处理 。
Let's look at the example. At first, the code looked like this:
让我们来看一个例子。 首先,代码如下所示:
bool Class::IsMagicWord()
{return m_name == "ML";
}It was fixed in this way:
它是这样固定的:
bool Class::IsMagicWord()
{return strcmp(m_name, "ML") == 0;
}Should the analyzer start learning in order to suggest (x == «y») replacement forstrcmp(x, «y»)?
分析仪是否应该开始学习以便建议(x ==«y»)替换strcmp(x,«y»)?
You can't answer that question without knowing how the m_name member is declared in the class. There might be, for example, such options:
如果不知道如何在类中声明m_name成员,就无法回答该问题。 例如,可能有以下选项:
class Class {....char *m_name;
};
class Class {....std::string m_name;
};Edits will be made in case if we're talking about an ordinary pointer. If we don't take into account the variable type, the analyzer might learn to issue both good and bad warnings (for the case with std::string).
如果我们在谈论普通指针,将进行编辑。 如果我们不考虑变量类型,则分析器可能会学会发出良好和不良警告(对于std :: string而言 )。
Class declarations are usually located in header files. Here were face the need to perform preprocessing to have all necessary information. It's extremely important for C and C++.
类声明通常位于头文件中。 这里面临着执行预处理以获取所有必要信息的需求。 这对于C和C ++极为重要。
If someone says that it is possible to do without preprocessing, he is either a fraud, or is just unfamiliar with C or C++ languages.
如果有人说不用预处理就可以做,那么他要么是骗子,要么就是不熟悉C或C ++语言。
To gather all the necessary information, you need correct preprocessing. To do this, you need to know where and what header files are located, which macros are set during the build process. You also need to know how a particular cpp file is compiled.
要收集所有必要的信息,您需要正确的预处理。 为此,您需要知道什么位置以及什么头文件位于何处,以及在构建过程中设置了哪些宏。 您还需要知道如何编译特定的cpp文件。
That's the problem. One doesn't simply compile the file (or, rather, specify the key to the compiler so that it generates a preprocess file). We need to figure out how this file is compiled. This information is in the build scripts, but the question is how to get it from there. In general, the task is complicated.
那就是问题所在。 一个人不只是编译文件(或者,指定编译器的键,以便它生成预处理文件)。 我们需要弄清楚该文件是如何编译的。 该信息在构建脚本中,但是问题是如何从那里获取信息。 通常,任务很复杂。

Moreover, many projects on GitHub are a mess. If you take an abstract project from there, you often have to tinker to compile it. One day you lack a library and you need to find and download it manually. Another day some kind of a self-written build system is used, which has to be dealt with. It could be anything. Sometimes the downloaded project simply refuses to build and it needs to be somehow tweaked. You can't just take and automatically get preprocessed (.i) representation for .cpp files. It can be tricky even when doing it manually.
而且,GitHub上的许多项目都是一团糟。 如果您从那里进行一个抽象项目,则通常必须进行修补才能对其进行编译。 有一天,您缺少图书馆,需要手动查找和下载。 改天使用某种自写的构建系统,必须对其进行处理。 可能是任何东西。 Sometimes the downloaded project simply refuses to build and it needs to be somehow tweaked. You can't just take and automatically get preprocessed (.i) representation for .cpp files. It can be tricky even when doing it manually.
We can say, well, the problem with non-building projects is understandable, but not crucial. Let's only work with projects that can be built. There is still the task of preprocessing a particular file. Not to mention the cases when we deal with some specialized compilers, for example, for embedded systems.
We can say, well, the problem with non-building projects is understandable, but not crucial. Let's only work with projects that can be built. There is still the task of preprocessing a particular file. Not to mention the cases when we deal with some specialized compilers, for example, for embedded systems.
After all, the problem described is not insurmountable. However, all this is very difficult and labor-intensive. In case of C and C++, source code located on GitHub does nothing. There's a lot of work to be done to learn how to automatically run compilers.
After all, the problem described is not insurmountable. However, all this is very difficult and labor-intensive. In case of C and C++, source code located on GitHub does nothing. There's a lot of work to be done to learn how to automatically run compilers.
注意。 (Note. )
If the reader still doesn't get the depth of the problem, we invite you to take part in the following experiment. Take ten mid-sized random projects from GitHub and try to compile them and then get their preprocessed version for .cpp files. After that, the question about the laboriousness of this task will disappear :).
If the reader still doesn't get the depth of the problem, we invite you to take part in the following experiment. Take ten mid-sized random projects from GitHub and try to compile them and then get their preprocessed version for .cpp files. After that, the question about the laboriousness of this task will disappear :).
There may be similar problems with other languages, but they are particularly obvious in C and C++.
There may be similar problems with other languages, but they are particularly obvious in C and C++.
Sixth nuance. The price of eliminating false positives. (Sixth nuance. The price of eliminating false positives.)
Static analyzers are prone to generating false positives and we have to constantly refine diagnostics to reduce the number of false warnings.
Static analyzers are prone to generating false positives and we have to constantly refine diagnostics to reduce the number of false warnings.
Now we'll get back to the previously considered V789 diagnostic, detecting container changes inside the range-based for loop. Let's say we weren't careful enough when writing it, and the client reports a false positive. He writes that the analyzer doesn't take into account the scenario when the loop ends after the container is changed, and therefore there is no problem. Then he gives the following example of code where the analyzer gives a false positive:
Now we'll get back to the previously considered V789 diagnostic, detecting container changes inside the range-based for loop. Let's say we weren't careful enough when writing it, and the client reports a false positive. He writes that the analyzer doesn't take into account the scenario when the loop ends after the container is changed, and therefore there is no problem. Then he gives the following example of code where the analyzer gives a false positive:
std::vector<int> numbers;
....
for (int num : numbers)
{if (num < 5){numbers.push_back(0);break; // or, for example, return}
}Yes, it's a flaw. In a classic analyzer, its elimination is extremely fast and cheap. In PVS-Studio, the implementation of this exception consists of 26 lines of code.
Yes, it's a flaw. In a classic analyzer, its elimination is extremely fast and cheap. In PVS-Studio, the implementation of this exception consists of 26 lines of code.
This flaw can also be corrected when the analyzer is built on learning algorithms. For sure, it can be taught by collecting dozens or hundreds of examples of code that should be considered correct.
This flaw can also be corrected when the analyzer is built on learning algorithms. For sure, it can be taught by collecting dozens or hundreds of examples of code that should be considered correct.
Again, the question is not in feasibility, but in practical approach. We suspect that fighting against specific false positives, which bother clients, is far more costly in case of ML. That is, customer support in terms of eliminating false positives will cost more money.
Again, the question is not in feasibility, but in practical approach. We suspect that fighting against specific false positives, which bother clients, is far more costly in case of ML. That is, customer support in terms of eliminating false positives will cost more money.
Seventh nuance. Rarely used features and long tail. (Seventh nuance. Rarely used features and long tail.)
Previously, we've grappled with the problem of highly specialized languages, for which may not be enough source code for learning. A similar problem takes place with rarely used functions (system ones, WinAPI, from popular libraries, etc.).
Previously, we've grappled with the problem of highly specialized languages, for which may not be enough source code for learning. A similar problem takes place with rarely used functions (system ones, WinAPI, from popular libraries, etc.).
If we're talking about such functions from the C language, as strcmp, then there is actually a base for learning. GitHub, available code results:
If we're talking about such functions from the C language, as strcmp , then there is actually a base for learning. GitHub, available code results:
- strcmp — 40,462,158
strcmp — 40,462,158 - stricmp — 1,256,053
stricmp — 1,256,053
Yes, there are many examples of usage. Perhaps the analyzer will learn to notice, for example, the following patterns:
Yes, there are many examples of usage. Perhaps the analyzer will learn to notice, for example, the following patterns:
- It is strange if the string is compared with itself. It gets fixed.
It is strange if the string is compared with itself. It gets fixed. - It's strange if one of the pointers is NULL. It gets fixed.
It's strange if one of the pointers is NULL. It gets fixed. - It is strange that the result of this function is not used. It gets fixed.
It is strange that the result of this function is not used. It gets fixed. - And so on.
等等。
Isn't it cool? No. Here we face the «long tail» problem. Very briefly the point of the «long tail» in the following. It is impractical to sell only the Top50 of the most popular and now-read books in a bookstore. Yes, each such book will be purchased, say, 100 times more often than books not from this list. However, most of the proceeds will be made up of other books that, as they say, find their reader. For example, an online store Amazon.com receives more than half of the profits from what is outside of 130,000 «most popular items».
是不是很酷? No. Here we face the «long tail» problem. Very briefly the point of the «long tail» in the following. It is impractical to sell only the Top50 of the most popular and now-read books in a bookstore. Yes, each such book will be purchased, say, 100 times more often than books not from this list. However, most of the proceeds will be made up of other books that, as they say, find their reader. For example, an online store Amazon.com receives more than half of the profits from what is outside of 130,000 «most popular items».
There are popular functions and there are few of them. There are unpopular, but there are many of them. For example, there are the following variations of the string comparison function:
There are popular functions and there are few of them. There are unpopular, but there are many of them. For example, there are the following variations of the string comparison function:
- g_ascii_strncasecmp — 35,695
g_ascii_strncasecmp — 35,695 - lstrcmpiA — 27,512
lstrcmpiA — 27,512 - _wcsicmp_l — 5,737
_wcsicmp_l — 5,737 - _strnicmp_l — 5,848
_strnicmp_l — 5,848 - _mbscmp_l — 2,458
_mbscmp_l — 2,458 - and others.
和别的。
As you can see, they are used much less frequently, but when you use them, you can make the same mistakes. There are too few examples to identify patterns. However, these functions can't be ignored. Individually, they are rarely used, but a lot of code is written with their use, which is better be checked. That's where the «long tail» shows itself.
As you can see, they are used much less frequently, but when you use them, you can make the same mistakes. There are too few examples to identify patterns. However, these functions can't be ignored. Individually, they are rarely used, but a lot of code is written with their use, which is better be checked. That's where the «long tail» shows itself.
At PVS-Studio, we manually annotate features. For example, by the moment about 7,200 functions had been annotated for C and C++. This is what we mark:
At PVS-Studio, we manually annotate features. For example, by the moment about 7,200 functions had been annotated for C and C++. This is what we mark:
- WinAPI
WinAPI - Standard C Library ,
Standard C Library , - Standard Template Library (STL),
Standard Template Library (STL), - glibc (GNU C Library)
glibc (GNU C Library) - Qt
Qt - MFC
MFC - zlib
zlib - libpng
libpng - OpenSSL
OpenSSL - and others.
和别的。
On the one hand, it seems like a dead-end way. You can't annotate everything. On the other hand, it works.
On the one hand, it seems like a dead-end way. You can't annotate everything. On the other hand, it works.
Now here is the question. What benefits can ML have? Significant advantages aren't that obvious, but you can see the complexity.
Now here is the question. What benefits can ML have? Significant advantages aren't that obvious, but you can see the complexity.
You could argue that algorithms built on ML themselves will find patterns with frequently used functions and they don't have to be annotated. Yes, it's true. However, there is no problem to independently annotate such popular functions as strcmp or malloc.
You could argue that algorithms built on ML themselves will find patterns with frequently used functions and they don't have to be annotated. 对,是真的。 However, there is no problem to independently annotate such popular functions as strcmp or malloc .
Nonetheless, the long tail causes problems. You can teach by making synthetic examples. However, here we go back to the article part, where we were saying that it was easier and faster to write classic diagnostics, rather than generate many examples.
Nonetheless, the long tail causes problems. You can teach by making synthetic examples. However, here we go back to the article part, where we were saying that it was easier and faster to write classic diagnostics, rather than generate many examples.
Take for example a function, such as _fread_nolock . Of course, it is used less frequently than fread. But when you use it, you can make the same mistakes. For example, the buffer should be large enough. This size should be no less than the result of multiplying the second and third argument. That is, you want to find such incorrect code:
Take for example a function, such as _fread_nolock . Of course, it is used less frequently than fread . But when you use it, you can make the same mistakes. For example, the buffer should be large enough. This size should be no less than the result of multiplying the second and third argument. That is, you want to find such incorrect code:
int buffer[10];
size_t n = _fread_nolock(buffer, size_of(int), 100, stream);Here's what the annotation of this function looks like in PVS-Studio:
Here's what the annotation of this function looks like in PVS-Studio:
C_"size_t _fread_nolock""(void * _DstBuf, size_t _ElementSize, size_t _Count, FILE * _File);"
ADD(HAVE_STATE | RET_SKIP | F_MODIFY_PTR_1,nullptr, nullptr, "_fread_nolock", POINTER_1, BYTE_COUNT, COUNT,POINTER_2).Add_Read(from_2_3, to_return, buf_1).Add_DataSafetyStatusRelations(0, 3);At first glance, such annotation may look difficult, but in fact, when you start writing them, it becomes simple. Plus, it's write-only code. Wrote and forgot. Annotations change rarely.
At first glance, such annotation may look difficult, but in fact, when you start writing them, it becomes simple. Plus, it's write-only code. Wrote and forgot. Annotations change rarely.
Now let's talk about this function from the point of view of ML. GitHub won't help us. There are about 15,000 mentions of this function. There's even less good code. A significant part of the search results takes up the following:
Now let's talk about this function from the point of view of ML. GitHub won't help us. There are about 15,000 mentions of this function. There's even less good code. A significant part of the search results takes up the following:
#define fread_unlocked _fread_nolockWhat are the options?
What are the options?
- Don't do anything. It's a way to nowhere.
Don't do anything. It's a way to nowhere. - Just imagine, teach the analyzer by writing hundreds of examples just for one function so that the analyzer understands the interconnection between the buffer and oher arguments. Yes, you can do that, but it's economically irrational. It's a dead-end street.
Just imagine, teach the analyzer by writing hundreds of examples just for one function so that the analyzer understands the interconnection between the buffer and oher arguments. Yes, you can do that, but it's economically irrational. It's a dead-end street. - You can come up with a way similar to ours when the annotations to functions will be set manually. It's a good, sensible way. That's just ML, which has nothing to do with it :). This is a throwback to the classic way of writing static analyzers.
You can come up with a way similar to ours when the annotations to functions will be set manually. It's a good, sensible way. That's just ML, which has nothing to do with it :). This is a throwback to the classic way of writing static analyzers.
As you can see, ML and the long tail of the rarely used features don't go together.
As you can see, ML and the long tail of the rarely used features don't go together.
At this point, there were people related to ML who objected and said that we hadn't taken into account the option when the analyzer would learn all functions and make conclusions of what they were doing. Here, apparently, either we don't understand the experts, or they don't get our point.
At this point, there were people related to ML who objected and said that we hadn't taken into account the option when the analyzer would learn all functions and make conclusions of what they were doing. Here, apparently, either we don't understand the experts, or they don't get our point.
Bodies of functions may be unknown. For example, it could be a WinAPI-related function. If this is a rarely used function, how will the analyzer understand what it is doing? We can fantasize that the analyzer will use Google itself, find a description of the function, read and
Bodies of functions may be unknown. For example, it could be a WinAPI-related function. If this is a rarely used function, how will the analyzer understand what it is doing? We can fantasize that the analyzer will use Google itself, find a description of the function, read and
understand it (understand it)
. Moreover, it would have to draw high-level conclusions from the documentation. The
。 Moreover, it would have to draw high-level conclusions from the documentation. 的
_fread_nolock_fread_nolock
Bodies of functions may be available, but there may be no use from this. Let's look at a function, such as memmove. It is often implemented in something like this:
Bodies of functions may be available, but there may be no use from this. Let's look at a function, such as memmove . It is often implemented in something like this:
void *memmove (void *dest, const void *src, size_t len) {return __builtin___memmove_chk(dest, src, len, __builtin_object_size(dest, 0));
}What is __builtin___memmove_chk? This is an intrinsic function that the compiler itself is already implementing. This function doesn't have the source code.
What is __builtin___memmove_chk ? This is an intrinsic function that the compiler itself is already implementing. This function doesn't have the source code.
Or memmove might look something like this: the first assembly version. You can teach the analyzer to understand different assembly options, but such approach seems wrong.
Or memmove might look something like this: the first assembly version . You can teach the analyzer to understand different assembly options, but such approach seems wrong.
Ok, sometimes bodies of functions are really known. Moreover, we know bodies of functions in user's code as well. It would seem that in this case ML gets enormous advantages by reading and understanding what all these functions do.
Ok, sometimes bodies of functions are really known. Moreover, we know bodies of functions in user's code as well. It would seem that in this case ML gets enormous advantages by reading and understanding what all these functions do.
However, even in this case we are full of pessimism. This task is too complex. It's complicated even for a human. Think of how hard it is for you to understand the code you didn't write. If it is difficult for a person, why should this task be easy for an AI? Actually, AI has a big problem in understanding high-level concepts. If we are talking about understanding the code, we can't do without the ability to abstract from the details of implementation and consider the algorithm at a high level. It seems that this discussion can be postponed for 20 years as well.
However, even in this case we are full of pessimism. This task is too complex. It's complicated even for a human. Think of how hard it is for you to understand the code you didn't write. If it is difficult for a person, why should this task be easy for an AI? Actually, AI has a big problem in understanding high-level concepts. If we are talking about understanding the code, we can't do without the ability to abstract from the details of implementation and consider the algorithm at a high level. It seems that this discussion can be postponed for 20 years as well.
Other nuances (Other nuances)
There are other points that should also be taken into account, but we haven't gone deep into them. By the way, the article turns out to be quite long. Therefore, we will briefly list some other nuances, leaving them for reader's reflection.
There are other points that should also be taken into account, but we haven't gone deep into them. By the way, the article turns out to be quite long. Therefore, we will briefly list some other nuances, leaving them for reader's reflection.
Outdated recommendations. (Outdated recommendations.)
As mentioned, languages change, and recommendations for their use change, respectively. If the analyzer learns on old source code, it might start issuing outdated recommendations at some point. Example. Formerly, C++ programmers have been recommended using
As mentioned, languages change, and recommendations for their use change, respectively. If the analyzer learns on old source code, it might start issuing outdated recommendations at some point. 例。 Formerly, C++ programmers have been recommended using
auto_ptrauto_ptrunique_ptr.unique_ptr .
Data models. (Data models.)
At the very least, C and C++ languages have such a thing as a
At the very least, C and C++ languages have such a thing as a
data model. This means that data types have different number of bits across platforms. If you don't take this into account, you can incorrectly teach the analyzer. For example, in Windows 32/64 the data model . This means that data types have different number of bits across platforms. If you don't take this into account, you can incorrectly teach the analyzer. For example, in Windows 32/64 the long type always has 32 bits. But in Linux, its size will vary and take 32/64 bits depending on the platform's number of bits. Without taking all this into account, the analyzer can learn to miscalculate the size of the types and structures it forms. But the types also align in different ways. All this, of course, can be taken into account. You can teach the analyzer to know about the size of the types, their alignment and mark the projects (indicate how they are building). However, all this is an additional complexity, which is not mentioned in the research articles. long type always has 32 bits. 但是在Linux中,它的大小会有所不同,并且需要32/64位,具体取决于平台的位数。 在不考虑所有这些因素的情况下,分析器可能会学会错误地计算其形成的类型和结构的大小。 但是类型也以不同的方式对齐。 当然,所有这些都可以考虑在内。 您可以教分析器了解类型的大小,它们的对齐方式并标记项目(指示它们的构建方式)。 但是,所有这些都是额外的复杂性,研究文章中没有提到。
Behavioral unambiguousness. (Behavioral unambiguousness.)
Since we're talking about ML, the analysis result is more likely to have probabilistic nature. That is, sometimes the erroneous pattern will be recognized, and sometimes not, depending on how the code is written. From our experience, we know that the user is extremely irritated by the ambiguity of the analyzer's behavior. He wants to know exactly which pattern will be considered erroneous and which will not, and why. In the case of the classical analyzer developing approach, this problem is poorly expressed. Only sometimes we need to explain our clients why there is a/there is no analyzer warning and how the algorithm works, what exceptions are handled in it. Algorithms are clear and everything can always be easily explained. An example of this kind of communication: "
Since we're talking about ML, the analysis result is more likely to have probabilistic nature. That is, sometimes the erroneous pattern will be recognized, and sometimes not, depending on how the code is written. From our experience, we know that the user is extremely irritated by the ambiguity of the analyzer's behavior. He wants to know exactly which pattern will be considered erroneous and which will not, and why. In the case of the classical analyzer developing approach, this problem is poorly expressed. Only sometimes we need to explain our clients why there is a/there is no analyzer warning and how the algorithm works, what exceptions are handled in it. Algorithms are clear and everything can always be easily explained. An example of this kind of communication: "
False Positives in PVS-Studio: How Deep the Rabbit Hole Goes". It's not clear how the described problem will be solved in the analyzers built on ML.False Positives in PVS-Studio: How Deep the Rabbit Hole Goes ". It's not clear how the described problem will be solved in the analyzers built on ML.
结论 (Conclusions)
We don't deny the prospects of the ML direction, including its application in terms of static code analysis. ML can be potentially used in typos finding tasks, when filtering false positives, when searching for new (not yet described) error patterns and so on. However, we don't share the optimism that permeates the articles devoted to ML in terms of code analysis.
We don't deny the prospects of the ML direction, including its application in terms of static code analysis. ML can be potentially used in typos finding tasks, when filtering false positives, when searching for new (not yet described) error patterns and so on. However, we don't share the optimism that permeates the articles devoted to ML in terms of code analysis.
In this article, we've outlined a few issues that one will have to work on if he's going to use ML. The described nuances largely negate the benefits of the new approach. In addition, the old classical approaches of analyzers implementation are more profitable and more economically feasible.
In this article, we've outlined a few issues that one will have to work on if he's going to use ML. The described nuances largely negate the benefits of the new approach. In addition, the old classical approaches of analyzers implementation are more profitable and more economically feasible.
Interestingly, the adherents' articles of the ML methodology don't mention these pitfalls. Well, nothing new. ML is provokes certain hype and probably we shouldn't expect balanced assessment from its apologists concerning ML applicability in static code analysis tasks.
Interestingly, the adherents' articles of the ML methodology don't mention these pitfalls. Well, nothing new. ML is provokes certain hype and probably we shouldn't expect balanced assessment from its apologists concerning ML applicability in static code analysis tasks.
From our point of view, machine learning will fill a niche in technologies, used in static analyzers along with control flow analysis, symbolic executions and others.
From our point of view, machine learning will fill a niche in technologies, used in static analyzers along with control flow analysis, symbolic executions and others.
The methodology of static analysis may benefit from the introduction of ML, but don't exaggerate the possibilities of this technology.
The methodology of static analysis may benefit from the introduction of ML, but don't exaggerate the possibilities of this technology.
聚苯乙烯 (P.S.)
Since the article is generally critical, some might think that we fear the new and as Luddites turned against ML for fear of losing the market for static analysis tools.
Since the article is generally critical, some might think that we fear the new and as Luddites turned against ML for fear of losing the market for static analysis tools.

No, we're not afraid. We just don't see the point in spending money on inefficient approaches in the development of the PVS-Studio code analyzer. In one form or another, we will adopt ML. Moreover, some diagnostics already contain elements of self-learning algorithms. However, we will definitely be very conservative and take only what will clearly have a greater effect than the classic approaches, built on loops and ifs :). After all, we need to create an effective tool, not work off a grant :).
No, we're not afraid. We just don't see the point in spending money on inefficient approaches in the development of the PVS-Studio code analyzer. In one form or another, we will adopt ML. Moreover, some diagnostics already contain elements of self-learning algorithms. However, we will definitely be very conservative and take only what will clearly have a greater effect than the classic approaches, built on loops and ifs :). After all, we need to create an effective tool, not work off a grant :).
The article is written for the reason that more and more questions are asked on the topic and we wanted to have an expository article that puts everything in its place.
The article is written for the reason that more and more questions are asked on the topic and we wanted to have an expository article that puts everything in its place.
Thank you for your attention. We invite you to read the article "Why You Should Choose the PVS-Studio Static Analyzer to Integrate into Your Development Process".
感谢您的关注。 We invite you to read the article " Why You Should Choose the PVS-Studio Static Analyzer to Integrate into Your Development Process ".
翻译自: https://habr.com/en/company/pvs-studio/blog/484202/
机器学习源代码
机器学习源代码_机器学习中程序源代码的静态分析相关推荐
- 机器学习 可视化_机器学习-可视化
机器学习 可视化 机器学习导论 (Introduction to machine learning) In the traditional hard-coded approach, we progra ...
- 汽车BCM程序源代码,国产车BCM程序源代码, 喜好汽车电路 控制系统研究的值得入手。
汽车BCM程序源代码,国产车BCM程序源代码, 喜好汽车电路 控制系统研究的值得入手. ♦ 外部灯光:前照灯.小灯.转向灯.前后雾灯.日间行车灯.倒车灯.制动灯.角灯.泊车灯等 ♦ 内部灯光:顶灯.钥 ...
- 机器学习:分类_机器学习基础:K最近邻居分类
机器学习:分类 In the previous stories, I had given an explanation of the program for implementation of var ...
- 机器学习指南_机器学习-快速指南
机器学习指南 机器学习-快速指南 (Machine Learning - Quick Guide) 机器学习-简介 (Machine Learning - Introduction) Today's ...
- python小程序源代码-Python数据库小程序源代码
源代码: # dict1 是 字典 , 用来对应相应元素的下标,我们将文件转成列表,对应的也就是文件的下标,通过下标来找文件元素 dict1 = {'sort':0 , 'name':1 ,'age' ...
- 机器学习 导论_机器学习导论
机器学习 导论 什么是机器学习? (What is Machine Learning?) Machine learning can be vaguely defined as a computers ...
- python完整程序源代码_Python数据库小程序源代码
源代码: # dict1 是 字典 , 用来对应相应元素的下标,我们将文件转成列表,对应的也就是文件的下标,通过下标来找文件元素 dict1 = {'sort':0 , 'name':1 ,'age' ...
- 机器学习算法_机器学习算法中分类知识总结!
↑↑↑关注后"星标"Datawhale每日干货 & 每月组队学习,不错过Datawhale干货 译者:张峰,Datawhale成员 本文将介绍机器学习算法中非常重要的知识- ...
- sql机器学习服务_机器学习服务–在SQL Server中配置R服务
sql机器学习服务 The R language is one of the most popular languages for data science, machine learning ser ...
- 机器学习指南_机器学习项目的研究指南
机器学习指南 Machine Learning projects can be delivered in two stages. The first stage is named Research a ...
最新文章
- android gravity和layout_gravity区别
- 手机端网页中图片之间出现白线的解决方法
- AI算法透明不是必须,黑箱和可解释性可简化为优化问题
- 《Java和Android开发实战详解》——2.5节良好的Java程序代码编写风格
- iOS,macOS,darwin,unix 简介
- JavaScript学习笔记-JSON对象
- Java Signal实例
- VSCode remote-ssh插件报错“拒绝连接“
- ADO.NET常用对象详解之:DataAdapter对象
- Darwin Streaming Server 安装流程
- java 单词倒序_【Java】单词倒序输出
- 驱动库分享整理(1)——用于单片机中的小巧多功能按键支持库
- 实现LAYERED窗口
- idea保存快捷键_windows10下idea快捷键文件
- 从阿里云迁移域名至 Amazon Route 53 帮你了解域名迁移
- Caffe windows下安装攻略
- 生物信息小知识_1_reads.contigs.scaffolds...
- Gos —— 掌控硬盘
- 怎么下载优酷视频呢,你可以这样下
- 配置数据源的三种方法