R语言聚类算法的应用实例
一家批发经销商想将发货方式从每周五次减少到每周三次,简称成本,但是造成一些客户的不满意,取消了提货,带来更大亏损,项目要求是通过分析客户类别,选择合适的发货方式,达到技能降低成本又能降低客户不满意度的目的。
什么是聚类
聚类将相似的对象归到同一个簇中,几乎可以应用于所有对象,聚类的对象越相似,聚类效果越好。聚类与分类的不同之处在于分类预先知道所分的类到底是什么,而聚类则预先不知道目标,但是可以通过簇识别(cluster identification)告诉我们这些簇到底都是什么。
K-means
聚类的一种,之所以叫k-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。簇个数k是用户给定的,每一个簇通过质心来描述。
k-means的工作流程是:
- 随机确定k个初始点做为质心
- 给数据集中的每个点找距其最近的质心,并分配到该簇
- 将每个簇的质心更新为该簇所有点的平均值
- 循环上两部,直到每个点的簇分配结果不在改变为止
项目流程 载入数据集 import pandas as pd data = pd.read_csv("customers.csv"); 分析数据
显示数据的一个描述
from IPython.display import display display(data.discrie());
分析数据是一门学问,感觉自己在这方面还需要多加练习,数据描述包含数据总数,特征,每个特征的均值,标准差,还有最小值、25%、50%、75%、最大值处的值,这些都可以很容易列出来,但是透过这些数据需要看到什么信息,如何与需求目的结合,最开始还是比较吃力的。可以先选择几个数值差异较大的样本,然后结合数据描述和需求,对数据整体有一个把控。比如在Udacity的第三个项目中,给出客户针对不同类型产品的年度采购额,分析猜测每个样本客户的类型。
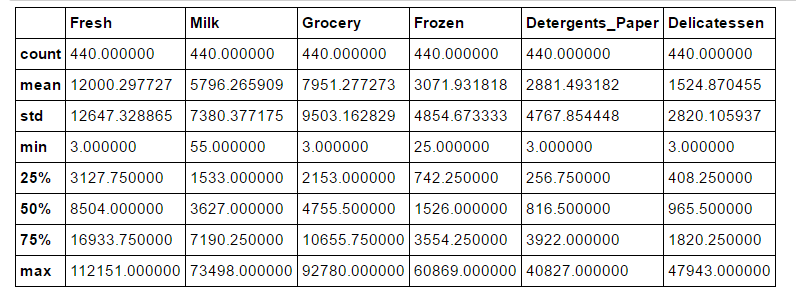
数据描述
三个样本客户
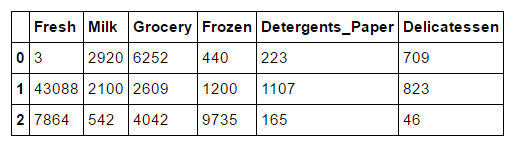
样本客户
每个客户究竟是什么类型,这个问题困扰我好久,第一次回答我只是看那个方面采购额最大,就给它一个最近的类型,提交项目后Reviewer这样建议:
恍然大悟,这才知道了该如何分析一份数据集,于是有了下面的回答

回答
所以分析数据一定要结合统计数据,四分位数和均值可以看做数据的骨架,能够一定程度勾勒出数据的分布,可以通过箱线图来可视化四分位数。
分析特征相关性
特征之间通常都有相关性,可以通过用移除某个特征后的数据集构建一个监督学习模型,用其余特征预测移除的特征,对结果进行评分的方法来判断特征间的相关性。比如用决策树回归模型和R2分数来判断某个特征是否必要。
如果是负数,说明该特征绝对不能少,因为缺少了就无法拟合数据。如果是1,表示少了也无所谓,有一个跟它相关联的特征能代替它,如果是0到1间的其他数,则可以少,只是有一定的影响,越靠近0,影响越大。
也可以通过散布矩阵(scatter matrix)来可视化特征分布,如果一个特征是必须的,则它和其他特征可能不会显示任何关系,如果不是必须的,则可能和某个特征呈线性或其他关系。
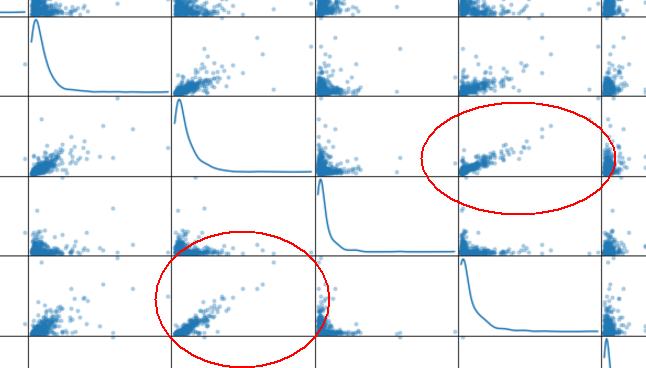
散布矩阵图举例
数据预处理
(一)特征缩放如果数据特征呈偏态分布,通常进行非线性缩放。
可以发现散布矩阵变成了下图
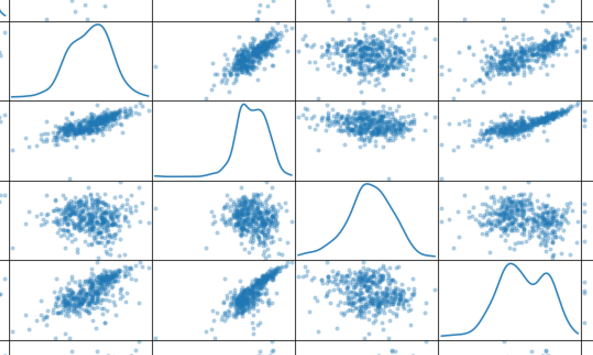
特征缩放后的散布矩阵
(二)异常值检测通常用Tukey的定义异常值的方法检测异常值。
移除异常值需要具体情况具体考虑,但是要谨慎,因为我们需要充分理解数据,记录号移除的点以及移除原因。可以用counter来辅助寻找出现次数大于1的离群点。
(三)特征转换特征转换主要用到主成分分析发,请查看之前介绍。
聚类
有些问题的聚类数目可能是已知的,但是我们并不能保证某个聚类的数目对这个数据是最优的,因为我们对数据的结构是不清楚的。但是我们可以通过计算每一个簇中点的轮廓系数来衡量聚类的质量。数据点的轮廓系数衡量了分配给它的簇的相似度,范围-1(不相似)到1(相似)。平均轮廓系数为我们提供了一种简单地度量聚类质量的方法。下面代码会显示聚类数为2时的平均轮廓系数,可以修改n_clusters来得到不同聚类数目下的平均轮廓系数。
▍需要帮助?联系我们
转载于:https://www.cnblogs.com/tecdat/p/9518514.html
R语言聚类算法的应用实例相关推荐
- R语言聚类算法之期望最大化聚类(Expectation Maximization Algorithm)
1.原理解析: 它将数据集看作一个含有隐性变量的概率模型,并以实现模型最优化,即获取与数据本身性质最契合的聚类方式为目的,通过"反复估计"模型参数找到最优解,同时给出相应的最优类别 ...
- R语言聚类算法之k中心聚类(K-medoids)
1.原理解析: 针对K-均值算法易受极值影响这一缺点的改进算法.在原理上的差异在于选择个类别中心点时不取样本均值点,而在类别内选取到其余样本距离之和最小的样本为中心. 2.在R语言中的应用 k中心聚类 ...
- R语言聚类算法之密度聚类(Density-based Methods)
1.原理解析: 1.从数据集中选择一个未处理的样本点 2.以1为圆心,做半径为E的圆,由于圆内圈入点的个数为3,满足密度阈值Minpts,因此称点1为核心对象(黑色实心圆点),且将圈内的4个点形成一个 ...
- R语言聚类算法之系谱聚类(Hierarchical Method)
1.原理解析: 不需要先设定类别数K,这是因为它每次迭代过程仅将距离最近的两个样本/簇聚为一类,其运作过程将自然得到k=1至k=n个类别的聚类结果. 2.在R语言中的应用 系谱聚类(Hierarchi ...
- R语言聚类算法之k均值聚类(K-means)
1.原理解析: 随机选取k(预设类别数)个样本作为起始中心点,将其余样本归入相似度最高中心点所在簇(cluster),再确立当前簇中样本坐标的均值为新的中心点,一次循环迭代下去,直至所有样本所属类别不 ...
- 【机器学习】R语言进行机器学习方法及实例
R语言进行机器学习方法及实例 机器学习的研究领域是发明计算机算法,把数据转变为智能行为.机器学习和数据挖掘的区别可能是机器学习侧重于执行一个已知的任务,而数据发掘是在大数据中寻找有价值的东西. 机器学 ...
- R语言数据分析、展现与实例(02)
R语言数据分析.展现与实例(02) 数据输入 > mydata <- data.frame(age=numeric(0),gender=character(0),weight=numeri ...
- R语言apriori算法进行关联规则挖掘(限制规则的左侧或者右侧的内容进行具体规则挖掘)、使用subset函数进一步筛选生成的规则去除左侧规则中的冗余信息、获取更独特的有新意的关联规则
R语言apriori算法进行关联规则挖掘(限制规则的左侧或者右侧的内容进行具体规则挖掘).使用subset函数进一步筛选生成的规则去除左侧规则中的冗余信息.获取更独特的有新意的关联规则 目录
- R语言apriori算法进行关联规则挖掘(限制规则的左侧或者右侧的内容进行具体规则挖掘)、查看限制了规则的右侧之后挖掘到的规则(置信度排序,只查看左侧即可)
R语言apriori算法进行关联规则挖掘(限制规则的左侧或者右侧的内容进行具体规则挖掘).查看限制了规则的右侧之后挖掘到的规则(置信度排序,只查看左侧即可) 目录
最新文章
- 高品质摄影作图台式计算机推荐,浅谈高质量摄影照片后期输出的打印机选择
- BZOJ 3156: 防御准备( dp + 斜率优化 )
- 多维数组的行优先和列优先, 数据描述语言
- Android ORM 框架:GreenDao 数据库升级
- C#通过VS连接MySQL数据库实现增删改查基本操作
- java监听器的原理与实现
- H5学习从0到1-H5的新特性(1)
- [POI2013]LUK-Triumphal arch
- Luogu 4245 【模板】任意模数NTT
- JPack发布0.5.0
- VS2017社区版安装
- 高可用的分布式Hadoop大数据平台搭建,超详细,附代码。
- 配置管理系统和整体变更系统有什么区别与联系
- 关闭445端口即关闭共享文件功能
- 显示器偏色测试软件,显示器显示偏色
- 菜刀、冰蝎、蚁剑、哥斯拉
- Python入门习题大全——T恤
- 《信息物理融合系统(CPS)设计、建模与仿真——基于 Ptolemy II 平台》——第2章 图形化建模 2.1开始...
- 机房空调漏水原因和常用处理方法
- OMRON CJ系列CJ1W-EIP21通过网关设备 EtherNetIP转RS232/485与Modbus Slave软件测试记录文档
热门文章
- Android中使用EventBus事件发布/订阅框架实现事件传递
- AndroidStudio中提示:uses-sdk:minSdkVersion 16 cannot be smaller than version 19 declared in libr
- Java中判断两个Date时间段是否有交集的方法
- ElementUI中el-radio-group使用v-model绑定是属性为String字符串类型时不回显数据
- DevExpress的TreeList的常用属性设置以及常用事件
- 工程实践规模化推进要点分析
- 数据中台建设中的得与失
- LILY 英语携手神策数据 数据赋能少儿英语学习创新体验
- 咕咚技术总监唐平麟:神策使我们的数据平台成本降低约 75%,迭代效率提升 2~3 倍...
- 神策数据搬新家,召唤有才新伙伴!