解决正在等待响应_解决一些等待问题
解决正在等待响应
背景 (Background)
On occasion, I’ll see waits that exceed what I expect well above normal and a few of them have some architecture and standards to consider following when troubleshooting, though like most waits’ issues, there can be other underlying factors that are happening as well. In this article, I investigate the three waits ASYNC_NETWORK_IO and WRITELOG. In general, waits vary by environment and server, so before reading this article an immediate question to ask is, “Do you know what’s normal for yours?” When a wait suddenly spikes, or if the architecture is designed in a manner that should prevent a specific wait from consuming time, and yet you see that the wait does, I would be concerned. In addition, because applications and environments differ by architecture, you may want to consider other troubleshooting steps, as these may not apply to your situations.
有时候,我会看到等待次数超出了我的预期,远远超过了我的预期,其中一些在故障排除时需要考虑一些体系结构和标准,尽管像大多数等待事件一样,可能还会发生其他潜在因素。 在本文中,我研究了三个等待ASYNC_NETWORK_IO和WRITELOG。 通常,等待时间因环境和服务器而异,因此在阅读本文之前,首先要提出的问题是:“您知道您的正常情况吗?” 当等待突然激增时,或者如果架构的设计应避免特定的等待消耗时间,而您却发现等待确实如此,我会很担心的。 另外,由于应用程序和环境因体系结构而异,您可能需要考虑其他故障排除步骤,因为这些步骤可能不适用于您的情况。
讨论区 (Discussion)
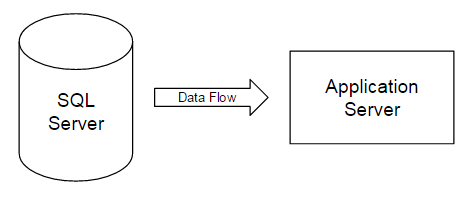
ASYNC_NETWORK_IO. In a multi-server application or ETL environment, this wait almost always occurs when one server is architected better than another server – whether better in that case is more hardware horsepower, a later edition of a database, or a .NET application that can’t keep up with the SQL Server. SQL Server has to wait on the other resource to respond – for an example using ETL, an load batch from SQL Server is sent to a MongoDB server, but the MongoDB server struggles to process the batch quickly thus SQL Server waits on the processing of the MongoDB server. An unrelated analogy would be someone trying to place low-limit orders in a market experiencing a rapid upswing – the market outruns orders like these because of how fast it trends upward. In the image below where we have data flowing from server one (SQL Server) to server two (Application Server), server two can dictate the speed of server one if it lacks the resource power to receive data fast enough:
ASYNC_NETWORK_IO 。 在多服务器应用程序或ETL环境中,当一台服务器的架构比另一台服务器更好时,几乎总是会发生这种等待-在这种情况下,更好的是更多的硬件功能,更高版本的数据库或可以使用.NET应用程序的.NET应用程序。跟上SQL Server。 SQL Server必须等待其他资源来响应-例如,使用ETL时,SQL Server的负载批处理将发送到MongoDB服务器,但是MongoDB服务器难以快速处理该批处理,因此SQL Server等待处理该批处理。 MongoDB服务器。 一个不相关的类比是某人试图在经历快速上涨的市场中下达低限订单–由于其上升的速度如此之快,市场超出了此类订单。 在下面的图像中,数据从服务器一(SQL Server)流向服务器二(Application Server),如果服务器二缺乏资源来足够快地接收数据,服务器二可以决定服务器一的速度:
WRITELOG. I’ve caught this wait type in two common scenarios, though it’s important to know how this can occur. Before writing a record to disk, log operations first occur on a memory block called the log buffer, and in administration and development, we’ll often see situations where a record that is inserted is also updated while the record is still in memory. This wait reflects the latency between the memory flush to disk.
写日志 。 我已经在两种常见情况中捕获了这种等待类型,尽管了解这种情况如何发生很重要。 在将记录写入磁盘之前,日志操作首先发生在称为日志缓冲区的内存块上,在管理和开发中,我们经常会看到这样的情况,即当记录仍在内存中时,插入的记录也会被更新。 此等待反映了内存刷新到磁盘之间的等待时间。
有用的提示和问题 (Useful tips and questions)
For troubleshooting ASYNC_NETWORK_IO problems, my solutions depend on how much permissions and (or) access I have to the second server which is struggling to maintain the performance level of the first server and how much I can match its power to the first server. Assuming that I cannot and I only can fine tune the first server:
为了对ASYNC_NETWORK_IO问题进行故障排除,我的解决方案取决于我对第二台服务器拥有多少权限和(或)访问,而第二台服务器正竭力维持第一台服务器的性能水平,以及我能为第一台服务器提供多少电源和电源。 假设我不能并且只能对第一台服务器进行微调:
I will reduce the SQL statements to a point where the second server can keep up the speed of the second server. In a sense, I become the governor. In testing loads, there is often a threshold at which a load can hit the “Goldilocks”-point of just right in that below and above that point receive less speed. As an example in median environments, I often start in batches of 25,000-40,000 for loads because that’s generally been a sweet spot. However, in larger environments, that’s way too low as a starting point, so it significantly varies.
我将把SQL语句减少到第二台服务器可以跟上第二台服务器的速度。 从某种意义上说,我成为州长。 在测试负载时,通常存在一个阈值,负载可以达到该阈值的恰好在该点以下和之上的“金锁”点接收的速度较慢。 例如,在中位环境中,我通常以25,000-40,000的批次开始装载,因为通常这是一个最佳选择。 但是,在较大的环境中,这作为起点太低了,因此变化很大。
I’ll re-evaluate the time relative to the second server’s resource use. It is possible that the second server is already receiving a batch of data from a load from other servers and the delay is caused by other applications, loads, client use, etc. As an example, in one case, moving a load post a massive delete helped increase performance, as the massive delete (which wasn’t optional) used many of the server’s resources while other applications were connecting that were performing other CRUD operations. Since the second server had to have that bottleneck for that period of time, the load from the first server after the massive delete finished saw a huge performance increase. When architecting a solution for ETL, maintenance, or any other additional tasks, consider that timing can be a deciding factor. In some cases with ASYNC_NETWORK_IO, the second server is busier than the first.
我将重新评估相对于第二台服务器的资源使用时间。 第二台服务器可能已经从其他服务器的负载中接收了一批数据,而延迟是由其他应用程序,负载,客户端使用等引起的。例如,在一种情况下,将负载过大地移动删除有助于提高性能,因为大规模删除(这不是可选的)占用了服务器的许多资源,而其他正在连接的应用程序正在执行其他CRUD操作。 由于第二台服务器在这段时间内必须具有该瓶颈,因此在完成大规模删除后,第一台服务器的负载会极大地提高性能。 在为ETL,维护或任何其他附加任务设计解决方案时,请考虑时间可能是决定性因素。 在某些情况下,使用ASYNC_NETWORK_IO,第二台服务器比第一台服务器更忙。
I will re-evaluate my transforms on the second server, most notably for ETL processes in this case. I’ve seen a lot of ETL flow that extract data on one server, transform on another server, and load on yet another set of servers. Let’s assume that my first extract server has a lot of resources and that the second server is my bottleneck; relative to the environment, I might do some or all transforms on the first server to reduce the impact on my second server, especially if the post-transform sees a reduction in data. As an example of this, rare precious metals, prices are not always available for the London, Hong Kong and New York markets so a transform task take the prices that are available along with the high and low differences between these markets (if applicable) with the final table possessing only four columns instead of the full set. That reduction of the data set means that loading data from one server to another server will be smaller. In addition, in some cases, I can reduce resources by performing transforms in the .NET layer instead of using T-SQL; T-SQL is a set based language, and performs poorly on individual records, which some transforms require. In these cases, I’ll stick to PowerShell and (or) C#.
我将在第二台服务器上重新评估我的转换,在这种情况下,最值得注意的是ETL流程。 我已经看到了许多ETL流程,它们可以在一台服务器上提取数据,在另一台服务器上进行转换并在另一台服务器上进行加载。 假设我的第一台提取服务器有很多资源,而第二台服务器是我的瓶颈。 相对于环境,我可能会在第一台服务器上进行部分或全部转换,以减少对第二台服务器的影响,尤其是在转换后的数据量减少的情况下。 例如,稀有贵金属在伦敦,香港和纽约市场上并不总是能得到价格,因此,转换任务将把可获得的价格以及这些市场之间的高低差(如果适用)与决赛桌只有四栏,而不是全套。 数据集的减少意味着将数据从一台服务器加载到另一台服务器将更小。 另外,在某些情况下,我可以通过在.NET层中执行转换而不是使用T-SQL来减少资源。 T-SQL是一种基于集合的语言,在某些转换要求的单个记录上表现较差。 在这些情况下,我将坚持使用PowerShell和(或)C#。
The assumptions in the above techniques assume that I cannot increase any hardware power on the second (or receiving) server. Regardless of the environment, development must match the relative power of each server involved in a process; it makes no sense to have an application server that can only handle one fourth of what a SQL Server is able to send, if the full amount of what SQL Server is sending will be needed as soon as possible. In an environment like that, since what SQL Server sends is required, the application server must match it, otherwise the end user will suffer.
以上技术中的假设假定我无法增加第二台(或接收)服务器上的任何硬件功能。 无论环境如何,开发都必须与流程中涉及的每台服务器的相对功能相匹配; 如果将尽快需要全部SQL Server发送的内容,那么拥有仅处理SQL Server发送能力的四分之一的应用程序服务器是没有意义的。 在这样的环境中,由于需要SQL Server发送的内容,因此应用程序服务器必须与之匹配,否则最终用户将遭受损失。
For troubleshooting WRITELOG, the three common issues I see are memory bottlenecks, lingering checkpoints, and per-record writes, which are incredibly costly. Some troubleshooting tips for these three issues:
对于WRITELOG的故障排除,我看到的三个常见问题是内存瓶颈,缠绵的检查点和每条记录的写操作,这是非常昂贵的。 针对这三个问题的一些故障排除提示:
For memory bottlenecks outside of vertical scaling, I will optimize expensive queries that use memory ineffectively where possible. As an example of this, running a replication’s distribution history cleanup may be costly to memory (note the fall in PLE and spike in memory), so relative to the time of the bottleneck, adjusting schedules for tasks, maintenance, ETL, etc may help.
对于垂直扩展之外的内存瓶颈,我将优化可能无法有效使用内存的昂贵查询。 例如,运行复制的分发历史记录清理可能对内存造成高昂的成本(请注意PLE的下降和内存峰值),因此相对于瓶颈时间,调整任务,维护,ETL等的计划可能会有所帮助。
With checkpoints lingering, I typically use a PowerShell script that terminates quickly (very short timeout) and runs a checkpoint. The key to avoiding these lingering checkpoints – which can occur – is to avoid allowing them to run forever. They may not be able to run due to other resources using the log. I’ve seen checkpoints that run for hours because they’re blocked by one transaction, and either the blocking transaction needs to be re-evaluated, or the checkpoint needs to try for a short period of time. We can always run checkpoints at a more appropriate time.
随着检查点的徘徊,我通常使用PowerShell脚本来快速终止(非常短的超时)并运行检查点。 避免出现这些挥之不去的检查点的关键是避免让它们永远运行。 由于使用该日志的其他资源,它们可能无法运行。 我已经看到检查点运行了几个小时,因为它们被一个事务阻塞了,或者阻塞的事务需要重新评估,或者检查点需要短时间尝试。 我们总是可以在更合适的时间运行检查点。
Similar to .NET application creating and disposing an object on each loop (slow practice), if we commit one transaction at a time in a batch insert the cost will be greater than committing the batch as a whole. Anytime I see a batch transaction, I immediately look for any explicit declaration of BEGIN/COMMIT/ROLLBACK, because it may be the culprit if it’s not explicitly declared. Similar to the above point on network, if I want to commit one record at a time because I don’t want a full batch to fail, I’ll wrap my logic inside of .NET since that will be much faster at object at a time rather than allowing T-SQL to handle it.
与.NET应用程序在每个循环上创建和放置对象(慢速实践)类似,如果我们在批处理插入中一次提交一个事务,则成本将比整个批处理要大。 每当我看到批处理事务时,我都会立即寻找BEGIN / COMMIT / ROLLBACK的任何显式声明,因为如果未显式声明它可能是罪魁祸首。 与网络上的上述点类似,如果由于不想让整个批处理失败而一次提交一个记录,则将逻辑包裹在.NET中,因为这样做可以更快地实现对象时间,而不是让T-SQL处理它。

In an ideal environment, my drives for different reasons are separate due to the read and write volume on the disks.在理想的环境中,由于磁盘上的读取和写入量,由于各种原因,我的驱动器是分开的。
Do I delineate my disks for data, log and tempdb? Be very careful about keeping log files on the same disks as “everything else” as a disk must be able to keep pace with writes and reads. Another recommendation I’ll make related to this point – scale out your disks for log use ahead of time and be very careful about relying on automated log growth; I heavily scrutinize any person or environment with automatic log growth.
是否要在磁盘上描绘数据,日志和tempdb? 在将日志文件与“其他所有文件”保存在同一磁盘上时要非常小心,因为磁盘必须能够跟上读写操作的步伐。 关于这一点,我将提出另一项建议–提前扩展磁盘以供日志使用,并且在依靠自动日志增长时要非常小心; 我会通过自动日志增长来仔细检查任何人或环境。
In this configuration example, the log is pre-grown to 51200MB and restricted to that growth.在此配置示例中,日志已预增长到51200MB,并且仅限于这种增长。
I’ve seen a few other situations, one of which was no disk space (how does memory flush to disk when there’s no disk space remaining), though these generally are rarer than the above cases. Like with all waits troubleshooting, each environment may experience differing reasons for the same waits.
我还看到了其他一些情况,其中一种情况是没有磁盘空间(没有剩余磁盘空间时内存如何刷新到磁盘),尽管这些情况通常比上述情况少见。 与对所有等待进行故障排除一样,每个环境对于相同的等待可能会遇到不同的原因。
最后的想法 (Final thoughts)
These tips provide some useful techniques for ASYNC_NETWORK_IO and WRITELOG wait types, and are by no means every troubleshooting possibility available, though they have been useful in reducing these waits. The more you understand your architecture, the more you’ll identify the weak points and you can either strengthen these – as systems are only as strong as their weak points – or you can design around them, if strengthening is not an option.
这些技巧为ASYNC_NETWORK_IO和WRITELOG等待类型提供了一些有用的技术,尽管它们对于减少这些等待很有用,但绝不是每种可用的故障排除方法。 对体系结构的了解越多,您就越会发现薄弱环节,您可以加强这些薄弱环节(因为系统的强度仅取决于它们的薄弱环节),或者如果无法选择,则可以围绕它们进行设计。
翻译自: https://www.sqlshack.com/troubleshooting-some-waits-issues/
解决正在等待响应
解决正在等待响应_解决一些等待问题相关推荐
- 装mysql最后一步没响应_解决MySQL安装到最后一步未响应的三种方法
这种情况一般是你以前安装过MySQL数据库服务项被占用了. 解决方法: 方法一:安装MySQL的时候在这一步时它默认的服务名是"MySQL" 只需要把这个名字改了就可以了.可以把默 ...
- ios请求头解决参数中文乱码_解决请求参数的中文乱码问题(get、post)
2018-11-28 在web请求与响应中,会遇到乱码问题,比如填写表单数据时,难免会输入中文,姓名.公司名称等.由于HTML设置了浏览器在传递请求参数时,采用的编码方式是UTF-8,但在解码时采用的 ...
- git解决冲突 删除本地_解决冲突
人生不如意之事十之八九,合并分支往往也不是一帆风顺的. 准备新的feature1分支,继续我们的新分支开发: $ git switch -c feature1 Switched to a new br ...
- python(pyqt5)多线程解决界面无响应
多线程解决界面无响应多线程解决界面无响应多线程解决界面无响应 def open_train_task():import osos.system(r"E:\kg\TURN-TAP-master ...
- 蓝桥杯嵌入式组第九届省赛练习(算是解决了长短按键,解决了高亮显示)
第九届代码实现代码 https://gitee.com/litte_enigner/lqb_emb_9th.git 蓝桥杯开发板的基本模块已经玩的差不多了,接下来就拿第九届题练一下手. 算是解决了长短 ...
- win7系统未响应卡住_系统经常假死怎么办|win7系统经常无响应|win10系统经常未响应怎么解决...
2016-12-09 10:51:44 电脑安装windows7操作系统后,难免会遇到一些故障问题,这不有位用户说打开应用程序经常出现未响应的情况,每次都要等待很久的时间,这可怎么办呢?有些用户尝试启 ...
- mysql+mdl+解决办法_Mysql DDL出现长时间等待MDL问题分析
给表新增字段时,发现锁表了,查看进程,提示Waiting for table metadata lock,等待锁释放:然而蛋疼的是几分钟过去了,依然没有任何的进展,特此记录下这个问题的定位过程以及MD ...
- matlab 正在等待响应标头。可能服务器没有响应,或者 weboptions.Timeout,Expect:100-continue
通过matlab进行webwrite测试,结果发现返回报错 原因是 "正在等待响应标头".可能服务器没有响应,或者 weboptions.Timeout 解法: 1.修改timeo ...
- 路由器wan口认证断开服务器无响应,路由器WAN口设置已断开(服务器无响应)的解决方法...
越洋帮路由网原创:文章是关于"路由器WAN口设置已断开(服务器无响应)的解决方法"的相关知识分享,希望可以帮到大家. - 素材来源网络 编辑:小易. 路由器WAN口设置的地方显示: ...
最新文章
- oracle控制文件都一样么,Oracle控制文件详解
- python自动化测试看什么书-Python接口自动化测试
- shell实例第8讲:seq命令
- 代码高亮_微信公众号代码高亮美化工具 Markdown Nice
- java面试题二十 try catch
- tf.clip_by_value()
- 规则引擎drools的简单使用
- 利用ping/ipconfig/nslookup/dig/whois简单工具测试DNS
- rainmeter 新人使用记录
- 下列不是python内置函数的是_Python 内置函数
- Excel二次开发学习笔记——获取某列最后一个非空单元格的行号
- PV3D的小练习~太阳系八大行星
- [语义分割]CTNet: Context-based Tandem Network for Semantic Segmentation
- 初学者须知 常见Web前端开发工具有哪些
- 云服务器搭建青龙面板每日自动拿京豆
- LaTex学习教程——插入较复杂的表格(合并、换行以及加标题)
- 渗透测试培训--(小迪篇)
- 前端身份证号码校验js代码
- uni-app动态引入图片
- 《崔庆才Python3网络爬虫开发实战教程》学习笔记(3):抓取猫眼电影榜单TOP100电影,并存入Excel表格