利用linux curl爬取网站数据
看到一个看球网站的以下截图红色框数据,想爬取下来,通常爬取网站数据一般都会从java或者python爬取,但本人这两个都不会,只会shell脚本,于是硬着头皮试一下用shell爬取,方法很笨重,但旨在结果嘛,呵呵。
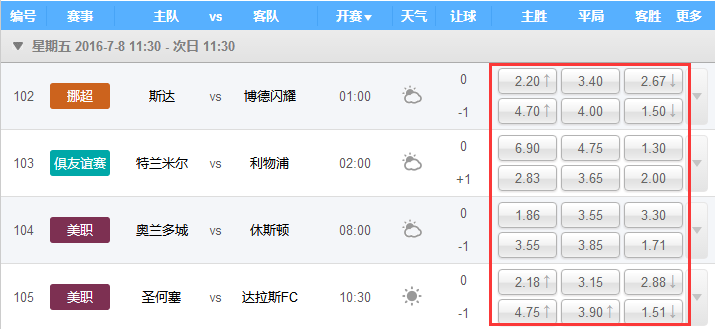
2.首先利用curl工具后者wget工具把整个网站数据爬取下来
curl 网址 >wangzhan.txt
3.查看wangzhan.txt文件,找出规则,看到数据是存放在哪个地方,本人是把txt文件拷到本机上用UE打开方便查看。通过查看文件,我发现数据是存储在“var automultiMatchList”与 “var setSingleMulti”这间的所有行,每个行后面的},结束代表一行:
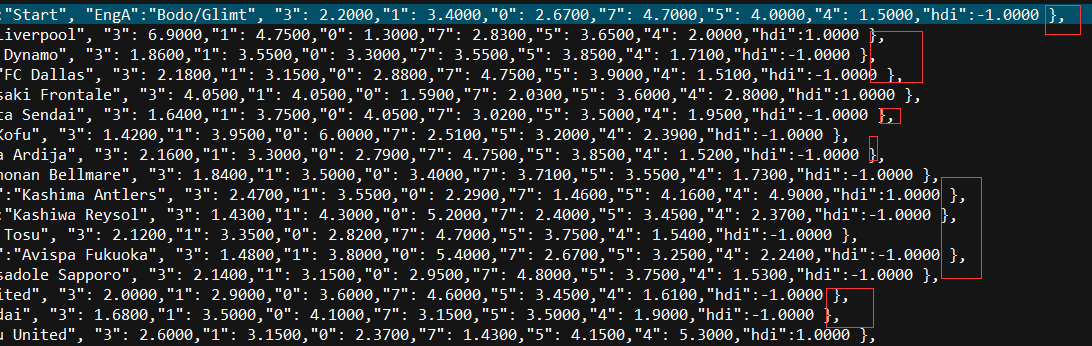
4. 截取所需的数据我是通过以下5个步骤

shell脚本分析:
(1)sed -n '/var automultiMatchList/,/var setSingleMulti/p' wangzhan.txt
这步是指从wangzhan.txt文件中查找到包含“var automultiMatchList”的行与包含“var setSingleMulti”的行之间的所有行:

(2)sed '$d' 是指删除最后一行的内容,因为这不是我们需要的数据。
(3)awk 'NR<2' 是指把第一行取出来做特殊处理,因为第一行包含不要的数据(红色线框的内容)
 (4)awk -F'= {' '{print $2}' 是指通过 ={ 分隔域,输出$2就把上步红色线框的内容去掉了
(4)awk -F'= {' '{print $2}' 是指通过 ={ 分隔域,输出$2就把上步红色线框的内容去掉了

(6)第二条shell脚本中的awk '/[0-9]/{print $0}' 就是把最后的空行都去掉

(7)第二条shell脚本中的awk 'NR>=2' >2.txt 是指把第二行及以下的所有行都输出到2.txt脚本

这里用了awk的match和substr函数,就是找到“3”在这一行的所在位置之后,再截取需要的内容,这里不用过awk函数的同学可以复习一下awk函数。到这一步,我们要截取的数据的雏形就出来了。
(11)awk -F',' '{print $1" "$2" "$3" "$4" "$5" "$6" "$7}'>data.txt 是指通过逗号分隔域,然后再通过空格隔开:
(12)sed 's/"[[:alnum:]]\+"://g' 是指把冒号前面的数据都去掉,例如"3": 这种数据:
(13)awk '{print $1,$2,$3,$4,$5,$6}' 是指只打印我们需要的6个域:
(14)xargs -n3 是指按照每3列输出,我们执行下第5条命令,然后33.txt的数据,就是我们要的数据:
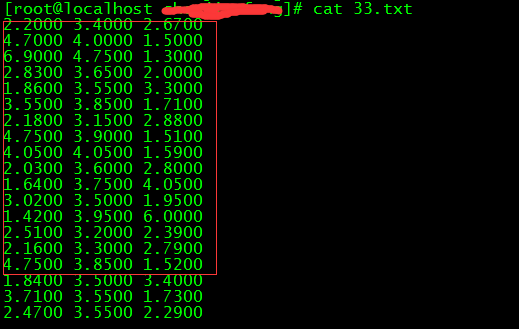
总结:用shell爬取网站数据,需要熟悉sed,grep,awk等文本操作工具以及还运用到正则表达式,需要了解的内容比较多,比较繁琐复杂,
转载于:https://blog.51cto.com/quguanhai/1825537
利用linux curl爬取网站数据相关推荐
- 如何利用python爬取网站数据
Python是一种非常适合用于网络爬虫的编程语言,以下是Python爬取网站数据的步骤: 1. 确定目标网站和所需数据:首先要找到需要爬取数据的网站,确定你需要爬取的数据是哪一部分. 2. 发送请求: ...
- python爬网站数据实例-利用Python爬虫爬取NBA数据功能实例分享
Python实现爬虫爬取NBA数据功能示例 本文实例讲述了Python实现爬虫爬取NBA数据功能.分享给大家供大家参考,具体如下: 爬取的网站为:stat-nba.com,这里爬取的是NBA2016- ...
- 用Excel,只需30秒就可爬取网站数据
是的,你没看错,就是用Excel爬数据.那么为什么要用它呢?因为它不需要写一行代码,只需要轻轻点几下鼠标,就可以得到你想要的数据,全程30秒左右就能搞定,在网站结构简单,需求比较简单的情况下,你只此一 ...
- python爬取网站数据(含代码和讲解)
提示:本次爬取是利用xpath进行,按文章的顺序走就OK的: 文章目录 前言 一.数据采集的准备 1.观察url规律 2.设定爬取位置和路径(xpath) 二.数据采集 1. 建立存放数据的dataf ...
- Pycharm + python 爬虫简单爬取网站数据
本文主要介绍简单的写一个爬取网站图片并将图片下载的python爬虫示例. 首先,python爬虫爬取数据,需要先了解工具包requests以及BeautifulSoup requests中文文档:ht ...
- 用Excel,爬取网站数据
0. 软件版本要求及先决条件 要求1 :Excel2016及以上版本,开箱即用.当然其他低版本,不是不可以,只是需要自己安装插件,爱折腾的可以自己尝试. 要求2:仅支持get请求(这一点不了解的人可以 ...
- #python学习笔记#使用python爬取网站数据并保存到数据库
上篇说到如何使用python通过提取网页元素抓取网站数据并导出到excel中,今天就来说说如何通过获取json爬取数据并且保存到mysql数据库中. 本文主要涉及到三个知识点: 1.通过抓包工具获取网 ...
- java爬虫抓取nba_利用Python爬虫爬取NBA数据功能实例分享
Python实现爬虫爬取NBA数据功能示例 本文实例讲述了Python实现爬虫爬取NBA数据功能.分享给大家供大家参考,具体如下: 爬取的网站为:stat-nba.com,这里爬取的是NBA2016- ...
- 使用python爬取网站数据并写入到excel中
文章目录 前言 一.使用python爬取网上数据并写入到excel中 例子一: 例子二: 二.工具类 总结 前言 记录一下使用python将网页上的数据写入到excel中 一.使用python爬取网上 ...
最新文章
- 微软私有云分享(R2)26配置基线与更新
- 【重磅】马斯克遇终极麻烦:被起诉欺诈罪 或丢掉CEO职位 特斯拉暴跌约13%
- python 从网络URL读取图片并直接处理的代码
- mysql自动添加多条数据_用一条mysql语句插入多条数据
- 2017年初随想——几个小目标
- scara机器人dh参数表_两分钟带你了解机器人标定的因素
- mongodb定时删除数据(索引删除)
- iis7 64位 操作excel的一系列问题(未完待续)
- 台达cp2000的面板怎么调节_吊灯怎么安装 吊灯怎么固定在顶上的
- 数字化项目建设管理难点分析与对策
- 能上QQ但不能打开网页——解决办法
- 关于海外置业,我泼点冷水
- ChatGPT能够干翻谷歌吗?
- Qt 局域网聊天(功能完善,界面美观,免费下载)
- 仿微信的录制小视频功能
- 单片机DAC输出方波简易实验
- ACP 云计算试题集
- PerfDog测试安卓模拟器初体验
- CSS #38; JS
- 谷歌五笔输入法电脑版_新手学拼音还是学五笔打字(看完你就明白)