Redis集群方案及框架
redis集群分为服务端集群和客户端分片,redis3.0以上版本实现了集群机制,即服务端集群,3.0以下使用客户端分片(Sharding)。
通常,为了提高网站响应速度,总是把热点数据保存在内存中而不是直接从后端数据库中读取。Redis是一个很好的Cache工具。大型网站应用,热点数据量往往巨大,几十G上百G是很正常的事儿,在这种情况下,如何正确架构Redis呢?
首先,无论我们是使用自己的物理主机,还是使用云服务主机,内存资源往往是有限制的,scale up不是一个好办法,我们需要scale out横向可伸缩扩展,这需要由多台主机协同提供服务,即分布式多个Redis实例协同运行。
其次,目前硬件资源成本降低, 多核CPU,几十G内存的主机很普遍,对于主进程是单线程工作的Redis,只运行一个实例就显得有些浪费。同时,管理一个巨大内存不如管理相对较小的内存高效。因此,实际使用中,通常一台机器上同时跑多个Redis实例。
方案
1、Redis官方集群方案 Redis Cluster(服务器端)
Redis Cluster是一种服务器Sharding技术,3.0版本开始正式提供。
Redis
Cluster中,Sharding采用slot(槽)的概念,一共分成16384个槽,这有点儿类似前面讲的pre
sharding思路。对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。使用的hash算法也比较简
单,就是CRC16后16384取模。
Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个
slot都对应一个node负责处理。当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。当然,这一过程,在目前实
现中,还处于半自动状态,需要人工介入。
Redis集群,要保证16384个槽对应的node都正常工作,如果某个node发生故障,那它负责的slots也就失效,整个集群将不能工作。
为
了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。这时,如果主节点失
效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务。这非常类似前篇文章提到的Redis
Sharding场景下 服务器节点通过Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
Redis
Cluster的新节点识别能力、故障判断及故障转移能力是通过集群中的每个node都在和其它nodes进行通信,这被称为集群总线(cluster
bus)。它们使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是
16379。nodes之间的通信采用特殊的二进制协议。
对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个
node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node,这
有点儿像浏览器页面的302 redirect跳转。
Redis Cluster是Redis 3.0以后才正式推出,时间较晚,目前能证明在大规模生产环境下成功的案例还不是很多,需要时间检验。
Redis Cluster集群搭建方法(Linux) http://blog.csdn.net/qq_32364027/article/details/79568701
2、Redis Sharding集群(presharding 客户端)
Redis 3正式推出了官方 集群技术,解决了多Redis实例协同服务问题。Redis Cluster可以说是服务端Sharding分片技术的体现,即将键值按照一定算法合理分配到各个实例分片上,同时各个实例节点协调沟通,共同对外承担一致服务。
多Redis实例服务,比单Redis实例要复杂的多,这涉及到定位、协同、容错、扩容等技术难题。这里,我们介绍一种轻量级的客户端Redis Sharding技术。
Redis
Sharding可以说是Redis
Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用 哈希算法将Redis数据的key进行散列,通过 hash函数,特定
的key会映射到特定的Redis节点上。这样,客户端就知道该向哪个Redis节点操作数据。Sharding架构如图:
庆幸的是,java redis客户端驱动jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。
Jedis的Redis Sharding实现具有如下特点:
采
用 一致性哈希算法(consistent
hashing),将key和节点name同时hashing,然后进行映射匹配,采用的算法是MURMUR_HASH。采用 一致性哈希而不是采用简单类
似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。 一致性哈希只影响相邻节点key分配,影响量小。
2.
为了避免一致性哈希只影响相邻节点造成节点分配压力,ShardedJedis会对每个Redis节点根据名字(没有,Jedis会赋予缺省名字)会虚拟
化出160个虚拟节点进行散列。根据权重weight,也可虚拟化出160倍数的虚拟节点。用虚拟节点做映射匹配,可以在增加或减少Redis节点
时,key在各Redis节点移动再分配更均匀,而不是只有相邻节点受影响。
3.ShardedJedis支持keyTagPattern模式,即抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一个Redis节点,这在避免跨节点访问相关数据时很重要。
Redis Sharding采用客户端Sharding方式,服务端Redis还是一个个相对独立的Redis实例节点,没有做任何变动。同时,我们也不需要增加额外的中间处理组件,这是一种非常轻量、灵活的Redis多实例集群方法。
当然,Redis Sharding这种轻量灵活方式必然在集群其它能力方面做出妥协。比如扩容,当想要增加Redis节点时,尽管采用一致性哈希,毕竟还是会有key匹配不到而丢失,这时需要键值迁移。
作为轻量级客户端sharding,处理Redis键值迁移是不现实的,这就要求应用层面允许Redis中数据丢失或从后端数据库重新加载数据。但有些时候,击穿缓存层,直接访问数据库层,会对系统访问造成很大压力。有没有其它手段改善这种情况?
Redis
作者给出了一个比较讨巧的办法--presharding,即预先根据系统规模尽量部署好多个Redis实例,这些实例占用系统资源很小,一台物理机可部
署多个,让他们都参与sharding,当需要扩容时,选中一个实例作为主节点,新加入的Redis节点作为从节点进行数据复制。 数据同步后,修改
sharding配置,让指向原实例的Shard指向新机器上扩容后的Redis节点,同时调整新Redis节点为主节点,原实例可不再使用。
presharding
是预先分配好足够的分片,扩容时只是将属于某一分片的原Redis实例替换成新的容量更大的Redis实例。参与sharding的分片没有改变,所以也
就不存在key值从一个区转移到另一个分片区的现象,只是将属于同分片区的键值从原Redis实例同步到新Redis实例。
并不是只有增
删Redis节点引起键值丢失问题,更大的障碍来自Redis节点突然宕机。在 《Redis持久化》一文中已提到,为不影响Redis性能,尽量不开启
AOF和RDB文件保存功能,可架构Redis主备模式,主Redis宕机,数据不会丢失,备Redis留有备份。
这样,我们的架构模式变
成一个Redis节点切片包含一个主Redis和一个备Redis。在主Redis宕机时,备Redis接管过来,上升为主Redis,继续提供服务。主
备共同组成一个Redis节点,通过自动故障转移,保证了节点的 高可用性。则Sharding架构演变成:
Redis Sentinel提供了主备模式下Redis监控、故障转移功能达到系统的 高可用性。
高访问量下,即使采用Sharding分片,一个单独节点还是承担了很大的访问压力,这时我们还需要进一步分解。通常情况下,应用访问Redis读操作量和写操作量差异很大,读常常是写的数倍,这时我们可以将读写分离,而且读提供更多的实例数。
可以利用主从模式实现读写分离,主负责写,从负责只读,同时一主挂多个从。在Sentinel监控下,还可以保障节点故障的自动监测。
3.利用代理中间件实现大规模Redis集群
上面分别介绍了多Redis 服务器集群的两种方式,它们是基于客户端sharding的Redis Sharding和基于服务端sharding的Redis Cluster。
客户端sharding技术其优势在于服务端的Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强。其不足之处在于:
由于sharding处理放到客户端,规模进步扩大时给运维带来挑战。
服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。
连接不能共享,当应用规模增大时,资源浪费制约优化。
服务端sharding的Redis Cluster其优势在于服务端Redis集群拓扑结构变化时,客户端不需要感知,客户端像使用单Redis服务器一样使用Redis集群,运维管理也比较方便。
不过Redis Cluster正式版推出时间不长,系统稳定性、性能等都需要时间检验,尤其在大规模使用场合。
能不能结合二者优势?即能使服务端各实例彼此独立,支持线性可伸缩,同时sharding又能集中处理,方便统一管理?本篇介绍的Redis代理中间件twemproxy就是这样一种利用中间件做sharding的技术。
twemproxy处于客户端和服务器的中间,将客户端发来的请求,进行一定的处理后(如sharding),再转发给后端真正的Redis服务器。也就是说,客户端不直接访问Redis服务器,而是通过twemproxy代理中间件间接访问。
参照Redis Sharding架构,增加代理中间件的Redis集群架构如下:
twemproxy中间件的内部处理是无状态的,它本身可以很轻松地集群,这样可避免单点压力或故障。
twemproxy又叫nutcracker,起源于twitter系统中redis/memcached集群开发实践,运行效果良好,后代码奉献给开源社区。其轻量高效,采用C语言开发,工程网址是:GitHub - twitter/twemproxy: A fast, light-weight proxy for memcached and redis
twemproxy后端不仅支持redis,同时也支持memcached,这是twitter系统具体环境造成的。
由于使用了中间件,twemproxy可以通过共享与后端系统的连接,降低客户端直接连接后端服务器的连接数量。同时,它也提供sharding功能,支持后端服务器集群水平扩展。统一运维管理也带来了方便。
当然,也是由于使用了中间件代理,相比客户端直连服务器方式,性能上会有所损耗,实测结果大约降低了20%左右。
3:redis4.0、codis、阿里云redis 3种redis集群对比分析
1、架构对比
1.1、redis 4.0 cluster
redis 4.0版本的集群是去中心化的结构,集群元数据信息分布在每个节点上,主备切换依赖于多个节点协商选主。
redis 提供了redis-trib 工具做部署集群及运维等操作。
客户端访问散列的db节点需依赖smart client,也就是客户端需要对redis返回的节点信息做判断选择路由等操作。例如客户端请求一个节点,如果所请求的key不在该节点上,客户端需要判断返回的move或ask等指令,重定向请求到对应的节点。
1.2、codis
codis由3大组件构成:
- codis-server : 修改过源码的redis, 支持slot,扩容迁移等
- codis-proxy : 支持多线程,go语言实现的内核
- codis Dashboard : 集群管理工具
提供web图形界面管理集群。
集群元数据存在在zookeeper或etcd。
提供独立的组件codis-ha负责redis节点主备切换。
基于proxy的codis,客户端对路由表变化无感知。客户端需要从codis dashhoard调用list proxy命令获取所有proxy列表,并根据自身的轮询策略决定访问哪个proxy节点以实现负载均衡。
1.3、阿里云redis
阿里云的redis集群版由3大组件构成:
- redis-config : 集群管理工具
- redis-server : 优化过源码的redis,支持slot, 扩容迁移等
- redis-proxy : 单线程,c++14语言实现的内核
架构图如下:
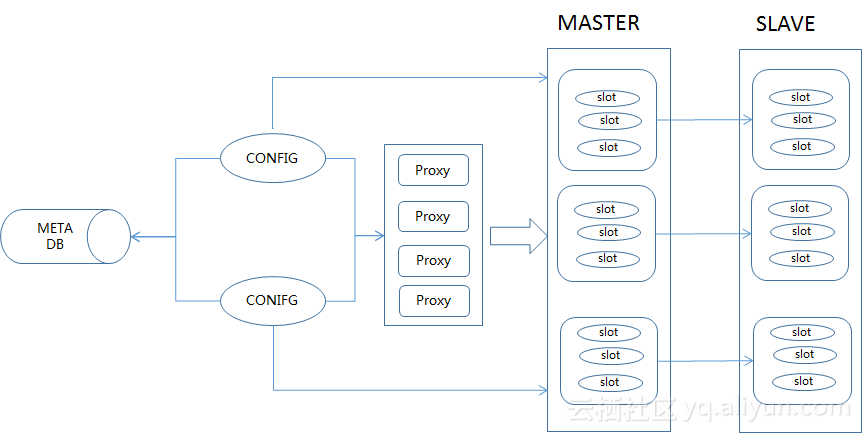
redis-proxy 无状态,一个集群根据集群规格可挂多个proxy节点。
redis-config 双节点,支持容灾。
集群元数据存储在rds db上。
提供独立的组件HA负责集群的主备切换等。
阿里云的redis集群同样基于proxy,用户对路由信息无感知,同时提供vip给客户端访问,客户端只需一个连接地址即可,无须关心proxy访问的负载均衡等。
2、性能对比
2.1、压测环境
在3台物理机上分别搭建了以上3种redis集群。每台物理机千兆网卡,24核cpu,内存189G。3台物理机分别跑压测工具memtier_benchmark、codis proxy/阿里云proxy、redis server。redis server使用各种集群配套的redis内核。
固定key size 32个字节,set/get 操作比例为1:10。每个线程16个客户端。连续压测5分钟,分8个, 16个, 32个, 48个, 64个线程压测。
因为redis4.0集群需要额外的客户端选择节点,而memtier_benchmark不支持,所以使用了hashtag 来压测redis4.0。
每个集群有8个master db, 8个slave db, aof打开。aof rewrite的最小buffer为64MB。
压测的对象分别为单个redis 4.0 节点, 单个阿里云redis-proxy, 单核的codis-proxy, 8核的codis-proxy。
codis 使用的go版本为1.7.4。
压测结果图如下:
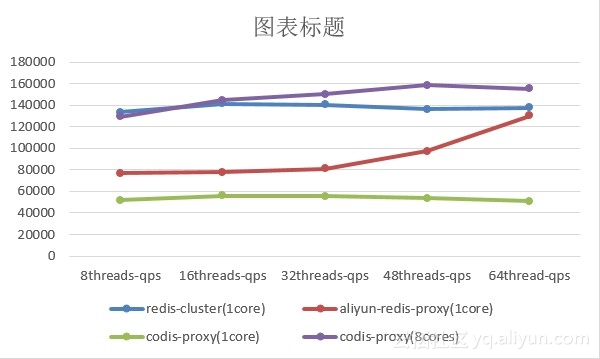
可看出,单核的codis-proxy性能最弱。8核的codis-proxy压测没有对key使用hashtag,如此相当于将请求分散到后端8个db节点上, 也可以说相当于8个阿里云的redis-proxy。自然性能数据就比较高了。
单核的阿里云redis-proxy在压力够大的情况下性能逼近原生的redis db节点。
在实际生产环境中,使用原生的redis cluster,客户端需要实现cluster protocol, 解析move, ask等指令并重定向节点,随意访问key可能需要两次访问操作才能完成,性能上并不能完全如单节点一样。
3、支持特性对比
3.1、主要不同协议的支持对比
| | redis 4.0 | 阿里云redis | codis |
| ---------| :--------: | :---------: | :--------: |
| 事务 | 支持相同slot | 支持相同的slot | 不支持 |
| sub/pub | 支持相同slot | 支持 | 不支持 |
| flushall | 支持 | 支持 | 不支持 |
| select | 不支持 | 支持 | 不支持 |
| mset/mget | 支持相同slot | 支持 | 支持 |
更多命令请参考各自的集群版本说明。
3.2、水平扩展对比
redis4.0 cluster,codis,阿里云redis 分布式集群均实现了面对slot的管理,扩展的最小单元是slot。
分布式集群中水平扩展的本质是对集群节点的路由信息管理以及数据的迁移。这3种集群迁移数据的最小单位均是key。
3.2.1 redis cluster 水平扩展原理
redis4.0 cluster支持指定slot在节点中移动,也支持加入空节点后根据集群节点中已存在的slot分布自动进行再分布。以redis-trib的move_slot为例解析slot移动的过程:
- 步骤1): 调用setslot命令修改源、目标节点slot的状态
- 步骤2): 获取源节点上slot的key列表
- 步骤3): 调migrate命令迁移key,迁移过程中redis属于阻塞状态,只有目标节点restore成功后才返回
- 步骤4): 调用setslot命令修改源、目标节点slot的状态
在迁移过程中,如何保证数据的一致性呢?
redis cluster提供迁移状态中的重定向机制,向客户端返回ASK,客户端收到后需先发送asking指令到目标节点上,然后再发请求到目标节点上才可以访问。当访问的key满足以下全部条件时会出现重定向返回:
- key所属slot在该节点上,如不在,返回的是MOVE
- slot处于迁移状态中
- key不存在
如上所述,migrate 是一个同步阻塞型的操作,如果key并不为空,即使slot处于迁移状态,key依然能被读写,以此保证数据的一致性。
3.2.2 codis 水平扩展原理
codis对slot的再分布策略与redis cluster相同。codis-server内核并没有存储slot的信息,也不解析key所在的slot,只有在dbadd等操作时将对应的key记录到以slot为key的dict中,如果key带有tag,则将tag做crc32运算后将key插入到以crc32值为key的skiplist中。
codis Dashboard 后台起迁移状态机程序,先确保通知到所有proxy开始迁移,即prepare阶段,如有一台以上proxy失败,则迁移任务失败。迁移步骤与redis cluster类似,不同点是:
- slot状态信息存储在zookeeper/etcd
- 发送slotsmgrttagslot而非migrate指令,slotsmgrttagslot执行时会随机获取一个key迁移,如key带有tag,则从上文中的skiplist获取所有key批量迁移
codis同样也是同步阻塞型的迁移操作。
在保持数据一致性方面,因为codis-server内核不维护slot的状态,所以一致性的保证落在了proxy组件上。codis-proxy在处理请求时,先判断key所在slot的状态,如slot处于迁移中,则向codis-server发起指定key迁移的命令,等key迁移完成后,codis-proxy转向目标的codis-server请求。做法简单,对redis内核修改较少,但同时也导致迁移慢,客户端卡住的时间较久。
3.2.3 阿里云redis 水平扩展原理
阿里云redis除了提供指定源、节点、slot外,还提供按节点的容量、slot的大小等考量参数动态分配slot,以最小粒度影响集群可用性作为分配原则。迁移大体步骤如下:
- 步骤1): 由redis-config计算源、目标节点、slot
- 步骤2): redis-config向redis-server发送迁移slot指令
- 步骤3): redis-server启动迁移状态机,分批量迁移key
- 步骤4): redis-config定时检查redis-server并更新slot状态
与codis不同,阿里云redis在内核上同样维护了slot的信息,并且抛弃了codis迁移整个slot和redis cluster迁移单个key的做法,从内核上支持批量迁移,加快迁移速度。
阿里云redis迁移数据是异步的流程,不等待目标节点是否restore成功,由目标节点通知和源节点定时检查来验证是否成功。以此缩小同步阻塞对其他slot访问的影响。
同时也是因为迁移异步化,所以在保证数据一致性时,判断请求如果是写请求并且key存在且不在迁移的key列表中,走正常的写请求流程。其他数据一致性保证与redis4.0 cluster相同。
阿里云redis-server优化了迁移大key的流程,详情可见https://yq.aliyun.com/articles/64884?spm=5176.8091938.0.0.fF3UZH
3.3、其他
| | redis 4.0 | 阿里云redis | codis |
| --------- | :--------: | :---------: | :--------: |
| 内核热升级 | 不支持 | 支持 | 不支持 |
| proxy热升级 | 无proxy | 支持 | 不支持 |
| slots槽数 | 16384 | 16384 | 1024 |
| 密码 | 不支持,需改redis-trib脚本 | 支持 | 支持,所有组件密码必须一致 |
阿里云的redis内核和proxy的热升级过程中均不断连接,对客户端无影响。
Redis集群方案及框架相关推荐
- Redis集群方案,Codis安装测试
Redis集群方案,Codis安装测试 1,关于豌豆荚开源的Codis Codis是豌豆荚使用Go和C语言开发.以代理的方式实现的一个Redis分布式集群解决方案,且完全兼容Twemproxy.Twe ...
- Redis集群方案及实现 - yfk的专栏 - 博客频道 - CSDN.NET
Redis集群方案及实现 - yfk的专栏 - 博客频道 - CSDN.NET yfk的专栏 学习&记录&分享 目录视图 摘要视图 订阅 [公告]博客系统优化升级 U ...
- 基于Twemproxy的Redis集群方案
基于Twemproxy的Redis集群方案 原文地址:http://www.cnblogs.com/haoxinyue/p/redis.html 为了保持方便,愿原博主谅解 概述 由于单台redis ...
- Redis - 集群方案
在开发测试环境中,我们一般搭建Redis的单实例来应对开发测试需求,但是在生产环境,如果对可用性.可靠性要求较高,则需要引入Redis的集群方案.虽然现在各大云平台有提供缓存服务可以直接使用,但了解一 ...
- redis集群方案-Twemproxy
redis集群方案-Twemproxy 1 Twemproxy是什么? Twemproxy是一种代理分片机制,来源于Twitter开源.Twemproxy按照路由规则,转发给后台的各个Redis服务器 ...
- Redis集群方案对比:Codis、Twemproxy、Redis Cluster
为了保证Redis的高可用,主要需要以下几个方面: 数据持久化 主从复制 自动故障恢复 集群化 我们简单理一下这几个方案的特点,以及它们之间的联系. 数据持久化本质上是为了做数据备份,有了数据持久化, ...
- Redis 集群方案
根据一些测试整理出来的一份方案: 1. Redis 性能 对于redis 的一些简单测试,仅供参考: 测试环境:Redhat6.2 , Xeon E5520(4核)*2/8G,1000M网卡 Redi ...
- Redis集群方案应该怎么做?都有哪些方案?
1.codis. 目前用的最多的集群方案,基本和twemproxy一致的效果,但它支持在 节点数量改变情况下,旧节点数据可恢复到新hash节点. 2.redis cluster3.0自带的集群,特点在 ...
- Redis集群方案及实现
之前做了一个Redis的集群方案,跑了小半年,线上运行的很稳定 差不多可以跟大家分享下经验,前面写了一篇文章 数据在线服务的一些探索经验,可以做为背景阅读 应用 我们的Redis集群主要承担了以下服务 ...
最新文章
- 计算机专业今后的发展方向
- 找回 macOS Sierra 中的“任何来源”选项
- python读取中文-python读取中文txt文本
- 米兔点读笔点读包_小米米兔点读笔评测:养成教育只要轻松一点
- 洛谷P4831 Scarlet loves WenHuaKe
- ArcGIS制图表达Representation-制图表达原理
- iOS蓝牙开发总结-4
- 小猿圈之测试用例的八大要素
- ClickHouse 实时数据去重final+group by
- RabbitMQ使用教程
- 手机html在哪个文件里,手机相册在哪个文件夹,教您手机图片存放在哪里
- 古墓丽影暗影显卡测试软件,游戏新消息:战地5古墓丽影暗影8K测试单显卡根本带不动...
- paypal php 返回_接入 paypal PHP-sdk 支付 / 回调 / 退款全流程
- Vue3+TS 快速上手 (尚硅谷)
- Python编程入门之Arcade游戏编程(一)
- mysql数据库的简介(安装和卸载)
- python做淘宝_我用 python 做了款可开淘宝店赚钱的工具!
- Ubuntu下Eclipse环境中有时print screen按键失效无法截屏的问题
- 小记:找不到或无法加载主类
- iOS内IPC(进程间通信)方法小结