Datawahle组队学习——妙趣横生大数据 Day3
妙趣横生大数据 Day3
- 四、HBase
- 1. 背景
- 2. HBase 概述
- 3. HBase 数据模型
- 相关概念
- 数据坐标
- 概念视图
- 物理视图
- 面向列的存储
- 4. HBase 实现原理
- HBase 功能组件
- 表和 Region
- Region 定位
- 5. HBase 运行机制
- 系统架构
- Region服务器的工作原理
- Store工作原理
- HLog工作原理
- 实验
Datawhale![]()
大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data
四、HBase
1. 背景
Hadoop 的局限性:批处理、顺序的方式访问数据,无法实现对数据的随机访问
数据结构的分类:结构化数据、半结构化数据、非结构化数据
为存储不同数据结构,数据库包括:
关系型数据库 (MySQL)、键值存储数据库 (Redis)、列存储数据库 (HBase)、面向文档数据库 (MongoDB)、图形数据库 (Neo4J)、搜索引擎数据库 (Solr)
HBase与传统的关系型数据库的区别主要在于:数据类型 (存储为未经解释的字符串)、数据操作(不会把数据充分规范化)、存储模式(列存储)、数据索引 (支持行键索引)、数据维护(保留一段时间)、可伸缩性(水平扩展性好)
2. HBase 概述
- 构建在Hadoop文件系统之上的一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
- 提供对大量结构化数据的快速随机访问。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mASUsLA3-1676984437639)(null)]
3. HBase 数据模型
相关概念
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族。
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
- 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元。表中的每个列都归属于某个列族,数据可以被存放到列族的某个列下面(列族需要先创建好)。在创建完列族以后,就可以使用同一个列族当中的列。列名都以列族作为前缀。例如,
courses:history和courses:math这两个列都属于courses这个列族。 - 列限定符:列族里的数据通过列限定符(或列)来定位。
- 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组
byte[]。 - 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
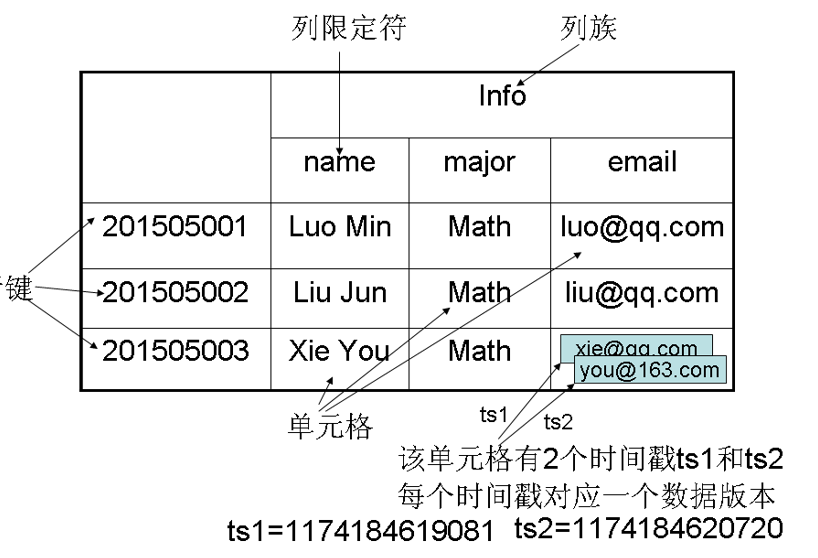
数据坐标
一个“四维坐标”,即
[行键, 列族, 列限定符, 时间戳]HBase可以视为一个键值数据库:‘四维坐标’(键)、单元格内容(值)
![]()
概念视图
一个表可以视为一个稀疏、多维的映射关系
- eg:存储网页的HBase表的片段:每个行都包含相同的列族,行不需要在每个列族里存储数据
![]()
物理视图
采用基于列的存储方式(与传统关系数据库的最大区别)
- eg:前述概念视图进行物理存储,会存储以下两个小片段
![]()
面向列的存储
- 数据按列存储,每一列单独存放
- 数据即是索引
- 只访问查询涉及的列,大量降低系统IO
- 每一列由一个线索来处理,查询采用并发处理方式
- 数据类型一致,数据特征相似,采用高效压缩方式
- 缺陷:执行链接操作时,需要昂贵的元组重构代价
4. HBase 实现原理
HBase 功能组件
- 库函数
- 用于连接到每个客户端
- 一个 Master 主服务器
- 负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡
- 许多 Region 服务器
- 负责存储和维护分配给自己的Region,处理来自客户端的读写请求
- 客户端读取数据:获得Region的存储位置信息后,直接从Region服务器上读取数据
- 客户端通过Zookeeper获得Region位置信息,大多数客户端甚至从来不和Master通信
表和 Region
HBase存储了很多表,每个HBase表有包含大量行(无法存储在一台机器)
一个 HBase 表被划分成多个 Region 分区
- Region包含了位于某个值域区间内的所有数据,是负载均衡和数据分发的基本单位
一个 Region 会分裂成多个新的 Region
Region 定位
- 每个Region都有一个
RegionID来标识它的唯一性,这样,一个Region标识符就可以表示成表名+开始主键+RegionID - “元数据表”,又名
.META.表: Region标识符、Region服务器标识 .META.表也会被分裂成多个Region- “根数据表”,-ROOT-`表:记录所有元数据的具体位置
-ROOT-表是不能被分割的,永远只存在一个Region用于存放-ROOT-表- 存放
-ROOT-表的唯一个Region,它的名字是在程序中被写死的,Master主服务器永远知道它的位置
5. HBase 运行机制
系统架构
客户端
- 客户端包含访问HBase的接口
- 缓存中维护着已经访问过的
Region位置信息,用来加快后续数据访问过程
Zookeeper服务器:
- 帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题
- 很好的集群管理工具
Master服务器:主服务器Master主要负责表和Region的管理工作:
- 管理用户对表的增加、删除、修改、查询等操作
- 实现不同Region服务器之间的负载均衡
- 在Region分裂或合并后,负责重新调整Region的分布
- 对发生故障失效的Region服务器上的Region进行迁移
Region服务器
- HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
Region服务器的工作原理
- 用户读写数据过程
- 用户写入数据时,被分配到相应Region服务器去执行
- 用户数据首先被写入到
MemStore和Hlog中 - 只有当操作写入
Hlog之后,调用commit()方法才会将其返回给客户端 - 当用户读取数据时, Region服务器会首先访问
MemStore缓存,如果找不到,再到磁盘的StoreFile中寻找
- 缓存的刷新
- 系统会周期性地把
MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记 - 每次刷写都生成一个新的
StoreFile文件,因此,每个Store包含多个StoreFile文件 - 每个Region服务器都有一个自己的
HLog文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务
- 系统会周期性地把
StoreFile的合并- 每次刷写都生成一个新的
StoreFile,数量太多,影响查找速度 - 调用
Store.compact()把多个StoreFile合并成一个 - 合并操作比较耗费资源,只有数量达到一定阈值后才会启动合并
- 每次刷写都生成一个新的
Store工作原理
Store是Region服务器的核心- 多个
StoreFile合并成一个StoreFile - 单个
StoreFile过大时,又触发分裂操作,1个父Region被分裂成两个子Region
HLog工作原理
保证系统发生故障时能够恢复到正确的状态
[第四章:HBase (datawhalechina.github.io)](https://datawhalechina.github.io/juicy-bigdata/#/ch4 HBase?id=_432-表和region)
实验
Datawhale![]()
大数据技术相关内容的导论课程:妙趣横生大数据 Juicy Big Data
Datawahle组队学习——妙趣横生大数据 Day3相关推荐
- 资源 | AI、神经网络、机器学习、深度学习以及大数据学习备忘单
向AI转型的程序员都关注了这个号☝☝☝ 以下是关于神经网络.机器学习.深度学习以及大数据学习的备忘单,其中部分内容和此前发布的<资源 | 值得收藏的 27 个机器学习的小抄>有所重复,大家 ...
- 新手如何学习云计算大数据,云计算的学习路线
如今云计算火的一塌糊涂,不管你是男生还是女生就业前景摆在那里,只要你有技术有能力,前景不可限量,所以,不要担心就业前景的问题,要担心就担心你自己的能力问题.只有你真正的掌握了技术,才能有更好的就业发展 ...
- 深度学习 vs. 大数据:神经网络权值的版权属于谁?
深度学习 vs. 大数据:神经网络权值的版权属于谁? width="22" height="16" src="http://hits.sinaj ...
- Python之GUI:基于Python的GUI界面设计的一套AI课程学习(机器学习、深度学习、大数据、云计算等)推荐系统(包括语音生成、识别等前沿黑科技)
Python之GUI:基于Python的GUI界面设计的一套AI课程学习(机器学习.深度学习.大数据.云计算等)推荐系统(包括语音生成.识别等前沿黑科技) 导读 基于Python的GUI界面设计的一套 ...
- 量化学习:大数据时代的学习方式
摘 要:未来人工智能.大数据.学习分析等技术被广泛应用于教育教学中,量化学习将成为新的研究热点.本研究首先对量化学习的内涵.特征.工具和方法进行概述,然后阐述了量化学习的价值意义和应用案例,进而分析了 ...
- 深度学习和大数据之间,主要是什么关系?
1)深度学习(Deep Learning)只是机器学习(Machine Learning)的一种类别,一个子领域.机器学习 > 深度学习 2)大数据(Big Data)不是具体的方法,甚至不算具 ...
- 四位顶级AI大牛纵论:深度学习和大数据结合的红利还能持续多久?
这轮 AI 热潮的很大一个特点就是底层技术方面在打通,虽然说过去对通用人工智能大家曾经有过很高的期望,但一直没有落地.这次,深度学习给大家带来了很多机会,使得我们在底层技术方面有了越来越多的共性.然而 ...
- 零基础学习java大数据真的难吗?
java是一门永不言败的开发语言,随着软件行业的兴盛,现在学习java的人员也是越来越多了,但是想要学好java的话自学是没有那么容易的事情.特别是对于零基础的学员来,所以对于零基础的学员来说都是要参 ...
- 大数据开发学习,大数据学习路线(完整详细版)
很多初学者,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习qq群:199427210,有大量干货(零 ...
最新文章
- 如何对单手和双手协同运动方向进行神经表征和解码?北理工研究团队给出了相关方案
- CVPR 2021 | 天津大学提出PISE:形状与纹理解耦的人体图像生成与编辑方法
- ABAPGit的安装方式
- 天梯赛模拟 链表去重 (25 分)
- 炒股要学会向动物学习
- scrollbar wpf 高度_Wpf ScrollBar自定义样式
- atitit.attilax的软件 架构 理念.docx
- MATLAB复数相关运用
- 花生壳 linux客户端 命令
- STM32学习(二)
- 获取时间戳,以秒,毫秒,微妙为单位
- 用户体系分离项目总结
- 写代码不行,考研没考上,怎么办?
- 计算机高层应用,计算机通信技术在高层建筑智能化工程中的应用
- a标签去掉下划线_HTML 所有标签列表
- vue表格实现前端分页
- 外汇优势 炒外汇优势 外汇保证金交易的优点有哪些?
- CloudCompare源码分析_八叉树(Octree)算法基础CC中的八叉树结构
- 招募法师盗贼开箱游戏java,法师和盗贼经常用的宏
- Word控件Spire.Doc 【其他】教程(7): 使用象征符号在 Word 中绘制复选框