王阳明心学 量子物理_量子物理学论文的文本分类
王阳明心学 量子物理
Have you ever been looking for the most recent research findings in machine learning or AI, and found yourself on arxiv.org, perusing the Computer Science section? (If you haven’t you should definitely check it out, it’s a great open-source website of the latest research findings in a variety of topics.) How about browsing vixra.org?
您是否一直在寻找有关机器学习或AI的最新研究成果,并在arxiv.org上仔细阅读“计算机科学”部分,从而发现自己? (如果您还没有的话,绝对应该查看一下它,它是一个很棒的开源网站,提供有关各个主题的最新研究结果。)浏览vixra.org怎么样 ?
If you have heard about the first, but not of the second, you’re not alone. For an in-depth comparison of the two I refer the reader to each website’s Wikipedia articles (arXiv, viXra); what’s important to us, however, is that the two sites are very different. It’s enough to take a look at the first paragraphs of two papers next to each other to see a distinct style:
如果您听说过第一个,但不是第二个,则您并不孤单。 为了对两者进行深入的比较,我向读者介绍了每个网站的Wikipedia文章( arXiv和viXra )。 但是,对我们而言重要的是,这两个站点非常不同。 看看彼此相邻的两篇论文的第一段就足够了,从而看到一种独特的样式:
While there is no strict peer-review process on either website, publishing on arxiv.org has stricter guidelines, and as a result papers on this website are usually high-quality research papers. Meanwhile, the guidelines of vixra.org are less strict, and notes published there tend to be less mathematically rigorous, and more speculative in nature.
尽管在两个网站上都没有严格的同行评审过程,但是在arxiv.org上发布具有更严格的指南,因此,该网站上的论文通常是高质量的研究论文。 同时,vixra.org的准则不太严格,并且在那里发表的笔记在数学上往往不太严格,而且本质上是投机性的。
Would an algorithm be able to tell whether a paper originates from arxiv.org or from vixra.org?
算法能否判断论文是来自arxiv.org还是来自vixra.org?
The question I wanted to answer is: while a researcher in Quantum Physics can usually tell the difference between two papers from each of these websites, would an algorithm be able to tell whether a paper originates from arxiv.org or from vixra.org?
我想回答的问题是:尽管量子物理学的研究人员通常可以分辨出来自每个网站的两篇论文之间的区别,但是一种算法能否分辨出论文是来自arxiv.org还是来自vixra.org?
采集数据 (Acquiring data)
For this classification task, I decided to focus on a research area that exists on both arXiv and viXra: quantum physics. This way, the classification won’t focus on the topic (for example, astrophysics vs. quantum physics papers will have wildly different verbiage and style).
对于此分类任务,我决定专注于arXiv和viXra上都存在的研究领域:量子物理学。 这样,分类就不再关注该主题了(例如,天体物理学与量子物理学的论文将有截然不同的语言和风格)。
Both websites require all uploads to present a rendered and readable pdf file. Most arXiv uploads also have source files from which the pdf was compiled, these are pure-text tex files. As I ultimately need text from the papers, the best approach would be to try to get these text-based source files. However, not all arXiv papers have these, and most viXra papers don’t have them either (they are usually pdf versions of a Microsoft Word document).
这两个网站都要求所有上载内容以呈现呈现且可读的pdf文件。 大多数arXiv上传文件还包含从中编译pdf的源文件,这些文件是纯文本tex文件。 当我最终需要论文中的文本时,最好的方法是尝试获取这些基于文本的源文件。 但是,并非所有arXiv论文都包含这些文档,大多数viXra论文也不包含这些文档(它们通常是Microsoft Word文档的pdf版本)。
A quick solution is to download the pdfs only from both sources, and use the pdfminer Python library to extract the text.
一种快速的解决方案是仅从两个来源下载pdf,然后使用pdfminer Python库提取文本。
I used Python’s requests library together with Beautifulsoup to find the specific pdf urls and download 600+ papers from each website. Here’s a code snippet for finding all papers in the “quant-ph” category of arXiv, uploaded in August 2020:
我将Python的请求库与Beautifulsoup一起使用,以查找特定的pdf网址,并从每个网站下载600多种论文。 这是一个代码片段,用于查找2020年8月上传的arXiv的“ quant-ph”类别中的所有论文:
import reimport requestsfrom bs4 import BeautifulSoup# Get list of all papers submitted in August 2020topic = 'quant-ph'year = '20'month = '08'max_records = '1000'base_url = f"https://arxiv.org/list/{topic}/{year}{month}?show={max_records}"r = requests.get(base_url)soup = BeautifulSoup(r.content)sub_urls = soup.find_all("a") # Find all urls on this website# Cycle through all urls and find the ones pointing at a paperquant_ph_papers = []for item in sub_urls: url = item.get('href') if url: # If this item is a url, grab the paper identifier result = re.search(r'/pdf/(\d\d\d\d.\d+)', url) if result: quant_ph_papers.append(result.group(1))After we have a list of papers we’re interested in downloading, we simply need to cycle through them and download them one-by-one:
在获得了我们想要下载的论文列表之后,我们只需要循环浏览并逐一下载即可:
import requestsimport time# Cycle through all paper identifiers found, and download each pdffor paper_id in quant_ph_papers: r = requests.get(f"https://arxiv.org/pdf/{paper_id}.pdf") if r.status_code == 200: with open(f"./arxiv/{paper_id}.pdf", 'wb') as f: f.write(r.content) # Sleep for 1 second after each download time.sleep(1)Downloading papers from viXra follows the same pattern, with the addition that trying to use the requests library results in a 406 response when accessing vixra.org. This is likely due to the maintainers of viXra trying to prevent programmatic, mass access to their website, as changing the User Agent from the default “python-requests” one circumvents the problem. Here is a list of potential User Agents you might use for your GET requests, for example:
从viXra下载论文遵循相同的模式,另外,访问vixra.org时尝试使用请求库会导致406响应。 这可能是由于viXra的维护者试图阻止以编程方式大规模访问其网站,因为从默认的“ python-requests”更改用户代理可避免此问题。 这是您可能用于GET请求的潜在用户代理的列表,例如:
base_url = f"https://vixra.org/{topic}/{year}{month}"r = requests.get(base_url, headers={"User-Agent": "Mozilla/5.0 (Linux; Android 7.0; SM-T827R4 Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.116 Safari/537.36"})提取文字 (Extracting text)
After acquiring the pdf files, the next step is to extract the text. Loading and performing the extraction on a pdf file is a slow process, so it’s best to do this upfront, and only once:
获取pdf文件后,下一步是提取文本。 在pdf文件上加载和执行提取是一个缓慢的过程,因此最好先进行一次,并且只执行一次:
import osfrom pdfminer.high_level import extract_textarxiv_files = [f for f in os.listdir('./arxiv')]for fn in arxiv_files: # Load pdf and save the extracted text as a text file try: full_text = extract_text('./arxiv/' + fn) failed = False except Exception as e: print(f"Error {e} happened:") print(f">>Failed to parse {fn}") failed = True if not failed: # Save the extracted text with open(f"texts/arxiv/{fn[0:-4]}.txt", 'wb') as f: f.write(full_text.encode('utf8'))将每篇论文表示为一组功能 (Represent each paper as a set of features)
We have all our labeled data on our hard drive — now what?
我们所有的标签数据都存储在硬盘上-现在呢?
For the purposes of text classification, we’ll need to create a set of features from each paper. For this part of the tutorial, I will assume that the reader is familiar with basic NLP concepts like stop words, tokenization, vector representation of tokens, but haven’t done text classification before (as I haven’t!).
出于文本分类的目的,我们需要在每篇论文中创建一组功能。 在本教程的这一部分中,我将假定读者熟悉基本的NLP概念,例如停用词,标记化,标记的矢量表示,但是之前没有做过文本分类(因为我还没有!)。
Creating features can be approached in several ways. Some ideas for features I found helpful are:
创建特征可以通过多种方式进行。 我发现有帮助的功能的一些想法是:
- Use the number of words in the paper and the average number of characters in a word;
使用论文中的单词数和单词中的平均字符数; - Bag-of-words model, i.e., counting the occurrence of each unique word in the text;
词袋模型,即计算文本中每个唯一词的出现; - Creating a vector representation of each word, and averaging all representations within the text;
为每个单词创建矢量表示,并对文本中的所有表示求平均; - Feeding vector representations of words through a trained neural net to create a representation of the text.
通过训练有素的神经网络馈送单词的矢量表示,以创建文本的表示。
As I wanted to try advanced techniques in this project, I started with 3 and 4.
当我想尝试该项目中的高级技术时,我从3和4开始。
使用spaCy创建平均矢量表示 (Using spaCy to create an averaged vector representation)
Spacy is an NLP package with pre-trained models that allows you to tokenize and vectorize words quite easily. I used their large English model:
Spacy是具有预训练模型的NLP软件包,可让您非常轻松地对单词进行标记和向量化。 我使用了他们的大型英语模型 :
import numpy as npimport spacynlp = spacy.load('en_vectors_web_lg')def get_average_token_for_text(text: str) -> np.ndarray: tokens = nlp(text) vectors = [token.vector for token in tokens] all_vecs = np.array(vectors) vec = np.mean(all_vecs, axis=0) return vecThis approach vectorizes each word/token individually, then takes an element-wise average of the resulting vectors throughout the text.
这种方法分别对每个单词/令牌进行矢量化处理,然后对整个文本中的矢量进行元素平均。
The resulting representation is a single vector, and can be interpreted as a single “master token”, which stands for the entire text. It is essentially a single-word summary of the entire text.
所得表示形式是单个矢量,并且可以解释为单个“主令牌”,代表整个文本。 它本质上是整个文本的一个单词摘要。
I applied this method to all texts downloaded from arXiv and viXra.
我将此方法应用于从arXiv和viXra下载的所有文本。
Without further preprocessing, I trained a couple of different classifiers (Logistic Regression, Random Forest, K Nearest Neighbors, Naive Bayes) on this data, with a 70–30% train-test split (training set: 942, test set: 405 papers, with a close to 50–50% allocation for each category).
在没有进一步预处理的情况下,我使用此数据训练了几个不同的分类器(逻辑回归,随机森林,K最近邻,朴素贝叶斯),并进行了70–30%的训练测试拆分(训练集:942,测试集:405篇论文) ,每个类别的分配接近50–50%)。
Logistic Regression produced the best results, by far overperforming the others by about 5–10 percentage points for the resulting F1-score (0.897).
Logistic回归产生了最好的结果,远远超过了其他F1得分(0.897)约5-10个百分点。
前512个字使用BERT (Using BERT with first 512 words)
BERT is another, state-of-the-art language model, developed by Google [published in 2018 — look, an arXiv paper!]. Using the pre-trained tokenizers and models of BERT allows you to leverage already learned representations of words, as well as representations of texts. The latter, contrary to the simplistic approach we took with spaCy above, takes into account structure and word order.
BERT是Google开发的另一种最先进的语言模型[ 于2018年发布 -外观,arXiv论文!]。 使用BERT的预训练标记器和模型,您可以利用已经学习的单词表示形式以及文本表示形式。 与我们上面使用spaCy的简单方法相反,后者考虑了结构和词序。
I used the base cased BERT model, available through the Python “huggingface” library. This base model can take at most 512 tokens. Then, it creates a representation of these by feeding a combination of the word vectors (a tensor) through a pre-trained neural network. The output of the network is a single vector, representing the entire text that was fed into it.
我使用了基本案例的 BERT模型, 该模型可通过Python“ huggingface”库获得 。 此基本模型最多可以使用512个令牌。 然后,它通过预训练的神经网络输入单词向量(张量)的组合来创建这些表达。 网络的输出是单个向量,代表输入到其中的整个文本。
from typing import Listimport numpy as npimport torchfrom transformers import BertModel, BertTokenizer, BertConfig# Load BERT tokenizer and modelmodel_name = 'bert-base-cased'tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)config = BertConfig.from_pretrained(model_name)def get_tokens(text: str, tokenizer: BertTokenizer, config: BertConfig) -> List[str]: tokens = tokenizer.tokenize(text) max_length = config.max_position_embeddings tokens = tokens[:max_length-1] tokens = [tokenizer.cls_token] + tokens return tokensdef make_vector(text: str) -> np.ndarray: tokens = get_tokens(text, tokenizer, config) token_ids: List[int] = tokenizer.convert_tokens_to_ids(tokens) token_ids_tensor = torch.tensor(token_ids) token_ids_tensor = torch.unsqueeze(token_ids_tensor, 0) last_hidden_state, pooler_output = model(token_ids_tensor) vector = pooler_output np_vector = vector.detach().numpy() np_vector = np_vector.squeeze() return np_vectorApplying this representation to all papers, Logistic Regression is still the best choice for classifier, and it yields results comparable to the spaCy model.
将这种表示形式应用于所有论文,Logistic回归仍然是分类器的最佳选择,其结果可与spaCy模型媲美。
However, as this implementation of BERT only takes into account the first 512 words of every paper, I wanted to try out explicitly adding the length of the text as a feature. I chose character length, and tried both adding it as a raw feature, as well as applying standard scaling to the features before classification. While this step in itself didn’t improve the model much, it nicely illustrates the need for feature scaling!
但是,由于BERT的这种实现方式只考虑了每篇论文的前512个单词,因此我想尝试显式地添加文本的长度作为功能。 我选择了字符长度,并尝试将其添加为原始特征,以及在分类之前对这些特征应用标准缩放。 尽管这一步骤本身并没有太大改善模型,但很好地说明了功能扩展的必要性!
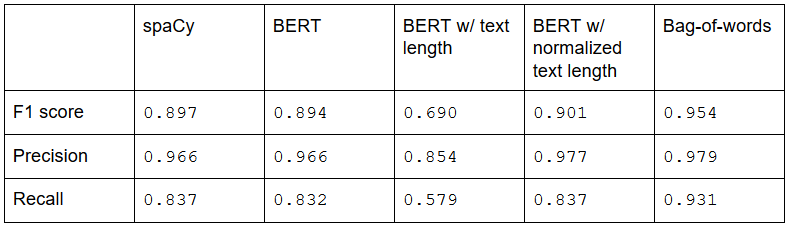
怎么提高 (How to improve)
In order to further improve the models, I inspected the misclassified papers. Some arXiv papers that were misclassified are: a typical single-author arXiv paper, a paper on the consequences of living inside a computer simulation, a paper touching on philosophy and Gödel’s theorem, among others.
为了进一步改进模型,我检查了分类错误的论文。 一些被错误分类的arXiv论文是: 典型的单作者arXiv论文 , 关于生活在计算机模拟中的后果的 论文,涉及哲学和哥德尔定理的论文 ,等等。
Some of these papers have a style or topic that can indeed be misconstrued as the other category. However, the terms and rigor used throughout the papers should be sufficient indication enough to identify these correctly.
其中一些论文的风格或主题确实可以被误认为是另一类。 但是,整篇论文中使用的术语和严谨性应足以表明它们是否正确。
Maybe I tried to use word order and correlations when really I should have used simply the list of words as features? I took a step back and tried a simple bag-of-words model.
也许我真的应该只使用单词列表作为特征时尝试使用单词顺序和相关性? 我退后一步,尝试了一个简单的单词袋模型。
词袋模型 (Bag-of-words model)
This model represents each text as a simple “dictionary” of sorts: each word is assigned an id, and each id in turn has a number for each text, representing the number of times that word appears in the text.
该模型将每个文本表示为简单的“字典”:将每个单词分配一个ID,每个ID依次为每个文本指定一个数字,表示该单词在文本中出现的次数。
It is not too difficult to write an implementation of bag-of-words, but for this exercise I used BERT’s already available tokenizer and identifier. I needed to modify the previous “get_tokens” method so it doesn’t cut off words after reaching a length of 512:
编写单词袋的实现不是太困难,但是对于本练习,我使用了BERT已有的令牌生成器和标识符。 我需要修改以前的“ get_tokens”方法,以使其在达到512个长度后不会切断单词:
from typing import Listfrom transformers import BertTokenizerdef get_tokens_unlimited(text: str, tokenizer: BertTokenizer) -> List[str]: tokens = tokenizer.tokenize(text) tokens = [tokenizer.cls_token] + tokens return tokensdef token_ids_to_bow(id_list: List[int]) -> dict: bow = dict() for i in id_list: if i in bow.keys(): bow[i] += 1 else: bow[i] = 1 return bowThen, looping through all files, and creating a matrix with all possible token ids:
然后,遍历所有文件,并创建具有所有可能的令牌ID的矩阵:
import pandas as pdimport picklefrom transformers import BertTokenizer# Load BERT tokenizer and modelmodel_name = 'bert-base-cased'tokenizer = BertTokenizer.from_pretrained(model_name)arxiv_files = [f for f in os.listdir('./texts/arxiv')]df = pd.DataFrame()i = 0for fn in arxiv_files: try: with open(f"texts/arxiv/{fn}", 'r', encoding='utf8') as f: full_text = f.read() failed = False except Exception as e: print(f"Error {e} happened:") print(f">>Failed to parse {fn}") failed = True if not failed: tokens = get_tokens_unlimited(full_text, tokenizer) token_ids = tokenizer.convert_tokens_to_ids(tokens) bow = token_ids_to_bow(token_ids) df_i = pd.DataFrame(data=bow, index=[i]) df = pd.concat([df, df_i]) i += 1with open('bow/arxiv/arxiv_bow_features.p', 'wb') as f: pickle.dump(df, f)Filling all missing values with “0” and applying standard scaling before classification, this model outperforms all previous models.
在分类之前将所有缺失值填充为“ 0”并应用标准缩放比例,该模型的性能优于之前的所有模型。
Here is a comparison of ROC curves for each model considered:
这是每种模型的ROC曲线的比较:
我们仍然错误分类了什么? (What do we still misclassify?)
Some papers from the arXiv we still misclassified are: a single-author paper on a unique interpretation of quantum mechanics, a short note meant to be a “Comment” to a previous paper, a response to a previous comment.
我们仍然将arXiv中的一些论文归类为: 关于量子力学独特解释的单作者论文 , 旨在作为对先前论文的“评论”的简短注释 , 是对先前评论的回应 。
A number of these indeed have a different, and more informal format and tone!
其中许多确实具有不同且更加非正式的格式和基调!
Some papers from viXra.org we misclassified are: a paper about compressed data, measurements and observations, one about applying quantum annealing to a scheduling problem, and an Addendum by a former colleague of mine to a previous arXiv paper.
来自viXra.org的一些论文被误分类为: 一篇关于压缩数据,测量和观测的论文 , 一篇关于将量子退火应用于调度问题的论文 ,以及我的一位前同事对先前arXiv论文的附录 。
All in all, not bad! A number of these seem to be rigorous enough that could be published on the arXiv just as well.
总而言之,还不错! 其中许多似乎足够严格,也可以在arXiv上发布。
结论 (Conclusions)
In summary, we have achieved quite good classification results with most models. Typically, arXiv papers and viXra papers are different in length, structure, rigor, and verbiage and so it is quite clear which category any given paper falls into. This allows us to approach the problem with different models and achieve similar results.
总而言之,我们对大多数模型都取得了很好的分类结果。 通常,arXiv纸和viXra纸的长度,结构,严谨性和语言差异都不同,因此很明显任何给定的纸属于哪一类。 这使我们可以使用不同的模型来解决问题并获得相似的结果。
It turns out that the classic bag-of-words model for feature encoding, and Logistic Regression for classification performed best. This should reinforce the practice to always start simple, and add complexity only as needed!
事实证明,用于特征编码的经典词袋模型和用于分类的Logistic回归性能最好。 这应该加强练习,使其始终从简单开始,并仅在需要时才添加复杂性!
What’s next? Well, if you’re interested in research paper classification, there’s a number of avenues to explore:
下一步是什么? 好吧,如果您对研究论文分类感兴趣,则有许多方法可以探索:
- Can we build a good classifier with even simpler features, like (e.g.) length and most frequent 50 words (only)? What are the most important features?
我们可以建立一个更好的分类器,使其具有更简单的功能,例如(例如)长度和最常见的50个单词(仅)吗? 最重要的功能是什么? - Can we improve on the current classifiers by toggling capitalization, removing stop words, and other preprocessing steps?
我们是否可以通过切换大小写,删除停用词和其他预处理步骤来改进当前分类器? - Can we extend this classifier to other topics? I looked at quantum physics only. What about a topic-agnostic arXiv vs. viXra classifier?
我们可以将此分类器扩展到其他主题吗? 我只看了量子物理学。 与主题无关的arXiv与viXra分类器如何处理? - Can we build something more sophisticated for arXiv papers, like finding the closest paper (stylistically) to another paper?
我们是否可以为arXiv论文构建更复杂的内容,例如(从风格上)寻找与另一篇论文最接近的论文? - What about being able to tell who the author(s) is (are) of a new paper, based on similarity to other papers already published?
基于与已经发表的其他论文的相似性,能够判断谁是新论文的作者呢?
翻译自: https://medium.com/@komaranna137/text-classification-of-quantum-physics-papers-702da42b5268
王阳明心学 量子物理
相关文章:
- 王阳明心学思考
- 王阳明心学感悟1——勇敢地剖析自己的内心
- 深度哲学:王阳明心学精髓
- 【王阳明心学语录】-001
- 重温王阳明心学
- 王阳明心学 之 心即理感悟
- 知乎关于王阳明心学的高赞答案。
- 王阳明心学的智慧
- 王阳明心学研究
- 王阳明 心学
- 王阳明与阳明心学
- ps 仿章工具的使用
- PS--怎么取消之前选择的工具?
- PS如何快速使用对象选择工具抠图?
- PS之5分钟学会使用快速选择工具抠图
- Ps中的钢笔工具和快速选择工具
- ps基础学习:钢笔工具抠图
- PS——选区工具组
- html5如何快速选择工具,PS快速选择工具怎么使用?快捷键是什么?
- 找不到ps选择主体_怎么找不到ps“选择主体”功能?
- PS里面的快速选区工具
- 让自己更积极、阳光、拼搏、向上的方法
- 提升自己的方式
- 关于技能提升的方法
- 有什么软件能每天提醒自己坚持吗?每日定时提醒做某事的便签
- 如何提高自己的java开发功底
- 怎么做期货可以每天都赚钱?都有哪些技巧和方法?
- 如何提高自己的编程能力
- 空闲时间不要接私活,要提升自己
- 目标检测比赛提高mAP的方法
王阳明心学 量子物理_量子物理学论文的文本分类相关推荐
- 狐言:王阳明心学、量子物理、心外无物的乱弹
声明:对于王阳明心学与量子物理,我都算不上一知半解,只能算毫知末解,以下皆为狐言乱弹. 在网易公开课上听浙江大学的董平教授讲王阳明心学,他对阳明心学是否是唯心主义有自己的看法.对于阳明心学中最著名的一 ...
- 王阳明心学:此心光明,夫复何言
王阳明心学:此心光明,夫复何言 <传习录>里记载了王阳明和他的门徒九川这样的一段对话: 九川卧病虔州.先生云:"病物亦难格,觉得如何?"对曰:"功夫甚难.&q ...
- 深度哲学:王阳明心学精髓
如果说,在中国有且只能评出一位哲学家,那么我认为就是王阳明. 这是因为他不仅在哲学思想上造诣极深,通达了那个彼岸世界或者称之为超感性世界,而且在人生的实践之中,将其所创立的心学运用的炉火纯青,有所向披 ...
- 《王阳明心学营销》营销落地-知行合一
王阳明心学营销的落地的精髓 知行合一.成功都是磨出来的,让我们聚焦,做到极致. 华为发展过程中可以看到成功都是抓住了 华为的通讯的机遇,做到极致 苹果手机注重我们美学 做到极致. 知:先研究这个知识 ...
- [每周心学]浙江大学公开课:王阳明心学
本课程共9集 更新至第9集 欢迎学习 浙江大学公开课:王阳明心学(点击观看) 课程介绍: 基于王阳明心学体系之结构的全面把握,本课程比较全面而系统地讲解.阐述了王阳明的心学思想,对其思想体系中的一些主 ...
- 每月一书(202112):《王阳明心学》
现在是每月一书的时间,本月没有阅读具体的书,而是看了一套视频,视频名称为浙江大学公开课:王阳明心学,视频的作者是董平教授. 上个月通过阅读书籍知道了王阳明的生平,不过没有学到太多心学的内容,因此本月在 ...
- 18图详解:王阳明心学到底说了啥?
阳明心学是中国古代哲学的一种,其核心观点可以概括为"心即理也"."知行合一"和"致良知". 1. "心即理也" 阳明心学 ...
- 王阳明心学的基础概念和核心思想
简介 王阳明(1472年-1529年),字仲弓,号阳明,是明代著名的哲学家.思想家和军事家.他的思想被称为"心学",是中国思想史上的重要流派之一. 心学核心概念 王阳明心学的基础概 ...
- 王阳明心学主要讲了什么
王阳明是一位中国哲学家,他的心学主要讲述了有关人类心灵.心理和道德方面的问题.王阳明认为,人类的本质是仁爱,仁爱是人与人之间自然而又基本的关系.人的心灵应当发展成一种"纯净心",这 ...
最新文章
- zabbix.php访问不了_zabbix_配置Nginx连接php
- 田志刚:为什么要尊重老师?
- python 冒泡排序算法(超级详细)
- Android10崩溃,华为荣耀Android10崩溃
- ubuntu声音太小的解决方案
- jframe和mysql登陆_刚写的一个从数据库读取账户和密码进行登陆的小程序~高手请无~...
- ffmpeg-从flv文件中提取AAC音频数据保存为文件
- android录屏存在什么位置,安卓视频录制在哪里
- python删除单元格_Openpyxl删除单元格/清除内容
- Nand2Tetris Project1
- 数商云化妆品行业电商平台系统解决方案
- TabLayout+ViewPager实现tab切换
- linux sort排序及取前几条数据
- 公开「处刑」!波士顿动力的搬砖机器人,私下竟「翻车」不断
- java 线程阻止_Java:在特定队列大小后阻止提交的ExecutorService
- java 机器人捡豆子,【小孩老是注意力不集中】_小儿_怎么办-大众养生网
- linux firefox严重卡顿,火狐浏览器卡顿怎么办 卡顿解决方法一览
- 【HCIP题库哪里买?】
- 机器学习总结2 #博学谷IT学习技术支持#
- 编辑MD文件的语法格式